
- 28.03.2023
- 08.02.2025
- выступления
- #NLP
На канале DS Talks разбирали статью GPTs are GPTs. An Early Look at the Labor Market Impact Potential of Large Language Models.
Слайды: gpts_are_gpts.pdf
Текстовая расшифровка, сделана нейронной сетью, еще не вычитана:
Меня зовут Дмитрий Колодезев, это разбор статьи о том как языковые модели повлияют на рынок труда. Почему вообще эта статья интересна, почему ее стоит читать?

Во-первых, она вышла буквально 20-го марта, а ее уже процитировали и разобрали везде, только мы ее не разобрали. Financial Times буквально полчаса назад выпустила статью с криком «А, все пропало, роботы забирают нашу работу и 80% людей будут затронуты потерей работы, 300 миллионов человек потеряют работу». То есть буквально заголовок: «Generative AI set to affect 300 million jobs across major economies». В OpenAI есть отдел, который занимается оценкой влияния больших языковых моделей на экономику. И как раз Тина и Сэм работают в этом отделе. Про Памилу я не в курсе, а Дэниел Рок, такой веселый парень внизу, он из Penn University, он у них самый настоящий экономист. И что они оценили? Тут эта статья целиком художественное произведение по методологии, по тому, как она подается и по хайпу везде, где это можно и по времени выхода. Но тем не менее она интересная. Тут в абстракте буквально написано, что мы выяснили, что примерно 80% рабочей силы, как минимум 10% их задач будут затронуты внедрением ГПТ и как минимум 19% будут затронуты этим влиянием ГПТ как минимум наполовину. То же самое можно было бы переформулировать по-другому, что не меньше 20% вообще никак не заметят и для большинства влияние будет не столь сильное. То есть это та же самая информация, сказанная просто по-другому, но так гораздо хайповее. И еще они обращают внимание, что достанется не только тем индустриям, в которых продуктивность вырастет, но и всем остальным. И вот, собственно, поехали.

О чем они говорят в заголовке? Во-первых, есть генеративные предтренинг-трансформеры. Это то, что мы обычно думаем, когда говорим ГПТ. И во-вторых, есть так называемые технологии общего назначения. В качестве технологии общего назначения они приводят печатный станок, паровые двигатели. В этот же ряд они ставят и чат ГПТ и большие языковые модели. Они, правда, оговариваются, что скорее любая ML-технология может рассматриваться как General Purpose Technologies. Но почему они считают, что ГПТ это модель общего назначения? Технология общего назначения отличает, во-первых, широкое проникновение в экономику, во-вторых, постоянное улучшение. То есть они, раз попав, там остаются, прорастают корешками везде и дорабатываются. И вокруг них возникают дополняющие их инновации. По всем признакам вроде бы как языковые модели под это определение попадают.

Как выполнялся анализ, результатом которого явилась вся статья? Во-первых, брались все виды деятельности, все работы Occupations из справочника видов деятельности, где представлены в основном те виды деятельности, за которые платит американская Родина. То есть все госслужащие, ну и кто повезет из самозанятых. Затем мы посмотрим, какие у этих видов деятельности задачи. То есть, например, что делает секретаршусь, что сделает компьютер-сайенс-инженер и так далее и тому подобное. И посмотрим, по какой части этих задач мы можем снизить трудозатраты как минимум вдвое. А как мы будем это оценивать? Мы спросим людей. Причем мы не скажем, сколько людей мы спросим, каких людей. То есть, если бы это было нормальное эконометрическое исследование, нам бы сказали, что вот смотрите, мы опросили домокозяек, бизнесменов и, скажем, фермеров. Но тут они отдали в краудсорсинговую разметку и поэтому нам не говорят ничего об этих людях, даже сколько их. Как и принято поступать в мышеленке. Затем они те же самые вопросы, то есть, удастся ли у этой профессии уменьшить трудозатраты вдвое, задали чат GPT. Чат GPT, она, понятно, отвечает то, что ей в подводке запихали. Поэтому подводки они попробовали две разных, одна сработала лучше, ее в публикацию и добавили, а вторую они не раскрывают. Затем они считают пороги воздействия, экспозия. Альфа, бета и гамма. Альфа это оптимистичные для нас людей. То есть, сколько точно будет затронуто в любом случае. Бета сколько, скорее всего, будет затронуто. А гамма сколько будет затронуто, если удастся хорошо внедрить те самые дополняющие технологии вокруг языковых моделей, которые бурно растут. Затем, когда мы посчитали эти пороги, мы можем по каждой профессии взять результаты занятости. То есть, сколько людей работают, какое у них образование, какая у них этническая группа и т.д. и т.п. из Bureau of Labor Statistics. И мы можем построить регрессию на этой демографии и сказать, вот смотрите, наш бета объясняется, например, тем, что это женщина-латина с высшим образованием. Ну и вот тут первое столкновение подходов, то есть, если разметку они собирали как настоящие машинленщики, никак не валидируя, никак не раскрывая демографии вообще, то регрессию они строят как настоящие эконометристы. То есть, без валидации ее обобщающей способности, просто без разделения на тройный тест, все сложили и посчитали коэффициенты. В принципе, это нормально для эконометрики, они так думают. Ненормально то, что мы смешиваем подходы эконометрики и машинного обучения в одной статье. Ну и после того, как мы все это сделаем, публикуемся и хайп.
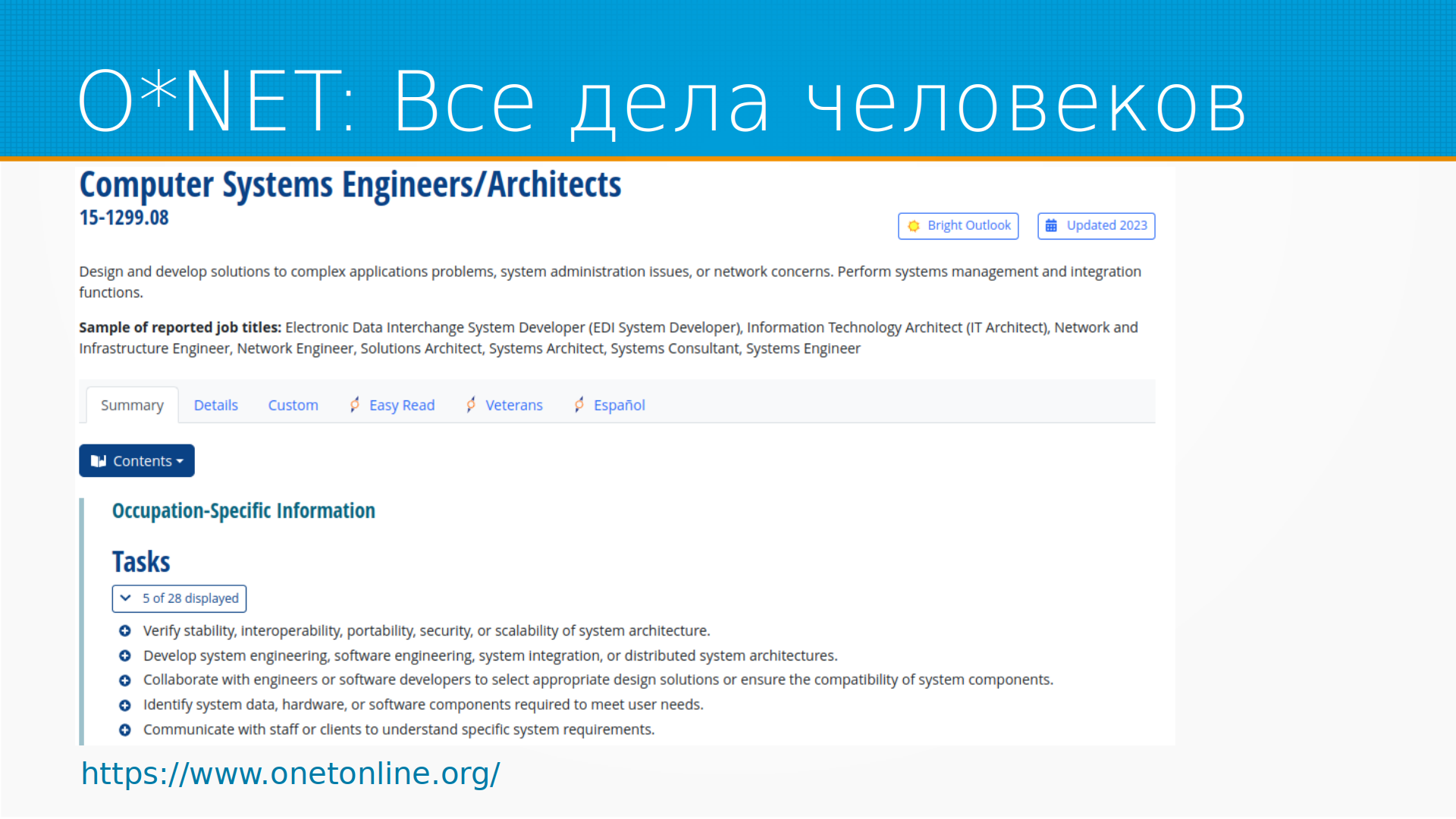
Классификатор родов занятий ОНЕТ, он, к сожалению, закрыт, по-моему, из России, туда надо через ВПН ходить, но там хорошо разбираются много видов деятельности, причем они разбираются подробно, что делают, описание работы, какие задачи входят в это описание работы, сколько людей на самом деле занято на этой работе и как меняется занятость. Сама по себе очень интересная статистика. Чем еще этот классификатор интересен? Тем, что его можно выгрузить в любой момент. Он доступен в виде csv, xls файлов, баз данных, то есть это открытые данные, и это прикольно.
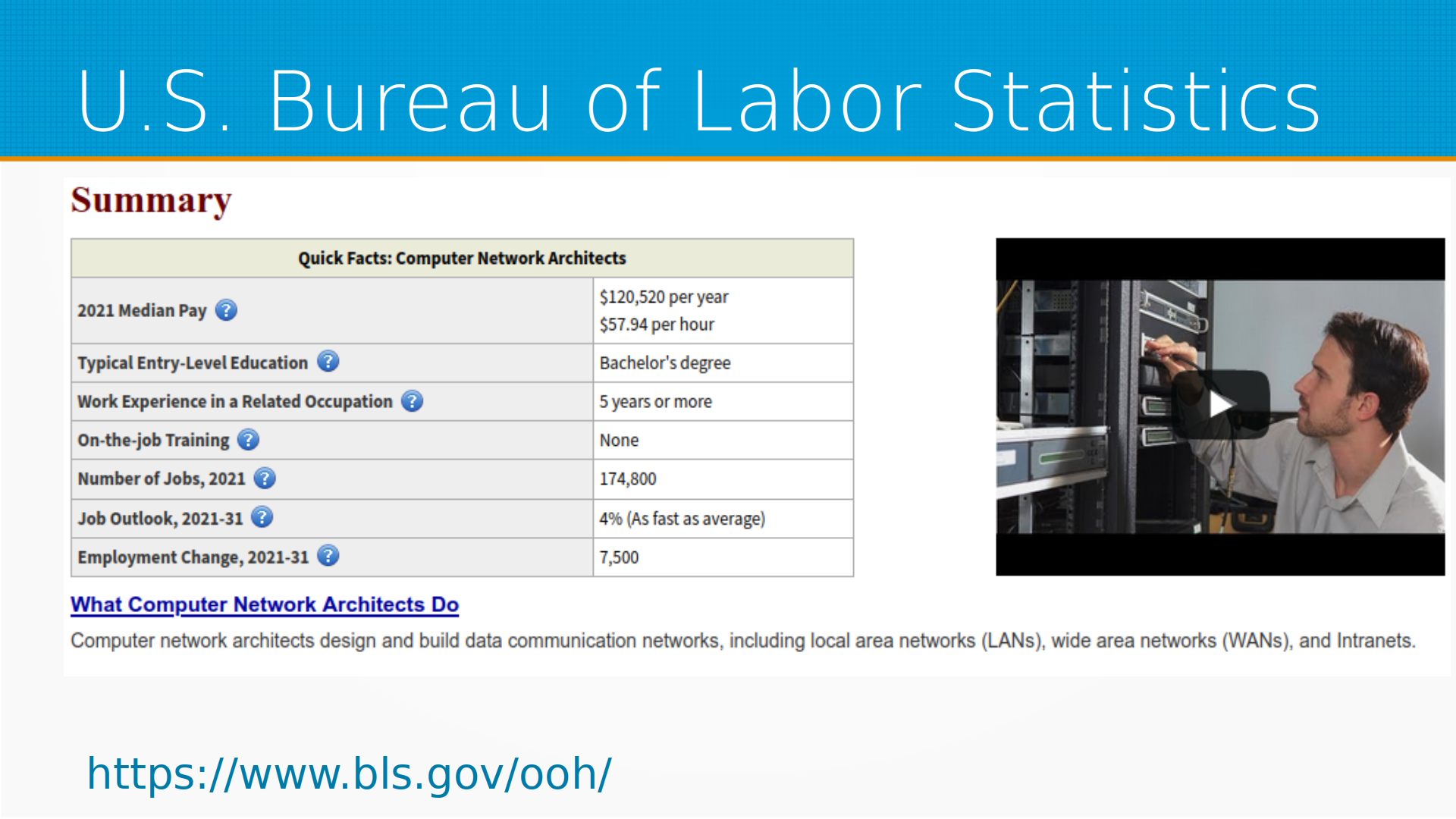
данные есть, и тут мы можем видеть, например, сколько людей у нас работает, какое у них образование, и сопоставив данные Bureau of Labor и классификатора, мы можем посмотреть, ага, если, допустим, нейронные сети научатся делать хорошие транскрипты к текстам, то у нас, скажем, 3 миллиона человек потеряют работу. U.S. Bureau of Labor Statistics, там немножко не так, но тоже
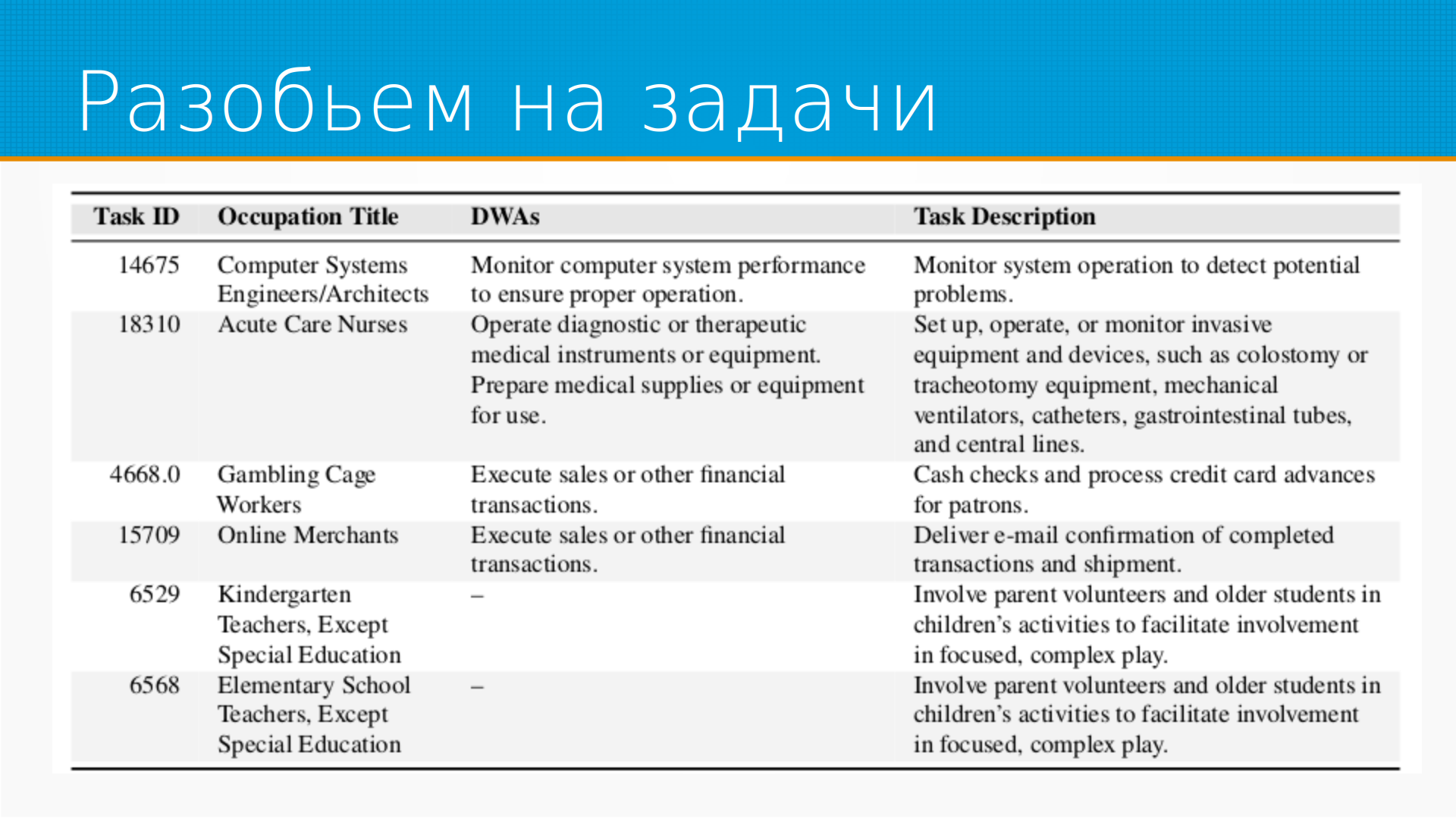
А как выглядит разбиение на задачи? Они выделили задачи, которые есть в описании видов деятельности, работ, и собрали их в такую табличку, выделив отдельно Task Description и детальное описание работ дверей.

Затем они исходили из того, что как такового человека полностью заменить языковую модель трудно, но мы можем сэкономить ему половину времени, и тогда сама по себе профессия изменится, скорее всего, до неузнаваемости. И вот они искали, где можно заменить 50%. Ну, 50% они говорят, ну, знаете, нам так понравилось, все равно надо было какой-то порог брать, 50% это нормальный порог.

А как выглядит влияние языковых моделей на работу? Вот, например, это сокращенная версия их Exposure Rubrics, но Exposure это если нет никакого или минимальное уменьшение времени, требуемого на выполнение задачи. При примерно том же самом качестве. Direct Exposure это если используя просто одну языковую модель саму по себе, или обвязку к ней, мы можем уменьшить трудозатраты вдвое хотя бы. Или E2, второй, последний вид, если нам для того, чтобы снизить трудозатраты вдвое, недостаточно языковой модели, но мы легко можем себе представить дополнительный софт, который может быть сопряжен с языковой моделью, и эта комбинация уже позволит снизить трудозатраты как минимум вдвое. Вообще они там выделяли еще третью рубрику E3. Это возможность для языковой модели выполнять простые операции, по сложности примерно как то, что умеет ResNet, то есть распознавание объектов без распознавания их взаимного положения и без точного измерения размеров, веса и т.д. В принципе они объединили E2 и E3 варианты, потому что это просто дополнительная технология, которая расширяет возможности языковой модели.

Кто оценивал от людей? Люди и роботы использовали одну и ту же подводку текстовую. Часть задач разметили сами авторы, часть профессии, для того чтобы понять как это все устроено, с какими трудностями будут сталкиваться разметчики, ну и вроде бы как они размечали самые трудные с их точки зрения задачи. А остальное оценивали разметчики OpenAI. Если помните, когда появился чат GPT, шутили, что судя по скорости ответов и их качеству, это какой-то колл-центр на Филиппинах, вот этот колл-центр на Филиппинах, и размечал как повлияет ли на работу того или иного человека, на ту или иную профессию чат GPT. Очевидно, что эти люди имеют байс какой-то в сторону чат GPT. Может быть они думают, что она всемогущая, а может быть они наоборот думают, что она тупее, чем есть на самом деле, поработав с ней достаточное количество времени. Ну и количество и демография разметчиков не раскрывается. Поэтому мы не можем ни оценить байс, ни ничего по его поводу сказать.

В команде терминаторов играли две GPT-4, то есть GPT-4 с двумя вариантами подводок. Первый вариант подводки использовался для ранней версии GPT-4, а второй для текущей. В статье они использовали только последнюю. Они говорят, что первая подводка дала похожий результат. Они приводят графики согласованности, разметки вот этих двух подводок, но саму вторую подводку не раскрывают. Тоже на самом деле любопытно почему.

Как они считали пороги? У нас есть, допустим, некоторая профессия, скажем, секретарша, и от нее требуется отвечать на звонки, вести календарь шефа, искать ему ссылки, бронировать гостиницу и варить чай. Понятно, что варить чай, наверное, языковая модель не сможет, но отвечать на звонки с некоторыми дополнительными приспособлениями сможет, бронировать гостиницу с дополнительным софтом сможет, суммаризировать статьи сможет, искать ссылки сможет. Мы смотрим, какой процент подзадач этой профессии мы можем здорово ускорить с помощью ChatGPT, и это то самое альфа. Если мы можем ускорить просто одной ChatGPT, это E1, если ChatGPT с дополнительным софтом, это E2. И вот они считали коэффициенты альфа, бета и гамма, как альфа это только E1, бета это E1 плюс половина E2, и гамма это E1 плюс E2, то есть хоть так, хоть и так ускорим. По итогам у них получились оценки степени влияния ChatGPT на разные профессии. То есть это не количество людей, которых ChatGPT на самом-то деле уволит, как я тут написал и как написал Financial Times, независимо от меня. Это именно количество подзадач, которые у этой профессии в среднем по оценке разметчиков будут ускорены как минимум вдвое.
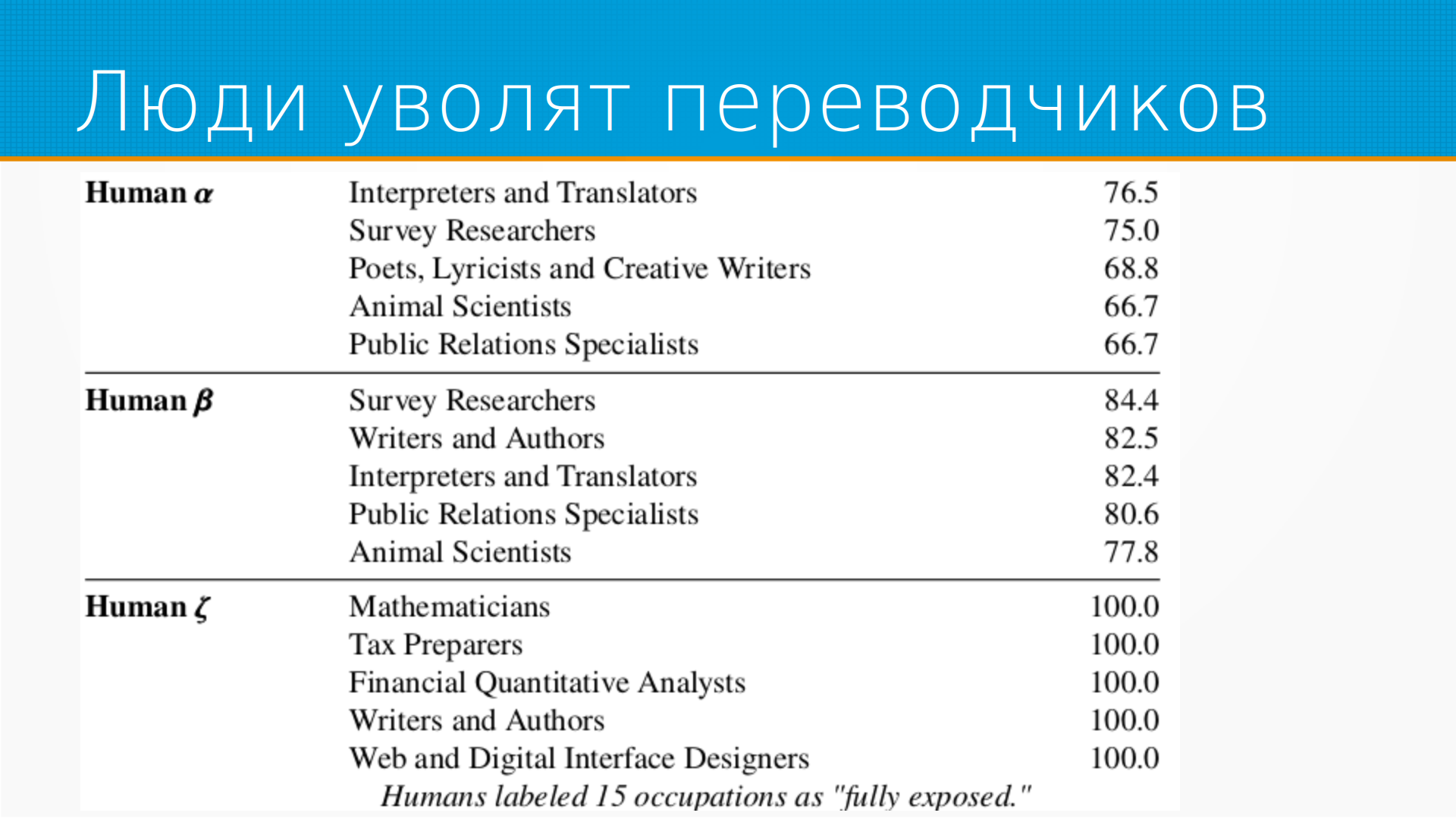
И видим, что люди говорят, что пострадают первые переводчики и интерпретаторы. Что интересно, это не бьется с реальностью, во всяком случае до сих пор, потому что хорошие технологии перевода существуют уже несколько лет, а рынок труда переводчиков только растет со страшной скоростью. Я думаю, это связано именно с США, что они выходят на внешние рынки с какими-то бизнесами, и им нужен перевод на язык потребителей. Хотя, казалось бы, Google Translate давно есть. И при пессимистичной для людей оценке полностью будут затронуты влиянием языковых моделей математики, налоговые консультанты, финансовые аналитики. И это, кстати, похоже на правду. Недавно один из плагинов к ChatGPT был это плагин к WolframAlpha. То есть вы уже можете с помощью ChatGPT решать какую-то сложную математику. Она просто все, чего не понимает, будет в альфа отправлять. И поэтому издеваться над ней, что она не умеет в логику, уже не надо. Надо просто подключить плагин к WolframAlpha, и логика у нее появится. И об этом они как раз говорят в статье, что в принципе у языковой модели образно говоря нет часов, но ей легко купить будильник.
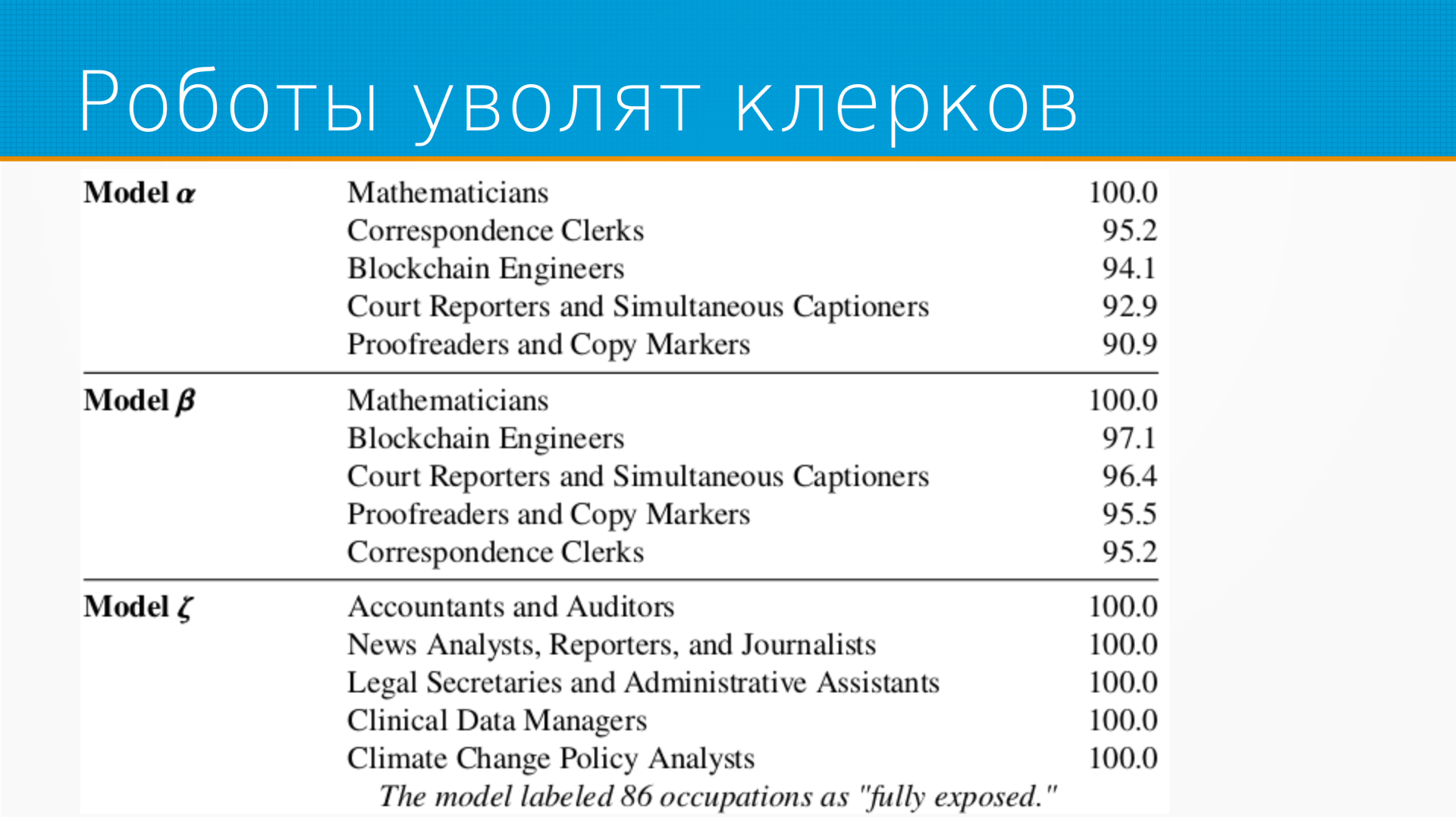
Оценку, которую дали языковые модели по степени влияния на профессию, она отличается от людей. У ChatGPT получается, что первые как раз уйдут всякого рода клерки и математики подвергнутся влиянию. Я, честно сказать, больше присоединяюсь к мнению роботов. Но тут, когда я говорю мнение роботов, на самом-то деле первая разметка людей это разметка того, как центры на Филиппинах. А вот это ответ модели на подводку, сделанную ребятами из OpenAI. То есть на самом-то деле это зеркало, которое отразило их представление. Поэтому я бы тут говорил не, что это модель людей и модель GPT, а модель обычных людей и модель ресерчеров из AI, аугментированной с помощью GPT.

Есть профессии, к которым ничего не грозится, согласно исследованию. Это сельхозрабочие, отделочники, спортсмены и все такое прочее.
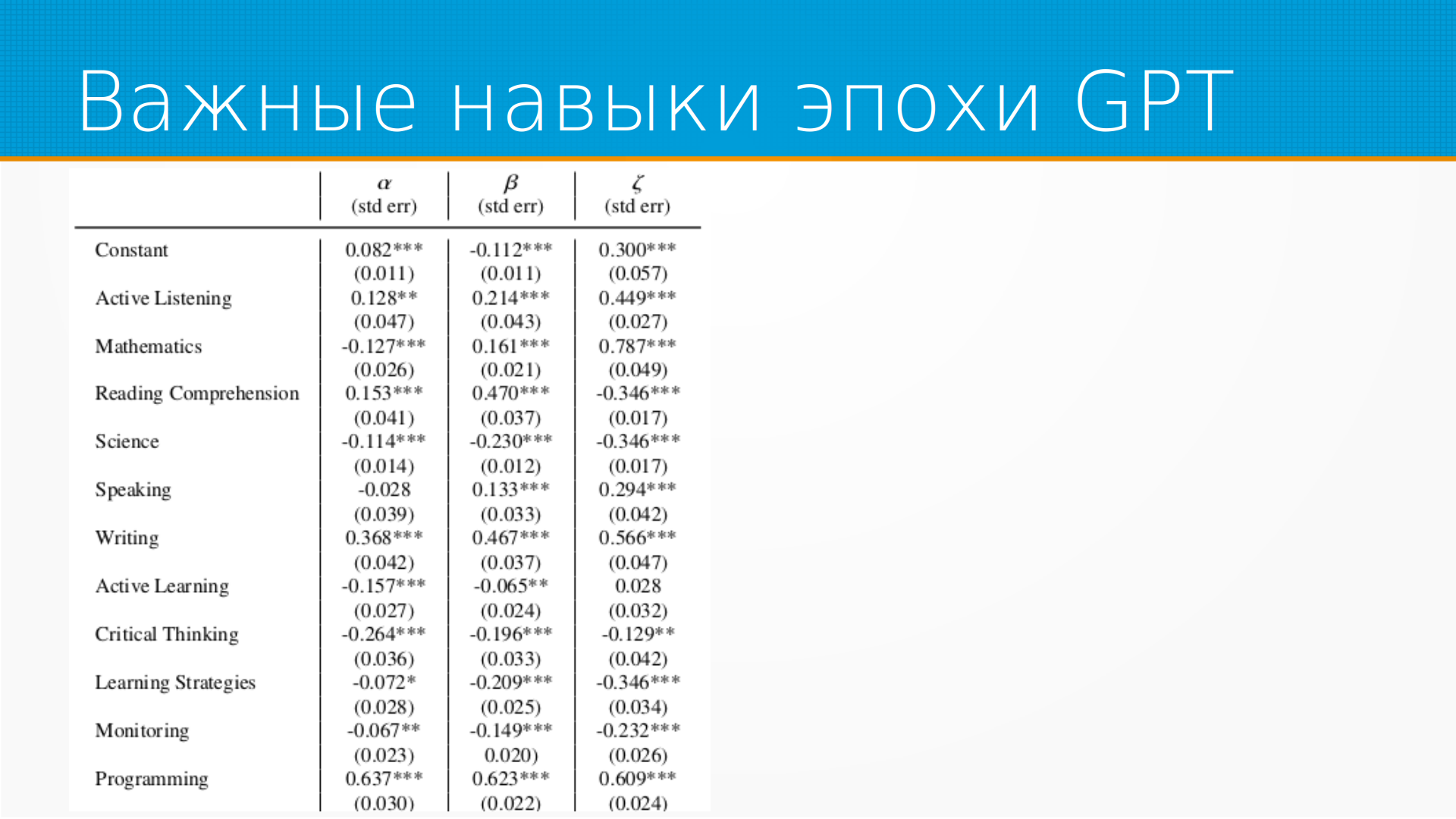
Какие навыки нужны нам для того, чтобы GPT пережить? То есть у нас они построили регрессию, и отрицательно это значит, что навык мешает влиянию GPT на нашу профессию. А положительное значение, что навык наоборот высоко подвержен влиянию GPT. Звездочки, как положено в эконометрике, это уровень статистической достоверности. И мы видим тут на самом-то деле, что с точки зрения совокупной людей и роботов, программистов заменят практически сразу. Останутся и будут востребованы навыки критического мышления, мониторинга почему-то и стратегического планирования. И я думаю, что это скорее всего баяс, привнесенный разметкой авторов статьи в подводку.
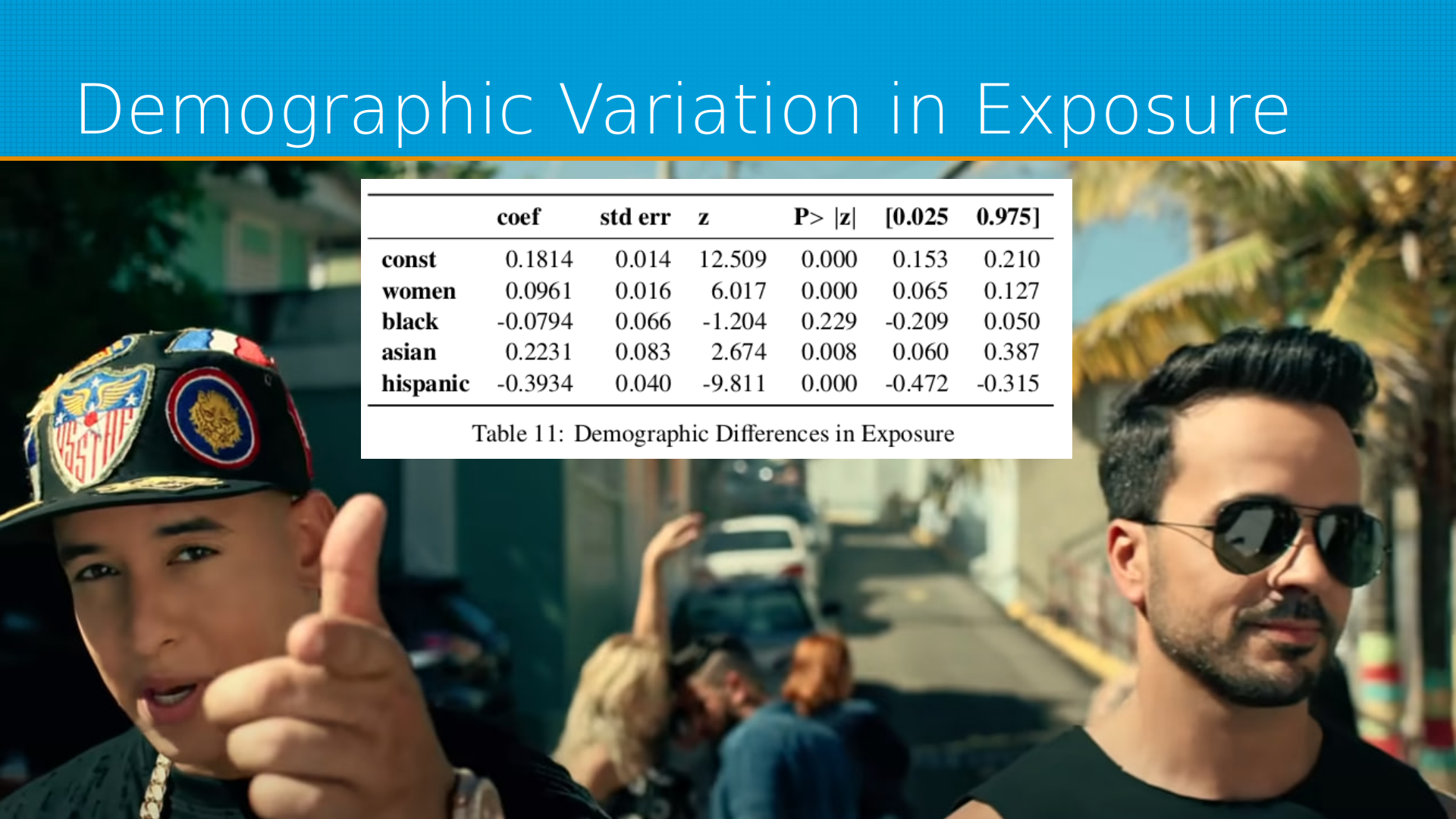
По демографии, это уже по данным Бюро труда, мы видим, что меньше всего часть GPT затронет работы, занятые мужчинами-латиносами. Наверное, потому что они в основном работают руками, то есть многие из них крутят гайки на автосервисе, строят дома и так далее. Подобная языковая модель этим заниматься не будет. Затронет работу азиатов, среди которых очень много как раз клерков и вообще белых воротничков. Ну и женщинам достанется больше, чем мужчинам.
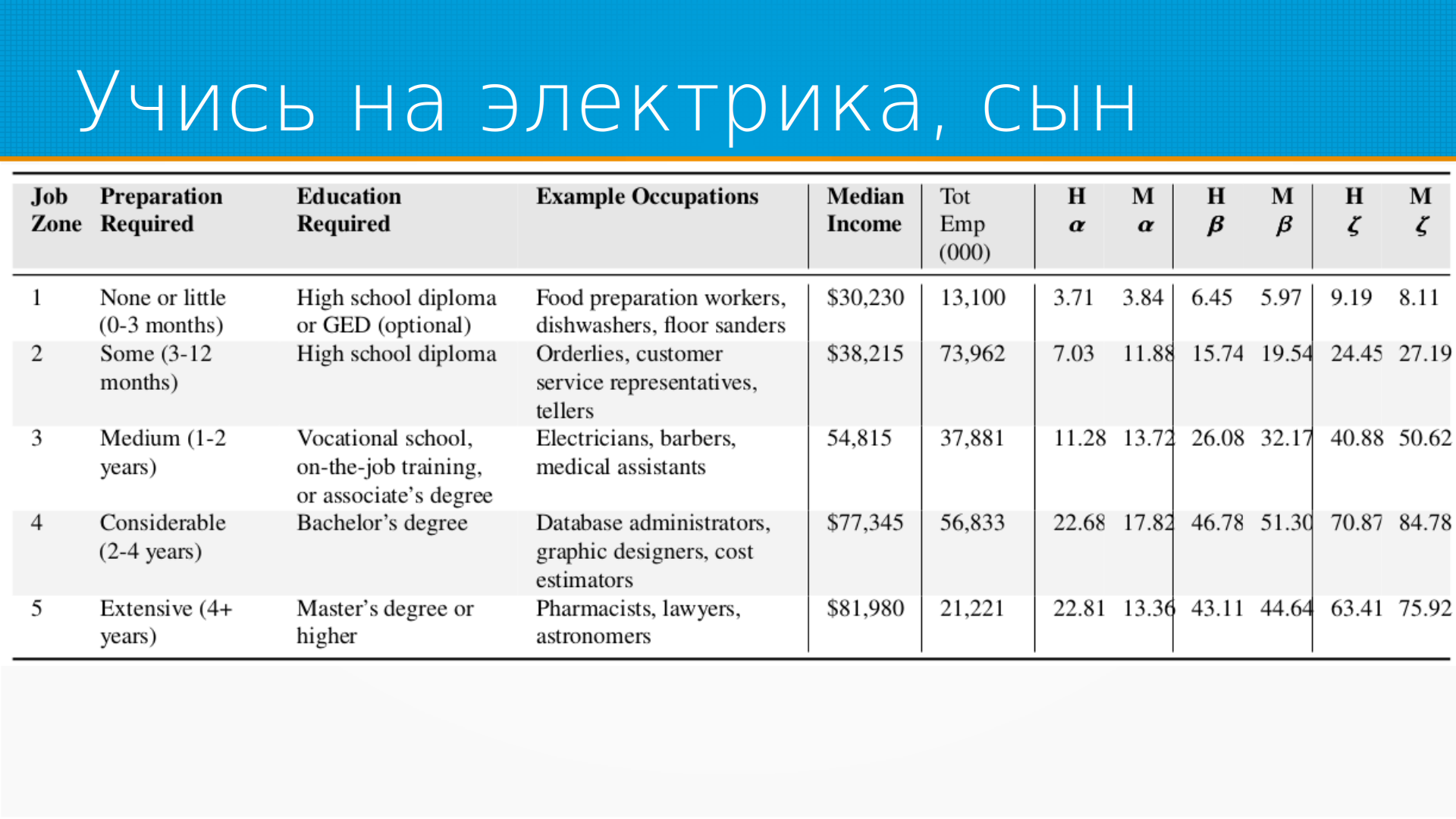
По поводу влияния уровня образования на подверженность эрозии профессии с помощью языковой модели, тут интересная статистика, что буквально с бакалавра уже получается, что влияние моделей на работу будет очень велико. То есть, если вы хотя бы бакалавр, то вам так или иначе придется жить с языковой моделью. И в принципе, наверное, стоит уже прямо сейчас учиться, использовать ее в своей деятельности, это будет только расти. Ну а если вы не хотите учиться, тогда работать с языковой моделью, тогда, наверное, имеет смысл учиться на электрике. Им тоже ничего не выражает. Кто-то же должен провода к компьютерам прокладывать.
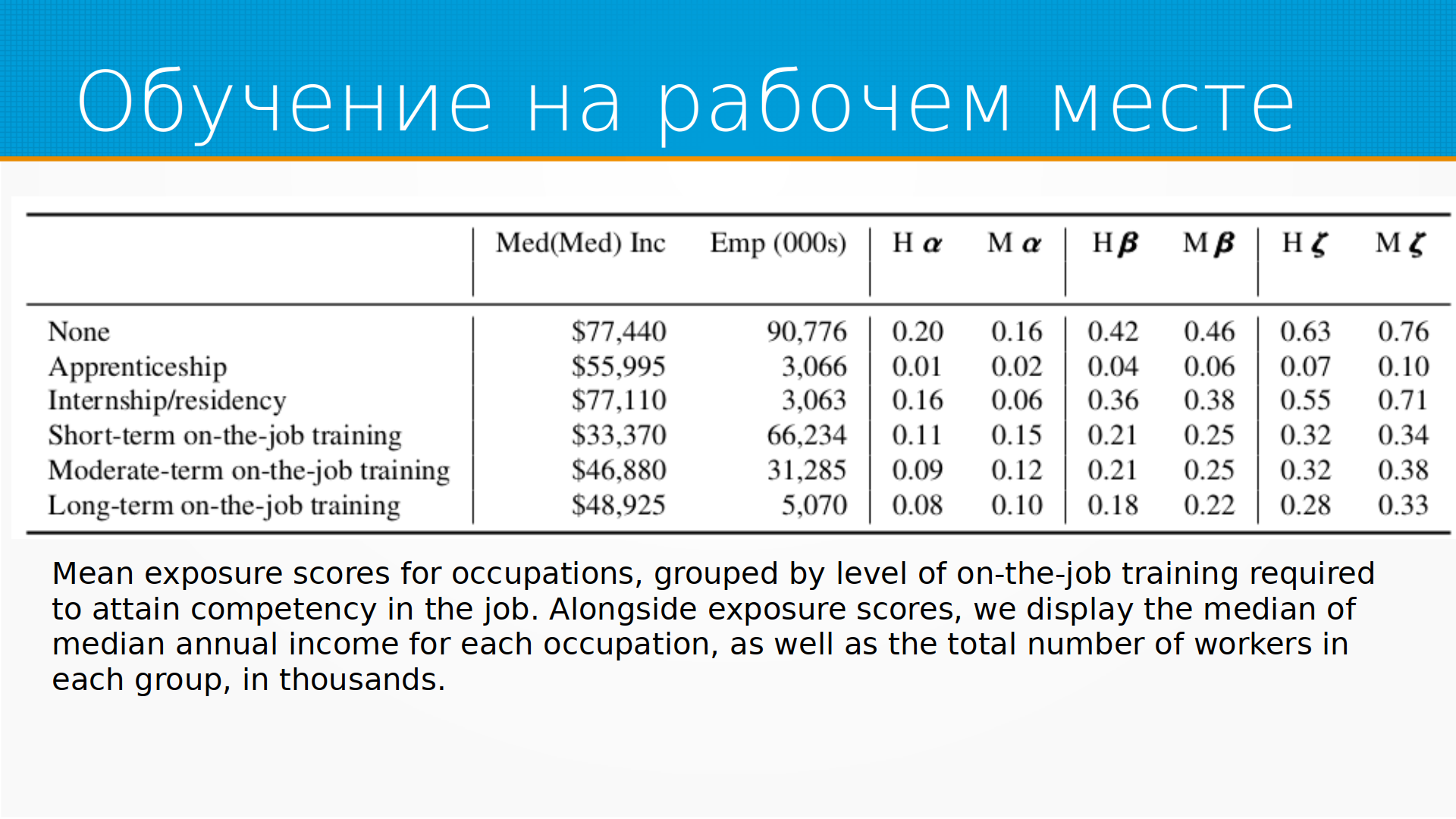
Относительно обучения на рабочем месте, тут интересный глюк статистики, что интернатура на самом-то деле пострадает от ChatGPT сильнее всего. Сильнее, чем просто кратковременное обучение на рабочем месте. Это просто нелогично. Казалось бы, что чем сильнее человеку надо адаптироваться на рабочем месте, тем быстрее его заменят роботы. А интернатура это же 3, 5, 8 лет где-то. Правда в том, что интернатура это законный способ не доплачивать врачу. Врач уже все умеет, но просто ему платят меньше, чем остальным. И значительную часть рутины, которую он делает, это работа не врача. Ее можно скинуть на языковую модель. Это такие джуны в мире медицины. И тут тоже интересный момент, что вот эта зарплата, которую они оценивают, это медианы-медианы. Потому что, допустим, в интернатуре это много разных групп, которые имеют интернатуру. Много групп имеют наставничество, и они внутри каждой группы оценили медианную зарплату, а потом оценили медианную зарплату между группами. Это, в принципе, хороший подход для быстрого вычисления медианы на большом наборе данных. Даже есть такой алгоритм медиан-медиан для быстрой оценки медианы набора. Но тут проблема в том, что эти подгруппы, они же все очень разного размера, где-то отличаются на порядок. И, соответственно, в этих условиях, на мой взгляд, медианы-медианы – это просто случайное число. Очень широко разбросанное. Но это в числе других вопросов к методологии.

Как устроена была подводка? Подводка есть в самой статье, я тут ее вольно перевел на русский. Мы возьмем самую мощную языковую модель от OpenAI, существующую на момент исследования, которая способна работать с текстами до 2000 слов. Наверное, имеется в виду 8K токенов. Ее сведения устарели на год. Мы садим среднего по умениям работника делать обычные для него задачи.

И мы просим языковую модель отнести какую-то задачу, которую упомянуто сразу после подводки, к одной из ниже перечисленных рубрик.

Рубрика либо DirectExpose. Пометьте, задача как E1, если прямой доступ к языковой модели может уменьшить трудозатраты как минимум наполовину. И дальше дан список явным образом задач, которые относятся к обработке документов. И вот это первый источник байеса в оценке влияния языковой модели на рынке труда, потому что меняя вот этот список, мы просто будем скорее всего менять получившийся результат. Но это, кстати, тоже не точно. Это можно проверить, поскольку доступ к chatGPT есть, можно посмотреть, насколько эта работа с этим списком влияет.

Пометьте, задача как E2, если доступ к LLM сам по себе не уменьшает, но есть дополнительный софт, который его дополняет. И тут тоже список для иллюстрации.

E3, это если у вас есть система обработки изображений, которая может использоваться языковой моделью. Она может читать текст, сканировать изображения, создавать или детектировать простые изображения по инструкции. При этом не понимает отношения между объектами.

Если ни одно из вышеперечисленных не попадает, помечайте как E0, или если сомневаетесь, помечайте как E0. Помечайте как E0 задачи, требующие большого количества взаимодействий между людьми, точной оценки, требуют рук или ног, или коррекции воды для принятия финального решения. Или уже хорошо решаемое без LLM. Но вот тут тоже вопросы у меня. Некоторые из задач, которые определенно попадают в эту рубрику, они, по-моему, вполне могут быть ускорены с помощью языковой модели, например, требующей большого количества взаимодействий между людьми.

Пример такого анализа – это, к примеру, контролер. То есть, инспектор, тестер, сортировщик, семплер. Его задача – это корректировать или чинить processing equipment, корректировать дефекты, найденные во время инспекции. То есть, он ходит вдоль линии, смотрит, ага, что-то у нас тут забарахлило, давай-ка я гаечку подкручу. Или давай-ка я грязь отсюда счищу с датчики. Ну и она оценивается как E0, потому что у модели нет никакой физичности, она не может ходить, она не может трогать руками. Более половины задачи – это настройка, очистка, ремонт, требуя рук или какого-нибудь соответствующего способа влиять на окружающую действительность.

Пример – computer science researcher. Применять теоретическую экспертизу и инновации, чтобы создавать или применять новые технологии. Тут E1, потому что модель может выучить некоторую теоретическую экспертизу во время обучения и применять эти принципы при генерации текста и помогать. Я, в общем-то, согласен с ним.

Пример администратора – это E2. То есть, например, если нам нужно бронировать столики в ресторане, то сама по себе языковая модель не особенно бронирует столики в ресторане. Но есть куча сайтов, тот же самый Rezi американский, которые позволяют бронировать столики в ресторане и вполне можно себе представить интерфейс для языковой модели, который возьмет и начнет это делать.

Сами авторы говорят, что их исследование имеет кучу фундаментальных ограничений. И одно из них – это то, что сама по себе разметка субъективна. То есть, мы никак не проверяем нашу разметку. Мы не валидируем, насколько разметка согласована между собой. Это я в самом начале говорил. Мы просто собрали у людей какую-то разметку, и люди так думают. То есть, это не то, как будет устроено будущее. Это то будущее, у которого боятся люди. В исследовании использовались люди, которые много работали с GPT-моделями, и поэтому они, в принципе, понимают, чего ждать от GPT-моделей. Но, с другой стороны, diversity там рядом не лежало. То есть, они просто могут знать мир с какой-то одной конкретной стороны. Ну и то, что там, они говорят, 80%, они говорят, в принципе, это как проценты интерпретируют некорректно. Мы бы предложили рассматривать это как 0,6 – это больше, чем 0,1. Ну, не в 6 раз. Это, кстати, противоречит тому, что они написали в абстракте. Вот такую оговорку они делают.
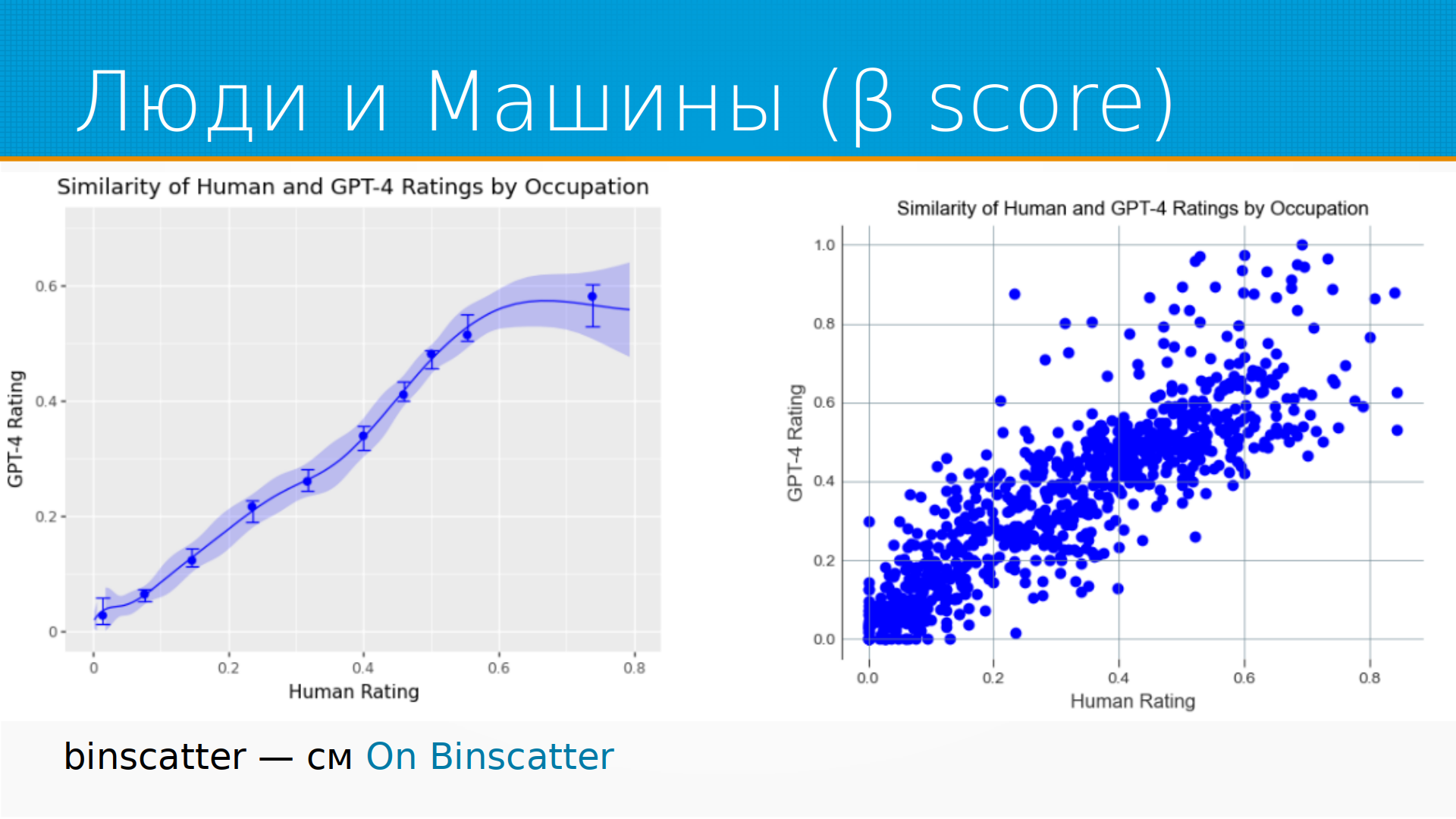
А как соотносится разметка людей и машин? Тут тоже интересно. Справа – это скаттерплот, каждая точка – это профессии, и средний рейтинг людей, и просто рейтинг машин. Наверное, рейтинг машин они не усредняли. То есть, какое влияние на эту профессию окажет языковая модель. И слева у нас есть такой интересный график – binscatter. Но не просто binscatter, а особенный binscatter. Я их раньше не встречал, и вот ссылочку приложил. Действительно, клевый способ суммаризировать график перегруженный. И мне кажется, что он в интерпретируемости модели машинного обучения зайдет, но это я еще не попробовал буквально. Руки не дошли. И на этих графиках мы видим, что на самом-то деле модели языковые консервативнее, чем люди. То есть, начиная примерно с оценки влияния 0.6, модели говорят, ну нет, дальше уже не будет влиять, а люди говорят, нет, все еще страшно, нашу работу берут роботы.
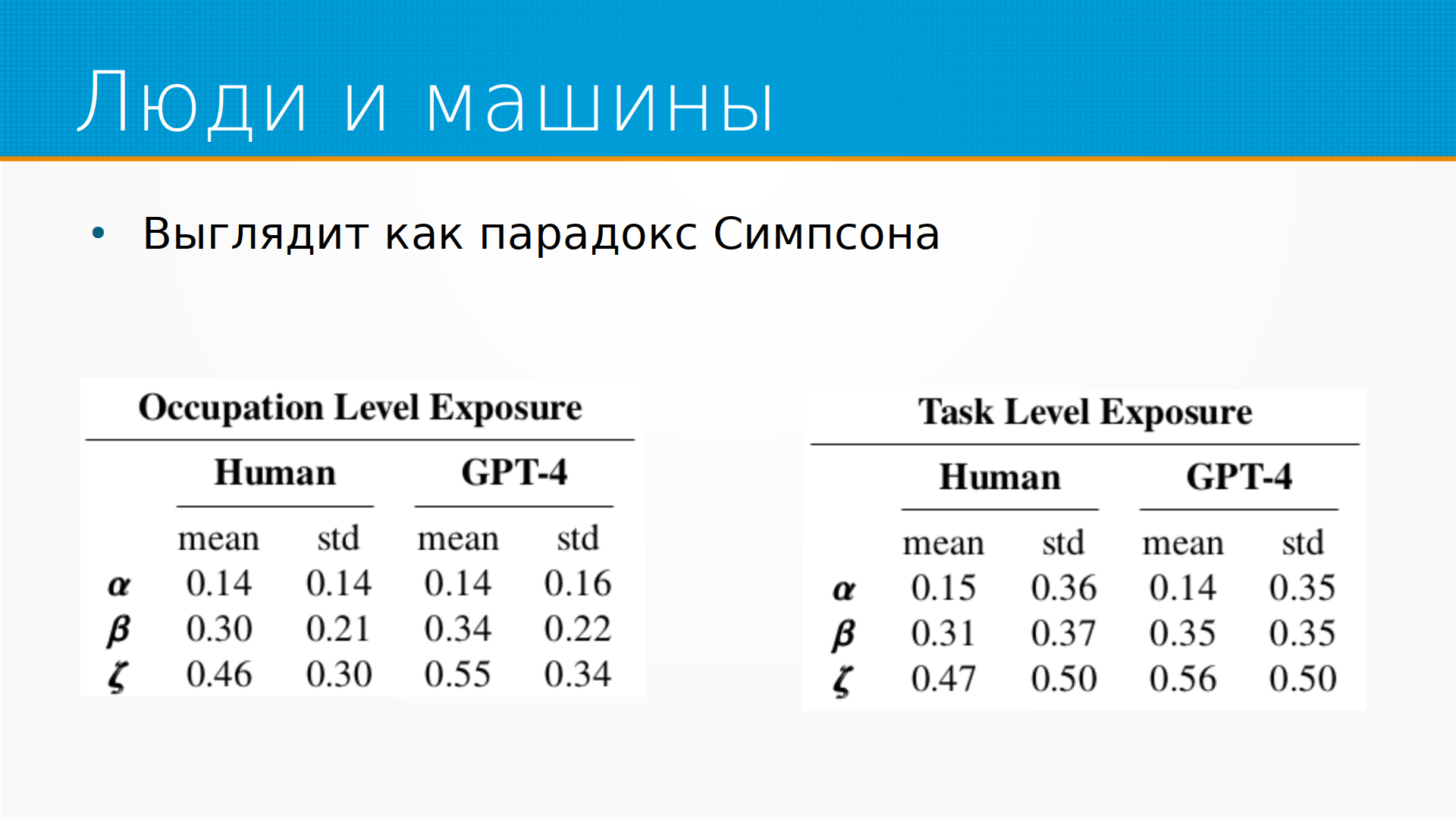
Помимо таких точечных оценок, они посчитали еще и средние. И в среднем картина выглядит ровно наоборот. То есть, здесь использовали бета-оценку, то есть, так сказать, наиболее вероятную оценку, Е1 плюс половина Е2. И мы видим, что на каждом из уровней практически у нас ГПТ-4 оценивало влияние на профессии сильнее, чем люди. То есть, Occupation Level Exposure у людей 0.3, у ГПТ-4 0.34, Task Level Exposure, то есть, по задачам, у людей 0.31, у ГПТ-4 0.35. То есть, получается, что тут люди консервативнее, а на общем графике у нас машины консервативнее. Для меня выглядит как парадокс Симпсона, когда в разных подвыборках у нас есть разные тренды.

И что в этой статье интересного? Есть хороший классификатор видов деятельности. Правда, я о нем раньше не знал, это прикольно, его можно использовать для разной аналитики. Нейронки консервативнее людей в оценке, ну или нет? Чем больше зарплата, тем быстрее нас заменят, критическое мышление будет цениться. Интересный момент, что для предсказания доли от 0 до 1 они использовали линейную регрессию. В принципе, с эконометристами такое бывает, но вообще, так говоря, тут бы лучше подошел был у Грек. И Луис Фонди своими песнями он в безопасности, потому что, во-первых, он певец, а во-вторых, он латинос, все будет у него хорошо.

Вот, а слайды тут, вопросы можно задавать. Я сейчас ссылку на слайды скину в чат.
У меня все? Ага. Спасибо, вопрос хороший, но тут надо понимать, что на нас буквально обвалился потолок. То есть, буквально 4 месяца назад никакого чат-GPT у публики не было, а сейчас мы уже говорим, что она отберет у нас работу.
Я думаю, что немножко по хайпу ему выяснится, что все не так страшно, во-первых, а во-вторых, действительно, это технологии общего назначения, они пойдут в работу, и у нас не исчезнут, как таковые математики, клерки и сисадмины, просто у них появится новый удобный инструмент, и они смогут больше времени выделять чему-то.
Конечно, возникнет много новых профессий, скорее всего. Всегда, когда появляется технология, она убирает каких-то людей с работы, то есть, например, у нас исчезают кучеры, и у нас возникают водители такси.
Но даже по смыслу это не очень большая разница. Появятся наверняка какие-нибудь промпрофессиональные инженеры, но их будет немного. Для большинства людей выйдет методичка, как использовать часть GPT при работе в Excel. Люди ее прочитают и начнут по-прежнему делать свои Excel-таблицы с помощью части GPT. Это в краткосрочном перспективе, то есть, скажем, 3-5 лет.
В более долгосрочной перспективе, скорее всего, ну если у нас вообще будет долгосрочная перспектива, потому что времена такие мутные, кто его знает. В более долгосрочной перспективе, скорее всего, произойдет точно так же, как в свое время программное обеспечение пожрал мир. ML, в значительной степени, сейчас пожирает программное обеспечение.
Для многих случаев, когда приходилось писать отдельную программу, я не про ML-модель, я именно про какую-то интерфейсную программу, они будут не нужны, но это опять же затронет не так много людей.
Чтобы было понятно, с ресерчеров 300 тысяч, а кассиров 3,5 миллиона в США. Рынок труда в нашей маленькой когорте, связанной с компьютерами, встает с ног на голову, а для остального мира мало что меняется. Поэтому я думаю, что в значительной степени эти атласы профессий никуда не денутся, люди по-прежнему будут сеять хлеб, считать налоги, но какие-то небольшие островки чудесных профессий появятся.
Смотрите какая штука. Сейчас существует два варианта как чат GPT. Два варианта как все эти вещи пойдут впрод. Первый, они пойдут впрод как инфраструктура. Большинство приложений, которыми мы пользуемся на компьютере используют какую-то базу данных, но мы часто даже их название не знаем. И из этих баз данных происходят утечки безопасности, и это никак не влияет на нас конкретных пользователей. Мы все равно пользуемся базовыми данными. Это хлопоты тех людей, которые их обслуживают. Допустим, из Сбера произошла утечка, мы же не перестали пользоваться Сбером.
Другая история, и это первый путь, которым может пойти тот же самый OpenAI, и это путь, которым, скорее всего, пойдут Яндекс и Сбер. У меня нет про них информации, но есть предположение, что не позже чем к концу лета API аналогичный чат GPT появится и в Яндекс.Облаке, и в Сбер.Клауде, и его можно будет встраивать в свои приложения. И тут у нас будет бурный взрыв приложений с чат GPT, как сейчас бурный взрыв телеграм-ботов с чат GPT. Его вставят для начала в каждый утюг, потом оно останется только там, где оно имеет экономический смысл.
Я думаю, что не остановят. Другая проблема. Есть две проблемы. Во-первых, в языковых моделях из них можно вытаскивать данные, на которых они учились. И если смотреть не чат GPT, а поменьше модель стенфордскую Альпаку, там прямо кусками разметка, на которой учились, выпадает в предиктах. То есть, если задать генерацию текста чуть подальше, она отвечает на ваш вопрос, а потом начинает куски разметки прямо выдавать. Это первое. А второе, в принципе, сейчас идет тенденция, чтобы зарегулировать искусственный интеллект. Из разных соображений. Чтобы создать преимущество одним странам, отобрать его у других, как с ядерным оружием. Чтобы дать возможность выбранным хорошим зарабатывать деньги, а выбранным плохим не зарабатывать деньги. Чтобы ограничить спамеров. Тут куча этических бизнес и политических проблем. США пытаются не дать Китаю стать ведущей державой. Китай пытается отвоевать свое место под солнцем. Мы сидим и смотрим, где же мы будем брать вычтительные мощности. Там все очень сложно, и я думаю, что утечка данных никакая этого не остановит. Но будет много интересных проблем. Продолжение следует.
Я вас понял. Смотрите. Я думаю, что вы преуменьшаете даже проблему. Потому что нейросети, их не просто дорого, их невозможно обучать большинству стран. Большинство стран физически не смогут их обучить. И по состоянию на сегодняшний день, количество организаций, которые способны учить и предоставлять доступ к таким моделям, их можно пересчитать на пальцы двух рук в мире. Я думаю, что тем не менее, у всех будет через GPT, прежде всего, использоваться, в ближайшие перспективы, потому что далеко сейчас смотреть непонятно. Это как погоду предсказывает на год вперед. Нельзя сказать, пойдет дождь в какой-то день или нет, слишком велика неопределенность. Что она хорошо зайдет именно как системный клей. То есть у вас есть какие-то приложения, которые умеют делать частные задачи, и вы говорите голосом, а она их как в свое время появился, вот когда в Excel появился Visual Basic for Application, из него стало возможным вызвать это, вызвать то, и появилась куча VBA приложений, которые мог слепить любой у себя на компьютере прямо в Excel, и прямо сделать такую сложную систему из ничего. То есть системный клей. И вот я думаю, что будущая, ближайшая часть GPT это системный клей. То есть она будет оркестрировать вызовы API.
И уже после выхода вот этой статьи были анонсированы плагины, то есть вы можете на свой веб-сайт, например, добавить специальным образом сформатированный JSON, который описывает, как ваш сайт дергать. И в чат GPT появится такой навык. То есть пока это ограниченный доступ к этим штукам, но вот так это будет работать. И получается, что мы все сможем лепить на коленки с помощью этого системного клея маленькие приложения и пользоваться ими как-то, может быть, даже наживаться.
Так, вот у Никиты вопрос. Не очень понятно, кого подразумевают под математиками, тех, кто теоремы доказывает или расчеты в Маткаде, или подобного дела. Тут это же OpenAI. Они не выкладывают ничего. То есть если бы это был какой-нибудь саратовский университет, они бы выложили результаты разметки. И можно было бы понять, кого они подразумевают под математиками. А тут, ну, математика.
Ну, как-то Вы прямо так широко мухнули с вопросом. Можно отдельную лекцию. Опять же, сегодня, по-моему, или вчера, вышла статья, в которой описывается, что часть G5 в среднем работает лучше, чем средний разметчик с Mechanical Turk амазоновский. То есть уровень разметчика вполне достигла, и непонятно, как ее оценивать. Это вообще проблема оценки. Она, кстати, на картиночных моделях первая всплыла, которые первые Human Level достигли, что когда у нас модель работает с качеством, сравнимым как с человеком, не очень понятно, как ее оценивать. То есть получается уже слово против слова. То есть люди ошибаются, и модели ошибаются, как ее оценивать. Ну, есть варианты, конечно. Но мне попадалась недавно статья, я вот сейчас сходу не скажу, где как раз предлагались новые подходы к оценке качества модели.
Мы не пытаемся ее оценить на каком-то конкретном, не измерить перплексию или чего-то. Мы пытаемся оценить ее, как приемлемость ее действий в той или иной ситуации. Опять же, где-то год назад была статья про Behavioral Test для языковых моделей, когда мы точно знаем, что тут должны ответить нормальные люди, и смотрим, что ответит языковая модель. То есть какие-то простые такие штуки.
И вот, наверное, сюда мир будет развиваться. То есть мы будем тестировать, мы же людей как-то тестируем, мы просто такими же способами будем тестировать языковые модели, как мы людей тестируем.
А относительно того, что странно, что первыми автоматизировали творческие деятельности, ну, во-первых, суммаризация не такая уж и творческая деятельность, она такая достаточно механическая, а во-вторых, это вам, может быть, со стороны кажется, что штукатурить стену, например, или, скажем, кидать землю лопатой, это интеллектуально простая деятельность.
Да, она простая символьно, но если мы попытаемся сделать робота, который на лопате будет балансировать кусок земли и кидать его, мы столкнемся с очень сложными задачами. То есть реально мозг, вот наши полтора килограмма мозга, они используются при копании земли полностью. Просто они работают не символами, они работают с управлением нашим телом, с балансировкой и так далее и тому подобное. То есть у нас такой…
А, про реинформирование тут интересно. Собственно, это не в этой статье, в исходной статье про ChatGPT там же объяснялось, что… про ChatGPT3 которые, что на самом деле про инстрагм-GPT, что в принципе сама эта модель существовала давно и только добавление к ней второй модели, которая ранжирует ее ответы, то есть языковая модель сама выдает не один ответ, а на бимсерчинге находит несколько вариантов параллельно. И затем ранжирующая модель, та самая, которую с reinforcement learning выучили, она выбирает ту, которая сильнее всего понравится людям. Мы как раз на завтраке обсуждали это, что это можно сравнить вот с чем, что когда ребенок живет, он смотрит, как движутся предметы вокруг, он слушает, что человек начал говорить, он закончит фразу, стакан начал падать, он долетит до пола и так далее. Птица влетелась слева, долетит вправо. То есть он строит постоянно модель, предсказывающую поведение мира. И свое поведение, реакцию мира на свое поведение он тоже может предсказывать. А затем мы дополнительно ему даем воспитание, то есть мы говорим, слушай, не суй пальцы в розетку, не ори на тетю, не мажь торт на лицо.
И таким образом он выучивает не только, как устроен мир и как с ним взаимодействовать, и как он отвечает на воздействие, но и какие воздействия его в этом мире приемлемы или нет. И фактически вот этот второй компонент, который превратил GPT3 в ChatGPT, это вот этот Reinforced Learning,то самое воспитание, когда мы говорим, ну знаешь, ты можешь думать про себя разное, но вот тебе функция, которая позволяет оценить, как твои создатели к этому отнесутся. Что интересно, она же ухудшила метрики, классические языковых моделей после того, как к ней добавили Reinforced Learning, вот эту модель.
Но она улучшила Human Alignment, то есть то, насколько модель нравится людям.
Они уже двигают. Если вы давно пользуетесь интернетом, то вспомните, как вы гуглили в самом начале или в Яндексе искали. И как у вас менялся язык запросов, которыми вы обращаетесь к Яндексу без всякого специального обучения. То есть вы просто подстраивались под него, по мере того, как он становился поиск сложнее, вы подстраивались под него и начинали спрашивать его по-другому.
И в конце концов мы, люди, выработали некоторое Google-фу, как его называют, то есть как спросить этого тупого робота, и он все-таки ответил.
Так вот. Похоже, что сейчас, на примере Бинга мы это можем видеть, у нас потребность в Google-фу атрофируется, то есть мы снова можем какое-то время задавать вопросы на простом человеческом языке, и нас робот поймет.
В этом смысле, ну да, язык влияет. Наверное, тогда все?
Можно, да. Слушайте, смотрите. Да, я понял вашу штуку, ваш вопрос. Смотрите. Краткий ответ. Дообучать такие модели под конкретную задачу будет невозможно. Длинный ответ. Вы же архитектуру мозга менеджера продаж не меняете, когда он приходит на работу. Вы ему даете набор инструкций, некоторый контекст. То есть то, что сейчас в языковой модели подводка. И этот контекст, он у первых моделей был короткий, потом он стал длиннее. Совсем недавно я видел статью, которая предлагает способ сделать бесконечный attention, бесконечного размера attention в трансформере, то есть вычислительно дешево сделать практически бесконечную длину контекста.
Что на самом-то деле равняет нас с языковыми моделями в этом вопросе? То есть к вам приходит на работу языковая модель, вы ей даете должностную инструкцию, то есть сейчас это подводка, коротенькая, до, допустим, двух тысяч числов, а дальше, может быть, вы ей даете, прочитая вот этот учебник и делая, как там написано. Все. То есть само по себе обучение именно весов модели, то есть мы там смотрим на loss function и тому подобное, на график лоссов, оно вроде бы как останется только у провайдеров этих языковых моделей.
Нет, вы вначале ей дадите подводку, то есть тот человек, который у вас, допустим, профессионал какой-нибудь, какой-нибудь высокопрофессиональный человек, который у вас на работе, он же на самом-то деле в магазине общается на обычном человеческом языке и на детей кричит обычным языком и так далее, и на парковке он разговаривает с другими водителями обычным языком. Просто есть контекст, в который у него прогружена дополнительная информация. Точно так же вы прогрузите дополнительную информацию в контекст, как вот здесь, допустим, и она именно в этом контексте скажет, ага, но здесь я спам не буду учитывать, здесь я не буду об этом думать, а буду я думать о том.
Отдельный вопрос, что модель состоит из нескольких частей, то есть собственно генеративная языковая модель, к которой применимы все сложности, о которых я сказал, и второе это alignment модель. Alignment модель, то есть модель, которая определяет, что приемлемо в данном контексте, она сильно проще. Если у вас будет возможность дообучать свою alignment модель, сейчас она как бы есть в теории, то вы можете именно брать среднюю языковую среду, но выучивать вот эту функцию приемлемости, что в данном контексте приемлемо, на что нужно обращать внимание, на что нет. Вы сможете воспитывать модель под каждую конкретную отрасль. И я думаю, что это как раз можно будет дообучать. Я на самом-то деле ожидаю, что вместе с всплеском использования тяжелых языковых моделей, вот таких вот, которые будут предоставляться как АПИ, растут и расширится использование коротких и сравнительно тупых языковых моделей, как той же самой Альпаки, которую я упоминал.
То есть те, которые могут быть запущены на одном личном персональном компьютере. И когда мы научимся хотеть чего-то от больших языковых моделей, мы можем с удивлением открыть для себя, что значительную часть этого можно сделать и маленькой языковой моделью. Так что я здесь оптимист.
Во-первых, языковую модель от Яндекса можно запустить, если я не путаю в облаке Яндекса, во-вторых, она в принципе запускабельна на компьютере с большим количеством оперативной памяти, с выгрузкой слоев. Я ее смотрел, большого интереса она мне не вызвала. Ну, языковая модель, языковая модель. Сама по себе часть GPT от GPT-3, на которой она была построена, она же тоже здорово отличается. Именно вот этим алайментом, то есть подстраиванием своего вывода под хотелки человека, то есть своей способностью уживаться с человеком, способностью подгонять свои ответы под то, чего от нее желают кожаные мешки.
В этом смысле яндексовская языковая модель примерно аналогична GPT-3 по своей выразительной мощи. Ну, там плюс-минус, в общем. Ничего такого принципиального. Принципиальный шаг это как раз до обучения алаймент, ну и они на самом-то деле последние модели учат на достаточно специфичных наборах данных, то есть они добавляют туда какую-то математику, они добавляют туда какие-то специальные истории. Я думаю, что яндекс туда еще просто не добрался. И я верю в то, что яндекс выкатит, как я уже говорил, не позже, чем до конца лета свою доступную API,и мы сможем использовать в своих приложениях. Я не вижу какой-нибудь причины, почему именно у яндекса не получилось бы сделать что-нибудь похожее.
Ну, просто у Openai немножко больше денег на разметчиков и вычислительные мощности, но так в принципе. Хороший инженер есть и там и тут.
Я думаю, что китайцы, кстати, выкатят прямо сейчас хорошие свои модели. Во-первых, для них это вопрос принципа сейчас, а во-вторых, есть достаточно хорошие, маленькие китайские модели, которые запускаются на одном компьютере, и они удивительно хороши. А уж если китайцы запустят что-нибудь на кластеht, обучат что-нибудь на класте из 10 тысяч GPU, наверное, оно вообще всех порвет. Я не думаю, что Openai что-то такое выдающее себе придумали. Они, судя по всему, тоже не думают, иначе бы они GPT-4 опубликовали технические подробности. То, что они их не опубликуют, я расцениваю как то, что они не хотят помогать конкурентам их догонять.
То есть они оценивают, что конкуренты вполне в состоянии их догнать в ближайшее время, поэтому перестали опубликовать технические подробности. Ну, я думаю, так.
Все? Спасибо, что позвали.
Update 17.08.2024
- Свежий обзор на эту же тему The Transformational Opportunity of AI on ICT Jobs
Update 08.02.2025
- Стартап одного из авторов статьи, где они используют этот подход для консалтинга https://www.workhelix.com/