
- 03.10.2022
- 05.10.2025
- обучение
- #mlsystemdesign
Вторая лекция открытого курса "Дизайн систем машинного обучения", "Основы проектирования ML-систем".
Слайды можно скачать тут mlsysd2ods.pdf
Текстовая расшифровка:
 Привет! Меня зовут Дмитрий Колодезев, и это вторая лекция нашего курса про дизайн систем машинного обучения.
Привет! Меня зовут Дмитрий Колодезев, и это вторая лекция нашего курса про дизайн систем машинного обучения.
 На прошлой лекции мы говорили о сложностях, с которыми мы сталкиваемся при практическом использовании наших моделей машинного обучения. Сегодня мы обсудим вопросы, которые нужно задать себе при проектировании ML-систем. Это вторая лекция с вопросами, дальше будут лекции с ответами. Оставайтесь с нами.
На прошлой лекции мы говорили о сложностях, с которыми мы сталкиваемся при практическом использовании наших моделей машинного обучения. Сегодня мы обсудим вопросы, которые нужно задать себе при проектировании ML-систем. Это вторая лекция с вопросами, дальше будут лекции с ответами. Оставайтесь с нами.
Я надеюсь, что у вас было время посмотреть дополнительные материалы к прошлой лекции. Если нет, обязательно сделайте это. Дополнительные материалы полезнее лекций.
 По мере того, как мы проектируем систему, мы погружаемся в ее разные слои. Сначала мы изучаем бизнес-окружение системы, зачем мы ее строим. Затем рассматриваем, как разные части системы будут взаимодействовать между собой, как мы будем добиваться соответствия ограничениям. Это как раз то, что обычно называют ML System Design. В процессе реализации у нас будут проектные ограничения - и нам с ними тоже надо как-то работать. Неожиданно подкрадываются юридические ограничения в виде запрета на использование данных и ограничения на работу с библиотеками. У заказчика обычно есть какая-то инфраструктура, которая диктует технические ограничения. И, наконец, сердцем любой ML-системы является одна или несколько ML-моделей - и для того, чтобы их обучить, нам нужно поставить задачу и на обучение ML-модели. И тут мы одну и ту же бизнес-проблему можем решить, формулируя по-разному ML-задачи.
По мере того, как мы проектируем систему, мы погружаемся в ее разные слои. Сначала мы изучаем бизнес-окружение системы, зачем мы ее строим. Затем рассматриваем, как разные части системы будут взаимодействовать между собой, как мы будем добиваться соответствия ограничениям. Это как раз то, что обычно называют ML System Design. В процессе реализации у нас будут проектные ограничения - и нам с ними тоже надо как-то работать. Неожиданно подкрадываются юридические ограничения в виде запрета на использование данных и ограничения на работу с библиотеками. У заказчика обычно есть какая-то инфраструктура, которая диктует технические ограничения. И, наконец, сердцем любой ML-системы является одна или несколько ML-моделей - и для того, чтобы их обучить, нам нужно поставить задачу и на обучение ML-модели. И тут мы одну и ту же бизнес-проблему можем решить, формулируя по-разному ML-задачи.
 Этот и следующий слайд я взял у Ирины Голощаповой, с которой мы вместе ведем телеграм-канал Reliable ML. Для большого бизнеса, в котором Ирина работает, ML системы - это такие же инвестиции, как, например, строительство нового складского центра или открытие нового магазина. Ресурсы всегда ограничены, и задача бизнеса вложить их туда, где они принесут наибольшую отдачу. А значит, нашу ML-систему мы можем рассматривать как какой-то инвестиционный проект.
Этот и следующий слайд я взял у Ирины Голощаповой, с которой мы вместе ведем телеграм-канал Reliable ML. Для большого бизнеса, в котором Ирина работает, ML системы - это такие же инвестиции, как, например, строительство нового складского центра или открытие нового магазина. Ресурсы всегда ограничены, и задача бизнеса вложить их туда, где они принесут наибольшую отдачу. А значит, нашу ML-систему мы можем рассматривать как какой-то инвестиционный проект.
Что отличает хорошие инвестиции в ML от плохих? Во-первых, они реализуемые. У нас есть силы и техническая возможность построить систему и потом ее внедрить. Во-вторых, они измеримы. Мы же инвестиции оцениваем - значит, нам нужно каким-то образом сравнивать разные варианты. Нам нужно измерить отдачу от инвестиций, проведя эксперимент или запустив пилотный проект. Мы предполагаем, что эти инвестиции положительно повлияют на наши бизнес-процессы, на прибыль и убытки. Причем повлияют не когда-нибудь, а в обозримой, нужной нам перспективе. Например, в течение года.
Система решает задачи, которые в настоящее время в приоритете у бизнеса. Обычно, как правило большого пальца, говорят, что это топ-3 проблем, о которых беспокоится генеральный директор.
Но в жизни проблемы бывают и помельче. Мы надеемся быстро внедрить систему и окупить наши затраты. Что делать, если мы не проходим через эти ограничения? Это здорово - мы узнали о проблемах до того, как потратили время и деньги. Нам нужно вернуться назад и уточнить нашу задачу, уточнить наши подходы. Может быть, наша система не нужна заказчику. Может быть, нужна, но нужно доработать идею, чтобы уложиться в заданные ограничения.
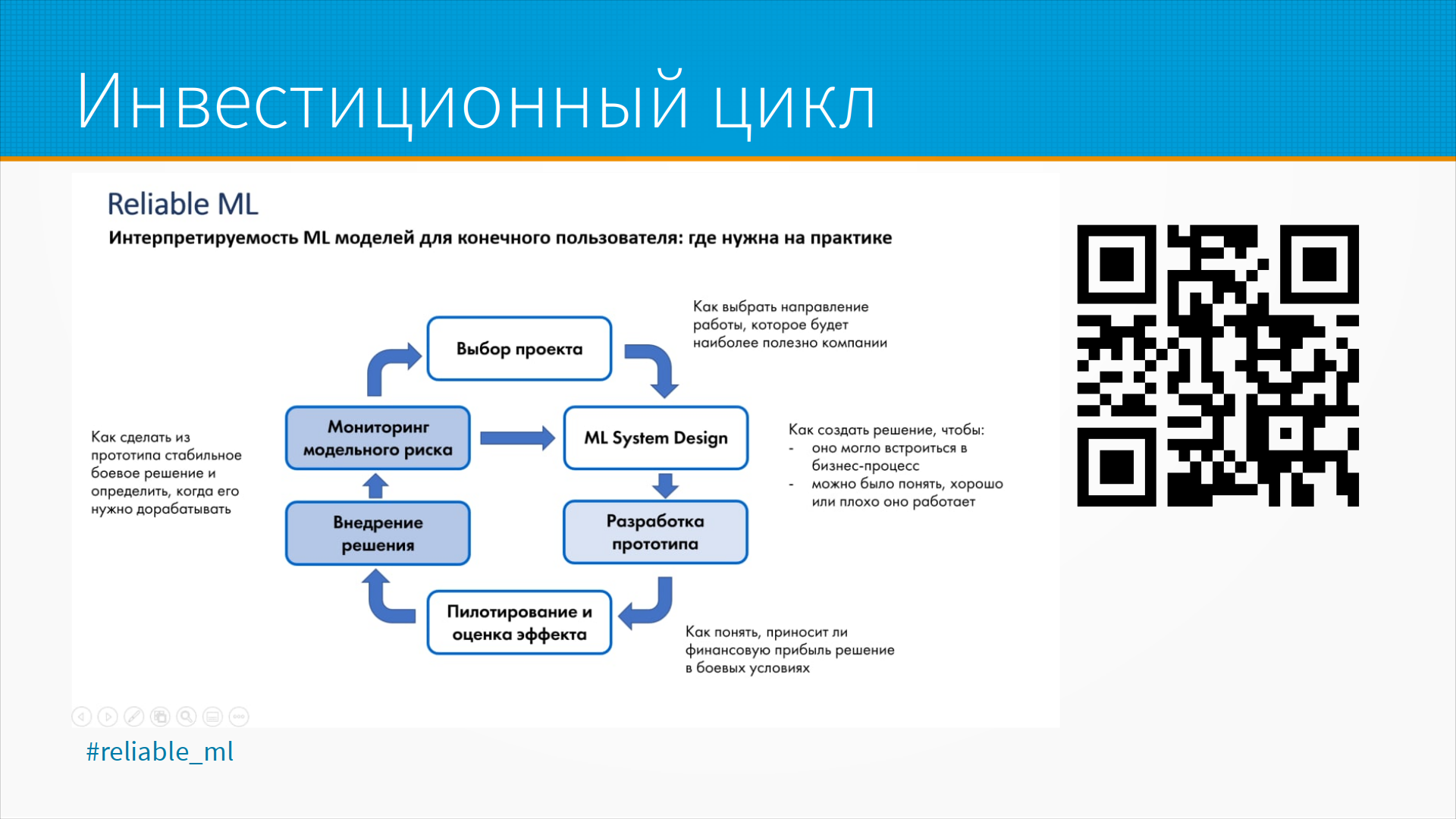 Работа с инвестиционными проектами идет в рамках инвестиционного цикла. Мы выбрали проект, спроектировали, разработали и выкатили прототип, оценили перспективность подхода, внедрили. Начали отслеживать качество работы модели. И, как только оно ухудшилось, или появилась надежда его улучшить - снова вернулись к проектированию системы. Или начали искать более перспективное приложение для наших усилий.
Работа с инвестиционными проектами идет в рамках инвестиционного цикла. Мы выбрали проект, спроектировали, разработали и выкатили прототип, оценили перспективность подхода, внедрили. Начали отслеживать качество работы модели. И, как только оно ухудшилось, или появилась надежда его улучшить - снова вернулись к проектированию системы. Или начали искать более перспективное приложение для наших усилий.
 Как вообще система может влиять на наши бизнес показатели? Например, мы хотим увеличить прибыль. Прибыль это доходы минус расходы. Мы должны либо увеличить продажи, либо снизить затраты. Мы можем повлиять явно, например, сделать какую-нибудь рекомендательную систему, которая увеличит средний чек или конверсию в интернет-магазине. Или сделать модель, которая управляет закупками, и тем самым снижает затраты на поддержание ассортимента на складе, или затраты на обслуживание клиента.
Как вообще система может влиять на наши бизнес показатели? Например, мы хотим увеличить прибыль. Прибыль это доходы минус расходы. Мы должны либо увеличить продажи, либо снизить затраты. Мы можем повлиять явно, например, сделать какую-нибудь рекомендательную систему, которая увеличит средний чек или конверсию в интернет-магазине. Или сделать модель, которая управляет закупками, и тем самым снижает затраты на поддержание ассортимента на складе, или затраты на обслуживание клиента.
Мы можем неявно повлиять на наши бизнес-показатели. Например, увеличить удовлетворенность пользователей. Они будут меньше уходить, у нас уменьшатся затраты на рекламу. Либо мы увеличиваем удовлетворенность персонала, и у нас уменьшится кадровая текучка, люди будут работать эффективнее. Или совсем неявно. Иногда ML-модель нужна не для того, чтобы увеличить операционную эффективность, а для того, чтобы увеличить инвестиционную привлекательность, или перевести операционные затраты в капитальные. О чем это?
Когда мы тратим каждый день 100 000 на наш колл-центр, эти 100 000 мы потратили - и они исчезли. Это операционные затраты. Если же мы 100 000 вкладываем в систему автоматизации колл-центра, то у нас к концу года образовываются капитальные затраты, которые как бы с нами, они принадлежат нам. С точки зрения бухгалтерии это как будто мы купили станок. У нас выросли капитальные затраты, у нас больше имущества. Это интеллектуальная собственность, которая может повлиять на нашу оценку как стартапа, например. Иногда нас любят за то, что мы создаем интеллектуальную собственность, а не повышаем операционную прибыль.
Зачем нам вообще вникать в эту бухгалтерию? Дело в том, что если мы не поймем ограничения, если мы не поймем контекст, в котором мы делаем проект, ничем хорошим это не кончится. Мы не сможем сделать его хорошо, потому что смысл любой системы расположен за ее пределами. Мы должны хорошо понимать, зачем бизнес платит за разработку ML-системы.
 Допустим, мы хотим внедрить машинное обучение, чтобы увеличить прибыльность интернет-магазина. Как мы можем ее увеличить? Например, сделать рекомендательную систему, которая при покупке рекомендует пользователю аналогичные товары, или товары, которые дополняют те товары, которые он уже купил, или помогают ему быстро найти нужный товар.
Допустим, мы хотим внедрить машинное обучение, чтобы увеличить прибыльность интернет-магазина. Как мы можем ее увеличить? Например, сделать рекомендательную систему, которая при покупке рекомендует пользователю аналогичные товары, или товары, которые дополняют те товары, которые он уже купил, или помогают ему быстро найти нужный товар.
Тут необходимо отследить, как мы хотим, чтобы пользователь начал себя вести. Например, некоторые пользователи заходят не для того, чтобы купить, а для того, чтобы посмотреть, что вообще существует в этой товарной категории - для того, чтобы уточнить свое представление о мире: до того, как они начнут выбирать товар по цене, они пытаются понять, что вообще бывает. И в этот момент то, что они ищут, мы, скорее всего, им не продадим. Но мы легко можем им продать какую-нибудь полезную мелочь, которую они, скорее всего, купили бы, и потом они к нам вернутся за чем-нибудь еще.
Если же пользователь пришел, уже зная, что он будет покупать, он хотел бы сравнить цены. Иногда ему нужно посмотреть, как это выглядит на фотографии, он хотел бы показать другому человеку. То есть не всегда человек, заходя на сайт, хочет как можно быстрее найти что-то и купить. Иногда наоборот, он хочет покопаться в товарной категории. И когда мы каким-то образом помогаем в чем-то человеку, мы в чем-то другом ему мешаем. Например, если человек сразу попал на тот товар, который он искал, а не попал в товарную категорию со списком всех аналогичных товаров, то он его, может быть, купит, а так, он мог бы купить более дорогой, может быть, более нужный ему товар. Всегда, когда мы вмешиваемся в опыт покупки, мы чему-то помогаем, чему-то мешаем.
Как мы будем измерять пользу от нашей модели? Например, рекомендательные системы для интернет-магазинов любят делать так. Они говорят: "Разместите наш блок на главной странице вверху, и вы увидите, как много покупателей к вам придет с этого блока". Но из нашего опыта - все, что вы повесите на главной странице вверху, будет приводить к вам покупателей. Любой товар, который вы прорекламируете вверху страницы посещаемого интернет-магазина, будет продаваться в 10 раз лучше, чем если бы он был размещен в другом месте. Тут есть эффект каннибализации пространства на экране. Вы поставили рекомендательную систему, вы улучшили поиск для пользователей для одних товаров, и ухудшили поиск для других. Как мы измерим поиск?
Самый очевидный способ - если мы измерим нашу выручку. Допустим, у нас выросла выручка. Но выручка, к сожалению, меняется от миллиона разных причин: изменилась погода, изменились цены, курс доллара, обстановка в мире, какие-то акции у конкурентов, скидки, конец года, выплатили премию, задержали премию. Получается, что огромное количество факторов, над которыми мы не имеем контроля, и не измеряем их, влияют на наши продажи. И еще влияет наша рекомендательная система. Получается, что наши метрики зачастую ненадежны, в том смысле, что они зашумлены. И даже, если бы мы считали такую вполне понятную штуку, как продажи каждого конкретного товара, то большинство товаров — длинный хвост распределения — продаются очень редко. И сколько бы у нас ни было этих товаров, продажи их не будут статистически значимы. Вы не сможете набрать за нужный период времени столько продаж, чтобы статистически значимо рассказать, что что-то стало продаваться больше или меньше.
 У нас метрики бывают, во-первых, зашумленные, во-вторых, неудобные. Чтобы работать с более удобными метриками, есть техника прокси-метрики, мы ее упомянем чуть позже, а пока, в принципе, какие у проекта могут быть метрики?
У нас метрики бывают, во-первых, зашумленные, во-вторых, неудобные. Чтобы работать с более удобными метриками, есть техника прокси-метрики, мы ее упомянем чуть позже, а пока, в принципе, какие у проекта могут быть метрики?
Во-первых, это бизнес-метрики - те метрики, которые измеряют влияние нашего проекта на ключевые показатели бизнеса: прибыль, доля рынка, привлекательность для инвесторов, если мы ее можем замерить. На этом уровне нашим бизнес-пользователям наши F1, ROC-AUC, Accuracy, Precision, Recall интересны только до тех пор, пока бизнес-метрики их радуют. Если будет падать прибыль, доля рынка - им будет плевать на F1, ROC-AUC и все остальное.
И есть инженерные метрики. Инженерные метрики - это могут быть метрики системы, такие как задержка и пропускная способность, и ML-метрики: F1, ROC-AUC, Accuracy, Precision, Recall. Проблема с ML-метриками в том, что на проде мы не всегда можем их измерить. Например, мы выдаем кредиты - задача кредитного скоринга. И о том, что человек не вернет кредит, формально мы узнаем через 90 дней после того, как он просрочил платеж по кредиту. Всякая способность в разумные сроки посчитать наш accuracy у нас отсутствует. И тут нам на помощь приходят прокси-метрики.
 Прокси-метрики - это метрики, которые сами по себе нас не интересуют, но они скоррелировались с интересными нам метриками, и их удобнее мерить. Например, если мы оптимизируем какую-нибудь рекламную кампанию, мы могли бы оптимизировать продажи. Но продажи у нас случаются редко и зашумлены. Мы можем посмотреть, сколько у нас посетителей на сайт пришло. Допустим, при конверсии посетителей на сайте в продажи 2%, этих событий у нас в 50 раз больше, чем продаж. А значит, статистическая значимость больше - мы можем увидеть разницу быстрее.
Прокси-метрики - это метрики, которые сами по себе нас не интересуют, но они скоррелировались с интересными нам метриками, и их удобнее мерить. Например, если мы оптимизируем какую-нибудь рекламную кампанию, мы могли бы оптимизировать продажи. Но продажи у нас случаются редко и зашумлены. Мы можем посмотреть, сколько у нас посетителей на сайт пришло. Допустим, при конверсии посетителей на сайте в продажи 2%, этих событий у нас в 50 раз больше, чем продаж. А значит, статистическая значимость больше - мы можем увидеть разницу быстрее.
Иногда мы не можем измерить нашу основную метрику в нужное время, как с кредитом, но мы можем измерить прокси-метрику, похожую метрику. Как правило, бизнес знает свои прокси-метрики, их надо спросить - они все равно их отслеживают без всякого машинного обучения. Если много данных, прокси-метрики можно поискать, исходя из корреляции этих данных. В идеальном случае мы комбинируем найденные нами из корреляции прокси-метрики и знания о бизнесе. Тут есть ссылка на статью Retail Rocket про прокси-метрики, а в дополнительных материалах есть рассказ про то, как Uber искал прокси-метрики в своем бизнесе. Также в дополнительных материалах есть интересный рассказ про то, как модель сломалась, а выручка выросла. Это модель Microsoft, которая подбирала страницы в поиске Bing. И когда они выкатили неудачную версию модели, пользователи не могли найти то, что им нужно, и смотрели в три раза больше страниц - соответственно, в три раза больше продавалось рекламы. И поэтому формально поиск Bing стал работать в три раза лучше, он стал в три раза больше денег приносить на какое-то время. Понятно, что это краткосрочный эффект. В долгосрочной перспективе пользователи бы ушли, поэтому они исправили эту ошибку. Вообще деньги могут быть очень зашумленным, сбивающим с толку фактором, об этом тоже надо помнить.
 После того, как мы очертили контекст нашей системы, можно приступать к ее дизайну. Дизайн системы машинного обучения - это процесс принятия решений про интерфейс, алгоритмы, данные, программную инфраструктуру и оборудование, чтобы соответствовать требованиям, предъявляемым к системе.
После того, как мы очертили контекст нашей системы, можно приступать к ее дизайну. Дизайн системы машинного обучения - это процесс принятия решений про интерфейс, алгоритмы, данные, программную инфраструктуру и оборудование, чтобы соответствовать требованиям, предъявляемым к системе.
Требования бывают функциональные, то есть что непосредственно система должна уметь делать: определить автомобильный номер с видеокамеры, найти фейковую транзакцию, рекомендовать товар к тем товарам, которые пользователь уже положил в корзину - какие-нибудь разумные случаи использования системы. И нефункциональные требования - это требования к качеству, надежности, масштабируемости, обслуживаемости, адаптируемости.
 Про надежность тут на слайде приведено определение надежности из ГОСТа. Если перефразировать его, то надежность - это свойство нашей системы выдавать то, что от нее ожидают, если на вход ей будет подаваться то, что она ожидает. То есть то, что мы ожидаем на вход и то, что вы ожидаете на выход.
Про надежность тут на слайде приведено определение надежности из ГОСТа. Если перефразировать его, то надежность - это свойство нашей системы выдавать то, что от нее ожидают, если на вход ей будет подаваться то, что она ожидает. То есть то, что мы ожидаем на вход и то, что вы ожидаете на выход.
Главная проблема тут - в плохо документированных ожиданиях. Мы не указали, что нам нельзя передавать вот это, и мы забыли сказать, что мы можем передать вот то. С надежностью основная проблема - как мы поймем, что все работает правильно, как мы отличим ошибочный предикт от хорошего? Модель машинного обучения выдает какую-то вероятность, на основании которой мы принимаем решения. И что, если она начала выдавать неправильную вероятность? Как мы поймем, что наши рекомендательные системы рекомендуют не то, или как мы поймем, что наш кредитный скоринг начал рекомендовать выдавать кредиты плохим заемщикам? Тут есть проблемы, и подробнее мы их обсудим в лекции про мониторинг. Иногда для того, чтобы отследить, что модель начала работать с ошибками, делают вторую модель - модель невязки, которая пытается предсказать вероятность ошибочности ответа первой модели.
 Масштабируемость. Если вы сделаете что-нибудь полезное, это обязательно придется масштабировать. Масштабируемость - это способность системы, сети или процесса справляться с увеличением рабочей нагрузки. Обычно с нагрузкой справляются, добавляя ресурсы. И тут есть два варианта - ваша система может быть способна к вертикальной или горизонтальный масштабируемости. Вертикальная масштабируемость - это когда мы взяли и купили более мощные сервера, они работают быстрее, мы можем обслуживать больше посетителей, больше запросов. Так или иначе, в любом вертикальном масштабировании мы упремся в потолок, и нам понадобится горизонтальная масштабируемость. Горизонтальная масштабируемость - это когда мы можем распределять нашу задачу на много систем, которые ее считают независимой.
Масштабируемость. Если вы сделаете что-нибудь полезное, это обязательно придется масштабировать. Масштабируемость - это способность системы, сети или процесса справляться с увеличением рабочей нагрузки. Обычно с нагрузкой справляются, добавляя ресурсы. И тут есть два варианта - ваша система может быть способна к вертикальной или горизонтальный масштабируемости. Вертикальная масштабируемость - это когда мы взяли и купили более мощные сервера, они работают быстрее, мы можем обслуживать больше посетителей, больше запросов. Так или иначе, в любом вертикальном масштабировании мы упремся в потолок, и нам понадобится горизонтальная масштабируемость. Горизонтальная масштабируемость - это когда мы можем распределять нашу задачу на много систем, которые ее считают независимой.
Кроме горизонтальной и вертикальной масштабируемости, есть еще масштабируемость вглубь. Практика показывает, что у вас будет расти не только трафик и объем данных - если вы сделаете что-то полезное, у бизнеса будут расти аппетиты, вас попросят добавить еще моделей, еще сценарии использования. В конце концов, вы столкнетесь с тем, что вам нужно управлять версиями моделей, их совместимостью, дообучением, выкаткой и так далее, это все тоже обсудим дальше.
 Обслуживаемость - это отдельная проблема, о которой часто забывают. Большинство проблем после того, как систему удалось запустить, касаются именно масштабируемости и обслуживаемости. Обслуживаемость - это приспособленность к восстановлению работоспособного состояния после отказа и повреждения.
Обслуживаемость - это отдельная проблема, о которой часто забывают. Большинство проблем после того, как систему удалось запустить, касаются именно масштабируемости и обслуживаемости. Обслуживаемость - это приспособленность к восстановлению работоспособного состояния после отказа и повреждения.
Какие отказы и повреждения тут имеются в виду? Сердцем ML-системы являются алгоритмы. Это, в общем-то, программа, они не ломаются. Но ломаются сервера, на которых они работают, ломаются сети связи, ломаются системы хранения. Нужно уметь определять - насколько наша система устойчива к отказу какого-то элемента, насколько ей нужна такая устойчивость, насколько она хорошо обслуживается, насколько она защищена от глупых решений администраторов. Потому что первичные администраторы системы, те, которым мы передадим систему с рук на руки, скорее всего, будут понимать, что происходит, как она работает, как правильно с ней обращаться, как ее обновлять, как ее мониторить. А те, кто придет им на смену через полтора года - будут ли они понимать, как с ней жить?
 Кроме всего прочего, оборудование, на котором мы работаем, будет обновляться, будут выходить новые версии операционных систем. Ставить их придется все равно, потому что в предыдущих будут дырки в безопасности. И вы можете столкнуться с тем, что, в целом, все работает хорошо, но именно ваша база данных не работает на этом сервере, потому что тут не хватает процессорной инструкции. Или поставщик данных сменил схему данных, и нужных вам данных теперь просто нет.
Кроме всего прочего, оборудование, на котором мы работаем, будет обновляться, будут выходить новые версии операционных систем. Ставить их придется все равно, потому что в предыдущих будут дырки в безопасности. И вы можете столкнуться с тем, что, в целом, все работает хорошо, но именно ваша база данных не работает на этом сервере, потому что тут не хватает процессорной инструкции. Или поставщик данных сменил схему данных, и нужных вам данных теперь просто нет.
И адаптируемость - это способность адаптироваться к меняющимся обстоятельствам. Кроме структуры данных, меняются еще и бизнес-требования, доступность данных, законодательство, оборудование, инфраструктурные сервисы. То есть сегодня мы сидели на Kafka, а завтра зачем-то перешли на Rabbit, и нам пришлось переписывать это все. Сегодня заказчик сидел гордо на Oracle, завтра Oracle перестал его поддерживать, и все начали мигрировать на Postgres, а нам со всем этим жить.
Кроме всего прочего, есть смена распределения данных — data shift и target drift.
Проще всего сдвиг данных объяснить на примере с Computer Vision. Когда до ковида мы обсуждали проблемы сдвига в распределении данных с коллегами по отрасли, ребята, которые занимаются Computer Vision, мне говорили: "У нас таких проблем нет, лица людей всегда одинаковые". Прошел месяц, начался ковид, на лица людей надели маски. Пришлось переучиваться. Мир меняется, и те данные, которые вам приходят, могут быть другими.
Затем target drift. Сами по себе классы, который вы предсказываете, могут измениться. А еще может измениться зависимость между входными и выходными данными, и с этим придется как-то работать, это придется как-то мониторить, и модель надо будет переделывать. Что вы будете делать при выкатке новой модели, как вы сделаете, чтобы пользователи, которые уже работают с ней, не отвалились, что вы сделаете, когда новая модель не заработает и ее нужно будет откатить на предыдущую версию - вот об этом тоже нужно подумать еще на этапе дизайна системы.
 Начав работать над проектом, мы столкнемся с проектными ограничениями. Правило большого пальца: примерно пятая часть работы - это запуск нашей системы, а 4/5 - это ее доработка, то есть что-то, что нам забыли сказать, что-то, о чем мы забыли подумать, или какие-то непредсказуемые вещи, которые все равно придется доделывать. Наши ограничения - данные, деньги, оборудование, люди - то, что позволяет нам сделать и успешно завершить проект - могут нас здорово ограничить в достижении целей, в инструментах, которые мы используем, в качестве, которого можем достигнуть. Самое большое ограничение обычно - это данные. Денег можно занять, выбить, превысить бюджет по деньгам. Каждый второй проект в IT превышает бюджет по деньгам. Оборудование можно купить новое, людей можно постараться нанять. Но если нет данных, скорее всего, проект не взлетит, или его нужно сначала переформулировать как проект по сбору данных.
Начав работать над проектом, мы столкнемся с проектными ограничениями. Правило большого пальца: примерно пятая часть работы - это запуск нашей системы, а 4/5 - это ее доработка, то есть что-то, что нам забыли сказать, что-то, о чем мы забыли подумать, или какие-то непредсказуемые вещи, которые все равно придется доделывать. Наши ограничения - данные, деньги, оборудование, люди - то, что позволяет нам сделать и успешно завершить проект - могут нас здорово ограничить в достижении целей, в инструментах, которые мы используем, в качестве, которого можем достигнуть. Самое большое ограничение обычно - это данные. Денег можно занять, выбить, превысить бюджет по деньгам. Каждый второй проект в IT превышает бюджет по деньгам. Оборудование можно купить новое, людей можно постараться нанять. Но если нет данных, скорее всего, проект не взлетит, или его нужно сначала переформулировать как проект по сбору данных.
 Зачастую, если у нас не хватает времени, мы можем немножко времени купить - то есть более мощные сервера, больше людей на разметке. Но самый хороший способ купить время - это не разрабатывать самим решение, а купить готовое, и интегрировать его в нашу систему.
Зачастую, если у нас не хватает времени, мы можем немножко времени купить - то есть более мощные сервера, больше людей на разметке. Но самый хороший способ купить время - это не разрабатывать самим решение, а купить готовое, и интегрировать его в нашу систему.
Это, конечно, дороже, но и значительно быстрее. Как показывает практика, обычно проблемы не в качестве ML-модели, не в ее архитектуре, а где-то на границах системы. Либо нам приходит не то, что мы ожидали, либо то, что мы выдаем, нельзя использовать там, куда мы его отдали. Если мы купим существующее на рынке решение, интегрируем его в сердце нашей системы, мы сможем начать работать с внешними ограничениями системы, сможем подтянуть остальную систему, и скорее всего, тогда ML-часть не будет бутылочным горлышком в нашей системе. А если будет, то мы его доработаем, заменим существующее решение на наше, будучи уже в выгодном положении, что вся система у нас работает, а нам нужно заменить только ее ML-часть - это значительно проще.
 Compliance and privacy. Как только мы начинаем работать с данными, нам хочется отдать их кому-нибудь на разметку. Не всегда мы можем отдать данные на разметку. Медицинские данные мы почти всегда не можем отдать на разметку. Можем ли мы хранить данные в облаке? Во многих странах есть ограничения на хранение данных за границей, есть ограничение на хранение данных зашифрованными, иногда данные нужно шифровать определенными алгоритмами. Некоторые данные пользователей мы собирать не имеем права. Иногда мы не имеем права использовать сторонние сервисы. В общем, хорошо бы с хорошим юристом это дело разбирать. Наш закон о персональных данных (в России) один из самых понятных и не жестоких. Есть законы пожестче и позапутанней.
Compliance and privacy. Как только мы начинаем работать с данными, нам хочется отдать их кому-нибудь на разметку. Не всегда мы можем отдать данные на разметку. Медицинские данные мы почти всегда не можем отдать на разметку. Можем ли мы хранить данные в облаке? Во многих странах есть ограничения на хранение данных за границей, есть ограничение на хранение данных зашифрованными, иногда данные нужно шифровать определенными алгоритмами. Некоторые данные пользователей мы собирать не имеем права. Иногда мы не имеем права использовать сторонние сервисы. В общем, хорошо бы с хорошим юристом это дело разбирать. Наш закон о персональных данных (в России) один из самых понятных и не жестоких. Есть законы пожестче и позапутанней.
 Технические ограничения. Технические ограничения обычно связаны с проблемой интеграции нашей системы в существующую систему заказчика. Нам так или иначе приходится получать данные и загружать данные обратно. Если у заказчика уже есть какая-то система, которая решает проблему, на которую мы нацелились, то нам нужно будет превзойти качество существующей системы. Причем не просто превзойти, а документированно превзойти, чтобы доказать, что заказчик потратил силы не зря. Нам желательно переиспользовать имеющуюся инфраструктуру заказчика, а значит, нам нужно провести ревизию этой инфраструктуры и понять, что из его инфраструктуры можем использовать.
Технические ограничения. Технические ограничения обычно связаны с проблемой интеграции нашей системы в существующую систему заказчика. Нам так или иначе приходится получать данные и загружать данные обратно. Если у заказчика уже есть какая-то система, которая решает проблему, на которую мы нацелились, то нам нужно будет превзойти качество существующей системы. Причем не просто превзойти, а документированно превзойти, чтобы доказать, что заказчик потратил силы не зря. Нам желательно переиспользовать имеющуюся инфраструктуру заказчика, а значит, нам нужно провести ревизию этой инфраструктуры и понять, что из его инфраструктуры можем использовать.
Нам придется обучать пользователей и операторов системы. Если они уже умеют работать с какими-то инструментами, базами данных, если у них уже внедрен Spark, если они уже используют Hadoop - это прямое указание, что следует попытаться сделать на их же технологическом стеке. Это будет проще для них и, возможно, дешевле.
 После того, как мы придумали саму систему, нам нужно так или иначе разработать сердце системы - ML-модель. Общее правило большого пальца во внедрении ML - это попробовать обойтись без внедрения ML, сделать решение без ML, если возможно. Многие ML-модели можно без значительной потери качества заменить какими-то простыми if-ами, выбором из таблицы значений. Нам желательно замерить качество, которое мы получаем в такой простой модели, и затем сравнивать, насколько мы смогли его улучшить, добавив простые, а потом и сложные ML-модели. Если мы начинаем решение нашей проблемы с нейронной сети (сразу сложной модели), и мы получили какое-то качество, то мы не знаем - может быть, всегда предсказывая одно и то же, мы получили бы качество и получше.
После того, как мы придумали саму систему, нам нужно так или иначе разработать сердце системы - ML-модель. Общее правило большого пальца во внедрении ML - это попробовать обойтись без внедрения ML, сделать решение без ML, если возможно. Многие ML-модели можно без значительной потери качества заменить какими-то простыми if-ами, выбором из таблицы значений. Нам желательно замерить качество, которое мы получаем в такой простой модели, и затем сравнивать, насколько мы смогли его улучшить, добавив простые, а потом и сложные ML-модели. Если мы начинаем решение нашей проблемы с нейронной сети (сразу сложной модели), и мы получили какое-то качество, то мы не знаем - может быть, всегда предсказывая одно и то же, мы получили бы качество и получше.
 И упрощенная модель ML-разработки - это определение границ проекта (то, о чем мы говорили в первой части лекции), подготовка данных, разработка модели, развертывание, мониторинг и дообучение, и потом анализ того, что у нас получилось. В этом кругу мы крутимся, улучшаем ML-модель с тем, чтобы добиться тех показателей, которые мы пообещали заказчику на старте.
И упрощенная модель ML-разработки - это определение границ проекта (то, о чем мы говорили в первой части лекции), подготовка данных, разработка модели, развертывание, мониторинг и дообучение, и потом анализ того, что у нас получилось. В этом кругу мы крутимся, улучшаем ML-модель с тем, чтобы добиться тех показателей, которые мы пообещали заказчику на старте.
 Взгляд исследователя на машинное обучение прост: дано, найти, критерий. Дано: что у нас есть? Найти: что нужно оптимизировать? Критерий: как мы поймем, что нашли то, что нужно и двигаемся в нужную сторону? В индустрии все сложнее - главным образом, тем, что критерий надо найти самим и согласовать. Он заранее неизвестен.
Взгляд исследователя на машинное обучение прост: дано, найти, критерий. Дано: что у нас есть? Найти: что нужно оптимизировать? Критерий: как мы поймем, что нашли то, что нужно и двигаемся в нужную сторону? В индустрии все сложнее - главным образом, тем, что критерий надо найти самим и согласовать. Он заранее неизвестен.
 Тут мы подходим к ML-метрикам. Зачастую не очень очевидно, что же мы будем измерять. Например, рекомендательная система в интернет-магазине. Что измерять в этой рекомендательной системе? Насколько пользователь нашел то, что он и так собирался найти? Кстати, зачем мы ему рекомендуем то, что он и так найдет? Как мы это измерим, с чем мы сравним? Цена ошибки первого и второго рода, требования к качеству модели - насколько нам нужно высокое качество этой модели, насколько достоверными будут результаты?
Тут мы подходим к ML-метрикам. Зачастую не очень очевидно, что же мы будем измерять. Например, рекомендательная система в интернет-магазине. Что измерять в этой рекомендательной системе? Насколько пользователь нашел то, что он и так собирался найти? Кстати, зачем мы ему рекомендуем то, что он и так найдет? Как мы это измерим, с чем мы сравним? Цена ошибки первого и второго рода, требования к качеству модели - насколько нам нужно высокое качество этой модели, насколько достоверными будут результаты?
 Начинать надо именно с baseline. Прежде, чем улучшать качество, прежде, чем учить модель и смотреть, насколько она хорошо работает, нужно сначала найти какой-нибудь baseline. Идеальный baseline - это существующие на рынке решения. Если есть у вас конкурент, подпишитесь на его API, прогоните данные через его API, посмотрите какое качество у него есть. Вот вам будет baseline.
Начинать надо именно с baseline. Прежде, чем улучшать качество, прежде, чем учить модель и смотреть, насколько она хорошо работает, нужно сначала найти какой-нибудь baseline. Идеальный baseline - это существующие на рынке решения. Если есть у вас конкурент, подпишитесь на его API, прогоните данные через его API, посмотрите какое качество у него есть. Вот вам будет baseline.
Простое решение на правилах. Если у вас есть возможность, можно оценить, как много ошибок делают люди. Скорее всего, вы не сможете превзойти качество людских оценок, потому что вы учитесь на разметке, сделанной людьми. Мы можем построить модели, которые принимают решение качественнее, чем человек, но для этого нам нужна разметка более качественная, чем делают люди. То есть какого-то сверхчеловека надо поймать, чтобы он нам данные разметил, тогда у нас будет сверхкачество. Этого обычно достигают, заставляя людей размечать данные консилиумом, или ансамблируя оценки нескольких людей, то есть строят ансамбль из людей так же, как строят ансамбль из моделей машинного обучения.
 Говоря об ошибке, нужно упомянуть о том, что у ошибок разная цена ошибки в разную сторону и разного типа. Например, если у нас false positive, то мы нашли то, чего нет, а если false negative - мы не нашли то, что есть. В некоторых моделях, например, при медицинском скрининге, когда мы ищем первые признаки рака, нам бы, конечно, лучше найти то, чего нет, чем пропустить, возможно, начинающийся рак, в то время, когда мы могли бы его еще вылечить. С другой стороны, иногда нам выгоднее пропустить какую-нибудь хорошую возможность, но зато ни в коем случае не допустить плохих, как при выдаче кредита. Ошибочно не выданный кредит - мы потеряли свою комиссию, ошибочно выданный кредит - потеряли гораздо больше.
Говоря об ошибке, нужно упомянуть о том, что у ошибок разная цена ошибки в разную сторону и разного типа. Например, если у нас false positive, то мы нашли то, чего нет, а если false negative - мы не нашли то, что есть. В некоторых моделях, например, при медицинском скрининге, когда мы ищем первые признаки рака, нам бы, конечно, лучше найти то, чего нет, чем пропустить, возможно, начинающийся рак, в то время, когда мы могли бы его еще вылечить. С другой стороны, иногда нам выгоднее пропустить какую-нибудь хорошую возможность, но зато ни в коем случае не допустить плохих, как при выдаче кредита. Ошибочно не выданный кредит - мы потеряли свою комиссию, ошибочно выданный кредит - потеряли гораздо больше.
Цены некоторых ошибок измерить трудно. Например - сколько стоит время пациента, сколько стоит убитый пациент, то есть умерший в результате неправильного диагноза, сколько стоит удобство использования. Зачастую мы даже не знаем о каких-то вещах, которые нужно было бы измерять.
 По требованиям к качеству - любой заказчик хочет, чтобы вас была 100% accuracy, 100% recall. Но тут надо понимать, что в реальности мы всегда остаемся с каким-то уровнем ошибок. Этому есть чисто математические причины и организационные причины. Есть некоторый идеальный байесовский классификатор и ошибка идеального байесовского классификатора, выше которой на этих данных не прыгнешь, потому что обычно данные чуть-чуть, но противоречат сами себе. В самоуправляемом автомобиле, который выбирает путь, обычно высокие требования к качеству. А если вы в мобильном телефоне набираете текст, и модель подсказывает, какое слово будет следующим, там не такие высокие требования - если модель вам подскажет не то слово, вы посмеетесь и исправите его руками. Рекомендации в интернет-магазине - даже если вам порекомендуют совсем не то, что вы ищете, то вы найдете нужный вам товар в поиске и все равно его купите.
По требованиям к качеству - любой заказчик хочет, чтобы вас была 100% accuracy, 100% recall. Но тут надо понимать, что в реальности мы всегда остаемся с каким-то уровнем ошибок. Этому есть чисто математические причины и организационные причины. Есть некоторый идеальный байесовский классификатор и ошибка идеального байесовского классификатора, выше которой на этих данных не прыгнешь, потому что обычно данные чуть-чуть, но противоречат сами себе. В самоуправляемом автомобиле, который выбирает путь, обычно высокие требования к качеству. А если вы в мобильном телефоне набираете текст, и модель подсказывает, какое слово будет следующим, там не такие высокие требования - если модель вам подскажет не то слово, вы посмеетесь и исправите его руками. Рекомендации в интернет-магазине - даже если вам порекомендуют совсем не то, что вы ищете, то вы найдете нужный вам товар в поиске и все равно его купите.
Очень трудно формализовать разумный уровень качества. Хорошо попробовать выразить в деньгах. Например, насколько вырастет прибыль, если увеличить accuracy на 1%? Обычно заказчик не может ответить на этот вопрос. Если вместе с ним начать искать ответ на этот вопрос, может быть, требования к вашей модели станут более реальными.
 Все это приводит к тому, что критерий нам приходится искать итеративно. То есть мы выбираем какую-то метрику, которую мы будем оптимизировать, собираем данные, разметку, готовим признаки, учим модель, выясняем, что в наших данных очень много мусора, и мы не можем достигнуть нужного нам качества, ищем ошибки, исправляем, переобучаем модель, выгружаем модель и выясняем, что вроде бы по метрике все хорошо, но модель работает неправильно. Подбираем подходящую метрику, возвращаемся к обучению модели и крутимся по кругу до тех пор, пока не придем к устраивающему нас и заказчика итогу.
Все это приводит к тому, что критерий нам приходится искать итеративно. То есть мы выбираем какую-то метрику, которую мы будем оптимизировать, собираем данные, разметку, готовим признаки, учим модель, выясняем, что в наших данных очень много мусора, и мы не можем достигнуть нужного нам качества, ищем ошибки, исправляем, переобучаем модель, выгружаем модель и выясняем, что вроде бы по метрике все хорошо, но модель работает неправильно. Подбираем подходящую метрику, возвращаемся к обучению модели и крутимся по кругу до тех пор, пока не придем к устраивающему нас и заказчика итогу.
 Сама по себе задача для машинного обучения может быть сформулирована разными способами. Если мы хотим ускорить работу службы поддержки, например, в банке или в какой-нибудь не кредитной организации, мы можем подойти к этому вопросу разными способами. Мы можем построить классификатор, который будет отправлять обращение нужному специалисту. Или рекомендательную систему, которая рекомендует оператору разные варианты ответа. Это ускорит его работу, нам нужно будет меньше операторов, клиент будет быстрее получать ответ на свои вопросы. Мы можем сделать регрессию, которая оценивает важность пользователя для нашего бизнеса, срочность его обращения, и, таким образом, приоритизировать его обращение и решать проблему важных пользователей в первую очередь. Мы можем построить систему, которая будет отвечать пользователю статьей из базы знаний - для этого нам нужно будет извлечение фактов из текстов, информационный поиск, генерация текста, суммаризация и т.д. Таким образом, из одной и той же бизнес-проблемы мы можем построить некоторое количество ML-проблем.
Сама по себе задача для машинного обучения может быть сформулирована разными способами. Если мы хотим ускорить работу службы поддержки, например, в банке или в какой-нибудь не кредитной организации, мы можем подойти к этому вопросу разными способами. Мы можем построить классификатор, который будет отправлять обращение нужному специалисту. Или рекомендательную систему, которая рекомендует оператору разные варианты ответа. Это ускорит его работу, нам нужно будет меньше операторов, клиент будет быстрее получать ответ на свои вопросы. Мы можем сделать регрессию, которая оценивает важность пользователя для нашего бизнеса, срочность его обращения, и, таким образом, приоритизировать его обращение и решать проблему важных пользователей в первую очередь. Мы можем построить систему, которая будет отвечать пользователю статьей из базы знаний - для этого нам нужно будет извлечение фактов из текстов, информационный поиск, генерация текста, суммаризация и т.д. Таким образом, из одной и той же бизнес-проблемы мы можем построить некоторое количество ML-проблем.
 Типичные ML-задачи - это классификация, регрессия и детекция объектов, аномалий, извлечение структурированной информации. Вот тут хотелось бы несколько подробнее разобраться в классификации. Прежде всего, классификация бывает на два класса, на несколько классов и на несколько классов одновременно, когда, например, мы присваиваем страницам теги - у страницы может быть много тегов. Или мы определяем заболевания у человека - у человека одновременно может быть несколько заболеваний. Сами по себе классификации бывают низкой или высокой кардинальности. Кардинальность - это мощность множества, а в данном случае имеется в виду, как много у нас классов. В зависимости от того, предсказываем мы пять классов или пятьсот, нам понадобятся разные модели.
Типичные ML-задачи - это классификация, регрессия и детекция объектов, аномалий, извлечение структурированной информации. Вот тут хотелось бы несколько подробнее разобраться в классификации. Прежде всего, классификация бывает на два класса, на несколько классов и на несколько классов одновременно, когда, например, мы присваиваем страницам теги - у страницы может быть много тегов. Или мы определяем заболевания у человека - у человека одновременно может быть несколько заболеваний. Сами по себе классификации бывают низкой или высокой кардинальности. Кардинальность - это мощность множества, а в данном случае имеется в виду, как много у нас классов. В зависимости от того, предсказываем мы пять классов или пятьсот, нам понадобятся разные модели.
 Классификация или регрессия? Тут есть некоторая гибкость. Мы можем заменить регрессию классификацией, разбив диапазон на несколько классов. То есть вместо того, чтобы предсказывать цену товара по фотографии - у нас в списке проектов есть такой проект на курсе - мы можем предсказывать не цену товара, а некоторый диапазон цены, что вот это дешевые товары до 10 000, эти товары от 10 000 до 50 000, эти от 50 000 до 100 000, эти от 100 000 до 300 000. То есть мы можем заменить регрессию классификацией, разбив диапазон на несколько классов. Базовая ошибка тут - делить на одинаковые диапазоны, например, на диапазоны по 5 000. Лучше разбивать на квантили, то есть на равномерно заполненные диапазоны. Если у нас, допустим, тысяча точек, мы их режем на десять поддиапазонов, в каждом из которых по сто точек. Или приводим распределение к равномерному, например, квантильным трансформером и предсказываем результат.
Классификация или регрессия? Тут есть некоторая гибкость. Мы можем заменить регрессию классификацией, разбив диапазон на несколько классов. То есть вместо того, чтобы предсказывать цену товара по фотографии - у нас в списке проектов есть такой проект на курсе - мы можем предсказывать не цену товара, а некоторый диапазон цены, что вот это дешевые товары до 10 000, эти товары от 10 000 до 50 000, эти от 50 000 до 100 000, эти от 100 000 до 300 000. То есть мы можем заменить регрессию классификацией, разбив диапазон на несколько классов. Базовая ошибка тут - делить на одинаковые диапазоны, например, на диапазоны по 5 000. Лучше разбивать на квантили, то есть на равномерно заполненные диапазоны. Если у нас, допустим, тысяча точек, мы их режем на десять поддиапазонов, в каждом из которых по сто точек. Или приводим распределение к равномерному, например, квантильным трансформером и предсказываем результат.
 Бинарная или мультиклассовая классификация? При малой кардинальности классов, когда у нас классов больше, чем два, но все-таки их не сотни, мы можем построить несколько бинарных классификаторов. Предположим, что мы предсказываем один из трех классов, и мы можем построить классификатор бинарный: является ли это первым классом, бинарный: вторым классом, бинарный: третьим классом. И построить либо последовательный классификатор, который сначала проверяет на первый, на второй, на третий, либо параллельный, который считает вероятность каждого из этих трех классов, и с помощью softmax выбирает, какой же из них более вероятен.
Бинарная или мультиклассовая классификация? При малой кардинальности классов, когда у нас классов больше, чем два, но все-таки их не сотни, мы можем построить несколько бинарных классификаторов. Предположим, что мы предсказываем один из трех классов, и мы можем построить классификатор бинарный: является ли это первым классом, бинарный: вторым классом, бинарный: третьим классом. И построить либо последовательный классификатор, который сначала проверяет на первый, на второй, на третий, либо параллельный, который считает вероятность каждого из этих трех классов, и с помощью softmax выбирает, какой же из них более вероятен.
Если же у нас большая кардинальность, много вариантов ответов - например, нам нужно предсказать, какой из 50 тысяч людей был моделью для этой фотографии - то мы можем сначала выбрать группу, потом подгруппу, а потом уже элемент в группе. При очень большой кардинальности самый разумный выбор - это нейронные сети.
 С multilabel классификацией, когда у каждой точки может быть несколько меток, есть свои проблемы. Это может быть либо бинарная классификация на каждую из меток - то есть, если у нас три возможных метки, у нас три модели; или мы можем группировать встречающиеся вместе метки в один класс. Например, пусть мы классифицируем людей на здоровых/больных, спортивных/малодвигающихся и курильщиков/некурильщиков. И все это мы пытаемся предсказать по нашим жизненным показателям: по пульсу, по дыханию, по потреблению кислорода легкими. Мы можем сгруппировать некоторые встречающиеся вместе метки. Например, "некурящий, спортсмен, здоровый" - это будет один класс. Или "курящий, больной, не спортсмен" - это будет другой класс. Некоторые метки не встречаются вместе, есть только некоторые подмножества возможных групп меток. И таким образом, multilabel классификацию мы можем свести к мультиклассовой классификации.
С multilabel классификацией, когда у каждой точки может быть несколько меток, есть свои проблемы. Это может быть либо бинарная классификация на каждую из меток - то есть, если у нас три возможных метки, у нас три модели; или мы можем группировать встречающиеся вместе метки в один класс. Например, пусть мы классифицируем людей на здоровых/больных, спортивных/малодвигающихся и курильщиков/некурильщиков. И все это мы пытаемся предсказать по нашим жизненным показателям: по пульсу, по дыханию, по потреблению кислорода легкими. Мы можем сгруппировать некоторые встречающиеся вместе метки. Например, "некурящий, спортсмен, здоровый" - это будет один класс. Или "курящий, больной, не спортсмен" - это будет другой класс. Некоторые метки не встречаются вместе, есть только некоторые подмножества возможных групп меток. И таким образом, multilabel классификацию мы можем свести к мультиклассовой классификации.
В многотемной, multilabel, классификации сложно стратифицировать выборку и измерять качество. Почему сложно стратифицировать выборку? Потому что обычно, когда мы готовим нашу тестовую выборку, мы отбираем данные так, чтобы распределение классов в ней было такое же, как и в нашей обучающей выборке. В многотемной классификации этого добиться достаточно сложно. Можно, но сложно. И измерять качество тоже сложно. Допустим, у нас один класс предсказывается всегда хорошо, а второй хуже. Как мы будем сравнивать между собой модели? Одна хорошо предсказывает один класс, вторая хорошо предсказывает другой. Тут тоже очень удобны нейронные сети, просто потому, что они органично работают с многоклассовыми и с multilabel классификациями.
 Наша целевая функция, Loss Function, оптимизируемый функционал - обычно какая-нибудь удобная, дифференцируемая функция, зависящая от наших данных и разметки. Мы хотели бы оптимизировать, например, прибыль в деньгах, но, как правило, бизнес-метрики не могут быть использованы для оптимизации: они часто недифференцируемые, зависят от внешних данных, которые, к тому же, все время меняются, вроде курса доллара и евро. И часто вычислительно дорогие, потому что за ними приходится ходить в какие-нибудь другие базы данных. На сайте paperswithcode.com есть подборка - типичные целевые функции в зависимости от того, с какой проблемой вы столкнулись: что у вас с балансом классов, что у вас с вашей целевой метрикой. Вы можете подобрать разные целевые функции под разные задачи.
Наша целевая функция, Loss Function, оптимизируемый функционал - обычно какая-нибудь удобная, дифференцируемая функция, зависящая от наших данных и разметки. Мы хотели бы оптимизировать, например, прибыль в деньгах, но, как правило, бизнес-метрики не могут быть использованы для оптимизации: они часто недифференцируемые, зависят от внешних данных, которые, к тому же, все время меняются, вроде курса доллара и евро. И часто вычислительно дорогие, потому что за ними приходится ходить в какие-нибудь другие базы данных. На сайте paperswithcode.com есть подборка - типичные целевые функции в зависимости от того, с какой проблемой вы столкнулись: что у вас с балансом классов, что у вас с вашей целевой метрикой. Вы можете подобрать разные целевые функции под разные задачи.
 И декомпозиция задачи хорошо работает. Часто задачу можно разбить на подзадачи, каждая из которых будет решаться своей моделью. Например, в распознавании капчи можно выделить задачу разбиения капчи на отдельные символы, повороты и масштабирование, и потом уже распознавание этого символа. Обычно декомпозиция задачи позволяет учить модель на меньших объемах данных. Такие модели легче тестировать и отлаживать, просто потому, что вы можете изолировать ошибку на каком-нибудь этапе и с ней работать с помощью каких-нибудь бизнес-правил или дополнительных моделей.
И декомпозиция задачи хорошо работает. Часто задачу можно разбить на подзадачи, каждая из которых будет решаться своей моделью. Например, в распознавании капчи можно выделить задачу разбиения капчи на отдельные символы, повороты и масштабирование, и потом уже распознавание этого символа. Обычно декомпозиция задачи позволяет учить модель на меньших объемах данных. Такие модели легче тестировать и отлаживать, просто потому, что вы можете изолировать ошибку на каком-нибудь этапе и с ней работать с помощью каких-нибудь бизнес-правил или дополнительных моделей.
 Иногда мы хотим оптимизировать одновременно несколько показателей. Например, продажи и прибыль. В некотором смысле, если мы управляем ценой, продажи и прибыль противоречат друг другу. Это зависит от эластичности спроса: мы можем сильно уронить нашу цену - продажи вырастут, и прибыли тоже не будет. Для того, чтобы оптимизировать одновременно несколько показателей, мы можем использовать взвешенную сумму. У нас есть какой-то один лосс и второй лосс, и мы их с некоторыми весами складываем при оптимизации. А еще мы можем ограничить какую-то из метрик. Например, мы хотим максимизировать наши продажи, при том, чтобы прибыль не упала ниже какого-то порога. В оптимизации это обычно делается с какими-нибудь, допустим, hinge loss, или контрастивный loss, когда мы до определенного порога не учитываем какую-то часть функции потерь, а начинаем ее учитывать, только когда она переходит через определенный порог. То есть мы ограничиваем какую-то метрику порогом, а вторую хотим сделать как можно лучше.
Иногда мы хотим оптимизировать одновременно несколько показателей. Например, продажи и прибыль. В некотором смысле, если мы управляем ценой, продажи и прибыль противоречат друг другу. Это зависит от эластичности спроса: мы можем сильно уронить нашу цену - продажи вырастут, и прибыли тоже не будет. Для того, чтобы оптимизировать одновременно несколько показателей, мы можем использовать взвешенную сумму. У нас есть какой-то один лосс и второй лосс, и мы их с некоторыми весами складываем при оптимизации. А еще мы можем ограничить какую-то из метрик. Например, мы хотим максимизировать наши продажи, при том, чтобы прибыль не упала ниже какого-то порога. В оптимизации это обычно делается с какими-нибудь, допустим, hinge loss, или контрастивный loss, когда мы до определенного порога не учитываем какую-то часть функции потерь, а начинаем ее учитывать, только когда она переходит через определенный порог. То есть мы ограничиваем какую-то метрику порогом, а вторую хотим сделать как можно лучше.
 Дополнительные материалы:
Дополнительные материалы: