
- 20.11.2022
- 25.08.2024
- обучение
- #mlsystemdesign
Девятая лекция открытого курса "Дизайн систем машинного обучения", "Потоковые данные".
Слайды можно скачать тут mlsysd9ods.pdf
Текстовая расшифровка:
Добрый день, меня зовут Дмитрий Колодезев и это 9-я лекция нашего курса про дизайн систем машинного обучения, она посвящена потоковым данным.

Прежде чем говорить про потоковые данные, следует заметить, что этот курс – это не учебник по распределенным системам и не учебник по потоковым данным. И ни в коем случае это не учебник для дата-инженеров. Это скорее краткое описание того, где потом гуглить. То есть, вам все равно придется столкнуться с потоковыми данными во время создания ML-систем, поэтому лучше знать, как они выглядят и чего от них можно хотеть.

Давайте посмотрим, как в принципе данные могут поступать в систему, как разные части системы могут общаться друг с другом. Тут есть несколько сложившихся шаблонов, таких как синхронный запрос ответа, синхронный ответ, модель издатель-подписчик, длинные опросы и так далее. Сейчас мы по ним пройдем, а потом отдельно схему издатель-подписчик разберем, потому что она – основа потоковых данных.
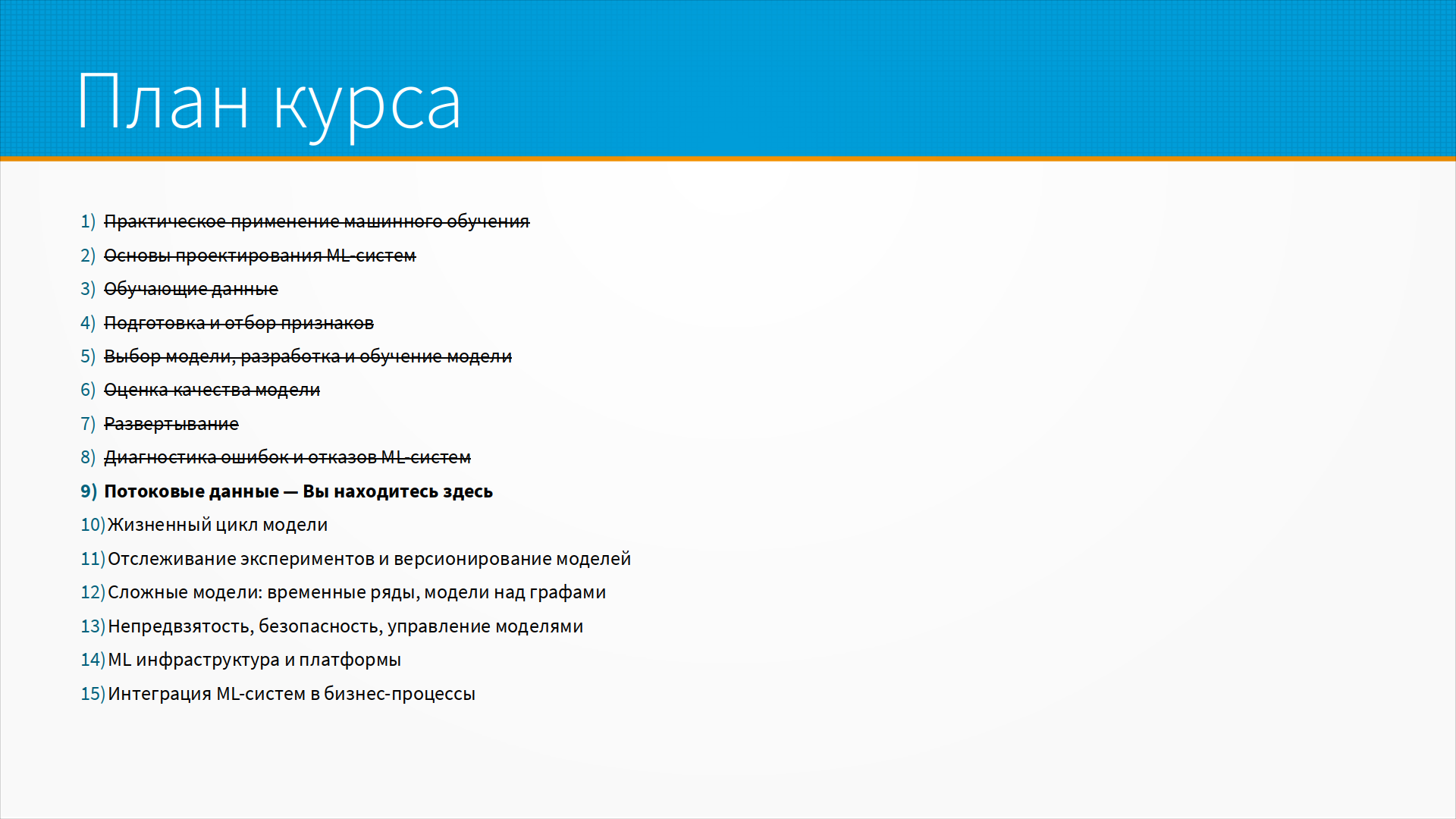
В случае синхронного запроса ответа клиент открывает соединение к серверу, отправляет запрос, ждет, пока ему ответят – а ему отвечают более-менее сразу, – и, пока идет обработка его запроса, он ничего не делает, он ждет. Получив ответ, он закрывает соединение и работает дальше.
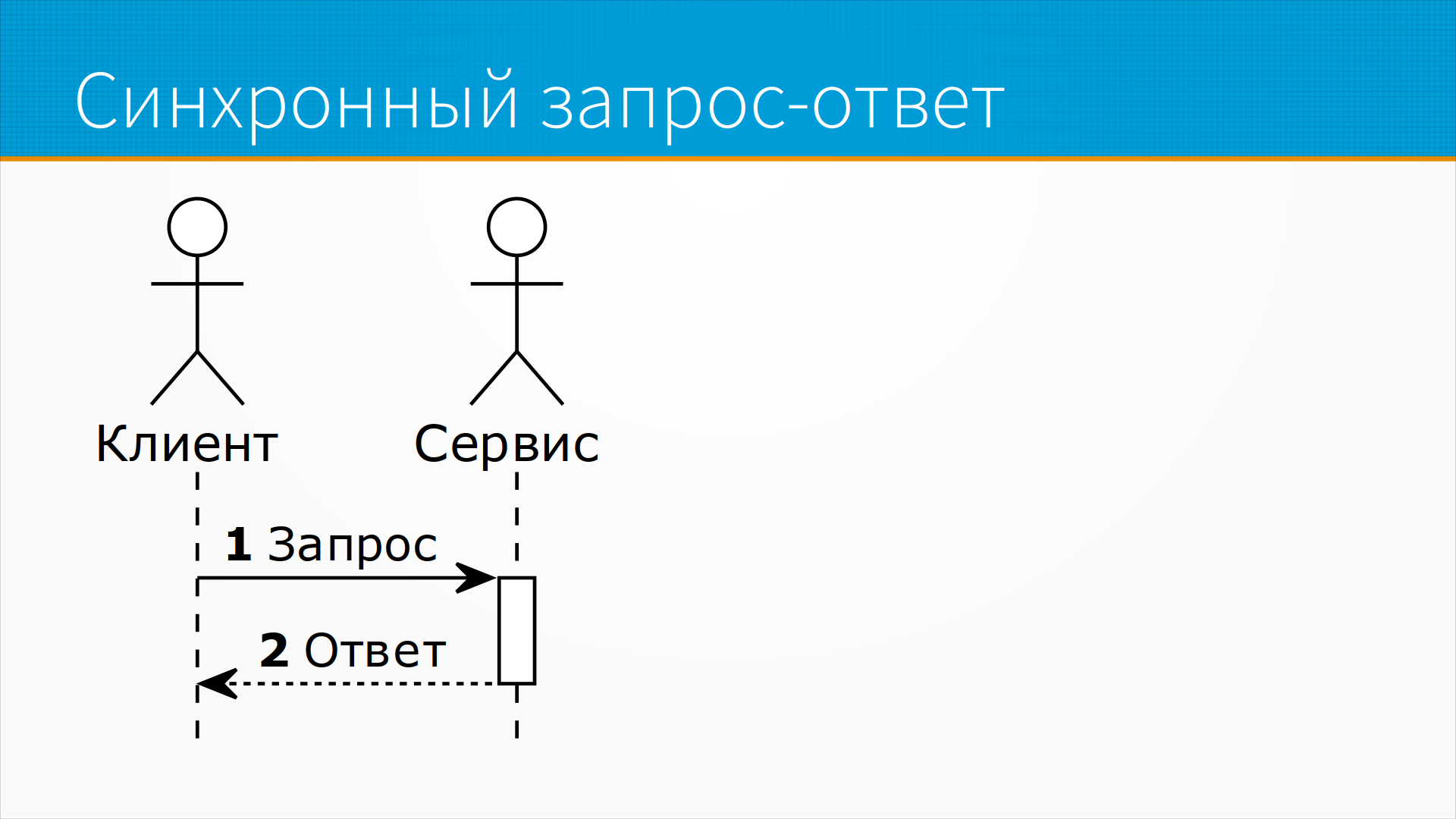
В случае асинхронного ответа, как чаще всего на самом деле выполняются запросы в современном вебе, клиент отправляет запрос к серверу и в это время начинает выполнять какую-то свою работу, какие-то свои задачи делать, и ждет, когда придет ответ. И, когда придет ответ, он переключается на ту задачу, которую хотел сделать и обрабатывает ее. Для сервера это выглядит синхронно, то есть пришел запрос, он работает над ним и отдал ответ.
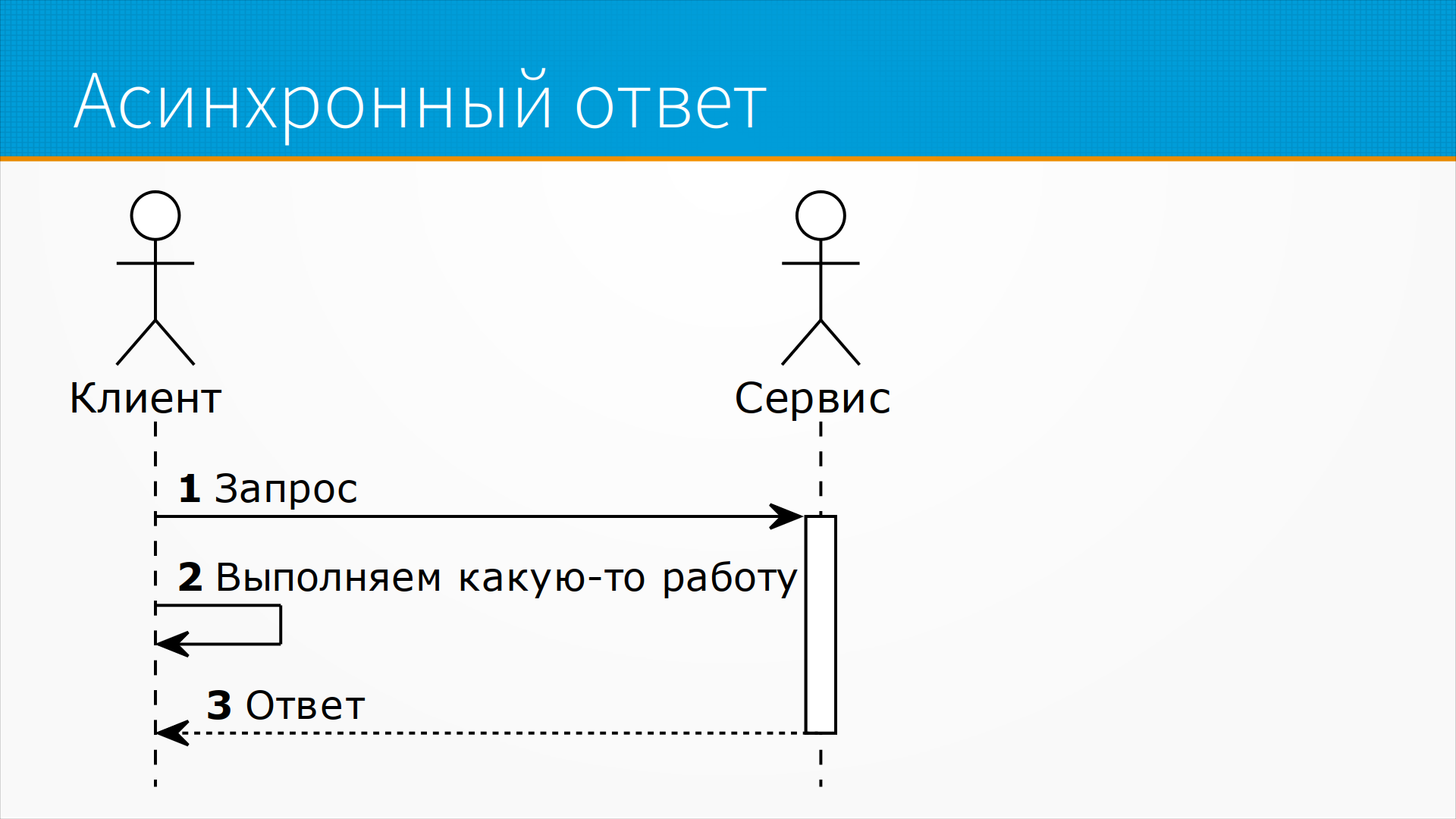
В случае, когда у нас и клиент может отправлять запросы асинхронно, и сервис асинхронно их обрабатывает, у нас есть полная асинхронная модель запрос-ответ. То есть предположим, что у нас есть два клиента. Первый из них отправил запрос на сервер и пошел заниматься своими делами. Потом второй клиент отправил запрос на сервер и пошел заниматься своими делами. Сервис независимо выполнял запросы этих двух клиентов, и второму он ответил раньше, чем первому, а потом он ответил и первому. Эта модель хороша, но она требует от сервиса непосредственно управлять своей параллельностью. И на самом деле, несмотря на то, что она подается как способ работы с большой нагрузкой, ее возможности по масштабированию ограничены, потому что сервер все равно должен создать, грубо говоря, отдельный поток под каждого клиента. Если этих клиентов сто тысяч или десять тысяч, вы все равно не вытянете такую нагрузку.
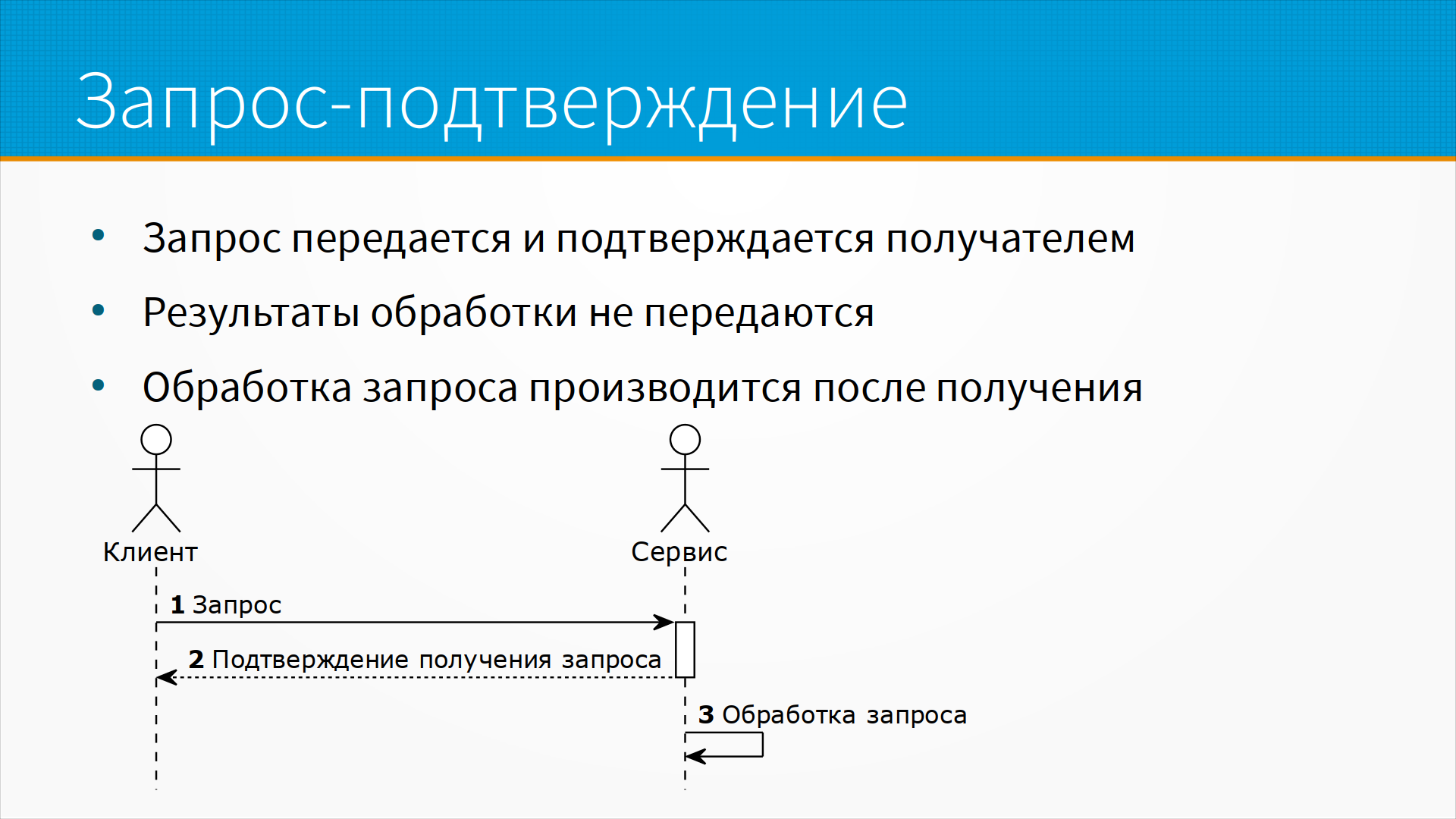
Модель запрос-подтверждение – это история, когда вы отправляете запрос, но не ждете окончания его обработки. Например, вы пишете логи или, например, вы отправляете смс-сообщение через соответствующий шлюз. То есть вы отправили запрос, а тот сервис, который будет заниматься обработкой вашего запроса, подтвердил вам его получение – "запрос получен, как ваше письмо получено, будет доставлено". После чего ушел его обрабатывать, а вы ушли работать дальше. В этом случае запрос передается и подтверждается получателем. Результаты обработки не ожидаются и не передаются, и обработка запроса производится после получения.
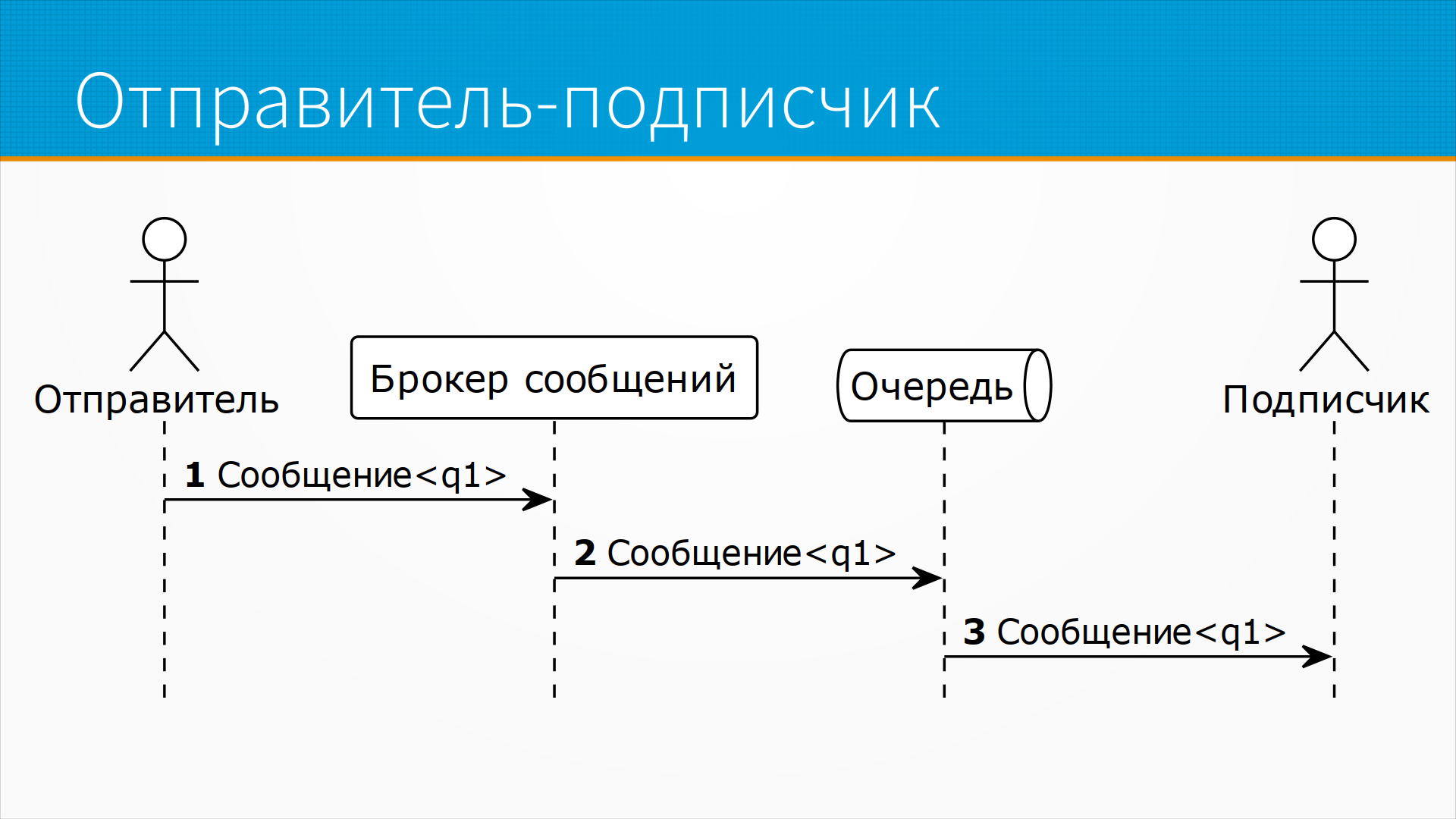
Модель издатель-подписчик, которая лежит в основе большинства потоковых архитектур, предполагает, что у нас, кроме отправителя, сообщения и подписчика, есть еще брокер сообщения. Обратите внимание, что вместо вызова метода или запроса мы говорим про сообщение – то есть кто-то отправил кому-то сообщение. Если получатель сообщения хочет что-то ответить в ответ, он отправит свое сообщение. Подписчик – это тот, кто получает сообщение. Брокер сообщения – это сервис или сущность, ответственная за доставку и маршрутизацию сообщения. Отправитель отправляет сообщение брокеру, брокер ставит это сообщение в очередь, и подписчик, когда ему удобно, забирает сообщение из очереди и обрабатывает. Причем в этом случае не вполне очевидно, зачем нам брокер сообщения. То есть у нас есть отправитель, есть подписчик, а брокер как бы лишняя сущность, не совсем нужная. Тут важный момент – подписчик может выбрать сообщения из очереди не тогда, когда они туда пришли, а когда ему будет удобно, возможно, с большой задержкой. Например, если у нас идет отправка запросов на обработку, и подписчик может обрабатывать их с фиксированной скоростью, мы можем наставить кучу запросов, и подписчик их разгребет, когда будет более спокойное время. То есть тут у нас полная асинхронность, развязка управления.
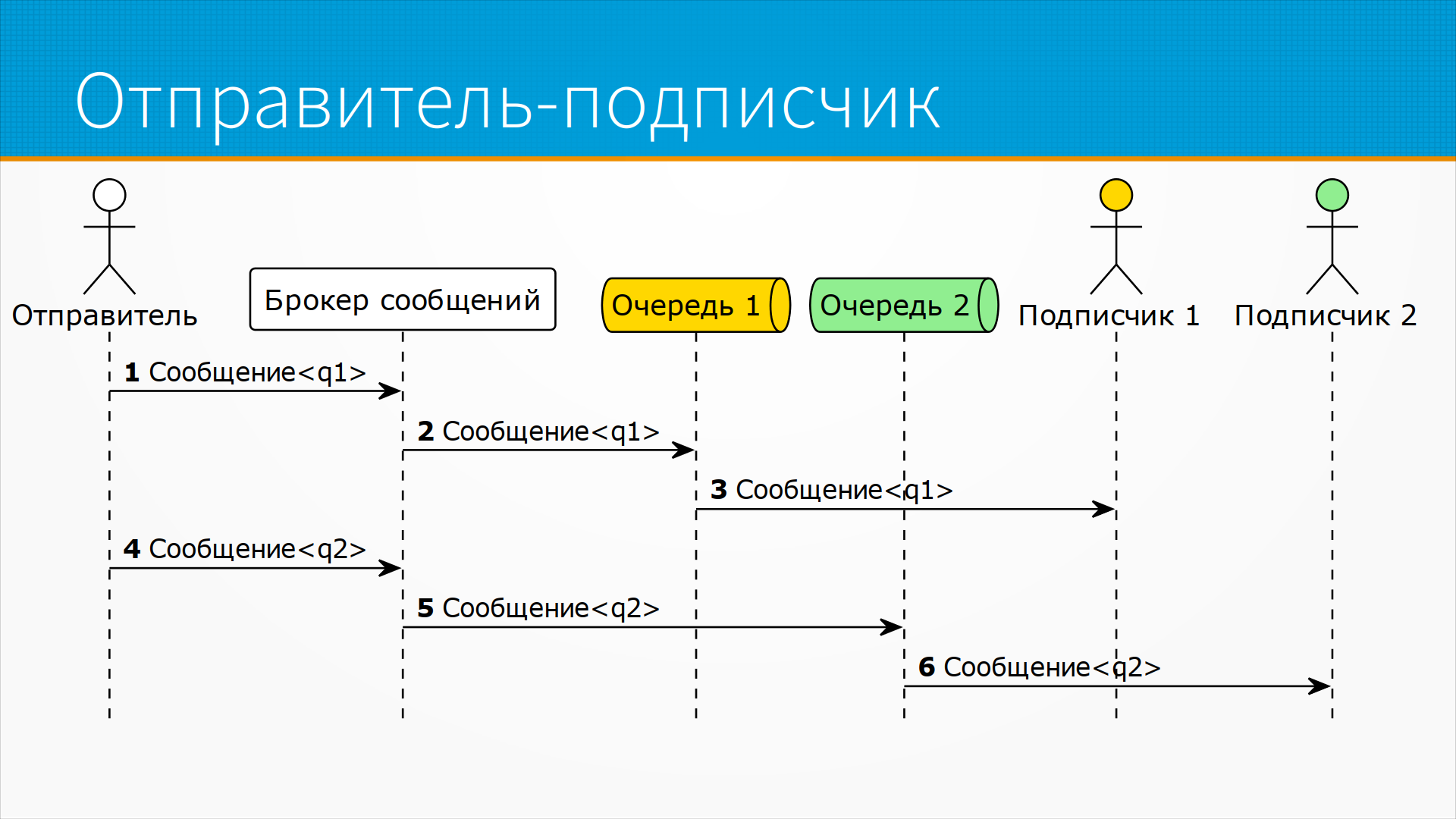
В модели издатель-подписчик возможна и часто встречается ситуация, когда отправитель ставит сообщение в разные очереди. То есть он помечает сообщение некоторым адресом, то есть очередью, в которую он хочет, чтобы это сообщение попало. Каждый подписчик слушает, например, свою очередь. И тогда брокер сообщения получает сообщение 1, видит, что оно предназначено для очереди первой, или там есть какие-нибудь правила, например, что до 12 часов дня все сообщения ставятся в первую очередь, после 12 до часа во вторую очередь и так далее. В соответствии с какими-то правилами он маршрутизирует, то есть распределяет в нужную очередь, а подписчики, подписанные на эту очередь, забирают эти сообщения.
Это похоже на работу почты. То есть вы отдаете на почте конверт, он идет через внутреннюю систему почты и попадает в почтовый ящик конкретного человека, и вам гарантируется, что ваш конверт дойдет до вашего получателя. При этом сам отправитель может ставить задачи в несколько очередей, отправляя все эти сообщения одному этому же брокеру. Он просто помечает сообщение каким-нибудь тегом, который указывает на то, в какую очередь его поместить, то есть куда его маршрутизировать.
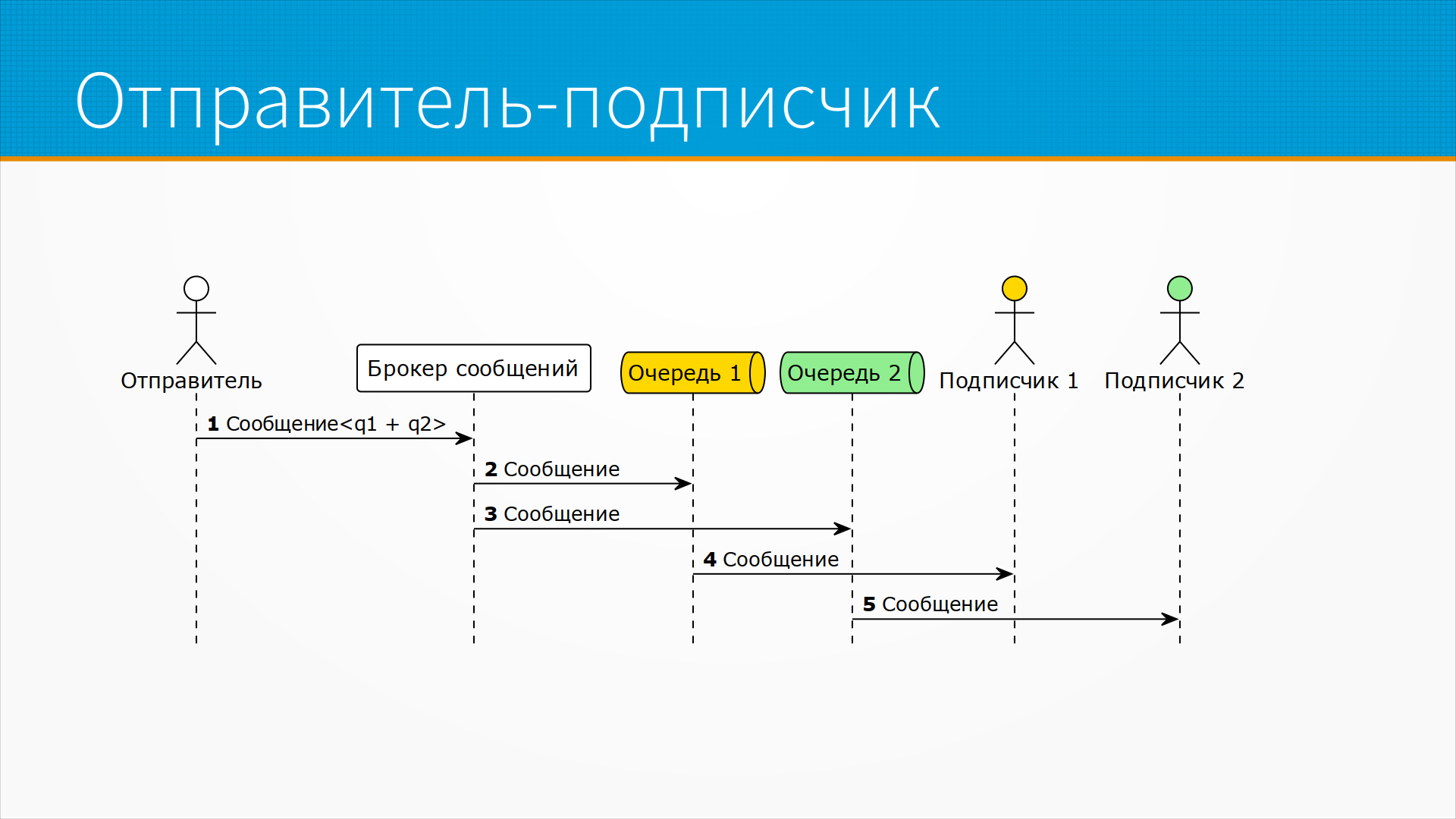
Есть следующий вариант этой же схемы, когда мы не знаем, сколько будет подписчиков нашего сообщения, но нам нужно доставить его всем. Например, у нас есть какие-то кучи сервисов, и нам нужно время от времени их уведомлять, что изменился адрес подключения чего-то или перестал быть доступен ресурс. То есть мы всей системе отправляем сообщения. Каждый из получателей должен получить это сообщение. При этом мы не знаем, сколько там подписчиков. Тогда отправитель отправляет сообщение брокеру очередей, который раскидывает это сообщение в соответствии с правилами, маршрутизирует, дублирует его во все очереди сразу.
В RabbitMQ это называется fanout схема. И каждый подписчик забирает сообщение из своей очереди. Это удобно, например, когда мы хотим обрабатывать входящее сообщение и заодно логировать. Мы можем настроить маршрутизацию одновременно в очередь для логирования и одновременно в очередь для обработки. Тогда у нас логер всегда выгребает сообщения в свою очередь и пишет ее в историю, а обработчик выгребает в свою очередь и обрабатывает.
Кратко – отправителя не интересует, сколько там будет подписчиков. Брокер ему гарантирует, что каждому из подписчиков сообщение будет доставлено.
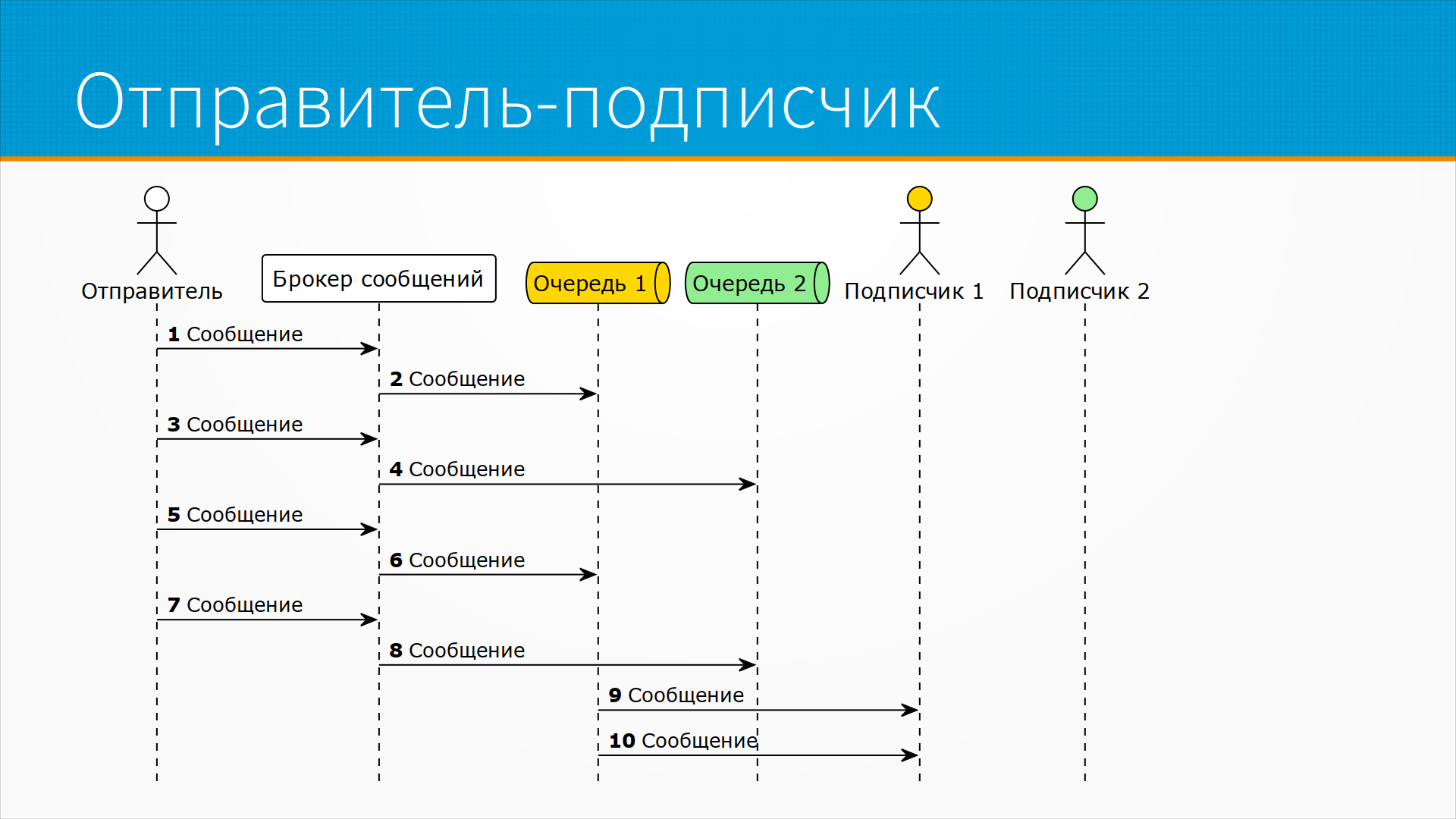
Бывает и очень часто встречается схема, когда отправителю неважно, сколько там подписчиков, но важно, чтобы хоть до одного это сообщение дошло. Например, у нас есть несколько однотипных воркеров, допустим, у нас есть 100 однотипных воркеров, которые обрабатывают входящее сообщение. Нам важно отправить сообщение какому-нибудь из воркеров, например, свободному, или по очереди отправлять им равномерно. И тогда отправитель отправляет сообщение брокеру сообщений, а брокер сообщений по какой-нибудь схеме маршрутизирует его в очередь. Например, в ту, в которой меньше сообщений, или в следующую по порядку. Еще раз – не знаем, сколько подписчиков, но хотим доставить кому-нибудь.
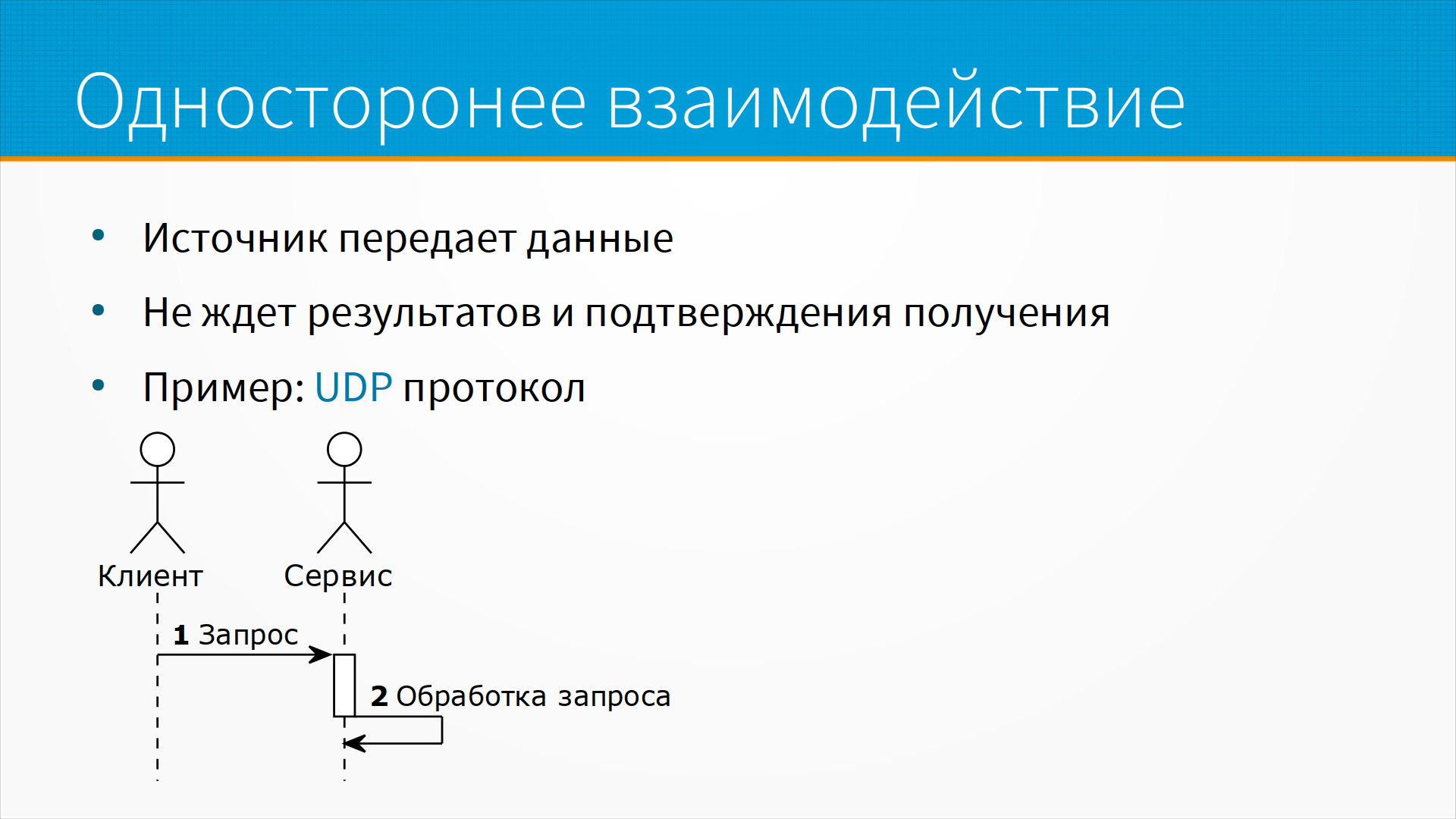
Из несвязанных с очередями сообщений полезная модель - это односторонние взаимодействия. Грубо говоря, выстрелил и забыл. То есть источник передает данные, но не ждет результатов, не ждет подтверждения получения. А сервис получает это сообщение, ничего в ответ не говорит, и как-то его обрабатывает. Оно, с одной стороны, выглядит странно, как бы клиента не интересует – придет сообщение к сервису или нет. Но на практике оно очень часто используется. Например, это протокол UDP, когда датаграммы отправляются, но не подтверждаются сервисом.
Хороший пример такой работы – это интернет-телефония, когда нам на самом-то деле не важно, если запрос пришел не вовремя или потерялся. Просто у пользователя будет легкий пропуск или глюк в его аудиопотоке. Мы все равно ничего разумного не сможем сделать. Мы не сможем перезапросить данные, а даже если мы сможем их перезапросить – что мы будем делать с этим звуком, который придет на три секунды позже, не в том порядке? Источник передает данные и не ждет подтверждения получения.

Часто используется схема длинных опросов – long polling. Например, таким образом мы можем подписываться на события ВКонтакта или, например, Твиттера. Схема какая- мы отправляем запрос на сервер. Например, мы хотим получать все события, попадающие под вот эту схему. То есть, например, все сообщения, попадающие под какой-нибудь наш запрос. И как только такое сообщение у сервера появляется, он его отправляет нам. Таким образом, мы получаем от него ответ, но не один ответ, а длинный поток непрерывных ответов.
Существующие программные реализации, например, Yandex MQ, позволяют так работать. По ссылке – описание, как это можно делать. Есть специальный сервис Socket.IO, который позволяет сделать long-poll поверх чего угодно. Ну и ВКонтакте, как я уже говорил, любит такие схемы работы.
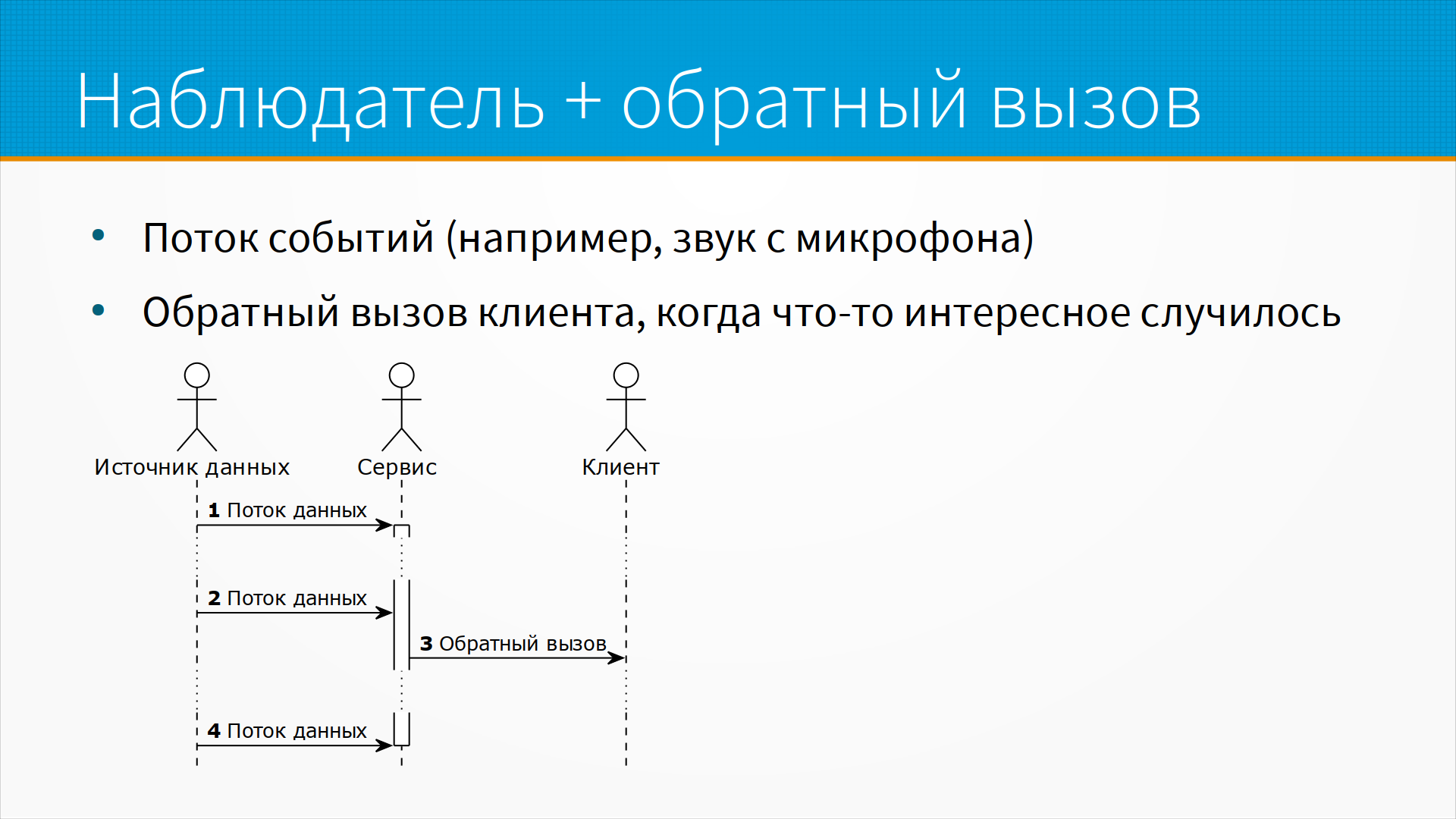
Важный и полезный способ организации обмена данными – это наблюдатель и callbacking. Предположим, что вы, допустим, умная колонка, и слушаете поток звука. Большую часть времени вам с ним ничего делать не надо. Но иногда вы распознаете в нем ключевое слово и отправляете куда-то запрос – "посмотри, смотри, мы получили интересное событие, давай его обработаем". Таким образом, у нас есть входящий поток событий, большая часть из которых игнорируется. Поток событий может поступать разными способами, но, кстати, часто он поступает как поток сообщений через схему издатель-подписчик. И есть колбеки, то есть когда с точки зрения клиента что-то интересное произошло, он отправляет запрос в нужный сервис или как раз отправителю запроса.

Теперь давайте поговорим подробнее про потоковую обработку. В потоковой обработке мы рассмотрим вопросы stream processing, streaming data, общую терминологию про брокеров сообщений и базовые сценарии использования.

Streaming processing – это способ проектировать системы таким образом, что обмен информации организован в виде событий. В систему поступают события, приложения подписываются на эти события, ну и приложения генерируют события. Что такое событие? Событие – это что-то, что случилось в системе. Маленький, независимый кусочек данных. По ссылке хорошее описание на английском того, что такое stream processing.

Streaming data – потоковые данные. Это способ организации данных такой, что поток событий – постоянный, генерирующийся в реальном времени, не имеющий определенного начала или конца. Мы его можем использовать, скажем, с середины – события обрабатываются асинхронно, сохранение и обработка данных разделены.
Пример потоковых данных – ну, например, большинство людей так или иначе смотрит прогноз погоды. При этом прогноз погоды в интернете обновляется независимо от нас. Он обновляется не когда он нам понадобился, он все время обновляется. Но время от времени мы приходим, смотрим погоду на сегодня, смотрим погоду на вчера, смотрим погоду на завтра и идем заниматься своими делами. При этом поток никак не прерывается, он не ждет, что мы обработаем наш прогноз погоды и так далее.

Самый простой пример потоковых данных – это логи серверов. То есть у нас сервера пишут логи, логи эти отправляются, допустим, в Kafka и из Kafka, из брокера сообщения, они записываются, например, в сервис для хранения ClickHouse.
Пример потоковых данных – это геолокация пользователя. То есть пользователь идет по маршруту, у него включен GPS, включена отправка его местоположения. И у нас есть куча точек, но по поводу каждой из точек нам вообще-то делать с ним нечего. Но когда к нам придет запрос – "а где пользователь сейчас находится?" – мы на него отвечаем, исходя из его текущего положения, которое мы смотрим в потоке. Ну и, может быть, какие-то несколько последних его точек, чтобы усреднить и защититься от флуктуации определения местоположения.
Еще примеры – какие-то датчики оборудования, которые передают влажность, температуру, шум, что-то еще.
В социальных сетях, рекомендательных системах, пример потоковых данных – это разного рода события, инициированные пользователями. То есть лайк, дизлайк и так далее и тому подобное.
В финансах это могут быть транзакции по кредитной карте, где fraud detection смотрит на этот поток данных и ищет какую-нибудь интересную транзакцию, чтобы заблокировать вам карточку и защитить ваши деньги от хакеров.
Системы bot detection, например, мониторят запросы пользователей к сайту и смотрят, какие из них сделаны ботом, чтобы включить защиту.
Ну и системы торговлями акций – stock trading – они постоянно смотрят на цифровые сигналы, и торговый робот ждет, когда нужно купить акции, продать акции, что-нибудь сделать по этому поводу.

Особенности потоковых данных – это, во-первых, структурированные короткие сообщения. Они могут быть длинными, на самом деле есть такой антипаттерн – ставить в поток длинные большие сообщения. Но лучше, если они будут короткие, потому что это позволит нам думать о них как о мгновенных событиях.
Отправитель обычно не ждет ответа на каждое сообщение. Отправитель не знает, кто конкретно обрабатывает это данное сообщение, он отправил данные, выстрелил и забыл. Данные получателю могут поступать с задержкой, даже с перерывами. Зачастую, например, когда отправитель теряет связь с сетью, он накапливает все данные, а потом отправляет их пачками.
И отсюда же неравномерный поток данных. Предположим, что мы фиксируем какие-нибудь события, допустим, из системы контроля доступа организации. Вот утром 5000 человек приходят на завод, все эти события приходят в течение 15 минут, а вечером они уходят. А все остальное время событий почти нет. В потоковых данных очень часто поток данных неравномерен.
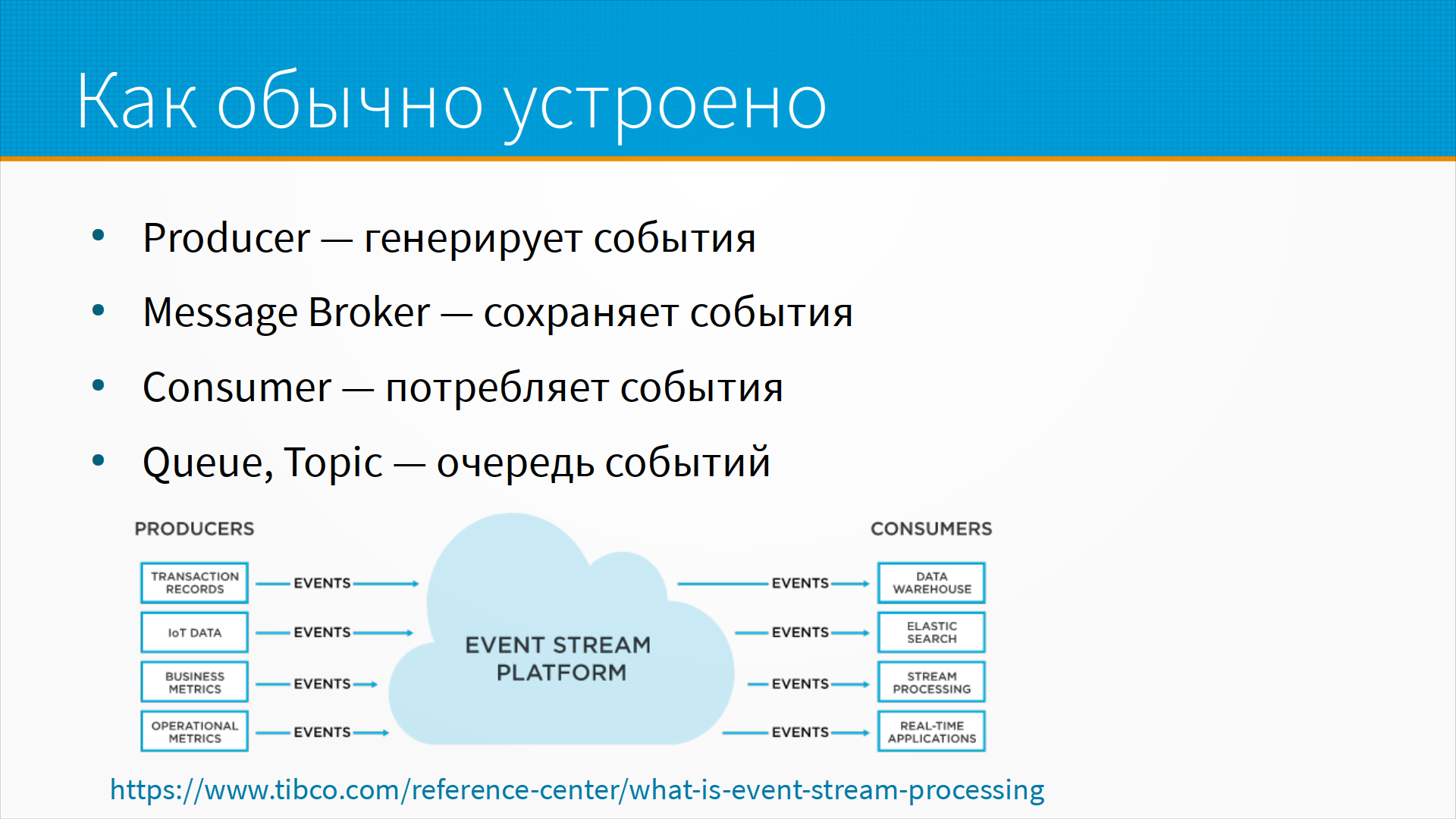
А как обычно это устроено? Есть некий producer, который генерирует события. Есть некий message broker, который сохраняет и перераспределяет события. Есть consumer, который потребляет события. И есть какой-нибудь queue или topic, в разных системах это называется по-разному – это некоторая очередь событий, в которую месседж-брокер складывает сообщения для тех или иных консюмеров.

Продюсер – это тот, кто генерирует события, некоторый внешний источник данных, это может быть ваше приложение. Он подключается к месседж-брокеру, и, кстати, он может быть одновременно консюмером, то есть он пишет в одну очередь, а читает из другой.

Месседж-брокер – это сервис, который получает сообщения, перераспределяет их, маршрутизирует в одну или несколько очередей, по запросу отдает сообщения из очереди и удаляет сообщения из очередей по запросу или по правилам. То есть, некоторые месседж-брокеры удаляют полученные сообщения, некоторые месседж-брокеры очищают очередь сообщений, когда, допустим, сообщение хранится больше определенного времени или очередь занимает больше определенного размера.

Ну и консюмер – это кто-то, кто получает сообщения, это может быть ваше приложение, какой-то внешний пользователь системы. Вы, кстати, во многих случаях можете предоставить интерфейс к вашей системе не как в RestAPI, а как, например, в Google Cloud Pub/Sub topic. Вам нужно обработать вашу данную моделью – ставьте ваши задачи вот в этот топик в брокере сообщений, мы их получим, и вот в этом топике вы получите ваш ответ. То есть, консюмер – это какой-то пользователь системы подключается к месседж-брокеру, и он одновременно может быть и продюсером, как в этом примере.

Что такое topic или queue? Это очередь сообщений, возможно, что в нее пишет много продюсеров, возможно, что из нее читает много консюмеров. Внутри одного месседж-брокера может быть много топиков или очередей. И важно, что сообщение внутри одного топика обрабатывается единообразно.

Какие бывают менеджеры очередей? В качестве месседж-брокера может выступать обычная база данных, это считается антипаттерном, но тем не менее есть хорошие примеры того, как это работает. Google Pub/Sub, есть Amazon Simple Queue Service и Яндекс Message Queue – это одинаково выглядящие снаружи сервисы. Я не знаю, как они внутри устроены, но они используют просто общие API, они взаимозаменяемы. RabbitMQ стоит несколько особняком. И, пожалуй, самый важный в промышленности брокер сообщений – это Apache Kafka. Apache Kafka отличается по модели обработки сообщений от RabbitMQ и Pub/Sub и SQS. Похожие на Apache Kafka сервисы – это Amazon Kinesis и Яндекс Data Streaming. Разберем их по очереди.
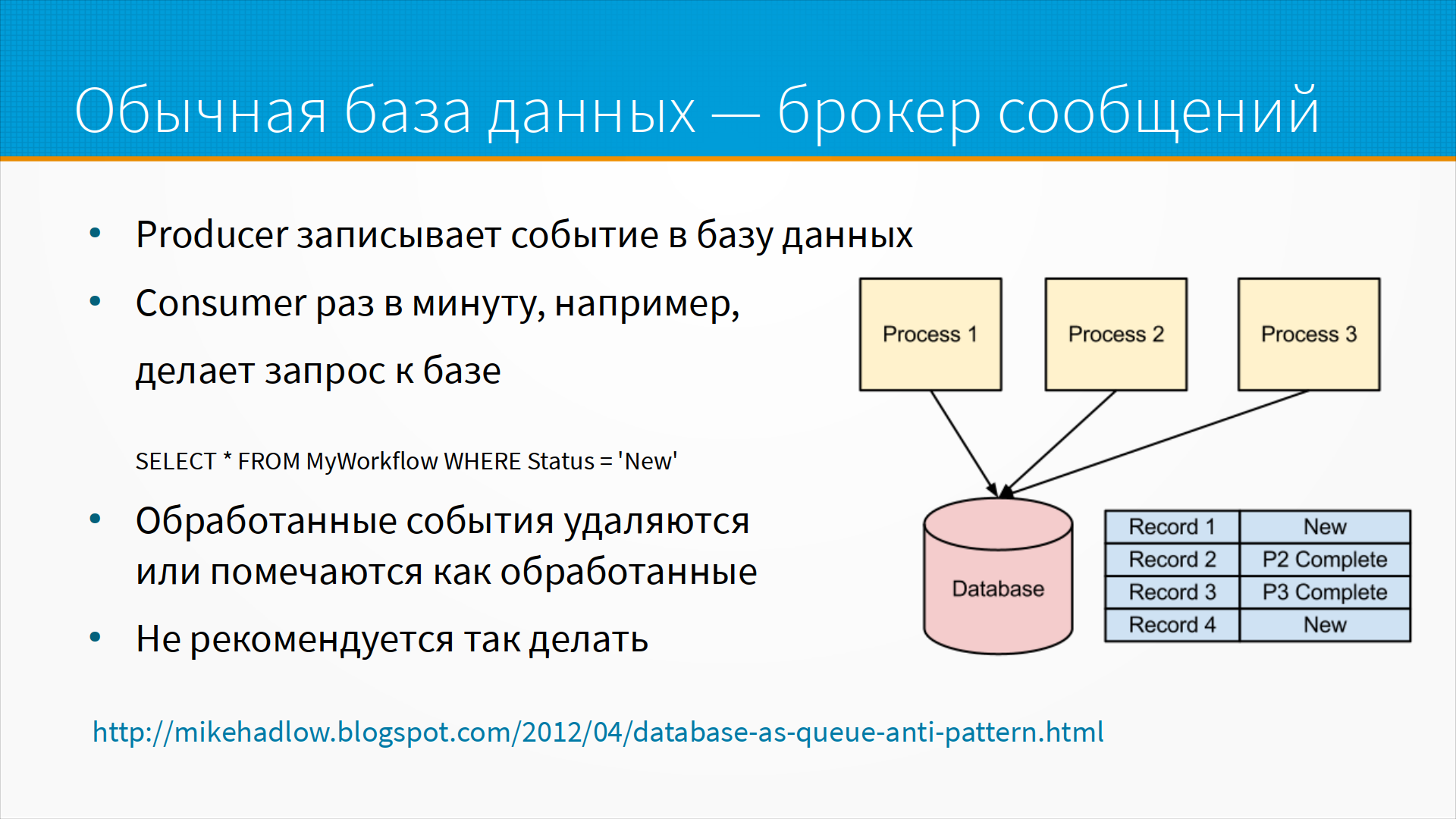
Обычная база данных как брокер сообщений устроена так. У нас есть некоторые продюсеры, которые записывают события в базе данных, то есть, буквально пишут в таблицу какую-то строчку. А консюмер, например, раз в минуту делает запрос в базу, что-то вроде "SELECT * FROM MyWorkFlow WHERE Status = 'New'". Отдайте мне, пожалуйста, новое сообщение. Он берет сообщение, обрабатывает его и помечает его как обработанное или удаляет его из таблицы. Обычно так делать не рекомендуется. По ссылке на слайде есть хороший разбор того, почему это антипаттерн.

Главным образом не рекомендуется так делать, потому что реляционные базы придуманы для другого типа нагрузки. Постоянная вставка и удаление записей в таблицу нарушают представление базы о том, как данные хранятся – редко вставляются, часто читаются, например, и еще реже удаляются. Многие базы данных, например, при удалении записи, не удаляют ее физически из таблицы, а просто помечают как удаленную. Таким образом, если вы будете тысячу раз в секунду вставлять и удалять записи, у вас таблица будет все время расти, и для того, чтобы ее именно сжать, выкинуть помеченное как удаленное сообщение, нужно запустить специальную процедуру. В разных базах она называется по-разному – например, вакуум или сжатие. И в этот момент в большинстве баз данных с таблицей ничего делать нельзя. То есть надо просто ждать, пока она сожмется.
Кроме всего прочего, это подразумевает, что у продюсеров есть прямой коннект в базу данных. Предположим, что ваш продюсер – это мобильное приложение конечного пользователя, которое по определению небезопасное, если оно в руках конечного пользователя, который вообще может попытаться сделать что-нибудь нехорошее. И предоставлять им прямой доступ в базу данных – это плохая идея. К тому же база данных не всегда хорошо работает, прямо вот так вот десятками, сотнями тысяч подключений. Почти всегда плохо работает.
Но так все равно делают. Почему так делают? Потому что в маленьких системах это очень удобно. А у вас обычно уже есть база данных, и она хорошо масштабируется. У нее есть системный администратор, который может ее настроить, чтобы она работала быстро. А еще с базами данных это удобно, когда у вас монолитная система, то есть она не порезана на микросервисы, а у вас все равно все компоненты имеют коннект к базе данных, и добавлять еще отдельную сущность трудно, а уже стоит мощная база данных, которая, допустим, собрана в кластер на какой-нибудь стойке хранения. И вообще-то в этом случае она может быть хорошо приспособлена для вставки и удаления больших объемов данных. При этом, поскольку это монолитная система, и у вас уже все равно есть коннект, мы тут не беспокоимся о том, что нам небезопасно давать прямой доступ продюсеру в базу данных, потому что он так у него уже есть.
Например, есть стартап Dagster, который под большой нагрузкой использует Postgres для обработки логов. По ссылке есть описание того, как они пришли к именно такой схеме. Они опытные инженеры, они понимают, что обычную базу данных вместо брокера сообщений использовать плохо. Но тем не менее, они используют, у них получается хорошо. И таких систем на самом деле очень много.
В продакшене очень много систем, которые как очередь сообщений используют обычную базу данных. И если вы увидите такой сценарий, не обязательно люди не умеют разрабатывать системы. Возможно, что у них есть для этого причины. Попытайтесь в этом разобраться.

Хороший пример очереди сообщений – это Yandex Message Queue. Там есть стандартные и FIFO очереди. В чем тут различия? В стандартную очередь вы отправляете сообщения и они в каком-то порядке, скорее всего, в том же порядке, в каком вы их поставили, и придут. Это не всегда удобно. Иногда нам важно фиксировать последовательность, в которой все произошло. То есть, мы сначала создали заказ, потом мы добавили туда товар, ну что-нибудь вроде этого, и тут нас выручают FIFO очереди – first in, first out.
У Yandex Message Queue есть интеграция с функциями и триггерами. Что это такое? Триггеры – это некоторые событи, которое срабатывают на добавление сообщения в очередь сообщений. Функции – это так называемые serverless-обработчики. То есть, представим себе, что мы написали некоторую программу, которая забирает одно сообщение из очереди сообщений, обрабатывает и складывает в другую. И настроили триггер, чтобы эта функция запускалась тогда, когда в очередь сообщений попадет какое-нибудь сообщение. И вот если мы не отправляем никакие сообщения, у нас не запускаются никакие функции. То есть, мы не платим за вычислительные ресурсы. Если мы пришли и отправили много сообщений, у нас запустилось много функций, быстро обработало наши сообщения, переложило их в другую очередь и опять ничего не делает. Это хороший шаблон для масштабирования в условиях пиковой нагрузки.
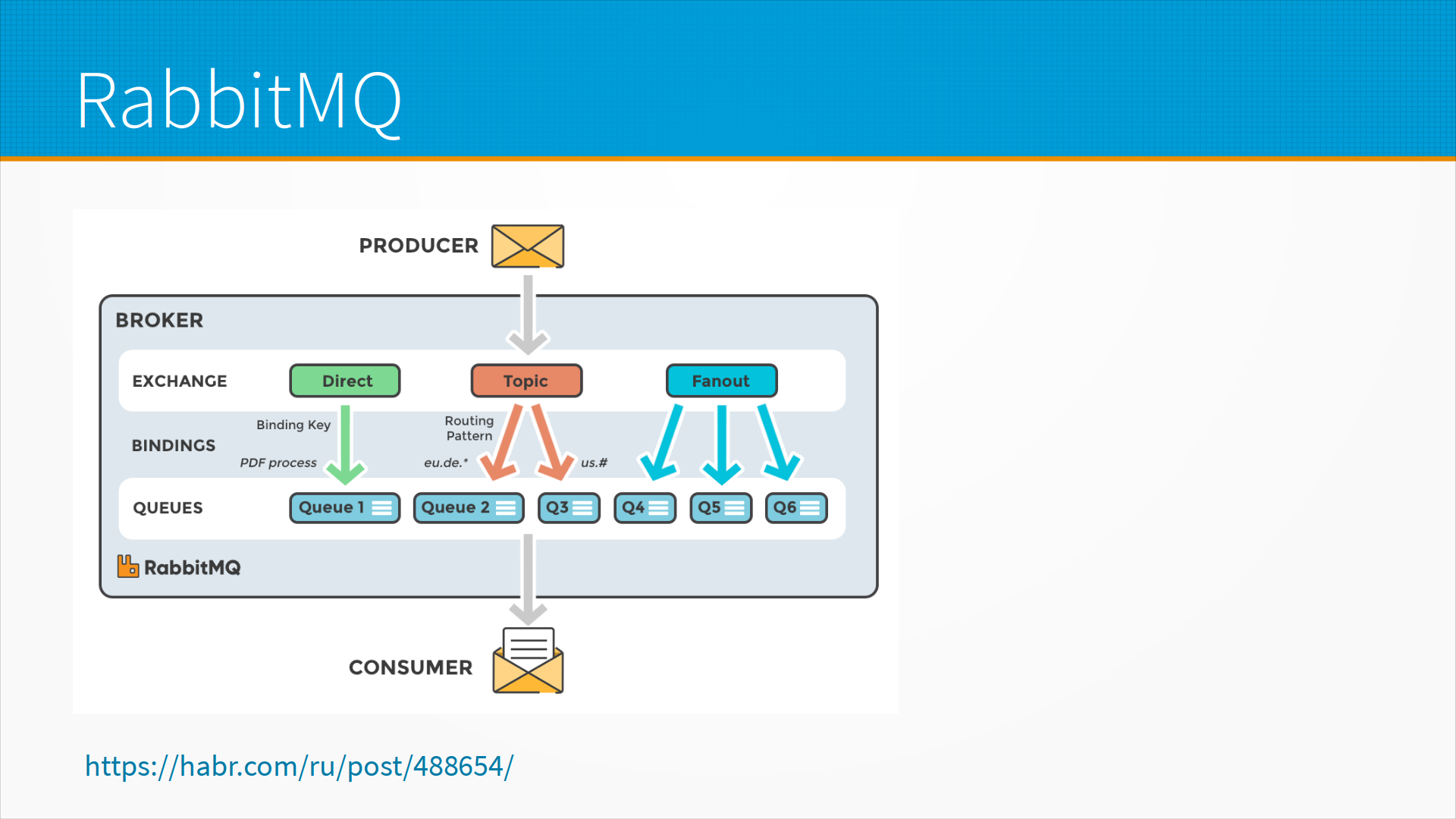
RabbitMQ – это брокер сообщений, первоначально разработанный для высокочастотной торговли акциями, когда важны тысячные доли секунды. Он как раз поддерживает базовые схемы, такие, как direct binding – это когда вы отдали брокеру сообщение, и он переложил его в какую-нибудь очередь. Некоторые топики могут распределять сообщения между очередями по каким-то правилам, и делать fanout, когда одно сообщение отправляется сразу в несколько очередей. На хабре есть хорошая статья про RabbitMQ.
В промышленности самый важный, как я уже говорил, брокер сообщений – это Apache Kafka. Apache Kafka устроен немножко по-другому, не так, как все остальные. Все остальные более-менее устроены как почтовые ящики. Вы положили письмо, оттуда письмо забрали. Как только письмо забрали, письма в почтовом ящике больше нет.
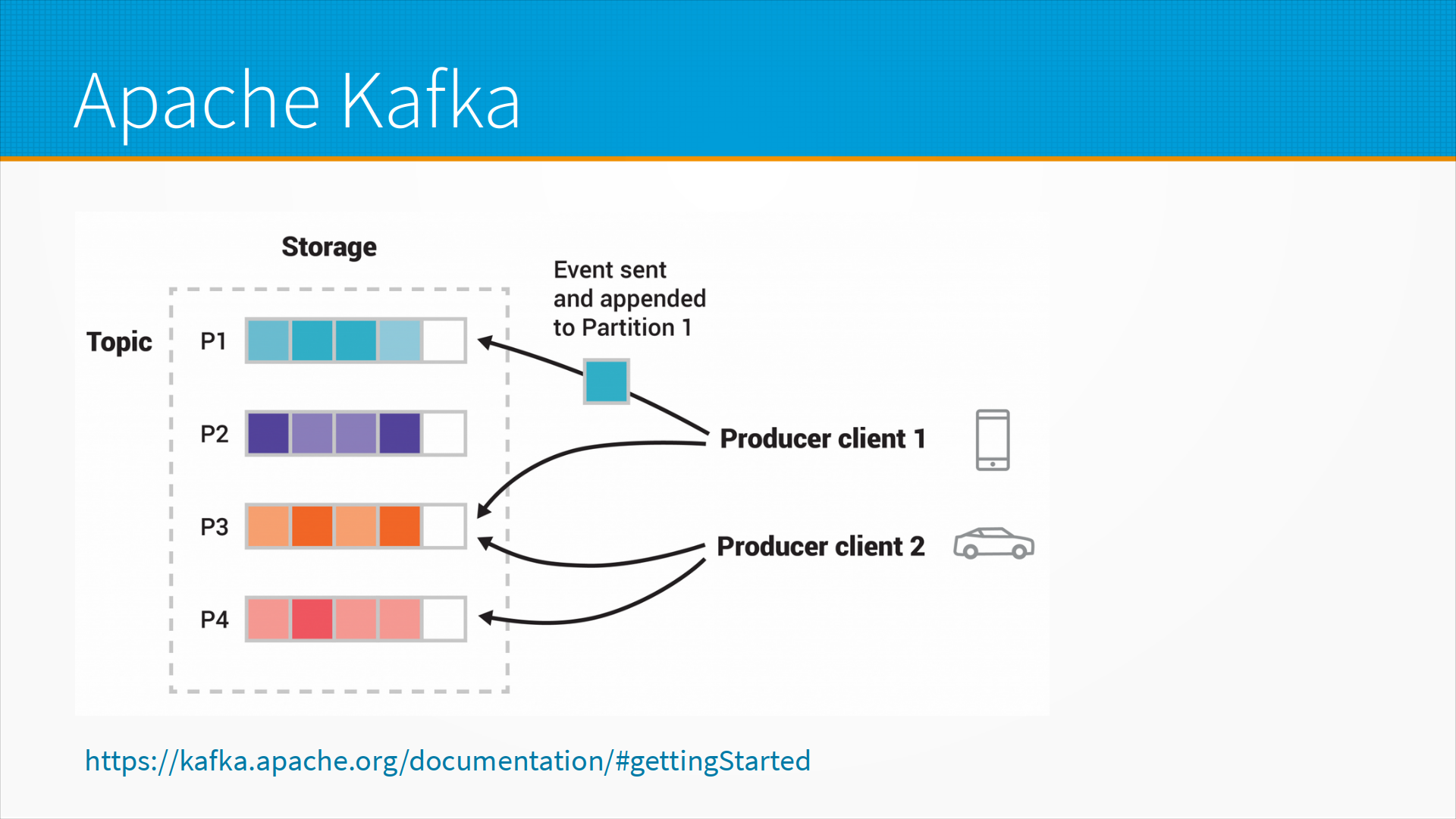
Apache Kafka устроен по-другому. Представьте себе, что у нас есть внутри несколько медленно движущихся лент конвейера. И входящее письмо попадает на эту ленту конвейера. И любой может подойти, прочитать – любой, у кого соответствующий доступ, конечно, есть к этой ленте конвейера, может прочитать это письмо, и оно останется на этом же месте. Каждый запоминает, до какого места в конвейере он дочитал. Это похоже на то, как мы разбираем багаж в аэропорту. То есть есть лента с вещами нашими и не нашими. Мы смотрим на них, находим нужные наши вещи, снимаем, ждем следующий наш чемодан. Как только очередь заполняется, скорее всего, в ней крайние сообщения выкидываются, новые добавляются. Опять же, один продюсер может отправлять в несколько очередей. Один клиент может читать из нескольких топиков.
Тут есть важное различие, что если вам нужно, например, 1000 топиков, то для RabbitMQ это легко, а для Apache Kafka, наверное, не очень. То есть ее топики более тяжеловесные. То есть если вам нужно много очередей – вам к RabbitMQ, если вам нужна возможность несколько раз обратиться к одному и тому же сообщению – вам к Apache Kafka.
Когда вам может понадобиться обратиться к одному и тому же сообщению несколько раз? Ну, например, если вы с помощью очереди сообщений обслуживаете запросы, которые внешне выглядят как синхронные запросы. То есть представим себе, что у нас есть в некоторой RestAPI сервис оценки кредитоспособности заемщика. Мы получаем запрос на оценку кредитоспособности, и в ответ нам в течение, скажем, секунды или двух прилетает ответ проскоренный. Может быть, 0.3 секунды, в зависимости от того, как это у вас работает. Сообщения ставятся в очередь, в очереди есть несколько слушателей. Во-первых, есть логер, который смотрит все сообщения и пишет их в лог. Затем есть, собственно, обработчик, который смотрит все сообщения. Сообщений много от разных отправителей, на каждом сообщении написано, кто его отправил. И воркеров много, воркер берет какое-нибудь из этих сообщений и идет с ними работать, обрабатывает его и ставит в очередь в другой топик из исходящих, уже обработанных сообщений. Там тоже стоит, кстати, логер, который логирует все обработанные сообщения. Исходный сервис, исходные воркеры, они также слушают, читают этот топик и ищут, как вы на багажной ленте, свой чемодан. То есть ждут, когда же придет ответ на их конкретно запрос, который они должны обработать. Найдут его – и отвечают пользователю, который у нас, так сказать, висит на трубке, ждет ответа, и завершают соединение.
Таким образом, для клиента это выглядело как синхронный запрос, а внутри у нас сообщение было поставлено в топик, обработано, поставлено в другой какой-то топик, обработано и возвращено. Нетрудно заметить, что это позволяет нам масштабировать, например, количество узлов, которые принимают сообщение, либо количество узлов, которые обрабатывают сообщение, в зависимости от того, где у нас нагрузка больше.

Ну и про Apache Kafka – каждый клиент помнит, докуда он дочитал. Кроме того, можно делать оконные запросы к потоку сообщений. То есть, например, дайте мне, пожалуйста, 10 сообщений, начиная с вот этого вот номера.
Обычно топики удаляют старые сообщения. И может получиться так, что уже удалили сообщения, которые вы не успели прочитать. Это обычно вызывает ошибку клиента. Тут надо это вручную как-нибудь обрабатывать. Что такое обрабатывать вручную? То есть, если мы потеряли сообщение, то есть конвейер уехал, а мы не читали те сообщения, которые сейчас там уже потеряны, мы должны как-то сообщить нашим клиентам, что мы не смогли обработать наш запрос, найти самое свежее сообщение и начать обрабатывать с его.
Apache Kafka – это самый сложный и, наверное, полезный вариант в построении систем потоковых. Он требует такой зрелой инженерной культуры. Там очень легко выстрелить себе в ногу. В принципе, если вы будете строить очереди сообщений, похожие на модели Apache Kafka, вам следует использовать Яндекс Data Streams или Amazon Kinesis, они позволяют реализовать такие же модели.

Что делать с потоковыми данными? То есть, вот у нас потоковые данные идут, а как мы их обрабатываем? Ну, во-первых, мы можем делать оконные запросы. Например, среднее количество запросов к сервису с этого IP-адреса за последние 30 минут, ну, чтобы отловить ботов, например. Мы можем строить материализованное представление. То есть, вот у нас, например, есть некоторый пользователь, который путешествует, и нам идет поток его координат. И мы где-то в какой-то таблице все время обновляем его последнее положение. Таким образом, пользователю системы не нужно идти в Apache Kafka, он из таблицы, из материализованного представления, читает наши насчитанные признаки. Ну и мы можем насчитывать более сложные признаки. Мы их обновляем по мере поступления новых сообщений и используем их при обработке запросов.
Мы можем настроить триггеры при выходе оконной статистики за пределы. То есть, например, если количество запросов с какого-то IP-адреса за полчаса превысило какой-то наш порог, мы можем либо отправить уведомление, либо запустить какую-то реакцию на событие. А в случае, например, если у нас как-то резко уплыла статистика входных сообщений, мы можем инициировать переобучение модели, например. То есть, детектировать сдвиг данных непосредственно из потока. Я думаю, что буквально так делать это не очень хорошо, прямо из потока детектировать сдвиг данных, но возможны ситуации, когда и это будет хорошо.

Пример того, как можно было бы думать о системе потоковой обработки. Пусть у нас есть один сервер, который обрабатывает 10 запросов в секунду. Пусть у нас один запрос – это 1 Мбайт входящего трафика и, скажем, 10 Кбайт исходящего трафика. У нас тысяча пользователей, каждый из них будет отправлять 10 запросов в день. И запросы будут идти равномерно в рабочее время, с 8 до 18. Итого у нас получится 10 000 запросов за 10 часов. То есть, примерно 0.3 запроса в секунду наш сервер легко сможет обработать. И входящий трафик не очень велик – 3 Мбит в секунду.

А тут можно обратить внимание, что я умножил не на 8, а на 10. То есть, мы, грубо говоря, имеем некоторое количество мегабит, которое мы хотим передать. А пропускная способность сетей традиционно измеряется в мегабитах и гигабитах. Кажется, что 1 Мбайт – это 8 Мбит. На самом деле чуть-чуть больше. В теории 100 Мбит на Ethernet прокачивает 96 Мбит, то есть 12 Мбайт, а на практике – еще меньше. Почему это возникает? Потому что каждое сообщение оборачивается в некоторые служебные заголовки. Между ними есть некоторые паузы. Если мы используем HTTP и HTTPS, то протокол еще сверху не очень эффективно использует наше пространство, и лучше недозаказать пропускную способность, то есть умножаем не на 8, а на 10. Fast Ethernet у нас 100 Мбит, Gigabit Ethernet – 1000 Мбит. Есть некоторые пределы пропускной способности коммутаторов. Например, у нас есть, допустим, 8-портовый гигабитный коммутатор, но реально он может обработать не более 3 Гбит, например, трафика. То есть, дешевые гигабитные коммутаторы часто обрабатывают 2 Гбит трафика. То есть, вы два порта полностью загрузили, третьему уже пропускной способности не хватит, но не канала, а коммутаторов.
Существует технология объединения каналов, то есть, в сервере может быть несколько сетевых карт, 10-гигабитных, и, например, он объединяет их вместе. Данные режутся на кусочки, часть отправляется через одну карту, часть через другую, на стороне коммутатора собирается. То есть, практически мы можем иметь и 50-гигабитные каналы и так далее и тому подобное. Но все это надо знать и заранее думать, что обычно это не работа дата-сатаниста, это работа дата-инженера, работа серверного подразделения эксплуатации и так далее.
Из полезных вещей про размер байта надо понимать, сколько весит, допустим, картинка. Вот если у нас картинка весит 1 Мбайт, сколько она занимает полосы пропускания? Она может занимать 1 Мбайт, если мы ее передаем через какой-нибудь бинарный протокол, например, Protobuff. Она может занимать значительно больше, если мы ее передаем, например, в виде Base64 или какой-нибудь другой кодировки, которая часто используется в вебе. Тут надо смотреть, какого на самом деле размера ваши данные. Если вы отправляете 1 Мбайт, вовсе не значит, что именно 1 Мбайт полосы пропускания будет использован, может быть использовано гораздо больше.

Пример еще один. Допустим, сервер может обработать 10 запросов в секунду, все остальное так же. У нас не 1000 пользователей, а 10 000 пользователей. У нас 100 000 запросов, трафик, входящий по-прежнему, вполне попадает в fast ethernet. 3 запроса в секунду. И КПД нашей системы 12%, то есть ночью она не загружена.

Допустим, внезапно у нас изменится схема отправки запросов, то есть запросы будут идти все так же в рабочее время, но в первый час все отправят в среднем, допустим, 5.5 запросов, а все остальные запросы отправят в течение рабочего дня. Для многих приложений корпоративных это очень реалистичная схема – когда все утром запускают свои компьютеры, все утром начинают обрабатывать свои задачи, и потом в течение дня запросов гораздо меньше. Но вот в этой схеме мы имеем 55 000 запросов в первый час работы, то есть 15 запросов в секунду. И трафик 153 мегабита в секунду. Мы помним, что наш сервер может обработать 10 запросов в секунду. В среднем у нас 3 запроса в секунду в сутки – должно хватить одного сервера, но у нас не хватит его, потому что нагрузка собрана в один большой пик.

А что мы можем сделать? Мы можем поставить два сервера. И у нас будет прокси-сервер на входе, два сервера, пропускная способность системы 20 запросов в секунду, или почти 2 миллиона в сутки. КПД системы около 6%. Почти весь день у нас используется одна треть одного сервера, ночью сервера не используются совсем, но мы платим за два сервера и за прокси-сервер. Мы вроде бы решили проблему пропускной способности, но мы здорово увеличили наши эксплуатационные расходы. Мы подняли кучу железа, которое стоит и не используется.

Если шаблоны использования наших сервисов позволяют обрабатывать запросы с задержкой, мы можем обойтись сервером очередей. То есть мы ставим наши сообщения в сервер очередей, сервер принимает задачи, ставит их в очередь, воркер выбирает задачи по мере возможности и обрабатывает, а результат клиенту, например, приходит по электронной почте или в другую очередь. Таким образом, мы платим за воркера и за сервер очередей. То есть нам хватает одного воркера, но клиенты приходят к нам и жалуются, что долго ждать обработки.

Вариант с облачной функцией. Предположим, что нам этот мегабайтный файл не поступает никуда, а складывается в S3. И как только файл в S3 создался, срабатывает триггер, запускается облачная функция. А готовый результат после обработки нашей облачной функции складывается в очередь сообщений, сервис выбирает из очереди сообщений и отдает клиенту. Платим мы только за время работы облачной функции. Скорее всего, это обойдется нам примерно в 5 раз дороже в расчете на одно сообщение, но при этом КПД системы близок к 100%. То есть по деньгам мы, скорее всего, особенно не сэкономили. Это та же самая история, что у нас один сервер стоял и все обрабатывал. Мы заплатим, скорее всего, столько же, но мы получили возможность обрабатывать пиковую нагрузку так, условно, без ограничений. То есть мы можем в два, в три раза получить пик и наш сервис это обработает нормально, без задерживания.

Дополнительные материалы: