
- 07.09.2023
- 01.10.2025
- обучение
- #mlsystemdesign
Первая лекция открытого курса "Дизайн систем машинного обучения (2023)", "Машинное обучение на практике".
Слайды: mlsysd23-02.pdf
Текстовая расшифровка лекции (еще не вычитана, в процессе):

Добрый день, меня зовут Дмитрий Колодезев и это вторая лекция курса по дизайну систем машинного обучения. В этой лекции мы поговорим про основы проектирования ML-систем, выявление требований и основную проблематику проектирования систем.
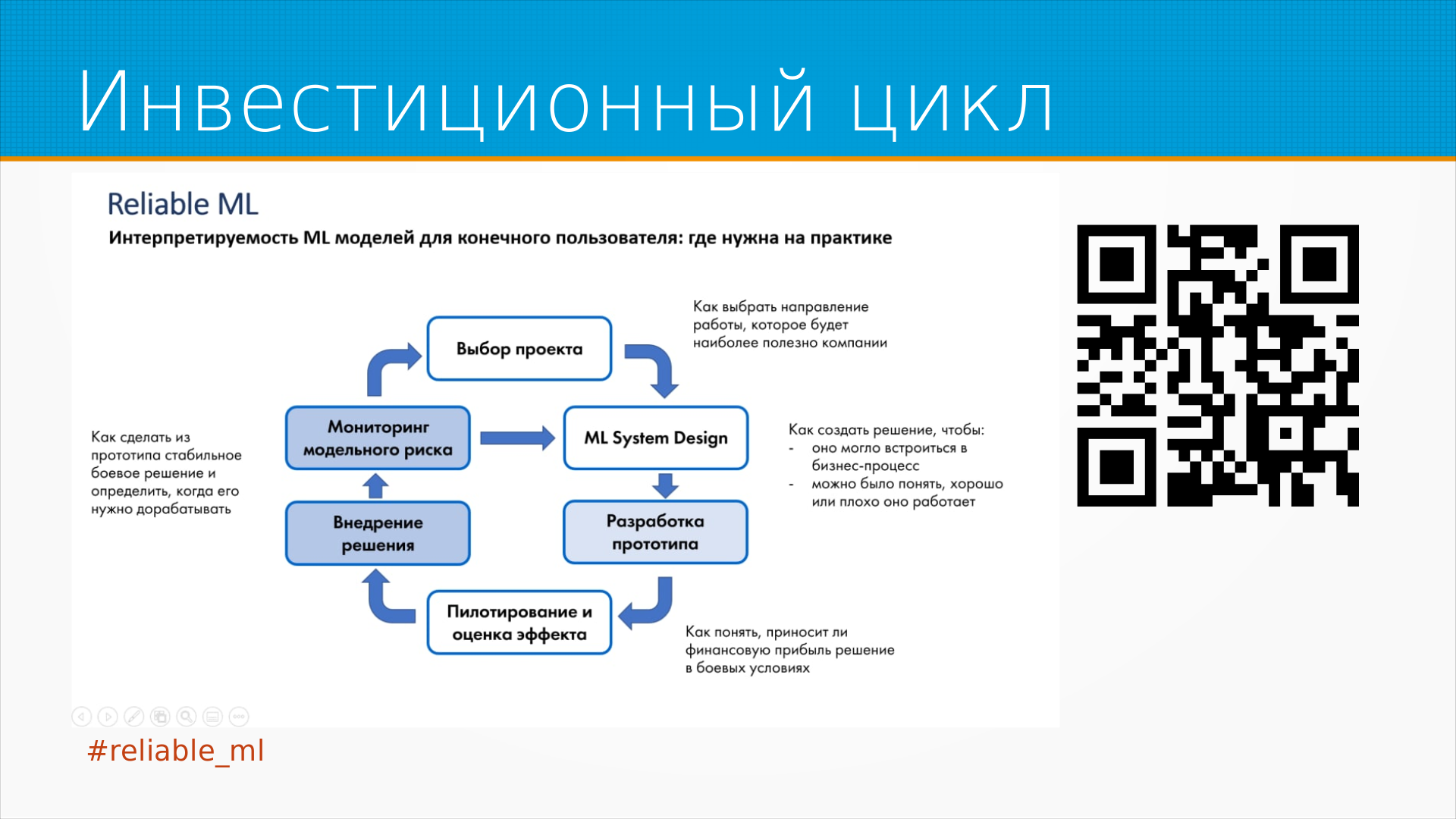
Прежде чем мы начнем проектировать нашу систему, нам хорошо бы убедиться, что эта система нам на самом деле нужна, потому что нам предстоит потратить на нее много времени, денег, ресурсов, нам с ней жить, и хорошо бы выбрать такой проект, в который организация могла бы вкладываться с пользой для себя. Как правило, большая организация имеет выбор из нескольких проектов, в которые она может вкладывать ресурсы, часто она одновременно вкладывает в несколько проектов. Если вы стартап, у вас обычно есть один проект, но у вас может быть несколько фич, которые вы хотели бы добавить туда, или может быть несколько подразделов вашего проекта, и вам в любом случае нужно выбрать направление работы, которое принесет как можно больше пользы. Что такое польза? В каждом конкретном случае это разные вещи. И все это является частью инвестиционного цикла, когда вы решаете вложить время, деньги, силы, придумываете, как это должно сработать, ML систем дизайн в нашем случае, разрабатываете какой-то прототип, проверяете, что это в принципе работает в маленьком объеме, пилотируем, внедряем, раскатываем всю организацию и мониторим то, что называется модельный риск, как мы поймем, что наша модель уже начала ошибаться, как мы поймем, что мир изменился и нам нужно все переделывать, или мы с самого начала сделали что-нибудь неправильно. И когда мы понимаем, что мы сделали что-нибудь не так, мы что-нибудь меняем в дизайне, разрабатываем новый прототип, пилотируем его и в общем идем по кругу инвестиционному циклу. Предполагается, что на каждом круге этого инвестиционного цикла мы приносим какую-то пользу.
 И когда мы решаем запускать проект
или нет, хорошо бы понять в принципе, что мы можем сделать, можем ли мы внедрить эти наши идеи в
текущие бизнес-процессы предприятия или пользователей, которым мы хотим это продавать или
предлагать. Можно ли проверить наши гипотезы на каком-нибудь маленьком объеме или нам нужно сначала
все запустить и потом уже смириться с тем, что она либо слетит, либо упадет. Можем ли мы посчитать
воздействие, эффект проекта на бизнес-процессы компании ключевые показатели и принесет ли он
денег, может ли он вообще быть достигнут результат в течение ближайших 12 месяцев. Если нет,
то организация может рассматривать это как стратегическое вложение сил. Если можно сделать что-то
быстро в течение года, но это совсем другое планирование бюджетирования. Затем является ли
именно этот проект приоритетным. С ML это вообще беда, потому что инженерам интересно делать
некоторые вещи, они видят проблемы, которые решаются с помощью ML и начинают их решать. Тогда
как может быть главная проблема для бизнеса вовсе не в ML, а например в финансах, в обучении
персонала или может быть во взаимодействии с регуляторами. Принесет ли проект положительный
результат, то есть будет ли у нас отдача от проекта больше, чем силы, которые мы в него запихаем.
Ну и как мы его будем внедрять, потому что некоторые очень хорошие проекты можем сделать,
но именно внедрить у нас их не получится. В принципе все эти вопросы задаются до того,
как мы приступаем к дизайну системы. Нам для того, чтобы сделать хорошую систему,
нам нужно знать ответы на эти вопросы.
И когда мы решаем запускать проект
или нет, хорошо бы понять в принципе, что мы можем сделать, можем ли мы внедрить эти наши идеи в
текущие бизнес-процессы предприятия или пользователей, которым мы хотим это продавать или
предлагать. Можно ли проверить наши гипотезы на каком-нибудь маленьком объеме или нам нужно сначала
все запустить и потом уже смириться с тем, что она либо слетит, либо упадет. Можем ли мы посчитать
воздействие, эффект проекта на бизнес-процессы компании ключевые показатели и принесет ли он
денег, может ли он вообще быть достигнут результат в течение ближайших 12 месяцев. Если нет,
то организация может рассматривать это как стратегическое вложение сил. Если можно сделать что-то
быстро в течение года, но это совсем другое планирование бюджетирования. Затем является ли
именно этот проект приоритетным. С ML это вообще беда, потому что инженерам интересно делать
некоторые вещи, они видят проблемы, которые решаются с помощью ML и начинают их решать. Тогда
как может быть главная проблема для бизнеса вовсе не в ML, а например в финансах, в обучении
персонала или может быть во взаимодействии с регуляторами. Принесет ли проект положительный
результат, то есть будет ли у нас отдача от проекта больше, чем силы, которые мы в него запихаем.
Ну и как мы его будем внедрять, потому что некоторые очень хорошие проекты можем сделать,
но именно внедрить у нас их не получится. В принципе все эти вопросы задаются до того,
как мы приступаем к дизайну системы. Нам для того, чтобы сделать хорошую систему,
нам нужно знать ответы на эти вопросы.
 И все начинается с того, зачем мы делаем проект,
как он принесет нам пользу. Проект может принести пользу каким-нибудь явным образом,
например в результате мы больше продаем, организация больше продает. Или например
организация экономит деньги, время, силы, может быть она экономит эмоции, то есть например
человеку нужно было лично принимать какие-то тяжелые решения, например о модерации контента или
что-либо, а сеть это делает за него, не иронка. И таким образом мы экономим не только время,
но и психику наших сотрудников, это тоже деньги и это тоже важно для организации.
Проект может приносить пользу неявно, увеличивая удовлетворенность пользователей. Например,
даже если система, которая автоматически отвечает на вопросы клиентов, не позволяет нам
сэкономить на колл-центре, тем не менее она может отвечать круглые сутки, тогда как колл-центр у
нас например работает в рабочее время. И таким образом формально мы ни одного работника колл-центра
не уволили, то есть мы не сэкономили, мы не получили новых денег, но наши пользователи, наши клиенты
стали более довольны и это то, чего мы допустим хотели бы достичь. Иногда нашему персоналу хорошо,
мы избавляем их от рутины и они готовы с нами работать, уменьшается текучка кадров,
они делают меньше глупых ошибок и так далее. Ну и есть совсем неявные примеры того,
как может внедрение ML или продвинутые аналитики принести пользу. Например,
увеличить инвестиционную привлекательность. То есть мы работали с одним проектом, который вообще
внедрил ML просто для того, чтобы в отчете для инвесторов было AI, то есть Artificial Intelligence. По
большому счету, если бы мы сделали что-нибудь, что позволило им на сервисе написать,
использует машинное обучение, то в общем-то они были уже довольны. Но мы старались перенести
пользу кроме этого. Еще иногда проект может помочь перенести операционные затраты в капитальные.
То есть предположим, что мы тратим миллион в месяц на модерацию контента, либо мы бы тратили
миллион в месяц на разработку системы, которая модерирует этот контент на разработку и ее развитие.
Но с точки зрения бухгалтерии, операционные затраты это вот убыток прямо здесь и сейчас,
а разработка системы это капитальные затраты, она встает на баланс организации, увеличивает ее
балансовую стоимость и так далее и тому подобное. То есть получается, что не всегда проект или
какая-то система строится для того, чтобы приносить деньги. Иногда она их неочевидным образом
экономит или приносит путем повышения привлекательности для кого-то из тех, с кем мы работаем.
И все начинается с того, зачем мы делаем проект,
как он принесет нам пользу. Проект может принести пользу каким-нибудь явным образом,
например в результате мы больше продаем, организация больше продает. Или например
организация экономит деньги, время, силы, может быть она экономит эмоции, то есть например
человеку нужно было лично принимать какие-то тяжелые решения, например о модерации контента или
что-либо, а сеть это делает за него, не иронка. И таким образом мы экономим не только время,
но и психику наших сотрудников, это тоже деньги и это тоже важно для организации.
Проект может приносить пользу неявно, увеличивая удовлетворенность пользователей. Например,
даже если система, которая автоматически отвечает на вопросы клиентов, не позволяет нам
сэкономить на колл-центре, тем не менее она может отвечать круглые сутки, тогда как колл-центр у
нас например работает в рабочее время. И таким образом формально мы ни одного работника колл-центра
не уволили, то есть мы не сэкономили, мы не получили новых денег, но наши пользователи, наши клиенты
стали более довольны и это то, чего мы допустим хотели бы достичь. Иногда нашему персоналу хорошо,
мы избавляем их от рутины и они готовы с нами работать, уменьшается текучка кадров,
они делают меньше глупых ошибок и так далее. Ну и есть совсем неявные примеры того,
как может внедрение ML или продвинутые аналитики принести пользу. Например,
увеличить инвестиционную привлекательность. То есть мы работали с одним проектом, который вообще
внедрил ML просто для того, чтобы в отчете для инвесторов было AI, то есть Artificial Intelligence. По
большому счету, если бы мы сделали что-нибудь, что позволило им на сервисе написать,
использует машинное обучение, то в общем-то они были уже довольны. Но мы старались перенести
пользу кроме этого. Еще иногда проект может помочь перенести операционные затраты в капитальные.
То есть предположим, что мы тратим миллион в месяц на модерацию контента, либо мы бы тратили
миллион в месяц на разработку системы, которая модерирует этот контент на разработку и ее развитие.
Но с точки зрения бухгалтерии, операционные затраты это вот убыток прямо здесь и сейчас,
а разработка системы это капитальные затраты, она встает на баланс организации, увеличивает ее
балансовую стоимость и так далее и тому подобное. То есть получается, что не всегда проект или
какая-то система строится для того, чтобы приносить деньги. Иногда она их неочевидным образом
экономит или приносит путем повышения привлекательности для кого-то из тех, с кем мы работаем.

В любом случае, если мы решили запускать проект, нам бы хорошо как-нибудь измерять то счастье, которое мы наносим нашим пользователям. Нам нужны какие-то метрики. Бизнес-метрики это как мы повлияем на ключевые показатели бизнеса. Например, прибыль увеличили или мы при той же прибыли, например, при той же норме прибыли увеличили нашу долю рынка и привлекательность для инвесторов. А на этом уровне наши любимые рукаук никому не интересны, то есть или точнее сказать интересны, любопытно конечно, что у меня рукаук больше, чем у соседа, но на самом-то деле не имеет у нас особенного смысла. Есть инженерные метрики, такие как, например, задержка предсказания, пропускная способность, опять же тот же самый рукаук. Тут другая сложность, то есть на проде при обучении рукаук мы можем измерить хорошо, а как мы измерим рукаук на проде, например. Особенно, если у нас предсказание приходит с некоторой задержкой, а как мы померяем accuracy, precision, перекол. Тут у Валеры Бабушкина есть хороший рассказ на датафесте, по-моему, или нет, это был нашей лая, был ML серийный митап, он рассказывал про деревометрик. Идея в том, что когда вы, допустим, строите систему в рамках какой-нибудь организации и говорите, вот я хочу увеличить рукаук, и менеджер, который выделяет вам деньги на это, говорит, ну хорошо, вот тебе, пожалуйста, занимайся чем-то. Но до тех пор, пока вы не простроите путь от вашего рукаук до конкретно ключевых показателей организации, которые вот этого менеджера заботят, вы будете таким проектом выходного дня, в том смысле, что вас запускают, пока нет других дел. Когда появится какой-нибудь Avral, вас снимут с проекта, может быть, закроют, когда финансовые показатели организации ухудшатся. То есть для того, чтобы представлять ценность для бизнеса, вам желательно простроить путь от этой самой лейтенсии или от рукаука до того, что непосредственно генерального директора беспокоит. Видео посмотрите, Валерий прекрасный.
 Зачастую мы не можем измерить нужные нам показатели. Ну, например, мы не можем измерить счастье
пользователя. Или иногда мы не можем измерить нужные нам показатели в нужное время. То есть потом
мы их узнаем, например, у нас приходят пользователи и берут, допустим, кредиты. И мы не знаем,
отдадут они кредит или нет. Мы узнаем это сильно позже. Нам бы хорошо какие-нибудь проксиметрики,
которые позволяют прямо сейчас понять, что все идет хорошо. Бывают анекдотические случаи. У
Microsoft, например, система контекстной рекламы в Bing как-то раз сломалась. То есть они выкатили
модель, которая делала не очень правильные рекомендации. И выручка от рекламы выросла, по-моему,
в трое локально. Потому что людям показывали ненужные рекомендации, и они вместо того,
чтобы по первой странице кликать, они их просматривали три. А у рекламной системы оплата шла за
показы. Поэтому, в принципе, то, что у вас локально выросла выручка, это не значит, что модель
работает хорошо. Наоборот, она может разрушать у вас бизнес. Просто сейчас еще пользователи ходят,
терпят, но вот они развернутся и уйдут, как, кстати, с Microsoft рекламой произошло. Многие
проксиметрики мы можем получить просто из знаний того, как работает бизнес. То есть,
например, в интернет-магазине есть какое-то количество страниц, которые пользователь просматривает,
прежде чем купить товар. И редко кто, например, просматривает меньше трех, редко кто больше 20.
Если человек просматривает больше 20 страниц, скорее всего, он ничего не купит. Если он просмотрел
меньше трех, то тоже, скорее всего, ничего не купит. Но конкретная цифра 3.20 зависит от вашего
бизнеса. В общем, такой ориентир. Иногда мы можем найти проксиметрики из корреляций в данных. То
есть, мы видим, что, например, когда счастье пользователей растет, они больше времени проводят на
веб-странице. Счастье пользователей мы меряем, допустим, опросами. Очень дорогая вещь. То есть,
опрос 5000 пользователей может спокойно стоить миллион рублей, может и 2 миллиона рублей стоить.
А время, проведенное на странице, мы получаем бесплатно из Яндекс.Метрики. И мы вдруг выяснили,
что эти показатели коррелируют. Ну хорошо, можем ориентироваться на более дешевую проксиметрику.
В целом, надо комбинировать машинное обучение, которое позволяет нам находить проксиметрики,
и знания о бизнесе. У RetailRocket, компании, которая делает рекомендательные системы для
интернет-магазинов, есть цикл статей на Хабре про проксиметрики. Прекрасные статьи рекомендуют.
Зачастую мы не можем измерить нужные нам показатели. Ну, например, мы не можем измерить счастье
пользователя. Или иногда мы не можем измерить нужные нам показатели в нужное время. То есть потом
мы их узнаем, например, у нас приходят пользователи и берут, допустим, кредиты. И мы не знаем,
отдадут они кредит или нет. Мы узнаем это сильно позже. Нам бы хорошо какие-нибудь проксиметрики,
которые позволяют прямо сейчас понять, что все идет хорошо. Бывают анекдотические случаи. У
Microsoft, например, система контекстной рекламы в Bing как-то раз сломалась. То есть они выкатили
модель, которая делала не очень правильные рекомендации. И выручка от рекламы выросла, по-моему,
в трое локально. Потому что людям показывали ненужные рекомендации, и они вместо того,
чтобы по первой странице кликать, они их просматривали три. А у рекламной системы оплата шла за
показы. Поэтому, в принципе, то, что у вас локально выросла выручка, это не значит, что модель
работает хорошо. Наоборот, она может разрушать у вас бизнес. Просто сейчас еще пользователи ходят,
терпят, но вот они развернутся и уйдут, как, кстати, с Microsoft рекламой произошло. Многие
проксиметрики мы можем получить просто из знаний того, как работает бизнес. То есть,
например, в интернет-магазине есть какое-то количество страниц, которые пользователь просматривает,
прежде чем купить товар. И редко кто, например, просматривает меньше трех, редко кто больше 20.
Если человек просматривает больше 20 страниц, скорее всего, он ничего не купит. Если он просмотрел
меньше трех, то тоже, скорее всего, ничего не купит. Но конкретная цифра 3.20 зависит от вашего
бизнеса. В общем, такой ориентир. Иногда мы можем найти проксиметрики из корреляций в данных. То
есть, мы видим, что, например, когда счастье пользователей растет, они больше времени проводят на
веб-странице. Счастье пользователей мы меряем, допустим, опросами. Очень дорогая вещь. То есть,
опрос 5000 пользователей может спокойно стоить миллион рублей, может и 2 миллиона рублей стоить.
А время, проведенное на странице, мы получаем бесплатно из Яндекс.Метрики. И мы вдруг выяснили,
что эти показатели коррелируют. Ну хорошо, можем ориентироваться на более дешевую проксиметрику.
В целом, надо комбинировать машинное обучение, которое позволяет нам находить проксиметрики,
и знания о бизнесе. У RetailRocket, компании, которая делает рекомендательные системы для
интернет-магазинов, есть цикл статей на Хабре про проксиметрики. Прекрасные статьи рекомендуют.

У наших ML-систем в сердце стоят ML-модели. У ML-моделей есть ML-метрики. То есть, все эти F1 и RocAUC. Нам их тоже нужно мерить, и встает вопрос, какие метрики нам нужны и как мы их будем измерять. Еще не менее важно, с чем мы их будем сравнивать. В учебных задачах обычно нас просят минимизировать, допустим, среднеквадратичное отклонение. Но в реальной жизни цены ошибки обычно вверх и вниз сильно не сбалансированы. То есть, они стоят по-разному. Например, если вы дали кредитов чуть меньше, чем могли, вы, допустим, кредитная организация, это ничего. Если вы дали кредитов чуть больше, чем могли, то у вас получился финансовый, кассовый разрыв. То есть, у вас деньги кончились внезапно. Если вы, например, дали кредит не тому заемщику, вы потеряли много денег. Если вы не дали кредит тому заемщику, которому надо было, вы не заработали немножко денег. То есть, обычно цены ошибки, они разные. И просто так считать среднеквадратичную ошибку обычно некорректно. Как понять, в какую сторону ошибка сколько стоит? Это хорошо бы, конечно, уточнить у бизнеса. То есть, у тех людей, которые понимают, как керосин в лампочку попадает, то есть, как ваша модель будет приносить деньги. Вот тут мы возвращаемся к тому видео с Валерием и деревом Метриковым. Зачастую, кроме требований к качеству модели, нам бы хорошо знать, насколько модель уверена в своем предсказании. Чтобы, например, когда модель выдает неуверенные предсказания, сообщать пользователю. Знаешь, вот мы тебе такое вот рекомендуем, но мы не уверены в нем. Иногда нам масштабируемость важнее качества модели. То есть, ну такой совсем игрушечный случай. Логрек очень дешев и достаточно неплохо работает. Для многих задач его можно запустить на разберепай. Тогда как ту же самую задачу можно решать нейронной сетью, и тогда вам понадобится мощный сервер, и вы сервером сможете обслуживать сто человек одновременно, не больше. Логреком могли бы обслуживать десять тысяч. Тут в шутку приведена картинка с разными типами ошибок. На самом деле, люди все время путаются с первым и вторым типом ошибок.

Где брать бейзлайн? То есть, с чем сравнивать ваше качество вашей модели? Самый хороший бейзлайн это существующие на рынке решения. Проблемы существующих на рынке решений те, что все пририсовывают себе качество, которого они на самом деле не достигают. В статьях, например, state of the art решения это обычно какой-нибудь читинг на дата-сети. То есть, реально такого качества они получить в продуктовом окружении не могут. Поэтому хорошо бы взять и как-нибудь использовать чужое решение, оценить качество, сравнить качество с простым решением на правилах. То есть, например, опять же вот тот самый кредитный скоринг. Если мы просто начнем выдавать кредиты всем людям, у которых нет других кредитов и, допустим, заработок в полтора раза выше среднего. Понятно, что это очень плохой подход, но насколько идеальный скоринг улучшит доход организации сравнительно с вот этим плохим доходом. То есть, какой-нибудь бейзлайн у вас все равно должен быть. Обычно сравнивают с тем, как проблему решают люди. И тут есть подводная камня. Дело в том, что люди и ML-модели ошибаются в разных местах. Поэтому, с точки зрения человека, часто ML-модель, решение ML-модели выглядит чудовищно. Как она делает такие глупые ошибки? Она, правда, не делает таких ошибок, которые делает сам человек, но люди не привыкли там проверять, где они. Не знают, что может быть ошибка. Поэтому на качество решения людей можно ориентироваться, но так сложно. Качество решения конкурентов – это хорошо. Хороший бейзлайн.
 Про разную цену ошибки
мы уже говорили, но есть очень разные цены. То есть, например, в некоторых случаях некоторые ML-модели
могут убить человека, если примут какое-нибудь неправильное решение. Такой книжный пример – это
система радиотерапии, которая убила как минимум пятерых пациентов за счет плохого интерфейса. То
есть, там была не ML-модель, но стояла там ML-модель, она точно так же могла убивать людей. То есть,
реально наши системы могут убивать людей. Медицинские системы уж точно. Системы, допустим,
пилотирования на Боинге, на Супермакс, который разбился в Индонезии, ошибались при попытке помочь
пилоту при взлете. И тоже убивали людей прям сотнями. Вот недавно было. Есть история, когда
наше модель, неправильное решение модели не создает ущерба какому-то пациенту, но она делает ему
неудобно. То есть, например, вот у нас есть рекомендательная система на сайте интернет-магазине,
и она рекомендует какую-нибудь ерунду, и человек вынужден руками искать этот товар. То есть,
в принципе, ничего страшного не произошло, но ему неудобно стало. Он в следующий раз, может быть,
к нам не пойдет. Еще иногда мы не знаем, что что-то нужно измерять. То есть, например, если вы
работали с e-commerce, вы знаете, что там одна десятая доля ответа секунды для поисковика, это важно.
То есть, вы на каждой десятой доле секунды несколько процентов трафика теряете с поиска. Но если
вы раньше с этим не сталкивались, как вы знаете, что вам нужно оптимизировать модель не только по
качеству, но и по скорости отдачи, потому что просто к вам люди перестанут ходить.
Про разную цену ошибки
мы уже говорили, но есть очень разные цены. То есть, например, в некоторых случаях некоторые ML-модели
могут убить человека, если примут какое-нибудь неправильное решение. Такой книжный пример – это
система радиотерапии, которая убила как минимум пятерых пациентов за счет плохого интерфейса. То
есть, там была не ML-модель, но стояла там ML-модель, она точно так же могла убивать людей. То есть,
реально наши системы могут убивать людей. Медицинские системы уж точно. Системы, допустим,
пилотирования на Боинге, на Супермакс, который разбился в Индонезии, ошибались при попытке помочь
пилоту при взлете. И тоже убивали людей прям сотнями. Вот недавно было. Есть история, когда
наше модель, неправильное решение модели не создает ущерба какому-то пациенту, но она делает ему
неудобно. То есть, например, вот у нас есть рекомендательная система на сайте интернет-магазине,
и она рекомендует какую-нибудь ерунду, и человек вынужден руками искать этот товар. То есть,
в принципе, ничего страшного не произошло, но ему неудобно стало. Он в следующий раз, может быть,
к нам не пойдет. Еще иногда мы не знаем, что что-то нужно измерять. То есть, например, если вы
работали с e-commerce, вы знаете, что там одна десятая доля ответа секунды для поисковика, это важно.
То есть, вы на каждой десятой доле секунды несколько процентов трафика теряете с поиска. Но если
вы раньше с этим не сталкивались, как вы знаете, что вам нужно оптимизировать модель не только по
качеству, но и по скорости отдачи, потому что просто к вам люди перестанут ходить.

Ну и требования к качеству модели – это такая сферическая вещь в вакууме. У самого управляемого автомобиля, например, высокие требования к качеству. Вам нужно его тщательно тестировать, проверять, потому что он выедет на дорогу и кого-нибудь убьет. А у тех же самых поисковых подсказок при вводе текста требований низкие по качеству, потому что если человек увидит подсказку, которая ему, скажем, в телефоне, какая-нибудь подсказка будет неприемлемая, но он посмеется, сделает скриншот, раскидает по друзьям, сам наберет буковками то, что ему нужно. Если рекомендации в интернет-магазине будут неподходящие, человек пойдет и найдет то же самое просто поиск.
Как формализовать требования к качеству? Опять же дерево-метрик – попробовать выразить качество в деньгах, то есть насколько вырастет прибыль, если увеличить курс на один процент. Это частый момент при переговорах с заказчиком о качестве. Мы аутсорсеры, поэтому для меня это больная тема. И заказчик всегда требует 105 процентов качества, иногда 110. И ты ему говоришь, ну вот, слушай, вот есть 95 процентов качества, сколько ты потеряешь от того, что их, допустим, не 98, не 96. Зачастую получается, что поскольку вообще в принципе ML обычно это быстрое и дешевое принимать более-менее неплохие решения среднего качества, не очень важное, то где-нибудь может быть 95 процентов качества. Вот в этом конкретном случае все равно, что 100. Никто не заметит разницы. Но для того, чтобы достигнуть 99 процентов, вам придется потратить в 10 или в 100 раз больше времени, сил, денег.

Это все возвращает нас к дизайну систем машинного обучения. После того, как мы решили, что мы идем в проект и определились, каких целей нам нужно достичь, нам нужно принять решение про интерфейсы, алгоритмы, данные, программную инфраструктуру и оборудование, чтобы соответствовать требованиям к надежности, масштабируемости, обслуживаемости, адаптированности, ну еще какие-нибудь требования.

Если у нас нет ограничений, нам не нужен дизайн, то есть как ни сделай, все равно будет хорошо. И вообще ограничения это частный случай требований к программному обеспечению. Наши ML-системы это тоже программное обеспечение, ничем они особенно не выделяются. Источниками требований, тут я цитирую Software Engineering Body of Knowledge, являются цели бизнес-задачи, то есть чего собственно говоря бизнес хочет достичь, иногда оттуда приходят требования. Есть какие-то знания предметной области, что все клиенты такого-то сервиса ждут вот это. Есть заинтересованные лица проектов, у них есть какие-нибудь потребности, то есть например оператору в колл-центре хочется, чтобы его система, которая подсказывает ему ответ, была удобной, а например тому, кто платит за разработку этой системы, хочется, чтобы клиенты меньше жаловались или больше покупали продуктов, то есть больше покупали услуг. То есть немножко разные пожелания. Есть бизнес-правила и регулирование. Многие отрасли зарегулированы по самые не хочу, например медицинские отрасли, банковская отрасль, безопасность. Окружение, в котором будет работать система, тоже является сильнейшим источником требований. Например, если у организации уже есть система хранения данных, то выбор базы данных системы хранения упрощается, использовать то, что под рукой. Капитальные затраты уже понесены и теперь вас заставят использовать эту систему, даже если она не самая оптимальная. Это история, в которой живет ходуб. Организации, которые создают и эксплуатируют систему, сами по себе являются сильнейшим источником ограничений. И давайте вот разберем эти моменты подробнее.

Самый простой и просчитываемый вариант это железное ограничение. То есть у нас всегда ограничена пропускная способность сети, интерфейса между, допустим, сетевой картой и, между видеокартой и материнской платой, интерфейс памяти, интерфейс к устройству хранения. Место для хранения у нас ограничено. Скорость поиска и произвольного доступа на разных устройствах у нас тоже не может быть мгновенной. Как Брукс говорил, даже 9 женщин не уйдет вам ребенка за один месяц. Размер оперативной памяти, хотя сейчас память дешева, но все равно в один сервер вы запихаете какое-то конкретное количество. Кэша всегда мало. Видеопамяти в видеокартах редко бывает больше 100 гигабайт. То есть вам все время есть какие-то ограничения, с которыми вы не можете справиться никак. То есть они просто заданы, как гравитация. Структура хранилища и условия доступа к нему. Есть ситуации, когда вы используете, например, для долговременного хранения какой-нибудь холодный сторидж в Амазоне, и хранение там дешево, но чтобы получить данные назад, вам придется ждать долго. Есть сторидж с мгновенным доступом, но доступ туда дорогой. То есть вы выбираете хранилище по требуемой вам скорости доступа, балансируя, скажем, со стоимостью. Задержки между обращениями. То есть, например, вы не можете беспрерывно, как у нас происходит общение по сети, то есть ваша система отправляет пакет, он идет, обрабатывается, приходит вам ответ. И у вас, даже если вы думаете, что вы непрерывно передаете данные, все равно они как-то квантуются в разных системах по-разному. И тут, к сожалению, без знания того, как оно квантуется в конкретном железе в вашей системе, вам не разобраться и с этим просто надо столкнуться будет. А систематические отказы оборудования. Что я тут имею в виду? Предположим, что у нас отказывается сервер, в среднем работает, например, три года. Если у вас тысяча серверов, это значит, что в среднем у вас хотя бы один сервер ломается. То есть вам нужно закладываться на то, что часть ваших инстансов будет отваливаться. На самом деле гораздо чаще. Мы в свое время ради экономии вычтительных ресурсов запускали системы на эфемерных инстанциях в Амазоне. Это инстанции вытесняемые, которые Амазон продает примерно в 10 раз дешевле, чем все остальное. Но как только ему не хватает вычтительных ресурсов для клиентов, которые платят полную цену, он, ваш инстанц, отбирает у вас и отдает тому, кто заплатил дороже. И даже в этих условиях можно на этих инстанциях запустить вполне отказоустойчивую систему, балансировать между ними трафик. Получите ту же самую вычтительную мощность, но в несколько раз дешевле. Есть ограничения по энергоснабжению и охлаждению. То есть, например, в тех же самых самоуправляемых автомобилях это вовсю проблема, потому что, допустим, у вас 5 киловаттный сервер под капотом. Его надо охлаждать, его нельзя, наверное, трясти, его надо чем-то питать. Это отнимает мощность двигателя и так далее. Я уж не говорю про какие-нибудь носимые устройства. То есть, вы, допустим, делаете веб-камеру, вы не можете запихать туда современные нейронки без того, чтобы специально не присесть. Просто потому, что у нее недостаточно вычтительной мощности, недостаточное энергоснабжение и недостаточное охлаждение. Мы делали системы мониторинга посетителей на Raspberry Pi, и все это было здорово, только охлаждать их приходилось специально, потому что она не предназначена для того, чтобы работать беспрерывно. То есть, это вот такие вот есть вещи, с которыми вы начинаете сталкиваться, когда вас ограничивают по энергоснабжению и охлаждению. Сталкиваются с этим и маленькие устройства, и носимые большие дата-центры.

Пример ограничений, которые возникают как слон в посудной лавке. Пусть у нас есть сервис, который считает посетителей на видео, и мы его будем продавать магазинам. У магазина небольшого стоит какое-то количество видеокамер, которые снимают людей, и мы людей на камере считаем. Например, YOLO. То есть, как бы технически ничего сложного нет. Берете видеопоток, ищите на нем посетителей, отдаете цифры. На старте у нас будет, допустим, 10 клиентов, а через год мы хотели бы иметь хотя бы 100, иначе зачем это все. У каждого клиента будет от 1 до 100 камер, в среднем 20. Видеопоток с камеры нормальный 6,5 мегабит в секунду. Ну то есть, мы берем нашего самого хорошего клиента со 100 камерами, и понимаем, что он должен в интернет на наш сервис отдавать 650 мегабит. Редко у кого интернет 650 мегабит на отдачу, да еще и свободный. С другой стороны сидим мы, и у нас 100 клиентов, 2000 камер, нам приходит 13 гигабит в секунду нашего сервера гигабитная сетевая карта. Мы не можем принять одним сервером этот трафик, в принципе. На слайде, кстати, калькулятор трафика с IP камер. Вот пример, когда задача в первоначальной постановке, в принципе, неразрешима. Какой бы мы ни сделали мощный сервер, 13 гигабитную карту мы то не запихаем. В принципе, в облаке, допустим, гугла можно и 50 гигабит обработать. Это само по себе не проблема, но это уже не отдельный сервер, это уже облачная архитектура.

Что мы можем сделать с такими ограничениями? Тут тоже пример высосанный мз пальца, но сам по себе подход рабочий. То есть, во-первых, мы можем уменьшить видеопоток. Пусть у нас будет не 6,5 мегабита, а 1 мегабит. Для клиентов с 36 камерами и больше мы поставим свой сервер на их площадке. Таких клиентов, допустим, у нас будет 10. Когда клиент собирается лить нам видео, пусть он обращается на специальный сервер, где ему выделят один из наших ненагруженных серверов для работы с видео. Кстати, так ВКонтакт делает при заливке картинок. То есть, вы или, во всяком случае, раньше делал, когда я последний раз заливал во ВКонтакт картинки программно. Вы сначала получаете адрес сервера, на который будете заливать картинки. Вам дают какой-нибудь адрес вспомогательного сервера, и туда уже вы заливаете картинки. Итого получается у нас средний трафик с клиента 5 мегабит, и пол гигабита в секунду вполне подъемно. Если разделить на несколько серверов, то это будет даже отказоустойчиво. Балансировку этого трафика можно доверить облаку. Ну и лучше, конечно, такие вещи считать прямо внутри веб-камеры. Ну и опять же встает вопрос, что внутри веб-камеры мы не можем использовать какие-то круто навороченные модели. Ну, кстати, YOLO, наверное, мы в Raspberry Pi вполне можем использовать.

У нас есть бизнес-ограничения. Например, время ответа системы. То есть, если наша ML-модель, рекомендательная система, отвечает дольше, чем, например, 0,3 секунды, пользователь видит, что сайт тормозит. Если подсказка в поисковой строке, когда пользователь набирает, ему рекомендуют подсказку, показывается медленнее, сильно медленнее, чем он сам печатает, его будет раздражать такая подсказка. То есть время ответа системы важная деталь. Требуемая пиковая нагрузка, то есть сколько пользователей к нам придет. Вот там пример с видеокамерами, он был достаточно простой, предполагалась равномерная нагрузка. Но предположим, что у вас есть сервис, который подбирает мем по погоде и политической обстановке. И вот каждое утро вся Москва приходит и запускает ваше приложение в 8.30 на работе, чтобы посмотреть мем дня. Таким образом, у вас нагрузка в целом маленькая, но в эти 8.30 у вас сервера лежат. Требование к стоимости обработки, то есть, например, если у нас транзакция приносит нам 100 рублей, она не должна требовать для обработки 150 рублей. Требование к надежности. Это мы обсуждали с ломающимися серверами. Требование к поддерживаемости. Насколько у нас получится поддерживать систему. То есть, если мы, например, делаем программное обеспечение ML-модель для встроенной системы, ее прошлют в прошивку и разошлют по всему миру. Как мы потом будем обновлять эту ML-модель? Требование к квалификации персонала. Если заказчик до этого справлялся низкоквалифицированным персоналом, а теперь ему внезапно понадобится IT-отдел просто для того, чтобы эксплуатировать нашу систему, он будет не рад.

Есть организационное ограничение, как раз это продолжение истории с персоналом. Мы не можем разработать систему, если у нас нет людей, знакомых с такими технологиями. То есть, когда мы выбираем технологии, мы выбираем их не только насколько они хороши для решения нашей задачи, но и насколько у нас есть люди, насколько они умеют с этим работать. Если у нас есть программисты на Go, пишем на Go. Если у нас есть программисты на Python, пишем на Python, что поделать же. Уже имеющиеся организации инфраструктуры, системы хранения, сервера переиспользуем по максимуму. Всегда есть ограничения на деньги, есть процессное ограничение. Некоторые организации, например, просто не умеют в CI-CD. Они затрудняются раздеплоить уже готовую модель. Некоторые, например, как мы, строят системы, в которых можно деплоить пять раз в день. Некоторые организации вынуждены деплоить раз в несколько месяцев. Например, люди, которые обновляют программное обеспечение на спутниках, они очень ограничены в возможности деплоя. Но весь остальной мир где-то посередине между нами и спутниками. Большое ограничение – это время. Иногда нам нужно срочно успеть к какому-нибудь распродаже, к введению закона, к запуску продукта конкурентам. И о времени правильно думать, что одна пятая уйдет у вас на разработку решения, и четыре пятых у вас уйдет на то, чтобы действительно его запустить. Время обычно можно купить, обеспечив разработчиков более мощными серверами, больше людей на разметку, купить в разработку. Но самый хороший способ купить время – это купить готовое решение. Понятно, что для многих бизнесов их ML-модель – это их ключевое преимущество, но зачастую вы можете купить готовый сервис по анализу картинок у Яндекса, у Гугла, у Амазона и просто навернуть поверх него какую-нибудь обертку. Она будет не так хорошо работать, как если бы вы обучились на данных вот этого конкретного вашего заказчика, на вашем бизнес-кейсе. Она будет работать хоть как-то, это будет очень быстро, и вы сможете быстро получить обратную связь и узнать что-то важное о бизнес-процессах.

Существующие системы, они с одной стороны – благо, с другой – проклятие. То есть, если у вас уже есть мощная Windows инфраструктура, а вы такие заказчики говорите, знаете, мы программируем только под Linux, все наши решения работают только под Linux, он будет вам не рад. Есть проблема интеграции в существующие системы. У них есть свои разработчики, и эти разработчики, может быть, не хотят, чтобы вы лезли в их баз данных своими руками грязными. То есть, бывает проблема получить данные, бывает проблема отдать данные в систему. То есть, например, у вас есть предикт, а как его дотащить до конечного пользователя? Его нужно куда-то загрузить, чтобы система какая-то его использовала. Зачастую у пользователя уже есть система, которая как-то криво-косо решает проблему. И для того, чтобы переключиться на вашу систему, он должен быть уверен, что ваша новая система лучше, чем его существующая. И вот это вот пилотирование бывает трудно организовать. По максимуму надо использовать имеющуюся инфраструктуру. Всегда надо помнить про то, что пользователей и операторов системы вам придется учить. И помните, что какие бы бизнес-процессы ни были, с какими бы бизнес-процессами вы не столкнулись, все изменится. То есть вам скажут, что мы делали так всегда, и всегда так будем делать, и завтра выйдет закон, который заставит их поступать иначе. Поэтому смотрите на бизнес-процессы существующие, но будьте готовы к тому, что все изменится.

Отдельная тема это compliance. Соответствие текущему законодательству правилам. Тут бывают проблемы прямо в неожиданных местах. Можем ли мы отдать медицинские данные на разметку, на толоку? Скорее всего не можем. Можем ли мы хранить медицинские данные в облаке? Непонятно. Скорее всего не можем, тем более зарубежно. В какой стране мы должны хранить данные? Тут принято вспоминать требования нашего Роскомнадзора о локализации данных. На самом деле мы работали с клиентами из Австралии, и у них регуляторов точно такие же требования. Мы мигрировали нашу систему из гугловских серверов, которые расположены в Америке, на гугловские же сервера, расположенные в Австралии, потому что такое было требование австралийского регулятора. Иногда мы не можем собирать какие-то данные пользователей, и тут тоже не только наш закон о персональных данных, это еще цветочки сравнительно с калифорнийским, например, законом о персональных данных или некоторыми изысками GDPR европейского. Обязаны ли мы шифровать данные? То есть иногда мы не имеем права хранить данные нешифрованными. У Google Cloud, например, есть интересная возможность хранить данные шифрованные их ключами, либо предоставлять свои ключи, и даже тогда у Google Cloud нет доступа к вашим данным. Но опять же, в ряде случаев мы не имеем права использовать сторонние сервисы, должны реализовывать у себя, по каким-нибудь соображениям безопасности. И всегда надо узнавать, какие законы существуют, какие вообще законодательные ограничения существуют в этой конкретной предметной области, вы можете неприятно удивиться, они на ровном месте возникают, в самых неожиданных для вас местах.

Что касается тех требований, которыми наша система должна удовлетворять, первое из них, конечно, это надежность. Ну, после того, как мы сделали то, что от нас просят, всем хотелось бы, чтобы мы делали это надежно. Что такое надежность? Это свойство объекта сохранять во времени в установленных пределах значение всех параметров, его характеризующих. То есть, попросту говоря, если наша система обрабатывала 100 запросов в секунду, она должна продолжать обрабатывать 100 запросов в секунду, и это есть надежность. Тут есть проблемы мониторинга, как мы поймем, что оно нормально работает. Есть чисто понятийные проблемы. Наша модель может выдавать ошибочный предикт, и если у нас длинная петля обратной связи, то есть мы очень долго узнаем, что предикт был правильный или неправильный, мы модель тогда на этом не поймаем. В общем, подробнее будет в лекции про мониторинг, про это есть отдельная лекция.
 Проблема масштабируемости — это если вам сильно повезет и ваш
сервис окажется нужен людям, вам придется справляться с растущим объемом трафика и объемом
данных. Но масштабироваться часто приходится не только по трафику и объему данных. Если ваш
сервис будет работать и приживется в организации, его начнут использовать неожиданным образом,
то есть будет расти количество сценариев использования, и модель у вас тоже будет не одна,
а одна, две, три, пять, десять, то есть у вас будет много моделей, много сценариев использования.
Есть интересное такое шутливое правило, что если у вас много пользователей, то любое недокументированное
поведение вашего API какой-то использователь на него заложился и использует. То есть вы что-то
исправили в вашем API, это нигде не обещано, нигде не документировано, и тем не менее у кого-то
что-нибудь сломалось. Хороший пример — это недавно чат GPT, было много статей про то, что качество
кода, который генерирует чат GPT, резко упало, что она поглупела. При внимательном рассмотрении
выяснилось, что они просто стали возвращать код в кавычках. Раньше возвращали без кавычек,
и естественно никто об этом не предупредил тех, кто генерирует код с помощью чат GPT. Таким образом,
как бы нигде недокументированное поведение, возвращается код в кавычках или не возвращается,
сломала системы, которые на это полагались. Мы обсудим проблему масштабируемости в дальнейших
лекциях.
Проблема масштабируемости — это если вам сильно повезет и ваш
сервис окажется нужен людям, вам придется справляться с растущим объемом трафика и объемом
данных. Но масштабироваться часто приходится не только по трафику и объему данных. Если ваш
сервис будет работать и приживется в организации, его начнут использовать неожиданным образом,
то есть будет расти количество сценариев использования, и модель у вас тоже будет не одна,
а одна, две, три, пять, десять, то есть у вас будет много моделей, много сценариев использования.
Есть интересное такое шутливое правило, что если у вас много пользователей, то любое недокументированное
поведение вашего API какой-то использователь на него заложился и использует. То есть вы что-то
исправили в вашем API, это нигде не обещано, нигде не документировано, и тем не менее у кого-то
что-нибудь сломалось. Хороший пример — это недавно чат GPT, было много статей про то, что качество
кода, который генерирует чат GPT, резко упало, что она поглупела. При внимательном рассмотрении
выяснилось, что они просто стали возвращать код в кавычках. Раньше возвращали без кавычек,
и естественно никто об этом не предупредил тех, кто генерирует код с помощью чат GPT. Таким образом,
как бы нигде недокументированное поведение, возвращается код в кавычках или не возвращается,
сломала системы, которые на это полагались. Мы обсудим проблему масштабируемости в дальнейших
лекциях.

Важная характеристика системы — это ее обслуживаемость, то есть насколько хорошо она приспособлена к тому, чтобы вы ее починили. Что, собственно, может сломаться в программной системе? Она ведь как бы там нет шестеренок, в ней не нужно заливать масло, как в двигателе, она не протыкается, как шину в автомобиле. Есть аварии серверов в сети связи. То есть, если связь между вашими серверами порвалась на минутку, сможет ли работа вашей системы потом восстановиться? Я много раз видал, как системы зацикливаются после того, как какая-нибудь система, от которой они не зависят, отвалилась. То есть, они пытаются отправить повторные запросы и у них что-нибудь ломается. Причем, поскольку сети связи могут ломаться удивительными способами, то и все их простым тестированием тоже не понимаешь, серверы отваливаются. Проблемы с данными. Может резко измениться формат данных или, допустим, формат какого-нибудь столбца может измениться в базе данных, либо какие-то данные резко станут недоступными. Что в этом случае будете делать? Проблемы с персоналом. То есть, например, люди, может быть большая текучка и вам нужна система, общение с которой, работе с которой, поддержки с которой, вам легко обучить людей. Или, допустим, если вы привыкли переобучать модель в ручном режиме, то вам нужен квалифицированный человек, который будет прогонять бэк-тесты. Это тяжелая неблагодарная работа и без такого человека вы вашу систему поддерживать не сможете. Как вы будете обновлять ваше оборудование, как вы будете обновлять ваши схемы данных на работающей системе? Об этом хорошо бы тоже подумать заранее, прежде чем ее выкатывать, потому что однажды вы столкнетесь с тем, что вы обновляете операционную систему на серверах и, допустим, ставите новый сервер баз данных, он говорит, знаешь, я на этом процессоре не работаю, тут нет поддержки вот такого набора инструкций. Мы сталкивались с этим с МОНГДБ, когда обновляли старую систему. И ничего не поделаешь.

И адаптируемость. Адаптируемость это способность системы адаптироваться к меняющимся обстоятельствам. А меняться в нашем мире будет все. Начиная, конечно, с бизнес-требований. Сегодня от вас хотели, чтобы вы обрабатывали 100 запросов, завтра тысячу. Сегодня от вас хотели, чтобы вы удаляли файл без подтверждения, завтра от вас потребуют подтверждение и еще и чтобы пользователь голосом сказал, да-да, я согласен, чтобы этот файл удалили. Доступность данных будет меняться, будет меняться оборудование, на котором мы работаем. Инфраструктурные сервисы, от которых вы зависите, и не только чат GPT, а допустим какая-нибудь система распознавания голоса или что-нибудь еще, они будут отваливаться, менять свой формат. Никто вас не будет об этом предупреждать. Ну и сами по себе данные будут меняться. То есть пресловутый сдвиг данных, о котором мы тоже будем говорить на одной из лекций. Он никуда не делся.

Дополнительные материалы к лекции: