
- 10.10.2022
- 05.10.2025
- обучение
- #mlsystemdesign
Третья лекция открытого курса "Дизайн систем машинного обучения", "Обучающие данные".
Слайды можно скачать тут mlsysd3ods.pdf
Текстовая расшифровка:
 Добрый день, меня зовут Дмитрий Колодезев, и у нас третья лекция нашего курса по ML-System Design, посвященная обучающим данным.
Добрый день, меня зовут Дмитрий Колодезев, и у нас третья лекция нашего курса по ML-System Design, посвященная обучающим данным.
 Мы поговорили до этого про практическое применение машинного обучения, затронули вопросы, которые нужно задать себе, когда проектируем ML-систему.
Мы поговорили до этого про практическое применение машинного обучения, затронули вопросы, которые нужно задать себе, когда проектируем ML-систему.
 Поскольку ML-система строится на данных, про данные мы и будем говорить.
Поскольку ML-система строится на данных, про данные мы и будем говорить.
Предположим, что у нас есть две команды. Одна команда состоит из крутых исследователей, квалифицированных программистов, они умеют работать с хорошими алгоритмами, они просто хорошие инженеры.
И вторая команда состоит из студентов и аспирантов, например, и у них есть доступ к огромному датасету. Они не очень хороши как разработчики, но данных у них очень много. И вот вопрос, кто из них сделает лучшую модель?
Есть ситуации, когда лучше отработает вторая команда, есть ситуации, когда лучше отработает первая команда. Я думаю, что в среднем, скорее всего, победит первая команда, то есть команда с большими мозгами победит команду с большими данными, просто потому, что в больших данных много мусора, и для того, чтобы с ними корректно работать, нужны золотые руки. Но это неоднозначно, то есть есть ситуации, когда, если у вас нет данных, ничто вас не спасет. Поэтому смотрите на вашу задачу, пытайтесь понять, что вам сильнее нужно, алгоритмы или данные.
 Про данные. Один из ведущих исследователей причинно-следственных связей, Джуда Перл, в своих работах предложил так называемую лестницу причинности. Данные нам нужны для того, чтобы делать на их основе какие-то выводы, и мы можем делать три качественно разных вида выводов.
Про данные. Один из ведущих исследователей причинно-следственных связей, Джуда Перл, в своих работах предложил так называемую лестницу причинности. Данные нам нужны для того, чтобы делать на их основе какие-то выводы, и мы можем делать три качественно разных вида выводов.
Первое - это ассоциации, то есть какие-то события происходят вместе. Например, у нас есть данные, мокрая трава или нет, и есть разметка, прошел дождь или нет. Почти всегда, когда дождь прошел, трава мокрая. Это ассоциация, и тут есть проблема: после не значит вследствие, correlation does not imply causation. То есть если мы видим, что трава мокрая, вовсе не обязательно, что был дождь - просто могла проехать поливальная машина или кто-то разлил воду.
Хороший пример - когда началась эпидемия ковида, люди, которых клали под аппарат искусственной вентиляции легких, умирали чаще тех, кого не положили. И возникла такая городская легенда, что аппараты искусственной вентиляции легких убивают, сопротивляйтесь, если вас будут пытаться класть под ИВЛ.
На самом-то деле, просто под ИВЛ, поскольку их тогда не хватало, клали тех, кто был в самом тяжелом состоянии, и они, к сожалению, чаще других умирали. Но их убивал не аппарат искусственной вентиляции легких, их убивала все-таки пневмония. И первый этап работы с данными, первый уровень - это ассоциация, то, что встречается вместе. В статистике это описательная, или дескриптивная статистика.
Второй уровень работы с данными - это эксперимент. Мы смотрим на наши данные, делаем какие-то предположения о зависимости и говорим, ну, мы можем сделать вот это и добиться такого-то результата. Например, у человека болит голова, он решает съесть таблетку, голова перестает болеть. Это эксперимент. Но у нас тут не вся правда. Перестала ли бы у него болеть голова, если бы он не съел таблетку - мы не знаем. Потому что для этого нам надо было бы иметь две параллельных реальности и два человека - один съел таблетку, другой не съел. Для того, чтобы однозначно проанализировать, было то или иное действие причиной, нам нужно две параллельных реальности, а лучше много - для того, чтобы добиться статистической значимости. А у нас нет параллельных реальностей, это фундаментальная проблема причинно-следственного анализа.
Но есть много хорошей математики, которая позволяет предположить обоснованно, было ли какое-то действие причиной какого-то результата. И мы максимум, чего можем достичь, это добиться обоснованного предположения. В принципе, с машинным обучением мы в лучшем случае находимся здесь.
То есть какие-то признаки появляются вместе с нужным нам целевым признаком, и мы говорим, что это вот причина нужного нам результата. И пытаемся по этим признакам результат предсказывать. Однако все ошибки из серии "после не значит следствие, correlation does not imply causation" наш алгоритм машинного обучения обязательно сделает. То есть роботы с трудом поднимаются выше уровня ассоциации.
 И дальше, что у нас есть с данными - проблемы больших моделей и проблемы больших данных.
Современное машинное обучение – это большие модели, большие модели требуют много данных, и в этих данных часто бывают ошибки разметки.
Потому что, например, если у вас есть сто тысяч или десять миллионов картинок, вы не можете просмотреть их все глазом и найти ошибки.
И даже если вы будете смотреть их глазом, все равно их будет смотреть несколько людей, и они будут размечать по-разному.
И дальше, что у нас есть с данными - проблемы больших моделей и проблемы больших данных.
Современное машинное обучение – это большие модели, большие модели требуют много данных, и в этих данных часто бывают ошибки разметки.
Потому что, например, если у вас есть сто тысяч или десять миллионов картинок, вы не можете просмотреть их все глазом и найти ошибки.
И даже если вы будете смотреть их глазом, все равно их будет смотреть несколько людей, и они будут размечать по-разному.
Например, вот есть сайт LabelErrors, который показывает типичные ошибки в разметке ImageNet, на котором построены большинство современных сверточных сетей, используемых в индустрии. Мы видим, например, что разметка "красная панда" - на самом деле гигантская панда. Но, что еще более интересно, мы видим разметка "ванна", а там человек на корточках, и видим только его джинсы. Как бы алгоритм машинного обучения догадался, что это непосредственно ванна? Но тут есть, кстати, и ванна, и джинсы, и рубашка, и ботинки, а метку нужно было сделать только одну. То есть, проблема ошибки в разметке незаметно проникает в наши данные, и ограничивает качество наших моделей.
Потом, когда данных много, их неудобно хранить и с ними неудобно работать. Есть интересное решение в WebDataset, более-менее стандартный подход, когда мы упаковываем наши картинки и разметку в виде tar-архивов, и создаем такой специальный датасет, который по мере необходимости при обучении моделей подкачивает данные с серверов. На слайде ссылка WebDataset, как раз с библиотекой и описанием соответствующей технологии.
Про ошибки, кстати - в ImageNet ошибочно размечено от 6 до 25% картинок, смотря что считать ошибкой.
Кроме ошибочной разметки, есть еще дисбаланс классов. Про дисбаланс классов обычно думают так - когда одного класса сильно больше, чем другого. Например, если мы решаем задачу antifraud, у нас очень много хороших пользователей и мало фродеров, то есть пользователей, которые делают что-то нехорошее. Это дисбаланс классов.
Но тут дисбаланс классов в другом смысле. В ImageNet 40 пород собак. И сеть, обученная на нем, легко может отличить французского пуделя от бульдога. Но она не сможет различить два вида компьютеров - допустим, компьютер под Apple и компьютер под Windows. Любой человек различит их, а ImageNet нет. Это неудобно, потому что зачастую мы не можем добыть больше данных, чтобы сгладить дисбаланс.
Кроме дисбаланса классов в больших датасетах есть такая проблема, как предвзятость. Проблема серьезнее, чем принято у нас в стране рассматривать.
Дело в том, что мир меняется, причем он меняется очень сильно. За последние 20, 30, 40 лет, я уже не говорю про 50, мир изменился кардинально. Изменились роли социальной структуры, появились вообще разработчики моделей машинного обучения, которых не было. Появился интернет, но во многих датасетах, особенно в текстовых, во многих картиночных датасетах, мы все еще в прошлом.
В некоторых странах, как, например, в Соединенных Штатах Америки, это более очевидно, потому что там много людей с черным цветом лица, белым цветом лица, а нейронные сети людей с черным цветом лица опознают как горилл. Вообще это не здорово.
Но есть гораздо более тонкие вещи. Например, датасет по тому, кем люди работают, или сколько люди зарабатывают, или о людском здоровье. Он построен на исторических данных. За это время изменились и профессии, и продолжительность жизни - а датасет все еще содержит в себе слепок старого мира, которого уже нет, и модели, которыми мы будем пользоваться в будущем, учатся на данных, которые мы собрали в прошлом.
Плюс неоднозначная разметка. Зачастую одна и та же картинка, или одна и та же строка, или один и тот же текст - их можно разметить несколькими способами. Или, например, ограничивающий прямоугольник bounding box, который показывает, где именно на картинке расположен человек, или какой-то предмет - можно нарисовать чуть шире или чуть уже.
Есть много вариантов, как разметить данные, и разные люди размечают по-разному. Как нам сообщить нейронной сети, что все эти разметки имеют право на жизнь?
 Потом, сама по себе разметка, она когда-то делалась вся вручную.
Потом, сама по себе разметка, она когда-то делалась вся вручную.
То есть, мы брали наши данные, садили людей - экспертов предметной области, они размечали. Это было очень дорого, пока не стало невозможно. Сначала у нас стало не хватать врачей на разметку медицинских данных, а просто в какую-нибудь краудсорсинговую платформу вроде Amazon Mechanical Turk или в Толоку мы не можем отдать, чтобы кто попало размечал рентгеновские снимки, есть здесь рак или нет, например.
Затем стали для разметки использовать transfer learning, то есть обученные на других задачах модели пытаются разметить нужным нам образом датасет.
Появились подходы к программируемым датасетам, когда мы пишем некоторое количество простых правил, слабых лернеров, и запускаем программную разметку датасета. Библиотека Snorkel реализует в себе вот эту логику, когда мы пишем простые разметчики, которые, например, для 5% данных могут дать хороший результат, а для остальных они говорят, что мы не знаем. И вот эту разметку, сделанную алгоритмами, людьми, библиотека Snorkel позволяет объединить и построить более-менее непротиворечивый набор разметки.
Тут много подходов.
Semi-supervision learning, то есть обучение со слабым учителем. Есть технология semi-supervision, которую продвигает v7Labs, у них есть стартап, и много документации по теме. Это когда мы размечаем часть наших данных, потом на этой части данных учим модель, и этой моделью мы размечаем остальные данные, и потом те данные, которые наша модель разметила с большой уверенностью, мы тоже используем как разметку.
Есть подход, называемый active learning, когда мы размечаем какое-то количество данных, и затем в оставшихся неразмеченных мы ищем те данные, разметив которые, мы сильнее всего улучшим качество модели.
Зачем это? Разметка данных стоит денег и требует времени. Поэтому если у нас, допустим, есть 10 тысяч картинок, а бюджет на разметку только на одну тысячу, мы хотели бы разметить ту тысячу картинок, которая помогла бы модели сильнее всего. И модули Baal и modAL реализуют технологии active learning, когда вы размечаете часть данных, и на оставшихся данных вы оцениваете, какие из этих данных нужно разметить, чтобы получить наибольшее качество модели.
Еще очень часто самую большую отдачу при работе с данными дает чистка их от ошибок. Например, очистка от ошибки разметки или просто исключение каких-то данных, которые сбивают с толку модели. Есть стартап и опенсорсная библиотека CleanLab, которая позволяет искать противоречивые данные, когда у похожих данных разная разметка.
Что мы можем делать с данными, если мы нашли противоречия в них? Ну, возможно, это ошибка, их нужно переразметить. А возможно, действительно, в мире все неоднозначно, и нам нужно оставить оба варианта разметки. Это надо решать с экспертами предметной области, но в любом случае такие точки надо находить и работать с ними. И CleanLab предоставляет удобные сервисы для проверки данных на ошибки и противоречия.
 Если вы возьметесь за ручную разметку данных,
сразу помните, что это долго, дорого и не очень качественно,
но иногда другого варианта нет.
За рубежом обычно пользуется Amazon Mechanical Turk,
где задача выдается людям,
которые за деньги размечают вам данные.
Есть хороший стартап Scale,
который поддерживает разные модели разметки,
в том числе semi-supervised learning, о котором мы говорили.
Есть удобный инструмент LabelBox.
И есть два стартапа, которые выросли в России - это LabelMe, который обеспечивает для вас разметку данных,
и Толока. Это аналог Amazon Mechanical Turk, и на мой взгляд, он даже лучше, чем Amazon Mechanical Turk.
Если вы возьметесь за ручную разметку данных,
сразу помните, что это долго, дорого и не очень качественно,
но иногда другого варианта нет.
За рубежом обычно пользуется Amazon Mechanical Turk,
где задача выдается людям,
которые за деньги размечают вам данные.
Есть хороший стартап Scale,
который поддерживает разные модели разметки,
в том числе semi-supervised learning, о котором мы говорили.
Есть удобный инструмент LabelBox.
И есть два стартапа, которые выросли в России - это LabelMe, который обеспечивает для вас разметку данных,
и Толока. Это аналог Amazon Mechanical Turk, и на мой взгляд, он даже лучше, чем Amazon Mechanical Turk.
Тут надо помнить, что, отдавая данные на разметку в Толоку, вам надо обеспечить, чтобы, если кто-то разметил вам данные неправильно, вы смогли это понять. На практике это обычно так: вы отдаете каждую задачу на разметку хотя бы трем людям. Или двум, а третьему - если у них не совпала разметка. И есть библиотека, которая реализует вот эту логику повторной разметки, то есть проверки качества с Толоки. На нее будет ссылка в дополнительных материалах и статья, как они работают.
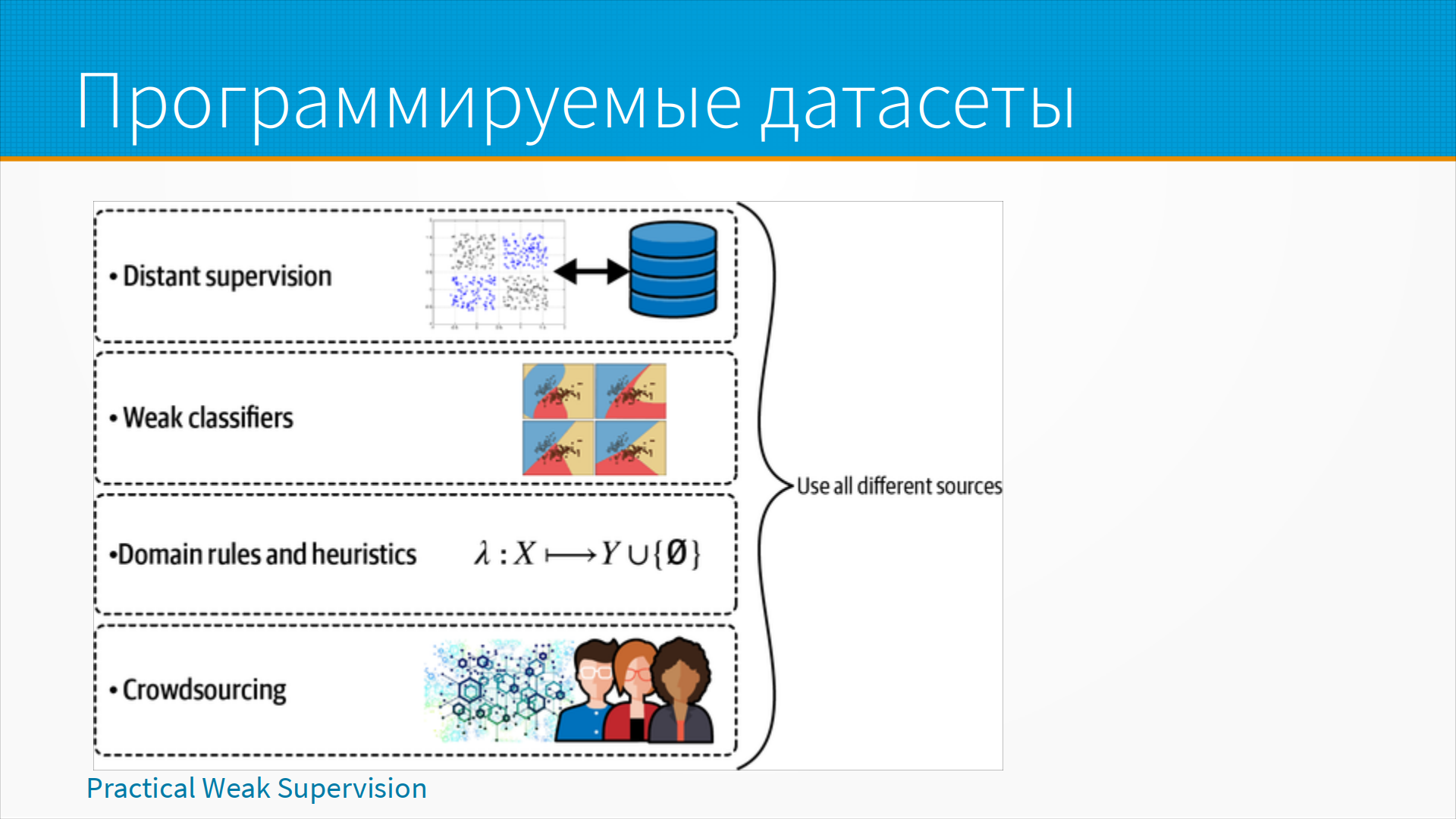 Другой подход к разметке данных - это программируемый датасет.
Я тут упоминал Snorkel, подробнее на нем остановимся.
У нас иногда есть хороший способ программно разметить какой-то кусочек данных.
Не все данные, а вот, например, кусочек.
Например, мы строим модель токсичного текста - текста, который может быть оскорбительным для тех или иных людей.
Допустим, у нас есть комментарий на сайте,
и мы хотели бы токсичный текст отправлять на премодерацию.
Мы не можем однозначно сказать, содержится ли в этом тексте издевка, скрытое оскорбление,
тем более, что и люди не всегда это понимают.
Но у нас есть набор простых правил - например, короткие тексты обычно не токсичны.
Для того, чтобы оскорбить человека, как правило, нужно написать много слов.
Тексты с матерными словами обычно токсичны.
И, таким образом, мы можем написать некоторые правила, которые разметят нашу модель,
пусть не весь набор данных, но часть его.
И потом на нашей разметке учить уже более-менее сложную модель.
И тут есть наблюдение, что какой-нибудь Bert будет использовать не те признаки, которые мы использовали.
То есть маловероятно, что мы совпадем по признакам.
Поэтому мы размечали данные по простым тупым признакам, по правилам - а модель выучила сложную логику, которая нам была нужна.
Звучит странно, но это работает.
Другой подход к разметке данных - это программируемый датасет.
Я тут упоминал Snorkel, подробнее на нем остановимся.
У нас иногда есть хороший способ программно разметить какой-то кусочек данных.
Не все данные, а вот, например, кусочек.
Например, мы строим модель токсичного текста - текста, который может быть оскорбительным для тех или иных людей.
Допустим, у нас есть комментарий на сайте,
и мы хотели бы токсичный текст отправлять на премодерацию.
Мы не можем однозначно сказать, содержится ли в этом тексте издевка, скрытое оскорбление,
тем более, что и люди не всегда это понимают.
Но у нас есть набор простых правил - например, короткие тексты обычно не токсичны.
Для того, чтобы оскорбить человека, как правило, нужно написать много слов.
Тексты с матерными словами обычно токсичны.
И, таким образом, мы можем написать некоторые правила, которые разметят нашу модель,
пусть не весь набор данных, но часть его.
И потом на нашей разметке учить уже более-менее сложную модель.
И тут есть наблюдение, что какой-нибудь Bert будет использовать не те признаки, которые мы использовали.
То есть маловероятно, что мы совпадем по признакам.
Поэтому мы размечали данные по простым тупым признакам, по правилам - а модель выучила сложную логику, которая нам была нужна.
Звучит странно, но это работает.
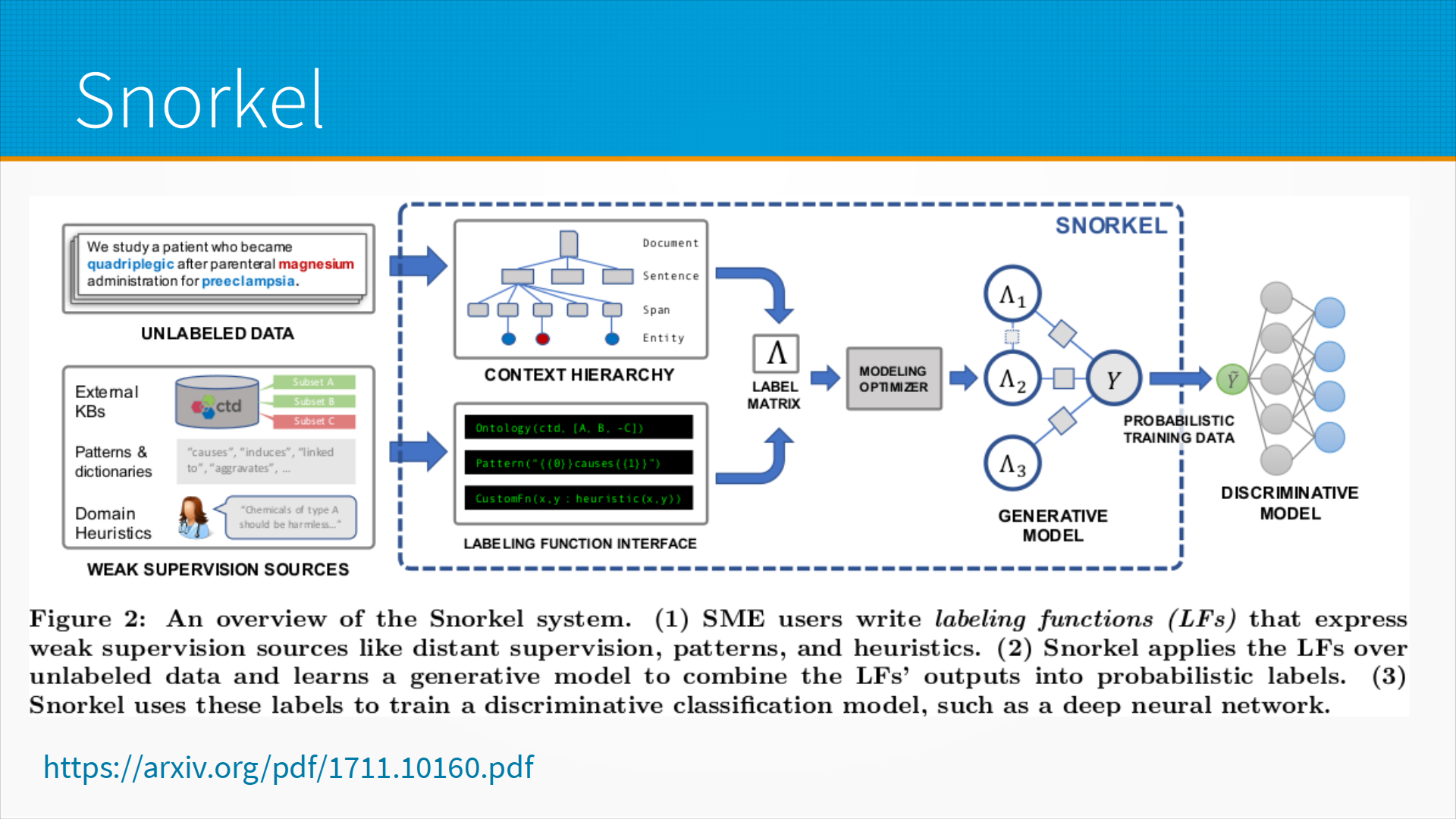 Общий подход библиотеки Snorkel такой, что мы пишем какое-то количество лейблеров, разметчиков.
При этом разметчики могут использовать разную информацию из разных баз данных: какие-то доменные евристики, как я уже говорил, например, что короткий текст обычно не оскорбителен;
внешняя база данных, например, вот этого человека забанили как тролля;
какие-то паттерны, шаблоны, то есть, например, словарь неприличных выражений.
И объединять все это, используя разные признаки, и строить вероятностную разметку, и на ней уже учить модель.
Общий подход библиотеки Snorkel такой, что мы пишем какое-то количество лейблеров, разметчиков.
При этом разметчики могут использовать разную информацию из разных баз данных: какие-то доменные евристики, как я уже говорил, например, что короткий текст обычно не оскорбителен;
внешняя база данных, например, вот этого человека забанили как тролля;
какие-то паттерны, шаблоны, то есть, например, словарь неприличных выражений.
И объединять все это, используя разные признаки, и строить вероятностную разметку, и на ней уже учить модель.
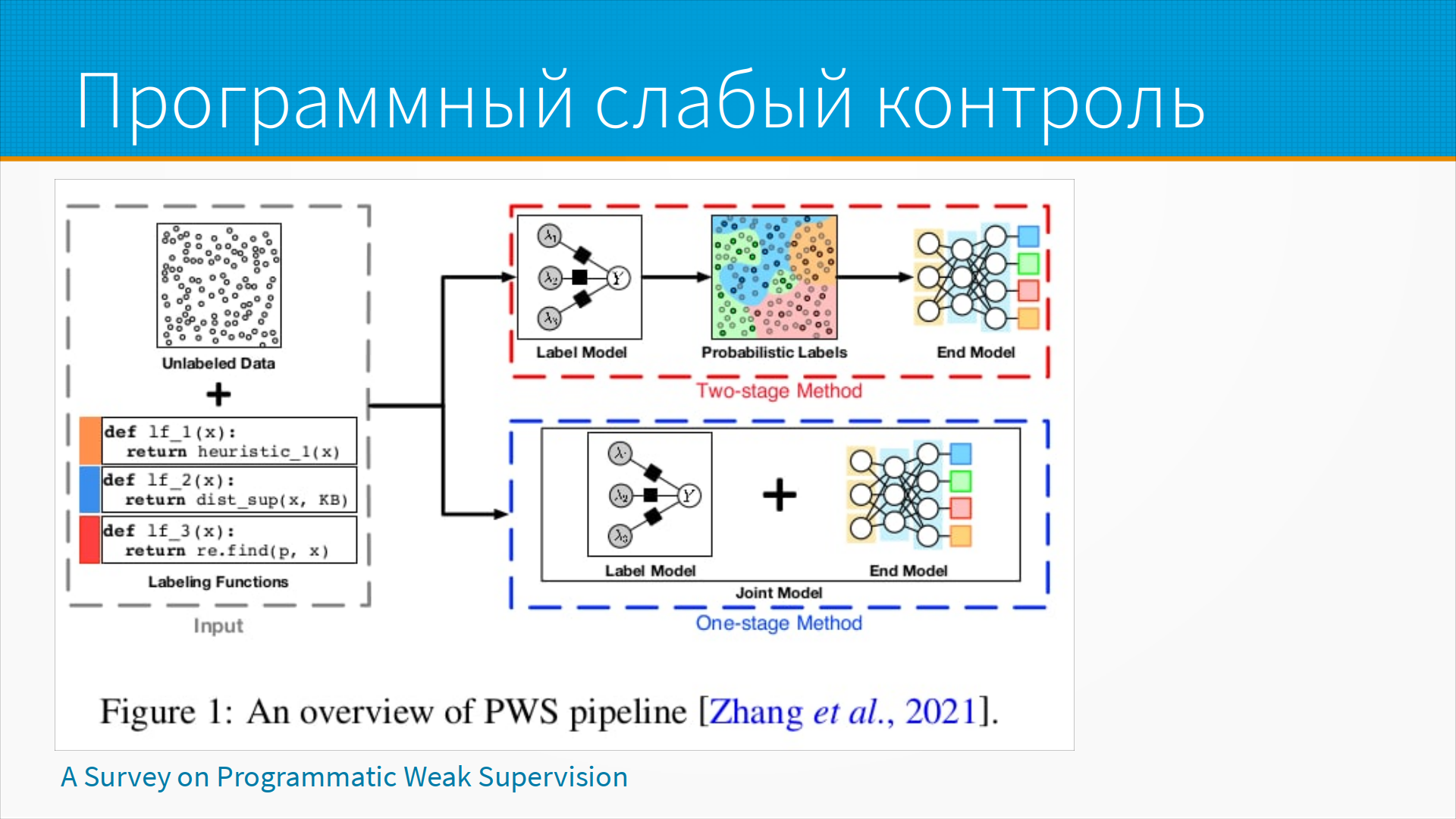 Тут есть два подхода.
Первый - это двухстадийный метод.
Первое - это мы учим вот эту модель разметки, то есть, когда наши простые правила говорят - скорее сработало, скорее не сработало.
Если правил много, допустим, у нас девять правил,
и четыре правила сказали - да, это скорее всего токсичный текст;
два правила сказали - это скорее всего не токсичный текст;
а остальные правила сказали - ну, мы не поняли, мы не знаем.
То есть разметка была на три класса.
И мы можем сказать, что вероятность того, что этот текст не токсичный - в данном случае одна третья.
То есть, два правила у нас сказали - не токсичный, четыре - токсичный.
Две третьих, что токсичный текст.
И мы получили так называемые мягкие вероятностные метки.
Тут есть два подхода.
Первый - это двухстадийный метод.
Первое - это мы учим вот эту модель разметки, то есть, когда наши простые правила говорят - скорее сработало, скорее не сработало.
Если правил много, допустим, у нас девять правил,
и четыре правила сказали - да, это скорее всего токсичный текст;
два правила сказали - это скорее всего не токсичный текст;
а остальные правила сказали - ну, мы не поняли, мы не знаем.
То есть разметка была на три класса.
И мы можем сказать, что вероятность того, что этот текст не токсичный - в данном случае одна третья.
То есть, два правила у нас сказали - не токсичный, четыре - токсичный.
Две третьих, что токсичный текст.
И мы получили так называемые мягкие вероятностные метки.
Тут отдельно сказать про вероятностные метки - бывает разметка данных жесткая, когда мы говорим, допустим, это токсичный текст или нетоксичный текст. Ноль или один. А бывает мягкая разметка, когда мы размечаем с некоторой вероятностью, что этот текст с вероятностью 0,6 у нас токсичный и с вероятностью 0,4 нетоксичный. Так вот, для того, чтобы учиться, моделям нужно на порядок меньше мягких меток, чем жестких. То есть, если у вас есть миллион жестких меток и сто тысяч мягких меток, то на ста тысячах меток модель научится, наверное, даже лучше, чем на миллионе жестких.
Вопрос, где эти мягкие метки взять? И вот, когда у нас есть несколько слабых лернеров, то есть моделей, которые простыми правилами размечают наши данные, мы можем из их ответов сформировать вероятностные метки. И по этим вероятностным меткам уже обучить конечную модель. Единственное, что наша конечная модель должна уметь работать с вероятностными метками - и в библиотеке Snorkel некоторое количество таких моделей, которые умеют работать с мягкими метками, есть.
В принципе, можно взять любую модель, которая позволяет взвешивать строки и заставить ее работать с вероятностными метками. Например, в логистической регрессии у нас есть вес каждой строки, и предположим, что мы хотим дать некоторой строке положительную разметку 0,8. Мы дублируем эту строку и включаем ее два раза. Один раз как, например, токсичный текст с весом 0,8, и второй раз как не токсичный текст с весом 0,2. Внутри модели эти веса используются просто при суммировании лосса, функции потерь. Поэтому мы получим те самые мягкие метки, и модель начнет учиться лучше. Другой подход - это когда мы учим конечную модель непосредственно на данных наших слабых разметчиков. Как это работает? Во-первых, это почти всегда нейронки. Данные слабых разметчиков можно рассматривать как некоторые эмбеддинги. Если у нас допустим, 9 функций разметки, а их может быть и 900, то где-то 0, где-то 1, то есть где-то спам, где-то не спам, где-то токсичный текст, где-то нетоксичный. И мы получили некоторый эмбеддинг, и на этом эмбеддинге мы уже можем учить нейронную сеть принимать решение. Это несколько более сложный, тяжелый в отладке способ, но он тоже хорошо работает.
Еще раз напомню, что при программном слабом контроле у нас случается магия. Мы учим, мы размечаем данные по правилам на одних признаках, а модель потом начинает учиться на других. Это нам не гарантируется, но почти всегда так получается, потому что признаки, удобные для модели и признаки, удобные для наших правил - это разные признаки. Обычно.
 Вопрос - как отбираем данные для обучения?
Как я уже говорил, данные стоят дорого, и часто нам нужно решить, какие взять - купить, собрать, разметить.
Тут есть несколько стратегий отбора.
Вопрос - как отбираем данные для обучения?
Как я уже говорил, данные стоят дорого, и часто нам нужно решить, какие взять - купить, собрать, разметить.
Тут есть несколько стратегий отбора.
Обычная стратегия отбора - мы просто берем все то, что доступно. Это не очень хороший подход, но на практике так поступают просто потому, что ничего другого не получается.
Иногда люди смотрят и говорят - нам бы в этот датасет добавить фотографии пешеходов на переходном переходе. Это эксперты решили, что это важно. Никакого обоснования - просто они так чувствуют.
Зачастую мы собираем данные примерно так же, как катают снеговика. То есть мы прочитали данные с одной страницы, пошли по всем ссылкам с этой страницы, собрали данные с этих страниц, потом пошли по ссылкам с этих страниц и так далее. Или обследовали одного человека, затем взяли всех людей, кто с ним контактировал в течение последних двух недель, обследовали их и так далее. Это подход, когда мы собираем данные по цепочке. И каждая точка данных нам говорит, какие еще данные взять.
Еще иногда мы можем определить некоторую квоту. Например, нам нужно, чтобы в нашем датасете для распознавания лиц, который будет работать в Северной Америке, было, например, 30% европейцев, 30% азиатов и 40% афроамериканцев. И так далее. То есть по каким-то внешним признакам у нас есть ограничения, сколько каких примеров нам нужно. И мы руководствуемся всеми этими ограничениями, когда собираем наш датасет.
 Затем, когда мы собрали наш датасет, нам нужно обычно поделить данные на обучающую и тестовую выборку.
И потом делить данные на фолды и так далее и тому подобное.
А когда мы учим нейронную сеть, нам нужно нарезать наш датасет на батчи.
То есть мы отбираем некоторое подмножество точек данных для каждого раунда обучения.
И тут стоит вопрос - как мы отбираем эти сэмплы, как мы сэмплируем из данных?
Затем, когда мы собрали наш датасет, нам нужно обычно поделить данные на обучающую и тестовую выборку.
И потом делить данные на фолды и так далее и тому подобное.
А когда мы учим нейронную сеть, нам нужно нарезать наш датасет на батчи.
То есть мы отбираем некоторое подмножество точек данных для каждого раунда обучения.
И тут стоит вопрос - как мы отбираем эти сэмплы, как мы сэмплируем из данных?
Одна из типичных проблем - это плохо отсортированные батчи. Например, предположим, что у нас есть модель, которая отличает кошечек от собачек. И есть много фотографий кошечек и собачек. Но как-то так получилось, что сначала в датасете у нас одни фотографии кошечек, а потом одни фотографии собачек. И мы сначала учим нейронную сеть на кошках, а потом на всех примерах собак. К тому моменту, как мы закончим ее учить на кошках и перейдем на собаках, она забудет, как выглядит кошка.
Для борьбы с этим данные хорошо бы перемешать, чтобы кошки с собаками попали в батчи в случайном порядке. Это не очень хороший вариант, но достаточно простой и быстрый. Вариант лучше - это стратифицированная выборка, то есть добиться того, чтобы в каждой выборке у нас был бы один и тот же процент кошек, один и тот же процент собак. Ну и скажем, если у нас там есть еноты, один и тот же процент енотов.
Стратифицировать выборку сложно. Особенно сложно, когда у нас задача multilabel, мультиразметки, когда у нас к одной точке может быть несколько меток. Например, мы как-то участвовали в соревнованиях, где на данных гистологии, то есть фотографии клеток под микроскопом, можно было определить, какие там органеллы есть. И была разметка на 28 классов. И просто стратифицировать аккуратно, чтобы все 28 несбалансированных классов были одинаково представлены во всех фолдах, было достаточно трудно. Мы написали распределение по фолдам, получилось красиво, хорошо, но очень медленно. Ну и, кстати, вопрос, как вы будете проверять равномерность распределения по фолдам - мы считали дивергенцию Кульбака-Лейбнера между фолдами и на нее ориентировались, так проверили качество распределения. Но мы сохранили распределение по фолдам и использовали его пресохраненным. А если бы нам нужно было в каждом батче это делать, у нас бы очень сильно тормозилось обучение нейронки.
Иногда нам какой-то класс важнее, чем другой, и тогда мы делаем взвешенную выборку. Например, стараемся, чтобы в каждом батче было хотя бы в два раза больше кошечек, чем собачек.
Иногда мы приоритизируем выборку по важности, потому что нам, скажем, эта ошибка обходится дороже, или потому что у нас примеров мало, или потому что мы с помощью Active Learning выяснили, что именно примеров этого класса нам не хватает, чтобы увеличить качество модели. То есть у нас может быть какая-то функция важности примеров, и мы делаем так, чтобы важных примеров в сэмпле было больше, неважных меньше.
Еще про сэмплирование выборки. Можно сэмплировать с возвращением и без возвращения. Это нелогично звучит, но если есть возможность, всегда сэмплируйте с возвращением. Сэмплируем с возвращением - это когда одна и та же самая точка данных может попасть в выборку несколько раз. Нейронные сети и алгоритмы на деревьях при сэмплировании с возвращением учатся лучше, сходятся быстрее, получаются более надежные, и в них меньше случайных зависимостей. На слайде есть ссылка на статью, где этот вопрос разбирается для нейронных сетей. Но вообще это общее правило: если есть возможность сэмплировать с возвращением - сэмплируйте с возвращением.
Отдельный пример, как сэмплировать в случае потоковых данных - то есть если вам, например, повезло работать с потоковыми данными, когда вам постоянно идет набор событий, например, с датчиков или кликстрим, а вам нужно выбрать представительную выборку какую-то из данных. А у нас сегодня с утра зашли, допустим, люди покупать одно, завтра люди покупать другое, потом люди пришли развлекаться - просто ходить по сайту, потом пришли какие-то еще люди из другой категории. То есть, например, с утра нам ходили дилеры покупать товары на сайт оптом, днем люди ходили в обеденный перерыв искать что-то для дома, вечером семейные покупки, ночью импульсивные покупки. То есть нам хотелось бы собирать сэмпл из потоковых данных более-менее представительным, но данные у нас идут неравномерные по времени. И вот тут есть такая техника, как reservoir sampling - когда мы выкидываем по определенным правилам данные из потока и собираем набор, который в любой момент готов для того, чтобы взять его в качестве сэмпла. Технология достаточно простая - например, мы случайно берем первые 100 точек и затем, по мере того, как к нам поступают новые данные, мы заменяем эти 100 точек случайным образом на новые. У reservoir sampling есть куча разновидностей, вот ссылка на статью, можно разобрать, как конкретно в вашем случае его делать.
 Есть популярная проблема и популярный вопрос - как быть с балансом классов.
Вообще, если вы чувствуете, что у вас проблема с балансом классов, то, скорее всего, вы где-то ошиблись.
Обычно проблема не в дисбалансе классов, а проблема в том, что у вас либо мало примеров для редких классов,
например, у вас все классы хорошо представлены, а для одного класса только 10 примеров - это проблема не дисбаланса, а просто примеров мало;
либо вы используете какое-то неподходящий функционал качества - например, вы считаете accuracy, процент правильных предсказаний,
но для несбалансированных классов это плохой выбор.
Есть популярная проблема и популярный вопрос - как быть с балансом классов.
Вообще, если вы чувствуете, что у вас проблема с балансом классов, то, скорее всего, вы где-то ошиблись.
Обычно проблема не в дисбалансе классов, а проблема в том, что у вас либо мало примеров для редких классов,
например, у вас все классы хорошо представлены, а для одного класса только 10 примеров - это проблема не дисбаланса, а просто примеров мало;
либо вы используете какое-то неподходящий функционал качества - например, вы считаете accuracy, процент правильных предсказаний,
но для несбалансированных классов это плохой выбор.
То есть, допустим, мы делаем детектор аномалий и у нас 1% плохих классов и 99% хороших, он работает хорошо. А если мы делаем классификатор на плохие и хорошие, то ему вычислительно выгоднее всегда говорить - это хороший вариант, и он будет в 99% прав, просто потому, что так устроена наша метрика. Как быть в таком случае? Надо использовать какие-нибудь вероятностные функционалы качества, например, binary cross-entropy, или, что в случае бинарной классификации то же самое, правдоподобие. У Дьяконова и Мельника хорошо разобрана эта проблема с описанием подходов. У Мельника вообще есть презентация по поводу того, что делать с дисбалансом классов. Ну и дисбаланс меньше, чем 10 к 1 - это обычно вообще не проблема, ничего специально делать не надо.
То есть, когда у нас проблема с дисбалансом классов, на самом деле у нас просто проблема с неправильной постановкой задачи.
 Тем не менее, что же с ним делать, если вы с этим дисбалансом столкнулись?
Ну, прежде всего - стратифицировать выборки. То есть, чтобы в каждом фолде, в каждом батче у вас были представлены классы более-менее равномерно.
Следующее, что следует попытаться сделать - это просто добыть больше данных для самого редкого класса, обычно именно он является проблемой. В большинстве алгоритмов есть механизм для взвешивания классов в loss-функции,
например, какой-нибудь class weight auto и тому подобное. Посмотрите в документации, часто при небольшом дисбалансе классов это отлично решает проблему.
Еще, как это у нас часто бывает, данные могут образовывать длинный хвост, когда есть несколько очень частых классов и много очень редких.
Иногда помогает объединение редких классов в один класс. То есть, мы, например, не можем выучить модель, отличить один редкий класс от другого,
но мы хотя бы можем сказать, что вот это что-то из частых классов, а вот это куча редких классов, пусть мы их как-нибудь по-другому будем делить.
Тем не менее, что же с ним делать, если вы с этим дисбалансом столкнулись?
Ну, прежде всего - стратифицировать выборки. То есть, чтобы в каждом фолде, в каждом батче у вас были представлены классы более-менее равномерно.
Следующее, что следует попытаться сделать - это просто добыть больше данных для самого редкого класса, обычно именно он является проблемой. В большинстве алгоритмов есть механизм для взвешивания классов в loss-функции,
например, какой-нибудь class weight auto и тому подобное. Посмотрите в документации, часто при небольшом дисбалансе классов это отлично решает проблему.
Еще, как это у нас часто бывает, данные могут образовывать длинный хвост, когда есть несколько очень частых классов и много очень редких.
Иногда помогает объединение редких классов в один класс. То есть, мы, например, не можем выучить модель, отличить один редкий класс от другого,
но мы хотя бы можем сказать, что вот это что-то из частых классов, а вот это куча редких классов, пусть мы их как-нибудь по-другому будем делить.
Для дисбаланса классов, как я уже говорил, отлично работают вероятностные метрики. То есть, если мы учим логистическую регрессию, у нее нет никакой проблемы с дисбалансом классов, просто с разным порогом у нее будут разного качества предсказания.
Еще мы можем насэмплировать, то есть добавить примеров редкого класса. Тут следует сэмплировать с возвращением, причем не один раз сэмплировать при подготовке датасета, а сэмплировать с возвращением во время каждого раунда обучения. Например, как делают при бутстрапе. Это позволит нам несколько нивелировать ту проблему, что мы будем одни и те же данные использовать много-много раз. Внутри библиотеки, например, catboost это происходит, то есть там при каждой итерации у нас идет сэмплирование с возвращением. Существуют функции потери, например, focal loss, которые специально построены так, чтобы работать с несбалансированными классами. Focal loss дает больше вес редким классам, у него есть хорошая реализация в TorchVision, но вообще его написать самим - 10 строк кода. И на Stack Overflow есть хороший пример, как его реализовать. Есть библиотека imbalanced-learn, где собраны разные сложные и простые интересные способы работы с балансом классов.
Но самый хороший способ - это все-таки попробовать найти дополнительных данных для редких классов вместо того, чтобы делать undersampling, SMOTE и так далее. На практике часто, когда мы используем какие-нибудь техники из imbalanced learning, мы просто переобучаемся на обучающие датасеты. Поэтому самый лучший подход - это все-таки добыть данные.
Иногда дисбаланс классов столь велик, что нам просто нужно переформулировать задачу. Если у нас в 10 000 примерах только 4 примера одного класса, а все остальные другого, нам нужно делать не классификатор, а детектор аномалий. Это будет хорошо работать и не будет никаких проблем с дисбалансом. Ну и на сегодня все.
 Дополнительные материалы:
Дополнительные материалы:
- Practice of Effective Fishing Data Collection via Crowdsourcing at Large Scale.
- Bayesian active learning for production, a systematic study and a reusable library
- A General-Purpose Crowdsourcing Computational Quality Control Toolkit for Python
- Can I use this publicly available dataset to build commercial AI software? Most likely not
- A Survey on Programmatic Weak Supervision