- 16.07.2024
- 18.08.2024
- выступления
- #NLP
На канале DS Talks разбирали статью STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases.
Слайды: stark.pdf
Текстовая расшифровка в процессе ;-)
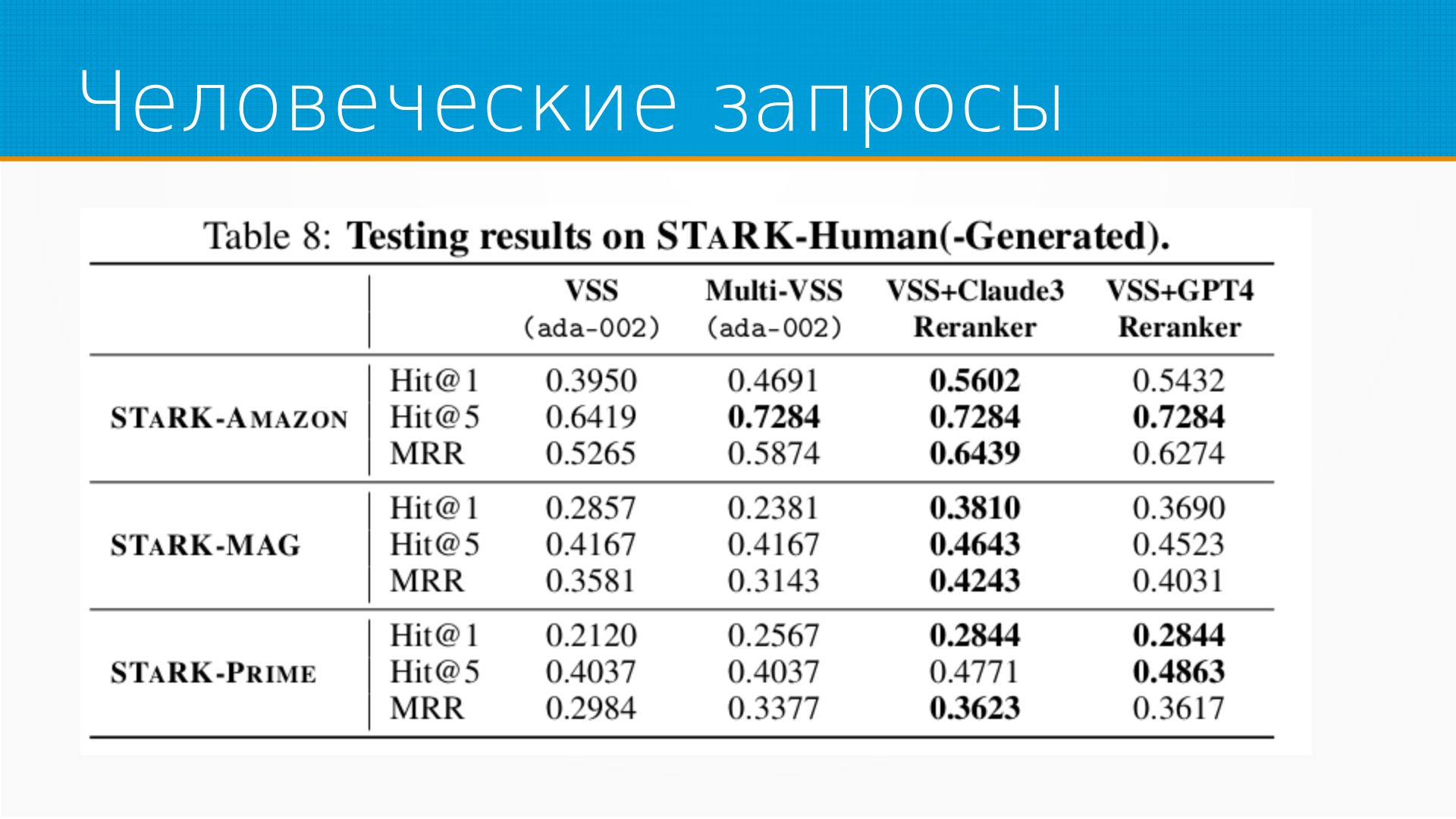
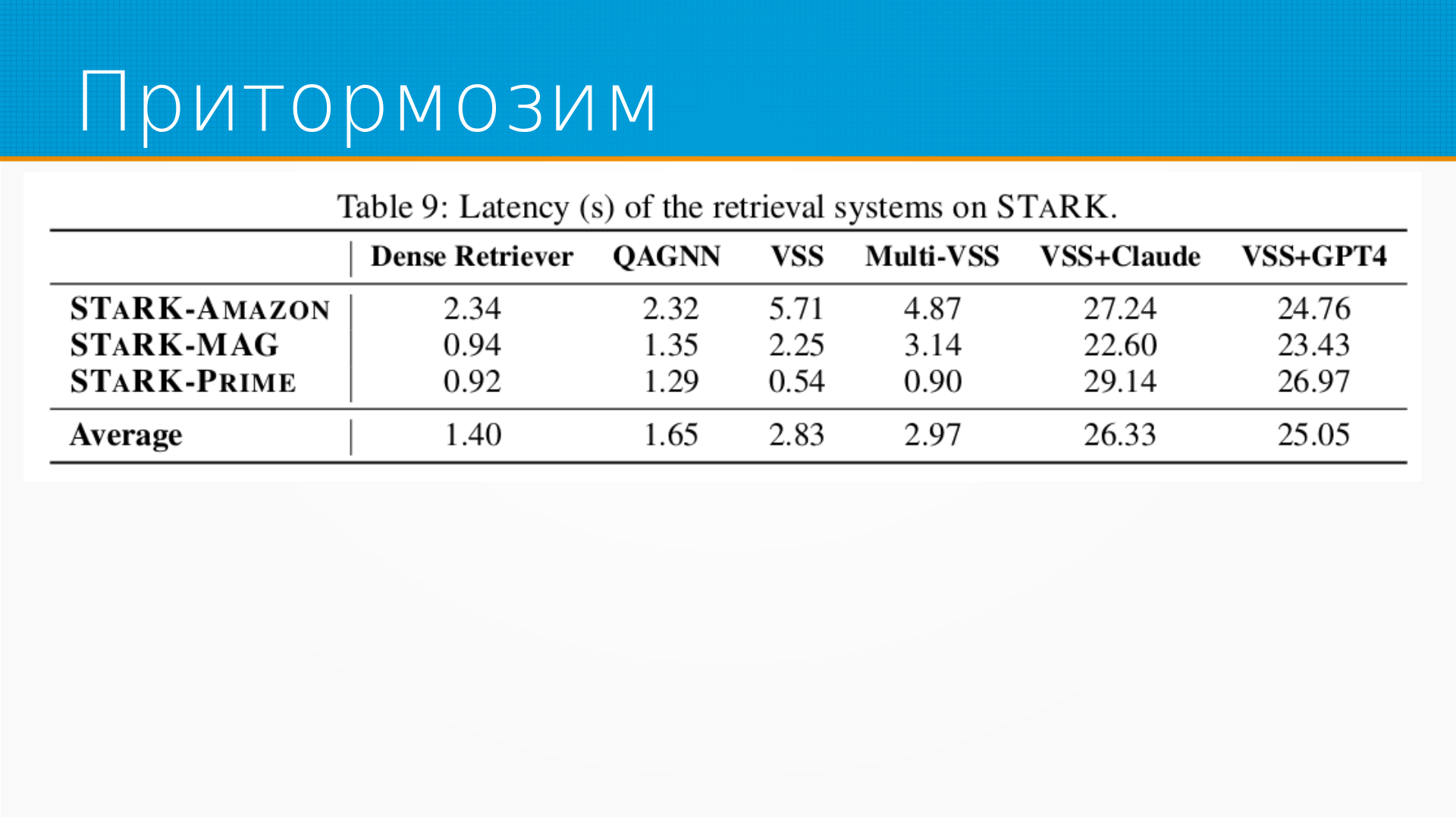
Сегодня я хочу рассказать про статью Stark, Benchmarking and Retrieval of Textual and Relational Knowledge Bases.
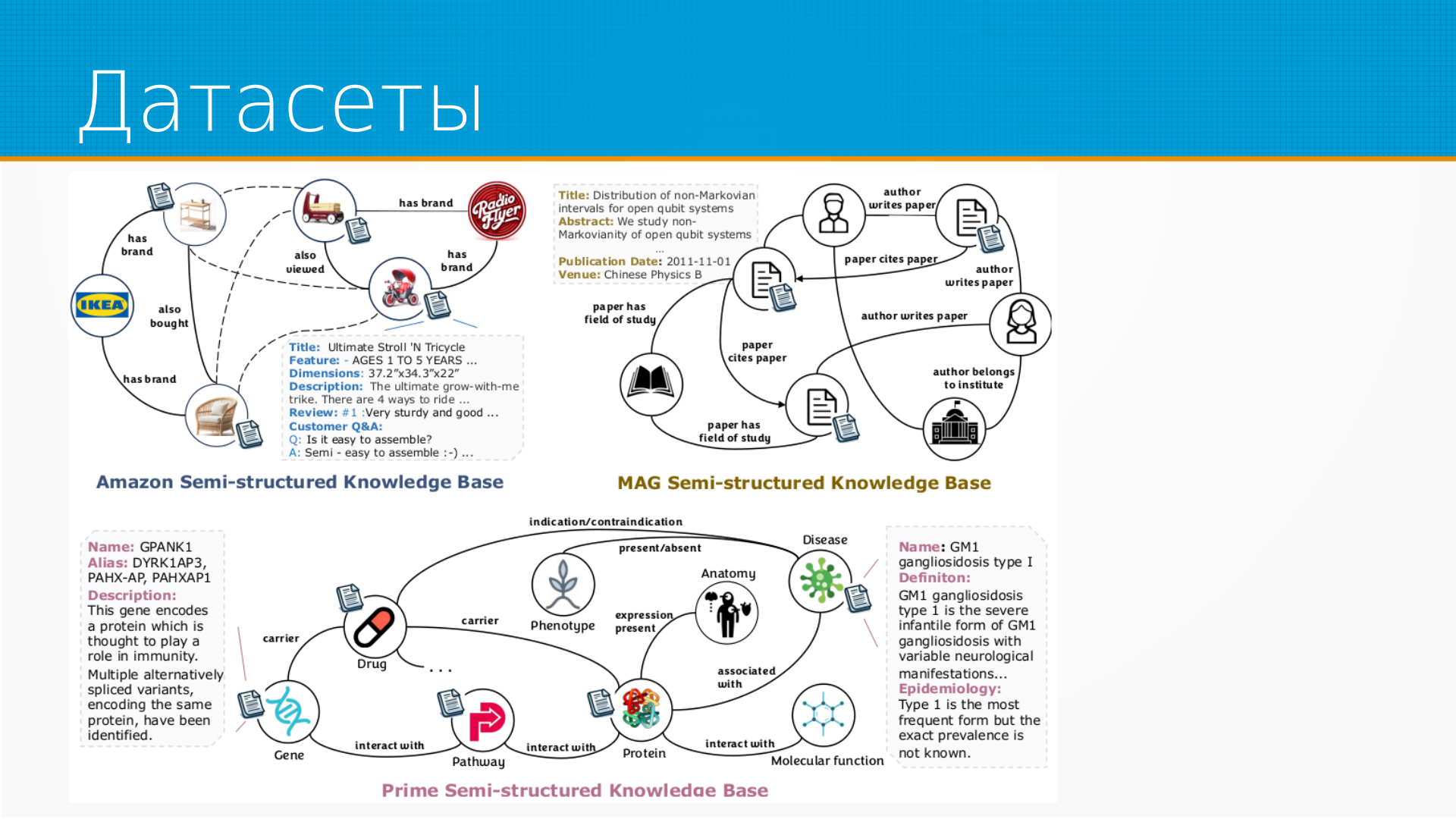
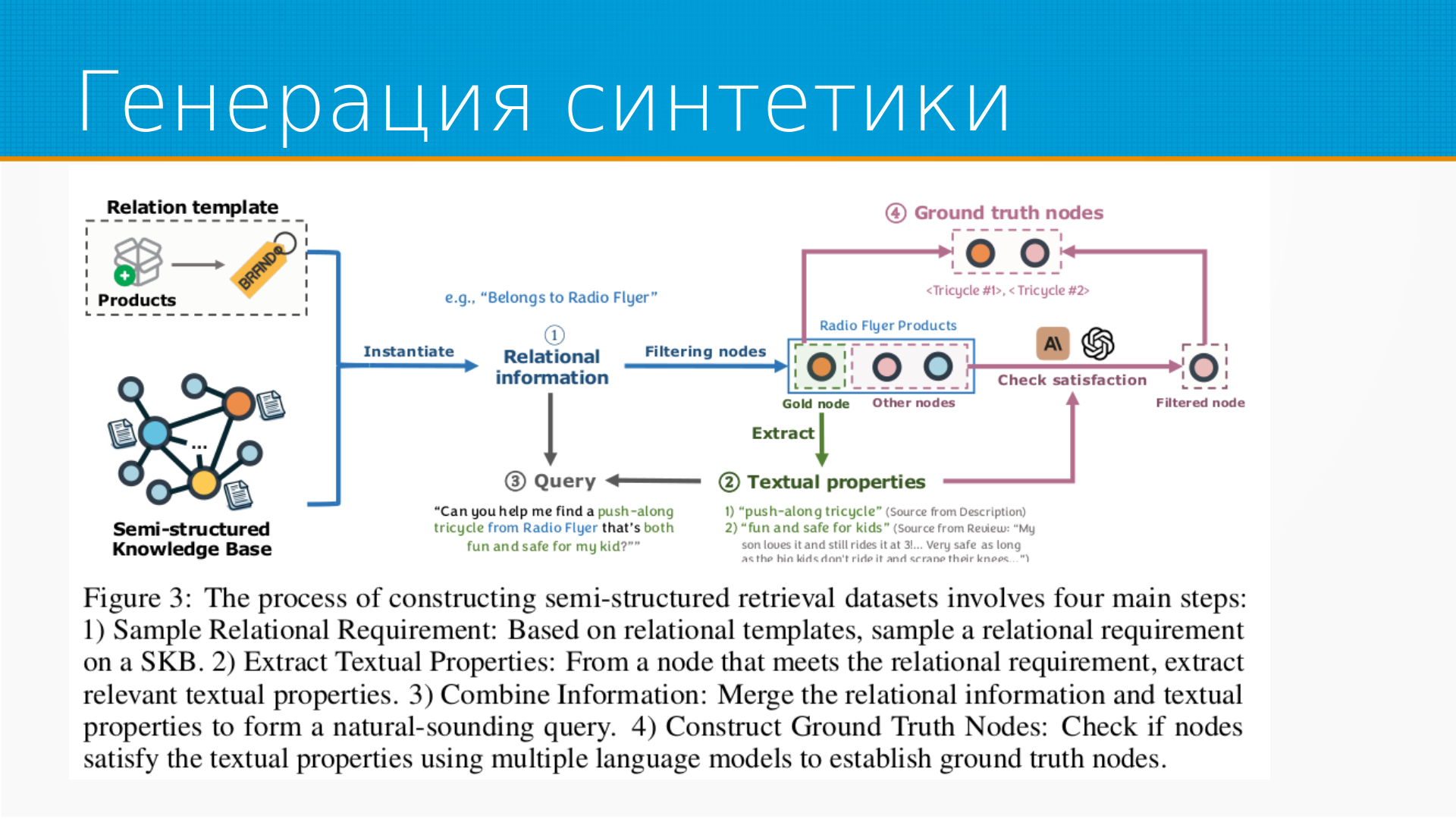
 Статья про то, что в большинстве бенчмарков для оценки поиска с помощью LLM либо ищут текст, либо генерируют запросы для поиска в базе данных или графе.
Статья про то, что в большинстве бенчмарков для оценки поиска с помощью LLM либо ищут текст, либо генерируют запросы для поиска в базе данных или графе.
Но в реальной жизни у нас одновременно существует и текст, и какая-то мета-информация о нем в базе или графе. И интересно посмотреть, как LLM сможет искать, используя всю доступную информацию.
 У статьи 10 авторов. Последний - всем известный Юрий Лесковец. Интересно, что они вдвоем с Джеймсом Цоу научруки у первого автора, Ширли Ву, как будто Юрия одного не хватило ;-)
У статьи 10 авторов. Последний - всем известный Юрий Лесковец. Интересно, что они вдвоем с Джеймсом Цоу научруки у первого автора, Ширли Ву, как будто Юрия одного не хватило ;-)
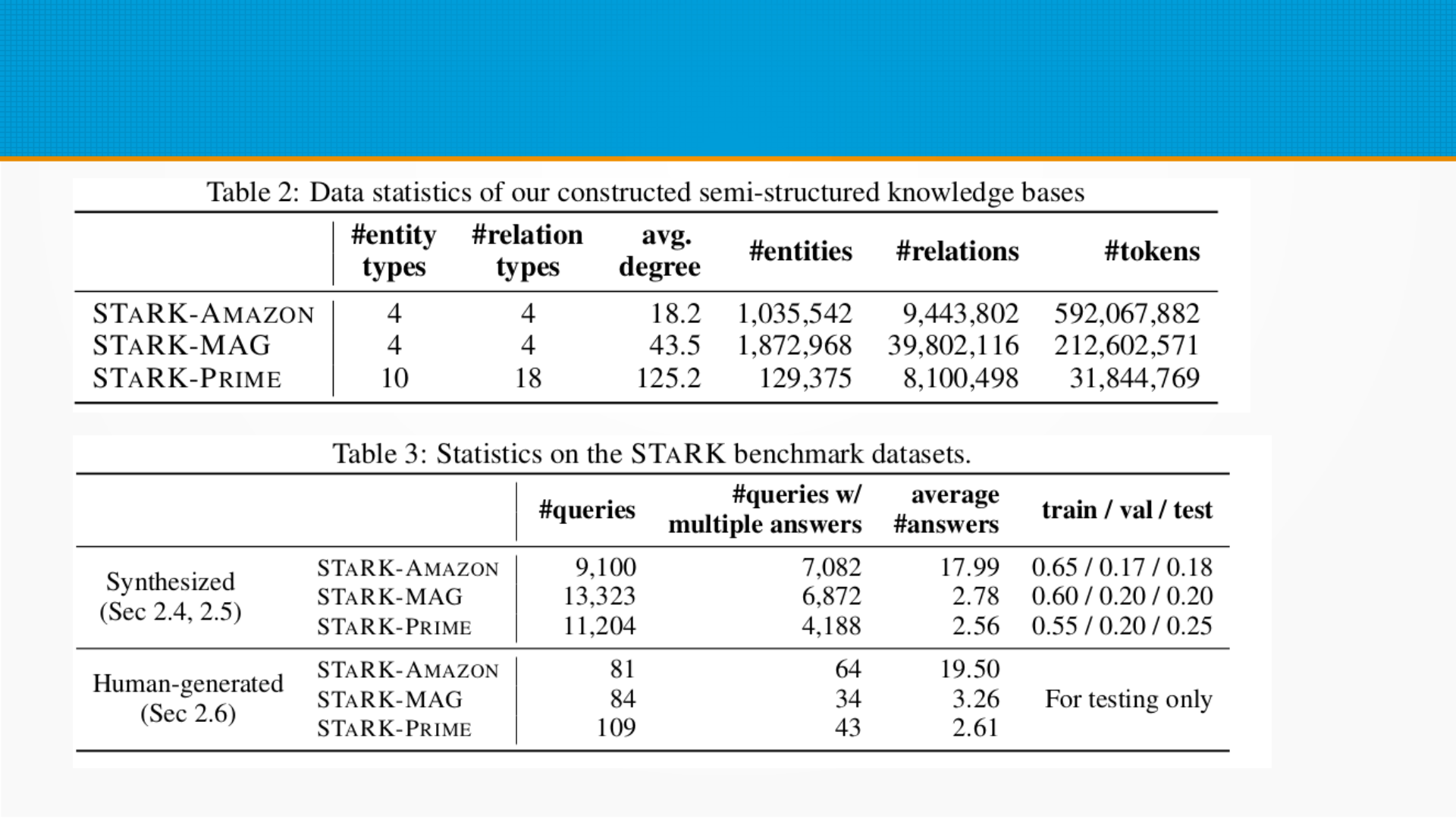
Два предпоследних автора, Василис и Кэрфик, работают в Амазоне. Возможно, они предоставили датасеты. Шестеро ребят в первой строке с простыми американскими фамилиями - студенты Лесковеца. Думаю, что они все и делали.
Студенты умницы. Если посмотреть, например, на Ширли Ву, она просто Гермиона какая-то. У нее есть сайт, и на ней собранны ее статьи.
Много интересных статей про объяснимость графовых сетей, про извлечение информации, про LLM. Мне вот три понравились, например: * борьба со сдвигом данных в графах через смесь aligned экспертов. Я даже подумать не мог, что такое можно сделать. Оказывается, можно. * поиск выявлений и избежание spiritus correlations, то есть случайных совпадений. * D4explainer - модель, которая объясняет, как графовая нейронная сеть принимает решения.
Еще мне понравился Мичи Ясунага. У него в этом году четыре хорошие твердые статьи. Остальные ребята не такие крутые, но тоже очень хороши.

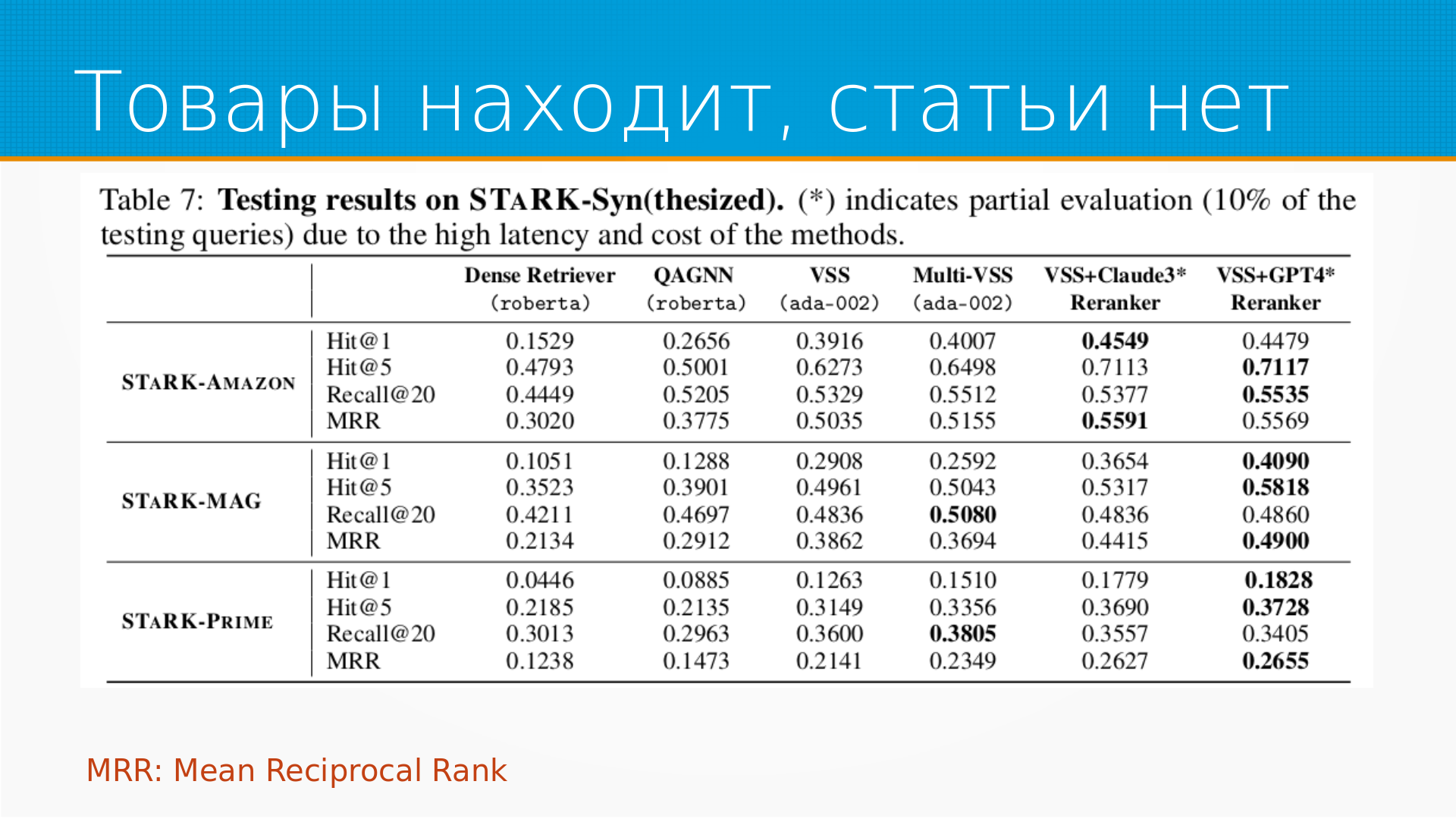
Поиск по тексту с помощью LLM широко применяется, например, в вопросно-ответных системах.