
- 29.04.2023
- 20.10.2024
- выступления
29 апреля в Екатеринбурге при поддержке Уральского центра систем безопасности прошел Датазавтрак, на котором я рассказал про устойчивость моделей - почему они ломаются и что с этим делать.
Слайды: 2023_ekaterinburg.pdf
Кроме моего выступления, на мероприятии были и другие доклады - и они были гораздо интереснее моего. Полная видеозапись мероприятия тут https://www.youtube.com/watch?v=eKEUE4z1lXA
Телеграмм-канал организаторов #ML_EKB.
Текстовая расшифровка, сделана нейронкой, пока не вычитана:

Меня зовут Дмитрий Колодезев, и я хочу рассказать про общую проблематику устойчивости ML-моделей, как часто дообучать модели и как делать это правильно.
Это первая (обзорная) часть рассказа про устойчивость ML-моделей. Вторая (более хардкорная) часть будет на DataFest 2023.

Про меня:
- Вместе с Ириной Голощаповой веду канал ReliableML,
- директор Промсофта
- автор курса ML System Design
- активно поддерживаю сообщество Open Data Science, чем могу.
Кстати, собираем спикеров на секцию ReliableML на DataFest.

О чем мы тут?
А много ли людей учили модели и выкатывали их на прод,
чтобы ими люди пользовались?
Ну, так-то даже есть.
Но остальные, наверное, их только в учебнике видели.
В учебнике нам рисуют такую картину, например,
что мы такие вжух, мы обучили ML-модель,
потом отдали ее, например, бизнесу,
бизнес сделал на ней предикт, получил прибыль.
Оно, на самом деле, даже так бывает иногда.
Очень часто бывает так, что мы сделали модель, отдали ее бизнесу,
бизнес поставил ее, а модель работает плохо.
Непонятно почему. На этих же данных учили, у нас работало хорошо,
у вас плохо, у меня такая же нога и не болит.
А еще бывает хуже.
То есть мы отдаем модель, она работает хорошо,
а потом, когда мы не знаем когда, она начинает работать плохо.
И вот тут у нас же сейчас ML-модели в каждом утюге,
бывает, что буквально мы делаем ML-модели
и вшиваем их в оборудование, например.
И они стоят в камерах, они стоят в железе в каком-то,
и потом, сначала они работали хорошо,
потом они начинают почему-то работать плохо,
а мы об этом не знаем, никто не спрашивает камеру,
как она работает.
А еще бывают анекдотические истории, что ML-модели вообще не работают,
а люди думают, что они работают, и все идет нормально.
Я знаю о многих случаях, когда в очень больших,
серьезных и тяжелых организациях важные модели
просто забывали запустить или подключить на прод,
и это день или неделю, или две недели шло,
и все думали, что все хорошо.
То есть, ну, в общем, на самом-то деле от Fit-Predict-Profit
здорово жизнь отличается.
А картинки нарисованы кадинским (нейронками).

Ну, собственно, об этом мы поговорим, кто виноват, что так получается, и что с этим можно сделать.
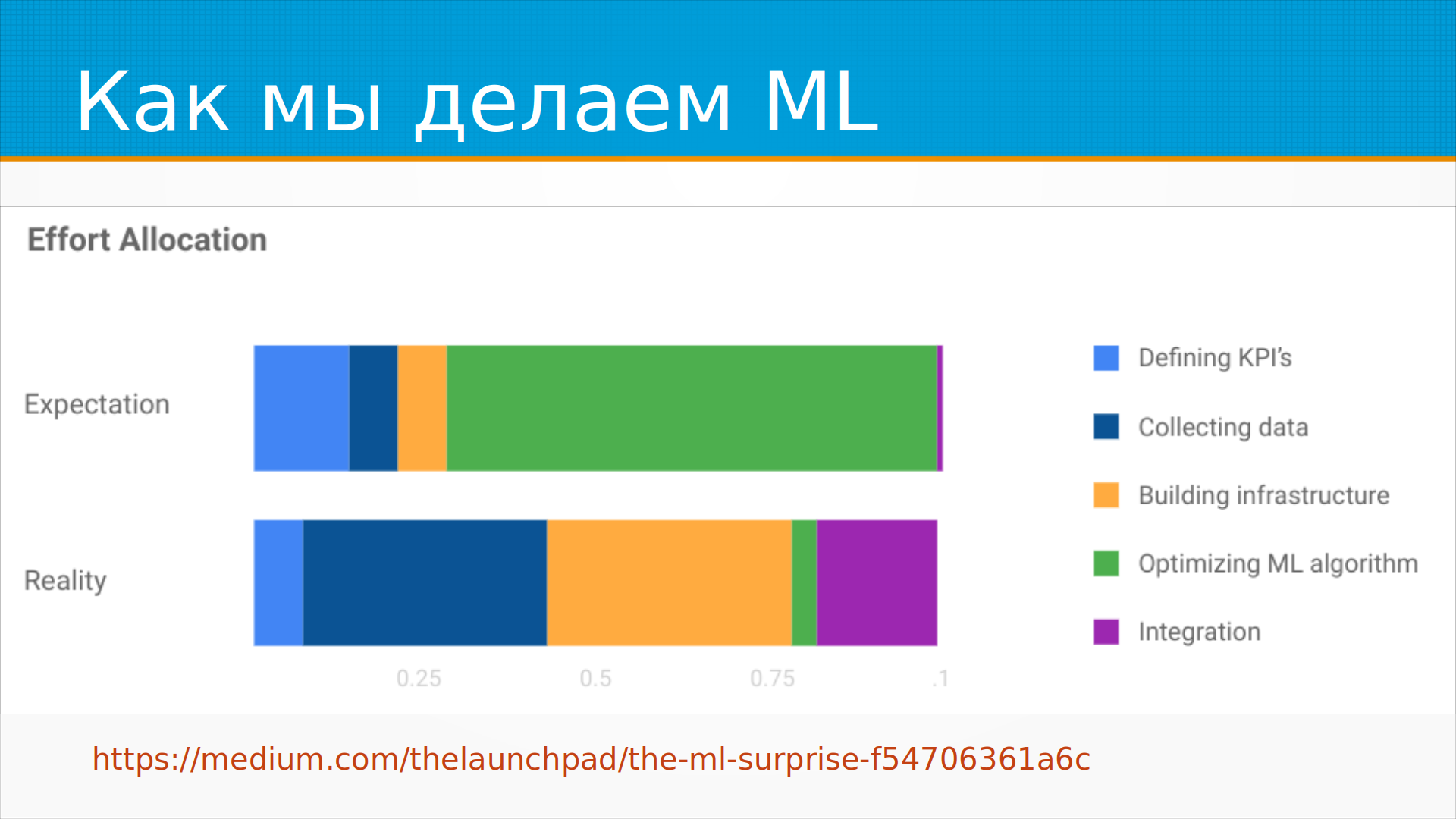
Есть интересная статья.
Там товарищ из Google Cloud провел опрос людей,
занимающихся построением и внедрением модели,
и мы как бы… как вы представляете себе,
на что уйдет время, на что оно реально уходит.
Ну, и кажется, что при построении ML-системы мы такие думаем,
ну, вот сейчас мы определим, что же она будет делать,
потом соберем данные, подготовим инфраструктуру,
потом будем долго, красиво, интересно обучать модель и внедрим ее.
А на практике получается почему-то совершенно не так.
То есть мы так по-быстрому о чем-то договорились,
потом долго-долго-долго собираем данные,
потом внезапно выясняется, что нам нужно долго возводить инфраструктуру,
потом раз, обучили модель, и долго, мучительно пытаемся ее запихать на прот.
Вот. То есть мир устроен не так, как FitPredict,
но все еще на самом деле хуже.
И если мы выкатили модель на прот, нам ее придется поддерживать.
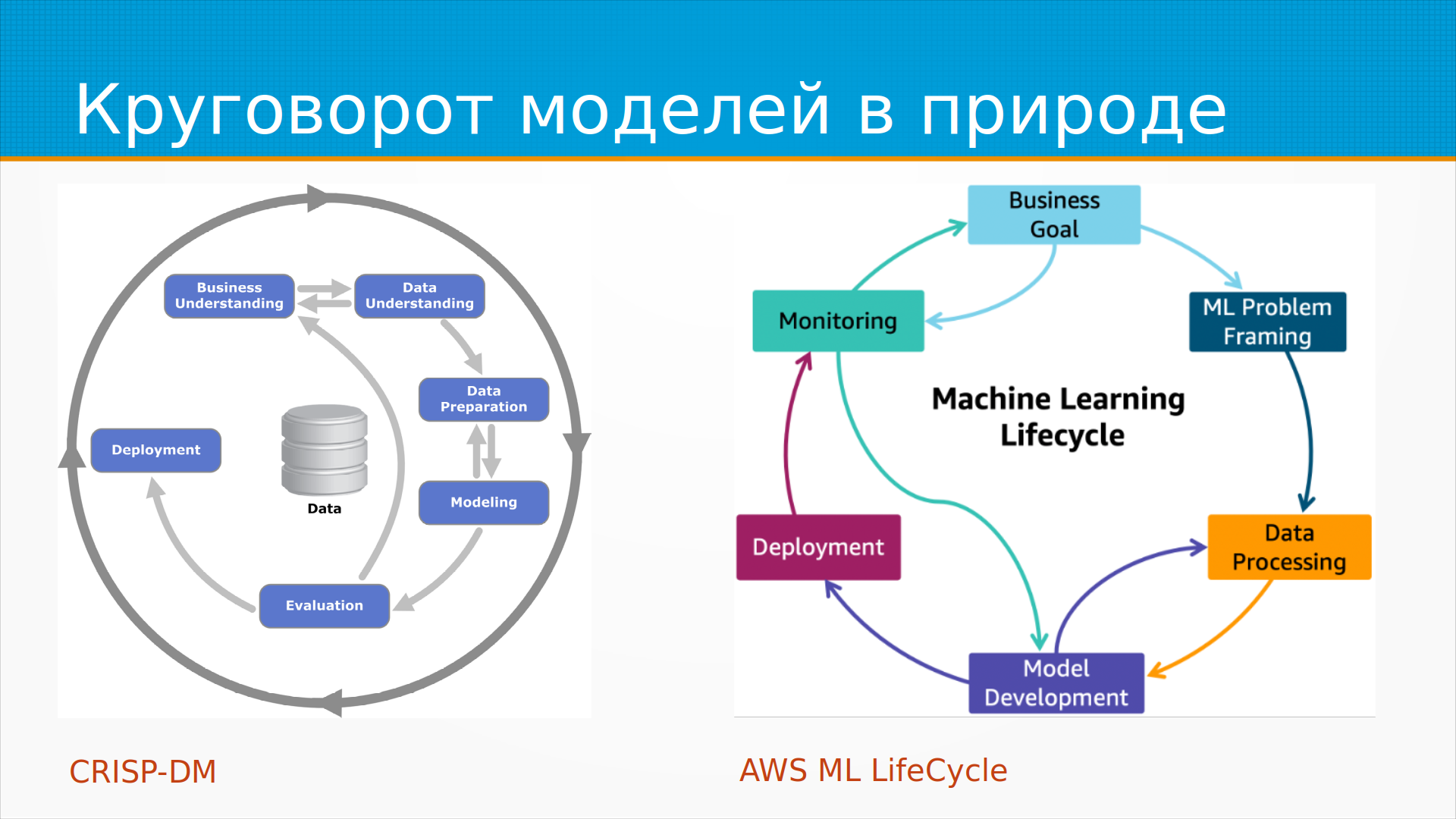
Вот тут два красивых кружочка.
Слева это еще из девяностых годов прошлого века модель CrispDM,
если не раньше.
Она считается устаревшей, безнадежно,
и ее даже в учебники перестали включать.
То есть процесс там такой.
Мы сначала смотрим, что же нужно бизнесу, собираем, изучаем,
учим модель, выкатываем, анализируем, как она получилась,
собираем обратную связь, снова учим и так далее.
Справа стильная, модная, молодежная схема от AWS,
то есть от Амазона, жизненный цикл ML-модели.
Что интересно, эти картинки, которые разделяют между собой 30 лет,
они, в общем-то, примерно одинаковые.
Только левая устарелая, а правая модная.
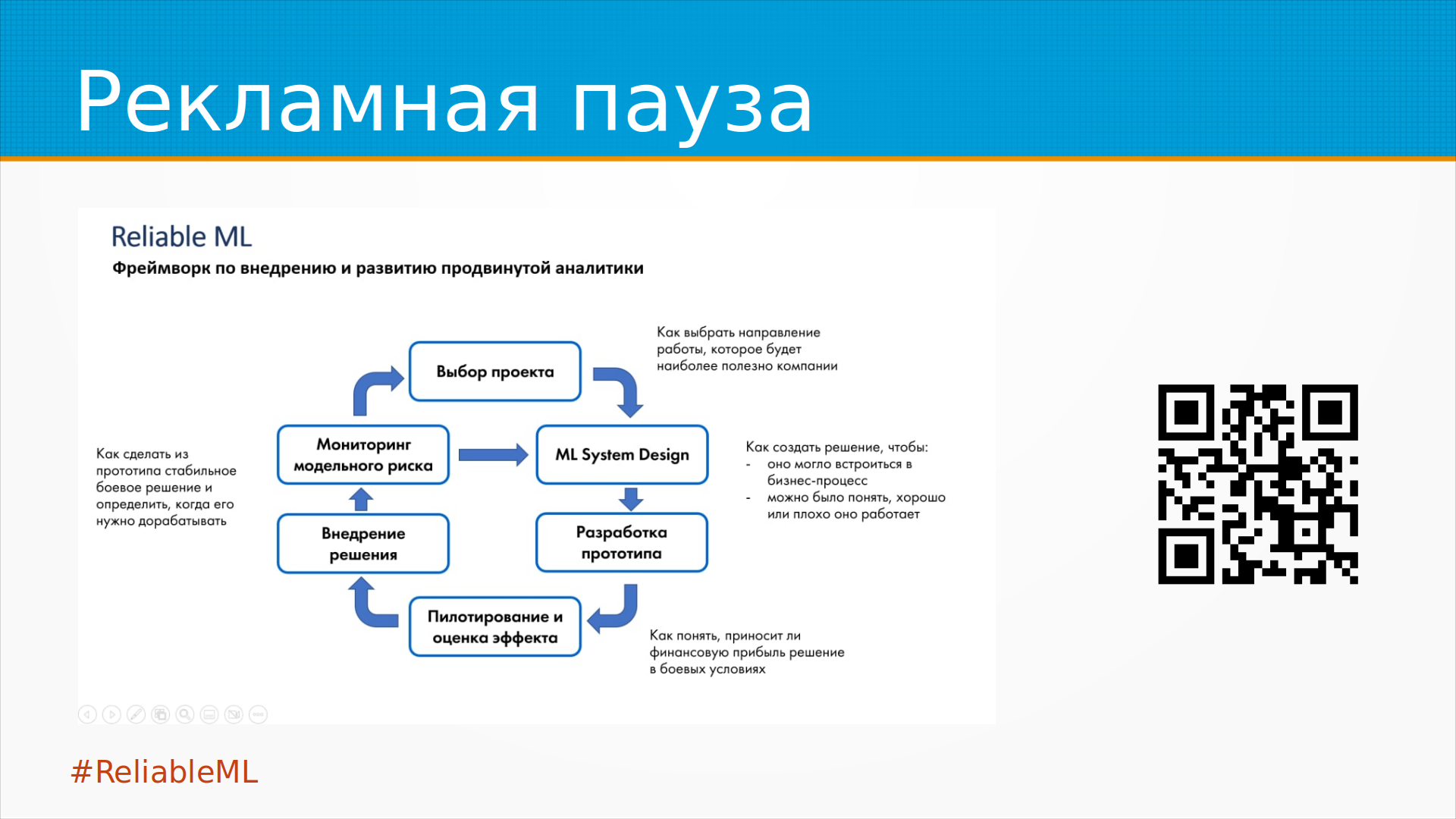
Ну и рекламная пауза.
Мы с Ирой Голощаповой в канале ReliableML собираем практики,
как делать машинное обучение надежным,
как делать так, чтобы оно приносило бизнесу пользу,
а не только расходы.
И в модели ReliableML у нас тоже есть колечко.
То есть мы собираем требования, мы учим модель,
мы ее валидируем, мы смотрим, как она работает на проде
и снова-снова-снова ходим по кругу.

То есть получается, что обучить модель — это неразовое действие. Так же, как, например, безопасность — это неразовое действие. Оказывается, его надо кормить. Причем стоимость владения модели достаточно большая. То есть мы ее мониторим. Там раньше сидел человек, принимал решение, мы его не мониторили. То есть если он плохо работал, мы его увольняли и нанимали следующего. Иногда он уходил в декрет или на пенсию. Ну вот и весь его мониторинг. А тут ML-модель за нее смотреть, не перестала ли она нормально работать, по-прежнему ли она вообще работает в принципе как-то. И получается, что мы представляли себе и мы обещали бизнесу, что мы сделаем модель, которая улучшит ему работу процесса, он вложится в разработку этой модели, в внедрение системы и после этого ему наступит счастье. То есть он понесет капитальные затраты и получит пользу. На самом-то деле он понесет капитальные затраты, получит, конечно, пользу и еще увеличит свои операционные затраты. То есть ему надо будет платить за эту модель сегодня, завтра, послезавтра и так далее. Это прям неожиданно.

Что еще важно понимать? ML-системы в том виде, как их обычно делают, они очень хрупкие. Про хрупкость это в том смысле, в каком Насим Талеб в книге «Антихрупкость» писал, что хорошо бы, если бы системы не ломались от каждого чиха, а наоборот все, что нас не убивает, делает нас сильнее. Есть у Александра Бандю хорошая книга на эту же тему «Антихрупкость в IT», но вот с ML-моделями почему-то так не получается. То есть мы заменяем гибких людей, которые подстраиваются под обстоятельства, на жесткие системы, которые под обстоятельства не подстраиваются, они принимают решения на основе данных, на основе шаблонов, которые они нашли в прошлом, и на самом деле не говорят нам, когда начинает твориться что-то странное. То есть мы берем у любого бизнеса, у него не только производительность ключевая характеристика, но и гибкость, насколько он хорошо подстраивается под изменение внешней среды, и мы, добавляя ему что уж там производительности, мы на самом деле отнимаем у него чуть-чуть гибкости и не предупреждаем его об этом. И получается, когда окружение меняется, оно меняется всегда, а системы наши ломаются.
 Ну, хотелось бы, чтобы было не так плохо, хотелось бы, чтобы было хорошо.
Давайте делать хорошо, плохо делать не делаем.
Устойчивость ML-моделей в каком тут смысле?
Что устойчивость, как по ГОСТу, это способность сохранять функционирование при изменении внешней среды.
А что тут во внешней среде может меняться?
Данное, в котором мы запускаем нашу ML-модель, оно то же самое, что и вчера.
Ну, во-первых, у нас меняются данные, которые к нам приходят в систему.
Сегодня приходили одни данные, приходят завтра почему-то другие.
Ну, процесс сбора данных изменился или что-нибудь еще.
Затем данные, это же просто отражение, отпечаток, слепок мира, который стоит за ними.
И может измениться мир, в результате изменятся данные.
Нам нужно что-то делать с ML-моделями.
Бывают проблемы безопасности, то есть нас атакуют.
И на самом-то деле атаки на ML-модели – это дело совершенно житейское и постоянное.
Ну, хотелось бы, чтобы было не так плохо, хотелось бы, чтобы было хорошо.
Давайте делать хорошо, плохо делать не делаем.
Устойчивость ML-моделей в каком тут смысле?
Что устойчивость, как по ГОСТу, это способность сохранять функционирование при изменении внешней среды.
А что тут во внешней среде может меняться?
Данное, в котором мы запускаем нашу ML-модель, оно то же самое, что и вчера.
Ну, во-первых, у нас меняются данные, которые к нам приходят в систему.
Сегодня приходили одни данные, приходят завтра почему-то другие.
Ну, процесс сбора данных изменился или что-нибудь еще.
Затем данные, это же просто отражение, отпечаток, слепок мира, который стоит за ними.
И может измениться мир, в результате изменятся данные.
Нам нужно что-то делать с ML-моделями.
Бывают проблемы безопасности, то есть нас атакуют.
И на самом-то деле атаки на ML-модели – это дело совершенно житейское и постоянное.
 Какие проблемы бывают с данными?
Самые простые проблемы – это выбросы или аномалии.
То есть аномалия, выброс – это какое-то необычное значение в данных.
И вот тут при обучении модели мы можем себе позволить взять и выбросить выбросы.
И мы можем сказать, давайте мы учим модель на чистых данных.
А что мы будем делать, когда эта же аномалия придет к нам на проде?
То есть от живого человека.
Мы скажем, нет, мы такого не обслуживаем.
Следующий.
Нет, ну это обычно не вариант.
Вариантов у нас не так много.
Если у нас есть возможность, мы можем как раз генеративные модели,
вот как Михаил рассказывал, мы можем восстанавливать то значение,
какое там было пропущено или это аномалия.
Аномалия, скорее всего, это скачок какого-нибудь датчика.
Но на практике дешевле обрезать аномалию по какому-то значению
и отдельно выставлять флаг, что значение было обрезано.
Например, у нас есть фитнес-датчик, который мониторит пульс.
И в принципе у живого человека пульс где-то от 40 до 220 в этом диапазоне колеблется.
В этот раз датчик у нас говорит, что пульс 800.
Что мы должны сделать?
Навряд ли у человека пульс 800, это, по-моему, физически невозможно.
Больше 300 сердца биться.
И мы обрезаем его до 220 и выставляем флаг, что мы его обрезали.
Другой вариант.
Наш датчик внезапно выдает нулевой пульс.
Есть, конечно, вероятность, что человек переусердствовал с упражнениями и умер,
но вообще-то в этом случае ему все равно, что мы ему предскажем.
Поэтому логичнее предположить, что у нас отвалился этот самый датчик,
либо пояс нагрудный, когда вы бежите кросс, либо здесь что-нибудь с светодиодом.
И его показания потом восстановятся.
То есть у нас есть такой просто провал, и мы его можем заполнить.
В датчиках таких в фитнес, по-моему, обычно скользящим среднему заполняют.
И опять же можно выставить признак.
То есть у нас, конечно, я сказал, что пульс 65, но на самом деле я точно не знаю.
С пропущенными значениями.
Это похожая история на выброс.
Зачастую мы учимся на данных, и нам обещают заказчики, что вот здесь данные у нас будут.
Что всегда человек заполнит поле возраст.
Всегда организация напишет, заполнит свои сферы деятельности и так далее.
На практике выясняется, что даже если в тех формах, в которых наши пользователи системы вводят эти данные,
жестко прописать в валидацию, что эти данные обязательно будут заполнены,
все равно они будут приходить не заполненные.
Это просто по разным причинам.
Где-то JavaScript валидирующий не отработал, где-нибудь еще.
Где-нибудь пришли данные, собранные из другой формы.
И получается, что к нам приходит пропуск, а ML-модели надо эти значения все равно обрабатывать.
Тут можно, конечно, добавить в данное специальное значение для пропусков,
но тут у нас возникает некоторый байз у модели, что есть люди, которые хорошо заполнили анкету, допустим,
и они, допустим, хорошие заемщики.
Есть люди, которые плохо заполнили анкету, они, допустим, плохие заемщики.
Вы пришли, поленились, и вы попали в плохие заемщики.
То есть, чтобы модель могла нормально работать на данных, на которых непредсказуемые вылетают пропуски,
можно имитировать пропуски прямо на этапе обучения.
То есть случайным образом из вполне заполненных данных выкидывать некоторые столбцы и учить ее.
Таким образом мы можем обучить модель, которая более устойчива к пропускам, если это нам важно.
Ну, редкие значения.
Редкие значения — это, например, есть у нас тот же самый фитнес-трекер.
Есть некоторые люди с патологически низким пульсом.
У них все хорошо, при этом они живут со своим пульсом 40, но просто вот так вот редко у них.
Повезло им или не повезло.
Но в датасете у нас их мало.
Или вообще, может быть, нет.
Мы точно знаем, что они есть, но их нет в датасете.
Как быть?
Мы можем добавить простые правила эвристики.
То есть, если у нас мы знаем, что есть редкий случай, для которого мы не смогли собрать достаточно примеров,
мы можем обмотать это место изолентой, то есть обставить ифами,
и пусть модель пытается простыми эвристиками найти, не редкий ли это случай.
Это гораздо лучше, чем эти случаи игнорировать.
Ну и самый интересный случай — это когда точка, которую нам нужно анализировать,
пришла не из того распределения, на котором мы учились.
Например, у нас есть какой-нибудь стартап, который отделяет кошечек от собачек.
Перспективный молодой стартап с большим будущим.
И вот тут пользователи кидают нам фотографию собачки.
Мы говорим собачка, кошки, кошка.
Они кидают нам фотографию верблюда.
Что наше приложение ответит? Ну, скорее всего, собака.
Что пользователь ожидает? Что пользователю нужно?
Ну, наверное, не знаю я. Я такого животного не видел.
Эту проблему решают по-разному.
Один из подходов — это мы добавляем какие попало мусорные значения и выучиваем третий класс.
Да, нет, не знаю.
Второй хороший подход — мы мониторим уверенность модели в своем ответе.
Самый простой вариант — это если у нас модель выдает вероятность от нуля до единицы,
то когда она выдает их в районе 50%, значит, она на самом деле не поняла, что это.
И мы в таких случаях можем говорить, ну вот это вот да, это нет,
а вот в этом диапазоне, как у полупроводников запретный коридор, если кто-то помнит,
вот это вот мы не знаем, что это такое.
Есть лучшие способы, но так часто делают.
Какие проблемы бывают с данными?
Самые простые проблемы – это выбросы или аномалии.
То есть аномалия, выброс – это какое-то необычное значение в данных.
И вот тут при обучении модели мы можем себе позволить взять и выбросить выбросы.
И мы можем сказать, давайте мы учим модель на чистых данных.
А что мы будем делать, когда эта же аномалия придет к нам на проде?
То есть от живого человека.
Мы скажем, нет, мы такого не обслуживаем.
Следующий.
Нет, ну это обычно не вариант.
Вариантов у нас не так много.
Если у нас есть возможность, мы можем как раз генеративные модели,
вот как Михаил рассказывал, мы можем восстанавливать то значение,
какое там было пропущено или это аномалия.
Аномалия, скорее всего, это скачок какого-нибудь датчика.
Но на практике дешевле обрезать аномалию по какому-то значению
и отдельно выставлять флаг, что значение было обрезано.
Например, у нас есть фитнес-датчик, который мониторит пульс.
И в принципе у живого человека пульс где-то от 40 до 220 в этом диапазоне колеблется.
В этот раз датчик у нас говорит, что пульс 800.
Что мы должны сделать?
Навряд ли у человека пульс 800, это, по-моему, физически невозможно.
Больше 300 сердца биться.
И мы обрезаем его до 220 и выставляем флаг, что мы его обрезали.
Другой вариант.
Наш датчик внезапно выдает нулевой пульс.
Есть, конечно, вероятность, что человек переусердствовал с упражнениями и умер,
но вообще-то в этом случае ему все равно, что мы ему предскажем.
Поэтому логичнее предположить, что у нас отвалился этот самый датчик,
либо пояс нагрудный, когда вы бежите кросс, либо здесь что-нибудь с светодиодом.
И его показания потом восстановятся.
То есть у нас есть такой просто провал, и мы его можем заполнить.
В датчиках таких в фитнес, по-моему, обычно скользящим среднему заполняют.
И опять же можно выставить признак.
То есть у нас, конечно, я сказал, что пульс 65, но на самом деле я точно не знаю.
С пропущенными значениями.
Это похожая история на выброс.
Зачастую мы учимся на данных, и нам обещают заказчики, что вот здесь данные у нас будут.
Что всегда человек заполнит поле возраст.
Всегда организация напишет, заполнит свои сферы деятельности и так далее.
На практике выясняется, что даже если в тех формах, в которых наши пользователи системы вводят эти данные,
жестко прописать в валидацию, что эти данные обязательно будут заполнены,
все равно они будут приходить не заполненные.
Это просто по разным причинам.
Где-то JavaScript валидирующий не отработал, где-нибудь еще.
Где-нибудь пришли данные, собранные из другой формы.
И получается, что к нам приходит пропуск, а ML-модели надо эти значения все равно обрабатывать.
Тут можно, конечно, добавить в данное специальное значение для пропусков,
но тут у нас возникает некоторый байз у модели, что есть люди, которые хорошо заполнили анкету, допустим,
и они, допустим, хорошие заемщики.
Есть люди, которые плохо заполнили анкету, они, допустим, плохие заемщики.
Вы пришли, поленились, и вы попали в плохие заемщики.
То есть, чтобы модель могла нормально работать на данных, на которых непредсказуемые вылетают пропуски,
можно имитировать пропуски прямо на этапе обучения.
То есть случайным образом из вполне заполненных данных выкидывать некоторые столбцы и учить ее.
Таким образом мы можем обучить модель, которая более устойчива к пропускам, если это нам важно.
Ну, редкие значения.
Редкие значения — это, например, есть у нас тот же самый фитнес-трекер.
Есть некоторые люди с патологически низким пульсом.
У них все хорошо, при этом они живут со своим пульсом 40, но просто вот так вот редко у них.
Повезло им или не повезло.
Но в датасете у нас их мало.
Или вообще, может быть, нет.
Мы точно знаем, что они есть, но их нет в датасете.
Как быть?
Мы можем добавить простые правила эвристики.
То есть, если у нас мы знаем, что есть редкий случай, для которого мы не смогли собрать достаточно примеров,
мы можем обмотать это место изолентой, то есть обставить ифами,
и пусть модель пытается простыми эвристиками найти, не редкий ли это случай.
Это гораздо лучше, чем эти случаи игнорировать.
Ну и самый интересный случай — это когда точка, которую нам нужно анализировать,
пришла не из того распределения, на котором мы учились.
Например, у нас есть какой-нибудь стартап, который отделяет кошечек от собачек.
Перспективный молодой стартап с большим будущим.
И вот тут пользователи кидают нам фотографию собачки.
Мы говорим собачка, кошки, кошка.
Они кидают нам фотографию верблюда.
Что наше приложение ответит? Ну, скорее всего, собака.
Что пользователь ожидает? Что пользователю нужно?
Ну, наверное, не знаю я. Я такого животного не видел.
Эту проблему решают по-разному.
Один из подходов — это мы добавляем какие попало мусорные значения и выучиваем третий класс.
Да, нет, не знаю.
Второй хороший подход — мы мониторим уверенность модели в своем ответе.
Самый простой вариант — это если у нас модель выдает вероятность от нуля до единицы,
то когда она выдает их в районе 50%, значит, она на самом деле не поняла, что это.
И мы в таких случаях можем говорить, ну вот это вот да, это нет,
а вот в этом диапазоне, как у полупроводников запретный коридор, если кто-то помнит,
вот это вот мы не знаем, что это такое.
Есть лучшие способы, но так часто делают.

Кроме данных может измениться сам мир, то есть мир может быть устроен по-разному. Чаще всего вспоминают в этом случае так называемый дрейф данных, когда изменились распределения или изменились законы, которые в этих распределениях действовали. Тут хороший пример — это, например, iPhone 4. В 2010 году у вас есть iPhone 4 и перспективное приложение, которое определяет, насколько вы стильный, модный, молодежный. Оно выдает вам 10 из 10. В 2016 году она вам выдает такую пятерочку, четверочку. На новый iPhone у мужика денег нет, но пусть живет. В 2023 году оно поднимает алерт. Слушайте, ребята, у него App Store не работает на 4 iPhone. Почему он с ним еще ходит? Что-то странное. Либо ли коллекционер, либо как-то, я не знаю, он украл его, не понял, что сделал. iPhone тот же самый, но смысл его для нашей модели получается совершенно разным. Часть признаков может просто банально пропасть. Например, одна известная, очень хорошая, добрая интернет-компания сливала данные пользователей микрокредитным организациям долгое время. А потом она что-то так задумалась. Мы же такие добрые, хорошие, ведущие российские. И перестала продавать. А организации, которые делали на них скоринг, так хоп, им сказали, ну, ребята, все, вот в марте 2020 года мы перестаем вам передавать скоринговый балл. Они такие, ну, как бы модели есть, истории есть, а данных больше нет. Интересно, что делать. А тут на самом-то деле мы можем восстановить это значение по оставшимся у нас признакам. То есть если у нас нет возможности мгновенно заменить модель, мы можем построить модель, которая будет предсказывать отсутствующий нам признак по всем остальным и подавать его на фронт просто для того, чтобы нам модель прямо сейчас не умерла, пока мы там собираем данные, переобучаем, делаем ретро-тесты и так далее. Могут появиться новые признаки. Как бы новые признаки — это не проблема. Ну, новые-новые, мы их просто игнорируем и работаем. Но хочется же, чтобы они сразу нам пользу приносили, раз они у нас все равно есть. Я заплатил за весь спидометр, я буду использовать весь спидометр. И тут до тех пор, пока мы не переобучим модель на новых признаках, тоже можно изолентой прикрутить следующую, сделать такой бустинг руками. То есть мы берем нашу текущую модель, которая на половине признаков работает, берем ее предикт, берем новые признаки, подаем вместе эти признаки и предикт старой модели как признак, и обучаем новую модель, и получаем уточненный признак. И так вот мы поверх прода эту изоленту можем прикрутить, чтобы у нас было время приспособиться к новому миру. Но в языковых моделях, которые обычно учатся длинно и тяжело, то есть вы взяли какой-нибудь BERT и хотите, чтобы он еще пару ваших токенов распознавал. Но учить BERT с нуля — это дорого. Учить какой-нибудь GPT-3 с нуля — это, наверное, нереально ради нового токена. И в большинстве моделей есть возможность последние решающие слои, так сказать, раздвинуть, добавить параллельно слой токенов, слой нейронок, инициализировать их более-менее разумно, и дообучить на новых примерах только вот эти вот токены. В тяжелых моделях иногда появляются новые классы. То есть какой-то класс, который у нас был один, внезапно выяснилось, что это куча из двух классов или из трех классов. И мы можем переобучить модель, которая будет их правильно разделять, либо, опять же, поставить временно каскадом модель, которая вот этот сложный класс будет раскидывать на примеры. Такое бывает, когда у нас данные накапливаются постепенно, и когда мы выкатывали модели, у нас еще не было данных достаточно, чтобы разделить этот класс, а потом они появились.

Ну, атаки имеют место быть. Хозяева мероприятия просто — это их хлеб. На фотографии этой статьи 2017 года ребята сделали Adversarial Patch, который можно было наклеить на что угодно, и после этого система распознавания образов классифицировала его как винтовку. То есть они взяли пластмассовую черепашку, это неживая черепашка, наклеили на нее этот патч, положили ее в аквариум, сняли ее под другим углом при другом освещении, и все равно она говорит — винтовка. Представьте себе, что у вас есть такая ручная черепашка, и вы такие пришли в аэропорт раз и выпустили, два выпустили, три выпустили. Потом, когда они наконец устанут и отрубят свою систему, вот тут вы придете с винтовкой.

Ну, в общем, не то чтобы очень хорошо,
но распознавание винтовок пока работает надежно.
Я беседовал с людьми, это неоткрытые результаты,
что наши системы к этому устойчивы,
которые у нас используются в наших специальных отраслях.
Американская военщина опубликовала доклад,
где они пытались такими adversarial-патчами прятать джипы,
склады с оружием, что-то еще, и получилось, что это тоже не работает,
потому что летит какой-нибудь вертолет, на котором установлен
или беспилотник системы компьютерного зрения,
непонятно каким углом, в непонятно каком освещении,
и adversarial-патч, который нужен, чтобы спрятать танк,
получается в несколько раз больше самого танка,
ну, в общем, непрактично.
То есть на вояк это пока не действует,
но, в общем, работа по этому направлению идет.

А банки тоже пока держатся. Я этой зимой участвовал как консультант и при подготовке соревнований, при подготовке ведения соревнования Data Fusion от WTB, где нужно было взломать банковские транзакции. Что такое взломать банковские транзакции? Это вот по последовательности платежей вас по кредитной карте, то есть как вы платите, можно достаточно хорошо определить ваш пол. Ну, это понятно, там, допустим, девушки покупают одно, мальчики там другое. Можно определить, есть ли у вас высшее образование, вот это уже сложнее, непонятно как, но, тем не менее, хорошо определяется. Можно определить, хороший вы или плохой заемщик, и вот тут становится интересно. Многие плохие заемщики хотели бы выглядеть в глазах банка заемщиками хорошими. И, кстати, есть сервисы, улучшим вашу кредитную историю. То есть, например, вы на протяжении двух месяцев совершаете вот такие покупки, ходите в спортзал, ходите в библиотеку и вроде бы как у вас там улучшается кредитная история. В Штатах много, у нас мало. Как был устроен конкурс? Выкатили модель, нереальную модель банка, но очень похожую на ту, которую банк использует. И нужно было заменить некоторое количество транзакций. Вот, ну, например, там типа девять раз купить в Томик Тургене, в один раз сходить в театр. Станете вы лучше заемщиком или нет? Если у атакующих был доступ к модели, они успешно ее обманывали. Но если у них не было доступа к весам модели, или если модель специально принимала меры для того, чтобы ее не обманули, у них не получалось обмануть. Там был турнир, на самом деле, можно было играть за атакующих, либо за защищающихся. А потом модели от лучших атакующих и защищающихся воевали друг с другом. Ну и, в общем, в этой борьбе щита и меча победил с большим перевесом щит пока, так что банки тоже пока держатся.
А вот поисковые машины давно эту игру проиграли. Накрутка поисковых подсказок всплывает перед каждыми выборами, когда к имени политика приделывается какое-нибудь обидное слово. Но гораздо чаще она используется для поискового продвижения. Например, вы хотите продавать пластиковые окна непременно вашей фирмы, и вы берете и накручиваете пластиковые окна в фирме такой-то. И роботы делают много запросов, а у поисковых машин поисковая подсказка устроена так, чтобы ловить тренды в данных. То есть они хотели бы, когда что-то случилось, например, случилась какая-то катастрофа или какое-нибудь выступление политика, чтобы в течение 15 минут поисковая подсказка уже это отразила. Поэтому у них быстро эта модель обрабатывают и ее реально накрутить. Потом в течение двух дней алгоритмы валидации эту глупость выкорчивают, но реально вот есть даже сервис накрутка поисковых подсказок, вы можете заплатить людям, вам накрутят. То есть поисковые машины эту битву и скорее проигрывают сейчас с адверсариал атаками.
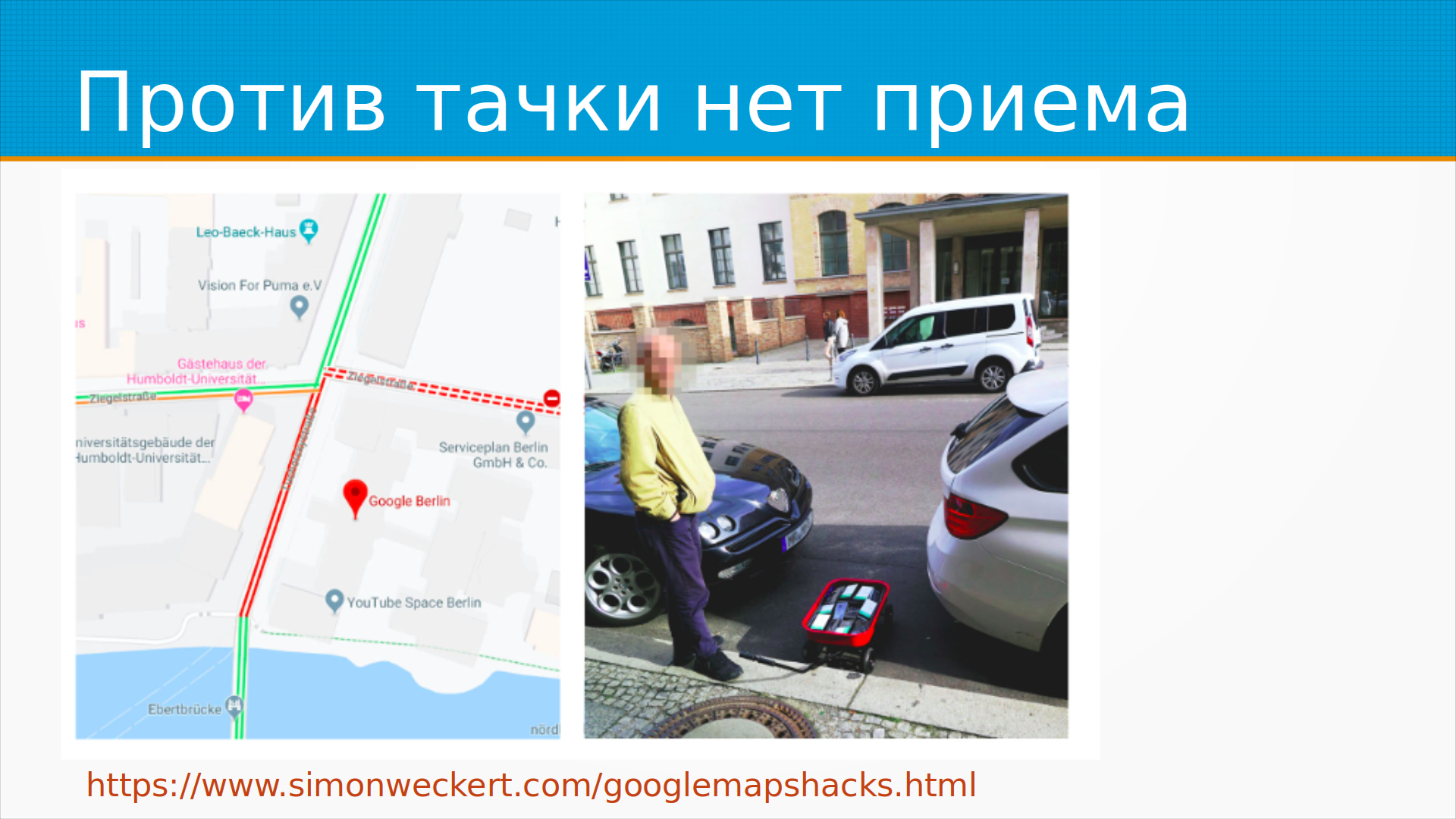
Ну и мой любимый пример — это один художник-концептуалист взял тачку, сложил туда кучу смартфонов с включенными гугл-мапами и медленно-медленно проехал по улице. Поскольку гугл-мапы, кстати, 2GIS и все остальные, яндекс-карты, они детектируют пробки по тому, с какой скоростью двигаются устройства, у которых включен навигатор, то, в общем, гугл-мап смотрит — у нас пробка. И на ровном месте совершенно он организовал пробку просто с помощью тележки смартфонов. Так что бойтесь дедушек с тележками, они сила.

Ну что делать-то? Что делать сильно зависит от того, как быстро у вас вызревают метки. Тут надо сделать еще введение, что такое вызревают метки. Обычно, когда мы говорим про обучение моделям машинного обучения, мы говорим об обучении с учителем, вот у нас есть какие-то признаки, вот у нас есть какой-то результат. И модель должна правильно предсказать результат. И тут мы неявно предполагаем, что результат, он как-то нам известен. А он нам не всегда известен. Предположим, что мы делаем модель для университета, который предсказывает будущее выпускника, насколько он проживет красивую полноценную жизнь и приведет ли он своих детей снова в университет. Ну, через 30 лет мы об этом узнаем, правильно ли наша модель работала или нет. Если мы показываем рекламу пользователям, то мы обычно в течение нескольких минут или самое позднее, там двух недель, знаем, кликнул он по рекламе или нет. Если мы выдаем кредит, то даже после того, как человек перестал платить по кредиту, все равно около двух месяцев метка наша созревает. Это еще не дефолт. И в случае, если мы, допустим, делали модель, которая предсказывает места, где построить магазин, чтобы он приносил прибыль наибольшую, мы узнаем после того, как магазин построится и там, скажем, полгода отработает. То есть реально мониторить качество работы модели в таких условиях непонятно как. Поэтому если метки вызревают быстро, то нам просто надо собирать, насколько предсказание попало в реальность. И как это делает, например, двогистам на дашборде в графане рисовать и ставить они в Прометеусе рисуют. И если оно вышло за какой-то коридор, мы поднимаем алерт, либо вытаскиваем старую модель, либо начинаем обучать новую. То есть как-то вот зовем людей, решаем проблему. Если же метки вызревают медленно, вот тут приходится всю свою инженерную злобу применять. Во-первых, у медленно вызревающих меток могут быть быстро вызревающие прокси. Проксиметрика — это метрика, которая предсказывает, позволяет нам предположить, как будет вести себя настоящая метрика, но она нам по какой-то причине удобна. Например, в одном из интернет-магазинов, с которым мы работали в e-commerce, проксиметрикой было то, что человек просмотрел от 3 до 20 страниц. Если он просмотрел больше 20 страниц, ну, наверное, он просто попялиться пришел, посравнивать. Если меньше 8, то его не заинтересовало. А вот если от 8 до 20, то даже если он сейчас не купил, то это все равно наш человек, он, может быть, пошел копить деньги, советоваться с женой и так далее и тому подобное. Он хороший. Если по ссылке со слайда там хорошая статья по проксиметрике, набор трех статей про проксиметрики в e-commerce, даже если вы не e-commerce занимаетесь, почитайте, очень интересный именно сам подход про построение иерархии метрика. Затем, если у вас нет возможности сделать хорошую проксиметрику, найти хорошую проксиметрику, где можно делать машинным обучением, Нетфликс делает это. Он ищет проксиметрики машинным обучением среди всех признаков. Автоматизирует это дело. Вы можете просто мониторить распределение предсказаний. О чем это? Предположим, что у нас есть модель банковского скоринга, которая одобряет или не одобряет клиентов. И в норме мы одобряем треть кредитов модель. Там еще потом сидит живой человек, например, который это дело проверяет. Одобряет модель, треть кредитов одобряет, две трети заворачивает. И тут внезапно, где-нибудь в конце марта 20-го года к вам прибегает финансовый аналитик и говорит, слушай, у нас модель стала одобрять 90%. Что делать? Ну, что делать? Порог одобрения задираем, чтобы по-прежнему она одобряла 30%. Начинаем анализировать, что произошло. Президент Российской Федерации Владимир Владимирович Путин к своей речи к народу сказал, мы не бросим заемщиков. Люди, которые из-за коронавируса оказались в сложной ситуации и не смогли платить по кредитам, мы их поддержим. Кредиты можно не платить, сказал народ. И ломамнулся получать кредиты. Это реальная история. То есть, если не мониторить распределение предсказаний, вы такие штуки пропустите, потому что как их еще поймать? Ну и хорошо, конечно, мониторить распределение входных признаков. Тут у меня тоже есть cool story. Была форма, в которую человек заполнял данные и на основании этой формы решалось, хороший он там, молодец он или плохишь. И форма была страшная, некрасивая, но нормально работала. Но все-таки хотелось ее украсивить, ее украсили. И одно поле передвинули наверх и сделали его более заметным. Раньше его никто не заполнял, кроме самых нудных, занудливых, хороших людей, которые заполняли всю форму до последней галочки. Есть такие люди, которые уперто форму до последней галочки заполняли. И модель их прямо любила. Она говорила, это прямо молодцы. А тут молодцами стали все, потому что она просто стояла вторая сверху и ее все заполняли. И на самом деле сначала подняли панику аналитики по распределению предсказаний. Вродк мир не менялся. Оказалось, что просто формочку переставили. Если бы они мониторили распределение признаков, что этот признак резкий, они после этого стали мониторить. Если бы они мониторили распределение признаков, они поймали это не через два месяца, а на следующий день. Хорошо валидировать входные данные. Вам обещают, что здесь будет строка, приходит число. Это еще ничего хуже, когда вам обещали, что здесь будет число, приходит строка. Так бывает всегда и всегда будет. Для мониторинга входных данных есть хорошая библиотека Great Expectation. Она встраивается во многие фреймворки. У нас она на самом деле почему-то не зашла, но мы все обкладываем моделями пайдантик, поэтому мы как-то живем. Но я верю, что однажды и мы тоже будем ее использовать. Есть интересный красивый подход моделировать невязку. О чем это? Предположим, мы обучили модель, которая предсказывает, допустим, тот же самый скор бал, то есть насколько человек хороший, а взъемщик плохой. Мы же ее учили не на всей выборке. У нас была валидационная выборка, на которой мы потом оценивали качество модели. То есть у нас есть данные, которых модель не видела. И мы берем ошибку на этих данных и признаки и строим модель, которая предсказывает ошибку модели. И у нас, получается, две модели. Есть сама модель, которая предсказывает то, что нам надо, и вторая модель надсмотрщик, которая предсказывает, ошибется модель или нет. И мы на прод их обе выкатываем. И когда вторая модель надсмотрщик говорит, слушайте, вот она кажется фигни делает, мы начинаем принимать меры. Это звучит странно, но это работает. И опять же, ВТБ на DataFusion, по-моему, на самом первом рассказывал, как они это у себя делают, но это многие делают.
Еще есть Uncertainty Estimation, целая дисциплина, которая позволяет оценивать неуверенность модели.
Там есть разные варианты.
Самый простой из них – это Trust Score,
насколько та точка, в которой мы предсказывали,
близка к тем точкам, на которых мы учились,
то есть насколько она хорошо поддержана в обучающем наборе.
Ну и есть по ссылке со слайда,
слайды доступны, я потом QR-код покажу,
можно будет сфотографировать, скачать.
И, наверное, их организаторы разошлют на самом деле.
Есть курс, который учит, как оценивать неуверенность модели.

Ну и в результате всего этого мы вдруг узнали, что пора модель переобучать. И что же делать? Нужно собрать новые данные, дообучить модель, как-то сравнить их с текущей моделью, чтобы шило на мыло не поменять, чтобы та модель, которую мы выкатили, была на самом деле лучше, чем та, которая у нас была. А как мы определим? Оставить ту, что лучше, ну и в этом цикле жить.

Как часто модель надо дообучать? Дообучение модели не бесплатное. То есть у нас есть люди, которые будут ее дообучать, у нас есть вероятность ошибки, что-то сломать при этом. Нам нужно обрабатывать данные. Если метки у нас созревают медленно, то просто процесс сопоставления признаков с метками может быть очень дорогой. То есть это может быть действительно дни запросов к базе. С другой стороны, снижение качества модели, если мы ее не переобучаем, оно тоже стоит денег. То есть мы позволяем модели ошибаться, и мы же делали для того, чтобы она какую-то пользу нам приносила, а пользу не приносит. То есть, допустим, каждый процент ошибки нам какой-то приносит убыток. И у нас простая арифметика, если убыток от переобучения модели меньше, чем убыток от плохого функционирования модели, давайте переобучим, будет хорошо. А как узнать, на сколько рублей устарела модель? У нас есть исторические данные, ну, предположим, что они у нас есть. И мы можем, например, обучиться на данных за позапрошлый год и смотреть, как ошибка нарастала на всем прошлом годе. И затем предположить, что скорость устаревания модели примерно одна и та же. Это очень сильное предположение, но обычно так можно сделать. Еще иногда бывает сезонность, и тогда мы знаем, что каждый сезон у нас модель плывет. Ну и оцениваем, сколько теряем, и принимаем решение.
А если мы делаем какой-нибудь промышленный ML с датчиками, тут надо смотреть, как часто мы вынуждены менять датчики. И переобучать модель не реже, чем половина срока жизни датчика. Но это такое ничем не обоснованное правило большого пальца, потому что если вы поменяли датчик, он на самом деле начинает выдавать другие чуть-чуть данные. То есть датчик плывет в течение срока службы. Вот нам надо переобучать модель, чтобы с этим делом бороться.

Есть модели, которые переобучаются прямо на лету. То есть их не надо отдельным образом переобучать. Вот, например, фреймворк River для целого класса моделей позволяет дообучать модели на ходу. Тут есть свои проблемы, главное из которых это то, что набор моделей, которые мы можем дообучать на лету, ограничен. То есть выбор такой второсортный. Есть более тонкие проблемы в больших ML-системах. У нас ML-модель работает не на одном компьютере, а на нескольких узлах. Если каждый узел доучивается отдельно, получается, что они научились разному. И тут обычно делают в таких случаях, что время от времени собирают данные, переобучают модели, перевыкатывают на узлы, а потом каждый узел чуть-чуть доучился опять. И есть еще попытка Federated Learning объединить, чему они там научились. В общем, все это надо по месту смотреть. Иногда это работает, чаще нет.
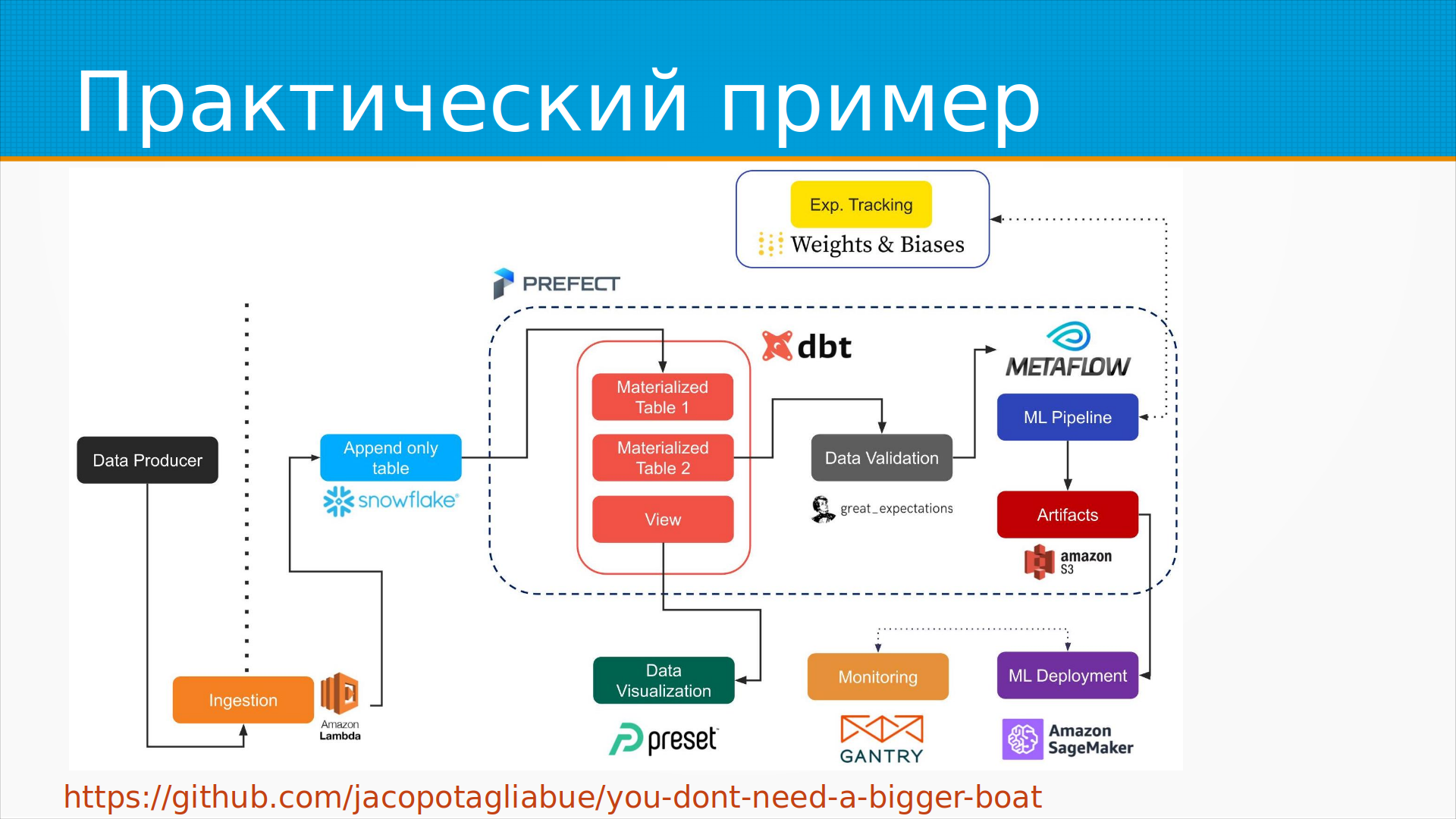 Практический пример. Есть ли у меня время его разобрать?
Это есть хорошая работа.
Вам, говорит, не нужна большая лодка для большой модели.
Пример того, как построить ML-систему средней сложности вообще не имея серверов,
то есть server-less.
Можно я прямо вот тут попрыгаю.
У нас есть какое-то место, откуда у нас идут данные.
И мы их собираем и ставим в какую-нибудь очередь.
Данные могут производиться на вашем телефоне или в вашем браузере.
И сохраняем их в базу данных.
Вот тут наша Data Warehouse Append Only Table.
Что это?
Обычно, когда мы храним данные в базе данных, нам приходят более свежие данные,
мы их перезаписываем.
Append Only Table – это когда мы сохраняем последнюю версию данных вместе со всеми предыдущими.
Предположим, у вас есть фитнес-трекер, который отслеживает ваш вес.
И он отслеживает не ваш последний вес, а всю историю ваших изменений веса.
А когда вам нужен вес на определенную дату, мы находим запись на эту дату и смотрим.
Это очень удобно именно для ретро-тестов, когда мы прогоняем модель
и смотрим, как бы она себя вела в прошлом,
если бы у нее были те данные, которые у нее были в прошлом.
Из этих данных мы собираем.
Все равно нам нужно последнее значение или значение на какую-то дату.
Так называемую Materialized View, материализованную таблицу, то есть признаки наши.
И из этих признаков мы делаем бизнес-аналитику, визуализацию.
Отправляем их в модель, дообучаем, показываем, мониторим.
В репозитории просто эта схема разобрана.
Тут они для мониторинга используют Gantry.
Точно так же я бы рекомендовал поставить здесь Evidently AI.
Что тут интересного?
Интересно именно сохранение данных так, чтобы вы могли вернуться в прошлое.
Если вы все время храните последний слепок данных,
то когда вы обучаете модель на исторических данных,
у вас всегда все поля заполнены, все ошибки исправлены,
и все странные случаи уже разрешены.
А в жизни у вас будет не так.
Поэтому хорошо хранить данные.
В программировании такой подход называют Event Sourcing.
Когда вы храните не текущее значение, а изменения мира.
Он, кстати, в бухгалтерии живет с этими веками.
То, что называется проводки.
Практический пример. Есть ли у меня время его разобрать?
Это есть хорошая работа.
Вам, говорит, не нужна большая лодка для большой модели.
Пример того, как построить ML-систему средней сложности вообще не имея серверов,
то есть server-less.
Можно я прямо вот тут попрыгаю.
У нас есть какое-то место, откуда у нас идут данные.
И мы их собираем и ставим в какую-нибудь очередь.
Данные могут производиться на вашем телефоне или в вашем браузере.
И сохраняем их в базу данных.
Вот тут наша Data Warehouse Append Only Table.
Что это?
Обычно, когда мы храним данные в базе данных, нам приходят более свежие данные,
мы их перезаписываем.
Append Only Table – это когда мы сохраняем последнюю версию данных вместе со всеми предыдущими.
Предположим, у вас есть фитнес-трекер, который отслеживает ваш вес.
И он отслеживает не ваш последний вес, а всю историю ваших изменений веса.
А когда вам нужен вес на определенную дату, мы находим запись на эту дату и смотрим.
Это очень удобно именно для ретро-тестов, когда мы прогоняем модель
и смотрим, как бы она себя вела в прошлом,
если бы у нее были те данные, которые у нее были в прошлом.
Из этих данных мы собираем.
Все равно нам нужно последнее значение или значение на какую-то дату.
Так называемую Materialized View, материализованную таблицу, то есть признаки наши.
И из этих признаков мы делаем бизнес-аналитику, визуализацию.
Отправляем их в модель, дообучаем, показываем, мониторим.
В репозитории просто эта схема разобрана.
Тут они для мониторинга используют Gantry.
Точно так же я бы рекомендовал поставить здесь Evidently AI.
Что тут интересного?
Интересно именно сохранение данных так, чтобы вы могли вернуться в прошлое.
Если вы все время храните последний слепок данных,
то когда вы обучаете модель на исторических данных,
у вас всегда все поля заполнены, все ошибки исправлены,
и все странные случаи уже разрешены.
А в жизни у вас будет не так.
Поэтому хорошо хранить данные.
В программировании такой подход называют Event Sourcing.
Когда вы храните не текущее значение, а изменения мира.
Он, кстати, в бухгалтерии живет с этими веками.
То, что называется проводки.

И еще хорошо бы записывать все предикты, которые вы сделали. То есть у вас есть какой-то мир, вы собрали из него какие-то признаки, нагенерировали какие-то фичи для модели, сделали предикт. И вместо того, чтобы успокоиться, вы взяли, сохранили эти признаки, пользователи, для которых вы это сделали, время, когда вы предсказывали, модель и результат. Зачем это нужно? Это, кстати, достаточно дорого. То есть вы, получается, храните все сделанные вами предикты. Но, во-первых, это хорошо для разбора полетов в каких-нибудь чувствительных сферах, типа финансов. А во-вторых, для медленно вызревающих меток вам потом, когда метки вызревают, вы просто сразу получаете возможность добавить их к уже насчитанным признакам и досчитать. Потом есть целый класс моделей, например, в рекомендательных системах, которые можно явно учить на вот таких ошибках. И еще такие вещи позволяют вам хорошо организовать мониторинг моделей. Это долго, сложно, но если есть возможность сохранять предсказания, которые вы сделали, делайте это, это на самом деле окупится.

Ну и вот мы каким-то образом автоматически по расписанию или по запросу или по звонку директора
мы дообучили новую версию модели.
И прежде, чем мы выкатим ее на прот, нам бы хорошо убедиться, что эта модель лучше, чем предыдущая.
Тут есть тоже несколько подходов.
Обычно вспоминают про АБ-тесты, но АБ-тесты для терпеливых.
То есть в случае обычного производства или небольшого интернет-магазина
вы можете не дожить до конца АБ-тестов.
И более того, мир к тому времени изменится.
Распределение сдрейфует, и ваш АБ-тест будет недействителен.
То есть АБ-тесты это для Яндекса, для Гугла, это не для большинства из нас.
Просто не прокрасятся они, как говорят.
Люди, которые торопятся быстро получить…
А ну и пока вы делаете АБ-тесты, на самом-то деле ваша модель-то не работает.
То есть вы знаете, что у вас есть хорошая модель, но еще нельзя ее выкатить всем, потому что у нас АБ-тесты.
Netflix делает интерливинг.
Грубо говоря, несколько моделей, две модели, которые предсказывают, какие фильмы вы будете смотреть,
и вам их показывают фильмы через одну.
То есть одна модель показывает вам 5 фильмов, вторая модель предсказывает вам 5 фильмов
и смотрит на предсказание какой модели вы чаще кликаете.
Таким образом, если мы выкатили новую хорошую модель, то она сразу начнет приносить пользу.
Мы увидели, что такие клевые предсказания, и пошли.
Если мы выкатили плохую модель, но у нас еще есть 5 старых предсказаний, пользователь выживет.
То есть если вы торопитесь наносить пользу, есть возможность делать интерливинг, делайте.
Для уверенных в себе есть канареечный диплой.
То есть мы берем на группу пользователей, скажем, на 1% пользователей выкатываем новую модель.
И если они не начали жаловаться и не перестали у нас покупать, выкатываем на всех остальных.
Если цена ошибки очень велика, как это бывает в безопасности, и, я подозреваю в энергетике,
то у нас есть всегда возможность сделать теневой диплой.
То есть мы выкатили модель, она делает предсказания, но на самом деле мы эти предсказания никак не используем.
Мы просто их сохраняем, чтобы посмотреть, что было бы, если бы мы на эти предсказания положились.
Ну и для тех, кто любит приключения, всегда есть вариант просто обновлять новую версию по расписанию.
Там можно наступить на интересные, очень любопытные грабли.

Итого, я уже заканчиваю, если вы не уснули.
Моделируйте устаревание модели.
Проектируйте с учетом стоимости владения на мониторинг, переобучение дообучение и замену модели.

Несколько ссылок на почитать. Из них, пожалуй, стоит отметить блок Evidently.ai.
Evidently.ai – это инструмент и платформа для мониторинга моделей.
Она прекрасна, и их основательница прекрасна, и блог их прекрасен.
Все в них прекрасно.
Вот слайды тут.
Спасибо вам, что не уснули.
