
- 27.04.2023
- 20.08.2024
- выступления
Наша с Ириной Голощаповой совместная лекция про ML System Design Doc от Reliable ML. Лекцию организовал AI Talent Hub в ИТМО в рамках курса по управлению проектами в DS. В ИТМО есть онлайн магистратура по ML инженерии, они приглашают на лекции специалистов из индустрии - и в этот раз такими специалистами были мы.
Рассказали про то, как выбирать ML-проекты, что такое ML System Design Doc и как его писать, чтобы предусмотреть основные риски, связанные с разработкой ML-решения и последующим его пилотированием и внедрением.
Слайды мои: ml_project_start.pdf
Слайды Ирины: Google Drive
Подробности на канале #ReliableML.
Расшифровка (сделана нейронкой, пока не вычитана):
Всем добрый день еще раз. Сегодня у нас занятие в рамках курса управления проектами в Data Science. И в качестве сегодня лектора, в качестве приглашенных экспертов у нас два очень интересных и многим из вас знакомых. Ирина Голощапова и Дмитрий Колодезев, достаточно активные участники комьюнити в Data Science. Вы Ирину выступление могли видеть на тему связанной с ритейлом, сейчас в банкинге. Дмитрий из Новосибирска, у нас есть ребята оттуда, кто тоже знакомы. И по курсу по ML-систем дизайн, по каналу Ирины RevivalML, поставьте плюсик в чате от 15, кто уже успел посмотреть шаблон, который отправлял вчера, связанный с оформлением документации для систем машинного обучения. Но сегодня чуть шире посмотрим, чем просто на документ, на тему инициации, на тему того, как вообще ML-проект, из каких частей, как он состоит, как он запускается, как его сделать качественным и хорошим. Все, на этом заканчиваю. Дмитрию слова передаю.

Привет. Меня действительно зовут Дмитрий Колодезев. Я работаю директором ООО Промсофт. С Ириной вместе ведем канал #ReliableML. Сейчас я попробую рассказать, из чего состоит хороший ML-проект.
 Я не всегда умел делать хорошо проекты. Много проектов я завалил.
Но так как я этим занимаюсь уже не один десяток лет, то какие-то даже и получились.
Я не всегда умел делать хорошо проекты. Много проектов я завалил.
Но так как я этим занимаюсь уже не один десяток лет, то какие-то даже и получились.

Что такое ML-проект? ML-проект – это проект, успех которого зависит от разработки или внедрения модели машинного обучения. Причем машинное обучение часто имеет улучшающее свойство на остальные проекты. Такой волшебный порошок, которого мы досыпали в проект, в процесс, и он стал работать лучше.

Далее на протяжении всей презентации я буду использовать слово «гипотеза». И гипотеза тут в смысле естественно научном. То есть предположение, которое не имеет достаточных подтверждений, но мы в него верим. Хорошую гипотезу мы можем верифицировать. То есть поставить какой-то эксперимент, который скажет нам, что эта гипотеза верна. Или фальсифицировать. То есть есть какие-то вещи, которых точно не может быть при условии, что эта гипотеза верна. И большинство фактов и ограничений в бизнесе, большинство требований, которые к нам предъявляют заказчики, большинство бесспорных утверждений, которые мы всегда принимаем на веру – это просто гипотезы. Их надо проверять, как и положено делать с гипотезами.
 Соредставляющие хорошего ML-проекта – это прежде всего какая-то насущная проблема, которую стоит решать.
Что мы не делаем ML ради ML.
Для ML-проекта нам нужны данные, причем не абы когда, а в нужное время.
Нам обязательно нужен доступ к экспертам предметной области, потому что мы, допустим, эксперты в ML,
а кто-то эксперт в том, что мы улучшаем.
Использовать какие-то гипотезы, как можно решить проблему.
Нам обязательно нужна возможность проверять гипотезу, потому что использовать гипотезу без проверки – это опасно и вредно.
Нам нужна возможность внедрить наше решение. Не всегда это возможно.
Мы иногда можем придумать хорошее решение, но внедрить его не сможем.
И здорово было бы иметь возможность измерить результат, чтобы самим хотя бы понимать,
что мы сделали его лучше. Иногда наша разработка может даже ухудшить процесс.
Соредставляющие хорошего ML-проекта – это прежде всего какая-то насущная проблема, которую стоит решать.
Что мы не делаем ML ради ML.
Для ML-проекта нам нужны данные, причем не абы когда, а в нужное время.
Нам обязательно нужен доступ к экспертам предметной области, потому что мы, допустим, эксперты в ML,
а кто-то эксперт в том, что мы улучшаем.
Использовать какие-то гипотезы, как можно решить проблему.
Нам обязательно нужна возможность проверять гипотезу, потому что использовать гипотезу без проверки – это опасно и вредно.
Нам нужна возможность внедрить наше решение. Не всегда это возможно.
Мы иногда можем придумать хорошее решение, но внедрить его не сможем.
И здорово было бы иметь возможность измерить результат, чтобы самим хотя бы понимать,
что мы сделали его лучше. Иногда наша разработка может даже ухудшить процесс.

Что такое насущная проблема? Если просто насущная проблема – это проблема, за которую люди вам охотно сами приносят деньги. Если люди не несут деньги, значит что-то у нас с гипотезой не сходится. Наверное, она не такая насущная. Попытка догнать людей и причинить им пользу, то есть порешать проблему, которая у них не болит, обычно поваливается.

У нас должна быть какая-то гипотеза о проблеме. Люди устроены так, что все проблемы, которые у них есть, они уже решили. Совсем нерешенных проблем обычно нет. Кроме проблемы, что мы живем сто лет, а хотели бы жить, например, двести. Но обычно решение, которое есть, оно сейчас не оптимально. То есть оно было оптимально когда-то, где-то у каких-то людей. С той поры что-то изменилось, появились новые технологии или появились новые ограничения. Например, как во время коронавируса взлетели сервисы для видеоконференций. Просто не потому, что новые технологии появились. Интернет был раньше. То, что появились ограничения, и видеозвонки стали удобнее перелета. Главная гипотеза – как мы ее будем проверять? Можем ли вообще ее проверить?

Иногда нам очень хочется что-нибудь сделать в этой отрасли, а проблемы нет. Как Генри Форд говорил, если бы я делал то, о чем меня просят люди, я должен был бы сделать более быструю лошадь. Решение тут стандартное. Возьмите какую-нибудь отрасль, которая вам любопытна. Торговля акциями, ветеринария, разведение крокодилов, путешествия. И поищите роли, которые есть у людей в этом бизнесе. Какие задачи решают эти люди, какие у них проблемы возникают. И куда у них уходит много времени, денег, трудозатрат, эмоциональных ресурсов. Иногда проблемы можно увидеть просто глядя в бухгалтерию. То есть мы смотрим, что у нас есть бизнес-процесс. На шаге первого, второго у нас по одному человеку, на третьем у нас пять человек, на четвертом и пятом опять по одному человеку. Наверное, на третьем шаге что-то неоптимальное. Возможно, что проблема там прячется. Иногда денег уходит немного, но просто людей что-то бесит. И вот это тоже проблема, и решение ее приносит деньги.

Нам нужно, чтобы были данные и данные вовремя. Потому что машинное обучение – это поиск и использование шаблонных данных. Нет данных – нет машинного обучения. Просите данные вперед и можете выяснить в самом начале проекта, что данных, которые мы обещали, на самом деле нет.

Если данных нет, мы можем их собрать самим. Но просто это отдельный проект. Надо сразу понимать, что первые полгода мы, например, будем собирать данные. Или, как это в случае, допустим, сельского хозяйства, первые пять лет будем собирать данные. То есть такие проекты – это для стойких людей с большим запасом денег, которые никуда не торопятся. Иногда данные есть, но просто на них как на данные не смотрят. То есть есть какие-нибудь логи, журналы звонков, CRM-системы, из которых можно склеить изолентой вполне хорошие данные, которые позволяют принимать интересные бизнес-решения, что-то улучшать. Часто есть куча неструктурированных данных – звонков, текстовых описаний, фотографий. И тут нас нейронные сети спасают. Вытащить из неструктурированных данных хорошие интересные данные. Иногда данных мало нужного примера, и их проще сгенерировать самим синтетически. Например, если вы делаете систему видеонаблюдения, которая отслеживает, что человек упал на рельсы, наверное, неразумно кидать людей на рельсы. Проще в 3D это делать, смоделировать. Конечно, мы получим еще одну гипотезу о том, что данные, которые мы сгенерировали, похожие на настоящее, тоже нужно будет проверить. Может быть, одного-двух все-таки надо будет скинуть.

Иногда, даже очень часто, данные есть, но их нет вовремя. То есть, например, данные в принципе есть, но в тот момент, когда нам надо учить, модель данных еще нет. Или бывает наоборот. Нам нужно делать предсказания, но нужные нам данные поступают с задержкой. У меня был такой опыт, когда данные, нужные для принятия решения, поступали буквально на 30 секунд после того, как это решение нужно было принять. Просто пока оно через брокер сообщений, через синхронизацию доползет до нужного места, все, поезд уже ушел. Бывает, что событий важного класса мало. Бывает, что мир изменился, и те обучающие данные, на которых мы учились, уже устарели. То есть, используется сейчас какое-нибудь другое оборудование или какой-нибудь другой ассортимент товаров или еще что-нибудь. А бывает еще, что мир остался тем же самым, данные есть хорошие, но впредь они будут недоступны. То есть, например, популярная интернет-компания в России, она продавала данные микрофинансовым организациям, которые дают займы под грабительские проценты до зарплат. А потом в какой-то момент решила, что это плохо для их имиджа, и данные перестала давать. Получилось, что данные за прошлые периоды есть, а теперь выкручиваетесь как хотите. Тут можно измениться, выкрутиться, можно построить какие-нибудь проксиметрики, можно одни данные смоделировать, восстановить по-другим, но в любом случае эту проблему надо найти, желательно до того, как вы пообещали сроки и деньги.

Вам нужен эксперт предметной области, кто-то, кто понимает, как работает процесс. И тут универсальное решение, универсальный совет – это идти в гэмбо, идти в то место, где как раз происходит бизнес-процесс, смотреть, слушать и искать какие-то мелочи, которые выпадают из вашей картины мира, которые не стыкуются.

Вам нужны гипотезы о решении. И когда вы будете придумывать гипотезы о решения, помните, что у каждой гипотезы есть отрицательная стоимость. Этот термин я впервые услышал, прочитал в блоге Артемия Лебедева – идея на минус миллион. То есть мы думаем, что мы можем реализовать какое-нибудь решение, которое помогает нашему заказчику как-то улучшить бизнес-процесс, улучшить наш процесс предсказания. Но у каждого решения, которое мы придумали, есть стоимость проверки решения. Например, мы придумали, что хорошо бы на конвейер поставить видеокамеру, которая бы выискивала дефектные детали. Для этого нам надо поставить видеокамеру, нужно потащить освещение, нужно согласовать установку всей этой штуки прямо над конвейером, как-то решить электропитание. То есть совершенно невинная видеокамера над конвейером может вылиться в миллион долларов. Это для того, чтобы проверить, что решение работает. Просто чтобы гипотезу проверить. Поэтому гипотезы надо оценивать не только по их эффекту, но и по стоимости проверки. Минус сколько миллионов – это гипотеза. Тут хороший совет. Мы представляем, что мы в будущем, когда мы уже решили проблему, смотрим назад, что было, и рассказываем, как мы туда попали. Обычно это такой отрезвляющий взгляд на вещи.

Эксперименты ставить трудно. Эксперименты, которыми в университете обычно учат, в институте, как проверять, как ставить эксперименты, как планировать – это сложная дисциплина, зачеты по которой сдавать очень больно. Но обычно это речь про эксперименты, которые ставят физики, металлурги. То есть какой-то сложный эксперимент с множеством контролируемых параметров и небольшим количеством тестовых проходов. Но нам нужно смотреть не то, как делают физики-ядерщики эксперименты, нам надо смотреть, как эксперименты ставят рекламисты и эпидемиологи. Потому что у рекламистов и эпидемиологов очень велика неопределенность, сложные причинные связи, и они как-то выкручиваются и умудряются добиваться хорошего результата. Ну и скорость проверки гипотез важнее качества своих гипотез. Если вы можете за один год проверить сто средненьких гипотез, то лучше, чем если вы одну хорошую гипотезу год собирались проверить. Мир меняется, и чем мы быстрее проверяем гипотезы, тем быстрее мы движемся, тем лучше мы ему соответствуем.

Не всякое решение можно внедрить. Иногда у нас есть законодательные ограничения, иногда для того, чтобы внедрить в принципе хорошее решение, нам нужно переделать системы поддержки, обучения, как у меня, например, есть знакомые. Они делают прибор, который делают из глупой лесопилки, то есть лесопилки, которая просто пилит лес. Умную лесопилку, которая сама прицеливается по доске и так далее и тому подобное. Приборчик небольшой, но существующий процесс торговли лесопилками, вы отгружаете лесопилку, ее увозят куда-то на крайний север и пилят, как себе дерево. Время от времени покупают новое полотно, смазывают ее и у них сгорает электромотор или еще что-нибудь. А тут вам нужно будет обновлять прошивку в вашем приборе. Люди, которые эксплуатируют, слово-то прошивки не знают. То есть вам придется менять сам процесс поддержки ваших лесопилок. И это больно неожиданно дорого может быть. Еще у людей перед ML-алгоритмом есть то преимущество, что люди гибкие. То есть если вы поставили человека за ним решать какую-то проблему, он верит, что это решение уже не подходит. То есть мы делаем какую-то фигню, он придет к вам и говорит, слушай, товарищ начальник, мы делаем ерунду, давай мы улучшим бизнес-процесс, потому что клиенты уже приходят с другими запросами. ML-модель к вам с этим вопросом не придет. То есть когда мы заменяем человека на алгоритм, а фактически к этому и сводятся все ML-проекты, что мы вместо живого человека ставим какую-нибудь бездушную машину, мы замораживаем тот бизнес-процесс, который был на момент внедрения. Но зачастую для бизнеса гибкость в бизнес-процессах так же важна, как и качество этих бизнес-процессов. Бизнес-процесс, бизнес выживает за счет того, что его бизнес-процессы гибкие. И мы делаем их жесткими, ставим туда ML вместо людей, мы, может быть, делаем ему хуже. То есть, в принципе, локально он оптимизировал процессы, глобально сам бизнес стал более хрупкий и неустойчивый. Иногда каким-то исполнителям просто невыгодно, что вы внедрите эту систему. Например, у них вместо 50 человек в подчинении станет 10, поэтому они будут сабботировать ведрение. Такое тоже бывает.

И, в принципе, все проблемы при внедрении ML-проектов это коммуникационные проблемы. То есть у всех участников процесса есть свой кусочек пазла, но они забывают выложить его на стол. Многие люди участвуют в внедрении ML-проекта первый раз в жизни, и важные вопросы остаются незаданными, важные проблемы остаются нерассмотренными. И решение этой проблемы, этой параллельной реальности, что у каждого из стейкхолдеров своя реальность мира, он в ней живет, и мы эти реальности сопоставляем только на запуске проекта, когда выясняется, что наши кусочки пазла не подходят друг другу. Решение тут это, например, ML-дизайн-док, фреймворк, который позволяет задать правильные вопросы правильным людям в правильном порядке и тем самым избежать грубых ошибок при планировании ML-проекта.

У меня все, но вопросы лучше потом, после того, как первый расскажет свою часть лекции. Мы, наверное, вместе ответим на вопросы. Хорошо. Спасибо, Дмитрий.

Спасибо. Тогда я, наверное, переключаюсь в презентацию. Меня хорошо слышно? Да, все слышно. Да, собственно, вторая часть лекции, она про ML-систем-дизайн-док. Я расскажу чуть подробнее, что это такое, как с этим работать и про наш с Димой шаблон, который мы в конце 2022 года выложили в открытый доступ.
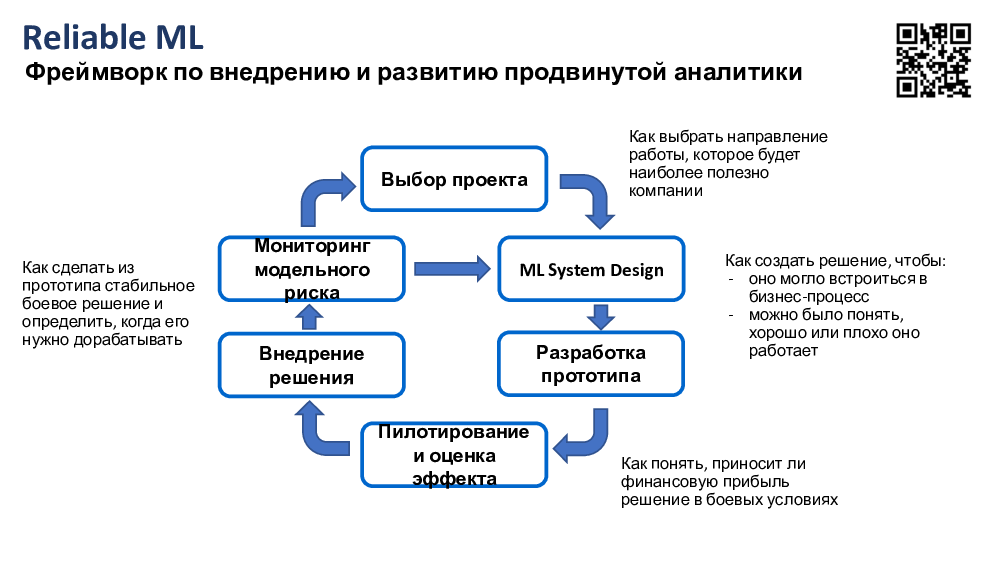 В принципе, для того, чтобы понять, наверное,
где применяется ML-дизайн-док,
стоит поговорить об основных этапах работы над ML-проектом.
В целом, то, что Дима рассказал в первой части лекции.
Сначала нам нужно выбрать вообще либо портфель проектов,
либо конкретный проект, над которым мы будем работать.
Когда мы это сделали, мы переходим к планированию нашей работы,
думаем о дизайне системы машинного обучения,
которую мы собираемся строить.
Как только мы сделали этот дизайн,
мы можем перейти к разработке прототипа
в соответствии с тем дизайном, который запланировали.
Дальше, когда прототип сделали,
хорошо бы его протестировать на реальных данных
и затем понять, действительно ли он приносит ту пользу,
которую мы от него ожидали.
Если он действительно эту пользу приносит,
значит, неплохо было бы его раскатать в прод, внедрить.
В принципе, для того, чтобы понять, наверное,
где применяется ML-дизайн-док,
стоит поговорить об основных этапах работы над ML-проектом.
В целом, то, что Дима рассказал в первой части лекции.
Сначала нам нужно выбрать вообще либо портфель проектов,
либо конкретный проект, над которым мы будем работать.
Когда мы это сделали, мы переходим к планированию нашей работы,
думаем о дизайне системы машинного обучения,
которую мы собираемся строить.
Как только мы сделали этот дизайн,
мы можем перейти к разработке прототипа
в соответствии с тем дизайном, который запланировали.
Дальше, когда прототип сделали,
хорошо бы его протестировать на реальных данных
и затем понять, действительно ли он приносит ту пользу,
которую мы от него ожидали.
Если он действительно эту пользу приносит,
значит, неплохо было бы его раскатать в прод, внедрить.
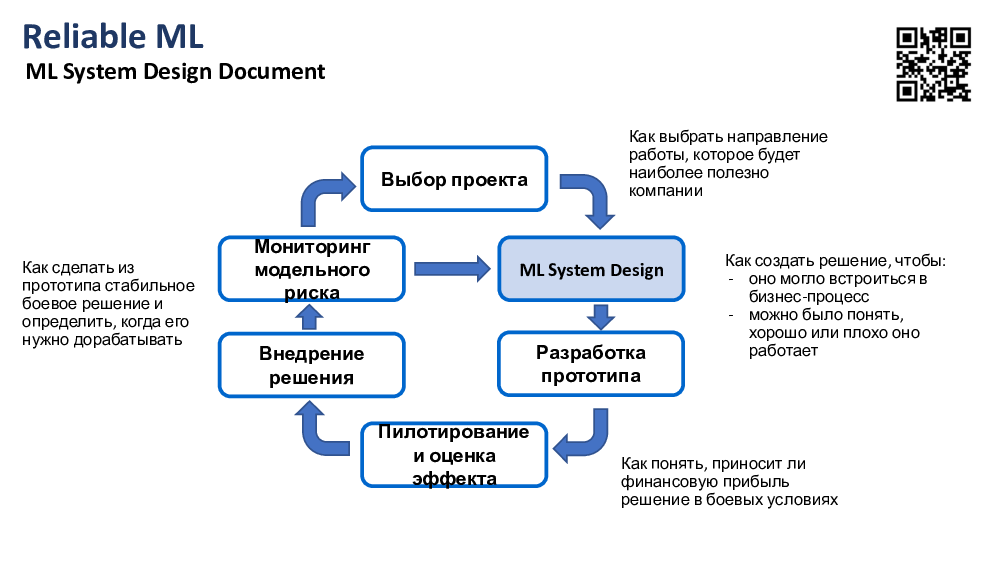
Если мы это, опять же, успешно сделали, то здорово мониторить успешность решения уже в продуктиве, чтобы вовремя понять момент, когда модель деградировала или когда условия поменялись, и перейти, возможно, к изменению ком-то дизайна или просто переобучению модели. Если изменение дизайна требуется, то можем пойти заново по циклу. Сейчас, говоря о дизайне системы машинного обучения и о дизайн-документе, это касается только этапа с дизайном системы.

Что же такое ML-дизайн-док и зачем он нужен? По сути, это как сводный план для построения вашего ML-решения, которое должно решать какую-то конкретную проблему или запрос бизнеса, с которым вы взаимодействуете, как это идентифицировать, рассказал Дима, используется на этапе дизайна системы.
 В принципе, дизайн-док помогает на основе уже,
так сказать, реального опыта и тестирования этой штуки,
очень хорошо помогает структурировать ваши же собственные мысли о том,
как вы будете разрабатывать прототип,
вообще делать ваше решение и затем тестировать его успешность.
Очень часто кажется, что в своей голове вы очень хорошо понимаете,
что вы будете делать, какие у вас этапы, что как,
но при этом, когда вы пытаетесь записать на бумагу,
оказывается, что огромное количество слепых зон,
куча запутанностей, каких-то вещей, которые надо дополнительно выяснить,
рисков различных и т.д. и т.п.
То же самое с данными.
Если мы понимаем, что мы не видим данные,
то это обязательно нужно прописать в рисках,
прописать требования к данным, которые вам нужны,
чтобы решение ваше все-таки состоялось.
И это вам в том числе поможет с коммуникацией с заказчиками.
Немножко касаясь того вопроса, который письменно был озвучен.
Также это поможет, помогает задать ключевые критические вопросы вашему заказчику,
точнее, требования.
В принципе, дизайн-док помогает на основе уже,
так сказать, реального опыта и тестирования этой штуки,
очень хорошо помогает структурировать ваши же собственные мысли о том,
как вы будете разрабатывать прототип,
вообще делать ваше решение и затем тестировать его успешность.
Очень часто кажется, что в своей голове вы очень хорошо понимаете,
что вы будете делать, какие у вас этапы, что как,
но при этом, когда вы пытаетесь записать на бумагу,
оказывается, что огромное количество слепых зон,
куча запутанностей, каких-то вещей, которые надо дополнительно выяснить,
рисков различных и т.д. и т.п.
То же самое с данными.
Если мы понимаем, что мы не видим данные,
то это обязательно нужно прописать в рисках,
прописать требования к данным, которые вам нужны,
чтобы решение ваше все-таки состоялось.
И это вам в том числе поможет с коммуникацией с заказчиками.
Немножко касаясь того вопроса, который письменно был озвучен.
Также это поможет, помогает задать ключевые критические вопросы вашему заказчику,
точнее, требования.
 Понять сам процесс, в который планируется встроить систему
и различные нюансы, связанные с тем, как сделать,
чтобы эта система потом в этом бизнес-процессе работала,
не сломала его и не оказалась для него в итоге лишней.
Понять, что вообще возможно построить такую модель,
не заранее подумать о различных рисках,
опять же, связанных с отсутствием данных возможным
или их, например, недостаточностью.
И, опять же, подумать о том, что вы будете с этим делать.
То есть если у вас, например, может оказаться,
не знаю, вы делаете прогноз спроса для какого-то большого,
для ста категорий товаров, например, у вас,
вполне может оказаться так, что для 20% этих категорий
данных очень мало для того, чтобы построить модель.
Понять сам процесс, в который планируется встроить систему
и различные нюансы, связанные с тем, как сделать,
чтобы эта система потом в этом бизнес-процессе работала,
не сломала его и не оказалась для него в итоге лишней.
Понять, что вообще возможно построить такую модель,
не заранее подумать о различных рисках,
опять же, связанных с отсутствием данных возможным
или их, например, недостаточностью.
И, опять же, подумать о том, что вы будете с этим делать.
То есть если у вас, например, может оказаться,
не знаю, вы делаете прогноз спроса для какого-то большого,
для ста категорий товаров, например, у вас,
вполне может оказаться так, что для 20% этих категорий
данных очень мало для того, чтобы построить модель.
 А что вы будете в этом случае делать?
Вы вообще не будете строить модель,
вы используете похожие категории или еще как-то придумаете,
как решить этот вопрос, используете алгоритмы,
которые работают на малых выборах.
Очень хорошо помогает синхронизировать ожидания
и возможности, собственно, ожидания бизнеса
и возможности технической команды,
потому что в реальном мире бизнес всегда будет хотеть
искусственный интеллект, который сделает всю работу за ним.
А что вы будете в этом случае делать?
Вы вообще не будете строить модель,
вы используете похожие категории или еще как-то придумаете,
как решить этот вопрос, используете алгоритмы,
которые работают на малых выборах.
Очень хорошо помогает синхронизировать ожидания
и возможности, собственно, ожидания бизнеса
и возможности технической команды,
потому что в реальном мире бизнес всегда будет хотеть
искусственный интеллект, который сделает всю работу за ним.
Но при этом техническая команда далеко не всегда это может сделать,
а может сделать только какую-то часть,
которая, скорее всего, просто поможет и сделает жизнь бизнеса лучше.
Это тоже на этапе планирования очень хорошо проговорить.
И для себя же установить стандарты работы,
что вы будете считать завершенным прототипом,
какое качество решения, какой код,
в каком виде созданы, по каким стандартам написаны.
Когда вообще нужно писать документ, когда нет.
Если вы делаете… что значит продукт?
Продукт – это что-то, что живет долго,
долго дорабатывается, у него долгий жизненный цикл,
поэтому, конечно, для продукта обязательно писать документ
и планировать его.

И, в принципе, необходимость дизайн-дока увеличивается
с увеличением сложности проекта и планированной длины его реализации.
Если это какая-то небольшая моделька, которую вам нужно сделать,
и вы ее теоретически сделаете недельки за две,
не стоит для нее с начала месяца писать дизайн-док.
Это будет не очень эффективное расходование вашего времени и усилий.
И при этом хочется сказать, что не стоит к шаблонам дизайн-дока
относиться как к каким-то железобетонным вводам,
которые обязательно нужно заполнить от и до.
Это некое меню, из которого вам нужно выбрать то,
что наиболее релевантно вашему проекту.

И чем сложнее этот проект, тем, наверное, больше и внимательнее
стоит относиться к шаблону и больше стараться заполнить,
потому что чем больше будет заполнено, тем больше риск нитигировано,
но не всегда это оправдано, если проект простой.
Поэтому здесь стоит каждый раз индивидуально смотреть,
а нужен вам дизайн-док, и насколько нужен, и насколько сложный.
Конечно, опять же, его необходимость повышается,
если вам не очень понятно, что делать,
если бизнес неясно формулирует свои ожидания,
если у вас какие-то спорные истории.

Что такое итерация?
Также на слайде указаны итерации и в шаблоне в нашем,
и в принципе мы называем то решение, ту доработку,
ту работу, которую вы собираетесь сделать, до пилота.
То есть вы что-то сделаете, потом вы это будете тестировать,
пилотировать и смотреть эффект на реальных данных.
Вот это и будет ваша итерация.
Обычно дизайн-док пишется на итерацию,
а потом проверить пилотом и прийти к какому-то выводу дальше.
Но при этом бывает так, что дизайн-док полезен для того,
чтобы в принципе верхнеуровнево понять,
что вы собираетесь делать в этом проекте,
какие у вас вообще ключевые этапы разработки.
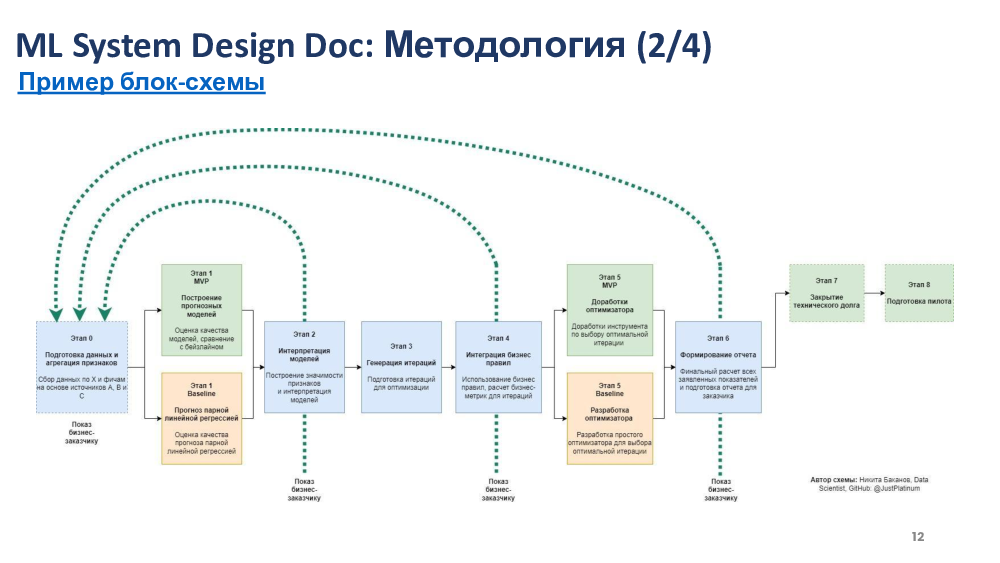
То есть просто все итерации перечислить и кратко каждую описать.
Главное, чтобы этот документ был для вас полезен.
А в репозитории Reliable E-Mail дизайн-дока
там как раз второй пример, который мы уже вложили,
он про как раз вот этот верхнеуровневый дизайн,
когда полезно было именно понять ключевые этапы разработки.
Собственно, какая вообще практика по дизайн-документам?
В российской практике неизвестен только наш шаблон,
наш методичка, так сказать, для составления дизайн-документа.
Если вам известны другие, то, пожалуйста, пришлите ссылку, мы добавим.
В международной практике довольно много статей разных
и вариантов, темплейтов, как это делать.
Собственно, мы, когда разрабатывали наш шаблон,
мы учитывали эту международную практику.
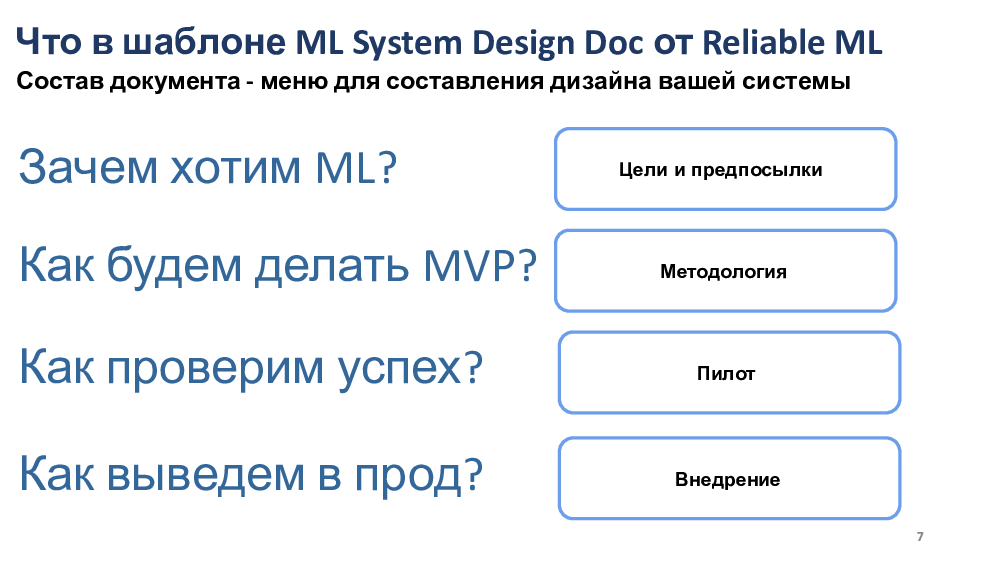
Теперь про состав самого документа.

Он состоит из четырех ключевых частей.
Первая из них — это описание целей и предпосылок решения.
Зачем мы вообще хотим делать E-Mail?
Почему станет лучше от того, что мы внедрим этот E-Mail?
Процесс как-то живет сейчас, что в нем будет лучше и почему,
если вдруг придет E-Mail?
Вторая часть — это методология, как именно мы будем делать наш MVP.
Пилот — это как именно мы проверим успех нашего решения.
И внедрение — это как мы, собственно, выведем впрод наше решение.
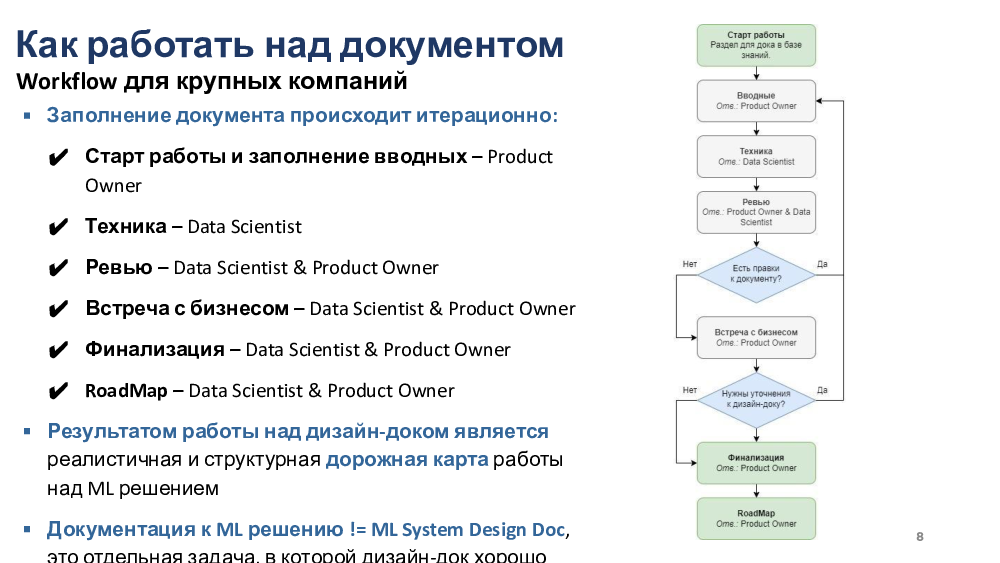
Как выглядит классический воркфлоу работы над документом в крупной компании?
В крупной компании обычно это такая итерационная штука.

Часто на продукте есть свой product owner,
который, собственно, отвечает за то, чтобы быть мостиком
технической команды и бизнесом,
и максимизировать для них ценность продукта.
Соответственно, он обычно заполняет ключевые вводные,
вот эту часть целей и предпосылки решения,
передает это Data Scientist, они заполняют техническую часть,
дальше вместе ревьюят, встречаются с бизнесом,
потому что, как правило, нужна прям не одна итерация,
чтобы с бизнесом различные вопросы утрясти и договориться.
В конце концов, все договариваются, и каких-то вопросов по доку не остается.

Документ финализируется, и его одним из главных результатов
является не только план вашего исследования,
а еще и roadmap, который вы составите гораздо более адекватно,
точно и структурированно, если вы сначала напишете дизайн-док.
Составляется, собственно, дорожная карта, и вперед.
Ну и маленький коммент, что все-таки дизайн-док —
это не документация к вашему решению, потому что это только план.
Когда вы уже делаете ваш прототип и как-то его финализируете,
вы уже ведете документацию по правилам.
Конечно, в идеальной ситуации вы все же планируете так же, как и сделаете,
и вам очень легко будет написать документацию,
но обычно все-таки какие-то нюансы возникают.

В случае с заполнением документа на курсе наверняка
workflow будет выглядеть намного проще, то есть вы, скорее всего,
сами работаете над документом, ревьюете его с менторами,
задаете им какие-то вопросы и мы с Димой сможем помочь, ответим.
И финализируете, наверное, составляете roadmap и идете по нему.
Какие еще вещи стоит держать в голове при заполнении дизайн-дока?
Если дизайн-док получается шаблонным, это не очень хорошо.
То есть если вы составили документ, написали, ну вот мне нужно построить регрессию,
показать цены на недвижимость.
Я сначала соберу данные, потом я построю фичи,
потом я фич-селекшн сделаю, флосс-функцию выберу,
потом определю, какие у меня метрики качества будут,
и построю регрессию.
Тогда ваш документ можно применить к очень многим проектам,
где будет просто задача регрессии, не только цены на недвижимость,
но и на что угодно. Вы просто напишите еще один шаблон.

То есть в документе должно быть максимум мяса.
Какие данные вы возьмете, откуда проработаны они или нет,
что вы будете ожидать от завершения этого этапа,
то есть как вы поймете, что вы собрали нужные вам данные,
что вы будете делать, как вы будете строить регрессию,
какие вы примерно фичи собираетесь построить,
какие алгоритмы вы хотите выбрать, какой бейзлайн вы построите,
насколько лучше ваш MVP должен быть лучше бейзлайна,
к каким метрикам качества конкретным вы стремитесь и почему.
И отсюда логично следует то, что наилучший дизайн-док получается,
если во время него делать EDA, то есть эксплоратор и дата-анализ.
Хотя бы для целевой перемены.
Если вы ее уже можете собрать, посмотреть сэмпл,
поковыряться в них, вы уже гораздо более продуманно напишите дизайн-док.
Не бойтесь записывать много, не мало.
Не стоит думать, что там стоит какие-то вещи оставить в голове,
типа док не надо заносить, лучше занести,
потом вы будете сами себе благодарны за это.
Максимально точно сформулировать ключевые параметры,
то есть то, что вы ожидаете от завершения каждого этапа,
какие вещи вы хотите сделать в каждом этапе.
И подумать про риски.
Может быть, у вас будет недостаточно данных или что-то с поступлением данных и периодичностью, как говорит Дима. Может быть, например, задачей вашей модели является определить степень влияния какого-то фактора на целевую переменную. Как у нас изменяется выручка от изменения цены, например. И может быть риск в том, что у вас окажется вообще супер неожиданной для бизнеса и для вас же зависимости. Как вы поймете, что все нормы, вот именно все правильно вы сделали, просто действительно зависимости такие. А это не ошибка в коде. Так, сейчас я посмотрю, сколько времени, потому что дальше у меня... Ой, простите. Сколько времени, скажите лучше? 33 минуты, то есть вполне комфортно. Вполне еще есть время, но я здесь просто могу прям чуть-просто зум сделать уже в каждый раздел и прям кратко приближаться какие есть кусочки внутри каждого раздела. В целях и предпосылках, что мы хотим описать. Зачем вообще идем в разработку продукта, почему станет лучше от использования email, чем сейчас. Собственно, если кто-то читал такую маленькую книжечку, не знаю даже, можно ли книжкой называть пост, 100 правил email. Первое правило этой известной книжечки гласит, что если вы можете сделать что-то без машинного обучения, делайте это без машинного обучения. Бизнес, требования и ограничения. Собственно, какие вообще есть ограничения по данным. Не знаю, с точки зрения бизнеса, то, что бизнес вам говорит и что он вообще требует. Максимально там ссылки, что удалось стрясти с бизнеса. Что вы собираетесь делать в рамках той итерации, которую вы сейчас описываете в дизайн-доке. Если вы описываете все, то вам тунг нерелевантен. Какие предпосылки вашего решения, то есть какие, опять же, ограничения с точки зрения выполнения. То есть бизнес, опять же, от вас хочет все, но в рамках данного решения вы готовы сделать раз-два-три. Подстановка задачи. Здесь уже перевод желания бизнеса на технические формулировки, что на самом деле мы будем делать. Рекомендашку, поиск аномалий или прогноз. Блок схемы решения. Здесь, наверное, долго не стоит объяснять. Есть примеры на сайте, в репозитории. Здесь вы просто лангкобс на ваше решение отрисовываете. Вот один из примеров у меня обозначен. Здесь в начале подготовка данных. Далее разделяется на два подраздела. Эта история в том, что сначала строится бейзлайн. К нему своей древней он как-то просто строится. Это простая модель. Условно-скользящим средним мы прогнозируем временной ряд. Это сложная модель, которой мы стремимся в разработке нашего прототипа. Это наш MVP. Дальше нам в любом случае нужно эти модели проинтерпретировать, показать бизнесу. Возможно, после этого нам придется вернуться в этапной и что-то доработать. Дальше мы делаем подготовку к оптимизации. У нас есть также бейзлайн оптимизации и более сложная история. Дальше мы формируем отчет, периодически тоже ходим в бизнес, что-то показываем. Здесь на этом слайде рассказано про описание уже методологии про подготовку данных. Наверное, я особо не буду останавливаться, но здесь данный формат. Возможно, он будет для вас удобным, возможно, нет, но он просто позволяет детализировать те источники данных, которые вы хотите использовать и понять, насколько долго вам с ними придется работать, чтобы подготовить данные для моделирования. В том числе обозначить, понимаете ли вы качество этих данных или нет. Если вы не понимаете качество этих данных, значит, времени на работу с ними стоит закладывать сильно больше и вообще обозначать эти риски в договоре или просто внутри компании. В методологии, опять же, вы описываете все, что можете описать максимально подробно. Какие модели вы хотите строить, каким метриком качества прийти, какие риски для себя видите для этого. Также описываем информацию про пилот, как мы собираемся его провести, что мы будем считать пилотом успешным, с этим тоже должен быть согласен бизнес, в первую очередь, и ваш заказчик. И что нужно вообще сделать с точки зрения модели для того, чтобы пилот подготовить. Если у нас есть дизайн-доки и этап внедрения, очень часто они пишутся не для внедрения, а для ресерча, поэтому на самом деле четвертый блок заполняется довольно редко. Тут прям стандартные истории, что обычно описывается для систем, которые планируете вводить в прод. Собственно, ссылка на шаблон, она у вас уже есть. Вообще, если вы будете работать с документами, у вас возникнут какие-то идеи, как его можно изменить, расширить, дополнить, упростить или что-нибудь еще, обязательно пишите, мы только рады. Те кейсы, которые близки к промышленным, мы готовы публиковать в репозитории, смотрим их, помогаем довести до ума, усилить с точки зрения формата и с точки зрения содержания. То есть алгоритмам тоже можем помочь. Вот, собственно, все. Спасибо. Я тогда убираю шеринг. Вот. Супер. Спасибо, Ирина. Много комментов. Да, Дмитрий активно коммуницировал, активно отвечал. Может быть, Дмитрий, я тогда попросил, исходя из такого большого сейчас общения в чате, резюмировать основные вопросы или, может быть, какие были инсайты, исходя из вопросов или то, что благодаря вопросам захотелось подробнее осветить, и дальше уже в формате диалога тоже можем продолжить. Да, на самом деле вопросы достаточно типичные. Про данные, недоступные до начала проекта, а после начала проекта, может быть, уже поздно. Тут надо понимать, что это вы создали ситуацию, в которой вам уже поздно. То есть кто вас заставлял подписываться под ценными сроками и 99% качества, не глядя в данные? Это вопрос не к заказчику, это вопрос к вам. Никто вас не гнал в эту мышеловку, вы в нее строим, зашли добровольно. Есть такая вещь, что если вы пообещаете человеку чудо, возьмете за эти деньги, он имеет право это чудо с вас потребовать. Гражданский кодекс нас этому учит и обязывает. Поэтому не обещайте того, чего у вас нет. Дизайн-док начинается с того, что заказчик и группа, которая его будет делать, пытаются договориться, что возможно, что нужно, что необходимо и какой ценой. А также, что для этого нужно. Часто приводят пример. У меня богатый опыт торговли за программные продукты. Приходит заказчик и говорит, сколько будет стоить? Я говорю, да фиг его знает. Он говорит, ну как же, я сажусь в такси, я хочу заплатить фиксированную сумму и меня привезут. Я говорю, ну здорово, давай ты, допустим, приходишь и говоришь, слушайте, а сколько будет строить дом? Сколько он будет стоить? Сколько вы будете строить? И выясняется, что дом, допустим, девятиэтажный будет строить одну сумму, а садовый домик другую сумму. Более того, садовый домик один и тот же, может стоить разные деньги в разное время года. Или, например, ковид, все подорожало, допустим, металлы. То есть строители спокойно с вас дерут деньги за то, что подорожали материалы во время стройки, и вы им ругаетесь, но платите. А программистам так нельзя себя вести. Мир устроен так, чудес не им нет. Если что-то дороже, чем вы его продали, вы его можете либо не продать, либо продать себе в убыток. Просто думаете, что делаете, управляете ожиданиями заказчика. Вот это краткое содержание всей беседы. Вообще-то дизайн-док лучше всего подходит для внутренней разработки. И так он, по большому счету, и родился. Не для контрактной разработки. В контрактной разработке вы становитесь по разную сторону стола, и кто кого поборет кит или слон, тот и победил. На самом деле это неправильный подход, и вообще-то в случае контрактной разработки первое, что нужно решать, это нужно выходить из вот этой дуэли. То есть вы не противник своему клиенту, вы ему соратник. Если вы не смогли построить ситуацию, в которой вы клиенту-соратник, если он вам не верит, тогда все равно проект будет очень сложно строить. То есть по-хорошему, если у людей есть насущная проблема, она болит, а вы тот самый айболит, который эту проблему вылечите, то вы с ними не враги, вы с ними друзья. Ему должно быть выгодно, что у вас хватит ресурсов дотащить эту проблему до проды. Ему должно быть выгодно, чтобы у вас все получилось. И вам должно быть выгодно, чтобы у него получилось. Это вопрос к вам как к переговорщику и человеку, который переформулирует проблему из ситуации, что кто-нибудь из вас непременно лузер, кто-нибудь потеряет деньги, к ситуации, когда вы оба выиграете. В проектах такого небольшого и среднего размера хорошо заходит разделение на дискавери и деливери. То есть вообще-то большинство ML-проектов это просто проекты по разработке программного обеспечения, но у них есть такой момент неопределенности, связанный с тем, что фиг вы знаете, получится оно или нет. И мы говорим, ну хорошо, сейчас месяц или два мы будем учить модельки, и нас не трогайте, сколько сможете, сможем выделить на это дело, мы поэкспериментируем. А потом у нас появятся нормальные результаты, мы понимаем, чего можно достичь, и вот тут нормальная интерактивная разработка, спринты эти ваши любимые и так далее. А как быть, если заказчик говорит нет, вы мне сразу скажите. Ну говорите нет, все это идеальное, правильное слово в переговорах, самое главное слово, которое в переговорах есть, это нет. То есть вы видите, что что-то не сходится, говорите нет, я так не могу. Ну все, идите к следующему заказчику, и напоминайте вашего продажника, чтобы он нашел вам того, кому вы можете сказать да. Каким образом можно измерить бизнес-метрики, когда мы ускоряем процесс, ускоряем работу человека, а он вместо того, чтобы больше работать, начинает больше спать. Ну на самом-то деле в жизни так не бывает. Очень часто может получаться так, что вы ускорили какую-то некритичную для бизнеса метрику, но от этого ничего не изменилось. Тут есть хорошая такая книга «Критическая цепь» Голдрайта, это у нас он так, по-моему, называется. Целен, что, грубо говоря, у вас есть бытовочное горлышко, и любые улучшения за пределами этого бытовочного горлышка вообще не поменяют процесс. Просто вы лечили не там, где болит человек. Вы лечили не тот бизнес-процесс. Надо искать узкое место, его расширять. Если есть какое-то другое узкое место, вы распрямили части процесса, которые не болели, это вопрос к постановке задачи к согласованию. Когда следующий дата-завтрак в центре Новосибирска? В центре Новосибирска завтраки провожу не я. Их проводят ребята, которые когда-то у меня работали, сейчас у меня не работают. Поэтому вот как им удобно, так и не проводят. У них там какие-то организационные перестановки. В конце марта они говорили, что хотят. Как только они смогут, сразу начнут. А в конце мая. Каким образом продавать Discovery? Искать способ, чтобы вы были заказчику не враг. Чтобы вы были его другом. Тогда он на Discovery согласится. Вы на самом-то деле снижаете риски. То есть вы делаете маленький кусочек проекта для того, чтобы снизить риски. Вы же не только свои риски снижаете, вы и его риски снижаете. Может получиться, что вы два года что-то сделали. Он вам дал какой-то аванс, а теперь у него не результат. И судится его еще с вами еще год, чтобы эти деньги вернуть. То есть заказчику, нормальному заказчику, такому заказчику, с которым стоит работать, ему выгодно, чтобы у вас все получилось. На моей практике к увольнениям еще не приводило внедрение. Обычно перевеспределение. Да, вообще говоря, выгодом может быть просто снижение текучки кадров. То есть раньше это была такая мучительная работа, на которой человек больше трех месяцев не удерживался, а теперь вот он удержался. И вы все-таки заработали деньги, просто не в этом месте. У меня там на одном из слайдов было, я голопом по Европам пробежал, чтобы не час рассказывать слайды, что вы можете улучшить не сам процесс, а надпроцесс, то есть процесс, в который он входит. То есть, допустим, у вас есть торговый робот, который торгует акциями, и вы реально его не улучшили. Вы улучшили процесс поиска и истребления плохих торговых роботов. Или вы реально не улучшили работу человека, но вы уменьшили текучку кадров на этой должности, потому что человек приходит домой и чувствует себя живым, нормальным человеком и невыжатой тряпкой. Такое вот есть. Заказчик все равно ожидает какого-то качества от модели. Откуда эти ожидания взялись? Почему он их ожидает? То есть это вы ему пообещали, ему кто-то другой пообещал, он их высылал из пальца, как часто бывает. То есть, по большому счету, хороший способ убить ML-проект, это спросить его, сколько денег он вам принесет. Заказчик такой посчитает, скажет, слушай, а они сколько? Все, ничего не делают. И на самом деле это хорошо узнать до того, как в конце, потому что если он в конце, когда он заплатил вам денег, и вдруг поймет, что на самом деле ему ничего не приведет, он вас вернет и авансы отсудит, у него обычные юристы лучше, чем у вас. То есть, если заказчик с вас требует странного, может быть, просто вообще не надо в этот проект лезть. Или лезть его на то именно материал. Заказчик говорит, я хочу поиграться в машинление. Говорим, отлично. Играться в машинлейнинг стоит 45 тысяч рублей в день. Пожалуйста, играйся. Вот. Ну и все. Так, что у нас еще? Дальше вот это два вопроса. Мне кажется, я могу сказать, что в среднем написание дизайн-дока занимает около двух недель. Если вас оперативно там отвечают. Тоже зависит от сложности проекта, но там больше трех недель редко. Но в среднем две. По поводу того, что мы можем потратить кучу времени на продумывание рисков, но при этом потеряем суть. Но здесь как раз о том, что не стоит увлекаться в любом деле без фанатизма и увлекаться дизайн-доком как шаблоном тоже не следует. Нужно не потерять суть, а писать главные вещи и уже пойти вперед. Особенно если вы совместите написание дизайн-дока с EDA, то суть вы вряд ли упустите и важный риск предусмотрен. У меня есть вот комментарий, тратится овер тысяча часов на анализ, а результат может случиться никакой. А вообще так оно обычно бывает. То есть это самая частая история в индустрии. Обычный проект по разработке программного обеспечения, он там в несколько раз выходит за сроки и бюджеты. И от того, что вы чуть-чуть больше времени потратите на проработку самой задачи, вы ситуацию не ухудшите. То есть так он в среднем в 3 раза будет медленнее работать, вы потратите лишние 2 недели. Про то, что с метриками качество плохо, это действительно проблема, но тут это проблема не метрик, это проблема вас. Дело в том, что часто можно придумать прокси-метрики. То есть в случае медленно вызревающих метрик, таких как, например, в финансах, в инвестициях или там в рекламе, часто мы можем ориентироваться на какую-то метрику, которая предсказывает метрику. То есть, например, мы не можем предсказать, купит человек дом у нас на веб-сайте или нет, допустим, вот такое редкое явление. Но мы можем посмотреть, просмотрел у нас от 8 до 20 страниц, или меньше, или больше. И, в общем, максимизировать количество людей, которые просмотрят от 8 до 20 страниц, потому что нам отдел маркетинга сказал, что эти самые люди, они как раз больше домов и покупают. То есть у Бабушкиных, кстати, было хорошее на нашем серийном мероприятии, он говорил про иерархические метрики. То есть вы берете какую-то метрику, типа мы ускорим на 10% генерацию вот этой вот штучки. А зачем? А из этих 10% получится, мы ускорим на 3%, оборачиваясь вот этого товара. И вот так вот до денег посчитать, до той ключевой метрики, которая на самом деле важна бизнесу. То есть в большинстве случаев метрики, когда вы приходите к бизнесу, типа 98% точности распознавания, 97%, они для него на самом-то деле ничего не значат. Это он просто вас в договоре прожимает, как у него условный рефлекс, прожимать всех поставщиков по цифрам. По всем цифрам, по любым цифрам. На самом деле его интересует скорее всего оборачиваемость склада, капитализация компании, какое-то ограниченное число метрик. Поэтому если вы сможете дотащить через цепочку прокси-метрик до вот этой вот метрики, которая его на самом деле интересует, у вас все будет получаться. Они сможете к вам будут докапываться в пол до процентов и вести с вами юридическую войну. Спасибо, Дмитрий, за развернутый ответ. Спасибо, Ирина. Уточнение с точки зрения документов. В первую очередь, особенно все, что связано с бизнес-целями, с предпосылками разработки, это лежит на продакт-менеджере, продактованнере. В каких кейсах у вас в практике было? Или как построить такую работу? Чтобы в дизайн-доке был в первую очередь заинтересован инженер, и чтобы при разработке хотелось его заполнять, хотелось систематизировать свою работу. Продакт заполняет только первую часть. А дата-инженер, дата-сайентист, как бы этот человек ни назывался в компании, заполняет техническую часть. Какая его основная мотивация? Как должна взаимодействовать команда, чтобы они находили эти точки? Была интересна и бизнес-цель, чтобы не было разрыва между тем, что дата-сайентист оформляет условно и оперативные точки прохождения самого технического решения, а продакт только бизнес. Как их соединить? Насколько ваш дата-инженер любит выкидывать в мусорку уже сделанную работу? Если он не очень любит, тогда он, может быть, вполне с удовольствием будет заполнять дизайн-док. Либо просто это будет дольше, чем 2 недели. Если он не будет читать то, что написано и обозначено, исходя из того, что хочет бизнес, то будет видно, что его решение не достигает. Все проблемы с мискоммуникацией, когда люди забыли кому-то что-то важное сказать, что забыли заполнить что-то в дизайн-доке, они все выливаются просто в переделки. Пойдем, давайте еще полгодика поработаем, потому что нам на финише забыли сказать, что мы делаем не это. В том числе задача продакта, мне кажется, хорошего вдохновить и объяснить, зачем мы что-то делаем, почему реально станет лучше, если мы классную модель построим. И заинтересовать. А как дальше живет документ после того, как его заполнили, согласовали, все приняли? На этапе разработки, на этапе уже запуска пилота, тестирования, внедрения решения? Как часто к нему возвращаются? Вносятся ли в него правки? Или он должен быть перезаписан заново? Как можно этот процесс изменения... Мы идем по нему работать. Он является основой, основным доком для разработки прототипа и во время этого процесса подготовки пилота. Когда уже пилот пошел в работу, так дизайн-доку стоит вернуться, посмотреть, что мы хотели получить от пилота, то есть наши договоренности, что мы будем считать успешным пилотом, как мы собирались это оценивать, на чем все договорились. Если у вас какие-то кардинальные правки, если вы хорошо написали дизайн-док, то у вас родмат по нему, вы к нему возвращаетесь что-то разрабатывать, пишете документацию. Если вдруг вы поняли, что вы супер неправильно написали диздок, вы вернетесь к этапу редизайна системы, и тогда придется его сильно обновить или написать другой. Так тоже бывает, у нас был кейс, что мы писали дизайн-док, но мы довольно быстро уперлись в то, что при такой постановке задачи сделать ее не получится. С этим диздоком пришли в бизнес, и это очень хорошо помогло объяснить, почему не получится. Это был кейс по оптимизации полочного пространства в ленте. И вместе с заказчиком реально на основе этого дока поняли, как по-другому поставить задачу, и быстренько написали новый диздок, и по нему уже система построена сейчас. Дима тоже хотел что-то дополнить. Тут я хотел напомнить еще, что все-таки, когда Ирина рассказывает, она явно подразумевает, что это внутренняя разработка. Тогда, как много вопросов, казалось, контрактной разработки. И когда вы делаете контрактную разработку, ML систем дизайн-док, он не обязан один в один соответствовать одному договору. Я бы вообще советовал рассматривать это именно как архитектурный документ. То есть у нас есть представление о том, что мы строим, а контрактовать надо понятными, воспроизводимыми кусками. То есть посмотрели, что ага, вот это мы понимаем, вот это оно сделается за понятное время в понятные деньги, давайте мы вот эту часть контрактуем и уточним дизайн-док после того, как мы ее сделаем. Он позволяет создать и поддерживать общее видение задач. Общее видение – это архитектура решения нашего. Вот Василий в чате уточняет, это, наверное, похоже на то, что я спрашивал касаемо процесса, жизненного цикла, после пилота. Как он масштабируется или перезаписывается? Там как раз есть часть про внедрение, то есть все есть. Больший акцент у Вас будет на четвертом блоке про внедрение. Мне кажется, для разработки внедрения в принципе гораздо более проработана эта история, как это структурирует. Поэтому здесь не то, чтобы мы сильно что-то меняли относительно международных шаблонов. Архитектура. Все пункты риска, интеграция и все. Василий? Да, а еще тогда такой вопрос. Если в основном у нас вышел пилот, все хорошо, но мы видим, как улучшить нашу систему, то есть у нас идет вторая итерация работы над продуктом, нам под это отдельный ML-системдок писать? Друзья, обычно бывает так, что если вы разработали что-то, значит, пилот оказался успешным. Обычно внедряют то, что успешно, иногда это даже другая команда обязательно будет, и рисочется параллельно какое-то улучшение текущего решения. То есть вряд ли вы будете тратить много времени на то, чтобы сделать еще одну итерацию и улучшить решение, когда уже какой-то первый вариант дал положительный эффект. Тогда его, вероятно, стоит уже внедрить и начать получать свою value и параллельно делать или после этого внедрения делать новую итерацию разработки. Насколько нужно или не нужно писать дизайн-док? Опять же, если это вам полезно, если вам реально нужно структурировать мысли, это решение сильно будет, эта итерация будет сильно отличаться, напишите или обновите. А если там очевидные какие-то вещи, вы сразу roadmap можете составить и идти вперед. Здесь обязательно никогда не убивать. Окей. Тогда такой более общий вопрос. Что в принципе в вашем опыте подтолкнуло к того, что нужно систематизировать, нужно сделать этот документ открытым, нужно собрать где-то разрозненные здания, где-то систематизировать? Что послужил мотивацией? Мне кажется, мы даже много что сказали про это. То есть опыт у нас большой, и много проектов было разных, и тех, в которых в середине разработки выяснялось, что нужно-то совсем другое, или мы оба там занимались, занимаемся консалтингом разным, тоже там как бы выясняется, что требования сформулировать сложные, нужно задать правильные вопросы. Какие-то проекты, к сожалению, уходят в стол, потому что, опять же, не было продумано изначально, зачем это делать. И в какой-то момент стало понятно, что нужна структуризация, и на моем опыте дизайн-док дал прям очень большой эффект, улучшающий с точки зрения структуризации вообще общение с заказчиком, ожиданий и результатов. А про открытость, то есть почему это не внутренне, не стало продуктом ленты или другой кампании? Почему была ценность там, чтобы сделать это открыто? Потому что хочется как-то способствовать развитию дата-сайенса в нашей стране. Как бы пафосно это не звучало, но если это людям поможет, это круто. А у меня, с моей стороны, я до того, как... То есть идея изначально была Ирины, а я коллекционировал чек-листы. То есть на самом-то деле чек-листы по разработке ML-проекта, они есть у Фейсбука, они есть у Гугла, они есть у любой крупной кампании, и у большинства мелких есть уже какой-то чек-лист. И я их коллекционировал, и из них складывалась общая структура. То есть фактически приходит человек и говорит, я сейчас, мы улучшим, а давай мы по пунктам пройдем методичным. И проходим по пунктам. И три четверти я улучшил, а оказывается, Пшиком еще на этапе планирования. Можно это даже и не пробовать. А какие-то вещи, вот об этом не подумал, довернули, и вместо просто средненького получился феноменальный успех. То есть это способ делать то, что мы делаем лучше. И в общем, если это Фейсбук выкладывает в открытый доступ, то почему бы нам не выкладывать в открытый доступ? Неправда. Но сейчас вообще очень классный тренд у нас пошел. Мы выкладываем эти примеры, и кажется, с каждым примером ценность этого дока растет. И сейчас уже начинают и компании коммерческие хотеть выкладывать свои доки. Вообще классно. То есть у нас время позволяет. Если есть возможность, Ирина Дмитриевна, на каком-то примере кейса, может быть, пройти с верхнего уровня, но уже, может быть, даже больше с акцентом на техническую часть. Я знаю, что вы делали. Там, по-моему, выручка в магазинах была, да? Да, был первый сейчас. Не помню, конечно. Давайте сейчас импровизация. А там же в репозиториях он был вроде. Да, он есть, но я детали-то не помню. Давайте попробуем читать его вместе. Да, у нас первый кейс, который мы выложили, это прогнозирование выручки в магазинах. Собственно, вот, да, первая часть. Бизнес-цель – замена ручной работы прогнозами модели. Для чего будет использоваться? Побочная цель, наверное, сейчас не так важна. Здесь очень классно автор подошел, сделал так, чтобы процесс был понятен для всех, кто будет читать, то есть прямо описал, как выглядит сейчас бизнес-процесс, почему, собственно, станет лучше. Для малого бизнеса, так понимаю, что там будет локальных точек продаж. Исключим человеческий фактор, увеличим точность определения значимых в магазинах, поймем, с кем нужно взаимодействовать в первую очередь. Есть четкая граница по качеству, которая нужна. Определена метрика, объяснено, собственно, почему она выбрана. Даже вот экономию затрат сразу в рублях считают, это вообще классно. Тоже все формулки выложены. Бизнес-требования. Вот, да, бизнес-требования тоже важно, может быть, не всегда понятно, что это может быть, то есть на какой срок нужен прогноз, с какой регулярностью он нужен. Тоже вот какие-то детальки, что когда, какое число там месяца, до какого момента нам в этот момент нужны данные, соответственно, где там пересечение, то есть мы там делаем прогноз, не знаю, 1 апреля, в этот момент у нас доступны данные только до, не знаю, 15 февраля. Что нам с этим делать? Гранулярность прогноза. Плюс, чтобы решение было используемо бизнесом и применимо, нужно не просто сделать прогноз, а там разбить его потом по сегментам и выдать бизнесу в удобном формате. Вот, то есть даже там предполагается создание даже борда или хотя бы Excel, то есть бизнес не будет в код смотреть. Дальше, собственно, обсуждается, что именно будет сделано в первой итерации, что пойдет в пилот, как будет тестироваться, как будет проведен пилот. Критерии успешности еще раз обозначены и обозначено, что вот в первой итерации тоже пункт этот в некоторых случаях, когда мы рассказываем про дизайн-док, спрашивают, а зачем про итерацию, если вы вроде и так пишите там цельные предпосылки, ожидания, зачем вообще пункт про итерацию. Здесь про то, что вообще бизнес хочет, чтобы был дашборд, было интегрировано решение во внутреннюю систему, но в первой итерации, которую мы сейчас проговариваем и делаем, мы это не включаем. У нас просто там в Excel выводится прогноз. Стандарты разработки, вот о чем конкретно договорилась команда, то, что обязательно используем GitLab, доки введем в Google Docs, код пишем в JupyterLab, соблюдаем PIP8 и модульную структуру. Какой степ, какая база используется. Дальше конкретно расписали про данные, описали, соответственно, проверены ли качества данных, это дальше помогает составить roadmap и вообще понять, как будут распределены усилия и время на работу с данными. Соответственно, какие требования к данным с точки зрения проверки, этот таб даже, по-моему, в шаблоне его нет, коллеги добавили. Какие риски видят. Не знаю, мне кажется, я просто читаю, я даже не знаю, насколько это ценно сейчас продолжать. На конкретном примере, когда есть задачи, когда есть бизнес-требования, кажется, что здесь у нас картинка общая вырисовывается лучше. Хорошая часть, что как раз описаны ожидания того, какие должны быть данные, чтобы мы продолжили работать дальше. Это тоже ценная штука. Описаны риски. Есть тут, по-моему, некоторые недопонимания, что дизайн-док не сначала пишется. То есть не то, что мы сначала написали до конца дизайн-док и сделали, мы его чуть-чуть написали, пошли к заказчику, к бизнес-заказчику. Бизнес-заказчик уточнил. Мы его чуть-чуть дописали. То есть мы его делаем вместе. И это документ, который уже родился. Просто так получилось, что мы его видели в черновиках с Ириной. В черновиках он был совсем не такой. Не такой прекрасный. Именно в процессе подготовки его они на самом деле очень отлично поработали люди. Они смогли уточнить, что они строят, как они строят, зачем они строят. Чтобы считать успехом, что нужно бизнесу, чтобы использовать модель, что именно эти сегменты нужно выделить. Живым документом. Это живой документ. Дальше вот уже непосредственно про методологию, что будет делать, как построить бейзлайновые прогнозы. Собственно, бейзлайном в данном случае являются прогнозы самих торговых представителей. То есть то, как эти прогнозы угадывают эксперты. Они там имеют свой большой опыт работы в предметной области, могут просто посмотреть на магазин и сказать, что он будет зарабатывать 20 тысяч рублей в месяц или больше 80 тысяч рублей. Дальше мы применяем модель и уже смотрим и угадывают. Смотрите-ка. Собственно, 65 это, скорее всего, точность, кстати, ошибка, мне кажется. Вот. И мы хотим, чтобы модель была с точностью как минимум 80 процентов, чтобы это было существенно выше, чем то, как угадывают просто люди. Вот. Дальше, соответственно, как мы планируем этого достичь, какие метрики используем, собственно, что делаем. Здесь даже прописаны наши два МГП, два этапа. Вот. Оценку спроса делается, как делается модель прогноза продаж. Вот. Дальше, что у нас обязательный этап интерпретации модели. То есть мы должны не только построить что-то, а еще и объяснить, как это работает, чтобы это потом использовали, потому что это, на самом деле, очень важная штука. И, конечно, торговые представители не будут доверять модели, если вы не объясните им, как она работает. Они всегда будут говорить, believe me, я, как бы, знаю этот район, я знаю этот магазин, он точно будет зарабатывать 10 рублей, а ваша модель, понятно, как работает, и буду я ее использовать, пока вы мне не объясните, почему она лучше, чем я. Вот. Дальше, про ансамбль модели. Ну, здесь в технику, мне кажется, проще просто считаться, играться в бизнес-правил. Подготовка к плоту, то, что вопрос возникал, исходя из того, как масштабирование, да, то есть как заранее понять, как мы будем это уже внедрять. Здесь тоже это, в принципе, мы можем договориться с бизнесом, обсудить, в каком формате вам нужны данные, чтобы вы их могли использовать для улучшения текущего бизнес-процесса. Как нам выдать вам прогнозы, чтобы вы их использовали в принятии решений. Вот. В каком виде они должны быть, чтобы вы им поверили и чтобы вы на основе них работали какое-то время. Мы дальше посмотрели. Здесь вот даже, тут как бы АБТ-тест же далеко не всегда мы можем провести. В данном случае он не проводится, но делается оценка адекватности модели другим способом. Вот. То есть мы смотрим, принимаем решение, смотрим, потом закупаем просто исторические данные. Смотрим, на сколько мы попали. Тогда такой вот вопрос касается дизайн-дока, более общий. Будет ли являться с точки зрения проведенного собеседования с инженером для вас плюсом, если человек не обязательно именно обладает вашим шаблоном, но структурность понимания процессов разработки, требований, как мы переходим от бизнес-требований к ML-требованиям. Насколько при собеседовании это важный фактор? Супер важный. Ну, конечно, не на собеседование джуниор-специалисты, наверное, мы это не ожидаем, но от недла ожидаем как бы некое стремление к этому. А сеньоры прям очень хотелось бы, очень хотелось бы структурности. Если человек супер структурный и умеет думать, зачем это нужно и думать про эффект и вообще, он даже не сеньор, наверное. Ну да, я как раз хотел спросить, через это, наверное, можно и построить какие-то грейды, насколько человек верхнеуровневый, поднимаясь над проблемой, может декомпозировать на части задачи. Ну да, здесь, конечно, очень правильно. Ключевое слово в структурности мысли о том, а зачем мы что-то делаем и нужно ли это на самом деле делать, почему станет лучше, это главное. Не главное знать шаблон, не выучить его. Задавать правильные вопросы. Да, главное думать. Тоже вспомнила, что ты спрашиваешь, Олег, как там созрел дизайн-док. Я вспомнила, что я в девятнадцатом году еще читала доклад, когда дизайн-док никакого не было, про интерпретируемость моделей, там разные способы понятия, что хочет бизнес и, собственно, разные способы, как ему объяснить вашу модель, какими там путями, при разных, целях, при разных запросах к интерпретации, запросы на интерпретацию тоже могут быть разные. И заканчивала свой доклад слайдом с главным выводом, что пожалуйста, думайте, очень полезно думать о том, зачем нужна ваша модель, и как она будет использоваться до ее построения. Долго зрела в наших с Димой головах эта мысль и наконец созрела. Ну да. Мне кажется, ты что-то тоже хотел сказать. Как важный фактор. Дмитрий, вижу, что в чате параллельно отвечают. Ну, давайте я скажу. Тут есть на самом деле два повторяющихся вопроса в разных формах. То есть первое, что же делать, если та польза, которую мы приносим заказчику, меньше тех денег, которые мы с него хотим. Ну, что поделаешь. Тут либо вы хотите работать в убыток, либо нет. Либо заказчик хочет, чтобы ему ваш проект принес убыток, либо нет. То есть, ну, по честному, если мы поступаем как ответственные взрослые, не делать проект убыток. Вот и все. Вот. А второй, этот самый, второй вопрос. А как же так раскрутить заказчика, чтобы он заплатил нам за предпроектное обследование? Так и говорите. Я не буду работать с вами, если вы не заплатите мне за предпроектное обследование. Вы говорите, но ведь этот же у нас всего один заказчик во всем мире. Он уйдет от нас. Вот для этого у вас менеджер по продажам. Менеджер по продажам это не человек, который сидит и ждет, пока он позвонит один человек и вас спросит и через губу будет с вами разговаривать. Это тот, который организует вам поток людей, из которого вы сможете выбрать клиента, с которым вы сможете отработать в прибыль. Если у вас этого потока нет, это не вы инженеры плохие, это у вас продажники фиговые. Они могут думать, что они супер продажники. Они просто не продают и все. Пинайте их, пусть работают. То есть, не работайте в убыток. Требуете отстоя пены после долевой пива. Это супер логичный ответ для заказной разработки. Может быть, Алексей имел в виду внутреннюю, то есть, когда в кастом и как монетизируется. Наверное, нет. Но оплата работы на стадии шлифования договоренности, ну и зарплата. Люди на внутренней разработке зарплату получают. Этот этап уже заложен в этап разработки. Все эти процессы должны быть уже... Да, во внутренней разработке бизнес чаще всего прекрасно может сформулировать, что он хочет. Я хочу, чтобы у меня работало, чтобы у меня тут было видно, я нажимал и у меня пересчитывалось. Дальше вы говорите, что чтобы так было и чтобы понять, смогу ли я это сделать и за сколько я смогу это сделать. Ответь мне на вот эти раз-два-три-четыре-пять-двадцать вопросов. Пока ты мне не ответишь, я тебе не скажу, смогу я сделать или нет, и сколько мне нужно там времени и какую команду. Да, согласен. Саша, у вас... Я поднял руку, у вас сейчас, наверное, с Дмитрием примерно часов двенадцать. Разница, наверное. У меня минус шесть от Москвы. У Дмитрия плюс семь, да? Нет, плюс четыре. А, ну десять получается. У меня вопрос к Ирине. Вот вы начали про собеседование говорить, я, конечно, могу ошибаться. Это не вы год-два назад на Ёлке вредные советы делали? Я давала, да. О, я помню, это классно. Тогда лично спасибо, я помню это видео. Пожалуйста. Отлично. Может быть, если будет ресурс время позволять, какой-то из следующих встреч посвятить в другом формате, посмотреть через собеседование, либо какой-то такой вот карьерный трек развития. Ребята, если есть еще вопросы... У меня, кстати, спойлер, могу сделать спойлер. Минутка рекламы на нашей секции с dima.reliable.ml. 3-4 июня будет секция. Во-первых, будет дата-фест с 20 чисел мая с кучей секций. Там будет и наша секция, она пройдет 3-4 июня. Мы об этом даже еще не объявили, но объявим. У нас планируется активность с реал-тайм собеседованием по ML-системе дизайну. И вообще по дизайн-доку, кстати, тоже планируется классная активность. В канале все напишем. Нужно будет заранее записаться или там в спейшл-чат или где-то? Чтобы прийти послушать, ну там зарегаться просто нужно, но это можно сделать в последний момент, в принципе. Вот. Но в части именно, чтобы поучаствовать, то есть словно пройти это собеседование по ML-системе дизайна или поучаствовать в активности с написанием дока, таким быстрым обсуждением, как в группах. Вот. Нужно будет записаться. Мы все это вводим. Ребята самоорганизовались, тоже сформировали клуб, куда приглашают экспертов и проводят собеседование. Никуда, поэтому думаю, что там желающие точно будут. Несколько общих достаточно вопросов, если позволите, так как в любом случае у нас достаточно много ребят находятся в карьерном переходе, ну даже из тех, кто и работает в ДС и даже выше джуниерской позиции, все равно всегда рынок исследует, смотрит. Пару слов вообще в принципе по тенденциям, по навыкам, потому что у нас в первую очередь ML-инженеры, тем не менее кто-то больше смотрит в сторону классического ДС, кто-то в даты инженера и так далее. То есть какое-то вот такое сейчас понимание рынка. Ну вот Саша всегда любит по вилкам даже, если там сможете сказать, насколько это позволяет. Они так своей может быть компанией, ну понимая, что где вы. Вы сразу начинаете, нормально же общались. Это всегда, да, все ребята всегда уже в конкретику переходят. Вот такое общее сейчас по тенденциям, по рынку в целом, по рынку труда. Ну, не знаю, тут Дима может меня дополнить, если такое прям общее наблюдение, то кажется, что в целом здесь несколько моментов. Вообще в целом в дата профессии там, что Data Science, что ML-инженер там, как ни назови, зрелость рынка стала сильно выше, чем была. Условия изменились, конкуренция с точки зрения хардов выше и, в принципе, во многом выравнивается история, то есть условно довольно много людей, у которых хорошо прокачаны харды. То есть это как становится by default, то есть по умолчанию. Вот, при этом в таком случае как раз вот структурность мышления, способность думать о том, как вы выстроите исследование, как сделать его полезным, принести компании, веньги и все остальное, она выделяет вас гораздо больше, чем раньше. То есть раньше там условно умею FitPredict запускать, уже там можно сеньором устраиваться как бы. Вот, а сейчас чуть больше людей умеют делать FitPredict, умеют делать их хорошо, там деплоить модели, разрабатывать все ключевые этапы разработки, совершать. Вот. Вот это первая история, которую хотела сказать. И второе, наверное, момент в том, что, конечно, такое наблюдение по индустрии тоже вот, что, собственно, само слово там ML-инженер, очень многие компании могут понимать по-разному. Вот. И, ну, реально там единства нет. Вот недавно там я тоже, меня просили дать отзыв про один коммерческий курс про ML-инженеров. Я там дала отзыв. Говорю, ну, у вас же не совсем на то акценты. ML-инженер, он уже в этом, больше там акцент на деплое моделей, как бы вывод в прот, там всякую, может быть, ближе к MLOps, DevOps-историям. Там со мной начали спорить. В общем, поняли, что? Я думала уже, здесь у нас есть единство. Оказалось, что нет. И, в принципе, вообще, с точки зрения, чем отличается, как бы, с точки зрения определения, когда-то scientist и ML-инженер, когда он должен быть, когда он не должен быть. Вот это тоже такая холиварная дискуссионная история. Собственно, мы с Димой в начале года сделали опросы, какие темы были бы интересны, чтобы мы о них что-то написали в канале. Вот. И тема data scientist versus ML-инженер, она в топе с отрывом. Вот. И в целом мы тоже собираемся этой темой коснуться на секции. Кажется, что туда сейчас и data-инженер может добавиться с точки зрения разделения функционала и необходимости. Это тоже, кстати, вот заметила, вот недавно заметила, может быть, сформировалось это более давно, но что часто стали для data-инженера, как бы, в их сколп эти обязанности, стал ходить MLops. Типа, если они умели работать, это тоже интересный тренд. Я об этом узнала не так давно. Вообще, я много разговариваю, Дима, наверное, тоже что-то скажет. Ну, у меня следующее. То есть сейчас на рынке труда резко упал спрос на джунгов. Все хотят, чтобы все рождались медлами, еще лучше сеньорами. С промышленным опытом еще. Да, да, с медлами, с промышленным опытом, чтобы он сразу с пеленок был. И частично эту ситуацию создали, создала образовательная индустрия. Потому что несколько лет назад как-то мы беседовал с одним молодым человеком, он говорит, вот, говорит, через год я буду питомным медлом. Я говорю, как ты к этому придешь? Ну, как, я, говорит, оплатил денег, говорит, вот тут, говорит, курс, я не буду называть поставщика, но, в общем, известный. Вот, и вот у них ты по окончании курса, ты middle питом backend разработчик. Я говорю, о, клево, так вот прямо, middle по окончании курса, да. И вот эти люди, они приходят и они уверены, что их много. Вот, но они не медлы, конечно, что уж там. Вот. Про медлов, джунов и сеньоров есть, на самом деле, хорошее определение, что дети делают, взрослые разговаривают, старики смеются. Это вот как раз вот так устроена разработка программного обеспечения. Вот, то есть попросту говоря, джун это человек, который в принципе способен решить задачу, не способен решить задачу без поддержки, без помощи. То есть ему нужно с кем-то консультироваться. Middle способен. То есть ты ему дал задачу, он решил. Вот. А сеньор способен видеть мир за пределами задачи. То есть он может увидеть, когда решение этой задачи не нужно, создаст проблемы или надо решать вместо нее другую задачу. Вот. И таким образом спрос на медлов просто означает, что рынок хочет прямо сейчас, не хочет заниматься самообразовательной деятельностью, хочет брать людей, которых можно ставить к станку. Это вообще-то нормальное желание зрелого рынка. Но образование не решает эту проблему. Она ее поддержала, ее создание, но не решает никак. Вот. Кроме всего прочего, в связи с некоторыми структурными изменениями в экономике у нас есть движение по типу, как вот в свое время в Южной Корее было, когда несколько крупных корпораций на самом деле делают все в стране. Вот. То есть Samsung, например, он делает, если я ничего не путаю, он делает гаубицы, он делает телефоны. По-моему, ледокол он делает. Вот. И мы вынужденным образом идем к вот такой же вертикальной интеграции. Это не хорошо, не плохо, это просто экономическая реальность. Поэтому мой совет молодежи идите в Сбер, идите в Райф, идите в Яндекс, туда идите, потому что Data Science там. То есть Data Science за пределами, и тот Data Science, о котором вы читаете в книжках и в блогах, он там. А фирмы мелкого размера, которые способны заниматься Data Science, это статистическая ошибка такая, как мой, допустим. Вот. Вот вам и рынок труда. Сейчас рынок Data Science, это будут крупные компании. А какой там планктон утелеет, ну как повезет. Как будет лапками махать. Дмитрий, это скорее как тренд прослеживается или это скорее в целом всегда так, что большая разработка и масштаб. Это сейчас так. Вот. Но в принципе всегда данные, для анализа данных нужны данные. То есть чтобы вы там себе не нафантазировали, пока у вас нет данных, у вас нет ML. Вы можете прекрасно уметь запускать предикты и учить ResNet на кошечках и собачках, но пока у вас нет живых данных клиентов, вы ничего на самом деле, вы Data Science не делаете. Вы просто этого с фантазией. Вот. И в какой-то момент у нас было следующее. Когда рынки были более открыты, вы спокойно могли сидеть в Москве или в Ульяновске и работать на Россию, Америку, Австралию и в этом большом океане можно было найти себе легко нишу. Вот. В существующем, это не только у нас из... Не надо думать, что это у нас из-за вот этих вот последних структурных изменений. Та же самая история сейчас по всему миру идет. Просто я думаю, что это вот такое экономическое состояние, когда мир стал немножко жестче. Надо смотреть лицо фактам, надо ориентироваться на то, что если вы хотите заниматься анализом данных, вам надо попытаться попасть в корпорацию, которая это делает. Огромное количество интересных вакансий из берега. Да, ну, те, кто владеет данными, те, кто определенную монополию в рамках клиентского сервиса, банковского сервиса, владеет большими данными, соответственно, способен запускать новые какие-то фронтирные технологии. Наверное, это действительно так. Многие ребята, в принципе, у нас в этих компаниях и работают.