
- 31.10.2022
- 25.08.2024
- обучение
- #mlsystemdesign
Шестая лекция открытого курса "Дизайн систем машинного обучения", "Оценка качества модели".
Слайды можно скачать тут mlsysd6ods.pdf Пример кода mlsysd6_sample_quality.pdf
Текстовая расшифровка:
 Привет, меня зовут Дмитрий Колодезев и это шестая лекция курса дизайна систем машинного обучения "Оценка качества модели".
Привет, меня зовут Дмитрий Колодезев и это шестая лекция курса дизайна систем машинного обучения "Оценка качества модели".
 Когда мы говорим о качестве системы, нам надо смотреть на качество не только ML-модели, но и на качество нашей системы в целом.
Когда мы говорим о качестве системы, нам надо смотреть на качество не только ML-модели, но и на качество нашей системы в целом.
 Система в целом у нас состоит, как мы уже говорили, из интерфейсов, данных, ML-модели, инфраструктуры и оборудования.
И качество системы может проседать в интерфейсах, в данных, в ML-модели.
Про инфраструктуру и оборудование мы поговорим на других лекциях, а качество первых трех компонентов обсудим на этой лекции.
Система в целом у нас состоит, как мы уже говорили, из интерфейсов, данных, ML-модели, инфраструктуры и оборудования.
И качество системы может проседать в интерфейсах, в данных, в ML-модели.
Про инфраструктуру и оборудование мы поговорим на других лекциях, а качество первых трех компонентов обсудим на этой лекции.
 Что может быть качеством интерфейса? Как мы вообще можем измерить качество интерфейса?
Качество - это пригодность к использованию. Как используют интерфейсы? К ним подключаются, ими пользуются.
Интерфейсы у нас могут быть - во-первых, API для программного подключения, и тогда нам нужна доступность, чтобы клиент мог подключиться к нему.
Соответственно, у клиента могут возникнуть проблемы такие - у него внутренняя сеть, и он не может выходить в интернет; у него могут быть старые протоколы, старые системы могут не поддерживать, как ни странно, даже TCP/IP; там могут быть другие операционные системы, несовместимые с тем, с чем мы привыкли работать; или медленная сеть, что не дает возможность оперативно загружать, например, аудиофайлы и картинки. И какие-то другие еще проблемы.
Что может быть качеством интерфейса? Как мы вообще можем измерить качество интерфейса?
Качество - это пригодность к использованию. Как используют интерфейсы? К ним подключаются, ими пользуются.
Интерфейсы у нас могут быть - во-первых, API для программного подключения, и тогда нам нужна доступность, чтобы клиент мог подключиться к нему.
Соответственно, у клиента могут возникнуть проблемы такие - у него внутренняя сеть, и он не может выходить в интернет; у него могут быть старые протоколы, старые системы могут не поддерживать, как ни странно, даже TCP/IP; там могут быть другие операционные системы, несовместимые с тем, с чем мы привыкли работать; или медленная сеть, что не дает возможность оперативно загружать, например, аудиофайлы и картинки. И какие-то другие еще проблемы.
Надежная API - это доступная API с хорошей документацией, логированием и мониторингом. Есть стандарт OpenAPI на документирование программных интерфейсов, и в библиотеке FastAPI, которую я горячо рекомендую, он встроен. И есть инструмент Swagger для редактирования этого OpenAPI. Описание в FastAPI генерируется самостоятельно по ссылке, можно посмотреть, как это делается.
И интерфейс может быть GUI, Graphic User Interface. Это то, во что тыкает мышкой пользователь. Тут важно удобство в использовании, usability. Самый простой способ измерить юзабилити - это так называемый коридорный тест. Это вы выходите в коридор, ловите какого-нибудь человека, который ничего не знает про ваше программное обеспечение, садите его за экран и говорите - "а ну-ка сделай вот это", не объясняя, как. И если он справился, то, наверное, это хороший интерфейс. Если он не справился, то вы смотрите, на чем он завис. Желательно, на самом деле, записывать экран.
По ссылке с презентации у нас есть лекция Стивена Круга, известного специалиста в области юзабилити, который рассказывает, как проводить тестирование юзабилити. Ну и опять же, нам важна надежность, доступность.
С доступностью в пользовательских интерфейсах есть свои проблемы, такие как, например - вы сделали красивую панель управления, но она хороша на компьютере, на десктопном браузере. А пользователь подключился с помощью мобильного клиента и вся ваша красота ему просто на экран не влазит.
Кроме всего прочего, у клиента могут быть старые браузеры, какие-нибудь древние Internet Explorer или Opera, потому что у него корпоративные правила, запрещающие сменять браузер самому. У него может быть медленная сеть, и ваш чудесный JavaScript может работать совершенно ужасно. Это надо тестировать, уточнять.
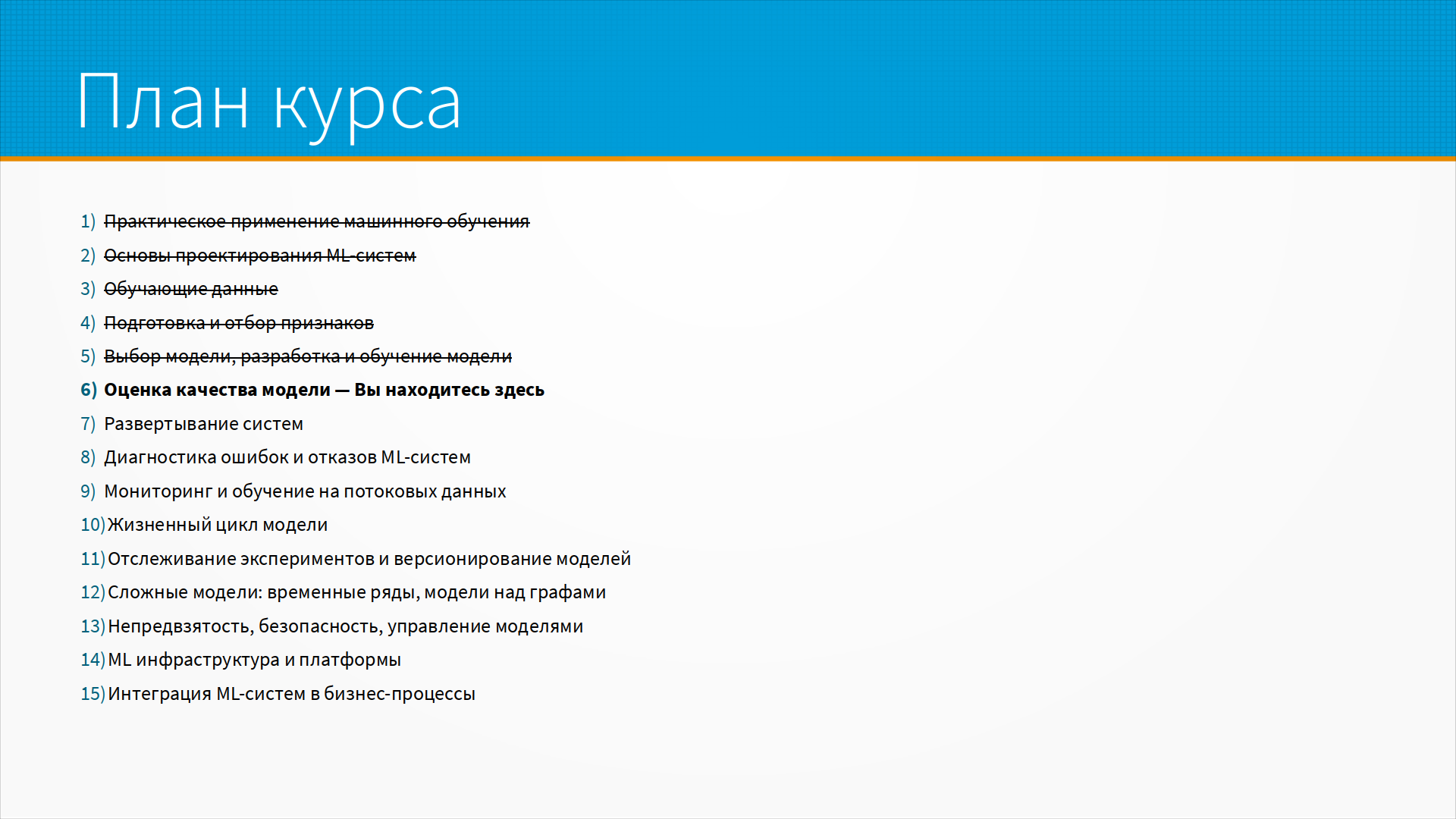
 Пример того, как выглядит документация FastAPI.
Для примера я взял сервис выгрузки данных Норвежского министерства обороны.
Они выгружают какие-то данные, но я на самом деле не смотрел, какие они выгружают.
Интересно тут другое, что у них есть точка доступа digdir-api
Мы можем запросить описание API, которое они поддерживают.
По адресу openapi.json нам вернется JSON в формате OpenAPI, который описывает,
какие запросы мы можем делать к этому серверу и какие ответы мы можем ожидать.
Пример того, как выглядит документация FastAPI.
Для примера я взял сервис выгрузки данных Норвежского министерства обороны.
Они выгружают какие-то данные, но я на самом деле не смотрел, какие они выгружают.
Интересно тут другое, что у них есть точка доступа digdir-api
Мы можем запросить описание API, которое они поддерживают.
По адресу openapi.json нам вернется JSON в формате OpenAPI, который описывает,
какие запросы мы можем делать к этому серверу и какие ответы мы можем ожидать.
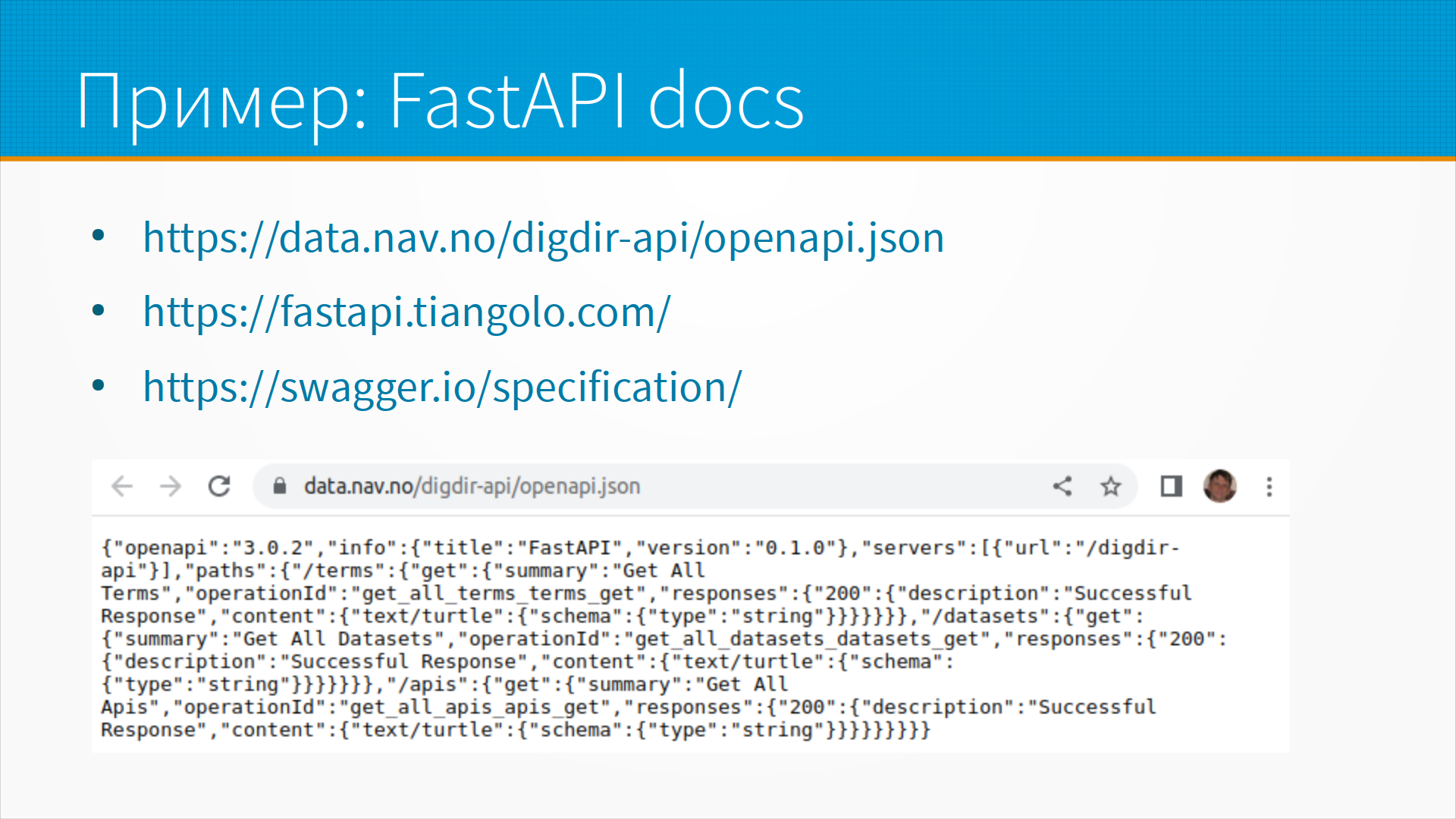
 Документация на FastAPI по ссылке, спецификация swagger тоже по ссылке,
но если мы наберем не /openapi.json, а наберем специальный служебный адрес /docs,
то нам откроется страничка просмотра API, где мы можем посмотреть документацию.
Документация на FastAPI по ссылке, спецификация swagger тоже по ссылке,
но если мы наберем не /openapi.json, а наберем специальный служебный адрес /docs,
то нам откроется страничка просмотра API, где мы можем посмотреть документацию.
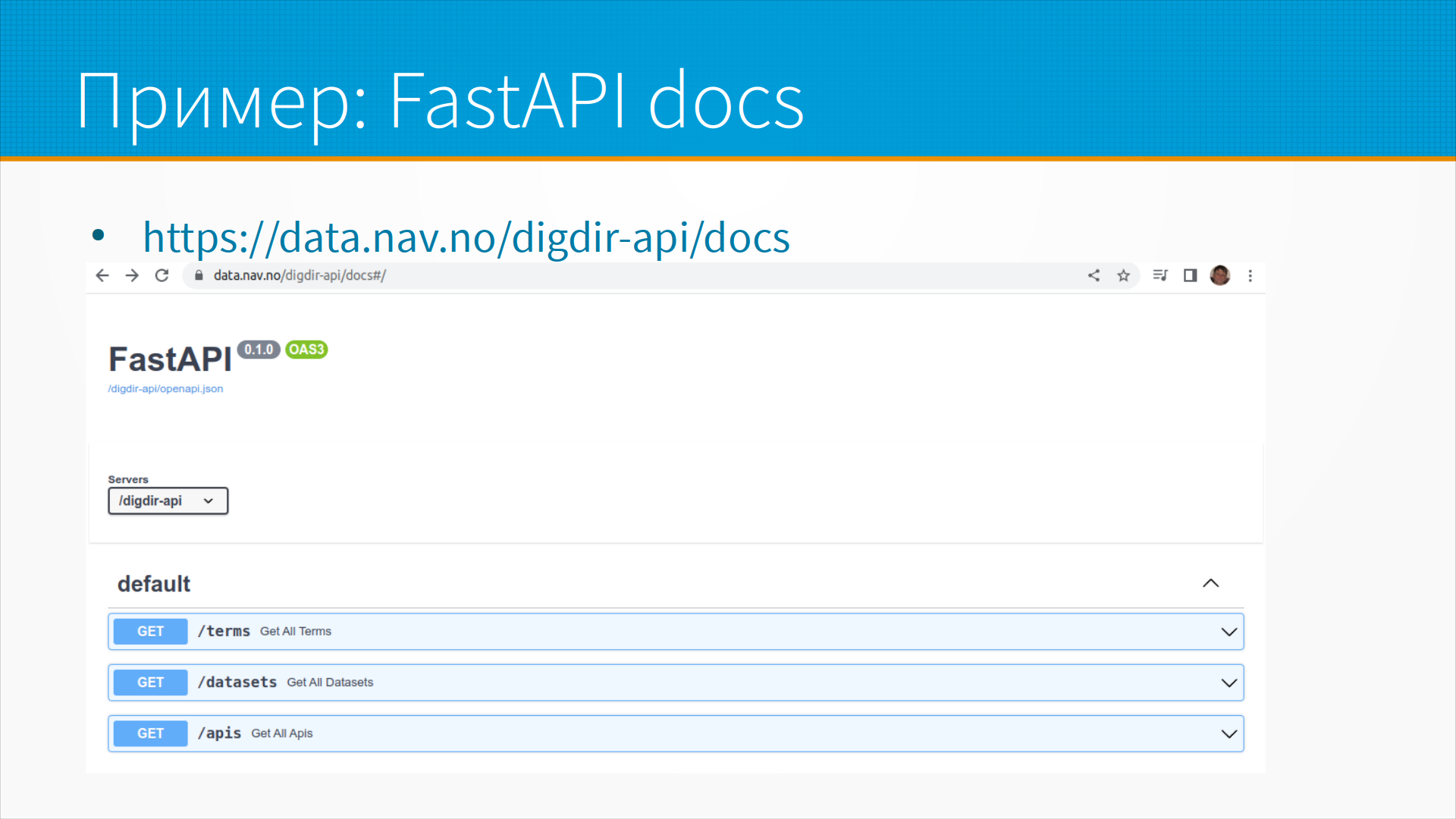
 Или, как вот на этом слайде, можем даже попробовать вызвать тот или иной метод.
То есть мы нажимаем кнопку try it out, нам открывается панель ввода
и мы вводим туда наши параметры, нажимаем кнопку и получаем результат.
Или, как вот на этом слайде, можем даже попробовать вызвать тот или иной метод.
То есть мы нажимаем кнопку try it out, нам открывается панель ввода
и мы вводим туда наши параметры, нажимаем кнопку и получаем результат.
 Как мы можем определить качество данных?
Качество данных - это мера пригодности к использованию.
Качественные данные - это данные, которые соответствуют нашим предположениям о них.
То есть мы ожидали, что в каком-то столбце у нас будут целые числа, и это целые числа.
Мы ожидали, что там не будет отрицательных чисел, и там нет отрицательных чисел,
это качественные данные.
Как мы можем определить качество данных?
Качество данных - это мера пригодности к использованию.
Качественные данные - это данные, которые соответствуют нашим предположениям о них.
То есть мы ожидали, что в каком-то столбце у нас будут целые числа, и это целые числа.
Мы ожидали, что там не будет отрицательных чисел, и там нет отрицательных чисел,
это качественные данные.
 И для проверки качества данных нам нужна валидация данных,
нужны какие-то библиотеки, которые проверяли бы поступающие данные
на предмет каких-то в них ошибок, несоответствия нашим предположениям.
То есть для того, чтобы мы могли проверить качество данных,
нам нужно сделать какие-то предположения о данных, как-то их задокументировать
и с помощью какой-то библиотеки проверить.
И для проверки качества данных нам нужна валидация данных,
нужны какие-то библиотеки, которые проверяли бы поступающие данные
на предмет каких-то в них ошибок, несоответствия нашим предположениям.
То есть для того, чтобы мы могли проверить качество данных,
нам нужно сделать какие-то предположения о данных, как-то их задокументировать
и с помощью какой-то библиотеки проверить.
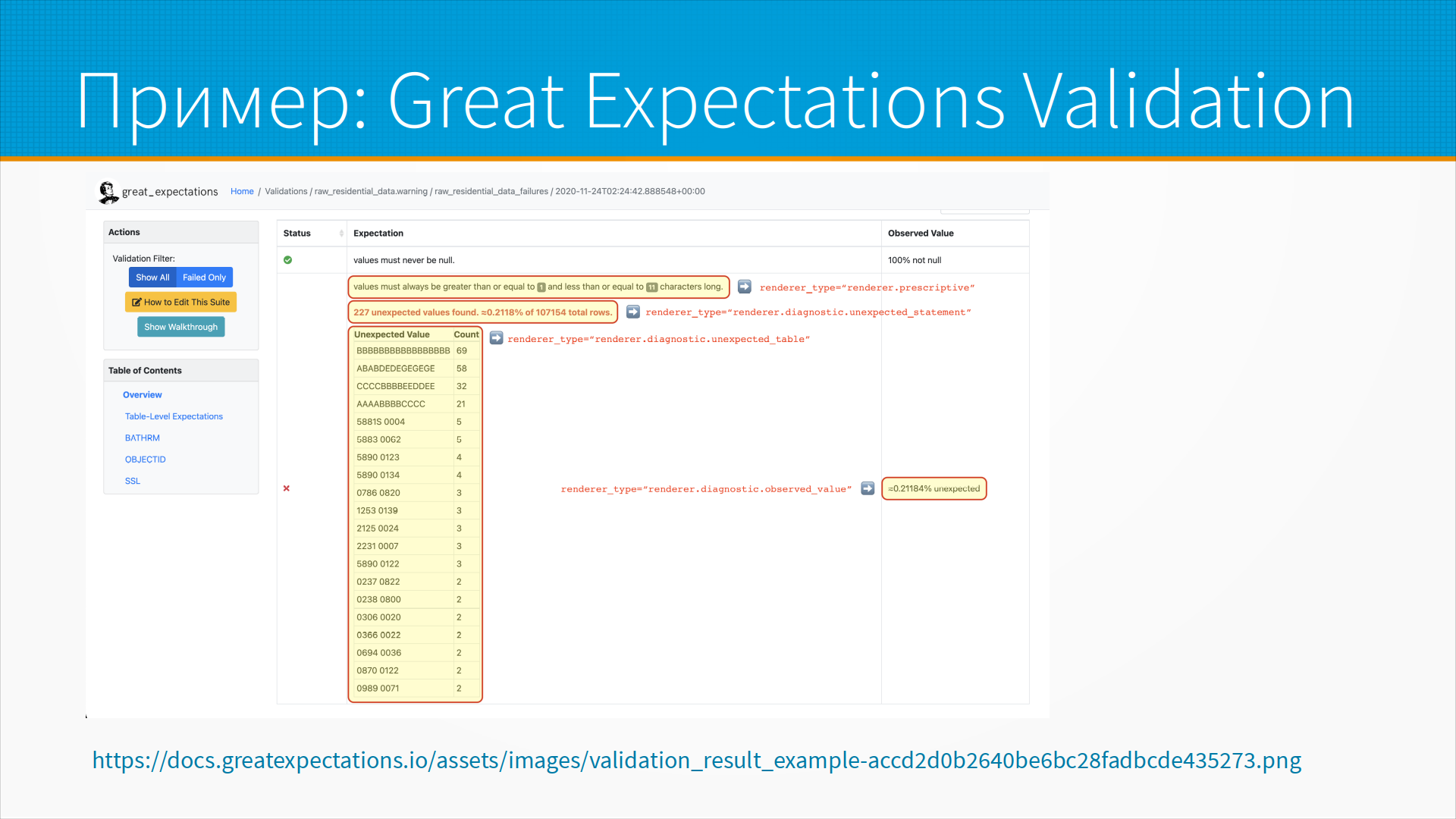
На мой взгляд, лучший вариант тут – это библиотека Great Expectations, которая позволяет, во-первых, выявить закономерности имеющихся в данных, то есть не расписывать руками, а получить, так сказать, профиль данных. То есть она анализирует данные и смотрит, что ага, здесь только положительные числа, и так и пишет, что, наверное, числа должны быть положительные. И добавить свои какие-то данные, например, что среднее не должно быть меньше 15, эти строчки должны соответствовать вот такому регулярному выражению и так далее. Мы написали правила с помощью простых питоновских команд, и у нас есть проверка, которая при запуске говорит нам - смотри, вот в этом столбце, это вот в примере, у нас есть 277 значений, которые не соответствуют нашим ожиданиям. Конкретно они не соответствуют вот этим ожиданиям - мы думали, что будет здесь это, а здесь то. Эту проверку можно делать в интерфейсе, эту же проверку можно делать автоматически и получать результаты, какие-то варнинги выставлять.
 Плюс в Great Expectations есть такая штука как DataDoc.
То есть мы можем запустить Great Expectations поверх наших данных,
и оно выдаст нам профиль данных, статистики, как распределены данные,
типичное значение, то, что называется, 5 базовых точек данных и так далее и тому подобное.
Очень удобно для предварительного анализа поступающих к нам данных.
Плюс в Great Expectations есть такая штука как DataDoc.
То есть мы можем запустить Great Expectations поверх наших данных,
и оно выдаст нам профиль данных, статистики, как распределены данные,
типичное значение, то, что называется, 5 базовых точек данных и так далее и тому подобное.
Очень удобно для предварительного анализа поступающих к нам данных.
 Как быть, если данные пришли неверные?
Есть шаблон проектирования Circut Breaker (предохранитель).
Что такое предохранитель?
Ну, к нам пришли плохие данные, мы просто их не пропустили.
Мы не всегда можем это сделать, но предположим, что у нас льются в нашу систему данные для обучения.
И у нас стоит система, которая проверяет, валидирует, эти данные,
и если они не соответствуют ожиданиям, она их не переливает в наше хранилище,
в котором мы встроим нашу модель,
а оно их льет в специальную, например, очередь или в специальное хранилище
для того, чтобы мы потом разобрались с этими данными
и решили, включать или не включать их в обучающий набор.
Таким образом, у нас данные получаются неполные,
но те данные, которые мы собрали, они соответствуют нашим предположениям.
Как быть, если данные пришли неверные?
Есть шаблон проектирования Circut Breaker (предохранитель).
Что такое предохранитель?
Ну, к нам пришли плохие данные, мы просто их не пропустили.
Мы не всегда можем это сделать, но предположим, что у нас льются в нашу систему данные для обучения.
И у нас стоит система, которая проверяет, валидирует, эти данные,
и если они не соответствуют ожиданиям, она их не переливает в наше хранилище,
в котором мы встроим нашу модель,
а оно их льет в специальную, например, очередь или в специальное хранилище
для того, чтобы мы потом разобрались с этими данными
и решили, включать или не включать их в обучающий набор.
Таким образом, у нас данные получаются неполные,
но те данные, которые мы собрали, они соответствуют нашим предположениям.
Соответственно, проблемы с данными могут возникать на трех уровнях. Data Source Issues - это когда у нас какие-то значения поступили не те, то есть, например, неверное значение, отрицательное значение, там, где мы ожидаем положительное, пропущенное значение, там, где мы этого не ожидаем, или дублирующийся первичный ключ и так далее и тому подобное.
Data Injection Issues – это когда у нас некоторые проблемы с потреблением данных, то есть, например, нам приходят данные в одной схеме, мы ожидаем в другой схеме. Или у нас, допустим, какие-нибудь ошибки с тайм-зоной или, опять же, дубликатами, то есть, что-то, что выявляется только на этапе вставки данных в базу данных уже. Мы приняли их у источника, мы начали вставлять в базу данных, и у нас случилась какая-то ошибка, например, дубликат ключа.
И Referential Integrity Issues – это, например, когда у нас есть строки документа, а самого документа, для которого эти строки, у нас в базе, например, нет. Или у нас есть зарплата человека, а человека такого в базе нет. То есть, это нарушение ссылочной целостности.
Во всех трех случаях мы просто исключаем те данные, которые нам не удалось нормально вставить, и отправляем их в специальное временное хранилище для последующего разбора либо для отказа от работы с ними. Таким образом, мы как бы заметаем наши ошибочные данные под ковер в надежде, что у нас потом будет время и силы с ними разобраться.
Вообще, это правильный способ на проде все непонятное отвергать. То есть, на проде нам самое главное - обеспечить нормальную работу большего числа клиентов. То есть, если у нас одна десятая процента клиентов отвалится, а все остальные клиенты будут счастливы - это нормально. Плохо, когда из-за этой одной десятой клиентов умрут все.
 Как мы можем оценить качество ML-модели, третьего нашего компонента?
В материалах прошлой лекции была статья
Себастьяна Рашки, и ее стоит прочитать.
Нам нужно оценить производительность модели, допустим.
То есть, как-то получить какую-то базовую оценку.
И тут все зависит от того, велик ли у нас датасет или нет.
Как мы можем оценить качество ML-модели, третьего нашего компонента?
В материалах прошлой лекции была статья
Себастьяна Рашки, и ее стоит прочитать.
Нам нужно оценить производительность модели, допустим.
То есть, как-то получить какую-то базовую оценку.
И тут все зависит от того, велик ли у нас датасет или нет.
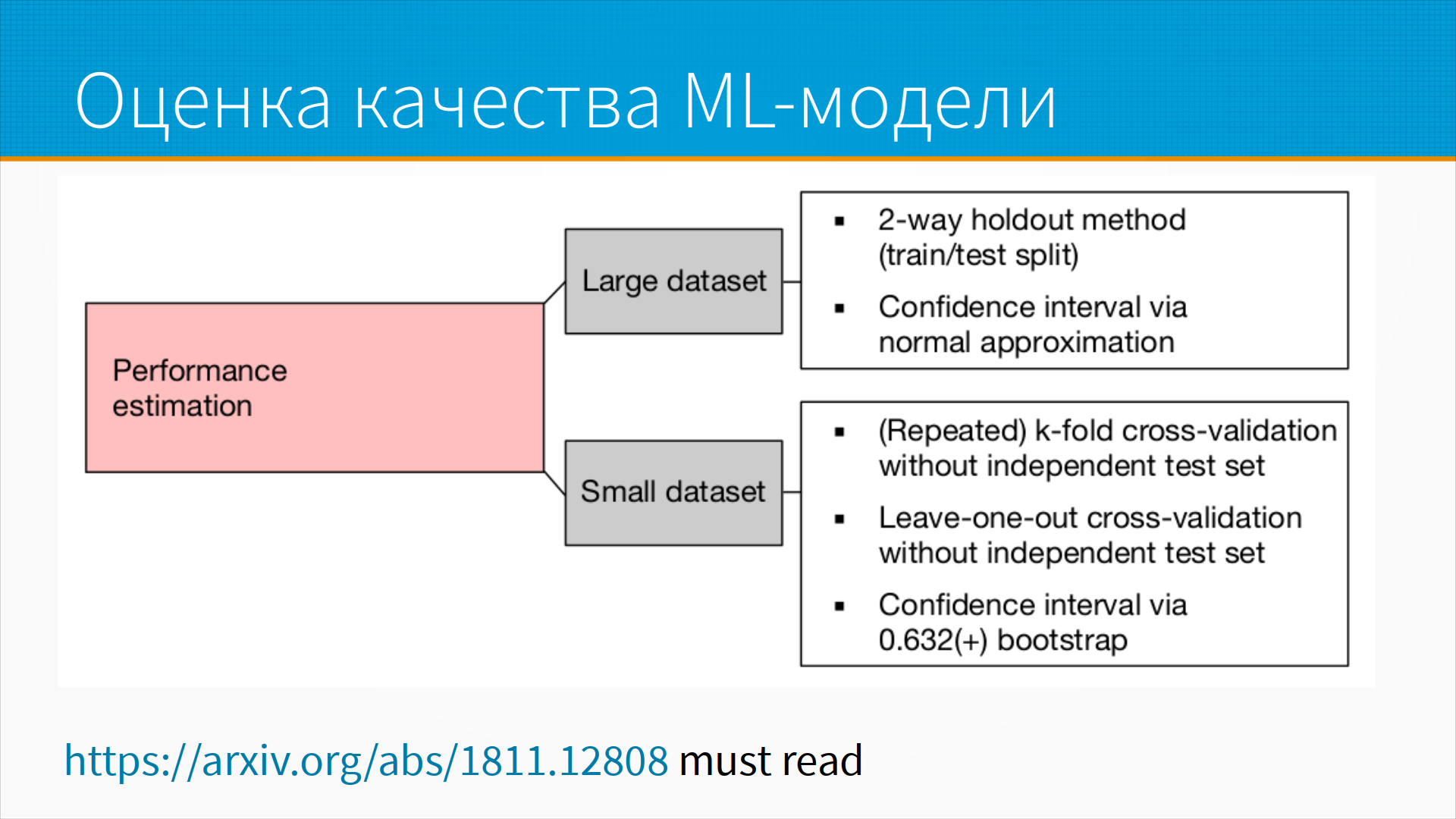
Если у нас большой датасет, то у нас нет особенного выбора. Мы не можем делать на нем кросс-валидацию просто потому, что, наверное, долго учить модель на большом датасете. Поэтому обычно делают разделение на train и test, иногда train, test и val split. Тогда на validation мы подбираем, например, какие-нибудь гиперпараметры, которые они смогли подобрать на train. Это two-way holdout метод. И доверительный интервал мы считаем через нормальную аппроксимацию.
Если датасет маленький, то мы можем позволить себе кросс-валидацию на нескольких фолдах без дополнительного тестового набора. Почему без дополнительного тестового набора? Потому что, скорее всего, у нас недостаточно данных, чтобы поймать какие-то ошибки и хорошо оценить качество. Leave-one-out cross-validation - для совсем маленьких наборов, когда мы выкидываем по одной записи из набора, на остатке учим и на этой записи тестируем. Если есть проблема, нам нужно убедиться, что в датасете нет дубликатов, чтобы так не получилось, что мы одну запись выкинули, а в ней есть копия в оставшемся датасете. Понятно, что оценка качества будет искажена. Ну и доверительный интервал мы считаем bootstrap-ом. Тут надо заметить, что bootstrap искажает оценку дисперсии, поэтому тут надо делать поправку. В статье Себастьяна Рашки это все хорошо расписано.
 После того, как мы получили какую-то первичную оценку качества,
нам нужно выбрать модель или выполнить какую-нибудь оптимизацию гиперпараметров
и оценить производительность нашей оптимизированной модели
уже на рабочем датасете.
После того, как мы получили какую-то первичную оценку качества,
нам нужно выбрать модель или выполнить какую-нибудь оптимизацию гиперпараметров
и оценить производительность нашей оптимизированной модели
уже на рабочем датасете.
Тут, опять же, если у нас большой датасет, мы делаем 3-way holdout метод, то есть train-validation-test split. На маленьком датасете мы, опять же, делаем cross-validation и отдельный независимый тестовый набор, который модель не видела.
 После того, как мы обучили модель, ее хорошо бы сравнить с другими моделями.
То есть нам надо понять, лучше ли эта модель, чем какая-то другая,
которую мы учили до того.
И тут у нас, опять же, два варианта.
Если у нас датасет большой, мы можем нарезать его
на несколько независимых обучающих тестовых наборов
и сравнивать на них алгоритмы.
Мы можем делать тест Макнемара.
В общем, это даст нам достаточно хорошую оценку.
После того, как мы обучили модель, ее хорошо бы сравнить с другими моделями.
То есть нам надо понять, лучше ли эта модель, чем какая-то другая,
которую мы учили до того.
И тут у нас, опять же, два варианта.
Если у нас датасет большой, мы можем нарезать его
на несколько независимых обучающих тестовых наборов
и сравнивать на них алгоритмы.
Мы можем делать тест Макнемара.
В общем, это даст нам достаточно хорошую оценку.
Для маленьких датасетов золотой стандарт – это 5 на 2 cross-validation. Это когда мы пять раз пополам делим датасет с разными сидами. На одной половине учимся, на другой предсказываем. И наоборот, на другой половине, на которой мы только что предсказывали, мы на ней учимся и первую опять предсказываем. И получается 10 вызовов, то есть 5 парных вызовов. И мы можем на нем делать либо тест Фишера, либо, на самом-то деле, тут у Рашки это не написано, можно делать тест Макнемара, тоже получается хорошо. Или вложенную cross-validation, по-прежнему, посмотрите статью Рашки, там мелкие подробности есть.
 Когда мы получили какую-то оценку качества,
встает вопрос, хорошая ли у нас модель или нет.
То есть с чем мы ее сравниваем?
Самый простой способ сравнить качество модели
хоть с чем-то - это случайный baseline.
Представим себе, что мы вместо нашей модели
поставили совершенно случайный алгоритм,
который выдаёт генератором случайных чисел классы.
Можно посмотреть, какое качество у нас получилось в этом случайном baseline
и какое в нашем baseline, насколько оно отличается.
Когда мы получили какую-то оценку качества,
встает вопрос, хорошая ли у нас модель или нет.
То есть с чем мы ее сравниваем?
Самый простой способ сравнить качество модели
хоть с чем-то - это случайный baseline.
Представим себе, что мы вместо нашей модели
поставили совершенно случайный алгоритм,
который выдаёт генератором случайных чисел классы.
Можно посмотреть, какое качество у нас получилось в этом случайном baseline
и какое в нашем baseline, насколько оно отличается.
Следующий такой тупой алгоритм - это выдавать предсказания в соответствии с распределением классов. То есть, грубо говоря, если у нас два класса, один в 70% случаев, другой в 30%, то мы случайно отвечаем в 70% случаев первым классом, а в 30% – вторым.
Либо самый частый класс, либо какие-то простые не ML-евристики, которые принимают решение, и мы сравниваем, какой получился, например, F1 простой евристики и какой получился F1 в нашей модели.
В конечном итоге нам хотелось бы сравнить работу нашей модели с качеством оценки человека, но такие бейзлайны не всегда есть. Но зачастую на рынке есть готовые решения, которые можно, допустим, купить и попробовать на нашем датасете.
Сейчас я переключусь с презентации на отдельный пример, где мы разберём примеры такой оценки.
 То есть тут я пользуюсь датасетом по профосмотру.
По-моему, это профосмотр на каком-то горнорудном предприятии в Казахстане.
То есть тут я пользуюсь датасетом по профосмотру.
По-моему, это профосмотр на каком-то горнорудном предприятии в Казахстане.
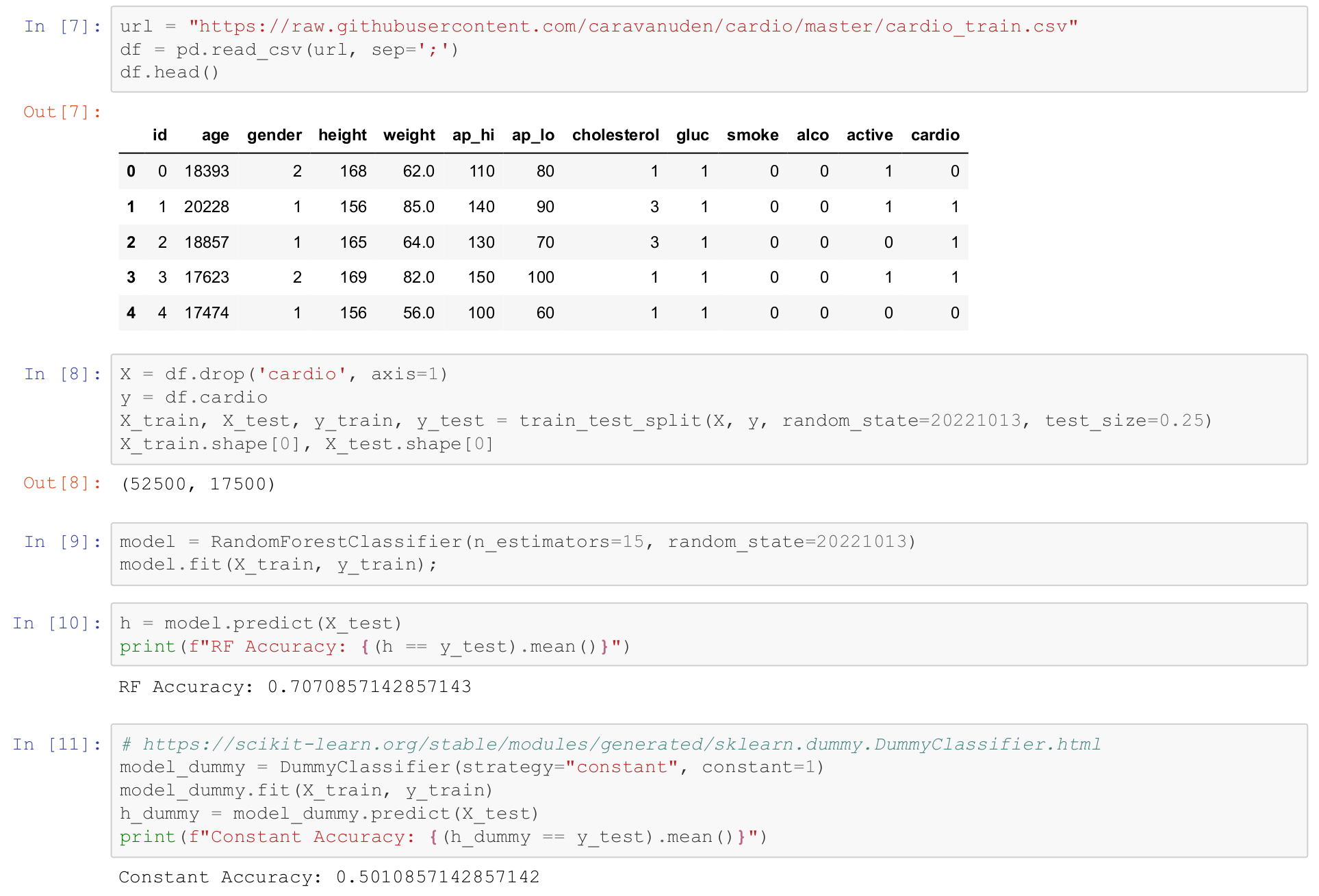 Мы его тут грузим, предобрабатываем, делим
и, не особенно вдаваясь в подробности, учим простой random forest с 15 деревьями, очень простую модель.
И получаем accuracy примерно 71%.
Модель предсказывает, есть или нет кардиозаболевания
в зависимости от возраста, пола, роста, веса,
артериального давления, систолического и диастолического,
уровня холестерина, глюкозы.
Уровень холестерина и глюкозы от 1 до 3 - типа, маленький, средний или высокий.
Курит ли человек, пьёт ли он и занимается ли он каким-нибудь спортом.
Мы видим, что, не напрягаясь, мы получили качество 71%.
Значит, вот у нас такой бейзлайн.
Мы его тут грузим, предобрабатываем, делим
и, не особенно вдаваясь в подробности, учим простой random forest с 15 деревьями, очень простую модель.
И получаем accuracy примерно 71%.
Модель предсказывает, есть или нет кардиозаболевания
в зависимости от возраста, пола, роста, веса,
артериального давления, систолического и диастолического,
уровня холестерина, глюкозы.
Уровень холестерина и глюкозы от 1 до 3 - типа, маленький, средний или высокий.
Курит ли человек, пьёт ли он и занимается ли он каким-нибудь спортом.
Мы видим, что, не напрягаясь, мы получили качество 71%.
Значит, вот у нас такой бейзлайн.
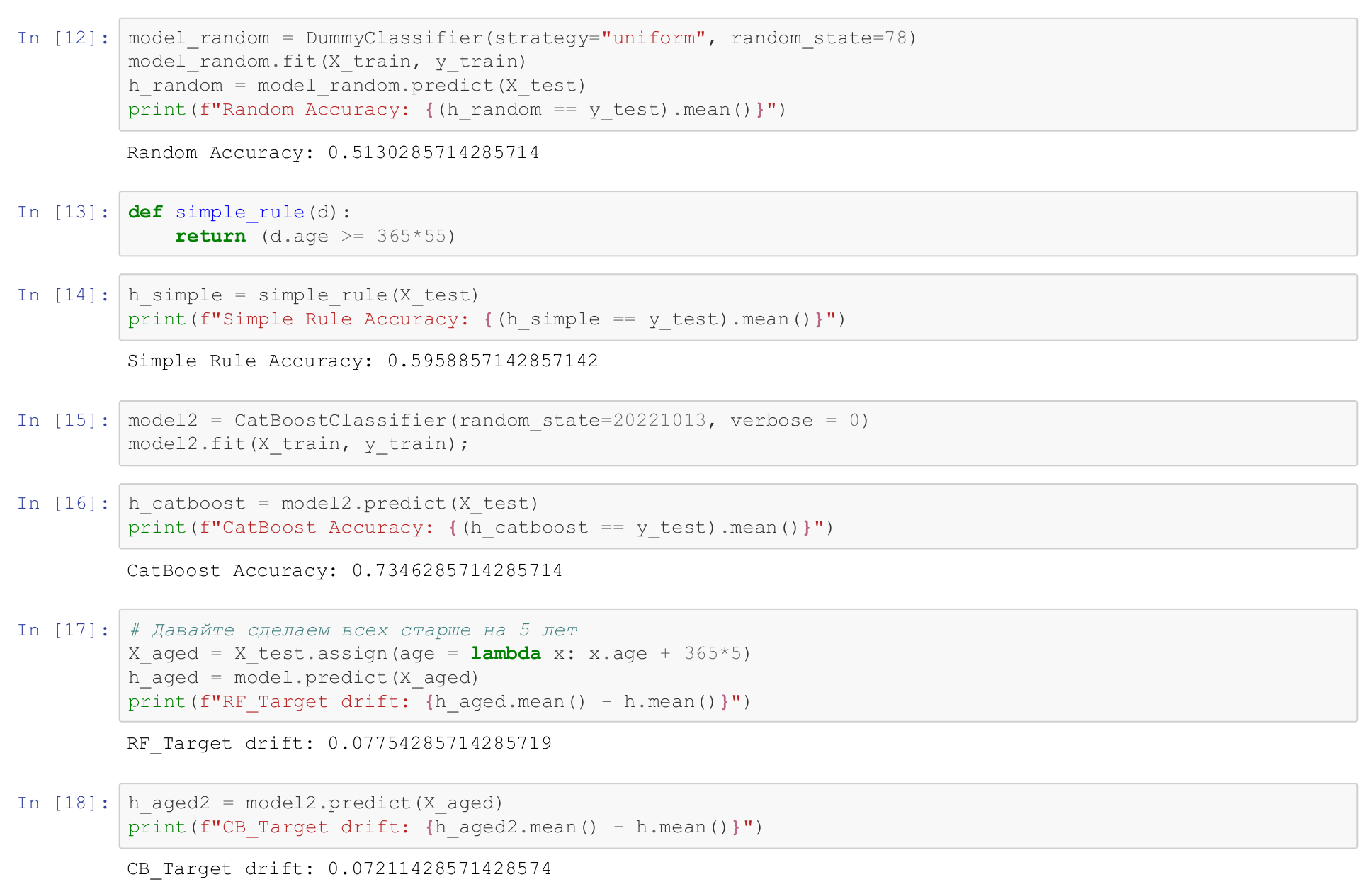 А какое бы качество нам выдала случайная модель?
Тут у нас есть в библиотеке scikit-learn DummyClassifier,
специально предназначенный для таких случаев.
И мы можем сделать этот классификатор.
Он притворяется обычным scikit-learn классификатором, который обучается, но на самом деле он ничему не учится.
Он в нашем случае всегда выдает константный класс 1.
И мы получаем accuracy примерно 50% - ну, неплохо.
А какое бы качество нам выдала случайная модель?
Тут у нас есть в библиотеке scikit-learn DummyClassifier,
специально предназначенный для таких случаев.
И мы можем сделать этот классификатор.
Он притворяется обычным scikit-learn классификатором, который обучается, но на самом деле он ничему не учится.
Он в нашем случае всегда выдает константный класс 1.
И мы получаем accuracy примерно 50% - ну, неплохо.
Если мы зададим равномерное распределение, то есть он будет случайно выбрасывать, то есть сердечное заболевание, то нет, то на этом датасете, это 12-я строчка, на этом датасете мы получим accuracy 51,3%.
Предположим, что у нас есть простое решающее правило. То есть пусть сердце болит у всех, кому больше 55 лет, тут возраст в днях в датасете, а у тех, кто младше 55 лет - пусть у них сердце не болит. И мы определяем решающую функцию simple_rule, этой функцией мы размечаем датасет. Какое качество, какой accuracy мы получаем? Мы получаем 59,5% качества просто вот таким решающим правилом.
Ну, а что, если мы обучим catboost? Мы обучим catboost, тоже на самом деле не сильно напрягаясь, это очень грязный датасет, на нем можно получить качество где-то 85% accuracy, по-моему. Но вот catboost без всякого обучения, дополнительной информации, дает нам качество 74%. То есть мы видим, что простой baseline нам дал 71%, catboost 74%, ну, хорошо, значит catboost более-менее хорошая модель.
Очень часто мы сталкиваемся с ситуациями, когда обучается какая-нибудь нейронная сеть, а ее забывают сравнить с простым baseline. Сравнивается с простым baseline, и получается, что ее качество от простого baseline, какого-нибудь логрега, не очень сильно отличается, а то и хуже.
 Я возвращаюсь назад к презентации.
После того, как мы обучили модель,
нам бы хорошо провести тесты устойчивости решения.
Например, perturbation test - насколько чувствительна модель к шуму.
Мы можем добавить какое-то количество шума к нашим данным.
Для аудио это может быть буквально шум.
Для табличных данных это могут быть какие-нибудь случайные значения, допустим, плюс-минус одна десятая стандартного отклонения для этой колонки.
Посмотреть, изменится ли предсказание модели.
Я возвращаюсь назад к презентации.
После того, как мы обучили модель,
нам бы хорошо провести тесты устойчивости решения.
Например, perturbation test - насколько чувствительна модель к шуму.
Мы можем добавить какое-то количество шума к нашим данным.
Для аудио это может быть буквально шум.
Для табличных данных это могут быть какие-нибудь случайные значения, допустим, плюс-минус одна десятая стандартного отклонения для этой колонки.
Посмотреть, изменится ли предсказание модели.
Затем очень важный invariant тест. То есть, что не должно поменять предсказание модели. Пример такого invariant теста: например, мы делаем кредитный скоринг, и человеку дают кредит. И если мы искусственно в данных увеличим его доход, или увеличим объем его имущества, или уменьшим его задолженность по другим кредитам, то его кредитная способность не должна упасть. То есть, она может не вырасти, но упасть она точно не должна. Или, например, мы тестируем специалиста на пригодность к работе разработчиком. Это мужчина. Мы прогнали его через тесты, мы собрали ему какую-то статистику - модель сказала, хороший разработчик, нанимай. Мы заменили в модели мужчину на женщину. Если модель в этот момент сказала - не нанимай, совершенно очевидно, что она что-то не то делает, для производительности программиста пол неважен. Если для предсказания работоспособности программиста вдруг пол оказался важен, значит, мы обучили модель не тому.
Третья важная вещь, которую нужно проверять - это directional expectations test. То есть, мы точно знаем, например, что если у человека кредитный скор, допустим, 600, и у него упадет доход, то кредитный скор не вырастет ни в коем случае. То есть, он может упасть, может остаться тем же самым, но точно не вырастет. Если мы, допустим, оцениваем здоровье человека, то при всех прочих показаниях, если мы сделали его искусственно старше, он не должен стать здоровее. То есть, он может остаться тем же самым по здоровью. Оценка здоровья может стать хуже, но здоровее он не станет от того, что он станет старше.
Вернемся к нашему примеру с медосмотром.
Проверим чувствительность наших моделей.
Добавим всем людям в датасете 5 лет. Это вот в 17-й строке, мы сделаем всех старше на 5 лет. И посмотрим на уже обученных моделях, как сдрейфует предсказание. Что значит сдрейфует предсказание? То есть, мы взяли предсказания для исходного дата-сета. Скажем, у нас было среднее количество больных, сердечных больных было, допустим, 50%. Потом мы взяли вот этот искусственно состаренный датасет, и он предсказал, что там 58% больных сердечных. То есть дрейф таргета, дрейф целевой переменной, у нас примерно 8%. Это примерно совпадает с тем, как оно в жизни устроено. То есть, каждый год жизни повышает вероятность заболеть примерно на 1%. То есть, близко к практике.
Посмотрим, как наша вторая модель, это у нас катбустовская, сдрейфует. Катбустовская модель показала дрейф 0,072, что тоже примерно совпадает с ощущением, как оно должно быть. То есть, я ожидал тут дрейф 5%, он 7%. Ну, в общем, как я и пальцем в небо ткнул, сказал 5%, тут 7%. Нормально, дымовой тест проходит.
Мое простое правило, что все старше 55 лет имеют больное сердце, не проходит эту простую проверку. Обратите внимание, что моё простое правило говорит: количество больных сердечных увеличилось на 25% после того, как мы состарили людей на 5 лет. Ну, это очевидно неверно. Простое правило - это плохой бейзлайн. Наше dummy правило, которое просто всем возвращает константную болезнь сердца, говорит, что ничего не изменилось. Ну, на то оно и тупое.
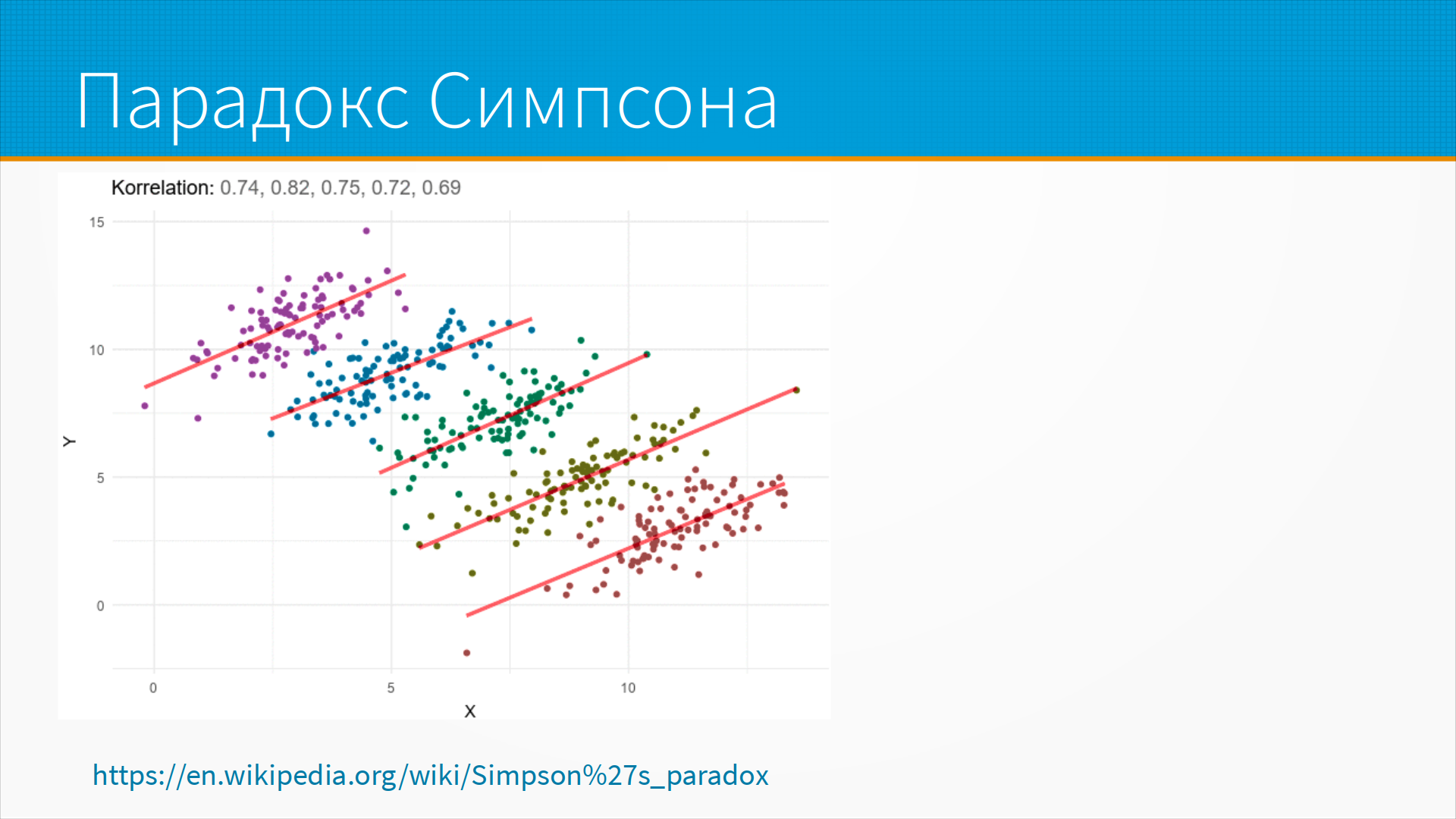 Возвращаемся к нашим слайдам и вспомним про парадокс Симпсона.
История про парадокс Симпсона такая.
В американском университете женщина подавалась на позицию
профессора, по-моему, сотрудника факультета, наверное, профессора все-таки,
и ее не взяли, как-то не выиграла на конкурсе.
Она подала в суд на университет со словами "меня тут ущемляют,
потому что я женщина".
Университет собрал статистиков, на университете был факультет статистики,
и статистики доказали суду, что на самом деле женщин
в этом университете не только не ущемляют,
но наоборот даже всячески поддерживают.
Хитрость тут была в том, что в среднем процент женщин
на кафедре был меньше, чем мужчин.
На тех кафедрах, на которых женщин было мало, поступало их еще меньше.
Грубо говоря, у женщины было больше, чем у мужчины шансов стать профессором.
Просто женщин поступало меньше.
Возвращаемся к нашим слайдам и вспомним про парадокс Симпсона.
История про парадокс Симпсона такая.
В американском университете женщина подавалась на позицию
профессора, по-моему, сотрудника факультета, наверное, профессора все-таки,
и ее не взяли, как-то не выиграла на конкурсе.
Она подала в суд на университет со словами "меня тут ущемляют,
потому что я женщина".
Университет собрал статистиков, на университете был факультет статистики,
и статистики доказали суду, что на самом деле женщин
в этом университете не только не ущемляют,
но наоборот даже всячески поддерживают.
Хитрость тут была в том, что в среднем процент женщин
на кафедре был меньше, чем мужчин.
На тех кафедрах, на которых женщин было мало, поступало их еще меньше.
Грубо говоря, у женщины было больше, чем у мужчины шансов стать профессором.
Просто женщин поступало меньше.
И вот тут пример парадокса Симпсона для регрессии. Если мы видим вот этот набор точек, и каждый из кластеров моделируем отдельно, мы видим, что тут есть положительная корреляция между x и y.
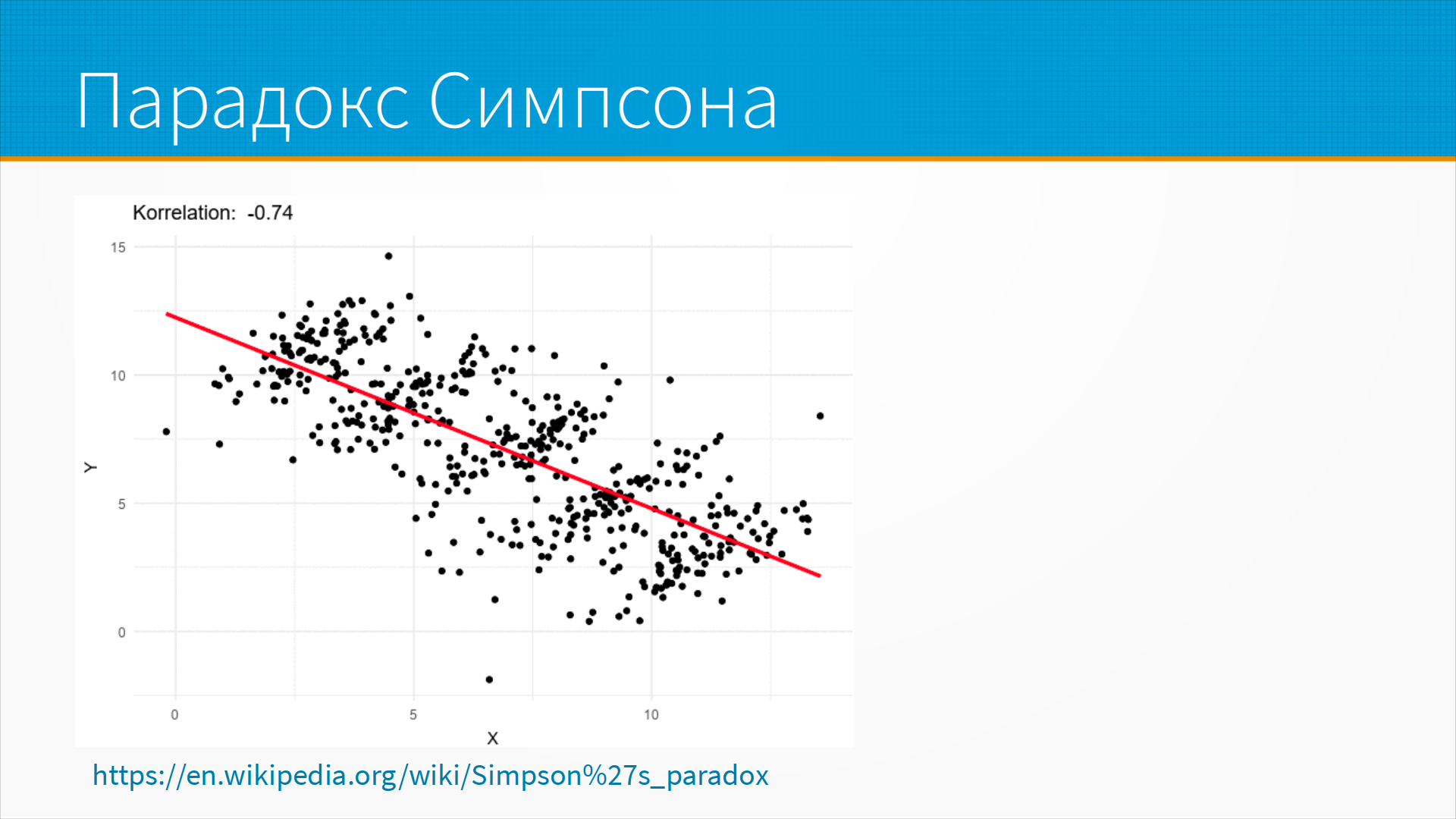 Но если бы мы, допустим, как на этом слайде, не разбили их на кластеры,
то мы видим отрицательную корреляцию.
И обратите внимание, что у нас сильная корреляция больше, чем 0,7 в первом случае - положительная,
а во втором корреляция больше, чем 0,7 по модулю - она отрицательная, на тех же самых данных.
Просто в зависимости от того, делим мы на подгруппы или нет.
Но если бы мы, допустим, как на этом слайде, не разбили их на кластеры,
то мы видим отрицательную корреляцию.
И обратите внимание, что у нас сильная корреляция больше, чем 0,7 в первом случае - положительная,
а во втором корреляция больше, чем 0,7 по модулю - она отрицательная, на тех же самых данных.
Просто в зависимости от того, делим мы на подгруппы или нет.
И вот эта ситуация и есть парадокс Симпсона, и ее надо иметь в виду, когда вы оцениваете производительность моделей. То есть может быть, что у вас модель работает в принципе хорошо, но для каких-то групп, например, для какой-то возрастной группы, для какой-то демографической группы, или для какой-то профессии, или для какого-то уровня дохода, как-то она работает очень плохо.
 Для поиска таких кластеров, на которых модель ведет себя странно,
существует много интересных алгоритмов,
в том числе Subgroup Discovery Algorithms и
Automated Data Slicing for Model Validation,
но обычно можно просто выполнить кластеризацию данных,
и для каждого кластера отдельно взять модель, обученную на всех данных,
и прогнать ее на каждом кластере,
и посмотреть отдельно на качество этой модели.
Для поиска таких кластеров, на которых модель ведет себя странно,
существует много интересных алгоритмов,
в том числе Subgroup Discovery Algorithms и
Automated Data Slicing for Model Validation,
но обычно можно просто выполнить кластеризацию данных,
и для каждого кластера отдельно взять модель, обученную на всех данных,
и прогнать ее на каждом кластере,
и посмотреть отдельно на качество этой модели.
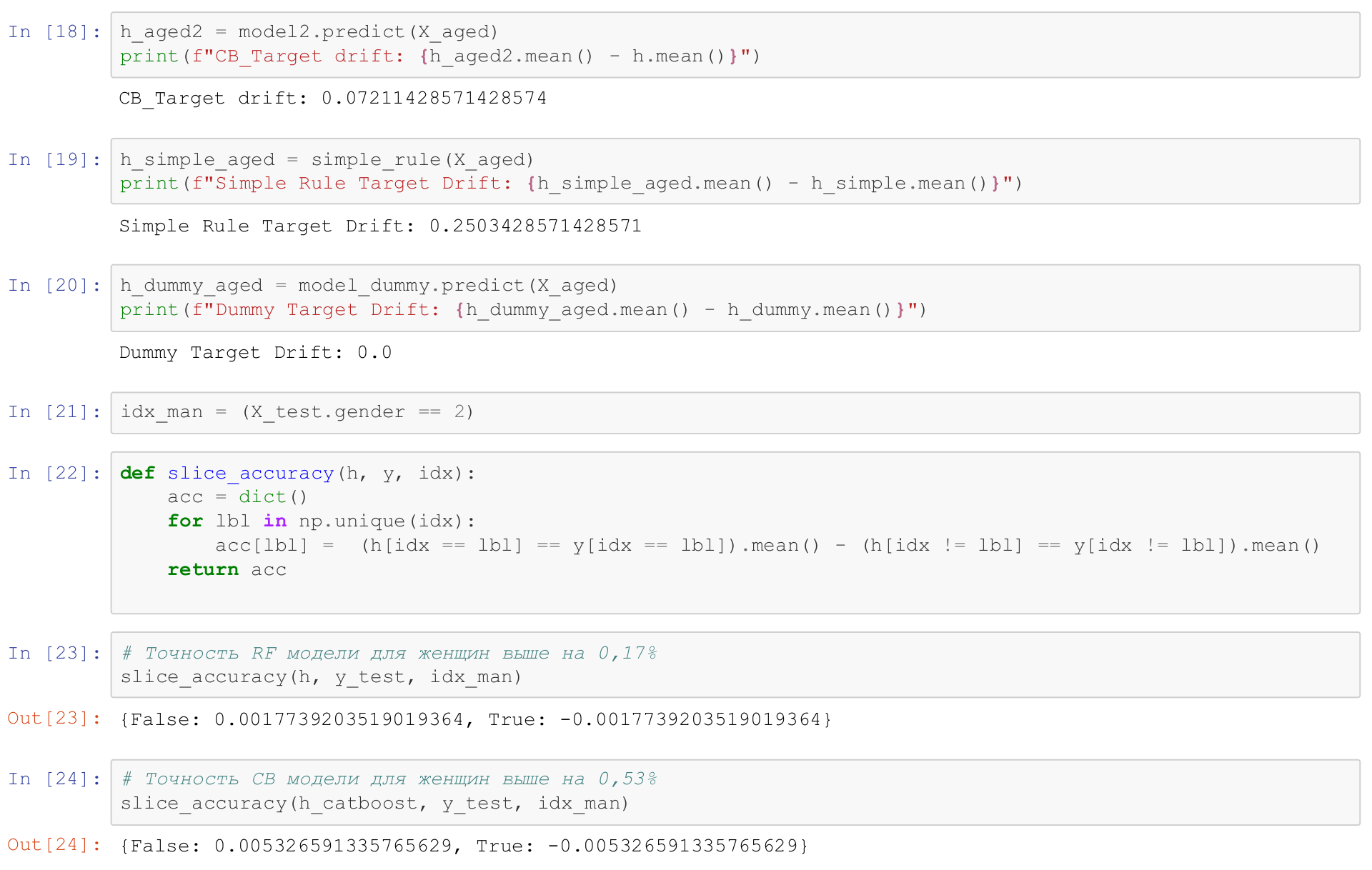 Вернемся к нашему примеру вот тут мы это же и сделаем.
Для начала в 21 строке мы отберем всех мужчин,
индексы всех мужчин,
и напишем простую функцию, которая прогоняет модель по выборке и по дополнению к ней,
и сравнивает качество работы модели, slice_accuracy.
И посмотрим, насколько хорошо работает у нас модель.
И мы видим, что для женщин качество работы модели выше на 0,17%,
в общем, я бы пренебрег такой разницей в качестве для random forest.
У catboost разница в точности предсказания для мужчин и женщин чуть выше, 0,5%,
мы можем разбить наши данные на кластеры.
Вернемся к нашему примеру вот тут мы это же и сделаем.
Для начала в 21 строке мы отберем всех мужчин,
индексы всех мужчин,
и напишем простую функцию, которая прогоняет модель по выборке и по дополнению к ней,
и сравнивает качество работы модели, slice_accuracy.
И посмотрим, насколько хорошо работает у нас модель.
И мы видим, что для женщин качество работы модели выше на 0,17%,
в общем, я бы пренебрег такой разницей в качестве для random forest.
У catboost разница в точности предсказания для мужчин и женщин чуть выше, 0,5%,
мы можем разбить наши данные на кластеры.
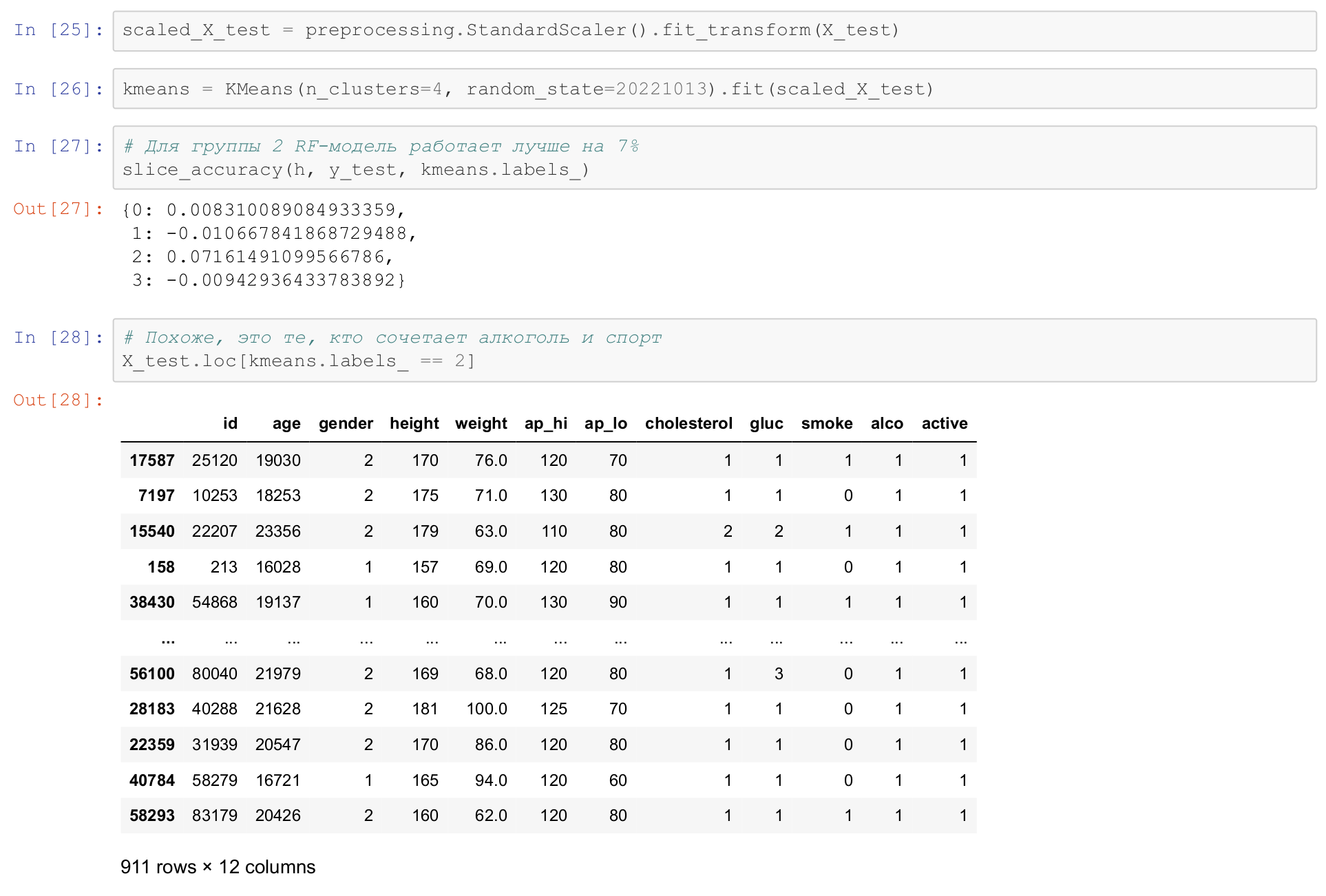 Вот тут я делаю самый простой подход, я нормирую данные и с помощью алгоритма k-means и ищу кластеры.
Почему нормирую?
Потому что k-means опирается на евклидово расстояние,
соответственно, метрика расстояния по всем осям должна быть одинаковой.
Самый простой способ добиться этого, ну или как бы приблизиться к этому -
это вычесть из данных среднее, поделить на стандартное отклонение.
И preprocessing.StandardScaler это и делает.
Вот тут я делаю самый простой подход, я нормирую данные и с помощью алгоритма k-means и ищу кластеры.
Почему нормирую?
Потому что k-means опирается на евклидово расстояние,
соответственно, метрика расстояния по всем осям должна быть одинаковой.
Самый простой способ добиться этого, ну или как бы приблизиться к этому -
это вычесть из данных среднее, поделить на стандартное отклонение.
И preprocessing.StandardScaler это и делает.
Мы учим кластеры в наших данных, и для каждого кластера мы измеряем качество работы модели. Я тут подобрал гиперпараметры, что лучше всего на 4 кластера делить. И мы видим, что для второго кластера наша модель работает лучше на 7%.
Это интересный результат, потому что на остальных кластерах модель более-менее ровно себя ведет. И давайте посмотрим, что это за кластер. Второй кластер – это кластер, в котором люди и пьют алкоголь, и ведут активный образ жизни. Это удивительная комбинация, и модель random forest работает лучше для пьющих спортсменов, чем для обычных людей.
Разница у катбустовской модели менее выражена,
то есть она для пьющих спортсменов работает лучше всего на 5%.
И мы можем таким образом проверить, насколько наша модель ущемляет критичную для нас группу населения. Если мы ожидаем, что в нашей выборке будет много пьющих спортсменов, тогда это может быть важно. Если мы этого не ожидаем, обычно такого мы не ожидаем, то это, наверное, можно проигнорировать. Главное – знать об этом.
В некоторых странах вас могут посадить в тюрьму за то, что вы ущемляете женщин или чернокожих людей. Ну, что-то в этом есть. Кредитоспособность человека не должна зависеть от его пола, она должна зависеть от его дохода и имущества.
 Дополнительные материалы:
Дополнительные материалы: