
- 03.06.2023
- 01.10.2025
- выступления
Слайды: model_sustainability.pdf
Текстовая расшифровка:

Расскажу про устойчивость моделей машинного обучения. Так получилось, что это вторая часть доклада. Первую (обзорную) часть рассказал в Екатеринбурге, а вторую сберег до ДатаФеста.
 Меня зовут Дмитрий Колодезев.
Меня зовут Дмитрий Колодезев.
- Про меня знает ChatGPT.
- Краткая справка про меня есть на сайте.
- С Ириной Голощаповой ведем канал ReliableML.
- Прочитал курс по дизайну систем машинного обучения.
- Организовываю дата-завтраки в Новосибирске.
- Директор ООО Промсофт.

О чем будем рассказывать:
- Что такое ReliableML
- Что такое "устойчивость" моделей
- Почему модель может работать плохо
- Как узнать, что она уже
- Что в этом случае делать
- Сколько можно ждать замены модели
- Что почитать + анонсы
 ReliableML это:
ReliableML это:
- название секции DataFest 2023
- канал в Телеграме
- Фреймворк, помогающий управлять внедрением и развитием продвинутой аналитики, чтобы ее результат был применим в бизнес-процессах и приносил компании финансовую пользу
- хорошая книга про ReliableML, в основном про MLOps и написана не нами
- наша с Ириной будущая книга про то, как внедрять ML в бизнес-процессы, от формирования портфеля проектов до мониторинга модельного риска.

В этом докладе хотелось обсудить жизнь модели после деплоя.
Модели бывают развернуты в продуктовую среду (прод) очень по-разному, но для наших целей их полезно разделить на 3 группы.
- Модели в прошивках оборудования,
- Модели в сервисах, построенных вокруг ML, где ML - основа бизнес-процесса.
- Модели как одна из вспомогательных частей бизнес-процесса.
Во всех этих мирах есть своя особенность жизни модели. Например, в прошивках оборудования реальный конечный пользователь бесконечно далек от ML-разработчика.
Ему прошили что-то в оборудовании,оборудование себя как-то ведет, и он воспринимает это, скорее всего, как данность, либо как сломавшееся оборудование.
Например, сейчас во многие медицинские приборы начинают вшивать ML-модели, и на тестах они ведут себя хорошо, а как они ведут себя у пользователей, мы не всегда знаем.
У Microsoft был такой опыт: они сделали модель для выявления повреждений сетчатки при диабете.
Модель в американском госпитале работала хорошо, в индийском госпитале работала плохо, там оборудование чуть-чуть другое, нейронка не видела этих повреждений сетчатки.
Вообще, медицинское оборудование умеет убивать. Есть история про то, как аппарат лучевой терапии убивал людей из-за неправильных настроек. Как операторы могли понять, что аппарат ведет себя неправильно? Им привезли людей больных раком. Они их лечили. Люди умерли. От рака умирают. Вроде все идет не то, чтобы хорошо, но по плану.
Точно так же умные камеры, например. Предположим, что камера считает посетителей в магазине. Как мы узнаем, что она не видит 10% посетителей просто потому, что они сменили летнюю одежду на зимнюю? То есть с мониторингом умных устройств обычно все плохо. Будет еще и хуже, потому что сейчас ML-модели встроены много где, и часто прошиты в железо, где их так просто не обновишь. Например, модель, используемая фотоаппаратом для поиска лица в кадре.
Есть мнение, что любое оборудование, имеющее IP-адрес, должно иметь либо фиксированный срок жизни, либо обязательную возможность обновлять прошивку. И, от себя добавлю, возможность обновлять модели.
Еще есть сервисы, построенные вокруг ML. Поиск, рекомендательные системы из "совсем большого IT". В мире ML это как Formula 1, и у них все сравнительно хорошо. Где-то рядом с ML-моделью стоит команда, которая поддерживает ее, кормит, смазывает и следит за тем, чтобы у нее было все отлично. У них совсем другие проблемы, мы их не будем рассматривать.
Гораздо чаще машинное обучение встречается как одна из частей бизнес-процесса, в котором ML - второстепенная часть, служебная шестеренка. То есть это какой-нибудь скоринг, предсказание продаж. Скоринг не обязательно кредитный. Скоринг может быть судебный, кадровый. Оценка сроков, рекомендательная система в интернет-магазине.
То есть там, где модель приносит нам деньги. Там, где ее отказ стоит нам денег, но такой вот большой катастрофы в случае отказа не ожидается.
Владельцы этого процесса, конечно, имеют доступ к ML-разработчикам, но зачастую это сделано либо аутсорсерами, либо специальной командой по цифровой трансформации бизнеса, которая пришла, навела порядок и ушла. Вот про них мы сейчас и поговорим.

Когда мы продаем ML-разработку, (я продаю ML-разработку), мы говорим заказчику: в обмен на капитальные затраты вы сможете повысить эффективность процессов.
Оказывается, кроме капитальных затрат на заказчика упадут дополнительные операционные затраты по поддержанию работоспособности модели. ML-модель - быстроизнашивающийся предмет, иногда приходит в негодность за полгода. И нам придется ее мониторить и доучивать. Операционные затраты при внедрении ML могут серьезно вырасти.
Далее, если раньше задачу делали люди, живые аналитики, а потом мы заменили их на ML-модель, процесс стал менее гибким.
Наверняка раньше у нас время от времени были какие-то странные случаи, люди звали начальство и разрешали проблему в ручном режиме, нарушая регламенты. Теперь у нас будет итальянская забастовка - будет делаться ровно то, чему модель научили.
И еще: эффект внедрения нестабилен. Мы повысили эффективность работы, но вот это вот повышение эффективности с каждым месяцем почему-то уменьшается.
Неприятно и интересно, почему так происходит.

Очень часто внедряемая модель плохо работала с самого начала. Не постепенно ухудшила качество, а начала работать плохо сразу после выкатки в прод, несмотря на хорошие метрики на тестовых данных.
Иногда она вообще не работала после выкатки. Неоднократно слышал истории про сервис, который забыли включить, включили не на том порту и так далее. Даже в условиях высокой нагрузки модель может не работать какое-то время и никто не заметит, если мониторинг налажен плохо.
Бывают проблемы с данными. Аномалии, выбросы, редкие значения, пропуски. При обучении модели этот мусор мы можем вычистить, а что делать в рабочем окружении?
Случается, что меняется распределение данных, пресловутый сдвиг данных, сдвиг меток, сдвиг чего-нибудь. Просто распределение поменялось.
Еще бывают отказы программные, аппаратные. Мог сервер умереть.
Бывает, что кто-то не оплатил сервер, включил для модели меньше воркеров, чем запрошено, включил сервисы не на том порту, неправильно настроил межсетевой экран и так далее. Это все организационные отказы - когда все бы работало, но люди сделали не то, не так, кто-то недопонял. Это должно решаться подходом "инфраструктура как код" - но и тут остается пространство для удивительных ошибок.
Могут быть проблемы с самой моделью.
Практически все модели недоопределены. Что такое недоопределенная модель? Это когда для заданных нами примеров, на которых мы ее учили, мы можем построить множество моделей, имеющих примерно одинаковую метрику качества, так называемый Rashomon Set. Термин обязан своему имени работе Лео Бреймана "Статистическое моделирование: две культуры".
То есть для нашей метрики все равно, какой конкретно моделью из этого множества хороших моделей решать задачу. Но бизнесу может быть не все равно.
Проблема обычно решается внесением какого-нибудь inductive bias. Например, мы знаем, что у нас веса в модели должны быть маленькими. Это регуляризация. Или мы знаем, как "на самом деле" влияет какой-то признак - и добавляем информацию о причинно-следственных связях. Или же добавляем аугментацию, потому что знаем, как данные могут быть искажены. Так или иначе, это решение проблемы недоопределенности модели.
Ну и еще модель может быть нестабильна или просто плохо обучена. Метрика, которой оценивали качество модели - F1 или ROC-AUC например, для бизнеса совершенно не интерпретируемая. Вроде показатели хорошие, а когда начали использовать, выясняется, что модель недостаточно хороша.
За пределами какого-нибудь чувствительного домена, вроде банков, редко рассматривают риски, связанные с атаками на модели. Но алгоритмы скоринга и ранжирования атакуют постоянно. Поисковые системы все время атакуют с целью сломать алгоритм ранжирования, как-то его подвинуть. По ссылке - краткое описание шести наиболее распространенных атак на ML-модели. Еще полезный Атлас угроз, с примерами и подробным разбором.
{kind=link}
Зачастую модели неправильно используют. Мы можем обучить модель для одной узкой задачи - но кто-то обязательно применит ее не по назначению. Например, мы обучим модель ранжирования инвестиционных предложений, и отдельно скажем, что Shapley Values для этой модели нельзя использовать для принятия управленческих решений. Но, как только мы отвернемся, кто-то именно так и сделает - потому что именно ему этого не объяснили.
Для таких случаев придумана ModelCard, в которой мы описываем назначение, область применимости и ограничения модели. И есть такой же подход для датасетов.

ML-системы, пользуясь терминологией Талеба, хрупкие. Из гибкого бизнес-процесса, в котором работают люди, мы делаем фиксированную программную систему.
Модели ищут шаблоны в исторических данных и воспроизводят их. Найденные шаблоны скрыты внутри модели, непрозрачны для пользователя и не могу быть им скорректированы.
Почти наверняка бизнес-процесс, схема или семантика данных будут меняться. Например, отдел маркетинга поменяет классификатор в CRM-системе. Мы ориентируемся на код классификатора. Они его просто переименуют, код останется тот же самый. Модель начнет выдавать ерунду.
Модели не приспосабливаются к изменениям (кроме онлайн-моделей, но они пока экзотика). И у пользователя обычно нет рычагов для адаптации модели к изменениям.
В моей практике была ужасная история как раз про CRM-систему, когда отдел маркетинга постоянно переименовывал классификаторы. Они всегда так делали, они к этому привыкли, и не понимали, почему теперь так нельзя. Можно было сделать, чтобы это не ломало модель, но никто не подумал об этом заранее. Заказчик сказал, что справочники фиксированы, а мы ему поверили. Двойная наивность, повлекшая множественные сложно отлаживаемые ошибки.

Как сделать ML-систему более гибкой?
Самый очевидный вариант - дать пользователю возможность настраивать пороги принятия решений, веса в линейных моделях. Подходит только для очень простых настроек. Например, есть у нас некий скор, по которому мы выдаем кредит, и мы можем его в аварийной ситуации задрать, чтобы кредиты выдавались только очень хорошим заемщикам, если мы видим, что идет что-то подозрительное. Но у пользователя такой рычаг должен быть.
Универсальный подход - строить ML-модель в виде kNN-классификатора поверх эмбеддингов. Строим сложную модель, а поверх ее эмбеддингов принимаем решение методом ближайших соседей. Чем это хорошо: иногда нам нужно обеспечить правильный ответ модели в какой-то новой для нас ситуации, для которой нам не удастся собрать обучающую выборку. Или дообучение модели займет много времени, а нам нужно вчера. Считаем эмбеддинг новой точки, добавляем в набор, и именно в этом месте модель начинает выдавать правильное решение. То есть мы можем модели на больное место наклеить лейкопластырь.
Сейчас в прод начинают выходить ML-системы поверх больших языковых моделей. Как следствие, люди пишут регулярные выражения которые проверяют и корректируют ответы ChatGPT. То есть регулярные выражения они могут корректировать и дописывать, а ChatGPT доучивать не могут. Еще из похожего Guardrails и Jsonformer.
Я не люблю low-code системы за некрасивые архитектурные решения вокруг них. Но они как раз дают возможность сохранять бизнес-процессы гибкими. Иногда слишком гибкими.
Еще ML-системы делают гибкими неструктурированные данные. Сегодня ребята рассказывали, как они заполняют карточку товара с помощью языковой модельи. Вместо того, чтобы писать регулярные выражения для извлечения характеристик товара из карточки поставщика, они собирают карточку товара в один большой текст - а потом вопросно-ответной системой извлекают нужные им поля. Чтобы не пропустить грубые ошибки, ставят оператора подтверждать решение модели. И больше чем в 70% случаях модель правильно заполняет карточку. Возможно, неструктурированные данные - будущее гибких ML систем.
Хорошо иметь в качестве последнего средства возможность переключения в ручной режим. Это не всегда возможно, но во многих случаях мы можем временно принимать решения вручную или вместо ML-модели принимать решения каким-то простым правилом.
Всякий раз, проектируя ML-систему, нужно пытаться сохранить гибкость бизнес процесса. Не только повысить его эффективность, но и добавить туда как можно меньше хрупкости. Автор коллекционирует антихрупкие решения. Если у вас есть примеры решений, снижающих хрупкость ML-систем, поделитесь, буду вам очень благодарен.
 Как мы узнаем, что с моделью что-то не то?
Как мы узнаем, что с моделью что-то не то?
Самое простое решение - во все сервисы добавлять функцию самопроверки, то есть какой-то простой дымовой тест, который мониторинг вызывает каждые несколько секунд или минут и проверяет, что система в принципе работает, доступна ли и есть ли у нее есть доступ к необходимым ресурсам.
Когда пора переобучать модель?
Мы можем обучить модель на старых данных и посмотреть, как со временем менялось качество прогноза. И, если предположить, что модель будет устаревать примерно с той же скоростью, что и до сих пор, мы можем оценить, как часто нужно ее переобучать. Проблема этого подхода в том, что скорость устаревания модели нестабильна.
Еще одна проблема - скорость вызревания разметки, или длина петли обратной связи.
Как быстро мы узнаем, что сделанное моделью предсказание было правильным или неправильным? Скорость вызревания меток сильно зависит от отрасли. Если мы рекомендуем рекламные ссылку на сайте, мы через несколько секунд после предсказания узнаем - кликнул посетитель по рекламе или нет. Если мы рекомендуем сложный товар в интернет-магазине, покупатель может думать несколько дней. Если мы выдали человеку кредит и он сразу решил его не платить, нам придется выждать довольно долго, прежде чем объявить дефолт по кредиту.
Если мы делаем систему для вуза, рекомендующую абитуриенту образовательный трек, мы можем ставить целью воспитать из него хорошего продуктивного специалиста, который проживет долгую счастливую жизнь и приведет своих детей в наш ВУЗ. Срок вызревания меток может составить 30 лет.
Для моделей с короткой петлей обратной связи мы можем отслеживать качество модели напрямую. Мы даем рекомендации, по ним не переходят - значит, рекомендация плохая.
Если же метки вызревают долго, нам нужно что-то специально предпринимать, чтобы сохранить способность учиться на своих ошибках.
Что такое "быстрое" и "медленное" вызревание меток? Если мы можем позволить себе деградацию модели до созревания метки - значит, метки вызревают достаточно быстро. Если мы не можем себе этого позволить - значит, метрики вызревают медленно.
Пример: Разметка по выданным микрокредитам приходит в течение 60 дней. Банк не готов 60 дней выдавать плохие кредиты. Значит, разметка вызревает медленно.
Если метки вызревают быстро, мы можем оперативно отслеживать качество предсказаний. Не понравилось, как работает модель - обучили новую. Не понравилось, как работает новая модель - откатились к старой.
Тут сработают подходы к мониторингу из SRE:
- SLI - Service Level Indicator. Индикатор, на который мы ориентирумеся Например, precision за последние 20 минут.
- SLO - Service Level Objective. Качество, устраивающее бизнес. Например, precision >= 95% в среднем за 20 минут.
- SLA - Service Level Agreement. Значение SLI, хуже которого мы обещали не падать. Например, в течение месяца наш SLI находится в нужных пределах в 99.9% случаев - то есть за 2 недели у нас только один отрезок в 20 минут со средним precision < 95%.
Это работает, когда петля обратной связи короткая, а данных много. Что делать в остальных случаях?
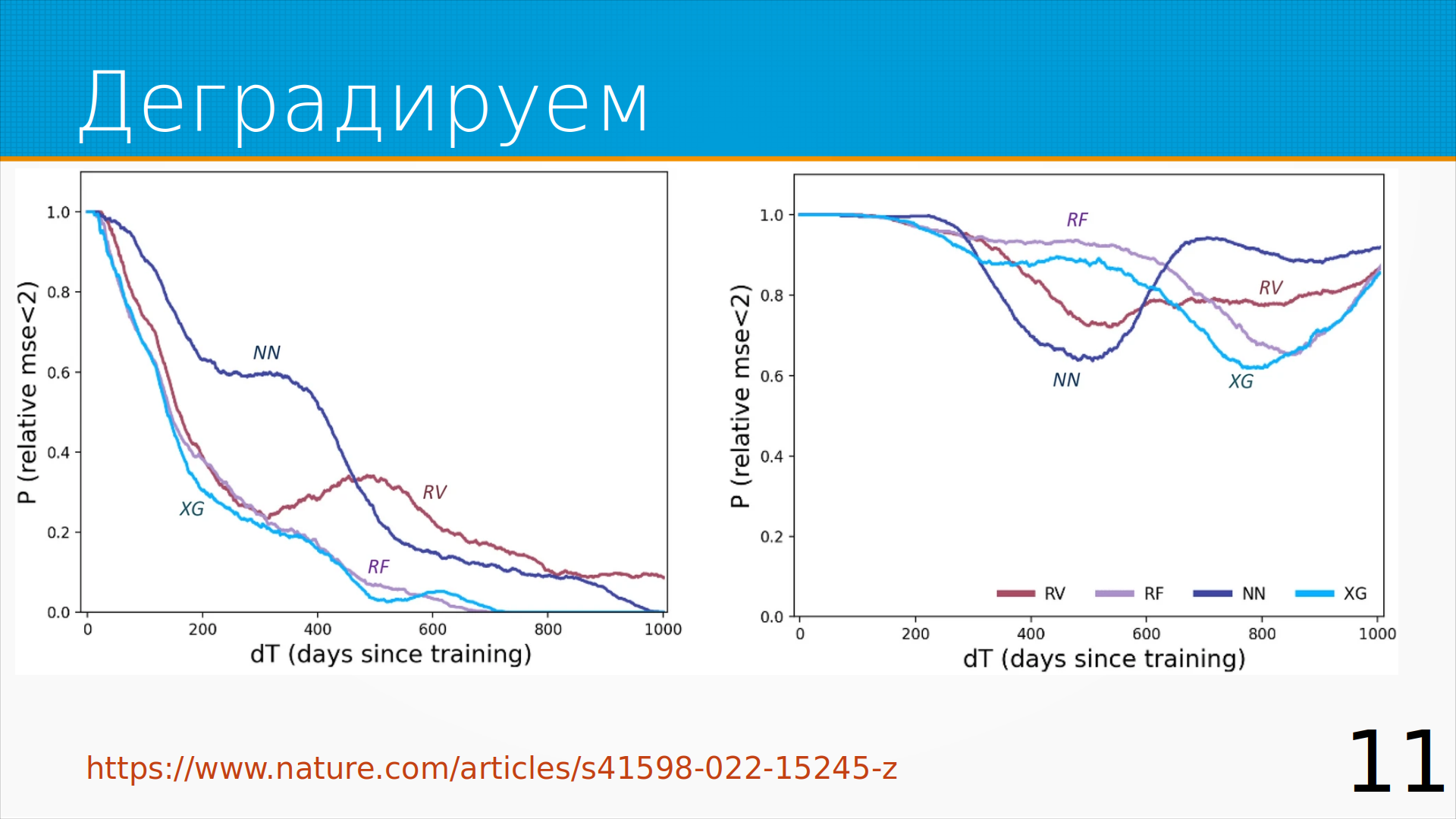 Про деградацию меток есть интересная статья в Nature. Авторы смоделировали устаревание нескольких типов моделей на разных наборах данных. На графике по оси X - возраст модели в днях, а по оси Y вероятность того, что качество модели осталось в определенных экспериментом рамках. Видим, что на одном из датасетов за первые 100 дней качество модели сильно упало. А на другом оно странно флуктуировало, но за три года не сильно ухудшилось. Устаревание модели - нелинейный процесс.
Про деградацию меток есть интересная статья в Nature. Авторы смоделировали устаревание нескольких типов моделей на разных наборах данных. На графике по оси X - возраст модели в днях, а по оси Y вероятность того, что качество модели осталось в определенных экспериментом рамках. Видим, что на одном из датасетов за первые 100 дней качество модели сильно упало. А на другом оно странно флуктуировало, но за три года не сильно ухудшилось. Устаревание модели - нелинейный процесс.
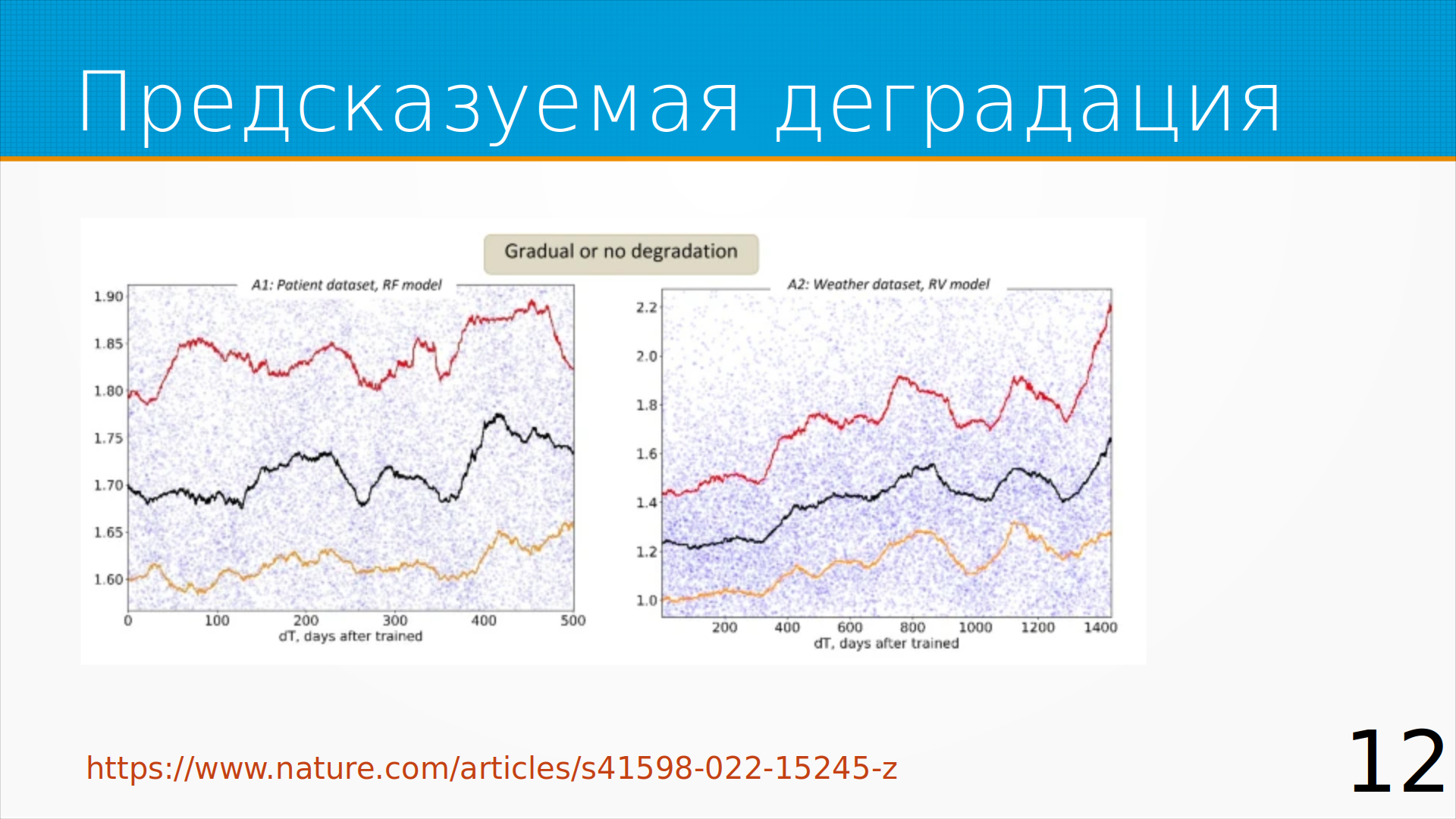 Иногда у нас есть предсказуемая деградация: мы видим, что качество модели падает постепенно и еще дней сто ее можно не переобучать.
Иногда у нас есть предсказуемая деградация: мы видим, что качество модели падает постепенно и еще дней сто ее можно не переобучать.
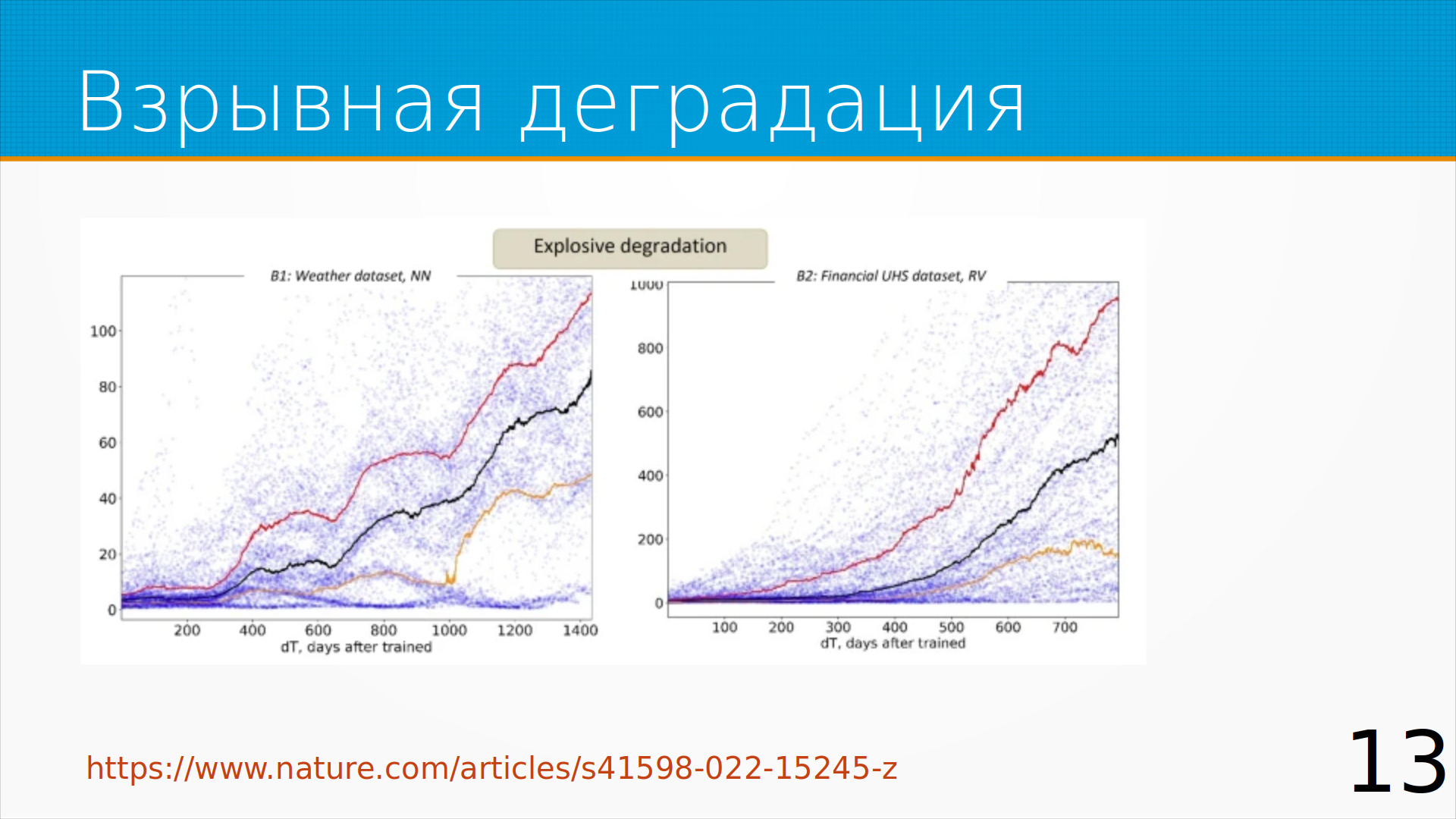 Иногда модели деградируют катастрофически. Например, до трехсотого дня все было более-менее хорошо, а потом
сразу все сломалось. Если метки вызревают быстро, можно отследить этот провал мониторингом.
Иногда модели деградируют катастрофически. Например, до трехсотого дня все было более-менее хорошо, а потом
сразу все сломалось. Если метки вызревают быстро, можно отследить этот провал мониторингом.
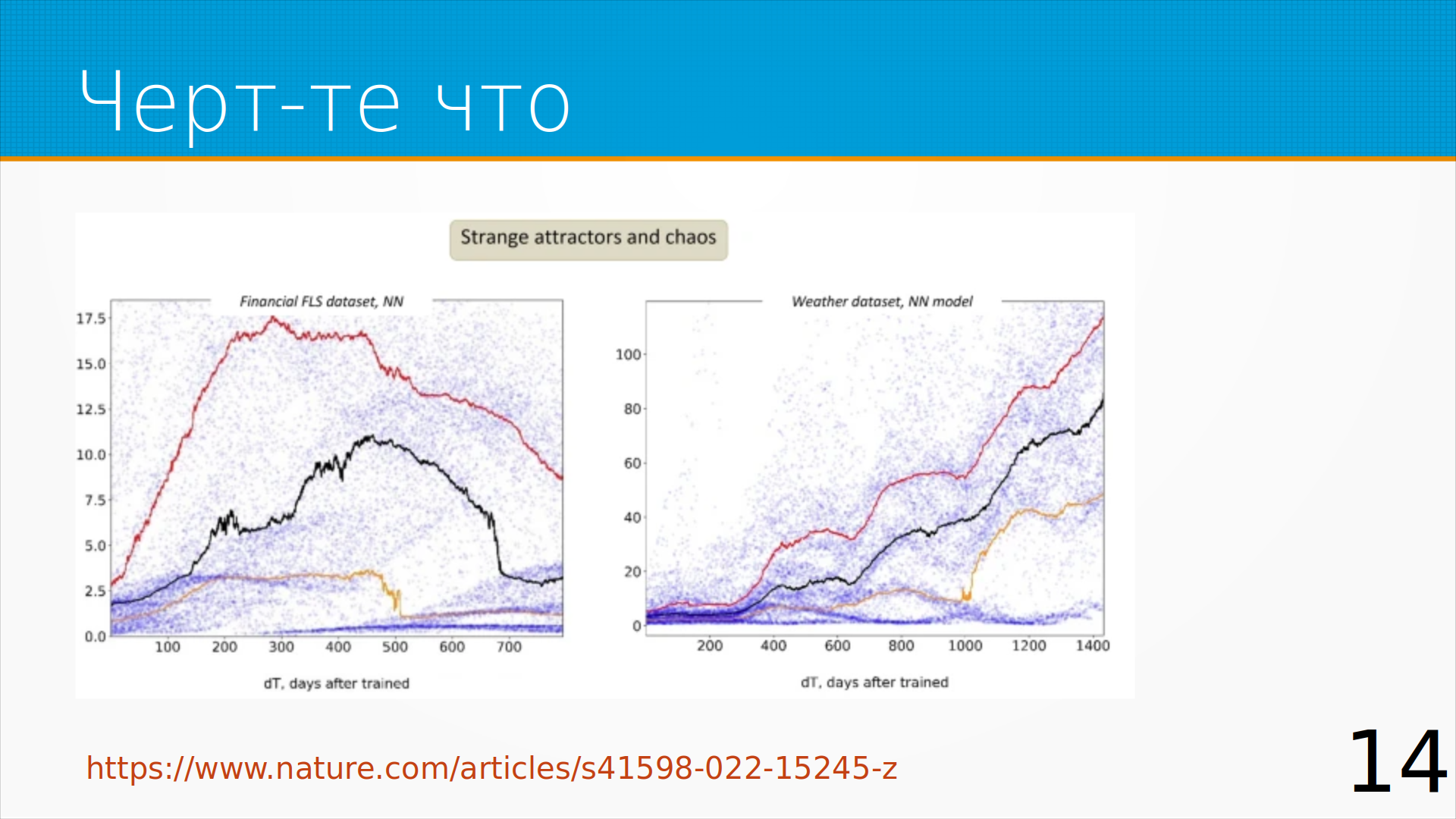 А иногда модели устаревают странным образом. На графике видим, что качество работы модели начало падать сразу, а спустя два года снова выросло. Это какие-то особенности предметной области.
А иногда модели устаревают странным образом. На графике видим, что качество работы модели начало падать сразу, а спустя два года снова выросло. Это какие-то особенности предметной области.

Если метрики вызревают медленно, можно попробовать найти прокси-метрики. Прокси-метрика - это косвенная мера целевой метрики, с которой она сильно коррелирует.
Если у нас нет хорошей прокси-метрики, можно мониторить распределение предсказаний. Делим наш предикт на диапазоны по квантилям. И следим за тем, чтобы в дальнейшем в каждый квантиль попадало одинаковое количество предсказаний. Простой метод, позволяет понять, что что-то пошло не так - но не позволяет понять, что именно.
Можно по-честному мониторить сдвиг данных - data drift, concept drift и т.д. Например, с помощью Evidently AI.
Валидация входных данных. Если вы не проверяете входные данные на аномалии, они у вас наверняка есть. Но кроме детектирования аномалий, хорошо проверять схему данных и вообще данными заниматься.
Можно оценивать уверенность модели, делать Conformal Prediction. И как только модель начала часто выдавать неуверенные предсказания, значит ее пора менять.
Моделирование невязки - мы строим вторую модель, которая предсказывает, насколько будет ошибаться основная модель. Мы учим ее на ошибках валидации. И мониторим предсказанную ошибку. Посмотрите NannyML, она такое умеет.
Универсальный рецепт — это слушать пользователей. Пользователи достаточно хорошо чувствуют, когда модель выдает что-то странное. Они, правда, обычно это сформулировать - что не так. Чтобы им в этом помочь, нужно повышать прозрачность решения (интерпретируемость, объяснимость).
Хорошо иметь запасную модели. Если мы смогли детектировать деградацию основной модели, можно переключиться на какую-то модель попроще, чтобы выдавать предикты ей, пока мы разбираемся с проблемой.
 Интерпретация модели машинного обучения нужна, в том числе, чтобы создать у экспертов ощущение, что все идет по плану.
Интерпретация модели машинного обучения нужна, в том числе, чтобы создать у экспертов ощущение, что все идет по плану.
Отчеты интерпретации сами по себе не очень информативны, но они не должны противоречить нашим знаниям о предметной области. Образно говоря, мы спрашиваем модель - почему не дала Петрову кредит? Хороший ответ - у него доход маленький, это ожидаемый ответ. Плохой ответ - у него глаза голубые, и с такой моделью надо разбираться. Результаты интерпретации модели не должны удивлять экспертов.
Интерпретируемость — необходимое, но недостаточное условие, потому что метрики интерпретируемости можно накрутить, пример в статье. Положим, вы сделали модель кадрового скоринга, которая угнетает чернокожих женщин, но не хотите, чтобы вас регулятор за этим поймал. Чуть-чуть модифицируете модель и результаты интерпретации показывают, что чернокожих женщин модель не угнетает, но и на работу она их все равно не берет.
Парадокс прозрачности - прозрачные модели надежнее, но обмануть их проще. Я консультировал один финтех, предложил показывать отчеты об интерпретируемости скоринговой модели сотрудникам при работе с клиентом. С точки зрения заказчика тут возникали риски безопасности - сотрудник после ухода из компании мог использовать эти данные для обмана компании. На самом-то деле это беспочвенное опасение, потому что SHAP и LIME, часто применяющиеся для интерпретации моделей не моделируют причинность. Даже если у какого-то признака большое Shapley Value, не факт, что изменив этот признак, вы измените решение модели. Примерно как в анекдоте - почему пушка не стреляла? Не было пороха, мы не видели куда стрелять. Туда стреляйте! - а пороха-то все равно нет.
Если вам нужна именно информативная интерпретируемость, подсказывающая действия по изменению предсказания, ищите контрафактические примеры. Примеры, очень близкие к выбранному, но с другим предсказанием. Они для практических целей более информативны.
 Если смотреть на интерпретируемость шире, когда мы строим модель, мы хотим, чтобы модель выучила шаблоны в данных. А потом пытаемся понять, какие именно шаблоны она выучила. Идеальная сферическая модель в вакууме выучит те шаблоны, какие есть в данных, и только их.
Если смотреть на интерпретируемость шире, когда мы строим модель, мы хотим, чтобы модель выучила шаблоны в данных. А потом пытаемся понять, какие именно шаблоны она выучила. Идеальная сферическая модель в вакууме выучит те шаблоны, какие есть в данных, и только их.
Шаблоны в данных можно посмотреть и без модели, например с помощью графика среднего отклика на признак. Mean Target Plot, или, строже говоря, маржинальная эмпирическая плотность распределения. Есть библиотека binsreq, которая делает почти то же самое, только еще учитывает распределение признака по квантилям. Вот статья с описанием того, как это работает.

Что можно сделать на этапе разработки / развертывания модели:
Провести аудит процесса подготовки данных. Например, если аналитик выполнял заполнение пропущенных значений или удаление строк с пропущенными значениями при подготовке данных, нужно решить, что будете делать с такими данными на проде.
Детектировать аномалии. Решить, что будем делать с аномалиями, когда выявим. В идеальном мире мы бы сказали - данные неправильные, дайте правильные данные. Иногда мы можем так сделать.
Чаще приходится клиппировать данные, то есть приводить данные к какому-то "разрешенному" диапазону. Можно еще выставлять бинарный флаг "признак был клиппирован". Но чтобы модель понимала, как вести себя в этом случае, у нее должны быть строки с флагом клиппирования в обучающей выборке. Если у нас есть разумные предположения о будущих аномалиях, мы можем смоделировать аномалии и добавить их в обучающую выборку.
То же самое с заполнением пропущенных значений. Их можно заполнять каким-нибудь разумным способом. Это называется импутация. Например, самым частым категориальным значением или медианой среди вещественных значений. И тоже можно добавлять флаг, что это значение было импутировано. Чтобы обучить модель работать с этим флагом, мы можем специально выбросить какие-то признаки в обучающей выборке, импутировать и добавить их в датасет, может быть, с меньшим весом.
И как план Б - контролируемая деградация. Более простая модель, использующая меньше признаков, более устойчивая.
Многие из вышеописанных проблем можно смягчить, если хорошо проработать ML Design Document, и у нас с Ириной есть про это видео.

Расходы, которые мы несем на предотвращение какой-то проблемы должны быть соизмеримы с матожиданием ущерба от этой проблемы. Чтобы посчитать, во сколько нам обходится недоученная модель, нужно знать - сколько стоит некачественный предикт. Бизнес не всегда это знает, но почти всегда может это посчитать, если хорошо поработать над деревом метрик модели.
Обычно более-менее понятно, сколько стоит доучить модель. Непонятно, насколько вырастет качество модели после дообучения на свежих данных. В качестве грубой оценки можно использовать предположение о равномерном устаревании модели, и что после дообучения будет достигнуто то же качество модели, что и в прошлый раз.
 Что мешает часто переобучать модели?
Что мешает часто переобучать модели?
- Малый поток данных. Если мы не Яндекс, данных для модели мало. Может помочь аугментация и генерация синтетических данных.
- Медленное вызревание меток (длинная петля обратной связи). Иногда можно сконструировать обратную связь вручную. Например, попросить пользователя ставить плюсик, если ему понравилась рекомендация. Использовать эти метки при обучении, с меньшим весом чем реальные метки.
- Громоздкая подготовка данных. Например, подготовка датасета для обучения занимает день - чаще чем раз в день обучать модель не получится. Можно сохранять насчитанные предикты и признаки, и тогда, когда к нам приходят метки, признаки пересчитывать уже не надо, мы сразу можем добавлять их в обучающую выборку.
- Трудно сравнивать модели. Трудно понять, стала ли переобученная модель лучше или хуже. Если есть возможность, вместо AB-тестов используйте интерливинг. АБ-тесты это долго, может не хватить трафика/мощности теста. Или, если метки вызревают очень быстро и вы предсказываете что-то не очень критичное, можно выкатывать новую модель и мониторить - с возможностью быстро откатиться на предыдущую версию модели, если метрика ухудшится
 Обещанный анонс:
Обещанный анонс:
Курс по ML System Design будет повторен осенью. Переработанный материал, лабораторные работы, промежуточные тесты, раздел про устойчивость моделей
Курс будет только онлайн, оффлайн потока не будет.
 Что почитать:
Что почитать:
- Письмо ФРС SR Letter 11-7 про управление модельным риском. От 2011 года и не устарело ни капельки.
- Книга Machine Learning for High-Risk Applications
- Статья Graceful Degradation. Не про Graceful Degradation, как ее обычно понимают в дизайне систем, а про то, как бороться с устареванием модели при сдвиге.
- DataFest 2023, много докладов, в которых разбирается устойчивость моделей.
- NannyML - система мониторинга моделей. Мониторит сдвиг и моделирует невязку. И у них отличный блог.
- Блог Evidently AI тоже хорош.
- Мой доклад в Екатеринбурге
- Курс ML System Design
