
- 24.10.2022
- 03.10.2025
- обучение
- #mlsystemdesign
Пятая лекция открытого курса "Дизайн систем машинного обучения", "Выбор и обучение модели".
Слайды можно скачать тут mlsysd5ods.pdf
Текстовая расшифровка:
 Добрый день, меня зовут Дмитрий Колодезев и сегодня у нас пятая лекция "Выбор и обучение модели".
Добрый день, меня зовут Дмитрий Колодезев и сегодня у нас пятая лекция "Выбор и обучение модели".

 Базовый подход к выбору архитектуры ML-решения - найдите самое простое решение, которое все легко превосходят
в своих крутых статьях, и его используйте.
Я не сам придумал этот подход, но так часто
делают - смотрят последние бенчмарки, с чем себя сравнивают самые современные
решения, и обычно то, с чем они себя сравнивают - это хорошее, надежное,
проверенное временем решение, которым надо пользоваться в продакшене.
Базовый подход к выбору архитектуры ML-решения - найдите самое простое решение, которое все легко превосходят
в своих крутых статьях, и его используйте.
Я не сам придумал этот подход, но так часто
делают - смотрят последние бенчмарки, с чем себя сравнивают самые современные
решения, и обычно то, с чем они себя сравнивают - это хорошее, надежное,
проверенное временем решение, которым надо пользоваться в продакшене.
 Как пример такого сравнения я взял просто случайную статью, где рассматриваются новые
квантовые алгоритмы, которые должны превосходить обычные неквантовые старые.
И посмотрел сравнение качества работы квантовых алгоритмов и классических
алгоритмов. На слайде мы видим их производительность для разных задач - и
на самом деле видно, что превосходство квантовых алгоритмов совершенно не
очевидно. То есть здесь они себя сравнивают с SVM и CRF, хорошими
проверенными алгоритмами, для которых есть много production ready библиотек, ну и
прирост качества такой весьма спорный.
Как пример такого сравнения я взял просто случайную статью, где рассматриваются новые
квантовые алгоритмы, которые должны превосходить обычные неквантовые старые.
И посмотрел сравнение качества работы квантовых алгоритмов и классических
алгоритмов. На слайде мы видим их производительность для разных задач - и
на самом деле видно, что превосходство квантовых алгоритмов совершенно не
очевидно. То есть здесь они себя сравнивают с SVM и CRF, хорошими
проверенными алгоритмами, для которых есть много production ready библиотек, ну и
прирост качества такой весьма спорный.
 Почему надо быть осторожнее с
современными state-of-the-art решениями? Очень часто это решение никто не пробовал в
продакшене. То есть оно может быть сильно медленнее, требовать сильно больше
памяти, дольше считаться. Для него может не быть готовых библиотек, оно может не
работать на больших или наоборот на маленьких наборах данных. Например, ему
надо очень много данных для того, чтобы завестись. А еще оно может вообще не
работать. То есть то, что оно опубликовано в статье, в которой описано, что она всех
превосходит, вообще не значит, что это подход работоспособный - иногда бывает и так.
Почему надо быть осторожнее с
современными state-of-the-art решениями? Очень часто это решение никто не пробовал в
продакшене. То есть оно может быть сильно медленнее, требовать сильно больше
памяти, дольше считаться. Для него может не быть готовых библиотек, оно может не
работать на больших или наоборот на маленьких наборах данных. Например, ему
надо очень много данных для того, чтобы завестись. А еще оно может вообще не
работать. То есть то, что оно опубликовано в статье, в которой описано, что она всех
превосходит, вообще не значит, что это подход работоспособный - иногда бывает и так.
 Всегда начинайте с простой модели, причем с простой в алгоритмическом смысле, а не
в смысле усилий. То есть, как правило, проще взять готовый Bert и им обработать,
но у него много предположений скрыто под капотом. Вы не увидите какие-то
проблемы данных, не увидите базовые проблемы на входе и выходе. Кроме того,
простая модель обычно проще в развертывании. И, поскольку ML-модель - это
сердце вашей ML-системы, то простая модель делает проще всю систему. Она проще в
отладке.
Всегда начинайте с простой модели, причем с простой в алгоритмическом смысле, а не
в смысле усилий. То есть, как правило, проще взять готовый Bert и им обработать,
но у него много предположений скрыто под капотом. Вы не увидите какие-то
проблемы данных, не увидите базовые проблемы на входе и выходе. Кроме того,
простая модель обычно проще в развертывании. И, поскольку ML-модель - это
сердце вашей ML-системы, то простая модель делает проще всю систему. Она проще в
отладке.
На самом-то деле ошибки на входе и выходе, то есть мусор, который вам приходит, и проблемы с применением вашего предсказания, которое вы уже сделали, обычно являются большими проблемами, чем качество вашей модели. То есть вы можете построить прекрасную модель, но пользователь передаст вам какие-нибудь неполные или странные данные или не сможет пользоваться тем предиктом, который вы сделали по его техническому заданию. В общем, сделайте как можно раньше как можно более простую модель. И все равно вам понадобится baseline, чтобы сравнивать ваши сложные модели. Вот это и будет ваша простая модель baseline.
 При сравнении моделей очень легко наступить на грабли,
специфичные именно для сравнения моделей. Предположим, что мы очень хорошо
умеем работать с градиентным бустингом и не умеем работать с нейронными сетями. И
тогда мы при обучении модели на градиентном бустинге хорошо ее
оптимизировали, подобрали гиперпараметры, а нейронную сеть сделали как попало. И
понятно, что наш градиентный бустинг будет работать лучше. Получается, что мы
как бы сравнили две модели и выбрали лучшую - но на самом-то деле нейронную сеть мы
не доучили. То есть модели в принципе трудно сравнивать, особенно разные
архитектуры. И надо экспериментировать с гиперпараметрами, отслеживать
эксперименты, чтобы потом, когда вы поймете, что модель надо было настраивать,
может быть, перезапустите и сравните результаты. И всегда сомневайтесь в
результатах сравнения моделей.
При сравнении моделей очень легко наступить на грабли,
специфичные именно для сравнения моделей. Предположим, что мы очень хорошо
умеем работать с градиентным бустингом и не умеем работать с нейронными сетями. И
тогда мы при обучении модели на градиентном бустинге хорошо ее
оптимизировали, подобрали гиперпараметры, а нейронную сеть сделали как попало. И
понятно, что наш градиентный бустинг будет работать лучше. Получается, что мы
как бы сравнили две модели и выбрали лучшую - но на самом-то деле нейронную сеть мы
не доучили. То есть модели в принципе трудно сравнивать, особенно разные
архитектуры. И надо экспериментировать с гиперпараметрами, отслеживать
эксперименты, чтобы потом, когда вы поймете, что модель надо было настраивать,
может быть, перезапустите и сравните результаты. И всегда сомневайтесь в
результатах сравнения моделей.
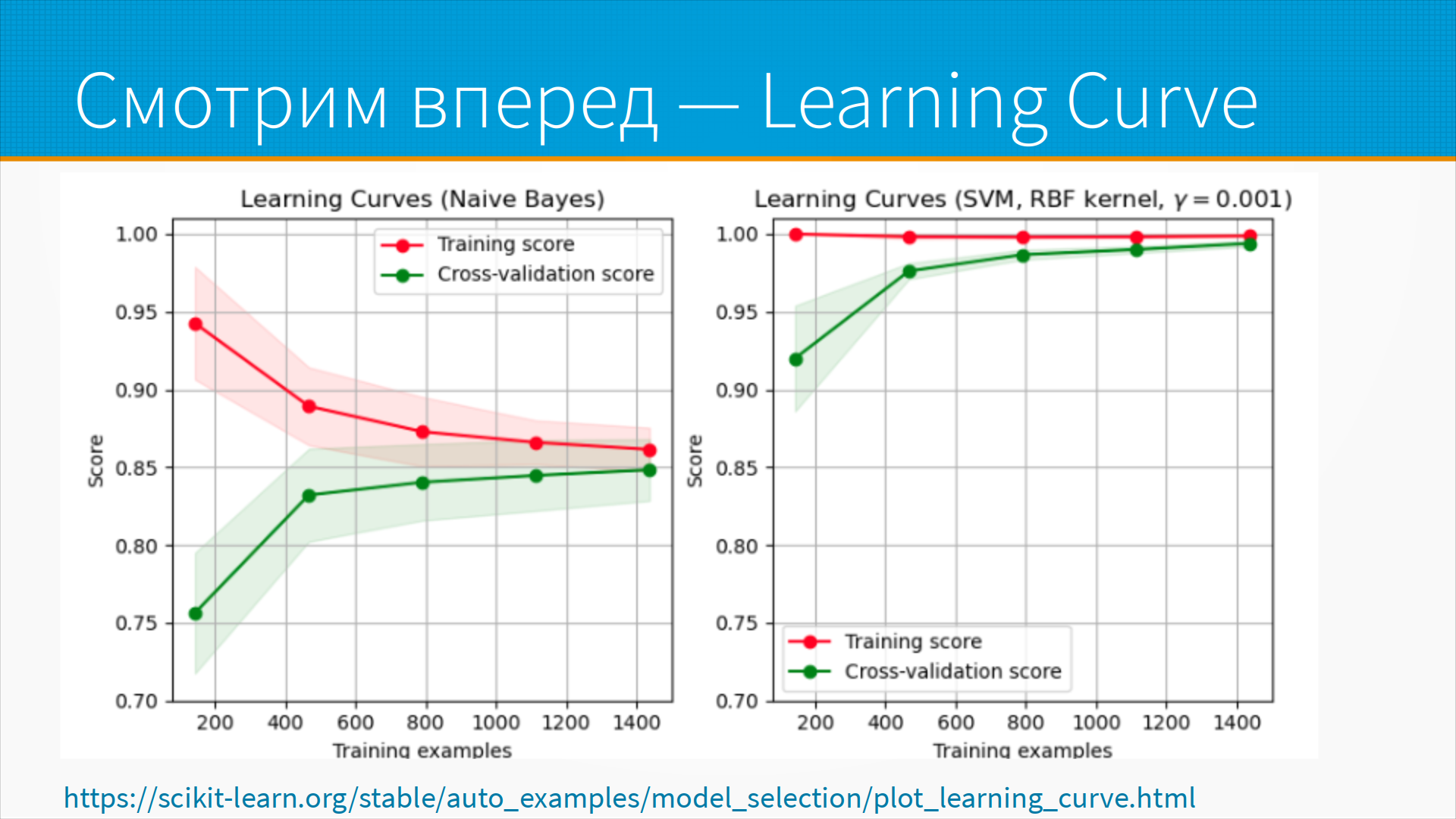 Когда мы сравниваем модели, нам нужно сравнивать
не только их текущую производительность, то есть ту
производительность, которую мы смогли получить на тех данных, которые нам сейчас
доступны, но и ту производительность, которую они в перспективе способны
выдать, когда данных будет больше. Обычно, когда мы запускаем систему, у нас
ограниченный набор данных, а по мере работы системы новые данные появляются, у
нас появляется разметка, мы вычищаем наши данные и так далее и тому подобное. И мы
можем оценить так называемый learning curve, кривую обучения. Обучить нашу модель на
небольшом количестве примеров, допустим на четверти примеров, потом на половине,
потом на двух третьих и смотреть, как качество модели на трейне и тесте меняется.
И если качество модели на трейне и тесте неуклонно растет по мере увеличения
объема данных, то мы можем сделать обоснованное предположение о том, как оно
будет расти по мере появления новых данных. И возможно, что модель, которая
лучше прямо сейчас, будет сравнительно сильно хуже потом, когда данных будет
много. Это часто происходит, например, с нейронками.
Когда мы сравниваем модели, нам нужно сравнивать
не только их текущую производительность, то есть ту
производительность, которую мы смогли получить на тех данных, которые нам сейчас
доступны, но и ту производительность, которую они в перспективе способны
выдать, когда данных будет больше. Обычно, когда мы запускаем систему, у нас
ограниченный набор данных, а по мере работы системы новые данные появляются, у
нас появляется разметка, мы вычищаем наши данные и так далее и тому подобное. И мы
можем оценить так называемый learning curve, кривую обучения. Обучить нашу модель на
небольшом количестве примеров, допустим на четверти примеров, потом на половине,
потом на двух третьих и смотреть, как качество модели на трейне и тесте меняется.
И если качество модели на трейне и тесте неуклонно растет по мере увеличения
объема данных, то мы можем сделать обоснованное предположение о том, как оно
будет расти по мере появления новых данных. И возможно, что модель, которая
лучше прямо сейчас, будет сравнительно сильно хуже потом, когда данных будет
много. Это часто происходит, например, с нейронками.
 Обучая модели, выбирая
архитектуру, мы всегда делаем какой-то выбор, чтобы удовлетворить
многим существующим ограничениям. Выбор, например, между Precision и Recall.
Выбор между Precision и Recall - это фактически выбор между ошибками первого и
второго типа. Что нам важнее - чтобы среди тех, кому мы дали кредит,
было больше людей, способных его отдать, или чтобы среди тех людей, которые к нам
пришли, мы нашли больше кредитоспособных заемщиков? Это разные задачи, и одна из
них оптимизируется по Precision, а вторая по Recall. В медицине очень часто
оптимизируют модели под Recall, потому что нам, например, гораздо важнее поймать на
скрининге рак или туберкулез, пусть даже это окажется ложной тревогой, но не
хотелось бы его пропустить, потому что человек умрет. В промышленности, в
торговле, может быть, нам стоит упустить какой-нибудь потенциально
прибыльный вариант, потому что потери в случае ошибки будут очень большие.
Обучая модели, выбирая
архитектуру, мы всегда делаем какой-то выбор, чтобы удовлетворить
многим существующим ограничениям. Выбор, например, между Precision и Recall.
Выбор между Precision и Recall - это фактически выбор между ошибками первого и
второго типа. Что нам важнее - чтобы среди тех, кому мы дали кредит,
было больше людей, способных его отдать, или чтобы среди тех людей, которые к нам
пришли, мы нашли больше кредитоспособных заемщиков? Это разные задачи, и одна из
них оптимизируется по Precision, а вторая по Recall. В медицине очень часто
оптимизируют модели под Recall, потому что нам, например, гораздо важнее поймать на
скрининге рак или туберкулез, пусть даже это окажется ложной тревогой, но не
хотелось бы его пропустить, потому что человек умрет. В промышленности, в
торговле, может быть, нам стоит упустить какой-нибудь потенциально
прибыльный вариант, потому что потери в случае ошибки будут очень большие.
Следующий компромисс, с которым все время приходится работать - это качество против сложности развертывания, качество работы модели. Обычный вариант - это выбор между нейронками, градиентным бустингом и, например, логрегом, логистической регрессией. Если, конечно, такой выбор стоит, то логистическая регрессия деплоится очень просто, деревья и градиентные бустинги тоже деплоятся просто, в с нейронными сетями приходится повозиться.
Качество vs вычислительные ресурсы. Например, ну такой игрушечный пример: random forest считается сильно быстрее, чем catboost, но catboost дает чуть-чуть побольше качество. С чем мы готовы мириться? С медленным обучением или с потерей качества? На самом деле, конечно, на практике выбор между random forest и catboost не стоит, используйте всегда catboost, но стоит зато выбор между градиентным бустингом, который будет учиться, допустим, четыре часа, и нейронкой, которая будет учиться два дня.
Качество vs задержка инференса. Некоторые модели могут быть очень качественными, но медленными. Например, предположим, что мы хотим создать текстовое описание картинки. Мы можем взять image-to-text модель, которая генерирует текст по картинке - например, "человек в красной куртке стоит на снегу". Это будут описания высокого качества, мы можем удобно их использовать для поиска по картинкам, но они будут медленно генерироваться. Другой вариант - использовать YOLO, которое выделяет объекты на фотографии, и использовать ResNet для быстрой классификации этих объектов, например, до классификации, дообученной на наших картинках. Или сразу YOLO дообучить на наших картинках. Таким образом, мы можем с очень большой скоростью выдавать список объектов, которые есть на картинке, и, конечно, это не будет такой связный текст, как "человек в красной куртке стоит на снегу, глядя за горизонт". Но там будут ключевые слова - "человек", "куртка", "снег", и, может быть, нам для поиска этого и хватит. Зато это будет очень быстро.
Затем качество vs эксплуатационные издержки. Это очень частая история - когда мы разворачиваем нашу модель, нам приходится платить за хостинг. Мы можем развернуть нейронные сети - мы будем оплачивать GPU-сервера; мы можем развернуть, допустим, градиентный бустинг - и он, например, будет считаться на CPU. На самом деле, нейронки тоже могут считаться на CPU, но, допустим, NLP-шные модели на GPU считаются явно веселее. И стоимость эксплуатации этих моделей будет совершенно разная.
Качество vs устойчивость к атакам. Тут, опять же, сложные модели иногда можно просто обмануть. Многие сложные модели уязвимы к adversarial-атакам, когда мы можем добавить небольшой шум на картинку, в данный или в текст, и модель сменит свое решение на то, которое хотел от нас атакующий. А простые модели более устойчивы к ним. Также они более устойчивы к случайному шуму, и нам всегда нужно понимать, что нам важнее - качество или устойчивость, качество или эксплуатационные ресурсы.
 Каждая архитектура модели
делает какие-то предположения. Например, линейная регрессия. Ее предположения
просто проходят в университете - базовое предположение линейной регрессии,
гомоскедостичность и так далее. Но на практике их редко проверяют. Сверточные
сети предполагают локальность на картинке. Например, если у вас на картинке
сфотографировано яблоко, то точки яблока, они локальны, они расположены
рядом. Кроме всего прочего, сверточные сети предполагают инвариантность, яблоко
можно сдвинуть на 100 пикселов вправо или влево, и это все равно останется яблоком.
Каждая архитектура модели
делает какие-то предположения. Например, линейная регрессия. Ее предположения
просто проходят в университете - базовое предположение линейной регрессии,
гомоскедостичность и так далее. Но на практике их редко проверяют. Сверточные
сети предполагают локальность на картинке. Например, если у вас на картинке
сфотографировано яблоко, то точки яблока, они локальны, они расположены
рядом. Кроме всего прочего, сверточные сети предполагают инвариантность, яблоко
можно сдвинуть на 100 пикселов вправо или влево, и это все равно останется яблоком.
Другой вариант, прямо противоположный - люди пытались анализировать с помощью сверточных моделей зашифрованный текст, или генераторы случайных чисел. Но дело в том, что в генераторе случайных чисел локальности быть не должно. То есть две соседние точки на картинке, сгенерированные генератором случайных чисел - они должны быть не связаны между собой. Кстати, в картинках, сделанных плохими генераторами случайных чисел, появляются рисунки, полоски и так далее и тому подобное, но это скорее совсем уж такие детские ошибки при разработке генераторов случайных чисел.
Марковские модели предполагают, что процесс у нас без памяти.
Кластеризация предполагает, что в пространстве, в котором мы оцениваем взаимное расположение наших точек, есть метрика, и эту метрику можно сравнивать - есть локальность, есть понятие дистанции, и мы можем объединять точки, у которых дистанция между собой меньше, и разделять точки, у которых дистанция между собой больше. Предположение о метрике часто нарушается, когда кластеризацию делают поверх сложного снижения размерности. Например, если мы делаем линейное снижение размерности, например, PCA, principal component analysis, там можно считать, что метрика сохраняется, а в модели t-SNE, когда мы нелинейно преобразовываем наше пространство, у нас близко расположенные точки расположены близко, далеко расположенные точки у нас расположены далеко, но больше, кроме этого, у нас ничего нет. То, что одна точка чуть дальше, чем другая, ничего не говорит, и кластеризацию поверх t-SNE надо делать очень осторожно.
Меньше всего предположений о распределениях, о метриках и так далее делают алгоритмы на деревьях, но у каждой модели есть свои предположения и ограничения, надо их проверять.
 Итого, при выборе модели нам
нужно избегать модных моделей, начинать с самой простой, всегда делать
поправку на человеческие ошибки, пытаться предсказать, как
качество модели изменится в будущем и изучать ограничения предположения
модели.
Итого, при выборе модели нам
нужно избегать модных моделей, начинать с самой простой, всегда делать
поправку на человеческие ошибки, пытаться предсказать, как
качество модели изменится в будущем и изучать ограничения предположения
модели.
 Качество работы модели можно увеличить, собрав несколько моделей
вместе и объединив каким-нибудь способом их предсказания. Обычно это называют
стекингом, тут есть терминологическая путаница - что у нас стекинг, что у нас
блендинг и так далее и тому подобное. По ссылкам - некоторое разъяснение всего
этого. Популярные готовые ансамбли - это градиентный бустинг и случайный лес. Вы
можете, используя библиотеку scikit-learn и классы StackingClassifier и StackingRegressor
собрать из своих моделей, соответственно, ансамбли
классификаторов и регрессоров.
Качество работы модели можно увеличить, собрав несколько моделей
вместе и объединив каким-нибудь способом их предсказания. Обычно это называют
стекингом, тут есть терминологическая путаница - что у нас стекинг, что у нас
блендинг и так далее и тому подобное. По ссылкам - некоторое разъяснение всего
этого. Популярные готовые ансамбли - это градиентный бустинг и случайный лес. Вы
можете, используя библиотеку scikit-learn и классы StackingClassifier и StackingRegressor
собрать из своих моделей, соответственно, ансамбли
классификаторов и регрессоров.
Тут почти всегда не имеет смысла ансамблировать слабые алгоритмы. Это, кстати, популярная ошибка на kaggle - когда учат много слабых и сильных моделей, а потом собирают их в кучу. Качество получившейся модели хуже, чем качество одной из самых сильных моделей. Не имеет смысла ансамблировать сильно скоррелированные алгоритмы, потому что они ошибаются одинаково, и от того, что вы их ансамблируете, собираете в кучу, ваша ошибка не уменьшится. Тут есть интересное исключение - это алгоритмы weak supervision типа Snorkel, когда мы строим очень много очень слабых и иногда скоррелированных алгоритмов, и все равно они работают хорошо.
 Пример про ансамблирование независимых алгоритмов.
Предположим, что у нас есть три алгоритма A, B и C, и вероятность ошибки каждого 30%.
Ошибки независимы в том смысле, что ошибка алгоритма A и ошибка
алгоритма B статистически независимы, как вероятности. Мы можем ансамблировать
алгоритмы большинством, то есть voting classifier: если у нас три или два
алгоритма сказали да - значит да, если три или два
алгоритма сказали нет - значит нет. Вероятность одновременной ошибки у нас
чуть меньше 3%. Вероятность ошибки двумя алгоритмами у нас примерно
19%. Итого, вероятность ошибки тремя или двумя алгоритмами у нас
примерно 22%. То есть мы повышаем качество работы нашей модели на 8%, есть выигрыш от ансамблирования.
Пример про ансамблирование независимых алгоритмов.
Предположим, что у нас есть три алгоритма A, B и C, и вероятность ошибки каждого 30%.
Ошибки независимы в том смысле, что ошибка алгоритма A и ошибка
алгоритма B статистически независимы, как вероятности. Мы можем ансамблировать
алгоритмы большинством, то есть voting classifier: если у нас три или два
алгоритма сказали да - значит да, если три или два
алгоритма сказали нет - значит нет. Вероятность одновременной ошибки у нас
чуть меньше 3%. Вероятность ошибки двумя алгоритмами у нас примерно
19%. Итого, вероятность ошибки тремя или двумя алгоритмами у нас
примерно 22%. То есть мы повышаем качество работы нашей модели на 8%, есть выигрыш от ансамблирования.
 Если алгоритмы
зависимы, ну, крайние случаи алгоритмов A, B и C, у них вероятность ошибки
одинаковая. И ошибки полностью скоррелированы, полностью синхронны. Мы
ансамблируем большинством, voting classifier, и вероятность ошибки у нас остается
ровно такая же, как и была - выигрыша от ансамблирования нет.
Если алгоритмы
зависимы, ну, крайние случаи алгоритмов A, B и C, у них вероятность ошибки
одинаковая. И ошибки полностью скоррелированы, полностью синхронны. Мы
ансамблируем большинством, voting classifier, и вероятность ошибки у нас остается
ровно такая же, как и была - выигрыша от ансамблирования нет.
 Но может быть и хуже.
Предположим, что у нас есть независимые слабые алгоритмы A, B и C,
вероятности ошибки 30, 40 и 45%. Ошибки независимы. Мы ансамблируем
большинством, voting classifier, я тут не привожу расчет, но вероятность ошибки
получается примерно 33 процента, то есть хуже, чем алгоритм A в одиночку.
Но может быть и хуже.
Предположим, что у нас есть независимые слабые алгоритмы A, B и C,
вероятности ошибки 30, 40 и 45%. Ошибки независимы. Мы ансамблируем
большинством, voting classifier, я тут не привожу расчет, но вероятность ошибки
получается примерно 33 процента, то есть хуже, чем алгоритм A в одиночку.
 Ансамбли из слабых алгоритмов на практике используются часто. Например,
ансамбли на деревьях, есть такая разновидность ансамблей на деревьях -
решающие пни. Пример решающего пня - это random forest с глубиной дерева 1. Мы имеем
кучу деревьев решений, состоящих ровно из одного if, и они работают хорошо.
Почему они работают хорошо, если это очень слабые алгоритмы? Мы специальным
образом боремся с корреляцией ошибки, то есть мы строим эти решающие деревья на
подвыборках строк, на подвыборках столбцов, и у нас на самом-то деле большой
ансамбль и качество их примерно равное. Ну и про weak supervision в Snorkel я уже
говорил, там это достигается другим способом. Там лернеры, слабые алгоритмы,
дают ответы трех видов - "да", "нет" и "не знаю". И если выкинуть ответы "не знаю", то в тех
ответах, где он дал "да" или "нет", это сильный алгоритм. Таким образом
ансамблировать их имеет смысл, потому что явным образом слабый алгоритм сказал -
"а вот здесь вот меня не учитывать".
Ансамбли из слабых алгоритмов на практике используются часто. Например,
ансамбли на деревьях, есть такая разновидность ансамблей на деревьях -
решающие пни. Пример решающего пня - это random forest с глубиной дерева 1. Мы имеем
кучу деревьев решений, состоящих ровно из одного if, и они работают хорошо.
Почему они работают хорошо, если это очень слабые алгоритмы? Мы специальным
образом боремся с корреляцией ошибки, то есть мы строим эти решающие деревья на
подвыборках строк, на подвыборках столбцов, и у нас на самом-то деле большой
ансамбль и качество их примерно равное. Ну и про weak supervision в Snorkel я уже
говорил, там это достигается другим способом. Там лернеры, слабые алгоритмы,
дают ответы трех видов - "да", "нет" и "не знаю". И если выкинуть ответы "не знаю", то в тех
ответах, где он дал "да" или "нет", это сильный алгоритм. Таким образом
ансамблировать их имеет смысл, потому что явным образом слабый алгоритм сказал -
"а вот здесь вот меня не учитывать".
Имеет смысл ансамблировать сильный и слабый алгоритмы с разной структурой ошибки. Например, очень популярное решение - когда мы применяем градиентный бустинг к временным рядам после того, как предсказали этот ряд регрессией или какой-нибудь, например, ARIMA. То есть мы с помощью градиентного бустинга исправляем ошибки предсказания линейной модели. Это работает, потому что структура ошибки у них совершенно разная.
 Когда мы выбираем модель, нам очень важно отслеживать
эксперименты. Нам нужно проверить много гипотез обычно, может быть, сотни.
У нас будут меняться модели, меняться признаки, сами по себе данные будут
меняться и еще очень часто при разных запусках модели мы будем получать
разное качество. С этим надо бороться, но у нейронных сетей иногда этого очень
трудно избежать. То есть вы учите нейронную сеть и получаете разные
нейронные сети на тех же самых данных и даже на том же самом random seed. Так бывает.
Когда мы выбираем модель, нам очень важно отслеживать
эксперименты. Нам нужно проверить много гипотез обычно, может быть, сотни.
У нас будут меняться модели, меняться признаки, сами по себе данные будут
меняться и еще очень часто при разных запусках модели мы будем получать
разное качество. С этим надо бороться, но у нейронных сетей иногда этого очень
трудно избежать. То есть вы учите нейронную сеть и получаете разные
нейронные сети на тех же самых данных и даже на том же самом random seed. Так бывает.
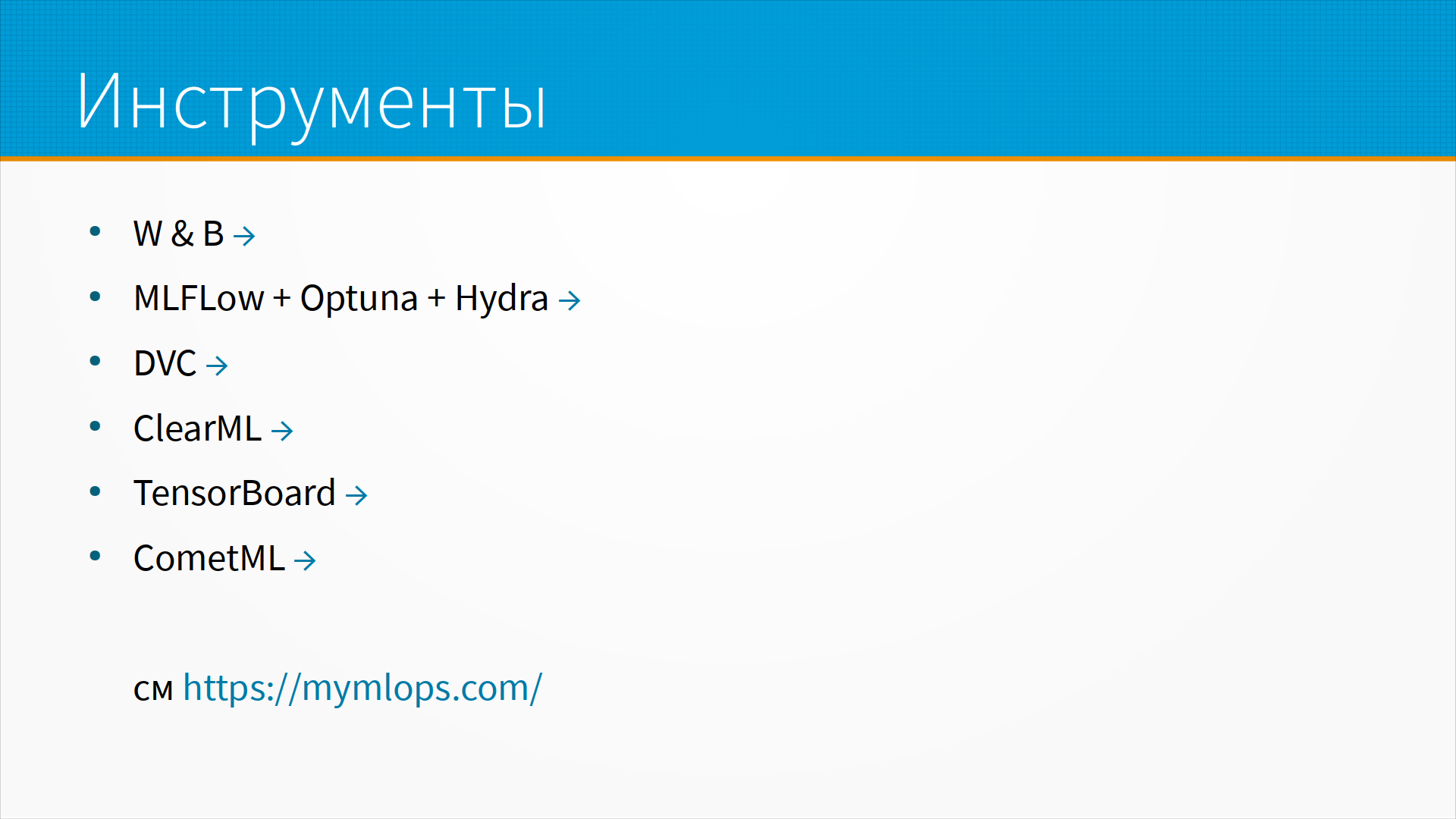 Для отслеживания процесса обучения модели есть набор хороших инструментов, и
лучший из них - это Weights and Biases. Он, к сожалению, очень платный. То есть не
просто платный, а очень платный. Но для личного использования он бесплатный, его
можно использовать. Есть хороший открытый набор инструментов
MLFlow, в котором можно добавить, например, Optuna для подбора гиперпараметров и
Hydra для перебора и хранения конфигураций экспериментов. По ссылке есть
хороший пример, как это делать.
Для отслеживания процесса обучения модели есть набор хороших инструментов, и
лучший из них - это Weights and Biases. Он, к сожалению, очень платный. То есть не
просто платный, а очень платный. Но для личного использования он бесплатный, его
можно использовать. Есть хороший открытый набор инструментов
MLFlow, в котором можно добавить, например, Optuna для подбора гиперпараметров и
Hydra для перебора и хранения конфигураций экспериментов. По ссылке есть
хороший пример, как это делать.
Инструменты для отслеживания версионирования моделей есть в DVC. DVC тем хорош, что он сохраняет слепки данных вместе с вашим пайплайном обучением модели. Это иногда очень хорошо, особенно когда данные маленькие. Вы их поучили и над ними экспериментируете. Когда данные идут к вам потоком и когда данные не помещаются к вам на компьютер, DVC использовать сложнее. Но и там можно, потому что, как правило, мы выполняем какую-то предобработку, и вот результат этой предобработки мы можем сохранять в системе контроля версии.
Инструменты ClearML и CometML позволяют отслеживать обучение модели. TensorBoard - это очень удобный бесплатный инструмент, который позволяет вам передавать из модели разную статистику во время обучения, и делиться ей, и отслеживать. Есть сайт mymlops.com, где для каждого этапа работы с моделями собраны примеры инструментов, которые можно использовать. Такой конструктор - собери свой MLOps пайплайн.
 Важная часть
работы с нейронками - это как распределить обучение, чтобы оно шло быстрее. Вы
можете раздобыть несколько GPU и учить модель на них. Есть хорошие библиотеки,
которые позволяют распараллелить обучение для нейронных сетей - это Accelerate
и DeepSpeed. Есть библиотеки, позволяющие распараллелить вычисления, такие
библиотеки общего назначения, например, Ray. DaskML - это набор
библиотек для распределенного обучения на основе Dask. Dask и Ray - очень
похожие подходы, там есть тонкое различие, но, в общем, на практике можно
пользоваться и тем, и другим. Я бы сказал, что Dask - это больше
распараллеленный Pandas, а Ray - это больше распараллеленное вычисление общего
назначения. На самом-то деле у Dask есть scheduler общего назначения, а у Ray есть
коннекторы, позволяющие параллелить наше вычисление над Pandas, поэтому они
более-менее взаимозаменяемы. На обоих этих библиотеках построены стартапы, в
которых можно брать облачные ресурсы в аренду. Ну, и Ray, и Dask можно
запускать на своих мощностях и даже на одном компьютере.
Важная часть
работы с нейронками - это как распределить обучение, чтобы оно шло быстрее. Вы
можете раздобыть несколько GPU и учить модель на них. Есть хорошие библиотеки,
которые позволяют распараллелить обучение для нейронных сетей - это Accelerate
и DeepSpeed. Есть библиотеки, позволяющие распараллелить вычисления, такие
библиотеки общего назначения, например, Ray. DaskML - это набор
библиотек для распределенного обучения на основе Dask. Dask и Ray - очень
похожие подходы, там есть тонкое различие, но, в общем, на практике можно
пользоваться и тем, и другим. Я бы сказал, что Dask - это больше
распараллеленный Pandas, а Ray - это больше распараллеленное вычисление общего
назначения. На самом-то деле у Dask есть scheduler общего назначения, а у Ray есть
коннекторы, позволяющие параллелить наше вычисление над Pandas, поэтому они
более-менее взаимозаменяемы. На обоих этих библиотеках построены стартапы, в
которых можно брать облачные ресурсы в аренду. Ну, и Ray, и Dask можно
запускать на своих мощностях и даже на одном компьютере.
 При обучении модели нам
приходится подбирать гиперпараметры. Тут у нас есть набор хороших инструментов
Optuna и Hyperopt - это байесовские оптимизаторы, и TPOT - оптимизатор на основе генетических
алгоритмов. Обычно подбор гиперпараметров не относят к AutoML, но я тут
привел вместе и библиотеки для подбора гиперпараметров, и библиотеки
AutoML, потому что разница между ними стирается. Auto-PyTorch - это библиотека,
которая позволяет вам построить модель на основе PyTorch автоматически,
придумав все нужные части, подобрав. Auto-sklearn берет алгоритмы из
библиотеки scikit-learn и строит из них на основе ваших данных пайплайн, который
лучше будет решать вашу задачу. И AutoML Book - это хороший твердый такой рассказ о
том, как оно бывает. У них есть своя библиотека, но заодно они очень подробно
рассказали, что вообще есть в этом мире AutoML.
При обучении модели нам
приходится подбирать гиперпараметры. Тут у нас есть набор хороших инструментов
Optuna и Hyperopt - это байесовские оптимизаторы, и TPOT - оптимизатор на основе генетических
алгоритмов. Обычно подбор гиперпараметров не относят к AutoML, но я тут
привел вместе и библиотеки для подбора гиперпараметров, и библиотеки
AutoML, потому что разница между ними стирается. Auto-PyTorch - это библиотека,
которая позволяет вам построить модель на основе PyTorch автоматически,
придумав все нужные части, подобрав. Auto-sklearn берет алгоритмы из
библиотеки scikit-learn и строит из них на основе ваших данных пайплайн, который
лучше будет решать вашу задачу. И AutoML Book - это хороший твердый такой рассказ о
том, как оно бывает. У них есть своя библиотека, но заодно они очень подробно
рассказали, что вообще есть в этом мире AutoML.
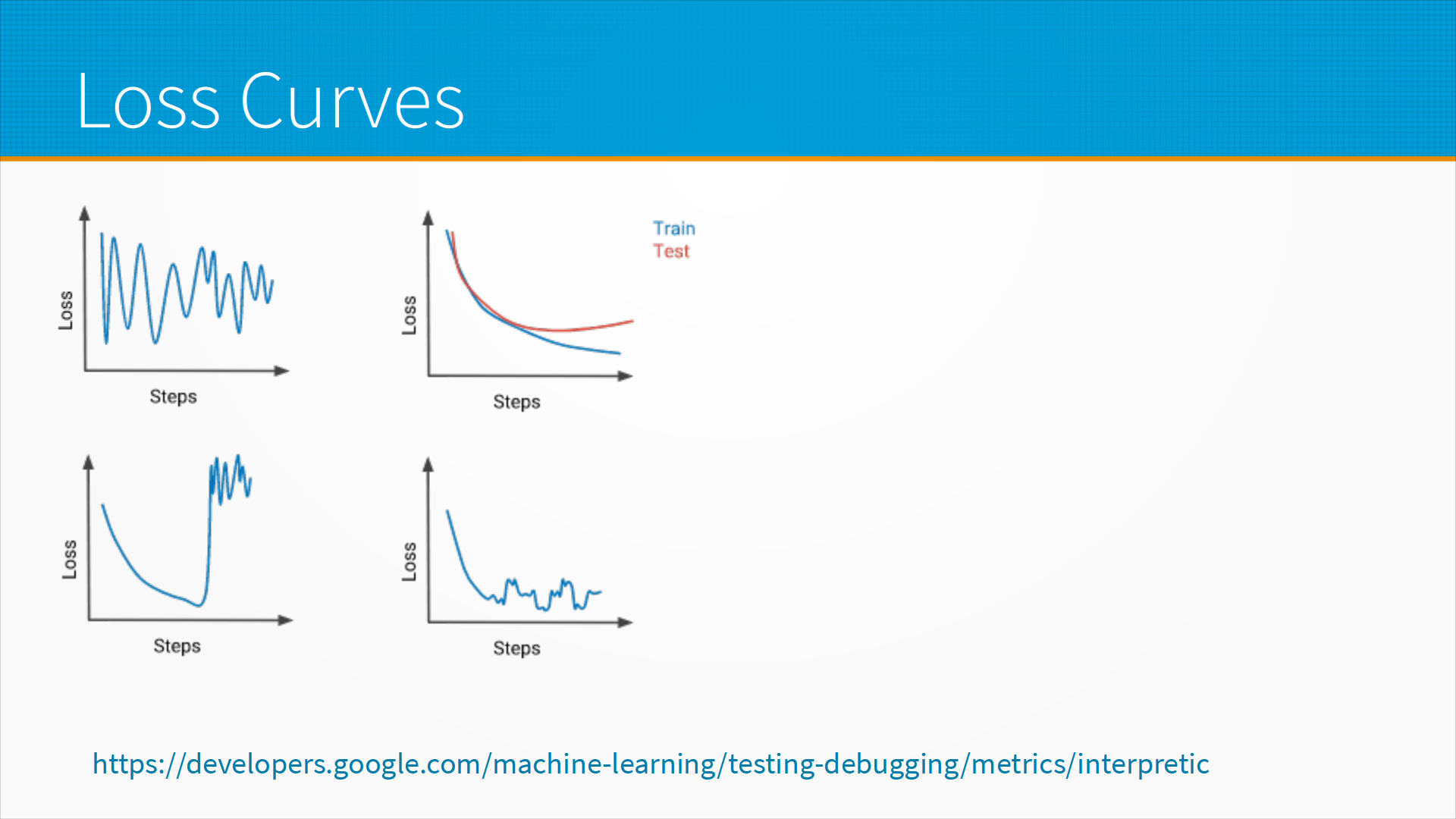 При обучении модели важный
диагностический инструмент - это график функции потерь. По мере того, как модель
учится, график функции потерь может либо монотонно убывать, если нам повезло,
либо как-нибудь скакать, если нам не повезло, либо увеличиваться бесконечно
много, если нам не повезло совсем. Что это все означает?
При обучении модели важный
диагностический инструмент - это график функции потерь. По мере того, как модель
учится, график функции потерь может либо монотонно убывать, если нам повезло,
либо как-нибудь скакать, если нам не повезло, либо увеличиваться бесконечно
много, если нам не повезло совсем. Что это все означает?
Обычно, если график прыгает вверх и вниз, это говорит о том, что у нас просто слишком большой learning rate, например, или плохой оптимизатор, который не умеет работать в этих условиях. Большинство оптимизаторов содержат настройки по поводу learning rate, инерции и так далее и тому подобное, то, что называется momentum. Там нужно покрутить эти настройки. Обычно они работают из коробки, но надо смотреть по месту.
Ситуация, нарисованная на левом нижнем графике - это когда у нас произошел так называемый взрыв градиентов, то есть модель вычислительно нестабильна. Обычно это из-за большого learning rate, но может быть и по другим причинам. Тут надо попробовать снизить learning rate, например, в три раза или на порядок и посмотреть, как оно будет.
Идеальная модель - справа вверху. Мы видим, что train у нас все время падает, а test с какого-то момента начинает расти. Вот тут обычно говорят - мы переобучили модель, нам нужно учить ее меньше. Но практика на самом деле показывает, что в этот момент надо успокоиться, пойти выпить кофе и дать модели поработать еще как минимум в 10 раз столько, сколько ей понадобилось для того, чтобы дойти до оптимальной точки, где качество на train и test начали расходиться. Это так называемый двойной спуск. Очень часто бывает, что если подождать, то модель сначала снова начнет падать качество на тесте, а потом она упадет еще ниже, чем была вот в этом первом оптимуме. Про двойной спуск есть много интересных специальных статей, но у нас тут, к сожалению, курс не про машинное обучение, а про модели. Поэтому если вы увидели, что ваша модель как бы переобучилась, не пугайтесь - попробуйте поучить ее дальше.
И последний вариант - в правом нижнем углу, когда модель вроде бы как у нас училась, а затем начала странно прыгать в качестве. Обычно это говорит о том, что у вас плохо отсортированные примеры в батчах. Например, если вы учите модель различать кошечек от собачек, а у вас один батч состоит целиком из кошечек, другой батч целиком из собачек - тут надо следить за сэмплированием.
 Что, если ваша модель не
работает? Первое, что нужно сделать с нейронными сетями, если они не работают -
это попробовать переобучиться на микродатасете. То есть, предположим, что у
нас есть датасет ровно из трех картинок разных классов. Наша нейронная сеть
должна быть в состоянии запомнить этот датасет. И если у нас не получается
доучиться до нулевого лосса - что-то странно, что-то не так с моделью.
Что, если ваша модель не
работает? Первое, что нужно сделать с нейронными сетями, если они не работают -
это попробовать переобучиться на микродатасете. То есть, предположим, что у
нас есть датасет ровно из трех картинок разных классов. Наша нейронная сеть
должна быть в состоянии запомнить этот датасет. И если у нас не получается
доучиться до нулевого лосса - что-то странно, что-то не так с моделью.
А другая частая проблема - когда портируют модели из TensorFlow в PyTorch и обратно, а у них разная размерность батчей. То есть у них в этих четырех размерностях две размерности стоят не на привычном месте, и многие люди делают эту ошибку. Надо визуализировать градиенты, чтобы смотреть, что с ними происходит. Искать взрыв градиентов или затухание градиентов при обучении. Если модель не учится, всегда имеет смысл увеличить или уменьшить на порядок скорость обучения. Посмотреть, как она будет учиться.
Еще может получиться так, что ваша модель учится, просто она делает это очень медленно. Ну, например, потому что задача сложная. И тут хорошо взять пять процентов данных и попробовать обучить модель на них. Посмотреть, как она будет учиться и как она будет себя вести. Ну и, как я уже говорил, просто дать модели поработать побольше.
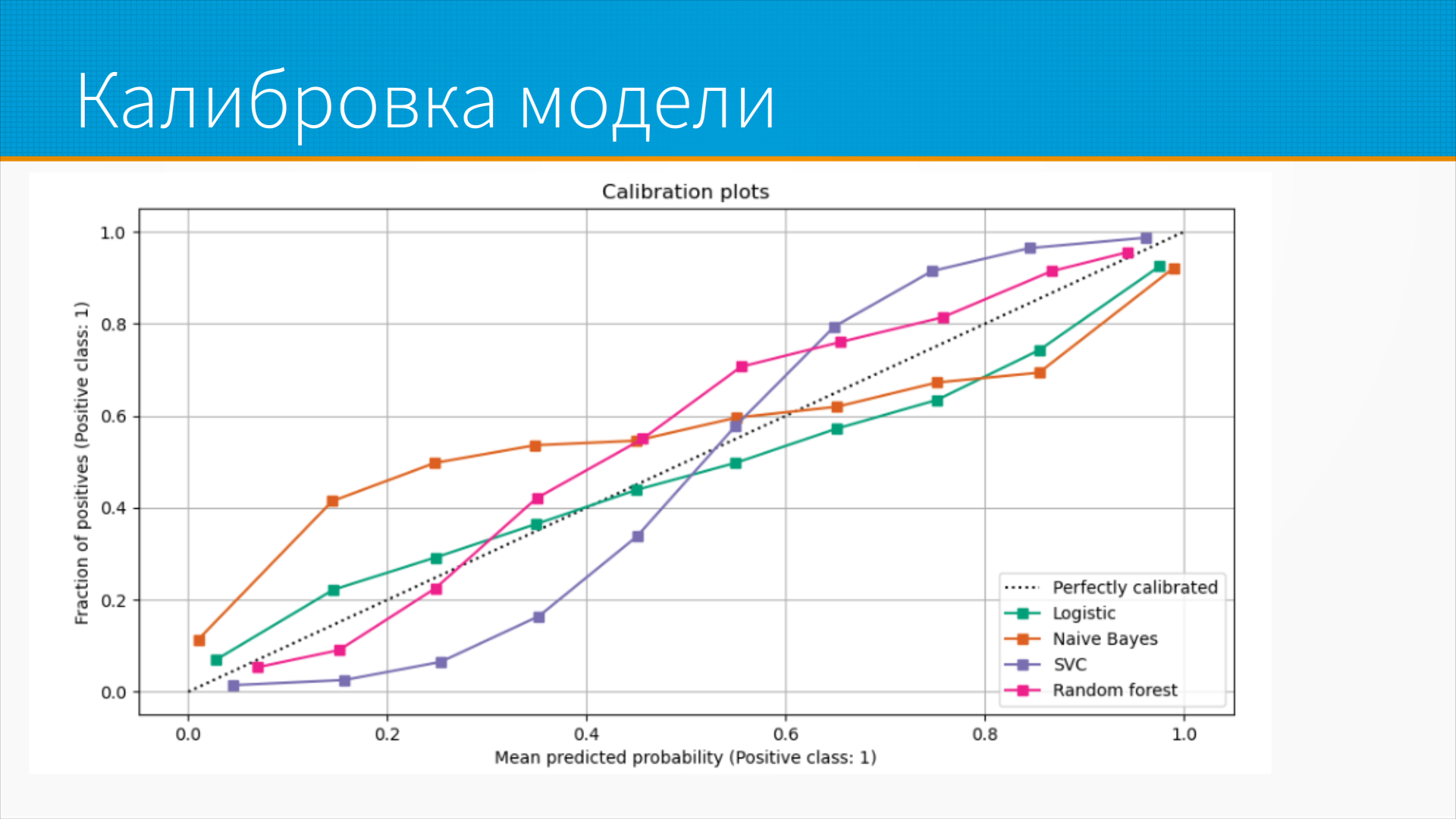 С калибровкой модели это отдельная история.
О чем это? Когда мы делаем классификатор, он нам выдает какое-то предсказание от
нуля до единицы о том, допустим, есть ли на фотографии объект нужного класса. Очень
легко совершить ошибку - интерпретировать это значение от нуля до единицы, как
вероятность. То есть нулевая вероятность, что тут есть объект, или
стопроцентная вероятность, что тут есть объект.
С калибровкой модели это отдельная история.
О чем это? Когда мы делаем классификатор, он нам выдает какое-то предсказание от
нуля до единицы о том, допустим, есть ли на фотографии объект нужного класса. Очень
легко совершить ошибку - интерпретировать это значение от нуля до единицы, как
вероятность. То есть нулевая вероятность, что тут есть объект, или
стопроцентная вероятность, что тут есть объект.
А на самом-то деле модели, особенно нейронные сети к этому склонны, они выдают некалиброванные вероятности. То есть они обычно очень уверены в своих предсказаниях. То есть, если, например, из данных следует, что тут, скорее всего, на картинке нет яблока, модель скажет - ну, вероятность яблока, допустим, 0,01. А если, может быть, есть яблоко, а может и нет, модель скажет - ну, вероятность, что тут есть яблоко, 0,7. А если есть, она скажет - 0,99. То есть модели в принципе переобучаются к более категоричным предсказаниям. С этим можно бороться, но самый простой способ - это брать предсказания моделей и калибровать их. Делать так, чтобы, уж если модель предсказала вероятность 0,6, то именно на 60% тех, кому она предсказала, что на картинке есть яблоко, было действительно яблоко. Делается это через специальную процедуру калибровки модели, когда мы откладываем часть наших данных и потом на них проверяем скалиброванность.
 Для калибровки есть модели в scikit-learn, CalibratedClassifierCV. Для моделей на деревьях обычно используют
Calibration Trees. Тут идея простая. Мы строим дерево решения, которое
предсказывает нам, где находится какая точка в данных, а затем мы используем номера
листов этого дерева как признаки для логистической регрессии, и ей уже мы
предсказываем нашу вероятность. Мы калибруем ей нашу модель. Звучит, может быть,
сложно, но пишется руками в 10 строк, и вот по ссылке есть описание.
Для калибровки есть модели в scikit-learn, CalibratedClassifierCV. Для моделей на деревьях обычно используют
Calibration Trees. Тут идея простая. Мы строим дерево решения, которое
предсказывает нам, где находится какая точка в данных, а затем мы используем номера
листов этого дерева как признаки для логистической регрессии, и ей уже мы
предсказываем нашу вероятность. Мы калибруем ей нашу модель. Звучит, может быть,
сложно, но пишется руками в 10 строк, и вот по ссылке есть описание.
И для нейронных сетей самый хороший вариант их калибровки - это использовать softmax с температурой. То есть, как правило, на выходе классификатора стоит softmax - функция, которая приводит сумму вероятности к единице, повышает вероятность самого вероятного класса и снижает вероятность менее вероятного класса. И вот в эту формулу вычисления softmax можно добавить константу, так называемую температуру, которая сделает решение модели более или менее категоричными.
Ну и, кстати, есть такая городская легенда, что логистическая регрессия не требует калибровки, что она выдает откалиброванные вероятности. На самом деле нет. Все модели отдают некалиброванные вероятности, просто логистическая регрессия теоретически тут должна была быть гораздо лучше.
 А еще, вне всякой связи с предыдущим, попробуйте
Lightning. Lightning это библиотека, позволяющая упростить весь цикл обучения,
тренировки, инференсы моделей. Мне очень нравится.
А еще, вне всякой связи с предыдущим, попробуйте
Lightning. Lightning это библиотека, позволяющая упростить весь цикл обучения,
тренировки, инференсы моделей. Мне очень нравится.
 Дополнительные материалы:
Дополнительные материалы: