
- 06.11.2022
- 25.08.2024
- обучение
- #mlsystemdesign
Седьмая лекция открытого курса "Дизайн систем машинного обучения", "Развертывание".
Слайды можно скачать тут mlsysd7ods.pdf
Текстовая расшифровка, пока не вычитана:


Добрый вечер, у нас сегодня седьмая лекция по дизайну систем машинного обучения - про шаблоны развертывания системы.

В этой лекции я оставил много терминов на английском языке, просто потому, что большинство документации и литературы на эту тему - на английском, и очень сложно сопоставлять русские переводы и английские.

Архитектура развертывания модели определяет, где конкретно будет работать ML-модель, когда будут рассчитываться предсказания модели, как модель получит запрос пользователя и как пользователь получит ответ модели.

Как правило, у нас есть разница между оффлайн и онлайн данными. Оффлайн данные - это данные, которые у вас уже есть на момент, когда пользователь к вам обратился. Это либо ранее собранная информация пользователя, либо какая-то ваша внутренняя информация, которая хранится у вас в базах данных, либо информация, которую вы забираете из внешнего API - то есть в любом случае это данные, которые уже готовы. Пользователь прислал данные вам, вы можете обработать их потом, посчитать эмбеддинги и, когда он к вам обратится, у вас уже есть насчитанные эмбеддинги и вам не нужно их считать.
Другие данные - это real-time data. Реальное время - это такой перегруженный термин, потому что вообще-то приложение реального времени и данные реального времени - совершенно определенные вещи с маленькими задержками, но тут мы имеем в виду не их, а данные, которые пользователь прислал и вам нужно обработать их прямо сейчас.
То есть, например, вы делаете поиск по картинкам. Пользователь прислал вам данные, и вам нужно на этой картинке посчитать эмбеддинг и найти среди других картинок, для которых вы посчитали эмбеддинги заранее, похожую на эти картинки. Тогда получается, что картинки, которые у вас уже были до этого в базе - это оффлайновые данные, а картинку, которую пользователь прислал, - "найди мне такие же", - это real-time data.

Следующее полезное разделение - это тип обработки: онлайн обработка, потоковая обработка и пакетная обработка.
Онлайн обработка - это обработка по требованию, то есть пользователь присылает один запрос, модель делает предсказание и отвечает ему.
Пакетная обработка - это когда мы собираем много запросов и обрабатываем их вместе, возможно, не в то время, когда их нам отправили. Например, готовим обработку заранее - то есть ночью насчитываем рекомендации, а утром пользователь запрашивает их рекомендацию.
И stream processing - потоковая обработка, когда пользователь постоянно присылает данные, модель постоянно или по запросу пользователя выдает предсказания.
Про потоковую обработку данных у нас будет отдельная лекция, девятая, сейчас мы просто пробежимся сверху.

Важное архитектурное решение, которое нам нужно принять - где мы будем развертывать нашу систему: в облаке, на устройствах пользователя или будем использовать какую-то комбинацию этих вариантов.
Cloud computing - это история про то, что модель работает на выделенных серверах, в облаке или в вашем дата-центре. Вообще вариант, когда модель работает в вашем дата-центре и вариант, когда модель работает в облаке, обычно разделяют, потому что у них разные модели оплат, разные модели финансирования. Но конкретно для разработчика моделей - если вы не платите за сервера, то вам все равно. То есть, что выделенный сервер, что облачный сервер можно рассматривать как cloud computing.
И edge computing - это ситуация, когда модель работает на устройстве конечного пользователя, например, на его телефоне или на его компьютере, или внутри умной колонки Алисы или Alexa, или внутри камеры видеонаблюдения. Есть библиотека TensorFlow JS, которая позволяет запускать модели машинного обучения прямо в браузере.

Давайте на примере разберем, как мы могли бы принимать такие решения. Пусть мы разрабатываем приложение, рекомендующее маршрут для прогулки, то есть на основе данных о текущем местоположении, истории местоположений, с учетом профиля пользователя, его календаря, прогноза погоды, новостей и истории рекомендаций, мы предлагаем ему маршрут прогулки, который, как мы думаем, ему понравится, а пользователь оценивает, понравился ли маршрут или нет.
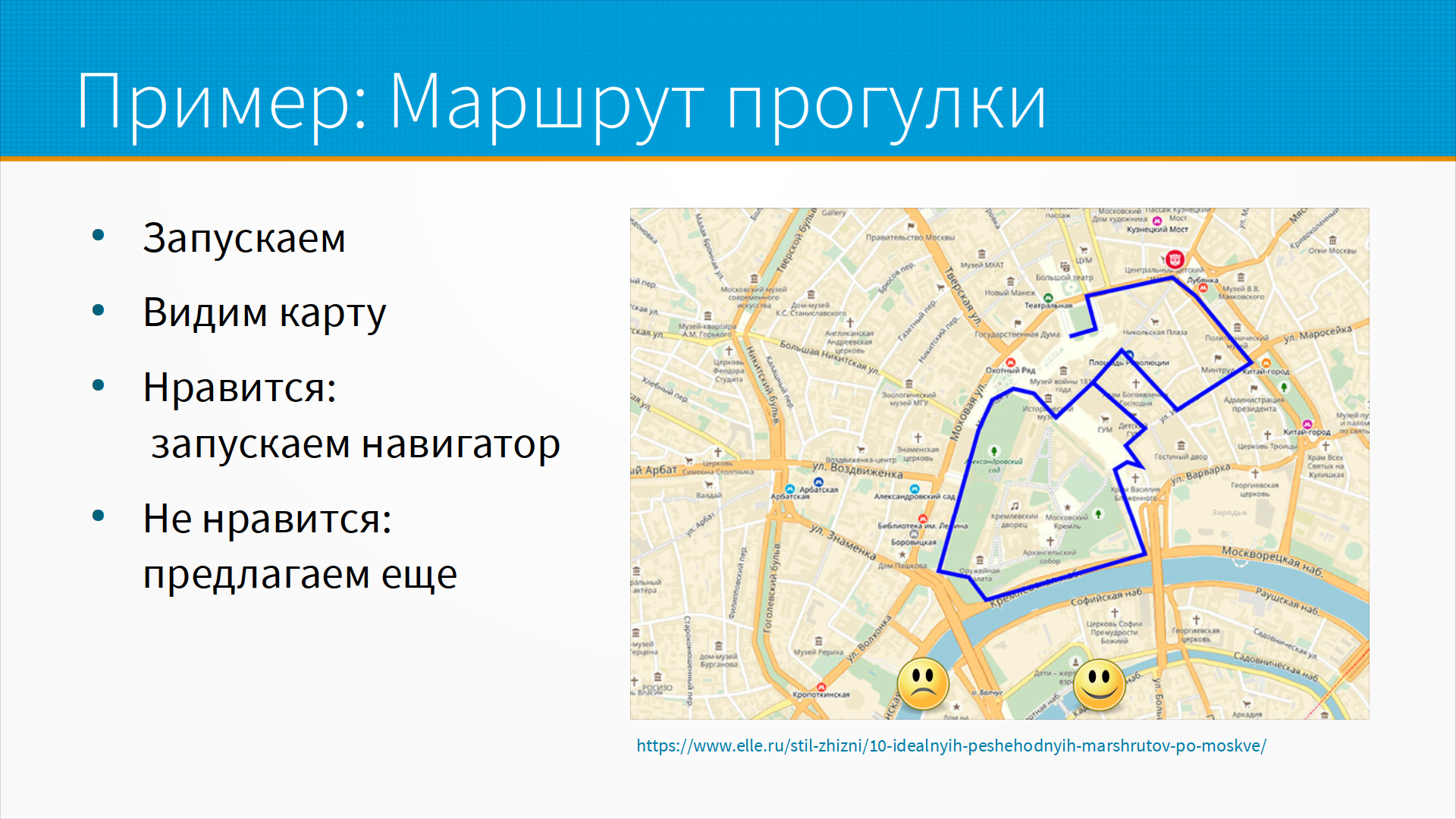
Интерфейс может выглядеть примерно вот так - то есть карта, на которой мы нарисовали маршрут, и кнопки like и dislike. История использования: запускаем приложение; видим карту; если нравится - мы говорим "да, нравится", и приложение запускает навигатор; если не нравится - то мы предлагаем еще один маршрут.

Как бы мы могли разворачивать эту модель? Например, онлайн рекомендации по запросу. Локально телефон будет рассчитывать маршрут сам, мы загружаем модель на телефон и все данные лежат на телефоне. Когда пользователь запускает приложение, телефон обращается ко всем этим данным и выполняет расчет рекомендаций, показывает рекомендованный маршрут. Тут есть проблема с тем, что нам нужно все базы притащить на телефон пользователя, и нам придется их все время оперативно обновлять, и, может быть, пользователь будет не рад тому трафику, который мы организуем.
Другой вариант - тоже онлайн рекомендации, приложение отправило запрос на сервер, и сервер, у которого базы все свежие, которые он обновляет сам у себя, рассчитывает маршрут. В этом случае и базы данных, и сама модель лежат на нашем сервере, а модель запрашивает рекомендацию и сразу же получает маршрут.
Почему это онлайн, что у них общего? То, что маршрут рекомендации не рассчитывается до тех пор, пока клиент к нам не обратится.
Другой вариант - это пакетная рекомендация. Предположим, что мы ночью для каждого пользователя считаем 10 рекомендаций на основании его истории, прогноза погоды и так далее. При старте приложения мы их загружаем на телефон, пользователь мгновенно получает рекомендацию - или мы отдаем по запросу, как будто это онлайн рекомендация. То есть к нам обратились за онлайн-рекомендацией, а мы вместо того, чтобы их считать, отдаем сохраненные рекомендации.
Так делают многие медиасервисы - музыкальные сервисы, видео-хостинги. Они для каждого пользователя считают рекомендации и затем они их отдают, "ваш плейлист дня" и так далее, это все вот эти истории.

Локальные рекомендации считаются более безопасными, то есть данные пользователя не передаются, они лежат у него на компьютере, модель обычно может работать без интернета и, что немаловажно, пользователь сам платит за железо, на котором эта модель работает - то есть он сам покупает телефон, сам берет на него кредит и вам не нужно тратиться на сервера, которые будут делать модели.
У нас есть ограничения по вычислительной мощности, то есть все-таки телефон может быть не очень мощным, и, даже если он очень мощный, все равно в него не влезет все, что мы хотим туда запихать. Там есть ограничения по месту, нет доступа к нашим закрытым данным на сервере и трудно обновлять модели. Причем не только трудно обновлять модели на компьютере пользователя, на мобильном телефоне пользователя, но и трудно дообучать наши модели, то есть для того, чтобы мы могли дообучать нашу модель на обратной связи пользователя, нам нужно, например, запускать что-нибудь типа federated learning, доучивать модель на телефоне пользователя, это сложная и дорогая история.

У онлайн рекомендации есть свои плюсы - это большая пропускная способность, мы можем купить много серверов и они будут работать быстро; мы сохраняем в тайне наши модели, то есть мы не загружаем их на мобильный телефон пользователя, таким образом мы храним наши коммерческие тайны; и нам удобно собирать статистику и разметку - то есть какой маршрут пользователь счел хорошим, какой маршрут пользователю не понравился, по какому он на самом-то деле пошел и так далее.
Минусы - тоже очевидны, то есть нам нужно платить за сервера. Есть проблемы неравномерной нагрузки, то есть, например, два раза в день в обед и вечером у нас будет пиковая нагрузка, когда все пошли гулять, все строят маршруты, а все остальное время сервера у нас по большому счету простаивают. Ну и если связь в том месте, где находится пользователь, медленная, то пользователю придется ждать, это будет его фрустрировать.

Пакетные рекомендации - если бы мы насчитывали предсказания заранее, и при запуске приложения, например, или при первом запросе загружали бы десять или пятьдесят рекомендаций для пользователя. Если ему не понравилась одна, мы бы предлагали другую из предрассчитанных. Тут преимущество в том, что сервер всегда отвечает быстро. Задержка модели на предсказании не так важна, то есть конкретное предсказание может считаться три секунды, пять или пятьдесят, мы считаем все заранее.
Минусы - это нам приходится считать много рекомендаций. Допустим, один пользователь в день просмотрит одну-две-три рекомендации, но мы все равно должны посчитать десять или пятьдесят. Некоторые пользователи, может быть, две трети из наших пользователей, вообще не будут запускать сегодня наше приложение, а нам все равно придется считать для них рекомендации. А эти насчитанные рекомендации нам нужно будет хранить, и, если ситуация как-то мгновенно изменится, например, пойдет дождь или перекроют какую-нибудь дорогу, мы не сможем мгновенно учитывать изменения в нашей рекомендации.

В ситуации с потоковыми рекомендациями у нас разнесена обработка данных и их сохранение. То есть, координаты передаются непрерывно из приложения пользователя, маршрут перестраивается на ходу, и время от времени приложение запрашивает изменения маршрута, новые рекомендации и так далее.
Это отличное решение для пользователя при условии, что у него быстрая сеть, потому что мы ее будем грузить постоянно отправкой данных туда и подкачкой новых рекомендаций отсюда. И это большая вычислительная нагрузка на наши сервера, потому что мы вынуждены считать модель не один раз в день, не пятьдесят раз в день, а, может быть, раз в несколько секунд.

Все это приводит к нескольким базовым шаблонам реализации. Есть пять базовых шаблонов реализации именно для машинного обучения, из них три хороших, два не очень.
Один хороший - Online Processing, offline data - это когда к нам приходит запрос к данным, но по этим данным все нужные эмбеддинги, какие-то рекомендации, что-то еще, мы насчитали заранее.
Online Processing, offline data + real-time data - это когда у нас есть заранее насчитанные эмбеддинги на данных и какие-то данные, которые пришли прямо в запросе. Мы дальше все эти ситуации подробно разберем.
Третий практически полезный шаблон реализации - это потоковые данные, streaming processing оффлайн насчитанных имбеддингов плюс какие-то real-time данные, поступившие в каждом запросе.
Два остальных шаблона - Online Processing, real-time data и Streaming processing, real-time data - обычно неудачны при развертывании. То есть это те же самые, что и второй и третий шаблон реализации, мы просто отказались от предрассчитанных данных на доступных нам оффлайновых данных, то есть они просто более дорогие вычислительно при реализации, поэтому мы разберем первые три.
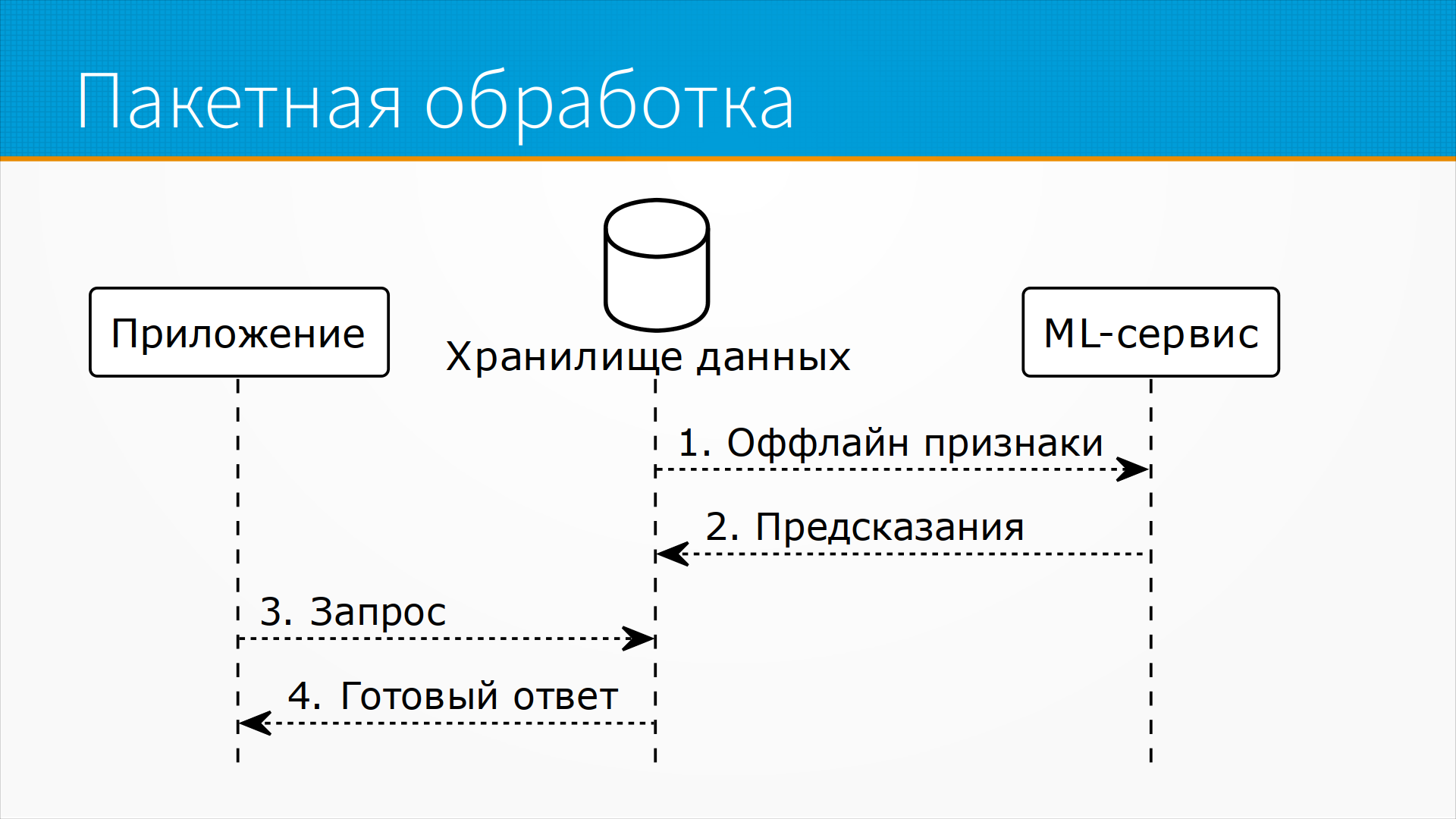 Online Processing, offline data - наше приложение
отправляет какие-то запросы и получает предрассчитанные
предсказания.
Несколько заранее в пакетном режиме наш
сервис забирает данные из хранилища данных и сохраняет
туда же рекомендации.
Это удобно тем, что нам абсолютно не важна скорость
предсказания, потому что наше приложение на самом
деле просто вытаскивает готовые результаты из базы
данных.
Мы можем поставить столько prediction-серверов, сколько
нам удобно, они работают с прогнозируемой нагрузкой,
никаких пиков запросов нет, потому что мы точно
знаем, что вот сейчас мы сели и ночью все пересчитали,
утром у пользователей есть рекомендации.
Online Processing, offline data - наше приложение
отправляет какие-то запросы и получает предрассчитанные
предсказания.
Несколько заранее в пакетном режиме наш
сервис забирает данные из хранилища данных и сохраняет
туда же рекомендации.
Это удобно тем, что нам абсолютно не важна скорость
предсказания, потому что наше приложение на самом
деле просто вытаскивает готовые результаты из базы
данных.
Мы можем поставить столько prediction-серверов, сколько
нам удобно, они работают с прогнозируемой нагрузкой,
никаких пиков запросов нет, потому что мы точно
знаем, что вот сейчас мы сели и ночью все пересчитали,
утром у пользователей есть рекомендации.
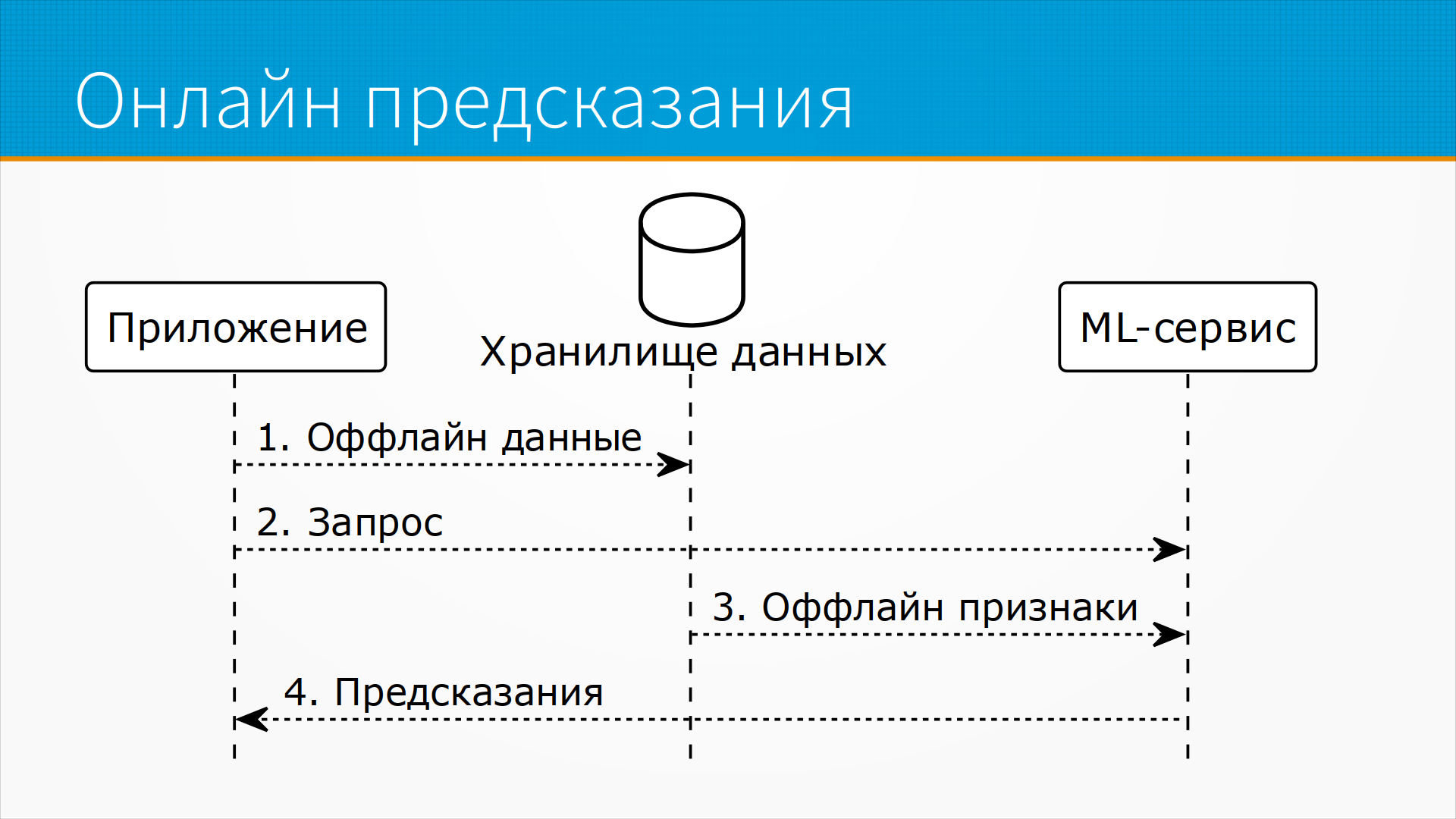 Online Processing, offline data + real-time data - это примерно то же самое,
но у нас еще есть какое-то хранилище, например, у нас
есть профиль пользователя, какая-то история его взаимодействий,
и мы насчитываем на них признаки - например, он
любит лес, или он любит гулять в заброшке, или он
любит гулять в людных местах, где есть хорошее кафе.
И таким образом мы раз в сутки насчитываем какие-то
признаки для пользователя, и, когда к нам приходит запрос
с конкретным географическим расположением, мы рассчитываем
ему маршрут, но уже учитывая те признаки, которые мы
насчитали заранее - то есть у нас есть потоковые данные
и у нас есть пакетные данные, которые мы получили, насчитали
заранее, предобработали.
Online Processing, offline data + real-time data - это примерно то же самое,
но у нас еще есть какое-то хранилище, например, у нас
есть профиль пользователя, какая-то история его взаимодействий,
и мы насчитываем на них признаки - например, он
любит лес, или он любит гулять в заброшке, или он
любит гулять в людных местах, где есть хорошее кафе.
И таким образом мы раз в сутки насчитываем какие-то
признаки для пользователя, и, когда к нам приходит запрос
с конкретным географическим расположением, мы рассчитываем
ему маршрут, но уже учитывая те признаки, которые мы
насчитали заранее - то есть у нас есть потоковые данные
и у нас есть пакетные данные, которые мы получили, насчитали
заранее, предобработали.
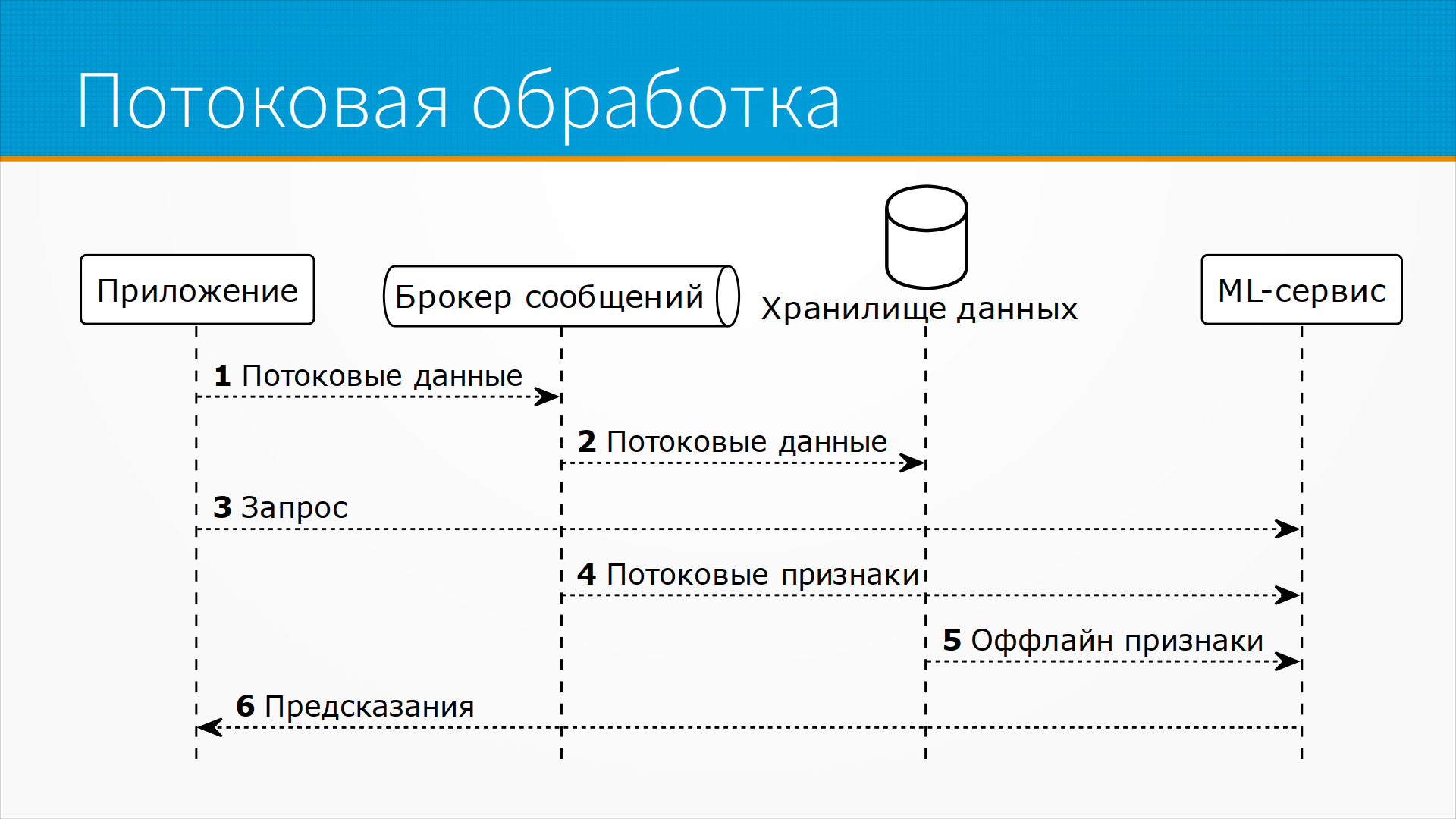 И streaming processing в чистом виде - это когда нам постоянно
идет какой-то поток данных, у нас есть некоторые данные,
которые мы в пакетном режиме тоже обрабатываем и сохраняем,
так сказать, консервируем наши эмбеддинги на будущее,
и в какой-то момент приложению срочно понадобился запрос.
Обычно там приходит мало данных в этом запросе, в
основном они базируются на тех данных, которые приложение
стримило или мы пакетно уже насчитали, и мы делаем
ответ.
И streaming processing в чистом виде - это когда нам постоянно
идет какой-то поток данных, у нас есть некоторые данные,
которые мы в пакетном режиме тоже обрабатываем и сохраняем,
так сказать, консервируем наши эмбеддинги на будущее,
и в какой-то момент приложению срочно понадобился запрос.
Обычно там приходит мало данных в этом запросе, в
основном они базируются на тех данных, которые приложение
стримило или мы пакетно уже насчитали, и мы делаем
ответ.
Опять же, в девятой лекции мы будем разбирать эту историю подробно.
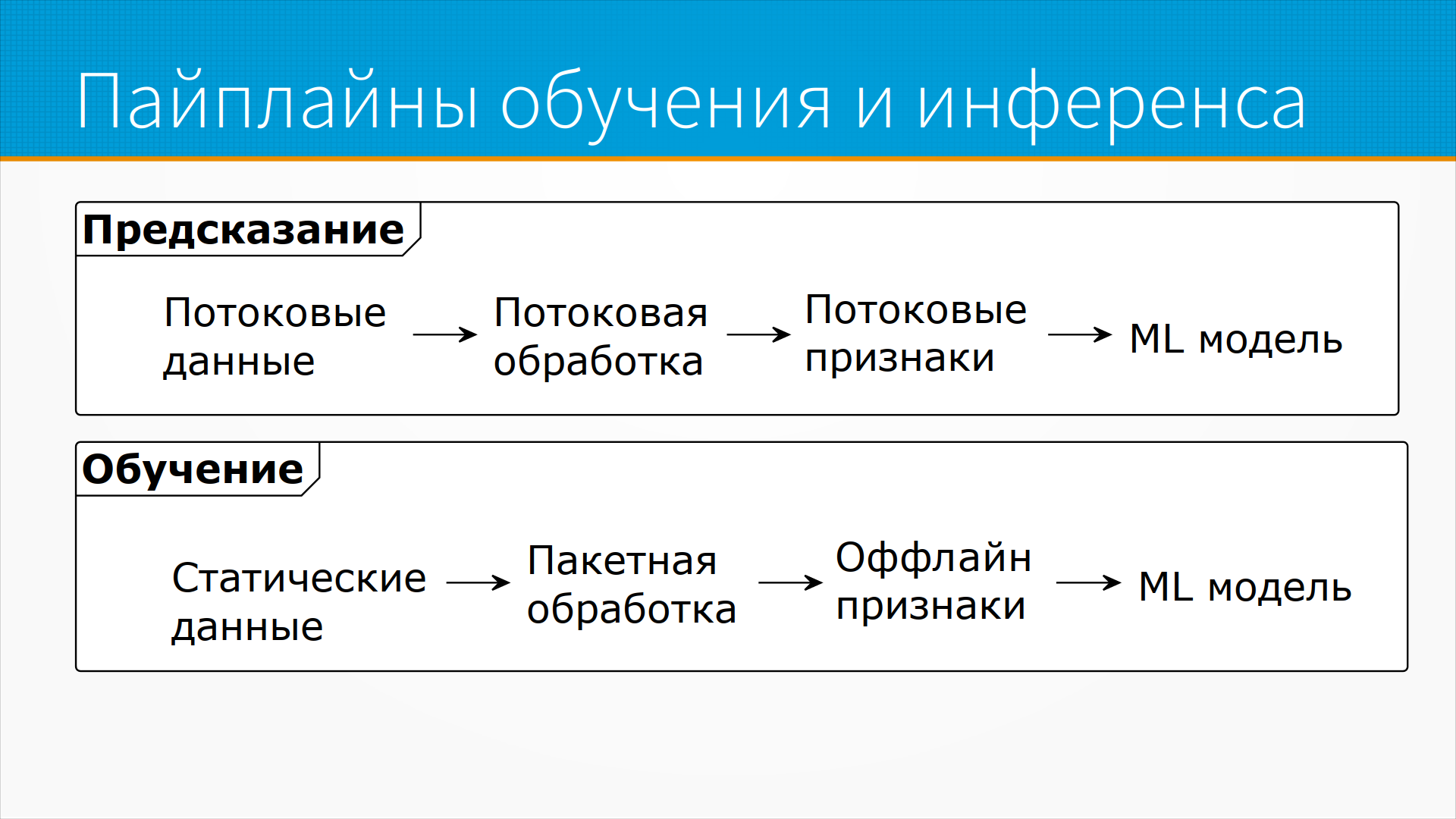 Даже в тех случаях, когда мы используем потоковые
данные, обычно обучение у нас все равно построено
в пакетном режиме - то есть на инференсе у нас потоковые
данные льются непрерывным потоком, мы делаем
из них какие-то признаки и предсказываем результат, а при обучении
мы берем статические данные, которые у нас сохранены,
то есть историю этих самых стриминговых данных, и
на них учим нашу модель.
Даже в тех случаях, когда мы используем потоковые
данные, обычно обучение у нас все равно построено
в пакетном режиме - то есть на инференсе у нас потоковые
данные льются непрерывным потоком, мы делаем
из них какие-то признаки и предсказываем результат, а при обучении
мы берем статические данные, которые у нас сохранены,
то есть историю этих самых стриминговых данных, и
на них учим нашу модель.
 Пакетная обработка - исторически первый способ работы
с данными, его применяли еще на мейнфреймах, он
более быстрый, потому что данные посчитаны заранее,
фактически закэшированы.
Он часто дешевле, но он редко лучше, чем онлайн-обработка.
И тренд мировой такой, что становятся быстрее сети
связей и компьютеры, и мы постепенно переходим
к онлайн-предсказаниям.
Пакетная обработка - исторически первый способ работы
с данными, его применяли еще на мейнфреймах, он
более быстрый, потому что данные посчитаны заранее,
фактически закэшированы.
Он часто дешевле, но он редко лучше, чем онлайн-обработка.
И тренд мировой такой, что становятся быстрее сети
связей и компьютеры, и мы постепенно переходим
к онлайн-предсказаниям.
Но параллельно к тому, как становятся быстрее сети связей и компьютеры, нейронки становятся огромнее, их предикты все еще медленны, и получается, что мы разумно можем сочетать как пакетную обработку для каких-то медленных предсказаний, так и онлайн обработку для быстрых предсказаний.
Можно провести аналогию между тем, как мыслит человек, есть хорошая книга Канемана "Thinking, Fast and Slow" про быстрое и медленное мышление, и в принципе оба подхода полезны.

Как мы можем ускорить работу модели? Основные подходы это сжатие модели, low-rank factorization внутри модели, knowledge distillation, pruning и quantization.
Компрессия - это про выкидывание из модели ненужных частей, например, какие-то блоки нужны для обучения модели, но не нужны для ее инференса, для предсказания.
Low-rank factorization - когда мы выполняем матричное разложение и упрощаем расчеты внутри. Мы несколько жертвуем точностью, но сильно повышаем скорость.
Knowledge distillation - это когда мы обучаем сложную модель. Вообще большинство моделей глубокого обучения глубокие не потому, что мы не можем предсказывать простыми моделями, а потому что мы не можем обучить простые модели. То есть теория учит нас, что двухслойной нейронки, ну, трехслойной, с двумя скрытыми слоями, достаточно для аппроксимации любой функции, но обучить ее очень сложно. Поэтому проще обучить очень глубокую сетку, которая будет медленно учиться и медленно предсказывать при этом, а потом, используя ее как учителя, обучить маленькую сетку делать все то же, что делает большая. Это knowledge distillation, мастер-студент, и для, допустим, NLP-моделей есть куча моделей, когда есть, допустим, Bert большой обученный, его не очень удобно тащить в прод, а есть какой-нибудь tiny-Bert, это Bert упрощенный, который делает практически предсказание того же качества, но на порядок быстрее, и сама модель занимает меньше места в памяти.
Pruning - это когда мы пользуемся тем, что модели наши разреженные, часть моделей на самом деле не используется при инференсе, то есть там нулевые коэффициенты, и что бы туда не попало на эти нейроны, оно не влияет на результаты. Мы при некоторых условиях можем выкинуть просто блоки из модели, и это ускорит нам предсказание.
И quantization – это когда мы переходим в расчет с меньшей точностью, то есть, допустим, мы переходим из float32 в float16, и, помимо того, что наша модель начинает занимать меньше места в памяти, зачастую у видеокарт, на которых мы делаем инференс, всегда, на самом деле, есть отдельный пайплайн для работы с FP16, зачастую он просто сильно быстрее, чем FP32, особенно на промышленных картах тяжелых серверных.
Quantization, pruning и все такое редко делают вручную. Обычно используют какие-нибудь библиотеки для ускорения инференса модели, и первое, о котором стоит поговорить - это ENOT.AI, ее разрабатывают ребята тут же из Новосибирского университета, рядом с ним, то есть не из университета, но они из него вышли. И она позволяет очень здорово ускорить inference моделей компьютерного зрения, ну, и в последнее время они научились и NLP-модели разгонять, ENOT.AI.
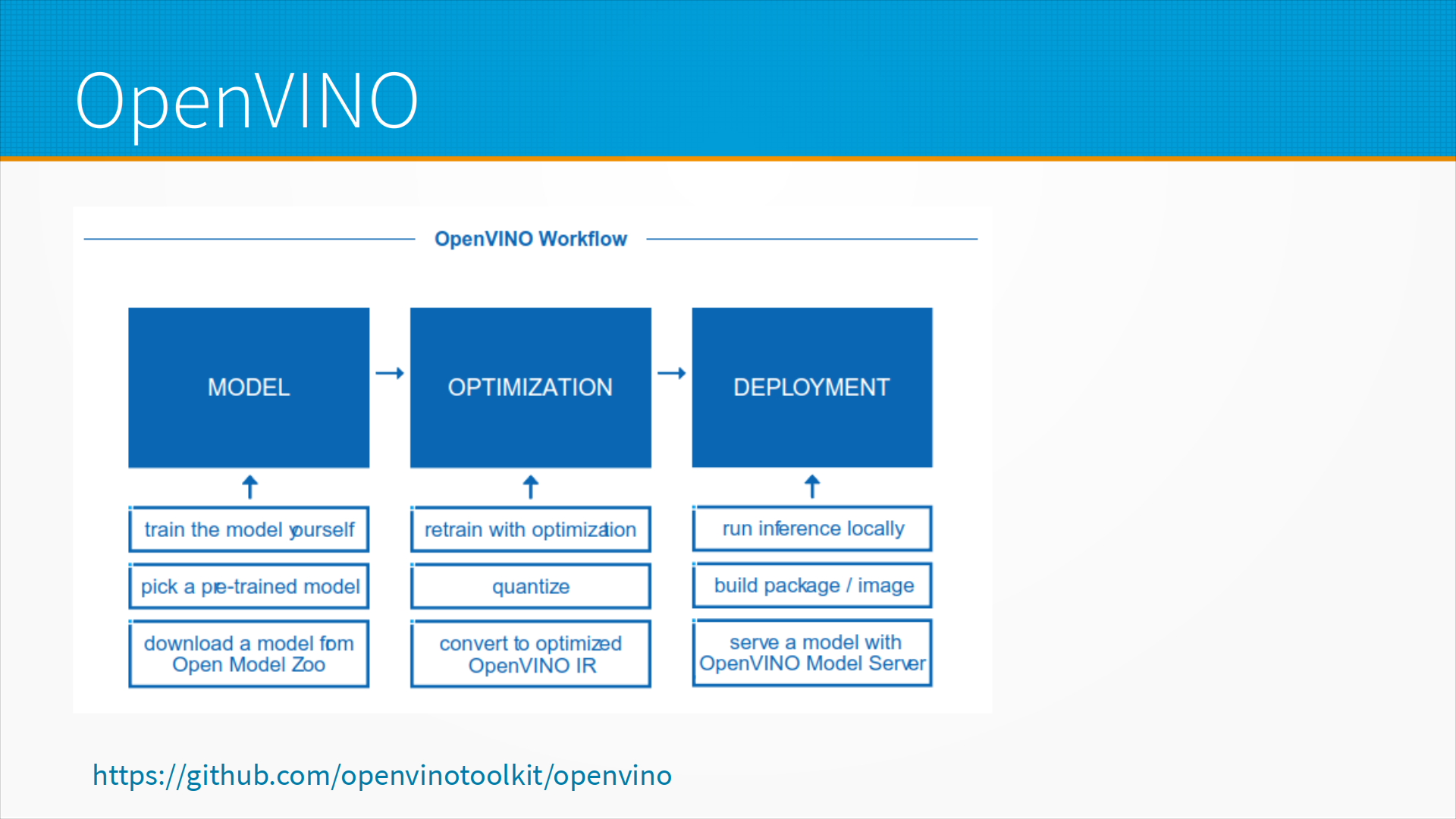
OpenVino - это библиотека для оптимизации работы моделей и запуска их на конечных устройствах от Intel, хорошая, зрелая и для нее очень много документации, там есть своя квантизация, есть переобучение с оптимизацией.

ONNX - это библиотека от Microsoft и стандарт представления моделей, в которой можно сконвертировать модели многих фреймворков, и существует ONNX runtime, который эти ONNX модели может исполнить.

Для Pytorch существует nvFuser, это just-in-time компилятор.
Есть отличная библиотека Hugging Face Accelerate, которая позволяет делать распределенный inference, ну, для прода это мало применимо, но для тестирования это может быть важно для инференса моделей, которые не вмещаются в оперативную память вашей GPU - то есть, например, модель может быть распределена между несколькими GPU, то есть одни слои на одной GPU, другие слои на другой. Либо для экспериментов вы можете подгружать вашу модель в GPU по частям.
И DeepSpeed позволяет делать распределенный inference, у него есть оптимизированные для инференса CUDA kernels, это как раз тот самый случай, когда какие-то вещи нам нужны для обучения модели, но не очень нужны для инференса, и там есть умная квантизация, обычно Accelerate и DeepSpeed используют вместе.

NVIDIA Triton Inference Server - это отраслевой стандарт для инференса моделей на GPU NVIDIA, туда можно выгрузить модели, написанные на разных фреймворках, то есть TensorFlow модели вы можете там сервить, PyTorch модели, он имеет много хороших инструментов для развертывания моделей, интеграции в ваш MLOps, и он развивается NVIDIA - соответственно все, что есть интересного в NVIDIA картах, он умеет использовать.

Дополнительные материалы: