
- 19.12.2022
- 25.08.2024
- обучение
- #mlsystemdesign
Тринадцатая лекция открытого курса "Дизайн систем машинного обучения", "Непредвзятость. Безопасность. Карточки моделей".
Слайды можно скачать тут mlsysd13ods.pdf
Текстовая расшифровка:
 Добрый день. Это тринадцатая лекция курса про дизайн систем машинного обучения — "Непредвзятость, безопасность и карточки моделей".
Добрый день. Это тринадцатая лекция курса про дизайн систем машинного обучения — "Непредвзятость, безопасность и карточки моделей".

Что такое карточки моделей? Примерно в конце восемнадцатого года сотрудники Google выпустили статью "ML Model Card for Model Reporting". В ней они предложили стандарт на документирование того, как работают модели, что требуется моделям, какие ограничения у них есть. С этого времени Model Cards фактически стали отраслевыми стандартами.

Рекомендации Google, то есть как Google рекомендует делать карточки моделей, включают в себя: описание, content — это собственно описание модели, на чем она обучена, какие данные использовались, как ее вызывать; process — сколько она тренировалась, на каких данных, метрики модели; experience — какого качества удалось добиться, в каких условиях она работает хорошо, в каких не очень; fairness — ограничения модели и как они там боролись с ее предвзятостью; и также privacy — какие были приняты меры для защиты персональных данных, и на какие компромиссы разработчики пошли при разработке модели.

Пример карточки модели, это, например Google Model Card для Face Detection. Что мы тут видим? Мы видим, что у нас есть описание модели, мы можем попробовать загрузить свою карточку, есть у нас какие-то performance метрики модели и возможность оставить свой фидбэк, описанны tradeoff и limitations модели, ограничения. То есть у нас есть все, что нужно для того, чтобы внедрять эту модель, и документация собрана в таком едином стандартном виде.
Надо заметить, что Model Cards — это не замена документации, это именно как наклейка на продукте для того, чтобы быстро вспомнить или сообщить нужную информацию всем заинтересованным лицам, то есть начальству или пользователю отправить почитать, или юристу, чтобы проверили, и так далее.
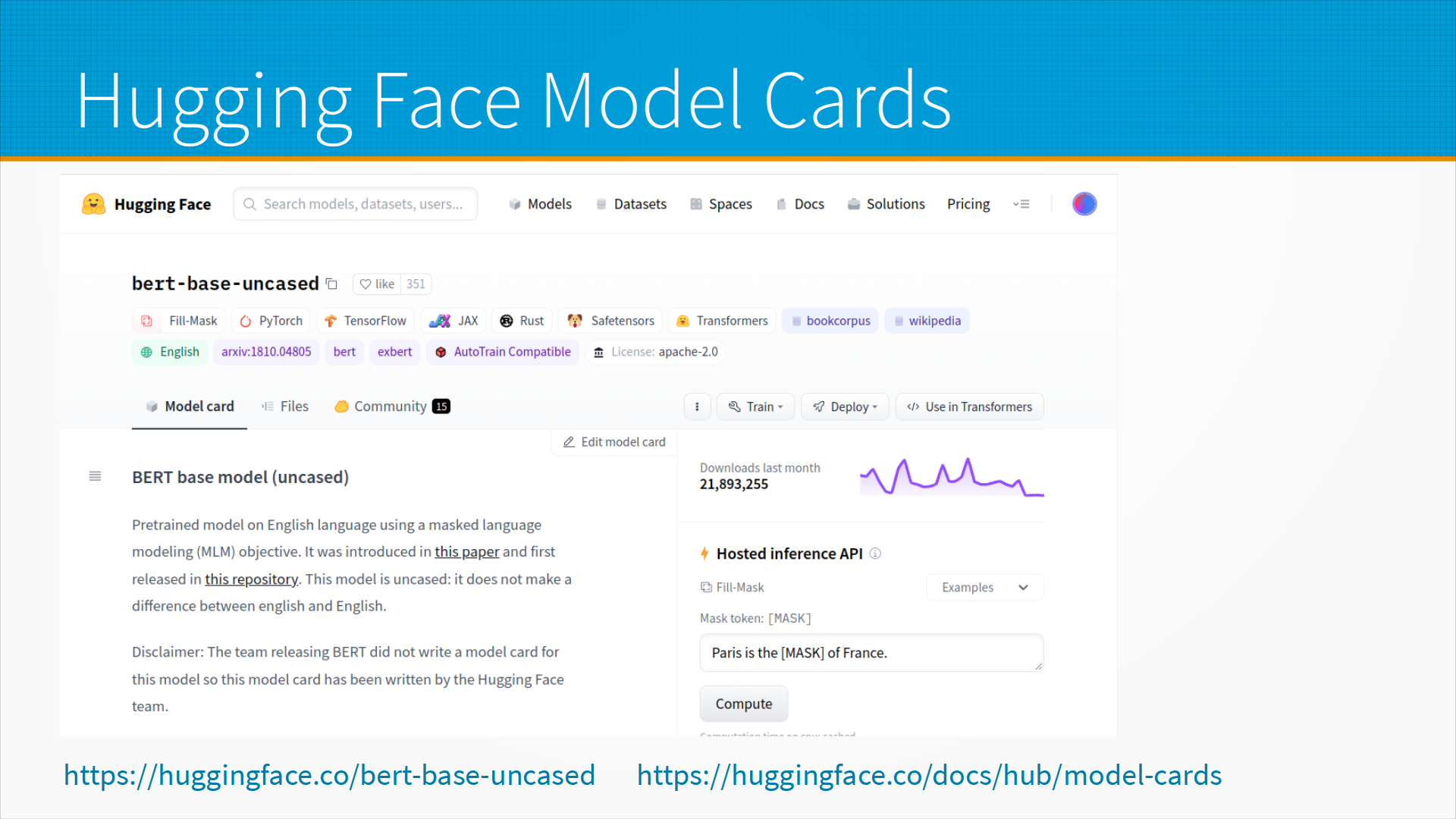
У библиотеки Hugging Face для каждой модели есть Model Card, и где-то они генерируются автоматически, а где-то пишутся вручную. Вот, например, карточка модели bert-base-uncased, и она написана вручную командой — то есть тут написано, что команда, выпустившая BERT, не создала Model Card, так что мы ее взяли и сами смастерили, потому что модель популярная.
Что мы тут видим? Мы видим пример того, как эту модель вызывать, мы можем попробовать запустить inference модели на наших каких-то тестовых данных, у нас есть описание того, как ее использовать в тех или иных фреймворках, и описание решаемых задач, на чем она обучена, и так далее. Это удобно, это позволяет подбирать модели, на Hugging Face есть поиск по карточкам модели, можно отфильтровать модели по задачам, по фреймворкам, по языкам, и так далее, и тому подобное.

На Kaggle, платформе для соревнований, есть курсы, и один из курсов — это Kaggle Intro to AI Ethics, и вот там в последнем, пятом, модуле рассказывается, как делать карточки модели. В частности, Kaggle рекомендует включать в карточку модели разделы: Module Details, то есть, собственно, детали о модели; Intended Use — то есть, например, если мы сделали модель, которая распознает лица, и она их распознает так приблизительно, для поиска по фотоархиву нормально, для авторизации по лицам, пожалуй, что не подходит, и мы хотели бы здесь об этом упомянуть; какие факторы использовались при обучении модели, то есть, признаки; какие метрики, по каким метрикам мы ее оценивали; на каких данных мы ее оценивали, на каких данных учили; количественный анализ того, как она работает; Ethical Considerations, то есть, что мы думали по поводу этичности, неэтичности этой модели, и когда мы не хотели бы, чтобы ее использовали; ну, и вообще, список разных граблей и рекомендаций для тем, кто будет с этой моделью работать.

И, в принципе, карточка модели – это краткий документ для заинтересованных лиц, то есть, одна-две страницы, небольшой документ. Главная его задача – это управлять ожиданиями от модели, предотвратить ее нецелевое использование.
Что такое, собственно, нецелевое использование? Это когда мы, допустим, сделали модель для поиска рака у животных, а с ее помощью пытаются искать рак у людей. Все-таки анатомия животных и людей немножко разная, и мы не хотели бы, например, чтобы эту модель так применяли. А чтобы предотвратить нецелевое использование, мы должны описать предполагаемое использование, указать, какие данные были использованы, границы применимости и какое-то ожидаемое качество, чтобы предотвратить какие-то ошибки уже при эксплуатации. Ну, то есть о Model Card можно думать примерно как о наклейке на коробке с сосисками. Калорийность, содержание жира, мясопродукты, которые были использованы, то есть, что-то, чтобы быстро понять, что происходит.

Важная часть разработки, эксплуатации и поддержки ML-систем — это безопасность ML-систем. У ML-систем, во-первых, есть обычные проблемы безопасности всех систем, то есть, проблемы с физической безопасностью, проблемы с безопасностью при проектировании, плюс есть обычные проблемы безопасности компьютерных систем, то есть, поскольку наша ML-система она работает на компьютерах, стало быть, эти компьютеры можно взломать и эти компьютеры могут тоже послужить площадкой для развертывания атаки в сеть предприятий и так далее и тому подобное.
То есть наши проблемы — это обычные проблемы безопасности всех систем, обычные проблемы безопасности компьютерных систем и еще специфичные для ML проблемы безопасности.

О них мы как раз и поговорим. Тут надо понимать, что безопасность должна обеспечиваться на всех этапах жизненного цикла ML-системы, то есть безопасность это не что-то, что мы сделали во время разработки моделей или во время эксплуатации. Безопасность должна обеспечиваться на всех этапах жизненного цикла.
Примеры специфичных для ML атак — ну, во-первых, это отравление датасета. Разработчики или те, кто имеет доступ к датасету, это не обязательно разработчики, могут вложить в наш датасет специально подготовленные, размеченные примеры. Предположим, например, что мы делаем систему контроля доступа, и у нас туда добавлены все фотографии всех людей, плюс у нас есть фотография людей в специальных красных очках, которые очень редко встречаются, и мы всем этим людям в красных очках приделали метку, что это наш генеральный директор. И тогда любой человек, у которого есть именно эта марка странных красных очков, зайдет, и система распознает его как генерального директора. Вообще-то говоря, системы распознавания лиц, которые используются в системах управления контролем доступа, работают так, что их, пожалуй, очками не обманешь, но вот как раз по ссылке на слайде есть пример про успешную реализацию отравления датасета.
Есть атаки на извлечение исходных данных — то есть, например, большие языковые модели обучают на всем тексте, найденном в интернете. И есть примеры, как из этих языковых моделей вытаскивают тексты, на которых они учились, в том числе содержащие номера карточек, адреса, какие-то персональные данные. Из обученных сверточных сетей можно вытащить фотографии людей, на которых они учились, а также фотографии людей можно вытащить из моделей, обученных на для распознавания лиц. То есть, в этих эмбеддингах, вообще-то говоря, фотографии в том или ином качестве лежат, их можно достать.
Интересным примером была деанонимизация Netflix-овского датасета, когда они выложили анонимизированный датасет, в котором все ID пользователей были заменены на числа, ID фильмов были заменены на числа, и предложили построить рекомендательную систему, которая бы предсказывала, какому пользователю понравятся какие фильмы. Но получилось так, что деанонимизировать фильмы достаточно просто. Во всяком случае, самые популярные. То есть, можно посмотреть, какие фильмы были самые популярные, и посмотреть, какие фильмы были самые популярные в датасете. Соответственно, отранжировав фильмы по популярности в датасете и в реальности, мы можем первый десяток самых популярных фильмов вытащить. Точно так же мы можем вытащить людей, которые чаще всего оставляли отзывы, и посмотреть, какие люди соответствуют каким отзывам на фильмы. То есть, мы деанонимизируем топ людей, мы деанонимизируем топ фильмов, а дальше примерно так же, как решаются японские кроссворды, мы деанонимизируем всю остальную таблицу. Получалось, что как бы у нас данные анонимизированы, ни фильмы, ни люди не имеют реальных меток, но они вытаскиваются, потому что есть доступ к внешним данным. По ссылке со слайда пример с вытаскиванием данных из модели.
Если у вас есть какая-нибудь интересная, сложная модель, которую вы считаете своей интеллектуальной собственностью, и к ней есть API, кто-нибудь может подойти и попробовать ее скопировать. То есть, мы будем подавать на вход вашей модели всякий мусор, смотреть, что она отвечает, и обучим свою модель на ваших ответах, или доучим свою модель на ваших ответах. Вам, может быть, этого не хотелось, но это возможно, и примеры таких действий есть по ссылке на слайде.
Наверняка многие слышали, видели, читали про адверсариал-атаки в задачах компьютерного зрения, когда, например, мы берем специальную наклейку, клеим ее на что-нибудь, и наша система распознавания образов говорит — вы знаете, это винтовка. Хотя это на самом деле могла быть черепашка или, например, сапог. Легко предположить, что мы можем сделать обратную операцию. Взять, например, наклейку, которая распознается системой распознавания образов как, допустим, чемодан, наклеить ее на винтовку и пройти мимо охраны. То есть, буквально так скорее всего не получится, но сама возможность этого очень интересная. И в ссылке со слайда есть пример адверсариал-атаки, на Arxiv все статьи есть.
Популярная атака, которой занимались задолго до того, как вообще начали прорабатывать адверсариал-атаки на ML-задачи — это манипулирование алгоритмами ранжирования. Есть целая индустрия, индустрия поискового продвижения, которая живет фактически тем, что пытается манипулировать алгоритмами ранжирования. Большинство делают это очень наивным образом, то есть выкручивают какую-нибудь одну фичу — например, частоту упоминания фразы "пластиковые окна" или "цветы в Москве", что-нибудь такое глупое, наивное и уже не работающее. Но есть хорошая свежая статья про то, как это делать правильно, тоже лежит на Arxiv, ссылка на слайде.
Атаковать можно не только нейронные сети. Например, ансамбли деревьев тоже отлично атакуются, нейронные сети в этом смысле не являются каким-то исключением.
Ну и то, с чем мы сталкиваемся каждый день — это прохождение фильтров, то есть кто-то хочет отправлять нам спам, а мы бы, например, не хотели бы его получать. Но люди модифицируют признаки, то есть заменяют букву О на ноль, вставляют какие-то картинки вместо текста — и спам-письма проходят фильтры, мы их читаем. И примеры на исследование того, как же правильно проходить спам-фильтры, есть на слайде.

Нашей безопасности угрожают не только атаки, но и недосмотры. То есть модель может быть просто плохо протестирована. Мы могли не проверить, как она работает с тем или иным пользовательским сегментом — например, мы протестировали модель распознавания образов на взрослых, а детей забыли включить в выборку. И наш робот, который обходит людей, чтобы в них не воткнуться, может, например, проехаться по какому-нибудь ребенку, это совсем нехорошо. Модель может плохо работать для какого-то сегмента — например, она может хорошо работать с взрослыми, но плохо работать с детьми и стариками.
А еще она может не выдерживать нагрузку. То есть, например, что произойдет с системой, когда ML-модель не сможет вовремя выдавать ответы? Ну, наверное, ничего хорошего, но — как она упадет? Откроет ли это какую-нибудь дыру в безопасности? Что сделает наша система контроля доступа, если вовремя не ответят ни да, ни нет? А как будет себя вести наш антифрод, если он будет перегружен?
Особенности ML-систем в том, что они могут не сообщать об отказах наших ML-моделей. То есть, например, если нам не пришло уведомление из детектора аномалии — это не значит, что все хорошо. То есть, у нас может не быть хорошего способа понять, жива ли наша ML-модель, или, даже если она жива, может не быть хорошего способа узнать, остались ли мы в ее области определения. То есть, можно ли все еще верить ее предсказаниям, или ей дали на вход что-то такое, по поводу чего она будет предсказывать чушь.
В принципе, любое нарушение работы модели может повлечь финансовые и репутационные риски, угрожать жизни и здоровью людей. Ну, а еще дроны могут убивать не тех людей — по ссылке статья, она не такая забавная, как остальные, где рассказывается, что американские дроны в Пакистане, которые расстреливали периодически по ошибке то свадьбу, то что-нибудь еще, классифицировали людей аж целым рандомфорестом по статистике телефонных звонков человека. То есть, курьер вы Аль-Каиды или нет, определяли по тому, как часто и какому количеству людей вы звоните. И рандомфорест, вроде бы, был не очень хорошо обучен, так что большинство бизнесменов, по статистике своих звонков вполне попадали в разряд курьеров Аль-Каиды.

По стадиям атаки есть ассоциированная с американской оборонкой организация MITRE и есть так называемый MITRE ATLAS. Они занимаются компьютерной безопасностью, и конкретно MITRE ATLAS это действительно атлас типичных атак на программное обеспечение, на ML-модели. И если мы посмотрим стадии атак, перечисленные у MITRE, то мы видим типичную последовательность секретной операции спецслужб — то есть, разведка, развитие ресурсов, первоначальный доступ, доступ к ML-модели, обеспечение своего присутствия, чтобы нас оттуда не вынесли и так далее и тому подобное. То есть, сами по себе атаки проработаны и систематизированы.

Сам по себе атлас — это пример техник, которые применяются на том или ином этапе атаки. Например, отравление обучающих данных, о котором я только что говорил, или, например, backdoor ML-model, то есть какая-нибудь закладка в ML-модели используется на этапе обеспечения своего присутствия при атаке. И exfiltration via ML inference API — например, мы можем некоторые модели обучить через API тому, что нам нужно.

Кроме непосредственно угроз, у MITRE есть также матрица тактик, которые применяют атакующие. И тут они тоже хорошо систематизированы. Для каждого этапа атаки, для каждой технологии мы можем посмотреть какие тактики, скорее всего, атакующие будут использовать — или какие можем использовать мы, если мы сами атакующие.
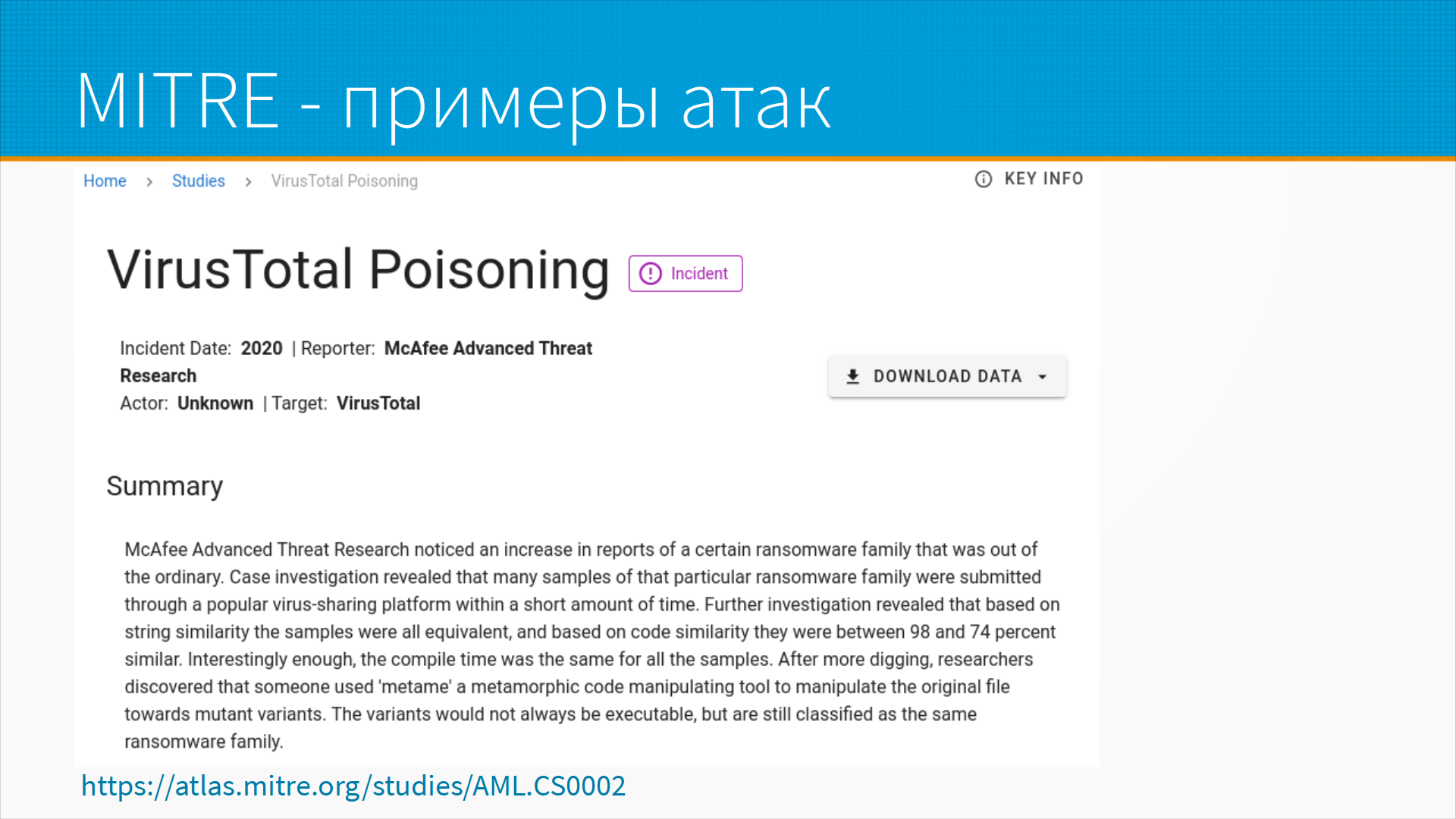
Вот примеры атак из каталога MITRE. Это, например, VirusTotal Poisoning. То есть представьте себе, что вы хотите каким-то образом помешать продукту конкурента выйти на рынок. У вас есть доступ к раннему прототипу продукта, и вы берете и начинаете добавлять в базу VirusTotal, отправлять экземпляры. Это можно сделать по-разному. Например, выкладывая вирусы на какой-нибудь форум — вы начинаете отправлять туда примеры вирусов, содержащие в качестве бесполезной нагрузки в теле куски кода программы конкурента. А спустя какое-то время, когда он выкатит свою программу, вирусная программа начнет определять его программу или его обновления как вирус. Ну и точно так же, планируя какую-нибудь атаку, мы можем перегрузить, то есть добавить какие-нибудь данные в антивирусную систему с тем, чтобы зашумить ее модель, и она пропустила потом нашу атаку. Вот по ссылке описание этой атаки на VirusTotal.
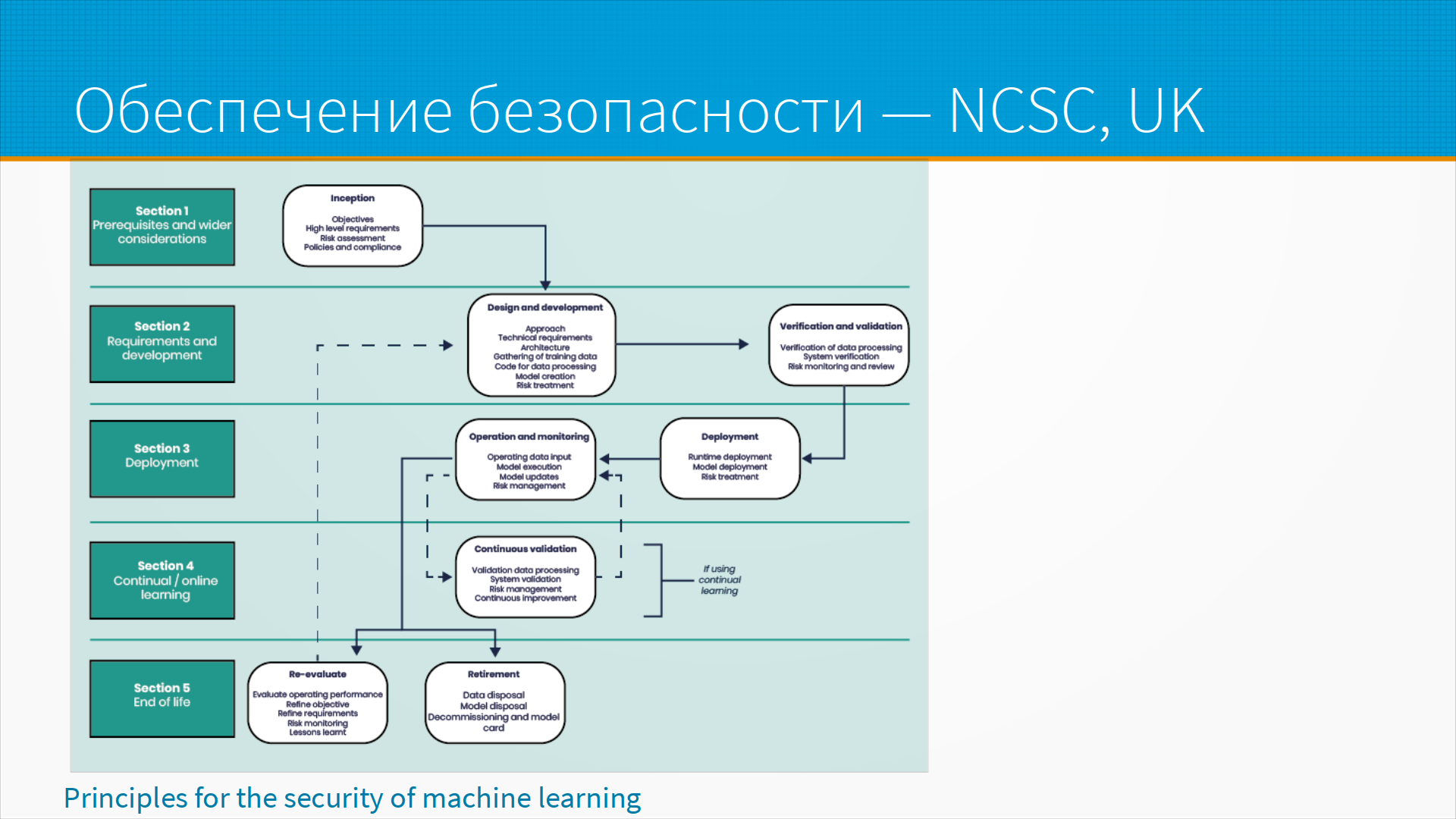
Другой оборонный проект — это National Computer Security Center UK, центр компьютерной кибербезопасности английский. Он расписывает, как на разных этапах жизненного цикла какие мероприятия по защите мы должны предпринять. Тут что интересно — что на самом-то деле защита не кончается, допустим, с окончанием работы модели. До самого вывода из эксплуатации мы по-прежнему должны защищать данные. То есть наша информация может лежать где-то в старых бэкапах, в уже не используемом, но еще не отключенном API, и так далее и тому подобное. Мы можем обеспечить безопасность, только если процесс обеспечения безопасности будет длиной в весь жизненный цикл системы.
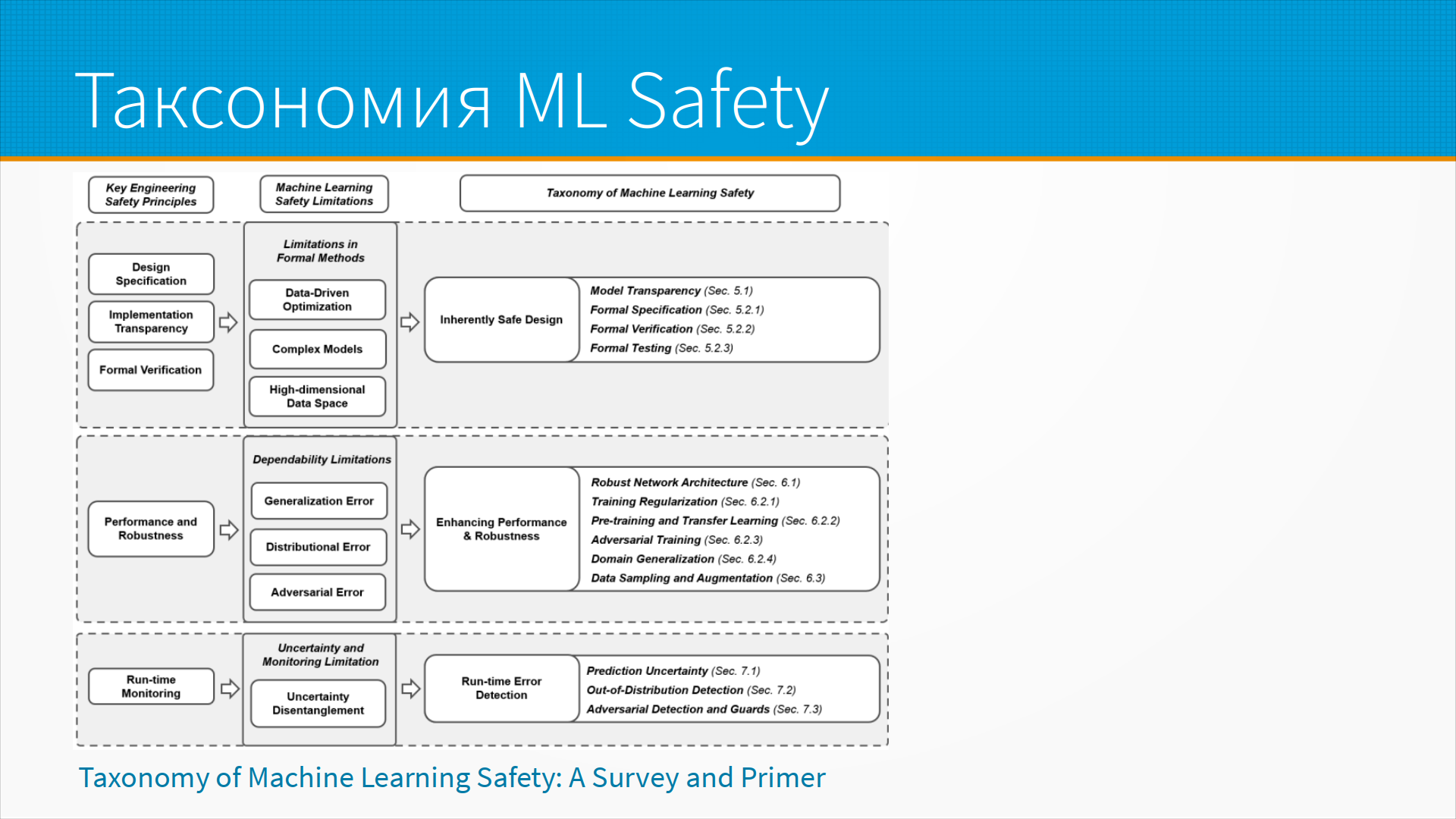
В прекрасной статье про таксономию Machine Learning безопасности мы видим разбор разных подходов к обеспечению безопасности, которые применяются на разных стадиях жизненного цикла. От мероприятий по верификации, которые используются при приемочных тестах, до рантайм мониторинга и детектирования ошибок в рантайме.

В принципе все проблемы с безопасностью — это какие-то риски, и про управление рисками у нас есть хорошо проработанные методики. Например, в Project Management Body of Knowledge, PMBoK, есть отдельно расписанный процесс управления рисками. И он состоит из планирования управления рисками, то есть как мы будем непосредственно планировать, что мы будем делать с этими рисками. Тут есть идентификация, то есть составить список того, что может пойти не так. Качественный анализ рисков, то есть оценить, какой ущерб может причинить этот риск, и количественный анализ рисков. Какое-то планирование и реагирование на риски, и контроль рисков.
Как это может быть? Предположим, что мы собираемся разрабатывать ML-систему. Для начала мы разработаем план управления рисками безопасности. Следуя плану, мы идентифицируем основные угрозы нашей модели — скажем, 10 основных угроз, которые нам покажутся самыми значимыми. Например, отравление датасета разметчиками, например, закладки в модели, например, копирование модели через API. Мы как-нибудь оценим вероятность этого риска и какой ущерб, как мы думаем, оно нам принесет. Затем мы решим, как мы будем с этими рисками работать, если они реализуются. И будем осуществлять постоянный мониторинг и контроль рисков. По мере того, как новые риски будут возникать, мы их будем идентифицировать, добавлять в список и повторять процедуру.

А что, собственно, можно сделать с рисками? С риском, как нас учит управление проектами, можно сделать четыре главных вещи. Во-первых, мы можем его принять и сказать — ну ничего мы с этим не можем сделать, риск этот есть. То есть есть риск, что нашу модель украдут, или есть риск, что в данных есть закладка. Мы решаем проигнорировать риск — и обычно это делают, когда выгода от реализации проекта велика, ущерб мал или нет ресурсов для работы с риском.
Иногда мы можем передать риск — то есть, например, мы можем застраховать свой риск, то есть заплатить за то, чтобы рисковали не мы. Или заплатить кому-то, чтобы он провел аудит данных. И тогда, если окажется, что в данных было что-то не так, ему тоже прилетит. Возможно, что наш риск уменьшится, то есть нас, допустим, не посадят и не оштрафуют, а мы сможем доказать в суде, что мы приняли необходимые меры.
Избегание риска — это то, что обычно думают как раз про работу с рисками, то есть мы можем, допустим, оплатить дополнительную повторную разметку другими разметчиками и посмотреть, насколько разметка разойдется.
А смягчение риска — это мы, допустим, видим, что есть шанс, что в результате риска нас, может быть, оштрафуют, но давайте сразу заложим какой-нибудь денежный резерв, тогда, даже если нас оштрафуют, эти деньги у нас хотя бы будут.
По ссылке пример того, как в принципе управлять рисками проекта.

Теперь про непредвзятость. В прошлый раз, когда мы затронули в лекции непредвзятость, это вызвало бурное обсуждение в форуме, ну, потому что тема такая неоднозначная. И сейчас я хотел бы поговорить про предвзятость данных, про этику, эндогенные переменные, как сейчас понимают fairness, ну и какие статьи есть на эту тему.

Прежде всего, что такое предвзятость в данных? Ну, наверное, это статистические закономерности в данных, на которые мы не должны полагаться. Или, как мы обсуждали в телеграмм-канале, это законодательно запрещенные data leaks. Вообще в данных часто встречаются закономерности, на которые полагаться нельзя. Некоторые из этих закономерностей еще и неэтичны, то есть дискриминируют какую-то социальную группу.

Что такое этичный? У людей неэтичное поведение — это переход на личности, который создает конфликтную атмосферу и напряженность. И первоначально, как в Википедии нас учат, смыслом слова этос, этика, было совместное жилище и правила — то есть, грубо говоря, правила совместного проживания, позволяющие обществу не распаться, сплачивающие его и скругляющие углы.

У компьютеров нет этики, у них нет воли, у них нет желания, они не мстят, не ломают, не оскорбляют нас, они не совершают поступков. И модель машинного обучения этична настолько же, насколько может быть этична книга. То есть, книга может быть неэтична, но дело не в книге, дело в авторе книги и в социальном контексте, в котором эта книга была написана и прочитана.
Ну и настоящая проблема машинного обучения не в этике, а в плохой работе с псевдозакономерностями и с данными. И неэтичные модели включают те псевдозакономерности, которые мешают людям. Надо заметить, что люди могут простить такие вещи друг другу, но ML-моделям они это не простят.
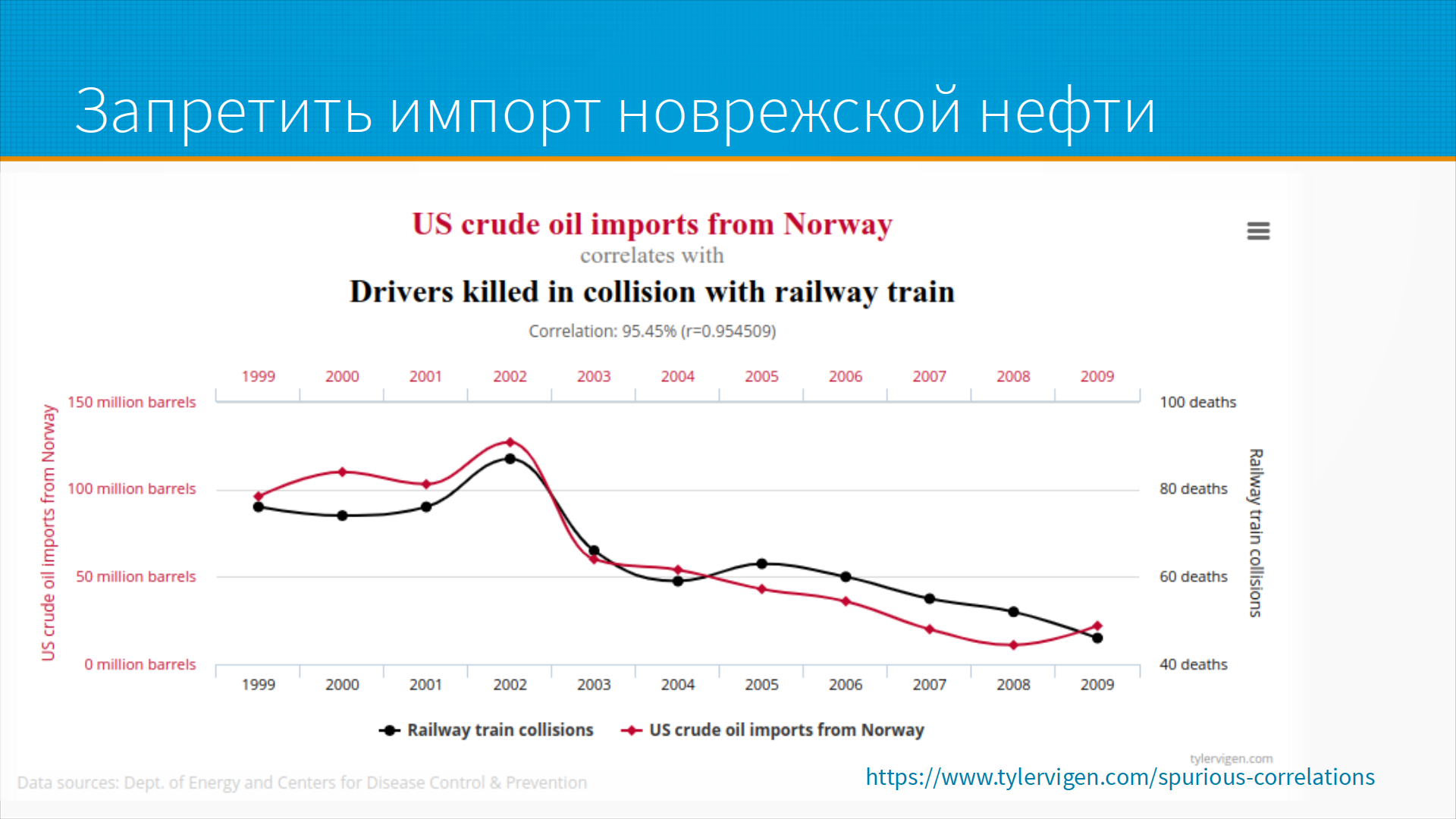
Что такое псевдозакономерность? Есть хороший сайт и книга Spiritous Correlations, то есть странные корреляции, где собраны вещи, которые совпали совершенно случайно, но коэффициент корреляции очень высок. Например, на этом графике мы видим импорт сырой нефти из Норвегии и количество автомобилей, сбитых на железнодорожном переезде поездом. И видно, что чем меньше мы покупаем норвежской нефти, тем меньше людей гибнет на железнодорожных переездах. Чем больше покупаем, тем больше. Надо ли на этом основании запретить импорт норвежской нефти? Ну, наверное, нет. Эти вещи просто так случайно совпали. И вот если эта вещь касается норвежской нефти, то все посмеются и отправят вас переделывать модель. А если она касается расы или пола, то на вас подадут в суд, линчуют вас и выпотрошат. Так работает общество.

А как формулировали раньше? Есть у нас экзогенные переменные. Это переменные, не скоррелированные с ошибкой. Это в до-ML времена так формулировали. Эконометристы, кстати, до сих пор так формулируют. Есть эндогенные переменные — это переменные, скоррелированные с ошибкой. И одна из причин эндогенности — например, пропущена какая-то существенная переменная. То есть, например, мы такие смотрим, что чем темнее кожа у человека, тем больше он, допустим, торгует наркотиками. А дело тут на самом деле не в цвете кожи, дело тут в среднем доходе в сообществах. То есть, группы людей с низким доходом чаще торгуют наркотиками. Группы людей с высоким доходом — у них деньги есть и так. Этим опасным бизнесом они занимаются меньше или по-другому.
Бывают еще ошибки измерения регрессоров, самоотбор — это то, что называют selection bias. Это когда у нас нерепрезентативная выборка, или, например, у нас есть разная выборка до лечения и после лечения. То есть, например, мы сравниваем людей, которые получали лечение — среди стариков, а людей, которые не получали лечение — сравниваем среди молодых. И видим, что люди, получавшие лечение, умирают чаще. Но тут дело не в лечении, это просто мы запутались немножко в зависимостях. Плюс есть некоторые одновременные вещи, или лаги. То есть, некоторые вещи просто происходят одновременно, при этом они не связаны.
И есть мнение, что все причины эндогенности, кроме первой, это следствие того, что пропущена какая-то существенная переменная. В статье Питера Эббеса есть введение в инструментальные переменные и эндогенность от эконометристов. Там написано хорошо, лучше не скажешь. Вот то, что сейчас у нас называют data leak, всяким нарушением fairness — это, по сути, просто эндогенные переменные.

Как формулируют fairness сейчас? Что fairness в машинном обучении? Им называют разные попытки скорректировать алгоритмическую предвзятость, bias, при автоматическом применении принятия решений моделями машинного обучения. Решения, сделанные и принятые компьютерами, могут расценены как нечестные, если они опираются на так называемые чувствительные переменные. А примеры этих чувствительных переменных — это гендер, или пол по-русски, этническая принадлежность, сексуальная ориентация, инвалидность и так далее и тому подобное. И как нас учит википедия, как и все этические концепции, в этом всем легко запутаться, оно все очень противоречит самому себе.

Итого: у общества есть больные темы, которые оно просит не трогать. И если ваша модель будет полагаться на псевдозакономерности, связанные с этими темами, то общество к вам придет и скажет вам свое фу.
Если закономерности хорошие, то их можно использовать. Например, расу, пол и возраст в медицинских моделях используют. Раса влияет на чувствительность к обезболивающим, возраст влияет на переносимость, чувствительность к лекарствам, пол вообще влияет на половину болезней. И использовать их в медицинских целях нормально.
Плохо, если такие признаки увеличивают ошибку на подвыборке. И в принципе один из способов формулировать fairness — это обеспечивать одинаковый true positive rate между группами. То есть, например, наша модель одинаково часто ошибается для мужчин и для женщин, или для чернокожих людей, для белокожих людей, для азиатов, для европейцев и так далее и тому подобное.

Для этого хорошо бы проверять ошибки на подвыборке. И в Microsoft Responsible AI Toolbox, опенсоурсном инструменте, есть хороший дашборд для проверки ошибок на подвыборке. То есть, вы можете определить какую-то подвыборку, все самые частые, так называемые, чувствительные переменные туда уже включены, и увидеть как там все устроено.
{kind=link}

По инструментам. Во-первых, это конечно Responsible AI Toolbox и его fairness dashboard. Responsible AI Toolbox — это прекрасный инструмент для анализа моделей, это часть систем, которые сама Microsoft использует в своих облачных сервисах для интерпретируемости.
Инструмент What-if Tool позволяет сравнивать ответы моделей в разных условиях.
FairLearn — это библиотека как раз для проверки на предвзятость, и Responsible AI Toolbox использует именно ее.
ML-fairness-gym это интересный симулятор, который позволяет смоделировать, как на общество влияют те или иные предвзятости в ML моделях.
Дальше прекрасное выступление на NIPS про проблемы в принципе с bias в машинном обучении.
И Cost of Fairness in AI: Evidence for E-Commerce — это грустная история про то, как люди пытались обеспечить fairness, но получилось, что чем больше fairness, тем меньше денег. Смысл тут очень простой — ищите экзогенные переменные, или общество заставит вас платить налог на fairness.

Дополнительные материалы: