
- 20.02.2024
- 01.10.2025
- выступления
- #NLP
На канале DS Talks разбирали статью Seven Failure Points When Engineering a Retrieval Augmented Generation System.
Слайды: gpts_are_gpts.pdf
Текстовая расшифровка, сделана нейронной сетью, еще не вычитана:
 Ну, отлично. Я хочу рассказать про эту статью, потому что мы как раз сейчас занимаемся RAG, и я все связанное с RAG читаю, и некоторые статьи интереснее, чем другие. Статья «Seven Failure Points When Engineering a Retrieval Augmented Generation System. Статья написана группой австралийских исследователей. Я про них ничего раньше не знал, пошел смотреть, кто они такие и почему они вообще пишут такие статьи.
Ну, отлично. Я хочу рассказать про эту статью, потому что мы как раз сейчас занимаемся RAG, и я все связанное с RAG читаю, и некоторые статьи интереснее, чем другие. Статья «Seven Failure Points When Engineering a Retrieval Augmented Generation System. Статья написана группой австралийских исследователей. Я про них ничего раньше не знал, пошел смотреть, кто они такие и почему они вообще пишут такие статьи.
 Университет Deakin, австралийский университет. Довольно-таки большой, 60 тысяч студентов. Это при 29 миллионах населения Австралии. 14-й в австралийском рейтинге, то есть там еще 13 университетов круче, чем этот. 200-й какой-то в мировых рейтингах. По ассортименту курсов, и факультетам напомнил мне Воронежский университет.
Университет Deakin, австралийский университет. Довольно-таки большой, 60 тысяч студентов. Это при 29 миллионах населения Австралии. 14-й в австралийском рейтинге, то есть там еще 13 университетов круче, чем этот. 200-й какой-то в мировых рейтингах. По ассортименту курсов, и факультетам напомнил мне Воронежский университет.
 И это конкретно его кафедра, отвечающая за искусственный интеллект. Кафедра довольно практичная, у них есть исследования по машинному обучению в баллистике неожиданно, то есть они предсказывают бронепробиваемость. По causal inference интересные вещи, по безопасности ML систем, в том числе, например, у них интересная статья про то, как ловко воровать чужие модели с минимальным бюджетом. Толковые ребята.
И это конкретно его кафедра, отвечающая за искусственный интеллект. Кафедра довольно практичная, у них есть исследования по машинному обучению в баллистике неожиданно, то есть они предсказывают бронепробиваемость. По causal inference интересные вещи, по безопасности ML систем, в том числе, например, у них интересная статья про то, как ловко воровать чужие модели с минимальным бюджетом. Толковые ребята.
 Интересная комбинация исследователей. Самый титулованный автор, первый в статье, про МЛ никогда ничего не писал. Он занимался каким-то прикладным материаловедением, чем-то еще. Думаю, что он заказчик этих систем. Этот веселый парень завлаб, у него тоже много научных статей. Внизу два инженера, у них ни одной научной статьи, кроме этой, и они даже на кафедре работают просто инженерами. Пследний - возможно тимлид, профессор. У него есть толковая статья по сбору требований к ML-системам.
Интересная комбинация исследователей. Самый титулованный автор, первый в статье, про МЛ никогда ничего не писал. Он занимался каким-то прикладным материаловедением, чем-то еще. Думаю, что он заказчик этих систем. Этот веселый парень завлаб, у него тоже много научных статей. Внизу два инженера, у них ни одной научной статьи, кроме этой, и они даже на кафедре работают просто инженерами. Пследний - возможно тимлид, профессор. У него есть толковая статья по сбору требований к ML-системам.
 .
И что они в своей статье написали? То есть они строили RAG-системы и почему вообще говоря RAG-системы мы строим, почему мы не файнтюним LLM и так далее и тому подобное. Мы хотим, чтобы нам LLM отвечала на вопросы и знала все о нашей доменной области. Доучивать ее долго, дорого и неудобно. Поэтому мы делаем какую-то поисковую систему по текстам, режем кусочки текстов, добавляем в промп, получаем генерацию дополненную поиском, то есть RAG. И вот они эти самые RAG-ы строили для нужд кафедры.
.
И что они в своей статье написали? То есть они строили RAG-системы и почему вообще говоря RAG-системы мы строим, почему мы не файнтюним LLM и так далее и тому подобное. Мы хотим, чтобы нам LLM отвечала на вопросы и знала все о нашей доменной области. Доучивать ее долго, дорого и неудобно. Поэтому мы делаем какую-то поисковую систему по текстам, режем кусочки текстов, добавляем в промп, получаем генерацию дополненную поиском, то есть RAG. И вот они эти самые RAG-ы строили для нужд кафедры.
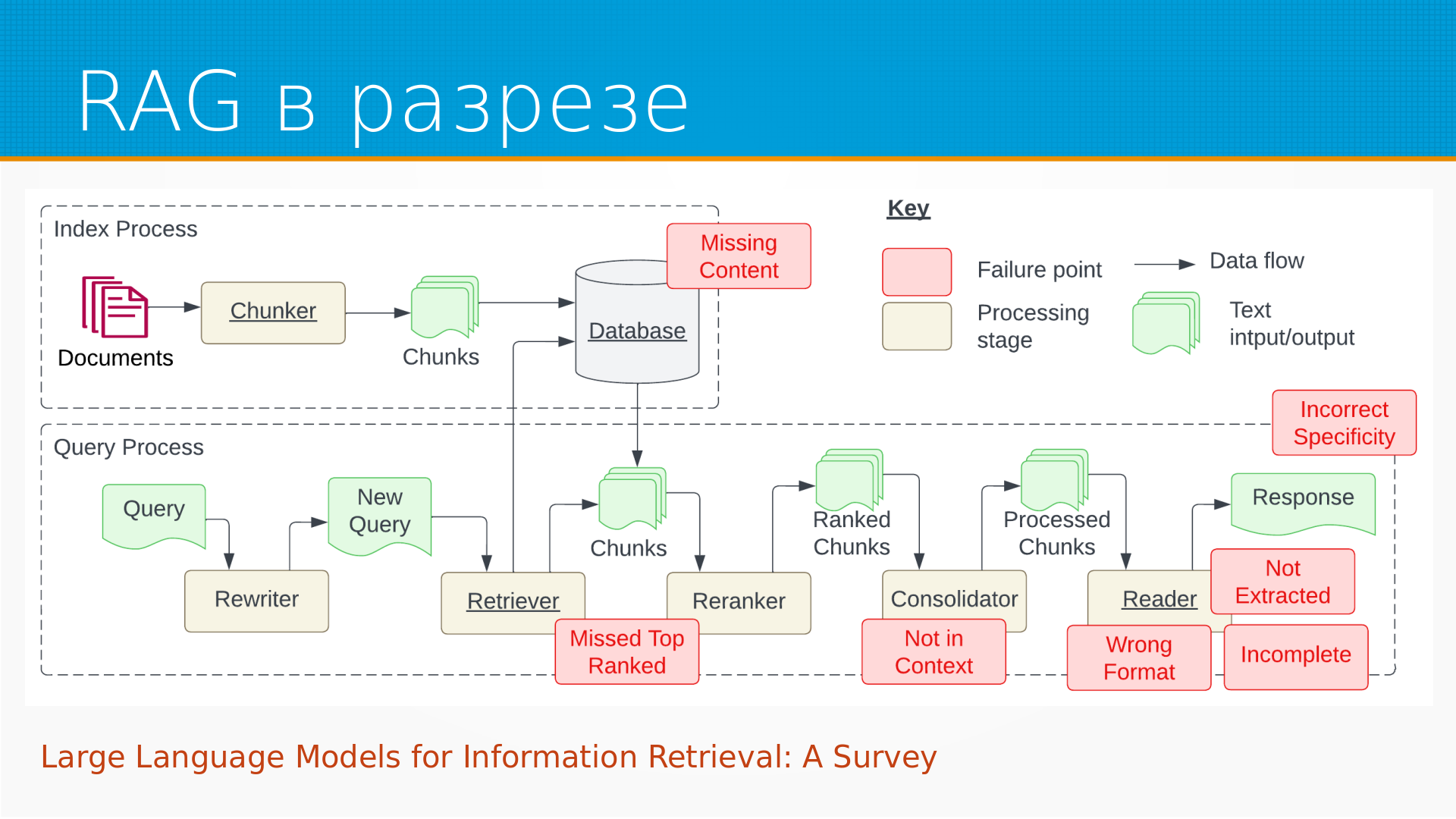 В этой статье на самом деле мне понравилась вот эта картинка. Они ее взяли из базовой статьи про RAG и красиво раскрасили. То есть как у них устроен RAG в их представлении. То есть вся общая статья – это хороший такой чертеж, как инженеры делают RAG. То есть мы берем документы, каким-то образом накручиваем нарезку их на кусочки начатки, складываем в базу данных, затем к нам поступает запрос от пользователя, мы его скорее всего переписываем, то что у Яндекса называется колдунщик, и уже новый запрос мы отдаем в ретривер. Ретривер, он вытаскивает из базы данных наиболее похожие на запрос кусочки, переранжирует их, как-то отбирает самое хорошее и прогоняет, возможно, через консолидатор, который из них, из этой большой кущи кусочков делает какой-то текст, который мы уже добавляем в промпт и отдаем языковой модели. Языковая модель на основании этого отвечает. Это все здорово, это позволяет делать умные поиски вопросно-ответные системы по корпоративной документации, например, и куча проблем возникает в процессе.
В этой статье на самом деле мне понравилась вот эта картинка. Они ее взяли из базовой статьи про RAG и красиво раскрасили. То есть как у них устроен RAG в их представлении. То есть вся общая статья – это хороший такой чертеж, как инженеры делают RAG. То есть мы берем документы, каким-то образом накручиваем нарезку их на кусочки начатки, складываем в базу данных, затем к нам поступает запрос от пользователя, мы его скорее всего переписываем, то что у Яндекса называется колдунщик, и уже новый запрос мы отдаем в ретривер. Ретривер, он вытаскивает из базы данных наиболее похожие на запрос кусочки, переранжирует их, как-то отбирает самое хорошее и прогоняет, возможно, через консолидатор, который из них, из этой большой кущи кусочков делает какой-то текст, который мы уже добавляем в промпт и отдаем языковой модели. Языковая модель на основании этого отвечает. Это все здорово, это позволяет делать умные поиски вопросно-ответные системы по корпоративной документации, например, и куча проблем возникает в процессе.
 То есть, если посмотреть, как RAG строится, то это прежде всего предобработка артефактов, это их извлечение нарезка, это сохранение и извлечение их из хранилища и, в общем, добавление в промпт-таллим и везде тут можно наступить на кинди-грабли.
То есть, если посмотреть, как RAG строится, то это прежде всего предобработка артефактов, это их извлечение нарезка, это сохранение и извлечение их из хранилища и, в общем, добавление в промпт-таллим и везде тут можно наступить на кинди-грабли.
 Какие-то вопросы они ставили перед исследованием. На какие грабли обычно наступают, когда такие системы строят? И о чем надо думать, когда мы рэк-системы строим, куда смотреть? Каким выводом они пришли? Что пока мы рэк-систему не построим, мы не поймем, хорошо мы ее задумали или нет. То есть пока не попробуешь, не оценишь. Validation of rэк-system is only feasible during operation. Ну и они говорят, что надежность RAG-системы она такая штука, что вы не можете построить, запланировать надежную RAG-систему. То есть, чтобы вы там не запланировали себе, все равно она будет где-то ломаться, и вам надо ее эволюционировать, а не то, что вы там придумали надежную систему, построили она и сделали. Грустные выводы на самом деле, но... Тем не менее.
Какие-то вопросы они ставили перед исследованием. На какие грабли обычно наступают, когда такие системы строят? И о чем надо думать, когда мы рэк-системы строим, куда смотреть? Каким выводом они пришли? Что пока мы рэк-систему не построим, мы не поймем, хорошо мы ее задумали или нет. То есть пока не попробуешь, не оценишь. Validation of rэк-system is only feasible during operation. Ну и они говорят, что надежность RAG-системы она такая штука, что вы не можете построить, запланировать надежную RAG-систему. То есть, чтобы вы там не запланировали себе, все равно она будет где-то ломаться, и вам надо ее эволюционировать, а не то, что вы там придумали надежную систему, построили она и сделали. Грустные выводы на самом деле, но... Тем не менее.
 Какие системы они строили? Они построили три вопросно-ответные системы. Первая Cognitive Retriever. Он прямо сейчас используется у них в универе для поддержки аспирантов, помогает делать им литобзоры. То есть это система в проде. AI tutor – система, которая поддерживает студентов во время решения домашних заданий. Студент получает задачу и начинает тупить и говорит «Слушайте, вот что-то я туплю, а почему это вот так получается?» AI Tutior его поддерживает - подсказывает, учит, но ответ не дает, а дает умные, наводящие вопросы. И третью систему, Biomedical Question and Answer, это вот как раз BioACQ датасет. Они с ним экспериментировали, но в прод она у них не вышла. Скорее всего, потому что их не устроило качество.
Какие системы они строили? Они построили три вопросно-ответные системы. Первая Cognitive Retriever. Он прямо сейчас используется у них в универе для поддержки аспирантов, помогает делать им литобзоры. То есть это система в проде. AI tutor – система, которая поддерживает студентов во время решения домашних заданий. Студент получает задачу и начинает тупить и говорит «Слушайте, вот что-то я туплю, а почему это вот так получается?» AI Tutior его поддерживает - подсказывает, учит, но ответ не дает, а дает умные, наводящие вопросы. И третью систему, Biomedical Question and Answer, это вот как раз BioACQ датасет. Они с ним экспериментировали, но в прод она у них не вышла. Скорее всего, потому что их не устроило качество.
 Датасеты в принципе не очень большие. Cognitive Retriever, которым их Ph.D. студенты пользуются, он как бы неограниченного размера, то есть ищет по статьям в интернетах. AI Tutor использует всего 38 документов. BioQA, он использовал 4000 документов из биологического домена. Что интересно, у двух первых систем был модуль рерайтер, который допиливал вопросы до нужного качества. А у последнего такого рерайтера не было. Возможно, это и было причиной низкого качества. Они выявили 7 базовых точек отказа в RAG-системах и поделились материалами. Для двух первых систем они не выкладывали вопросы и ответы из соображений приватности. Для последней системы они собрали набор вопросов для оценки и обстоятельно провели оценку качества. Мне понравилось. Отчеты по оценке качества авторы выложили в открытый доступ. Я вот оттуда кусочки понадергал с иллюстрацией.
Датасеты в принципе не очень большие. Cognitive Retriever, которым их Ph.D. студенты пользуются, он как бы неограниченного размера, то есть ищет по статьям в интернетах. AI Tutor использует всего 38 документов. BioQA, он использовал 4000 документов из биологического домена. Что интересно, у двух первых систем был модуль рерайтер, который допиливал вопросы до нужного качества. А у последнего такого рерайтера не было. Возможно, это и было причиной низкого качества. Они выявили 7 базовых точек отказа в RAG-системах и поделились материалами. Для двух первых систем они не выкладывали вопросы и ответы из соображений приватности. Для последней системы они собрали набор вопросов для оценки и обстоятельно провели оценку качества. Мне понравилось. Отчеты по оценке качества авторы выложили в открытый доступ. Я вот оттуда кусочки понадергал с иллюстрацией.
 .
Самая первая точка отказа это отсутствующий контент. То есть мы спрашиваем что-то нашу или ремку она ищет в нашей векторной базе, но на эти вопросы в наших документах, которые у нас там проиндексированы, ответа просто нет. Нам бы конечно хотелось, чтобы система в таких случаях сказала, но я не знаю. Но проблема в том, что если есть какие-то кусочки очень похожие на то, что мы спросили, то у модели будет какой-то похожий контент, и она что-нибудь сгаллюцинирует. Вот. Ну и вот тут пример такой ошибки. Ее модель спрашивает, какова цель CHPP проекта. Она говорит, ну, из той информации, которую я обладаю, сказать об этом нельзя. вот и объяснение от авторов ну действительно документ не в одном из документов которые модель индексировала про эту систему ничего не было написано
.
Самая первая точка отказа это отсутствующий контент. То есть мы спрашиваем что-то нашу или ремку она ищет в нашей векторной базе, но на эти вопросы в наших документах, которые у нас там проиндексированы, ответа просто нет. Нам бы конечно хотелось, чтобы система в таких случаях сказала, но я не знаю. Но проблема в том, что если есть какие-то кусочки очень похожие на то, что мы спросили, то у модели будет какой-то похожий контент, и она что-нибудь сгаллюцинирует. Вот. Ну и вот тут пример такой ошибки. Ее модель спрашивает, какова цель CHPP проекта. Она говорит, ну, из той информации, которую я обладаю, сказать об этом нельзя. вот и объяснение от авторов ну действительно документ не в одном из документов которые модель индексировала про эту систему ничего не было написано
 вторая точка отказа ожидаемая это объект был в базе данных. И он даже был в найденных кусочках, но поскольку мы не можем все найденные кусочки сложить в промп, мы берем некоторое количество самых релевантных, он в них не попал. И вот тут тоже пример, какие аналоги тироидных гормонов используются в исследованиях на людях. И, в общем, ответ очевидно неправильный. и объяснения, которые они предлагают, что нужная информация была, но документ был 15 по порядку, а они брали первые 4. И вот тут, если помните, мы говорили, что они не использовали рерайтер, и вот скорее всего из-за того, что они не использовали рерайтер, у них вот эта проблема ранжирования не была, потому что он ее хорошо лечит.
вторая точка отказа ожидаемая это объект был в базе данных. И он даже был в найденных кусочках, но поскольку мы не можем все найденные кусочки сложить в промп, мы берем некоторое количество самых релевантных, он в них не попал. И вот тут тоже пример, какие аналоги тироидных гормонов используются в исследованиях на людях. И, в общем, ответ очевидно неправильный. и объяснения, которые они предлагают, что нужная информация была, но документ был 15 по порядку, а они брали первые 4. И вот тут, если помните, мы говорили, что они не использовали рерайтер, и вот скорее всего из-за того, что они не использовали рерайтер, у них вот эта проблема ранжирования не была, потому что он ее хорошо лечит.
 Третья точка отказа – Notes in Context, то есть Если помните, на схеме RAG в разрезе, там был момент консолидации найденных кусочков перед запичиванием в промпт. То есть нужная информация была в кусочках, но консолидатор ее выкинул. В результате модель ее не увидела. Почему так бывает? Когда мы слишком много кусочков собрали и их надо как-то предобрабатывать, у нас мы можем выкинуть нужную информацию.
Третья точка отказа – Notes in Context, то есть Если помните, на схеме RAG в разрезе, там был момент консолидации найденных кусочков перед запичиванием в промпт. То есть нужная информация была в кусочках, но консолидатор ее выкинул. В результате модель ее не увидела. Почему так бывает? Когда мы слишком много кусочков собрали и их надо как-то предобрабатывать, у нас мы можем выкинуть нужную информацию.
 Точка отказа это нужная информация была в дата-сети, но вопросно-ответная система не ответила на неё, то есть она не использовала её при ответе. Но когда в найденных кусочках много разных и противоречивых каких-то утверждений, а это легко может быть, потому что когда рак делают, его текст режут на кусочки довольно-таки бессмысленных, как попало, и в нём получается много шума и противоречий.
Точка отказа это нужная информация была в дата-сети, но вопросно-ответная система не ответила на неё, то есть она не использовала её при ответе. Но когда в найденных кусочках много разных и противоречивых каких-то утверждений, а это легко может быть, потому что когда рак делают, его текст режут на кусочки довольно-таки бессмысленных, как попало, и в нём получается много шума и противоречий.
 Пятая базовая точка отказа – это неверный формат, то есть модель ответит, куда шел предикт модели, то есть живой человек, это может быть и хорошо. А если мы хотели использовать модель дальше, где-то в цепочке, как это часто бывает, то вся остальная цепочка сломается. Ну вот, допустим, просили список или GSUM. То есть, в принципе, вот тут на примере ответ более-менее правильный, но он дан не в виде списка, а в виде предложения. И вот тут от меня дополнение. Есть такая интересная библиотека Instructor, которая позволяет писать pydantic-модели для ответа LLM. И в случае, если ответ не проходит через вот эту pydantic-модель, Но на его повтор на некоторое количество раз лент пинаются в надежде, что все-таки какой-то ответ из нее выпадет.
Пятая базовая точка отказа – это неверный формат, то есть модель ответит, куда шел предикт модели, то есть живой человек, это может быть и хорошо. А если мы хотели использовать модель дальше, где-то в цепочке, как это часто бывает, то вся остальная цепочка сломается. Ну вот, допустим, просили список или GSUM. То есть, в принципе, вот тут на примере ответ более-менее правильный, но он дан не в виде списка, а в виде предложения. И вот тут от меня дополнение. Есть такая интересная библиотека Instructor, которая позволяет писать pydantic-модели для ответа LLM. И в случае, если ответ не проходит через вот эту pydantic-модель, Но на его повтор на некоторое количество раз лент пинаются в надежде, что все-таки какой-то ответ из нее выпадет.
 Шестая рассмотренная точка отказа – это некорректная специфичность. То есть ответ получен, но он или слишком общий, либо слишком конкретный. Такое бывает, когда на самом деле человек не очень понимает, как задать вопрос. И вот с этой проблемой они столкнулись во время объяснения студентам, которые объясняют студентам, как же надо правильно решать задачи. Потому что студенту недостаточно дать правильный ответ, надо дать такой ответ, который находится на границе его понимания, чтобы он его еще понял и он его продвинул. то есть ну это достаточно сложная вещь и как с этим бороться не очень понятно вот то есть как управлять степенью генерализации в ответе общности
Шестая рассмотренная точка отказа – это некорректная специфичность. То есть ответ получен, но он или слишком общий, либо слишком конкретный. Такое бывает, когда на самом деле человек не очень понимает, как задать вопрос. И вот с этой проблемой они столкнулись во время объяснения студентам, которые объясняют студентам, как же надо правильно решать задачи. Потому что студенту недостаточно дать правильный ответ, надо дать такой ответ, который находится на границе его понимания, чтобы он его еще понял и он его продвинул. то есть ну это достаточно сложная вещь и как с этим бороться не очень понятно вот то есть как управлять степенью генерализации в ответе общности
 и неполный ответ это когда модель ответил на половину вопроса То есть, например, если мы модель спросим, любишь ли ты смородиновое варенье и бутерброды с хлебом. То есть мы задали ей фактически два вопроса и она на что-нибудь из них ответит. И вот тут пример такого сложного ошибочного вопроса. какие гормональные нарушения обычны при синдроме Уильямса. И вот она отвечает слишком обще, а ниже пример того, как люди хотели, чтобы она ответила. Там по ссылке прямо в Excel документы примеры вопросов, примеры проблем и так далее.
и неполный ответ это когда модель ответил на половину вопроса То есть, например, если мы модель спросим, любишь ли ты смородиновое варенье и бутерброды с хлебом. То есть мы задали ей фактически два вопроса и она на что-нибудь из них ответит. И вот тут пример такого сложного ошибочного вопроса. какие гормональные нарушения обычны при синдроме Уильямса. И вот она отвечает слишком обще, а ниже пример того, как люди хотели, чтобы она ответила. Там по ссылке прямо в Excel документы примеры вопросов, примеры проблем и так далее.
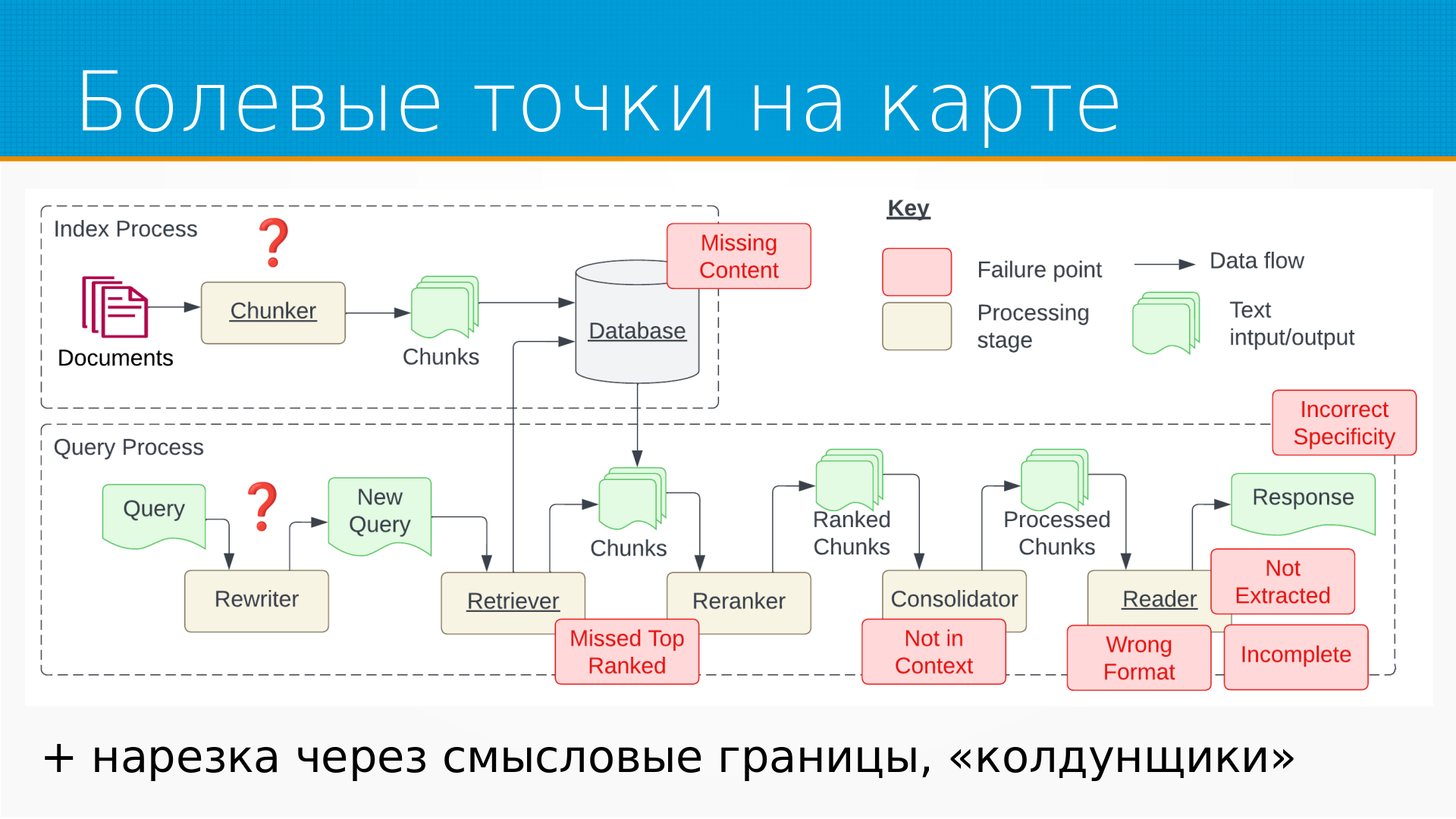 Если вернуться к вот этой карте Рега, то красными как раз прямоугольничками они отметили все вот эти болевые точки. Интересно, что они ничего не сказали о двух самых очевидных болевых точках, которые вот я вижу. Вот. То есть вообще такое в индустрии мнение, что самый большой враг рэк-систем это чанкер. То есть, когда мы берем наши документы и начинаем их резать на кусочки, чтобы потом их искать и подкладывать в промпт, мы можем, во-первых, некорректно резать их. То есть, мы можем, например, резать их по границам предложения, по точкам. Не дай бог, у нас там точка в середине текста, число какое-нибудь или специальное обозначение будет. Мы можем резать их, например, по длине какими-то правилами и легко разрезать предложение по смыслу посередине или абзац посередине. Мы, в общем, можем полагаться на то, что человек разумно отформатировал абзацы, но и тут мы бываем неправы. Самый, пожалуй, продвинутый способ делать чанкеры – это когда специальная языковая модель Вот, она конкретно делает чанки. То есть, когда у нас чанки не регулярками, не какими-то правилами, а другой языковой моделью. Но это достаточно дорого и медленно. Вот. И второй вопрос, к которому они совсем не коснулись, это рерайтер. то есть нам приходит вопрос вот допустим если помните лет например 10 назад яндекс такую штуку придумал колдунчик вы ищите билет в берлин например а он авиаперелет в германию и вот такие вещи расширял ваш запрос А в REC-системах это сейчас вполне хорошо работает. И для рерайтинга используются тоже языковые модели, причем есть такая, например, интересная техника, гипотетического ответа, когда мы берем вопрос и говорим языковая модель, а сочини примерный ответ на этот вопрос, каким бы он был. Она сочиняет и затем мы начинаем искать чанки похожие не на вопрос, а на ответ, что вообще-то говоря логичнее, потому что ответы вопрос могут в разных доменах лежать да вот и вот нарезка через смысловые границы колдунчики они почему-то пропустили такие
Если вернуться к вот этой карте Рега, то красными как раз прямоугольничками они отметили все вот эти болевые точки. Интересно, что они ничего не сказали о двух самых очевидных болевых точках, которые вот я вижу. Вот. То есть вообще такое в индустрии мнение, что самый большой враг рэк-систем это чанкер. То есть, когда мы берем наши документы и начинаем их резать на кусочки, чтобы потом их искать и подкладывать в промпт, мы можем, во-первых, некорректно резать их. То есть, мы можем, например, резать их по границам предложения, по точкам. Не дай бог, у нас там точка в середине текста, число какое-нибудь или специальное обозначение будет. Мы можем резать их, например, по длине какими-то правилами и легко разрезать предложение по смыслу посередине или абзац посередине. Мы, в общем, можем полагаться на то, что человек разумно отформатировал абзацы, но и тут мы бываем неправы. Самый, пожалуй, продвинутый способ делать чанкеры – это когда специальная языковая модель Вот, она конкретно делает чанки. То есть, когда у нас чанки не регулярками, не какими-то правилами, а другой языковой моделью. Но это достаточно дорого и медленно. Вот. И второй вопрос, к которому они совсем не коснулись, это рерайтер. то есть нам приходит вопрос вот допустим если помните лет например 10 назад яндекс такую штуку придумал колдунчик вы ищите билет в берлин например а он авиаперелет в германию и вот такие вещи расширял ваш запрос А в REC-системах это сейчас вполне хорошо работает. И для рерайтинга используются тоже языковые модели, причем есть такая, например, интересная техника, гипотетического ответа, когда мы берем вопрос и говорим языковая модель, а сочини примерный ответ на этот вопрос, каким бы он был. Она сочиняет и затем мы начинаем искать чанки похожие не на вопрос, а на ответ, что вообще-то говоря логичнее, потому что ответы вопрос могут в разных доменах лежать да вот и вот нарезка через смысловые границы колдунчики они почему-то пропустили такие

И вот уроки они извлекли. Просто вследствие того, что в большом контексте реже попадается разрезание смысла посередине. То есть у нас таких меньше смысловых щепок. Но это же повышает и зашумленность. В принципе, если бы у нас языковая модель могла работать с очень большим контекстом, нам бы нужно было меньше их сортировать и мы могли бы больше позволить себе запихать информацию туда. Вот. Дальше они говорят, что, используя семантическое кэширование, мы и снижаем стоимость всего этого счастья, и снижаем задержки на обработке. О чем это семантическое кэширование? То есть, когда мы отправляем запрос в модель, нам приходит от модели ответ, например. То есть, например, какие ягоды любят медведи? И хорошо было бы как-то этот ответ закэшировать на случай, если мы еще раз спросим. Но если мы чуть-чуть запрос изменим, вместо, допустим, какие ягоды любят медведи, отправим запрос, какие ягоды любимы медведями. То есть по смыслу запрос один и тот же абсолютно, но мы вместо этого отправим ее снова в языковую модель. Вот есть библиотека для семантического кэширования, которая смотрит То есть там ключи кэша семантически проверяет, не было ли очень похожего запроса. Если был, то он берется из кэша. Это здорово. Снижает расходы на чат GPT и ускоряет ответ. Jailbreaking – это когда студент что-нибудь такое впихает и, в общем, может надругаться над моделью. Вот. Урок такой, что добавление метадаты улучшает ретриву. И это, кстати, важный тоже момент, потому что в исходной статье про RAG они просто предлагали, вот давайте нарежем всю нашу информацию и будем искать ее как-нибудь в базе данных, потом добавим в PROMT, случится у нас чудо. На самом деле, если у вас есть какая-то метаинформация, которая позволяет разумно отфильтровать, вот эти чанки, прежде чем искать векторные близости. Это здорово повышает качество. Дальше одно из наблюдений, которое они сделали, это что опенсоверсные модели для эмбеддинга, то есть они пробовали и чат GPT-шные эмбеддинги и всякие открытые эмбеддинги. Для маленьких текстов они достаточно хороши, на больших все-таки чат GPT лучше. Вот. Один из уроков, что Rag System Require Continuous Calibration. В том смысле, что работают они неустойчиво. Все время надо ходить вокруг нее и подкручивать. Вот. И никак, кроме как мониторингом, этого не решишь. И следующий урок относится к этому же, что на самом деле нам все время придется подбирать прямо размер чанка, эмбейдинги, стратегию порезки на чанки. Есть такой подход как герархические чанки, когда мы режем маленькие чанки, побольше, еще побольше. И в зависимости от того, что мы там нашли, мы на самом деле в промп добавляем чанки более высокого уровня. То есть мы ищем среди мелких, добавляем высокие и так далее. Вот. Интересный предпоследний вывод, что RecPipeline собранный из специализированных решений особо оптимальный. То есть сейчас есть некоторое количество кирпичиков, например, типа у нас самый лучший векторный поиск, или у нас самая лучшая нарезка начанки, или у нас еще что-нибудь самое лучшее. То есть вы можете собрать все самое лучшее. В индустрии соберется франкенштейн, потому что на самом-то деле оптимизировать надо все вместе. Ну и следующий урок, который они для себя извлекли, что пока не соберешь и протестировать ты ничего не сможешь. То есть даже предположить, какое качество будет, не сможешь. Надо собирать, катить на прод и смотреть.
 Какие они предлагают направления развития? Но почанки на имбединг, они обращают внимание, что нарезка на кусочки гораздо сложнее, чем кажется. Как я уже говорил, часто используют разного рода эвристики. продвинутые способы нарезки используют семантику самого текста языковые модели и каких-то бенчмарков, которые позволили бы сравнивать качество нарезки, не качество имбеддингов для рынка, а именно качество нарезки. Я, например, не знаю. И мне вот их тоже остро не хватает, потому что в том, например, реге, об которой мы сейчас головой бьемся, там сам по себе этап ретривела, этап нарезки, ну вот он Непонятно, как его накручивать, не измерив. По поводу эмбеддингов для поиска. Есть, в принципе, такой общепринятый рейтинг эмбеддингов для русского языка, но вообще-то качество подбора зависит от доменной области. То есть одни эмбеддинги хорошо работают в одной доменной области, а какие-то в другой. сильно улучшает качество RAG и особенно это для негативных общих вопросов. Тут я добавил ссылку на статью, которую авторы не видели, потому что она вышла 29 января, по-моему. Corrective Retrieval Augmented Generation это как раз интересная техника, которая позволяет предобработать отобранные куски до того, как мы их передадим на другие этапы с помощью языковой модели. То есть, грубо говоря, мы языковую модель спрашиваем, как ты думаешь, а будет ли этот кусок полезен?
Какие они предлагают направления развития? Но почанки на имбединг, они обращают внимание, что нарезка на кусочки гораздо сложнее, чем кажется. Как я уже говорил, часто используют разного рода эвристики. продвинутые способы нарезки используют семантику самого текста языковые модели и каких-то бенчмарков, которые позволили бы сравнивать качество нарезки, не качество имбеддингов для рынка, а именно качество нарезки. Я, например, не знаю. И мне вот их тоже остро не хватает, потому что в том, например, реге, об которой мы сейчас головой бьемся, там сам по себе этап ретривела, этап нарезки, ну вот он Непонятно, как его накручивать, не измерив. По поводу эмбеддингов для поиска. Есть, в принципе, такой общепринятый рейтинг эмбеддингов для русского языка, но вообще-то качество подбора зависит от доменной области. То есть одни эмбеддинги хорошо работают в одной доменной области, а какие-то в другой. сильно улучшает качество RAG и особенно это для негативных общих вопросов. Тут я добавил ссылку на статью, которую авторы не видели, потому что она вышла 29 января, по-моему. Corrective Retrieval Augmented Generation это как раз интересная техника, которая позволяет предобработать отобранные куски до того, как мы их передадим на другие этапы с помощью языковой модели. То есть, грубо говоря, мы языковую модель спрашиваем, как ты думаешь, а будет ли этот кусок полезен?
 Затем RAG традиционно противопоставляется файн-тюнингу. Вроде как, что RAG поддерживать проще на PRODI и делать его быстрее, чем модель файн-тюнить. Но надо не забывать, что базовые модели становятся лучше и лучше. То есть, какая-нибудь CHAT-GPT4 уже внутри знает столько, что, может быть, то, что мы хотим ей сложить в RAC, у нее было в обучающей выборке. Запросто может быть. И по мере того, как модели новые выкатывают, открытые, закрытые, надо смотреть, может быть, нужен ли нам RAG. То есть в RAG проще добавлять новости, но какие-то доменные знания, может быть, они уже в модели и есть. И нам надо оценивать точность, задержку, эксплуатационную стоимость и
устойчивость.
Затем RAG традиционно противопоставляется файн-тюнингу. Вроде как, что RAG поддерживать проще на PRODI и делать его быстрее, чем модель файн-тюнить. Но надо не забывать, что базовые модели становятся лучше и лучше. То есть, какая-нибудь CHAT-GPT4 уже внутри знает столько, что, может быть, то, что мы хотим ей сложить в RAC, у нее было в обучающей выборке. Запросто может быть. И по мере того, как модели новые выкатывают, открытые, закрытые, надо смотреть, может быть, нужен ли нам RAG. То есть в RAG проще добавлять новости, но какие-то доменные знания, может быть, они уже в модели и есть. И нам надо оценивать точность, задержку, эксплуатационную стоимость и
устойчивость.

Ну и про тестирование. Для RAG нет хороших инженерных практик, Это как раз статья, это попытка их возвести. С тестированием и генерацией тестовых сценариев трудно. В общем, не очень понятно, как их тестировать, как составлять тестовые случаи. И процесс адаптации практики с других областей только идет. И как мониторить такие системы тоже непонятно. Хаггинфейс тут недавно выкатили репозиторий с кук-буками. И я от себя добавил ссылку. Может быть там, мне кажется, полезные замечания от Хаггинфейса.

Из интересных мелочей, на которые я наткнулся, пока читал список литературы. Во-первых, это OpenAI Evals. Он почему-то прошел мимо меня, а OpenAI есть, оказывается, целый фреймворк для оценки качества работы языковой модели. То есть вы пишете вот такие тесты, что сделай так, от тебя ожидаются вот такие ответы, и можно гонять и сравнивать на своем домене.
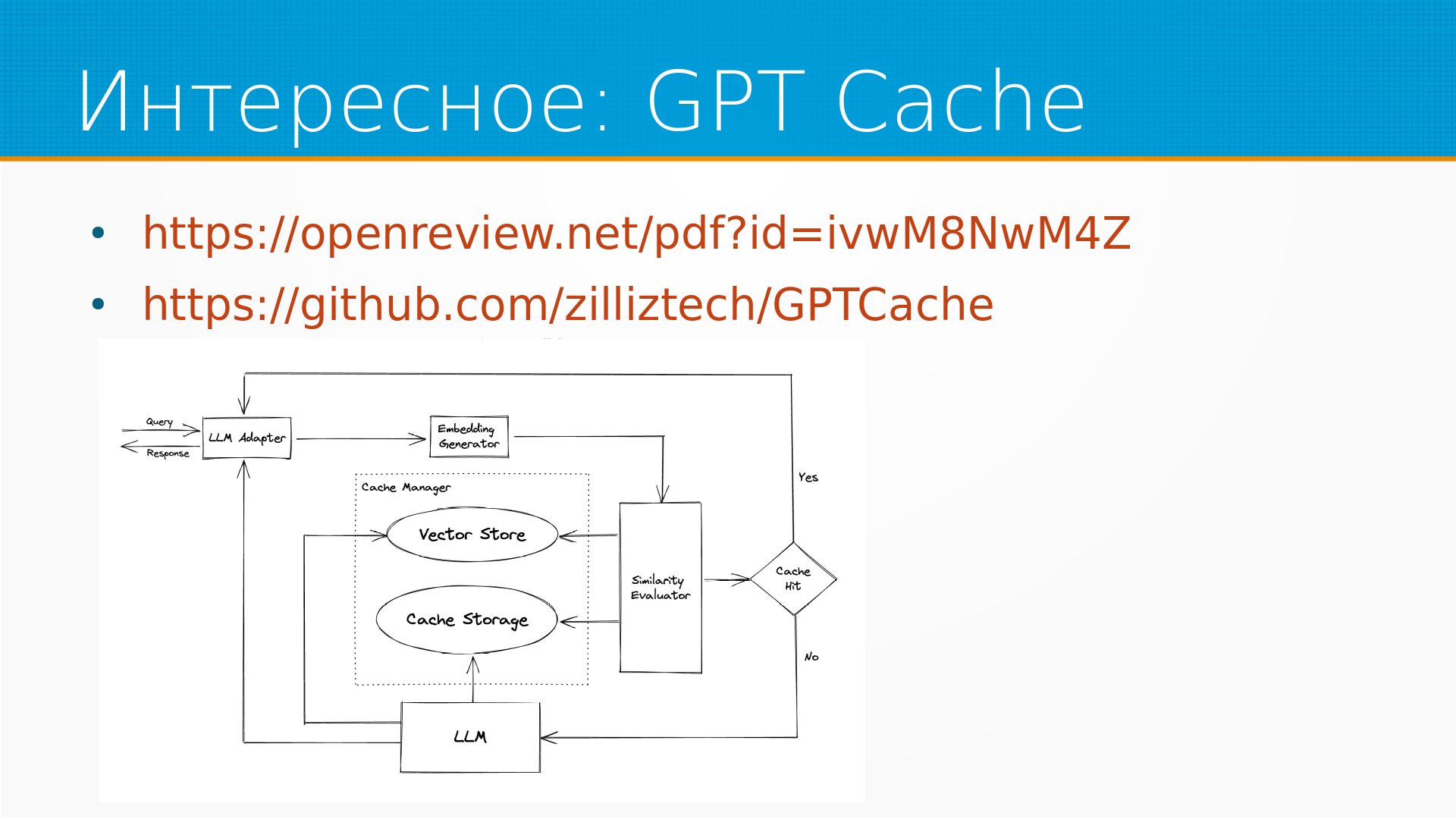 Ну, про GPT-Cache я рассказывал, это семантический кэш. Там есть статья у них на OpenReview и есть библиотечка, и в Lama Index они уже интегрированы. То есть там все достаточно прозрачно устроено, у нас есть некоторые генераторы эмбеддингов, и он эмбедит наши запросы, смотрит, не делали ли мы похожие запросы, если делали, то отвечает из кэша, если не делали, то запрашивает или ленку складывает с кэшем, то есть вот такая система.
Ну, про GPT-Cache я рассказывал, это семантический кэш. Там есть статья у них на OpenReview и есть библиотечка, и в Lama Index они уже интегрированы. То есть там все достаточно прозрачно устроено, у нас есть некоторые генераторы эмбеддингов, и он эмбедит наши запросы, смотрит, не делали ли мы похожие запросы, если делали, то отвечает из кэша, если не делали, то запрашивает или ленку складывает с кэшем, то есть вот такая система.
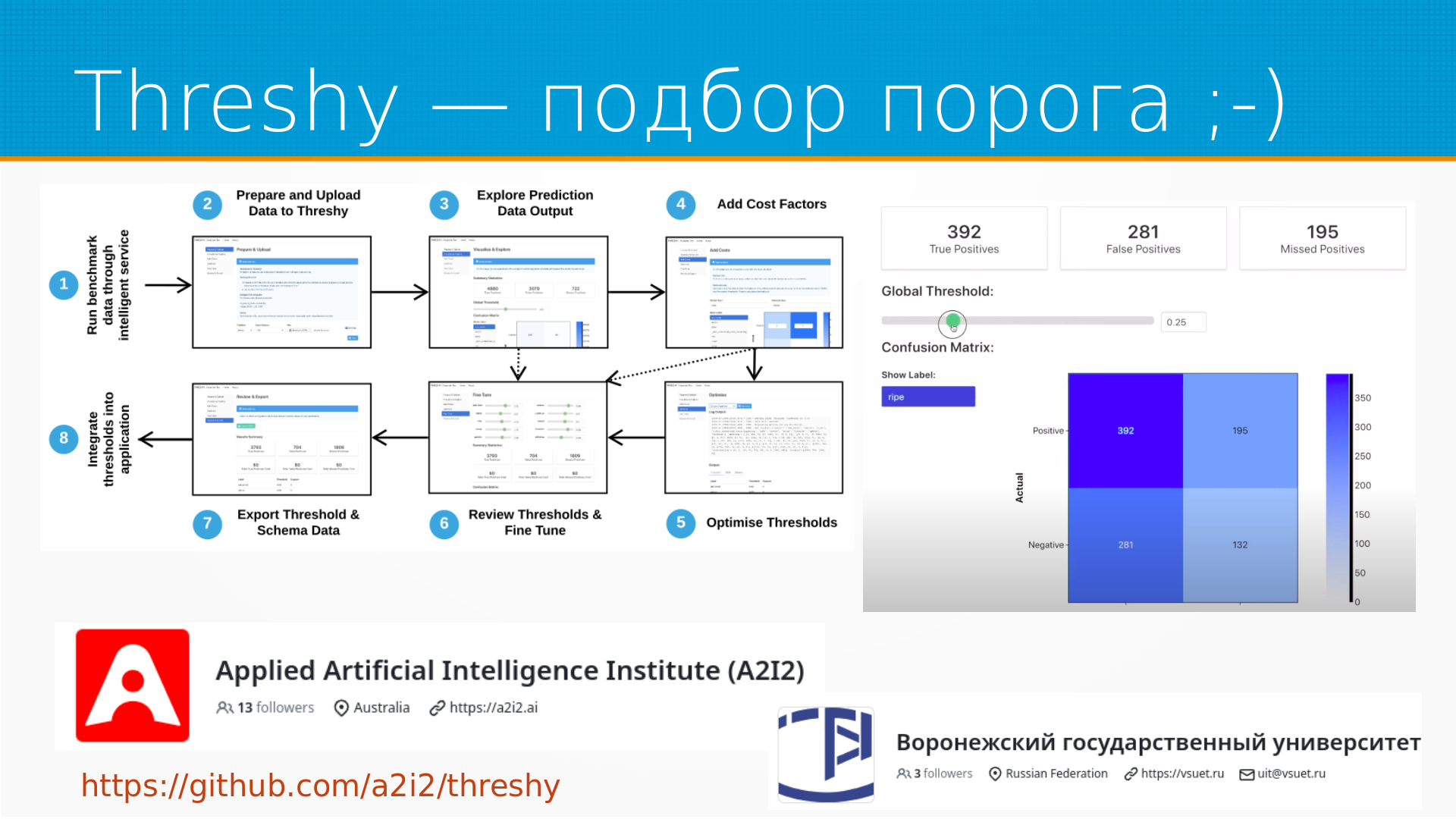
Ну и из забавного у них там в списке статей, но обязательно нужно себя процитировать, у них есть такая трэши. это библиотека для подбора порога в классификаторах. Вот. Она, с одной стороны, как бы такая смешная, то есть вы интегрируете в свой код их веб-приложений, оно отправляет туда свои решения, а вы подкручиваете порог принятия решений и следите за Confusion Matrix. То есть, по идее, если вы какой-нибудь Evidently AI используете, то вы это все и так видите. Но надо понимать, что, во-первых, они сделали это пять лет назад и выложили в открытый доступ. То есть они пять лет назад уже об этом задумывались. А во-вторых, это фактически говорит, что они инженеры неплохие, они пытаются дотаскивать пороги до конечных пользователей своих систем. что делает системы более гибкими. Я об этом когда-нибудь расскажу. Ну и относительно сравнения с Воронежским государственным университетом. У него три фолловера на гитхкабе, а у них 13. Вот. Ну, наверное, на этом все у меня.
Ведущий: Спасибо большое. Там за время доклада несколько вопросов в чате есть. Могу прочитать. Может, удобнее.
Дмитрий Колодезев: Давай, давай, давай. Да, а я чисто их не вижу просто в чате.
Ведущий: В чате, который в Jazzy.
Дмитрий Колодезев: Да-да, в Jazzy я не вижу их.
Ведущий: Первый вопрос про Failure Point 1. Попадание лишних документов в Terms разве плохо? Если ридер работает идеально, то он должен сам понять, что релевантно, а что нет.
Дмитрий Колодезев: Нет. Favorite 1 – это как раз миссинг контент. То есть на некоторые вопросы нет ответа в наших документах. То есть мы, допустим, у нас есть, например, вот эта негипотетическая, совершенно реальная система, которая строительные материалы REC. И мы спрашиваем, какова толщина стенки вот этого изделия. А этого в документах нет. И она придумывает, говорит, ну типа от 10 до 15 сантиметров. То есть реальная толщина 6 миллиметров. Но поскольку в документах нет на это ответа, она что-нибудь придумывает и у нас нет особенной возможности понять галлюцинировала она или нет. Вот о чем.
Ведущий: Угу. Олег, если там все ок, или есть вопросы, допиши. А второй вопрос от Олега. Profiler Point 7. Относится ли он действительно к RAG? Если RAG отобрал все релевантные участки документов, то неполный ответ – это проблема внутри лидера, который не относится к RAG. Retrieval Augmented Generation мы называем всю вот эту систему целиком.
Дмитрий Колодезев: Соответственно, всё, что происходит внутри неё, это проблема Retrieved Augmented Generation. То есть, видите, можно, конечно, сказать, что сломалась не рука, а нога, но система-то не работает. Поэтому...
Ведущий: А можно у меня какие-то глупые вопросы? Я давно хотела познакомиться с Rack, а он действительно полвремени оптимальнее, чем fine-tuning? Ну, то есть построить этот патч, с ней запросы...
Дмитрий Колодезев: Несравнимо. На самом-то деле обычно выбирают оба два. То есть обычно его и делают Rack, и делают fine-tuning. То есть, допустим, типичное приложение REG мы берем, ну, вот такой классический пример – это анбординг сотрудников. Есть у вас, допустим, какая-нибудь конфлюенция, да, и в ней есть все, что ваша команда разработки за 10 лет записала, и все, что надо важно прочитать. Если посадить нового сотрудника все это делать, читать, он будет два месяца читать, ничего не делать. вот можно конечно научить языковую модель отвечать на вопрос типа где получать ключи от парковки например да ну вот такие вот вопросы вот но время от времени эти факты будут меняться и гораздо лучше эти вещи делать через RAG, просто действительно надежнее. К тому же в RAG мы документ обновили, имбединг пересчитали, он начал отвечать свежими данными, то есть мы можем обновлять его с частотой, скажем, несколько минут. А еще есть киллер-фича, на самом деле, в RAG, которая нет в Fine-Tuning обученной модели, это та самая мета-информация. Предположим, что у нас чанки снабжены не только снабжены какими-либо тегами доступа. И, например, у руководителей отделов есть доступ ко всей информации, а у сотрудников, например, к меньшему количеству информации, а у посетителей офиса, допустим, только к каким-то открытым документам. И тогда одна и та же система может отвечать с разной степенью детализации, с разной степенью раскрытия, допустим, информации на одни и те же вопросы. И вы можете изменить ее ответ для конкретного человека, просто повысив ему степень доступа к документам. То есть они технологичнее гораздо, чем просто обученные вопросно-ответные системы на языковых моделях.
Ведущий: Но они, кажется, еще более white box.
Дмитрий Колодезев: Да, и помните, вот в одной организации на букву Х там хотели использовать графы знаний, да? Да. С языковыми моделями. Вот здесь, в этой схеме, мы ретривер делаем через векторный поиск. Но точно так же ретривер мы можем делать через граф. Абсолютно. И получим мы ровно то, о чем старики мечтали.
Ведущий: На самом деле, в компании на H пробовали такие эксперименты, и все получилось. К сожалению, это не пошло дальше, но...
Дмитрий Колодезев: Вот, ну вот, в общем, такие вот вещи. Причем, если у нас мы как в... У нас есть этап переранжирования, да, реранкер? и в модуль переранжирования, если у нас есть хороший, это позволяет нам собрать чанки разными способами, то есть собрать графами. Мы, допустим, в одной из таких тяжелых систем вместо векторного поиска банально используем BM25 и отлично работает. То есть, в принципе, можно собрать их По семантической близости, по ключевым словам БМ-25 можно по графу знаний собрать, потом переранжировать, отобрать самое сочное и сложить. И в принципе это то, как эта система и должна работать, если достаточно денег и времени.
Ведущий: Спасибо большое. Так, тут еще у Олега про FP1. В случае миссинг-поинт, как оценить качество именно RAG, то есть компоновки найденных участков документов? Если RAG выдал лишнее, это ошибка?
Дмитрий Колодезев: Так, у меня такое подозрение, что Олег словом RAG называет что-то не то. Вот, то есть RAG я называю всю систему полностью. Как она оценивалась здесь на самом-то деле? Если система не выдала ответа, который ожидали люди, то мы считаем, что она ошиблась. Ответил Илья на вопрос.
Ведущий: Но система вместе с языковой моделью имеется в виду?
Дмитрий Колодезев: На самом-то деле система, вот когда если у нас есть миссинг контент, если мы наступаем на эту граблю, то нам надо идти, допустим, доложить контента, и тогда наш рэк будет работать хорошо. То есть мы, конечно, можем сказать, что да, это у нас рэк хороший, просто ему данные плохие дали, но на самом-то деле Пока мы не увидели хорошего ответа, мы считаем, что RAG у нас плохой. Такие вот дела.
Ведущий: Спасибо. Может, у кого-нибудь еще есть вопросы или комментарии?
Дмитрий Колодезев: Как я уже говорил, мне больше всего понравилась именно эта картинка, потому что это просто готовый чертеж. То есть вывешиваешь на стену и пошел делать трек.
Ведущий: Такой, да, академический чертеж. Так, Олег, значит, комментарий от Олега. Может быть, все-таки имеет смысл делить ошибки на ошибки компоновки и ошибки ридера, поскольку это можно читать последовательность двух задач, которые можно оценивать независимо?
Дмитрий Колодезев: ошибки ридера и ошибки компоновки. Вот not in content ошибка отнесена к консолидатору, not extracted incomplete и wrong форматы отнесены к ридеру. Авторы так и поступили.
Ведущий: Возможно.
Дмитрий Колодезев: Может быть какие-то конечные ошибки?
Ведущий: Откуда они придаются? А тогда миссинг контент к чему относится?
Дмитрий Колодезев: Миссинг контент относится к этой части. Ответа на самом деле нет в базе данных. Как бы мы ничего не спрашивали, как бы не накручивали языковую модель, но нет ответа. Вот. А можно, конечно, сказать, зачем же вы спрашиваете такое, чего она не знает. Но проблема в том, что контент складывают одни люди, а спрашивают другие. И если бы мы заранее знали, что у нее спросят, тогда бы, вообще-то говоря, нам и не надо было языковую модель делать. Мы бы ответы просто написали, и мы отдали бы. Вот. Проблема как раз в том, что мы не знаем, что они спросят.
Ведущий: Ещё я, к сожалению, не записала, но некоторые проблемы мне показались общие, в принципе, для языковых моделей.
Дмитрий Колодезев: Ну, да, тут ещё некоторые проблемы этой статьи в том, что, ну, в общем, это, конечно, сельский вуз. То есть они говорили о том, что у них болит. Вот. Они не особенно читали чужие статьи. Вот. То есть они просто брали, отважно делали РЭК, смотрели на проблему, записывали их в тетрадочку, ну и вот. Написали об этом статью. На самом деле молодцы. Потому что вот таких статей десяток и в общем можно издавать их учебником по разработке RAG.
Ведущий: Так, вопрос от Олега. В миссинг-контент есть верный ответ? Я не знаю. Если модель выдала другой ответ, это ошибка RAG или READER? Но мы тут уже обсудили, что RAG – это всё вместе.
Дмитрий Колодезев: Да, то есть тут нет блока с надписью RAG-RAG, это вот все, что тут нависовано. Ну а еще что я хочу сказать, Олег, это статья, это не мое мнение, это я пересказываю. Мопед не мой, я просто разместил объяву. Вот. То есть, в принципе, эти ребята так видят. Они достаточно смелые, потому что они взяли... Кстати, вот обратите внимание, что они взяли для своего универа, сделали два RAG и держат их в проде. И платят зарплату людям, которые их накручивают. Вообще, так говоря, они молодцы.
Ведущий: А есть какие-то best practices, какими текстами вообще лучше наполнять базу данных? То есть туда просто все по определенному домену собирают или есть какие-то все-таки правила, как лучше это делать?
Дмитрий Колодезев: На самом деле обычно туда сваливает все, что мы считаем относится к нашей доменной области. там самая большая проблема всех регов вот это именно нарезка начанки почему они ее на нее не наткнулись непонятно вот то есть именно они упоминали что размер чанка размер контекста то есть по поводу нарезки начанки там столько всяких приблизительных решений накручено я как-то завтрак кидал ссылку типа 5 базовых подходов с нарезки начинки там один другого крашу то есть изоленты на изоленте вообще обоснования не под какого просто давайте мы попробуем еще вот так вот давайте я у стукну станет фиолетовый в крапинку то почти точное описание что будет то есть в давайте мы попросим чат gpt нарезать на чанки за нас это еще хорошо вот то есть самая типичная проблема в чанках это когда мы их режем не по смыслу например у нас есть мама мыла раму папа мыл машину и она режет ее на чанки вида мама мыла раму папа вот ну и потом мы его спрашиваем кого мыло мама ну такие вот то есть это совершенно живой пример и если кажется что пример надуманный но вот представьте себе у нас есть база данных по кабельной продукции где все названия и спец символов состоят и вот мы ее делим на предложение непонятно же как
Ведущий: Так, комментарий от Олега. Может быть многие из перечисленных проблем можно переформулировать как Precision и Recall для шага компоновки, то есть создания промпта для ридера.
Дмитрий Колодезев: Precision и Recall обычно имеют в виду, что вот у нас есть некоторая точность по некоторому множеству и полнота извлечений для некоторого множества. В данном случае Prompt для ридера – это непрерывный текст. Каким образом мы формулируем для него Precision и Recall? То есть я примерно понимаю, о чем Олег спросил. Да, типа это же где-то рядом с Precision, где-то рядом с Recall. Да, рядом функции, преобразующие одну в другую, я не вижу. Вот.
Ведущий: Вопрос от Василия. Какие сейчас популярные open-source-фреймворки для построения своей RAG-системы?
Дмитрий Колодезев: Все очень интересно. Lama Index, во-первых. Она чаще всего и используется. Во-вторых, есть, так сказать, enterprise-grade системы, как, например, Hi-Stack. И у них у всех есть свои какие-то особенности, достоинства. Есть некоторое количество облачных систем. OpenAI говорит, отдайте нам ваши PDF-ки, мы сделаем по ним вам RAG. То есть на рынке предложений хватает, но все они какие-то второсортные. А если самим делать, есть, во-первых, Lama Index, есть хороший Intel фреймворд для разработки RAG, И есть хорошая библиотечка для семантического поиска в для RAG. Наверное, это ближе всего к, так сказать, устоявшимся практикам. Я ссылки скину.
Ведущий: Так, следующий вопрос от Олега. Можно ли оценить качество ретривер и качество ридер независимо? Или для одних ридеров будут лучше одни ретриверы, для других другие? Иначе эти задачи независимы.
Дмитрий Колодезев: Проблема... Вот. И это обидно. Где-то я об этом говорил. Ну вот, собственно говоря, не хватает способов измерить качество нарезки. Мы делали, как можно обучить модель наручной разметки то есть в принципе мы можем взять чанки которая нам извлекла модель и посадить людей размечать типа вот это она хорошо для запроса извлекла вот это она плохо и мы разметили скажем с 1000 таких наборов чанка да и на этом мы можем обучить модельку и моделька будет нам оценивать качество подбора Качество извлечения. В общем, опять же, качество извлечения, учитывая, что потом мы их переранжируем, потом мы их переформулируем, потом мы в промпты недетерминированных языковая модель потом как-то пережевывает, то, в общем, даже имея идеальные чанки, не факт, что мы получим что-нибудь хорошее. То есть это как раз то, о чем они говорили, что во-первых, ее толком не синжиниришь, то есть ее надо складывать в кучу и смотреть, и подкручивать, чтобы она завелась. А во-вторых, что мы берем идеальные, совершенно подогнанные, совершенно оптимальные системы на каждом этапе и получаем неоптимальное решение. В экономике даже есть на это, по-моему, теорема про второй лучший результат. То есть это как бы ожидаемо в сложных системах, что оптимальное решение на каждом из подэтапов не образует общее оптимальное решение.
Ведущий: Тоже Олег спрашивает, бывает ли, что нерелевантные с первого взгляда чанки, попав в консолидатор, дадут прирост качества?
Дмитрий Колодезев: Поскольку мы только в начале изучения регов, ну, в смысле, что регам несколько лет, вот, я думаю, что бывает всё. Вот. На самом деле для нас, как для инженеров, интересует, не бывает ли А умеет ли смысл закладываться что? Вот. То есть с точки зрения, например, физики той, которую я помню еще с универа, существует ненулевая вероятность, что весь воздух соберется в одном углу комнаты и мы задохнемся. Но мы обычно закладываемся, что этого не будет. Потому что это маловероятно.
Ведущий: Ага. Олег пишет, что он имел в виду не случайные эффекты, а систематичные. Например, некий чанг наводит модель на нужный настрой для ответа.
Дмитрий Колодезев: Ну, учитывая, что языковые модели вообще ведут себя как полная чушь. То есть, например, если там будет какой-нибудь чанг про чаевые, он, конечно, будет лучше отгенерироваться.
Немного ссылок: