
- 17.10.2022
- 05.10.2025
- обучение
- #mlsystemdesign
Четвертая лекция открытого курса "Дизайн систем машинного обучения", "Подготовка и отбор признаков".
Слайды можно скачать тут mlsysd4ods.pdf
Текстовая расшифровка:
 Всем привет! У нас сегодня четвертая лекция - подготовка и отбор признаков.
Всем привет! У нас сегодня четвертая лекция - подготовка и отбор признаков.
 Мы прошли первые три темы и только сейчас подбираемся непосредственно к работе с моделью, к обучению ее.
Мы прошли первые три темы и только сейчас подбираемся непосредственно к работе с моделью, к обучению ее.
 Что такое подготовка данных?
Подготовка данных - это обработка входящей информации так, чтобы алгоритму было проще учиться.
В большинстве случаев нейронные сети могут и сами выучить нужные нам признаки,
но, если мы сделаем данные более удобными для нашего алгоритма, он будет учиться лучше.
Что такое подготовка данных?
Подготовка данных - это обработка входящей информации так, чтобы алгоритму было проще учиться.
В большинстве случаев нейронные сети могут и сами выучить нужные нам признаки,
но, если мы сделаем данные более удобными для нашего алгоритма, он будет учиться лучше.
Ну и как мы можем сделать их удобнее? Во-первых, конечно, мы можем дополнить наши данные, аугментируя их, расширяя наш датасет. Во-вторых, можно сгенерировать синтетические данные, искусственные. В данных много мусора, и мы можем их чистить, это всегда окупается. Данные требуют нормализации, преобразований. Мы можем конструировать признаки, затем отбирать хорошие признаки и выкидывать неудачные. Сейчас мы кратко пробежимся по данным темам.
 Аугментация данных, формально ее обычно не относят к генерации признаков,
но это, наверное, самое главное, что можно сделать с признаками в нейронной сети.
Когда мы обучаем нашу нейронную сеть, мы, допустим, фотографируем какие-то предметы
при одном освещении; а при эксплуатации нейронной сети у нас камера будет в других условиях, будет другой свет.
Нам нужно, чтобы наш алгоритм умел работать с данными, полученными в разных условиях.
И еще у нас может быть, допустим, не так много фотографий одного вида.
Аугментация данных, формально ее обычно не относят к генерации признаков,
но это, наверное, самое главное, что можно сделать с признаками в нейронной сети.
Когда мы обучаем нашу нейронную сеть, мы, допустим, фотографируем какие-то предметы
при одном освещении; а при эксплуатации нейронной сети у нас камера будет в других условиях, будет другой свет.
Нам нужно, чтобы наш алгоритм умел работать с данными, полученными в разных условиях.
И еще у нас может быть, допустим, не так много фотографий одного вида.
И обычно при обучении нейронной сети делают так называемую аугментацию. Выполняют преобразование изображений, меняют цвет, обрезают, случайно сдвигают ее, трансформируют, добавляют какой-нибудь шум, иногда переворачивают и отражают. И из одной картинки мы можем получить таким образом 16, 20, иногда 40 картинок. Мы можем увеличить наш датасет и в некотором смысле адаптировать его к сдвигу данных. Например, если мы знаем, что нам предстоит оценивать картинки с черно-белой камерой - например, у нас будет съемки с камеры систем безопасности, а наш датасет цветной, то мы можем выбрать то преобразование, которое наши картинки преобразует в черно-белый и позволит нам учиться лучше.
Аугментация данных выполняется как во время обучения, так и во время предсказания, так называемый TTA, Test Time Augmentation.
 Обычно об аугментации мы как думаем?
Что мы во время обучения случайно картинки отмасштабируем, перекрасим, изменим, и на этом обучим нашу модель.
Во время предсказаний мы тоже можем взять нашу картинку, по поводу которой нам нужно сделать предсказание,
сделать над ней эти преобразования, над каждой из преобразованных картинок сделать предсказание
и, например, большинством голосом выбрать, что же мы будем предсказывать на этой картинке.
Обычно об аугментации мы как думаем?
Что мы во время обучения случайно картинки отмасштабируем, перекрасим, изменим, и на этом обучим нашу модель.
Во время предсказаний мы тоже можем взять нашу картинку, по поводу которой нам нужно сделать предсказание,
сделать над ней эти преобразования, над каждой из преобразованных картинок сделать предсказание
и, например, большинством голосом выбрать, что же мы будем предсказывать на этой картинке.
Это хорошо помогает, когда, например, целевой объект занимает только часть картинки, а наша нейронная сеть ждет картинку квадратную. И тогда, если мы обрезаем картинку, например, посередине, то важная часть нашего объекта, например, голова у человека, может просто не попасть на картинку. Сдвигая картинку и обрезая ее случайным образом, random resize and crop, мы повышаем точность работы модели.
И, кроме всего прочего, Test Time Augmentation увеличивает устойчивость к сдвигу данных. Если мы вдруг выяснили, что нашей модели предстоит работать в других условиях, мы можем не переучивать модель, а только изменить модуль TTA, который адаптирует данные для предсказания к тому виду, в каком были данные, когда мы на них учились.
Как делается аугментация? В картинках, где чаще всего применяют аугментацию, выполняют преобразования симметричные, такие как поворот, вращение, обрезку, разные искажения цветовые - изменение насыщенности цвета, изменение яркости, контрастности. Аугментируют звук - добавляют шум, замедляют или ускоряют его. Текст аугментируют, например, переводом на другой язык и обратно - двойным переводом. Заменой синонимов, добавлением шума, случайным удалением слов, перестановкой слов. Как правило, мы не теряем смысла фразы, если пара слов или пара утверждений в ней переставлены местами - и нужно проверять, что модель тоже не теряет смысл фразы.
В табличных данных аугментацию применяют реже, но в табличных данных типичный пример аугментации - это сэмплирование с возвращением, например. То есть, когда у нас каких-то строчек данных мало, мы можем насэмплировать их с возвращением. Еще есть сложные алгоритмы сэмплирования - автоэнкодер, добавление шума в табличные данные. Шум, кстати, в табличные данные добавляют также в рамках сохранения приватности, так называемой дифференциальной приватности, но об этом мы будем в другой лекции говорить.
 Для аугментации есть хорошие библиотеки. Прежде всего это Albumentation.
Albumentation обычно применяют для картинок, но вообще-то это библиотека аугментации общего назначения.
Вы точно так же можете сделать модули для использования Albumentation с текстовыми данными или с чем-то другим.
Много kaggle-соревнований выиграно с помощью Albumentation, и у них есть стартап, в котором они это развивают.
Вообще библиотека интересная, сделанная несколькими kaggle-мастерами.
NLPAUG это библиотека для аугментации и расширения текстовых датасетов.
Здесь расширение на основе каких-то простых правил, то есть вы заменяете по правилам в тексте слова, например, на их синонимы.
Библиотека EDA - библиотека с аугментацией нейронными сетями.
DTA - библиотека аугментации для табличных данных.
Обычно считается, что с табличными данными нельзя делать аугментацию, так вот с DTA вы аугментацию делать сможете.
Torchaudio это библиотека аугментации для аудио, наложения шума и так далее.
Audiomentation - это вообще хорошая коллекция для аугментации аудио данных.
SpeсAugment аугментация для распознавания речи.
Для аугментации есть хорошие библиотеки. Прежде всего это Albumentation.
Albumentation обычно применяют для картинок, но вообще-то это библиотека аугментации общего назначения.
Вы точно так же можете сделать модули для использования Albumentation с текстовыми данными или с чем-то другим.
Много kaggle-соревнований выиграно с помощью Albumentation, и у них есть стартап, в котором они это развивают.
Вообще библиотека интересная, сделанная несколькими kaggle-мастерами.
NLPAUG это библиотека для аугментации и расширения текстовых датасетов.
Здесь расширение на основе каких-то простых правил, то есть вы заменяете по правилам в тексте слова, например, на их синонимы.
Библиотека EDA - библиотека с аугментацией нейронными сетями.
DTA - библиотека аугментации для табличных данных.
Обычно считается, что с табличными данными нельзя делать аугментацию, так вот с DTA вы аугментацию делать сможете.
Torchaudio это библиотека аугментации для аудио, наложения шума и так далее.
Audiomentation - это вообще хорошая коллекция для аугментации аудио данных.
SpeсAugment аугментация для распознавания речи.
 Во многих случаях единственным способом собрать датасет является генерация его в виртуальной реальности.
Так, например, можно проверять какие-то вещи, которые в реальности проверять опасно.
Например, снимать действия операторов, правильные и неправильные, на опасном производстве.
Какие-нибудь отладку поведения пешеходов и автомобилей виртуальной реальности.
У меня есть знакомые, которые делали проект, показывающий работнику на конвейере, в каком порядке ему нужно собирать детали.
То есть у него надеты очки дополненной реальности и ему подсвечивают, какую конкретно деталь и какой стороной нужно надевать на штырь какой-нибудь или крепежное место.
Они собирали компрессоры для КамАЗа - и вот они создали 3D модель этого самого компрессора, 3D картинку конвейера, фотографии деталей раскидали на этом конвейере, добавили какого-то мусора, шума. В этой смоделированной реальности они делали фотографии и учили на них модель.
Получилось вроде хорошо.
В тех случаях, когда вам нужно произвести какие-нибудь вещи, которые сложно собрать,
например, позу человека или что-то еще, вы можете просто в Unity создать фигуру человека, заставить его по сценарию выполнить что-то и учить вашу модель машинного обучения на этих изображениях.
Например Unity предлагает использовать их библиотеки для создания датасетов в дополненной реальности.
Во многих случаях единственным способом собрать датасет является генерация его в виртуальной реальности.
Так, например, можно проверять какие-то вещи, которые в реальности проверять опасно.
Например, снимать действия операторов, правильные и неправильные, на опасном производстве.
Какие-нибудь отладку поведения пешеходов и автомобилей виртуальной реальности.
У меня есть знакомые, которые делали проект, показывающий работнику на конвейере, в каком порядке ему нужно собирать детали.
То есть у него надеты очки дополненной реальности и ему подсвечивают, какую конкретно деталь и какой стороной нужно надевать на штырь какой-нибудь или крепежное место.
Они собирали компрессоры для КамАЗа - и вот они создали 3D модель этого самого компрессора, 3D картинку конвейера, фотографии деталей раскидали на этом конвейере, добавили какого-то мусора, шума. В этой смоделированной реальности они делали фотографии и учили на них модель.
Получилось вроде хорошо.
В тех случаях, когда вам нужно произвести какие-нибудь вещи, которые сложно собрать,
например, позу человека или что-то еще, вы можете просто в Unity создать фигуру человека, заставить его по сценарию выполнить что-то и учить вашу модель машинного обучения на этих изображениях.
Например Unity предлагает использовать их библиотеки для создания датасетов в дополненной реальности.
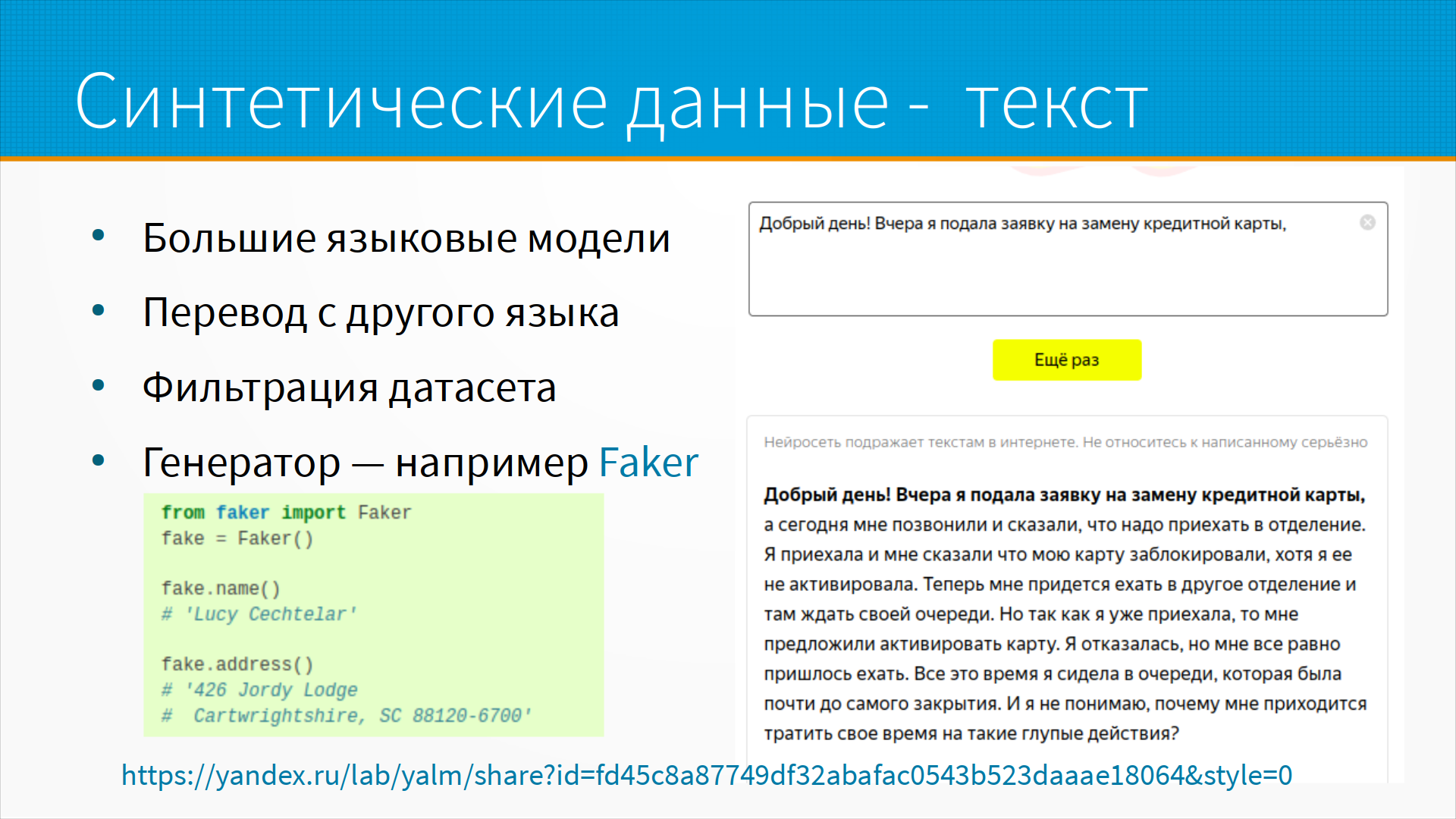 Про синтетические данные для текста.
В большинстве случаев, когда мы учим какие-то сложные текстовые модели, у нас очень не хватает некоторых классов данных.
То есть у нас почти всегда какой-нибудь дисбаланс, есть какие-нибудь редкие примеры, по которым нам удалось собрать мало текста.
Вот тут мы можем воспользоваться дополнением и синтетическими данными для текста.
Самый очевидный вариант, возможность которой появилась недавно - это большие языковые модели.
Есть большая модель Яндекса, например, и вы можете дать нужный вам кусок и она допишет его правдоподобным текстом.
Например сгенерируем с помощью LLM текст про замену кредитной карты.
Про синтетические данные для текста.
В большинстве случаев, когда мы учим какие-то сложные текстовые модели, у нас очень не хватает некоторых классов данных.
То есть у нас почти всегда какой-нибудь дисбаланс, есть какие-нибудь редкие примеры, по которым нам удалось собрать мало текста.
Вот тут мы можем воспользоваться дополнением и синтетическими данными для текста.
Самый очевидный вариант, возможность которой появилась недавно - это большие языковые модели.
Есть большая модель Яндекса, например, и вы можете дать нужный вам кусок и она допишет его правдоподобным текстом.
Например сгенерируем с помощью LLM текст про замену кредитной карты.
Я видел эти тексты вживую, какие получаются в банковских приложениях. В общем, люди примерно так и пишут. Другой вариант - мы можем взять датасет, уже собранный на другом языке, и перевести его на наш. Это похуже вариант, но тоже нормально.
Интересный подход – это фильтрация датасета. Например, однажды ребята, с которыми я работал, делали датасет для студентов, чтобы студенты могли выполнять кластеризацию переписки в банковском приложении. И понятно, что банковские данные отдать студентам на студенческий проект нельзя, со службой безопасности не сможете согласовать. Но мы взяли датасет из 7 миллионов русских твитов, и ребята отфильтровали его с помощью adversarial validation. То есть они построили классификатор, который отличает банковскую переписку и просто русские твиты случайные. И затем отобрали те русские твиты, на которых этот классификатор ошибался. Таким образом, они получили набор из 60 тысяч твитов, которые очень похожи на переписку в банковском приложении.
И есть генераторы текстовых данных, например, Faker. Он позволяет генерировать фальшивые имена, адреса, какие-то тексты по правилам. В общем, синтетические данные для текста нам тоже доступны.
 Есть несколько библиотек для генерации синтетических данных на основе вероятностных моделей, импутаций и так далее.
Это, прежде всего, Gretel и SDV. SDV позволяет генерировать по вашему примеру табличек бесконечное количество похожих на ваши,
но никакого прямого пересечения с вашими табличками не будет.
Также они умеют работать с временными рядами, и внутри они используют PyTorch.
Gretel - то же самое, плюс текст, и они построены на TensorFlow.
Их модуль для работы с временными рядами, однако, тоже использует PyTorch.
Есть несколько библиотек для генерации синтетических данных на основе вероятностных моделей, импутаций и так далее.
Это, прежде всего, Gretel и SDV. SDV позволяет генерировать по вашему примеру табличек бесконечное количество похожих на ваши,
но никакого прямого пересечения с вашими табличками не будет.
Также они умеют работать с временными рядами, и внутри они используют PyTorch.
Gretel - то же самое, плюс текст, и они построены на TensorFlow.
Их модуль для работы с временными рядами, однако, тоже использует PyTorch.
 Всегда есть дилемма - строить признаки или выучивать.
Когда появились глубокие нейронные сети, их главным обещанием было - вам больше не придется строить признаки,
мы их будем выучивать сами.
То есть нейронная сеть своими длинными, скажем, сверточными слоями выучивает признаки,
а затем в конце классификатор просто учится по этим выученным признакам принимать решения.
В классическом же машинном обучении мы признаки конструируем вручную, вручную же их отбираем.
Это очень сложный, долгий и дорогой процесс, требующий участия экспертов предметной области.
Их не только нужно привлекать, но их нужно еще и обучать основам статистики, чтобы они понимали, что происходит.
Всегда есть дилемма - строить признаки или выучивать.
Когда появились глубокие нейронные сети, их главным обещанием было - вам больше не придется строить признаки,
мы их будем выучивать сами.
То есть нейронная сеть своими длинными, скажем, сверточными слоями выучивает признаки,
а затем в конце классификатор просто учится по этим выученным признакам принимать решения.
В классическом же машинном обучении мы признаки конструируем вручную, вручную же их отбираем.
Это очень сложный, долгий и дорогой процесс, требующий участия экспертов предметной области.
Их не только нужно привлекать, но их нужно еще и обучать основам статистики, чтобы они понимали, что происходит.
В глубоких нейронных сетях, конечно, все красивее. Вы даете ей данные, она выучивает признаки, конструирует их автоматически, и работает все. Единственная проблема - для того, чтобы дипленинг так работал, ему нужно очень много данных. И разумный подход - это сочетать оба подхода везде, где можно: если мы что-то знаем, нужно сказать об этом модели прямо; если мы знаем, что есть какой-то важный признак, который мы можем сгенерировать простым арифметическим выражением, его надо сгенерировать.
Зачастую мы используем вывод простых моделей как признаки для сложных, или ошибку после работы простых моделей как признаки для сложных. Например, мы используем регрессию для снятия трендов данных, а на остатках предсказываем поведение с помощью катбуста. Градиентный бустинг, например, совершенно не умеет в тренды, но отлично умеет улавливать сложные шаблоны. Линейная регрессия отлично умеет в тренды, но вообще не умеет ловить сложные шаблоны.
С временными рядами тоже очень хорошо работает. Берем какую-нибудь SARIMA или Prophet и строим прогноз с их помощью, а потом ошибки прогноза мы приближаем с помощью катбуста.
 Следующая вещь - это про масштабирование данных.
Для линейных моделей, к которым, кстати, относятся нейронные сети,
масштабирование обязательно.
Следующая вещь - это про масштабирование данных.
Для линейных моделей, к которым, кстати, относятся нейронные сети,
масштабирование обязательно.
В Sklearn есть модуль preprocessing, который позволяет сделать хорошее преобразование для табличных данных. В сверточных сетях обычно нормализуют с помощью TorchVision Transforms. И есть набор волшебных чисел - это статистика ImageNet, на котором, допустим, какие-нибудь сверточные сети учились. И считается, что имеет смысл перед дообучением на своих данных их нормализовать так, чтобы их распределение походило на распределение исходного ImageNet.
На самом деле есть более удачный вариант GradInit.
Делают как: если вы беретесь дообучать сверточную сеть, вы замораживаете все слои и добавляете туда обучаемый параметр - масштаб для каждого слоя. А затем, не меняя веса в слоях, вы выучиваете только эти масштабы на ваших данных. Таким образом, сеть приспосабливается к статистике ваших данных. И потом, после того, как вы доучили до упора эти коэффициенты масштабирования для каждого слоя, тогда вы уже размораживаете слои и дообучаете на вашем датасете.
Если вам приходилось дообучать сверточные сети на вашем датасете, вы, наверное, помните, что сначала там идет такая большая хоккейная клюшка падения лосса, и потом такое медленное планомерное обучение. Так вот, первой фазы падения лосса, при которой у нас портится фич-детектор исходного реснета, вы можете избежать, выучивая нормировку для слоев таким образом.
Ну и очень многие модели делают предположение о распределении признаков. Например, все линейные модели делают предположение о распределении ошибки. Она должна быть или распределена нормально, или, допустим, должна быть распределены по Пуассону, если у вас пуассоновская регрессия. И если ваши данные распределены не так, как ожидает модель, она будет плохо работать на краях вашего распределения. А значит, она утащит центральную оценку куда-то вбок, то есть у вас будет большой bias у вашей модели. И для этого имеет смысл преобразовывать распределение данных. Например, в старину использовали преобразование Бокса-Кокса, а теперь, наверное, разумно использовать PowerTransform и QuantileTransform. При QuantileTransform мы делаем так, чтобы у нас в каждом квантиле было одинаковое количество точек, а PowerTransform - это такое преобразование Бокса-Кокса на стероидах, когда мы разными степенными преобразованиями пытаемся исправить распределение нашей выборки.
 Важная часть работы с данными - это что-то сделать с пропущенными значениями.
С пропущенными значениями, прежде всего, нужно понять, откуда они взялись и какие они.
Какие они вообще могут быть?
Важная часть работы с данными - это что-то сделать с пропущенными значениями.
С пропущенными значениями, прежде всего, нужно понять, откуда они взялись и какие они.
Какие они вообще могут быть?
Они могут быть полностью случайными пропусками, missing completely at random.
Они могут быть missing at random, то есть случайные пропуски, случайные, но зависящие от других признаков. Например, предположим, что у нас был медосмотр детский, и мальчиков и девочек осматривали разные врачи, и один из врачей был менее внимателен, а второй более. Соответственно, допустим, у мальчиков будет больше пропусков в данных, у девочек меньше, и это будет зависеть от признака "пол", но от самих данных, которые будут пропущены, это не зависит.
И есть третий вид пропуска – missing not at random. Это пропуски, зависящие от значения признаков. Самый популярный пример - это, например, при социологических опросах кто-то выбирает не раскрывать свой доход, потому что он очень маленький или очень большой, и он не хотел бы его лишний раз раскрывать, ему некомфортно.
 Как работать с пропусками?
Как работать с пропусками?
Самый простой способ - если у вас мало пропущенных значений, вы можете удалить пропущенные строки, в которых есть хотя бы один пропуск. Если же у вас пропуски рассеяны равномерно по вашему датасету, то удаление строк с пропусками сильно уменьшит количество данных, поэтому это вариант подходит, если только у вас 3-5% пропущенных значений.
Иногда нам приходится удалять столбцы с пропусками. Если значение заполнено меньше, чем, скажем, в 5% строк, обычно, но всегда есть исключения, обычно этот столбец бесполезен.
Еще мы можем заполнить пропущенные значения, исходя из статистики этого столбца, или значений других столбцов. Например, мы можем заполнить пропущенный рост либо средним ростом по популяции, либо, например, если у нас рост пропущен, но есть вес и пол, мы можем построить некоторую функцию, которая предсказывает рост по весу и полу. И вот это вот пример imputation, зависящий и не зависящий от значений других строк.
И обычно not at random пропуски, в них сам факт пропуска - это значимый признак. Пропуски missing completely at random и missing at random - обычно можно игнорировать, потому что все эти данные есть и так у нас в других строчках.
 Для импутаций есть набор хороших библиотек.
Первая из них - это, собственно, не библиотека для импутаций,
это библиотека для визуализации и анализа импутированных значений missingno.
Она позволяет готовить хорошие отчеты и в целом глазом посмотреть,
есть ли какие-то шаблоны в пропущенных значениях.
Для импутаций есть набор хороших библиотек.
Первая из них - это, собственно, не библиотека для импутаций,
это библиотека для визуализации и анализа импутированных значений missingno.
Она позволяет готовить хорошие отчеты и в целом глазом посмотреть,
есть ли какие-то шаблоны в пропущенных значениях.
Sklearn.impute содержит много базовых функций для работы с импутацией. Например, вставку самого частого, вставку по самым типичным значениям для окружения, то есть вставка через KNN.
Fancyimpute содержит сложные алгоритмы импутаций. GAIN импутирует через GAN, PyPOTS через, генетические алгоритмы, очень хорошие, но очень медленные. Transdim работает с пространственными данными, а Imputer с временными рядами.
С какими бы данными вы ни работали, скорее всего, есть библиотека для импутации именно для вашего типа данных.
 Есть задача дискретизации, когда мы преобразуем количественную переменную в категориальную.
Для чего это делается?
Есть задача дискретизации, когда мы преобразуем количественную переменную в категориальную.
Для чего это делается?
Например, если мы преобразуем целевую переменную, то мы тем самым меняем задачу с регрессией на классификацию. А если мы преобразовываем так какие-то наши исходные признаки, то мы зачастую делаем модель более устойчивой к шуму и более быстро обучающейся.
В классическом скоринге кредитном, например, данные разбивали на диапазоны, так называемые бины, и выдавали признак, в каком именно бине находится значение той или иной переменной. Есть библиотека optbinning, которая позволяет выучить оптимальные бины для каждого признака, исходя из информационных критериев.
Обычно, как правило большого пальца, хорошо разбивать диапазон на квантили. Например, pandas.qcat, или в numpy есть разбиение на квантили - то есть, чтобы в каждом диапазоне было одинаковое количество точек.
Кроме преобразования количественных переменных в категориальные, зачастую имеет смысл выполнить обратное преобразование из категориальной к количественную. Для чего это может быть важно? Например, когда у нас есть категориальные переменные с большим количеством уникальных значений, с большой кардинальностью. Например, если у нас есть какая-то категориальная переменная и у нее три значения, мы можем ее добавить тремя признаками, как через one-hot encoding или двумя признаками. Но если у нее тысяча уникальных значений и они категориальны и не образуют порядка, она не может быть упорядочена, то самое разумное, что мы можем сделать - это посчитать разные статистики, которые позволяют заменить нашу категориальную переменную на количественную. Например, какое-то распределение, гистограмму распределения или так называемый mean target encoding - то есть как часто этот признак встречался в примерах с положительной разметкой или еще что-нибудь. И вот в Category Encoder собрано много интересных подходов, в том числе там, по-моему, есть такой catboost encoder, который имитирует encoder, который выполняет внутри себя библиотека catboost.
И последний способ преобразования категориальных переменных – это hashing trick. Зачастую у нас не только очень много категорий в категории переменной, но мы их еще и не знаем на этапе обучения все. Предположим, что мы учим по какой-то причине логистическую регрессию поверх мешка слов. И что мы будем делать, если нам дадут новые слова? То есть, мы их можем выбросить, мы их можем проигнорировать, а еще мы можем сделать hashing trick. То есть, мы можем взять хеш наших слов и, допустим, мы посчитаем md5 hash от каждого слова и возьмем остаток отделения на 16. И таким образом у нас получится 16 признаков, то есть, каждое слово попадет в один из 16 бинов. Обычно бинов используют больше, но тут для примера. Если к нам придет какое-то новое слово, которого мы не видели, мы просто его тоже прохешируем, и оно тоже гарантированно попадет в один из 16 бинов. В этом смысле у нас не возникнет ситуации, что мы не видели такого признака. То есть, наша модель всегда будет получать фиксированное число признаков. То есть, hashing trick используется тогда, когда признаков очень много или когда у нас может возникнуть непредсказуемое количество новых вариантов этого признака на проде.
 Когда мы готовим наши данные, зачастую имеет смысл выполнить преобразование,
чтобы объяснить модели семантику этих данных.
Например, дату можем разбить на элементы, выделить отдельно год, месяц, день, день недели, час.
Вполне возможно, что у нашего веб-сайта, например, для которого мы строим модель посещаемости,
в какие-то часы или в какие-то дни недели посещаемость сильно выше.
Модель в теории сможет выучить сама это разбиение,
но мы могли бы облегчить ей работу, и она бы занялась чем-нибудь более полезным. Точно так же полезно разбивать на элементы адрес - то есть страна, город, улица, номер дома.
Когда мы готовим наши данные, зачастую имеет смысл выполнить преобразование,
чтобы объяснить модели семантику этих данных.
Например, дату можем разбить на элементы, выделить отдельно год, месяц, день, день недели, час.
Вполне возможно, что у нашего веб-сайта, например, для которого мы строим модель посещаемости,
в какие-то часы или в какие-то дни недели посещаемость сильно выше.
Модель в теории сможет выучить сама это разбиение,
но мы могли бы облегчить ей работу, и она бы занялась чем-нибудь более полезным. Точно так же полезно разбивать на элементы адрес - то есть страна, город, улица, номер дома.
Популярное преобразование – это переход в полярные координаты. Например, в моделях цены недвижимости часто делают расстояние от центра города. Предположим, что мы строим модель цены недвижимости в Москве, тогда у нас направление - юго-запад, юго-восток, север, и расстояние, скажем, от Кремля и каких-то других целевых точек наших – это хорошие признаки, хорошо объясняющие цены недвижимости.
Зачастую имеет смысл переходить в декартовые координаты. Например, если у нас долгота-широта, мы можем перейти в координаты в метрах, и это позволит нам удобно выполнять, например, кластеризацию.
Есть вариант снизить размерность наших данных для того, чтобы их как-то визуализировать, может быть, убрать какой-то шум – это PCA, UMAP, t-SNE. И с временными рядами, например, и с картинками, как ни странно, хорошо работает преобразование Фурье и прочие сложные преобразования, позволяющие выделить закономерности, невидимые глазом. Очень трудно нейронной сети выучить переобразование Фурье, хотя она, наверное, смогла бы, как универсальный аппроксиматор.
 Точно так же, как нам мешают пропущенные значения, так нам мешают выбросы и аномалии.
А что такое выбросы и аномалии? Выбросы и аномалии - это случайно высокие, или случайно низкие,
или случайно необычные значения признака.
Точно так же, как нам мешают пропущенные значения, так нам мешают выбросы и аномалии.
А что такое выбросы и аномалии? Выбросы и аномалии - это случайно высокие, или случайно низкие,
или случайно необычные значения признака.
Например, у нас есть датчик, который собирает данные о скорости, и время от времени его заклинивает. И он выдает нулевую скорость, тогда как скорость большая. Либо при старте датчик сильнее раскручивается, и в какой-то момент скорость у нас очень большая, а на самом-то деле она маленькая. То есть просто мы дернулись, и он мгновенно показал высокую скорость.
Outliers можно ловить по их отличию от окружающих точек и обращаться с ними как с пропущенными значениями. То есть мы можем увидеть, что аутлайер у нас completely at random, и просто попробовать его выкинуть. Аутлайер at random, но зависящий от других значений, обычно можно хорошо импутировать. И аутлайер not at random - это сам по себе признак, то есть почему у нас вообще случился этот выброс. Это какое-то значимое событие в данных произошло, которое вызвало выбросы.
Есть хорошие библиотеки Luminaire и PyOD. PyOD - это такой конструктор детекторов аномалий. В Luminaire много интересных подходов, в том числе прекрасный подход для работы с временными рядами. Обычно выбросы удаляют либо обрезают до значений, похожих на соседнее значение.
Главное, что надо понять про выбросы, также, как и про пропущенные значения - откуда они берутся. Какова природа, каков механизм генерации выбросов?
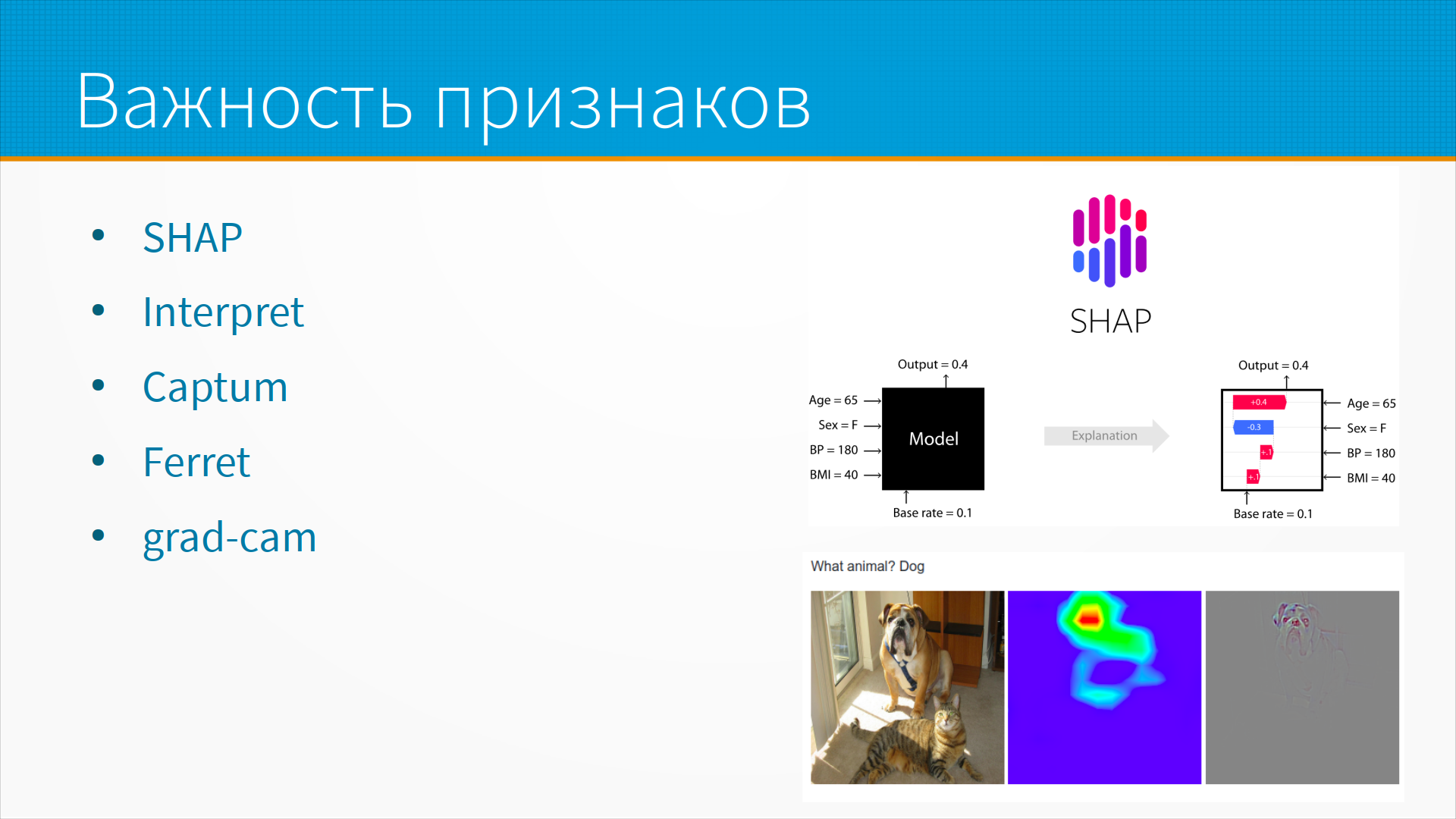 Когда мы строим модели, для большинства моделей можно запросить так называемую важность признаков.
То есть понять, какая часть данных, какие строки или какие столбцы помогли нам принять решение.
Когда мы строим модели, для большинства моделей можно запросить так называемую важность признаков.
То есть понять, какая часть данных, какие строки или какие столбцы помогли нам принять решение.
Например, на слайде у нас вход и выход модели, черный прямоугольник. В среднем по популяции вероятность сердечного приступа 10%. В данном случае у нас возраст 65 лет, пол женский, давление 180 и индекс массы тела 40. И мы видим, что все, кроме женского пола, сдвигает эту вероятность в сторону сердечного приступа. То есть мы говорим, что сердечный приступ у этого конкретного пациента вероятен главным образом, потому что он пожилой, потому что у него высокое давление, потому что он полный. Но то, что это женщина, чуть-чуть снижает вероятность сердечного приступа, не сильно - все равно у нее она на 30% выше, чем в среднем по популяции.
Это библиотека Shap для работы с табличками и картинками. В картинках она подсвечивает, какая часть картинки повлияла на то или иное решение. Это набор библиотека Interpret для работы с разными моделями. Captum – прекрасный инструмент для pytorch. Ferret – набор инструментов для интерпретируемости.
Grad-cam – это мой любимый для картинок. И вот тут нарисован пример, почему нейронная сеть считает, что на картинке нарисована именно собака. То есть ее просили сказать, есть ли на картинке собака. Она говорит, да, собака тут есть. И вот подсвечивает, на какую часть картинки она обращала внимание, когда отвечала, что да, собака тут есть. Ну и контуры собаки прорисовывается - так, в принципе, понятно, на что она обратила внимание.
Для чего нам нужно смотреть на важность признаков? Часто их используют для отбора признаков, но это очень спорный подход, потому что важность размазывается на скоррелированные признаки. То есть предположим, что у нас есть несколько признаков, которые говорят об одном и том же. И все эти инструменты предсказания важности, они размазывают эту важность по всем этим признакам. То есть, если у вас есть, допустим, 100 очень важных признаков, которые предсказывают одно и то же, и один не очень важный признак, но все-таки который хоть что-то предсказывает, то тот же самый Shap, он размажет важность по 100 признакам, и они у вас будут выглядеть как 100 не очень важных и один очень важный. И вы выкинете 100 этих неважных, и модель начнет работать хуже.
Поэтому для отбора признаков использовать важность, как она есть в чистом виде, не очень хорошо. Но важность нам нужна для диагностики модели. Мы смотрим на то, на что обращала внимание модель, и это не должно противоречить нашей картине мира. То есть, например, мы знаем, что в среднем у женщин сердечные приступы случаются реже. И вдруг мы видим, что модель резко повышает вероятность сердечного приступа пациенту, потому что он женщина - это странно. Наверное, что-то у нас не так с данными или с обучением модели. Или, допустим, на вопрос, есть ли на картинке собака, модель отвечает, глядя, например, на собачью миску, а не на собаку. Такое тоже может быть.
 Что касается отбора признаков, наиболее популярный подход к отбору признаков -
это выкидывать их по одному и смотреть, как качество на кросс-валидации проседает.
И если мы выкинули признак и упало качество на кросс-валидации - наверное, мы зря его выкинули.
Что касается отбора признаков, наиболее популярный подход к отбору признаков -
это выкидывать их по одному и смотреть, как качество на кросс-валидации проседает.
И если мы выкинули признак и упало качество на кросс-валидации - наверное, мы зря его выкинули.
И тут есть интересный подход. Есть библиотека Boruta для оценки перестановочной важности - то есть мы переставляем случайным образом какой-нибудь столбец данных и смотрим, насколько он был важен для предсказания. И BoostARoota – это дальнейшее расширение этого подхода. Мы переставляем какой-нибудь столбец данных, учим модель предсказывать с перемешанным столбцом. И учим xgboost, который быстро учится, и смотрим, просело или нет качество модели. И BoostARoota говорит нам, что вот от этих данных можно было бы отказаться, они не так чтобы сильно важны.
При отборе признаков полезно смотреть, кто у нас был источником ошибок.
И проверять, какая строчка научила модель плохому. Это так называемый object importance - то есть не важность по столбцам, а важность по строчкам. То есть может быть, что у нас есть неудачный обучающий пример, благодаря которому модель сбилась с пути истинного и предсказывает неправильно. Может быть, нам надо просто почистить наши данные, и наша модель будет работать лучше.
При отборе признаков нужно быть осторожными с категориальными признаками, потому что важность для категориальных признаков всеми библиотеками считается неправильно. Нужно быть осторожными с коррелированными признаками. Ну и есть прекрасный учебник на сайте feat.engineering про отбор признаков.
 Важная часть при подготовке данных для обучения - это борьба с утечками информации из тестового набора, обучающего набора.
То, что называют dataleaks.
Это большая проблема в соревнованиях.
На практике это не такая большая проблема,
потому что обычную модель все равно потом тестируют в каком-нибудь А/Б-тестировании,
и на прод модели с даталиками не попадут.
Но при обучении, при проведении первоначальных экспериментов, при оценке перспективных моделей
вы легко можете наступить на эти грабли.
Важная часть при подготовке данных для обучения - это борьба с утечками информации из тестового набора, обучающего набора.
То, что называют dataleaks.
Это большая проблема в соревнованиях.
На практике это не такая большая проблема,
потому что обычную модель все равно потом тестируют в каком-нибудь А/Б-тестировании,
и на прод модели с даталиками не попадут.
Но при обучении, при проведении первоначальных экспериментов, при оценке перспективных моделей
вы легко можете наступить на эти грабли.
Даталик - это любая информация, которая доступна модели при обучении, но не доступна при инференсе. Например, предположим, что у нас есть признак в датасете, вылетел студент после первого курса или нет. Еще у нас есть дата отчисления. И понятно, что эти информации - взаимозаменяемые. То есть, взглянув на дату отчисления, мы всегда можем понять, вылетел он на первом курсе или нет. И, зная, вылетел он на первом курсе или нет, мы можем предсказать дату отчисления. Она обычно через, допустим, три месяца - то есть сколько нужно вам то, чтобы всю эту бюрократию провернуть, на все эти попытки пересдать, спасти улетающего студента. И если мы сделали целевой признак, вылетит студент или нет, но забыли удалить дату отчисления, наша модель прекрасно будет работать - только это бесполезная в продакшене модель. Потому что там у нас даты отчисления не будет, мы заглянули в будущее.
Даталики завышают метрику качества модели. А еще даталики отвлекают внимание модели от по-настоящему важных признаков - зачем обращать внимание на какие-то признаки важные, когда у нас есть шпаргалка, с которой мы сразу можем подсмотреть ответ. Поэтому с даталиками нужно бороться.
 И типичные источники даталиков - это нерешенная проблема с дубликатами,
неправильное разбиение, масштабирование перед разбиением,
неверно сделана импутация, неаккуратная генерация признаков
и отсутствие групповой стратификации.
И типичные источники даталиков - это нерешенная проблема с дубликатами,
неправильное разбиение, масштабирование перед разбиением,
неверно сделана импутация, неаккуратная генерация признаков
и отсутствие групповой стратификации.
 Если подробнее, даталики часто возникают при наличии дубликатов в данных.
Например, если у нас есть две совершенно одинаковые строчки,
и одна из них попала в train, а вторая в test,
получится, что модель видела наш тестовый пример,
и, конечно же, она ответит правильным предсказанием на тесте.
Если подробнее, даталики часто возникают при наличии дубликатов в данных.
Например, если у нас есть две совершенно одинаковые строчки,
и одна из них попала в train, а вторая в test,
получится, что модель видела наш тестовый пример,
и, конечно же, она ответит правильным предсказанием на тесте.
Что тут делать? Самый очевидный подход - это удалять дубликаты. Но тут есть проблема, что если дубликатов много, то удалением мы искажаем распределение. То есть на самом деле у нас дубликаты могут быть естественные, в жизни могут быть действительно похожие примеры. Например, если у нас не так много вариантов, то есть если у нас есть возраст человека, если у нас есть пол, вес, ну, допустим, мы предсказываем, исходя из этих данных, например, вероятность того, что он ведет активный или неактивный образ жизни. У нас всего, допустим, 4 или 6 тысяч вариантов. И понятно, что если у нас, допустим, 100 тысяч людей, то дубликаты будут обязательно.
Мы можем стратифицировать разбиение, то есть сделать так, чтобы все дублирующиеся варианты попали в один из фолдов. Обычно дубликаты ухудшают качество моделей, причем они ухудшают качество работы даже сложносочиненных нейросетевых моделей для обработки текста. Тут есть интересная статья про то, что дедубликация данных, причем не только полная дедубликация, то есть дедубликация точных повторов, но и дедубликация для частичных повторов, она улучшает качество работы модели.
Тут есть подход, чем-то похожий на подход с методом опорных векторов, что в принципе самые главные признаки у нас - это признаки на границе, когда мы сохраняем рядом расположенные примеры, то есть они расположены рядом в пространстве признаков, но имеют разную разметку. Вот именно такие значения самые важные для нашей модели. Все остальные обычно можно удалять.
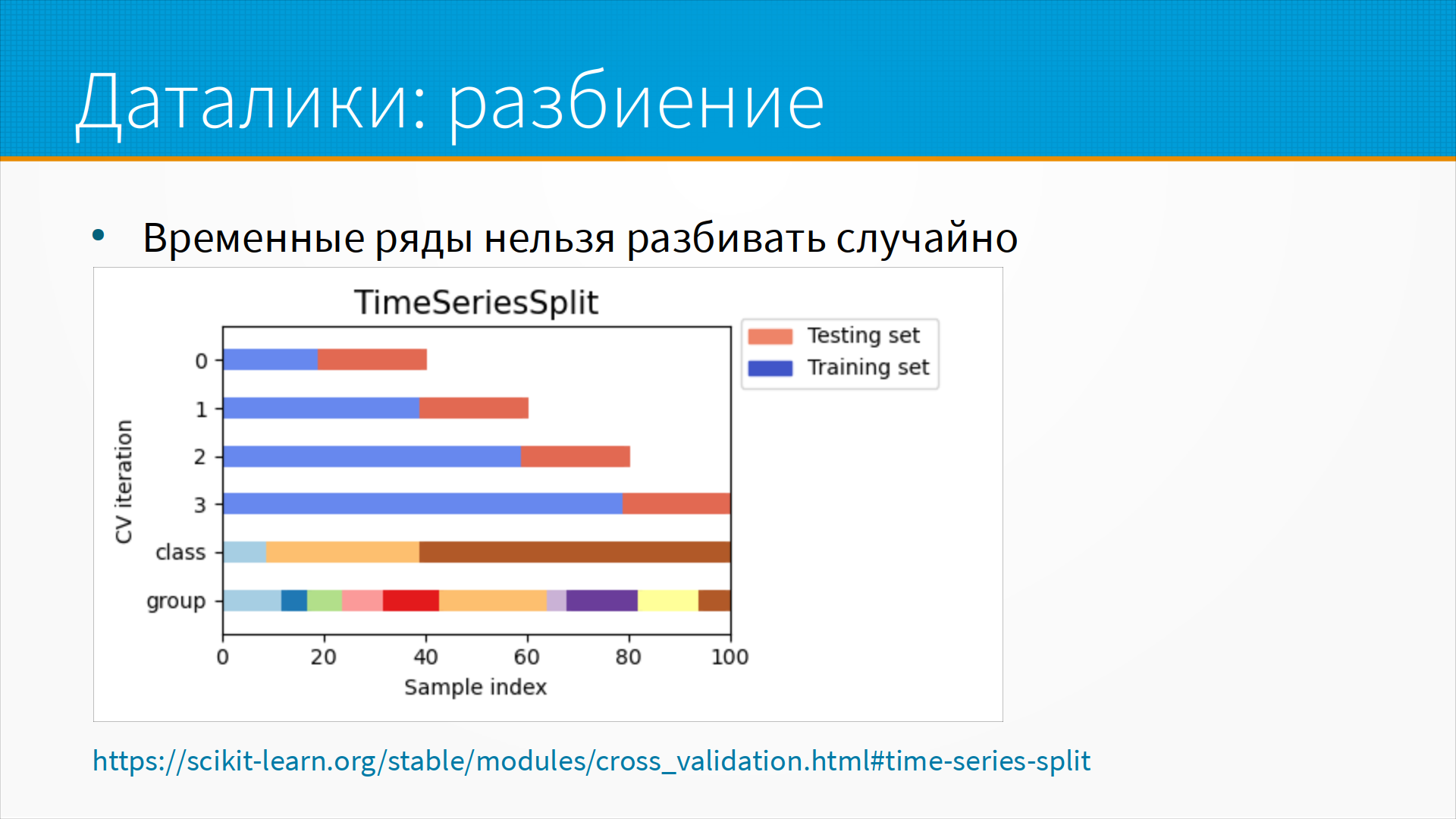 Про источник даталиков разбиения.
Например, мы берем временные ряды.
Сама по себе задача, которую решают временными рядами, обычно обладает инерцией.
Например, курс акций обычно тот же самый.
Продажи в магазинах обычно какие-то более-менее константные,
то есть они колеблются по дням недели,
но в два соседних дня продажи обычно похожи.
И если мы случайно перемешали временные ряды на тестовую и обучающую выборку,
мы фактически закинули близкие, почти дубликаты в трейн и в тест.
И, конечно, наша модель покажет выдающиеся результаты на таком разбиении, но она будет бесполезна.
Про источник даталиков разбиения.
Например, мы берем временные ряды.
Сама по себе задача, которую решают временными рядами, обычно обладает инерцией.
Например, курс акций обычно тот же самый.
Продажи в магазинах обычно какие-то более-менее константные,
то есть они колеблются по дням недели,
но в два соседних дня продажи обычно похожи.
И если мы случайно перемешали временные ряды на тестовую и обучающую выборку,
мы фактически закинули близкие, почти дубликаты в трейн и в тест.
И, конечно, наша модель покажет выдающиеся результаты на таком разбиении, но она будет бесполезна.
Поэтому для временных рядов есть специальный подход для разбиения, когда мы отрезаем какой-то протяженный кусок на обучение и небольшой кусок - сразу за ним или через некоторый лаг - для тестирования. Эта схема много где описана и реализована в scikit-learn как Time Series Split.
 Даталики при масштабировании возникают, если мы выполняем предобработку датасета -
например, стандартизацию приведения к нулевому среднему и единичному стандартному отклонению
- до разбиения на трейн и тест.
Надо проводить масштабирование уже на трейне,
а на тесте делать масштабирование тем же скейлером, каким вы делали масштабирование на трейне.
И на проде его тоже делать. Соответственно, вы поставляете на прод не только вашу модель,
но и обученный скейлер.
Или, если вы делите не на трейн и тест, а на несколько фолдов, вы должны масштабировать
внутри каждого фолда и выполнять оценку вот этим способом масштабирования.
Даталики при масштабировании возникают, если мы выполняем предобработку датасета -
например, стандартизацию приведения к нулевому среднему и единичному стандартному отклонению
- до разбиения на трейн и тест.
Надо проводить масштабирование уже на трейне,
а на тесте делать масштабирование тем же скейлером, каким вы делали масштабирование на трейне.
И на проде его тоже делать. Соответственно, вы поставляете на прод не только вашу модель,
но и обученный скейлер.
Или, если вы делите не на трейн и тест, а на несколько фолдов, вы должны масштабировать
внутри каждого фолда и выполнять оценку вот этим способом масштабирования.
 При импутации надо помнить, что импутированные значения содержат информацию о выборке в целом.
Например, значение о том, какое самое частое значение, какое среднее значение.
То есть та же самая история, что с масштабированием.
И импутацию мы проводим после разбиения на трейн и тест или внутри каждого фолда.
При импутации надо помнить, что импутированные значения содержат информацию о выборке в целом.
Например, значение о том, какое самое частое значение, какое среднее значение.
То есть та же самая история, что с масштабированием.
И импутацию мы проводим после разбиения на трейн и тест или внутри каждого фолда.
 Есть задачи, в которых очень велика пространственная корреляция.
Например, цены на недвижимость в одном здании обычно образуются одним и тем же способом.
То есть, например, на первом этаже квадратный метр в аренду стоит, скажем, 5 тысяч рублей в месяц.
Или 15, или 50.
То есть во всем здании цены на квадратный метр примерно одни и те же.
Есть задачи, в которых очень велика пространственная корреляция.
Например, цены на недвижимость в одном здании обычно образуются одним и тем же способом.
То есть, например, на первом этаже квадратный метр в аренду стоит, скажем, 5 тысяч рублей в месяц.
Или 15, или 50.
То есть во всем здании цены на квадратный метр примерно одни и те же.
Или, например, посещаемость магазинов, стоящих внутри одного и того же торгового центра, обычно одна и та же. То есть люди приходят в большой магазин и заодно заходят в этот магазинчик купить какие-нибудь мелочи или сухофруктов, орехов или сигарет. И если часть данных попадет в трейн, а часть в тест, мы получим тот же самый даталик, как при близких дубликатах.
Решение тут - стратифицировать по группам. Мы делали следующим образом, когда много работали с пространственными данными. Мы делали кластеризацию с помощью алгоритма MeanShift, который собирает рядом расположенные кластеры. По номеру кластера мы уже стратифицировали нашу выборку.
Иногда имеет смысл делать разделительную полосу между трейном и тестом. То есть какая-то часть пространства попадает в трейн, какая-то часть пространства попадает в тест, а часть на границе не попадает ни туда, ни сюда, и мы ее просто выкидываем.
 Тут возникает проблема сложной стратификации.
То есть, если вы стратифицируете по значению целевого признака,
если вы стратифицируете пространственно, еще как-нибудь,
то, скорее всего, стратификацию вам придется писать руками.
Это в принципе несложно, но там надо сделать много аккуратных действий.
Есть интересная довольно старая статья Multi-Way Survey
Stratification and Sampling от американского министерства статистики,
U.S. Census Bureau, которая рекомендует подходы к стратификации при переписи населения.
В принципе, наша история очень похожа.
Тут возникает проблема сложной стратификации.
То есть, если вы стратифицируете по значению целевого признака,
если вы стратифицируете пространственно, еще как-нибудь,
то, скорее всего, стратификацию вам придется писать руками.
Это в принципе несложно, но там надо сделать много аккуратных действий.
Есть интересная довольно старая статья Multi-Way Survey
Stratification and Sampling от американского министерства статистики,
U.S. Census Bureau, которая рекомендует подходы к стратификации при переписи населения.
В принципе, наша история очень похожа.
Есть библиотеки для R. Для питона, если найдете - напишите что-нибудь в чат. Я - все случаи, когда использовал сложную стратификацию, писал ее руками.
 В процессе генерации данных лики возникают еще до подготовки.
Лики, например - производный признак от целевой переменной какой-нибудь,
как, например, дата отчисления и признак "отчисленный или нет".
Или, например, порядковый номер строчки.
Вам сначала могли прислать хорошие примеры, а потом плохие.
И, соответственно, просто по порядковому номеру строчки
мы можем понять, хорошая или плохая разметка будет.
Мне встречалось соревнование с таким даталиком.
В процессе генерации данных лики возникают еще до подготовки.
Лики, например - производный признак от целевой переменной какой-нибудь,
как, например, дата отчисления и признак "отчисленный или нет".
Или, например, порядковый номер строчки.
Вам сначала могли прислать хорошие примеры, а потом плохие.
И, соответственно, просто по порядковому номеру строчки
мы можем понять, хорошая или плохая разметка будет.
Мне встречалось соревнование с таким даталиком.
Подписи и оборудование на рентгеновских снимках. Мы с ребятами делали модель, которая ищет пневмоторакс, то есть воздушные полости в легких. Это серьезное и тяжелое осложнение, чреватое коллапсом легких. Внезапная смерть развивается медленно, без особенных признаков. И хорошо скринить людей, искать воздушные полости - а их видно плохо, - и в разметке там была следующая проблема, что много рентгеновских снимков людей, у которых эти полости уже были выявлены, и им поставлены были трубки для отсоса воздуха, дренажные трубки. И эти трубки отлично видно на рентгеновских снимках. Таким образом, нашей модели, если бы мы делали классификацию, достаточно было бы предсказать, что на снимке есть трубка, и качество классификации было бы отличное, но только на тесте. Мы делали сегментацию, поэтому модель не обращала внимания на эти трубки и катетеры, но, в общем, смотреть на них все равно надо.
Зачастую качество и объем данных являются даталиком. Например, привозят больного, и обычно у медицинского персонала, который его отправляет на обследование, есть какие-то предположения: тяжелый это больной, легкий это больной, что, скорее всего, ничего серьезного, или, скорее всего, какая-то проблема у него есть. Допустим, больных в тяжелом состоянии могут отправлять на качественный новый томограф. Больных, которым делают МРТ для галочки, могут отправлять на старый, разрегулированный томограф. И нейронная сеть просто по особенностям томограммы может сразу сказать, на каком томографе это было сделано, и какие предположения делал медицинский персонал по поводу этого больного. И, допустим, модель предсказывает тяжелое состояние для всех, у кого качественная томограмма, и легкое для всех, у кого она некачественная.
И очень часто мы используем данные, которые недоступны модели. Они даже, может быть, одновременно попадают нам в базу данных. Или они поступают с некоторой задержкой. Поэтому при обучении мы попросили их, нам их дали, а на проде, в производстве, у нас этих данных в нужный момент не будет. Это тоже даталик - заглядывание в будущее.
 Дополнительные материалы:
Дополнительные материалы:
- Albumentations: Fast and Flexible Image Augmentations
- MEMO: Test Time Robustness via Adaptation and Augmentation
- EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks