
- 13.11.2022
- 25.08.2024
- обучение
- #mlsystemdesign
Восьмая лекция открытого курса "Дизайн систем машинного обучения", "Диагностика ошибок и отказов".
Слайды можно скачать тут mlsysd8ods.pdf
Текстовая расшифровка:


Добрый день, меня зовут Дмитрий Колодезев и это восьмое занятие нашего курса про ML-System Design - "Диагностика ошибок и отказов ML-систем". Прежде чем говорить о диагностике отказов ML-систем, нужно уточнить про петлю обратной связи, которую мы используем при обучении.

Петля обратной связи - это процесс, при котором выход модели влияет на входные данные, то есть те, которые идут на вход модели. Или в случае нашего обучения - это когда данные, которые мы выдали, то есть наше предсказание, каким-то образом попадает нам на вход нашей модели в качестве обучающих данных.
Для обучения нам нужны метки, и метки полезно разделять на естественные метки, то есть метки, которые нам доступны непосредственно из входных данных, То есть обычно вскоре после события, которое оценивала модель. Например, мы предсказывали переход по ссылке в рекомендательной системе, и пользователь перешел, мы это видим прямо из данных. Или есть отложенные метки, delayed labels - это метки, доступные с большой задержкой. Что такое большой - зависит от контекста. Пример отложенных меток - это возврат кредита, то есть мы оценили кредитный скор человека, решили, что кредит ему можно выдать. А узнаем мы, вернул он его или нет, спустя 90 дней после того, как пройдет срок выплаты по кредиту.

В естественных метках система может полностью или частично оценивать качество своей работы из доступных ей данных. Пример естественных меток - это, например, расчетное время прибытия, то есть мы предсказываем, что курьер приедет через 10 минут. Он приехал через 11 - и мы видим эту разницу непосредственно из данных. Или прогноз спроса на поездке в такси, цена акций, процент кликов по рекламе, ну и рекомендации рекомендательной системы - мы можем обычно отслеживать напрямую. То есть купил человек, перешел по странице - это естественные метки, которые нам доступны из данных.
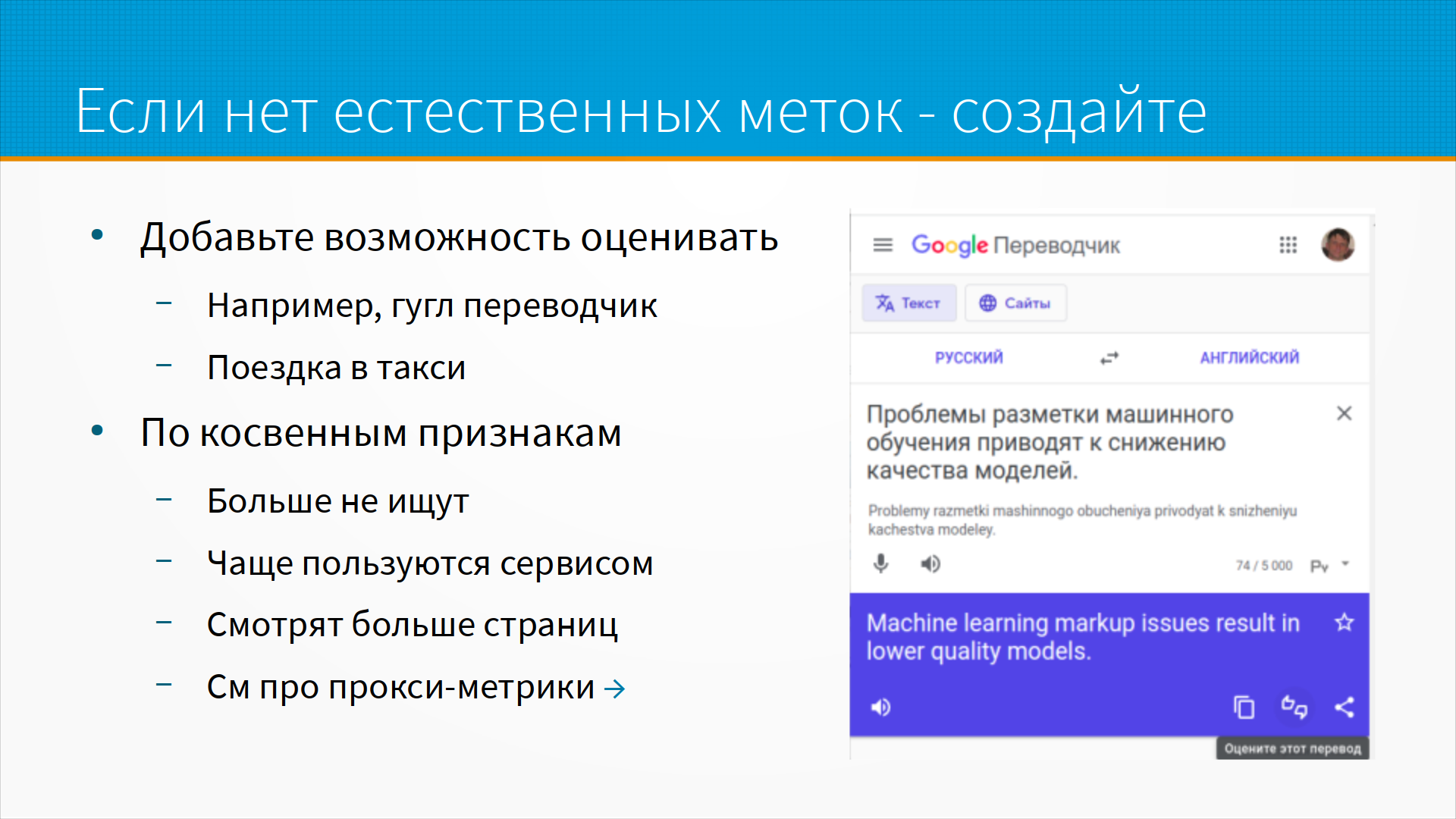
Не всегда есть естественные метки, но, когда их нет, мы можем их синжинирить, добавить. Например, в Google Переводчик есть кнопки оценки качества перевода или возможности предложить свой перевод. Таким образом Google Переводчик может собирать естественные метки с перевода. В такси мы можем оценить качество поездки звездочкой.
Ну и часто метки оценивают по косвенным признакам. Например, человек зашел в поисковую систему, набрал запрос, и больше он не ищет. Наверное, мы предполагаем, что, он нашел то, что нужно, на первой же странице. Ну, или, например, ему выдача показалась совершенно нерелевантной, и он нашел другую поисковую систему. Опять же, по косвенным признакам мы можем оценить, что, если человек стал чаще пользоваться сервисом, то, наверное, рекомендации улучшились.
Но и это может быть совершенно неверно. Например, в мире может произойти что-то такое, например, резкое изменение курса валюты или какой-нибудь экономической ситуации, и люди просто начали чаще пользоваться нашим сервисом - совсем не потому, что наши рекомендации хороши, а просто им чаще нужно.
Косвенный признак - люди смотрят больше страниц, потому что им нравится наш сайт. Ну это тоже очень спорный косвенный признак, но часто используемый. Пример - это когда Microsoft сломала поиск в своем Bing, и люди стали смотреть в три раза больше страниц для того, чтобы найти то, что им нужно. Статья про это была в дополнительных материалах. Ну и на хабре есть отличная статья про прокси-метрики, где эти варианты разобраны.

У естественных меток есть свои проблемы. Одна из них - это неполная выборка, то есть у нас часто естественные метки доступны не для всех точек данных. Например, в случае рекомендательных систем у нас есть так называемые имплицитные метки, то есть мы узнаем, что человеку понравилось, потому что он купил, но мы не узнаем, что человеку что-то не понравилось, потому что он, может быть, не купил, а может быть, просто не нашел, или, может быть, купит попозже. В естественных метках есть selection bias. Нам часто будут говорить о проблемах, но нам не будут говорить, когда все прошло хорошо, потому что кто же о таких вещах говорит.

С отложенными метками, как, например, погашение кредита, у нас сразу возникает проблема - можем ли мы обращаться с ними как с обычными метками, то есть просто подождать, пока они приедут, или нам нужно что-то по этому поводу предпринимать отдельно?
Отложенные метки - это, например, инвестиционные рекомендации по строительству, скажем, магазина или вложению в какие-нибудь акции. Магазин отбивается, например, через три года, если сильно повезло, то через полгода, но это какая-то чудовищная отдача. Иногда через пять, а инвестиционные рекомендации - ну, разумно держать деньги в акциях, например, полгода хотя бы. Поэтому о успешной или неуспешной рекомендации мы можем судить с большой задержкой, и, скорее всего, к тому моменту, когда эта разметка у нас уже придет, мир у нас уже изменится, и эта разметка будет относиться не к нашему распределению, а к тому распределению, которое уже сдвинуто.
Во многих случаях долго - это часы. Например, в случае ТикТока, если у вас появилось новое вирусное видео, и вы целый час его не рекомендуете пользователям, это, наверное, слишком долго. А в случае мошеннических схем с финансами недели или месяцы - это уже долго. То есть, если вы спустя месяц нашли fraud по кредитной карте - это плохо. А зачастую как раз разметка приходит через месяц, потому что многие люди, допустим, в тех же самых штатах сверяют свои выписки по кредитке раз в месяц.
Долго - это если за время получения данных метки изменилось распределение целевой переменной входных данных, ну или форма зависимости, то есть случился тот самый дрифт, о котором мы говорили.
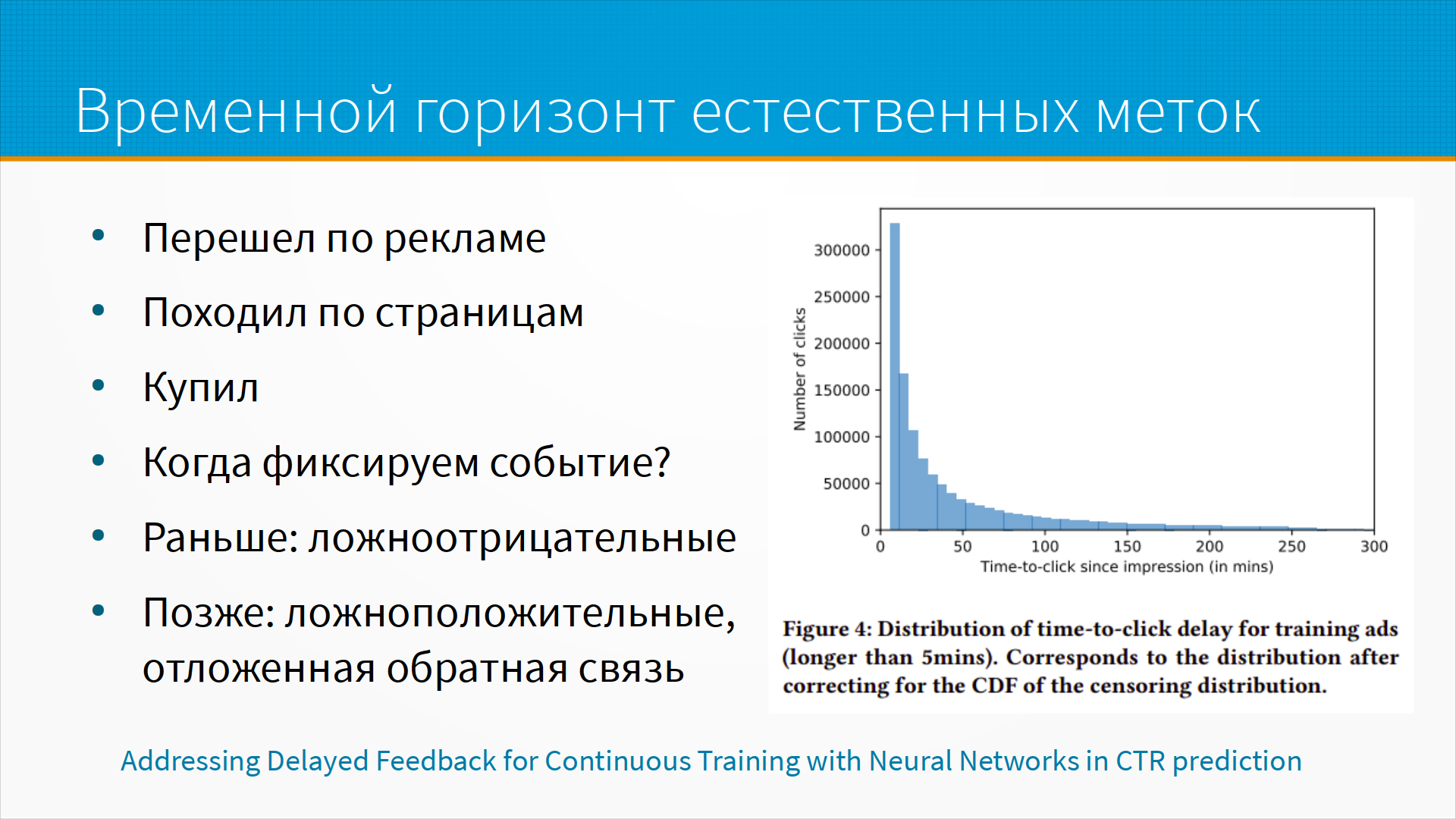
Про временной горизонт естественных меток - там тоже спорный вопрос. Например, человек перешел по рекламе, и мы зафиксировали это как разметку. Да, реклама ему понравилась, она хорошо сработала. Но вот на слайде у нас распределение времени действий пользователя после перехода по рекламе, и мы видим, что значительная часть пользователей в течение одного часа принимает решение о покупке. Но некоторые ждут и пять часов, а в моей практике я наблюдал, когда решения в интернет-магазине, это было видно по логам, принимались на протяжении нескольких месяцев. И в конце концов люди покупали - они просто все это время большую покупку согласовывали со знакомыми, с родственниками, согласовывали со своими бюджетными возможностями.
Вопрос - когда мы в данном случае фиксируем наше событие естественной метки? Если мы фиксируем раньше, то есть, например, считаем, что в первые 10 минут после перехода по рекламе человек купил, у нас будет много событий, которые мы не зафиксируем. Если мы отложим нашу реакцию и будем ждать, допустим, час или два или три, то у нас будет много ложноположительных срабатываний, когда мы посчитаем метку по рекламе, хотя на самом-то деле человек купил по совсем другой причине. То есть, он перешел по рекламе, реклама ему не подошла, но потом ему кто-нибудь прислал ссылку, сказал - слушай, вот это вот я хочу, - и он подумал - ну да, на самом деле, ладно, куплю.
Решение о горизонте естественных меток - это бизнес-решение, которое надо тестировать. В статье, ссылка на слайде, этот вариант разбирается.

Что мы считаем отказом ML-системы? Требования к системе формализуют через метрики - то есть, как мы поймем, что система работает правильно или неправильно? И метрики - это могут быть либо операционные метрики, средняя задержка, пропускная способность, процент доступности, либо ML-метрики, какой-нибудь BLEU или F1 или Accuracy.
И метрики обычно формализуют в виде Service Level Agreement. Например, у нас есть некоторые обещания, что мы вернем нашим пользователям деньги или посыпем голову пеплом, если наш сервис будет ошибаться больше, чем в 0,001% раз. При этом SLA, Service Level Agreement, устроен следующим образом. У нас есть некоторая метрика, которую мы готовы измерять - ее называют Service Level Indicator. Например, процент отказов нашего сервиса в течение получаса. И есть Service Level Objective - это некоторый уровень, на котором мы хотели бы удерживать наш индикатор. И вот если мы грубо нарушаем наш Service Level Objective, то есть качество упало сильно ниже поставленных нами планок или поднялся сильно выше заявленного уровень ошибок, скажем, в 2, 3 или в 10 раз, вот тут у нас должен срабатывать Service Level Agreement. То есть это три разных показателя, связанных друг с другом.

Пример отказа онлайн-переводчика. Если мы ввели текст и не получили перевода, это операционный отказ. Мы по журналам можем найти этот случай, по журналам сервиса, и разбираться, почему так случилось. Но если мы ввели текст и получили неправильный перевод, является ли это отказом?
Вообще не обязательно, потому что вообще-то во всех ML-системах мы ожидаем какой-то процент неправильных решений. И в данном случае отказом будет, если онлайн-переводы все будут неправильные или их будет слишком много - скажем, больше определенного процента.

Вот, например, меню в ресторане, где сами по себе блюда написаны на китайском, но ресторатор перевел их на английский с помощью Google-переводчика, и в результате у нас получились такие блюда, как жареная Википедия, например, или, например, яйца на пару с Википедией.
В данном случае особенность ML-систем - что ML умирает молча. Когда у нас происходят операционные ошибки, то есть сервис не отвечает, сервис отвечает медленно, обычно у нас срабатывают какие-то алерты, к нам прибегают разгневанные пользователи. Если ML начинает выдавать чудовищно нелепые предсказания, этого может никто не заметить месяцами.

Ну, вот пример, например - кто тут сладкая булочка? - это как нейронные сети ошибаются в классификации между хлебобулочными и собачками. Ну, надо заметить, что люди тоже тут могли бы ошибиться, если у человека плохое зрение. То есть, в принципе, сам по себе факт ошибки еще не говорит о том, что модель плохая. Насколько нам важно именно в нашем бизнесе отличать булочек от собачек - это большой вопрос.

Причины операционных отказов понятны. Обычно это либо проблемы зависимостей, либо какие-то проблемы деплоя, развертывания, либо аппаратные отказы, то есть у нас умер сервер, либо у нас какие-то сетевые проблемы - недоступность или перегрузка каналов. И на самом деле больше половины отказов, по некоторой оценке - 60% ML отказов, - они на самом деле где-то под капотом операционные. То есть, у нас сломалась какая-нибудь часть пайплайна, и в результате у нас идут либо пропущенные данные, либо данные с задержкой, либо не совсем те данные. И в результате мы это можем заметить только как ошибку ML-сервиса, как некачественное ML-предсказание. На самом-то деле там под капотом могла сломаться какая-то железка.
Ну и в принципе в инженерии программного обеспечения с качеством всегда было не очень. ML-модели тут ничем не отличаются. Если бы мы проектировали бары, то пользователей, зашедших выпить, убивало бы через одного.

Типичные причины специфичных для ML отказов. Например, реальные данные отличаются от обучающих данных. Например, при обучении мы имели доступ к хорошим пользователям в основном, а на проде к нам пошли плохие заемщики и фродеры.
Есть крайние случаи, то есть какие-то очень редкие ситуации, с которыми мы все-таки должны работать, но их в обучающей выборке мало, просто понятно, потому что это крайние случаи.
Ситуация вырожденной обратной связи типична для рекомендательных систем. То, что называется echo chamber, эховая комната: когда мы получаем те рекомендации, похожие на те, по которым мы уже кликнули. Соответственно, мы можем кликать только по ним. Дальше нам покажут еще более похожие на нас рекомендации.
Или другой пример - программа, которая учится стратегии, обыгрывая другие программы. И в конце концов программы начинают играть таким способом, каким не играют люди, и люди их обыгрывают легко. Просто потому, что программы и люди начинают играть по-разному. То есть в процессе обучения у нас сдвинулись обучающие датасеты.

Про отличие обучающих и реальных данных. Часто модель работает на реальных данных хуже, чем на тестовых. Или модель начинает со временем работать хуже. Это обычно говорит о сдвиге распределений. Вообще-то, это не обязательно сдвиг распределений. Это могут быть ошибки при разработке - например, утечки разметки, даталики. Когда вы видите, что ваша модель работает плохо, или у вашей модели на рабочих данных качество хуже, чем на обучающих; когда вы видите, что у вас внезапно откуда-то резко появился сдвиг распределений - возможно, что это просто ошибки разработки.
Я встречал ситуации, когда резкий сдвиг распределений был вызван изменениями в интерфейсе для ввода данных. Это была система для выбора кредита, где выкатили новый дизайн формы для запроса кредита. И движок с суммой кредита был по дефолту в другом положении. В результате у модели были проблемы.

Необычные ситуации, с которыми модель работает плохо, могут быть выбросами или крайними случаями. И то, и другое - это что-то странное, необычное для распределения, из которого мы брали примеры.
Но выбросы - это необычные входные данные, которые мы можем проигнорировать. Например, если у нас есть медосмотр, и к нам приходит человек с необычно редким или частым пульсом, наверное, это просто такой выброс. Бывают некоторые люди, много бегают, например, 40, 50, 60, 100 км в неделю. Их пульс редкий, сильно реже, чем у остальных.
И бывают крайние случаи - это необычные результаты, которые не похожи на остальные данные, но их нельзя игнорировать. Например, человек с обычными показателями, с обычным давлением, с обычным пульсом, но с тяжело больным сердцем. И вот тут нам нужно смотреть на то, можем ли мы эти данные выкидывать.
Пример выбросов самый частый - это шум датчика. Пример крайних случаев - это просто недостаточность данных для какого-то редкого класса.

Пример крайнего случая, наверное - это когда автопилот ошибается, потому что глядит на зеркальное отражение дороги в проезжающей цистерне с горючим. То есть на фотографии, на слайде у нас изображена цистерна. Это из доклада Андрея Карпаты про то, как они учили автопилот для Теслы.

Про выраженную обратную связь мы уже говорили. Это когда вам рекомендуют ролик про котят, вы щелкаете по ролику про котят, модель думает - о, он любит ролики про котят, - и больше ничего, кроме котят, вы не увидите.

Какие тут есть проблемы? Изначально ролики с котятами, может быть, случайно были чуть выше остальных. Возможно, это был просто шум, но, так как они стояли сверху, вы по ним чаще кликали, а так как вы по ним чаще кликали, модель решила, что они важны. Разница роликов с котятами и роликов с собачками увеличилась, и спустя какое-то время рекомендации становятся однородными. То есть вам не рекомендуют ничего такого, что вы уже не видели.
Проблема выраженной обратной связи в том, что ее очень трудно поймать при обучении. Она возникает только в реальной работе, и ее трудно смоделировать. Можно моделировать работу системы, чтобы проанализировать возможность возникновения вырожденной обратной связи, но это сложное и неочевидное дело.

Как мы можем выявить вырожденную обратную связь в мониторинге? Достаточно простые метрики - это средний процент трафика у товара, которого мы рекомендуем. Если мы видим, что мы все чаще и чаще рекомендуем только те товары, по которым ходят все, это может означать одно из двух. Либо у нас появился какой-то суперпопулярный товар, который на самом деле всем нужен - вышел новый iPhone. Либо у нас модель заклинила, и она рекомендует только то, почему пользователь уже кликнул.
Средний процент рекомендаций с длинного хвоста - мы предполагаем, что у нас частота рекомендаций для товаров распределена по так называемому power law, степенному закону. То есть, грубо говоря, первый по популярности товар получает половину кликов, второй - треть, третий - четверть и так далее. В общем, по степенному закону убывает процент трафика по товарам. И в конце мы имеем так называемый длинный хвост - куча товаров, на которые мы имеем один переход в день, а то и в месяц. И в здоровых рекомендациях должен быть постоянно какой-то процент редких рекомендаций, товаров из длинного хвоста. То есть, они в целом никому не подходят, но вот именно этому пользователю они самое то, что нужно. И этот процент можно мониторить.
Мы можем сравнивать, насколько разнятся рекомендации для разных пользователей. Если, например, для совершенно разных пользователей у нас одинаковые рекомендации, то, наверное, наша рекомендательная система просто рекомендует самые посещаемые товары без учета особенностей каждого пользователя.
Важно отслеживать процент товаров, которые никогда не попадают в рекомендации. Он может быть шокирующие высок. То есть, я на практике сталкивался с хорошими рекомендательными системами, которые никогда не рекомендуют две трети товаров. То есть, есть где-то треть товаров, которая всегда попадает в рекомендации, а две трети не попадаются никогда. Они, тем не менее, хорошо продают, пользователям нравится, но у нас получается такая большая куча товаров, которые никто никогда не рекомендует, и пользователь их сам не найдет.
Еще, если у нас падает CTR, то есть конверсия на первой странице рекомендаций, наверное, пользователь на ней не нашел то, что ему нужно, и пошел искать дальше. Это также заметно по росту CTR на второй и третьей страницах выдачи.

Как мы можем бороться с вырожденной обратной связью? Самый распространенный подход - это рандомизация. Мы можем разбавлять выдачу случайными рекомендациями. То есть, например, мы выдаем 5% кредитов, несмотря на то, что мы бы не хотели их выдать, или мы добавляем в нашу выдачу, в наши 10 ссылок, одну случайную, и собираем обратную связь и смотрим, была ли хороша наша случайная рекомендация.
Мы можем расширять рекомендации. Например, добавлять не ML рекомендации. У Яндекса это то, что они называли колдунщиками, или, например, там Spectre была, по-моему, такая технология, когда часть выдачи образуется экспертной системой, напрямую не связанной с вашим запросом, а скорее отслеживающей то, как вы себя ведете - какие-то новые поступления, рекомендации экспертов в этой категории.
Ну и позиционные признаки - это способ учитывать разницу в конверсии на разных позициях выдачи. То есть по первой ссылке выдачи всегда щелкают чаще, по следующим трём, с второй по четвёртую, пореже, но тоже чаще, с пятой по десятую - по ним щелкают редко. На вторую страницу вообще мало кто заходит.

С позиционными признаками есть вариант добавить признак позиции. Просто добавить в обучающие данные признак, была ли эта рекомендация показана на первой странице, когда по ней кликнули. И мы выставляем этот признак всегда в False во время предсказания, чтобы найти те рекомендации, которые бы кликнулись, даже если бы их показали не на первой странице или там внизу, потому что как раз именно это мы и ищем.
А другой вариант - мы можем взвешивать наши сэмплы при обучении, то есть чем выше позиция, тем меньше вес обучающего примера. Например, для первых трёх позиций пусть у нас вес будет 0,6, 0,75 и 0,9, а все остальные мы берём с весом 1.

Про сдвиг распределений. Наша модель аппроксимирует некоторую зависимость F от данных, разметки от данных. И мы можем выделять три важных практически разных случая.
Это сдвиг ковариатов - это когда распределение входных данных изменилось, но сама зависимость осталась та же самая.
Сдвиг разметки - это когда у нас изменилось распределение нашего целевого признака, но сама структура зависимости не изменилась.
И концепт дрифт - это когда у нас изменилась сама форма зависимости, то есть при тех же вводных мы должны получить другую разметку.

В случае сдвига ковариатов зачастую, если у нас изменилось распределение входных данных, у нас изменится и распределение выходных данных. Хорошо помогает взвесить обучающие данные по степени близости к рабочим. У нас, допустим, когда обучающих данных много, а свежих данных сдвинутых мало, мы можем выкинуть те обучающие данные, которые не похожи на те, что к нам придут сейчас с прода, либо построить некоторую функцию, которая предсказывает - с прода эти данные взятые или это наши старые обучающие данные архивные, и взвесить наши обучающие данные по тому весу, который выдаст эта функция. То есть, грубо говоря, если модель не может отличить наши обучающие данные от наших рабочих, значит, это хорошие обучающие данные. И вот тут есть статья про то, как это делать для нейронки.

По сдвигу разметки - зачастую это просто следствие сдвига ковариатов. Надо проверять баланс классов. Возможно, придется взвешивать классы. Потому что возможно, что у нас просто один из классов в нашем домене перестал к нам приходить, например, или стал приходить гораздо реже.

А самая сложная ситуация – это сдвиг концепции, концепт дрифт. Когда изменилась форма зависимости нашей целевой переменной от наших признаков. Например, изменилась ситуация на рынке. Это может быть цикличное сезонное изменение, и его хорошо бы отследить и учитывать. То есть, например, у нас может быть сдвиг, но этот может быть сдвиг, цикличный летом - каждое лето у нас покупатели ведут себя по-летнему, зимой по-зимнему. Либо это может быть временный эффект какого-то события - например, ввели карантин, и себя заемщики стали вести по-другому, а также покупатели в интернет-магазинах.

Как, в принципе, меняются данные? Во-первых, меняются признаки. То есть, признаки новые добавляются, удаляются, или меняется сама схема данных. То есть, что-то у нас было строкой, а стало целочисленным признаком. Бывает, что меняется разметка, появляются новые классы, исчезают классы. Или смысл метки может поменяться в одночасье. Например, где-то в конце 90-х, начале 2000-х в Америке резко стало больше людей с ожирением. Но не потому, что они отъелись, хотя этот эффект, конечно, тоже был. А просто потому, что до 99-го года, по-моему, ожирением считался индекс массы тела выше, чем 27,8. Потом стал считаться 25. И все люди с BMI 26 вдруг внезапно из здоровых стали жирными. Поэтому смысл метки может поменяться в одночасье точно так же. Это тоже надо учитывать.
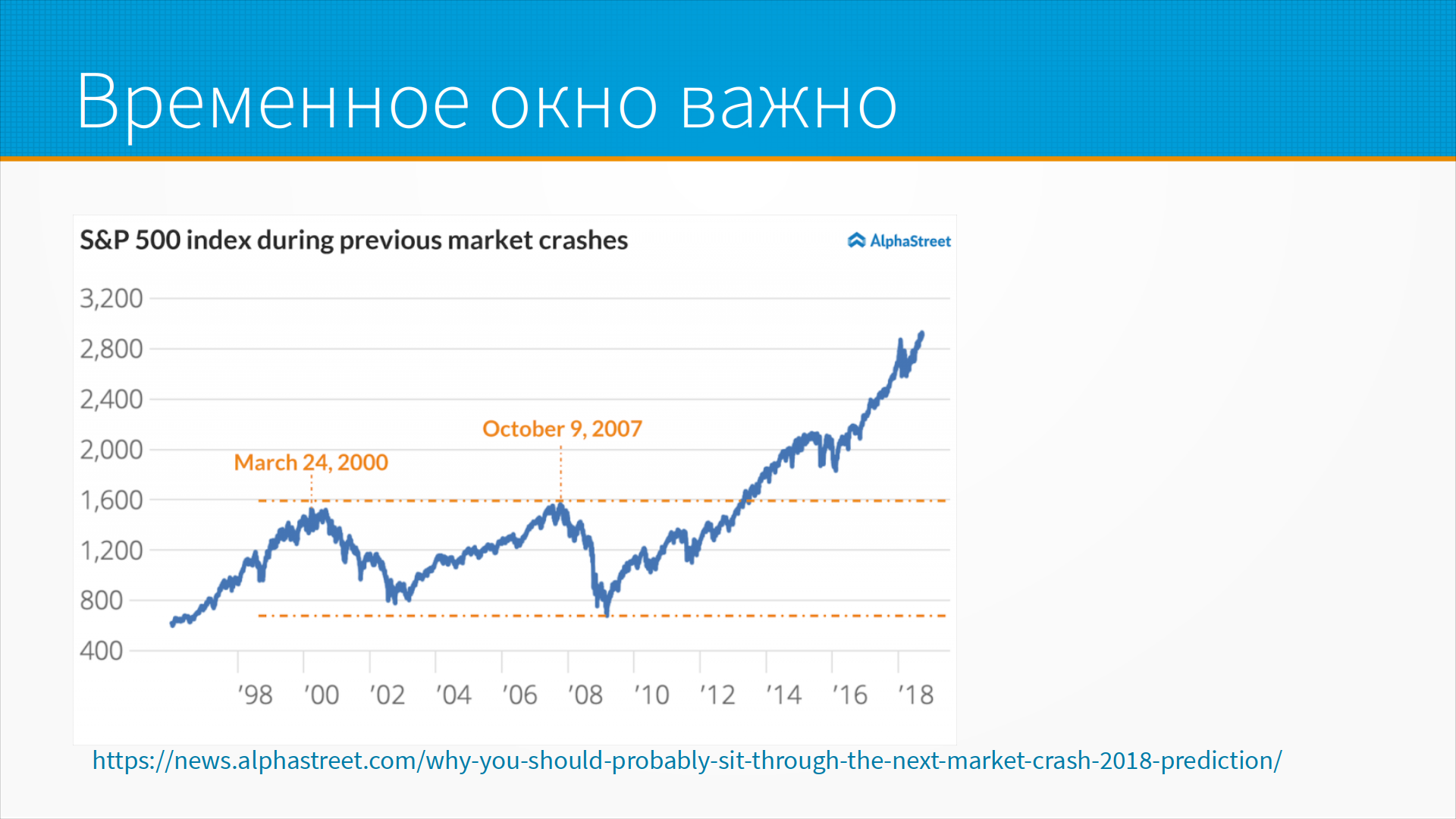
При разметке очень часто важно временное окно, в котором мы смотрим на наши данные. Например, на временной ряд. Мы могли бы сказать, что эта акция растет или падает, но в разных временных горизонтах у нас акция либо растет, либо падает, и это одна и та же самая акция. Вот тут график роста индекса Standard & Poor 500. При этом мы видим, что в зависимости от масштаба мы можем одну и ту же тенденцию считать ростом или падением. Ну и тут график до 18-го года, а потом он резко обрушился. Поэтому временное окно для временных рядов очень важно.
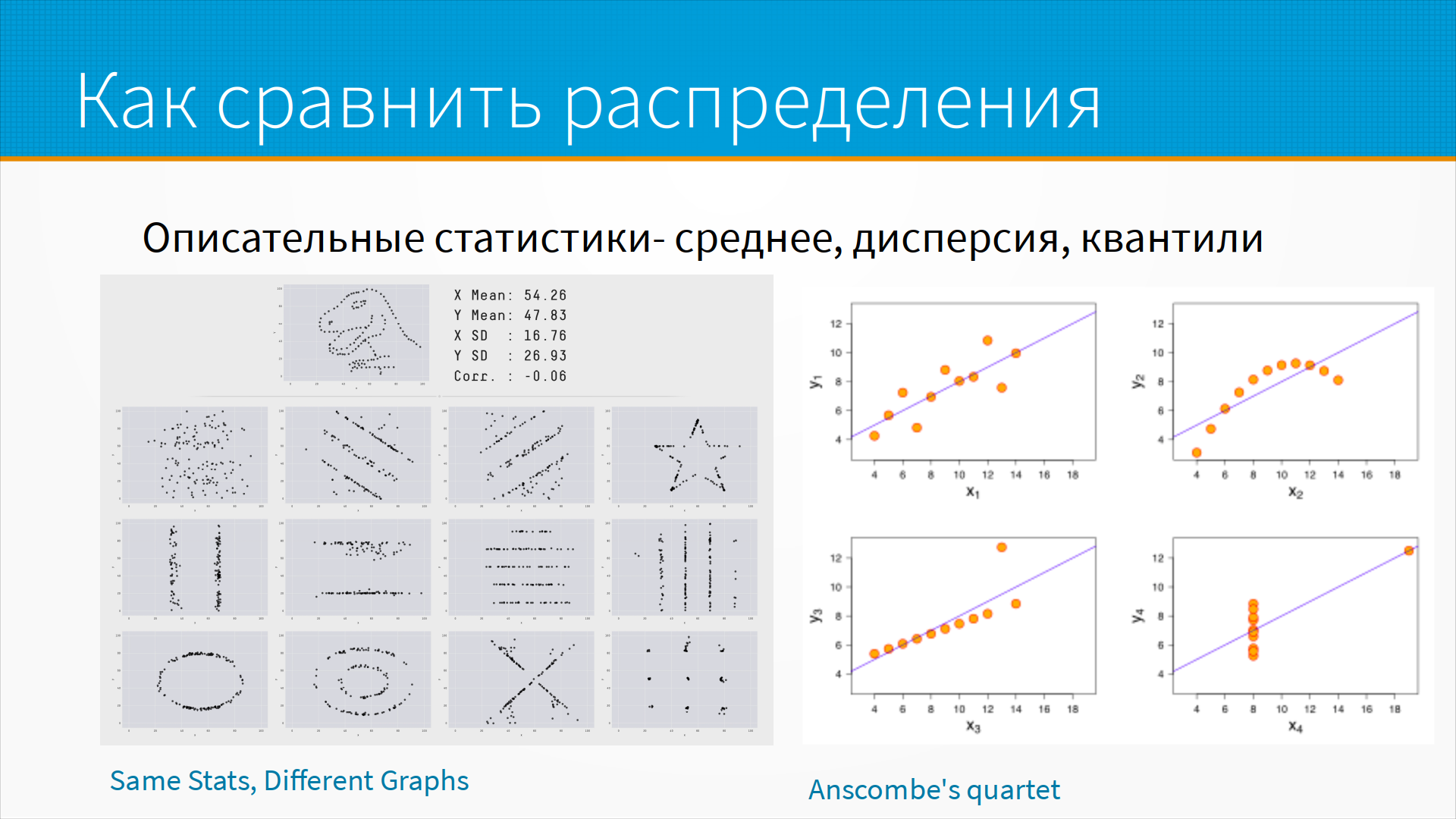
Как мы можем сравнить распределения? То есть тут мы говорим, изменилось распределение признаков. А как мы сравниваем распределения? Самый простой способ сравнивать распределения – это смотреть на описательные статистики. Например, среднее, дисперсию, квантили.
Очень часто данные могут сохранить средние дисперсии, при этом радикально изменить свою картину. Самый известный пример – это квартет Анскомбе, где четыре набора данных с одной и той же корреляцией, одним и тем же средним, при этом они имеют совершенно разную, очевидно, природу.
Гораздо более интересный пример от ребят от Autodesk - они написали программу, которая подгоняет любую картинку к нужному среднему и стандартному распределению корреляции. Это так называемый динозавр-датасет, где у всех - у круга, у крестика, у звезды, у динозавра и просто у случайного облака точек - у них одно и то же самое среднее, одно и то же самое стандартное отклонение, один и тот же самый коэффициент корреляции.

Как мы можем сравнить распределение лучше? Самый хороший способ - это, наверное, тест Колмогорова-Смирнова. Его проблема в том, что он слишком чувствительный, то есть он вам будет ловить разницу там, где она вам практически может быть и не важна.
Тест хи-квадрат очень хорош.
В индустрии часто используют population stability index. Про него вот тут есть строгое описание и статья, где про него рассказывают на пальцах.
А в блоге EvidentlyAI есть сравнение тестов для разных ситуаций. Они смотрят на чувствительность тестов к разному объёму выборки, к разной амплитуде изменений и делают выводы о том, какие тесты в каких условиях лучше.
Есть хорошая статья, как сравнивать между собой распределения, и у неё есть перевод на хабре, на русском языке - это удобно.
В библиотеке alibi есть alibi-detect детект для того, чтобы ловить распределение.
У EvidentlyAI есть много инструментов для мониторинга распределений. Собственно говоря, EvidentlyAI – это один большой инструмент для мониторинга сдвига распределений.
Вот тут есть ссылка на статью на хабре из блога ВТБ. Они обучили вторую модель следить за первой. То есть, грубо говоря, у нас есть модель, которая предсказывает нужное нам значение, и есть вторая модель, которая говорит, насколько можно верить первой модели. У них ещё было прекрасное выступление на DataFest, по-моему, в 2019 году про это. Ну, так делает не только ВТБ, просто ВТБ про это хорошо и красиво рассказывает.

Сдвиги бывают разные, и резкие сдвиги распределений заметить гораздо легче, чем постепенные сдвиги. Это та история, когда мы варим хвост у крысы, и она не замечает, если мы нагреваем его потихонечку, и, конечно же, отдёрнет хвост, если мы резко нагреем воду. Ужасный эксперимент, но он хорошо описывает эту историю.
Бывает, что сдвиг есть только у новых пользователей, и тогда хороший способ поймать сдвиг данных - это когортный анализ, когда мы сравниваем статистики не по дням, а по разным группам пользователей. То есть, например, какое качество показывает модель для тех, кто пришёл к нам в январе, в феврале, в марте. И бывает сдвиг у тех же самых пользователей. То есть, например, это те же самые пользователи, которые к нам пришли в январе, но раньше у нас было с ними всё хорошо, а теперь плохо. И сдвиг у тех же самых пользователей мы можем замерить, сравнивая их поведение с нашей зафиксированной историей их поведения, то есть сравнивая текущее поведение с историей поведения.

Что делать? Ну, если новых данных много, конечно, просто переобучить модель. Хуже, если новых данных мало. Один из вариантов - это отобрать из старых данных похожие на новые, я уже говорил про этот подход. Или взвесить старые данные степенью похожести на новые.
Иногда модель переобучить нельзя, потому что это, например, долго или дорого, а нам нужно скорректировать нашу модель прямо сейчас, в течение, скажем, 10 минут, потому что вышел какой-нибудь новый закон, который влияет на экономику нашего бизнеса, и нам прямо сейчас нужно изменить решение модели.
Хороший вариант, которым часто пользуются финансы - это корректировать пороги. То есть, например, раньше мы считали хорошим порогом заемщика, скажем, балл 380, а тут вручную финансовый аналитик передвинул порог и стали считать хорошим баллом без заемщика 600. И пока мы загрубили таким образом модель, мы все-таки выдаем хорошие кредиты и собираем данные, чтобы переобучить модель заново.
Либо мы можем обучить вторую модель исправлять ошибки первой. Такой бустинг, но не внутри моделей, а на моделях. Когда мы точно знаем, что вот здесь она ошиблась, и мы учим модели исправлять ошибки первой - в простых моделях это какая-то модель на предиктах старой модели, в NLP это на самом-то деле может быть few shot learning. Когда у нас есть маленькая выборка, и нам срочно нужно изменить предикты, мы можем быстро дообучить модель с помощью few shot learning, и потом медленно готовить новую версию модели.

Когда мы говорим о мониторинге, мы говорим обычно о процессе сбора, анализа и хранения метрик для того, чтобы принять решение - пошло что-то не так или все хорошо. Мониторинг опирается на наблюдаемость, observability, системы. Observability - это свойство системы, которое позволяет смотреть, исследовать ее работу. И вот наблюдаемость должна закладываться на этапе создания системы. Мы, конечно, можем взять текущую систему и инструментировать ее, как это говорят, для того, чтобы она собирала нужные нам метрики. На самом-то деле, основы мониторинга мы закладываем, когда разрабатываем систему. Нам нужно сразу во время разработки системы думать, как мы за ней будем следить, как мы будем ее мониторить.

Про SLA мы уже говорили, то есть нам нужно понять, что мы можем измерить, какой уровень метрик нас устраивает, и какой уровень ошибок нам неприемлем. И заложить достаточно большую границу между SLA и SLO, чтобы у нас было пространство для маневра. То есть, грубо говоря, чтобы мы успели исправить нашу ошибку до того, как нас потащат в суд.

Про операционные метрики - их обычно измерять просто, их трудно сформулировать. Но после того, как мы их сформулировали, мы их можем измерять нормально.
Например, задержка не более 200 миллисекунд. Что такое задержка не более 200 миллисекунд? Обычно это некоторая средняя задержка в течение 5 минут, чтобы 95% запросов отрабатывали не более, чем за 200 миллисекунд. То есть, это не каждый запрос, который отработал в 200 миллисекунд, это мы обычно строим какую-то сложную агрегированную метрику. Или, например, процент запросов с кодом ответа 200 - не менее 99% за 30 минут. Или там, например, доступность 3 девятки - это означает, что у нас целый рабочий день система будет лежать. Их трудно сформулировать, но просто измерить. И их обычно всегда включают в SLA, Service Level Agreement.

С ML-метриками сложнее. Например, если у нас задержки в обратной связи, мы не можем оперативно мониторить accuracy. Решение тут - собирать так много обратной связи, как можно. Во-первых, это дорого. Во-вторых, даже если мы можем собирать много обратной связи, все равно, пока нам не вернут кредит, мы не узнаем, что кредит возвращен. То есть некоторые метки принципиально поступают с большой задержкой.
У ML-метрик мы можем собирать метрики с входных распределений и с выходных. Если у вас ресурсы ограничены, мониторьте выходные распределения. Распределение выходных меток, то есть предсказаний, обычно малоразмерное. То есть мы предсказываем одну, две, три переменные. Там легко считать статистику, проверять распределение, делать стат-тесты. И обычно, если у вас изменилось распределение предиктов, скорее всего, что-то поменялось во входных данных. Поэтому, если ресурсы ограничены, то мониторьте распределение ваших предиктов.

Мы можем мониторить распределение признаков с помощью, например, библиотеки Great Expectations, которая позволяет задавать условия на данные и постоянно их проверять.
Для практических целей мы, например, широко используем Pydantic. Это библиотека валидации данных, в которых мы задаем правила на данные.
Есть библиотека TensorFlow Data Validation. Она большая, в чем-то громоздкая. Но если вы живете в мире TensorFlow, может быть, это для вас идеальный вариант.

С проблемами мониторинга. Главная проблема мониторинга - это то, что нам приходится обрабатывать много данных. Зачастую сами системы мониторинга съедают в два или в три раза больше процессорной мощности, чем непосредственно модель, которую они мониторят. И вам за это приходится платить - вам нужно будет развертывать ваши сервера, которые все это дело мониторят. Если у вас много мониторинга, у вас много сообщений, возникает так называемая alert fatigue, когда люди начинают игнорировать сообщения из системы мониторинга. Система данных меняется, и вам внезапно приходится переделывать не только модель, но и все валидаторы. Это та ситуация, когда сама по себе разработка и дообучение модели замедляется тем, что вам нужно переделывать не только модель, но и систему мониторинга.

Из чего в принципе состоит мониторинг? Прежде всего, мониторинг состоит из логов. Собираем все, до чего дотянемся, а до чего не дотянулись - до того тянемся и потом тоже собираем.
Дашборды - это то, как мы показываем наши данные конечным пользователям. Даже если у нас все собирается, но в нужный момент, когда авария, и нужно быстро оценить состояние системы, если нет хорошего дашборда, который легко читается и всегда доступен, все равно мониторинг получается будет бесполезен. То есть мониторинг должен не только собираться, но и быть доступным в нужный момент.
Алерт обычно определяется тремя вещами, то есть alert policy - когда мы будем отправлять сообщение при наступлении каких условий, notification channel - куда мы будем отправлять и кому, и description - что включаем в сообщение. И каждая из этих составных частей на самом деле влияет на качество алертов.
Мне, например, много приходили алерты от хостингов с сообщением - у вашего сервера заканчивается оплата. Учитывая, что у меня в тот момент серверов были десятки, у какого именно сервера заканчивается оплата - непонятно. Опять же, куда и кому отправляем - это важно. Если человек такой, как я, который два раза в сутки проверяет электронную почту, мне бесполезно присылать уведомления на почту. Мне нужно присылать в телеграмм, который я читаю сразу. С другой стороны, если в какой-то канал мне начинает сыпать телеграмм оповещения чаще, чем несколько раз в день, я его замьючу и тоже не буду получать. Если мне приходит сообщение, из которого непонятно, что же самое случилось, я могу не принять это во внимание. То есть, случилось что-нибудь страшное, а я не понял этого из алерта.
И хорошее правило – алерт всегда должен быть руководством к действию. Если вы сгенерировали алерт, который можно без вреда для системы пропустить и обработать позже, это должен быть не алерт, это должно быть сообщение на дашборде. Если алерт не требует действий, он не нужен.

Дополнительные материалы:
- Adversarial Validation Approach to Concept Drift Problem in User Targeting Automation Systems at Uber
- Degenerate Feedback Loops in Recommender Systems
- Addressing Delayed Feedback for Continuous Training with Neural Networks in CTR prediction
- Beyond NDCG: behavioral testing of recommender systems with RecList