
- 23.12.2022
- 25.08.2024
- обучение
- #mlsystemdesign
Четырнадцатая лекция открытого курса "Дизайн систем машинного обучения", "ML инфраструктура и платформы".
Слайды можно скачать тут mlsysd14ods.pdf
Текстовая расшифровка:

Добрый день. Сегодня у нас 14 лекция курса "Дизайн систем машинного обучения" — про ML-инфраструктуру и платформы.


Что такое инфраструктура? Инфраструктура в Википедии определяется как комплекс взаимосвязанных обслуживающих структур или объектов, составляющих и обеспечивающих основу функционирования системы. Можно сказать, что ML-инфраструктура — это набор обеспечивающих систем и инструментов для поддержки жизненного цикла системы.
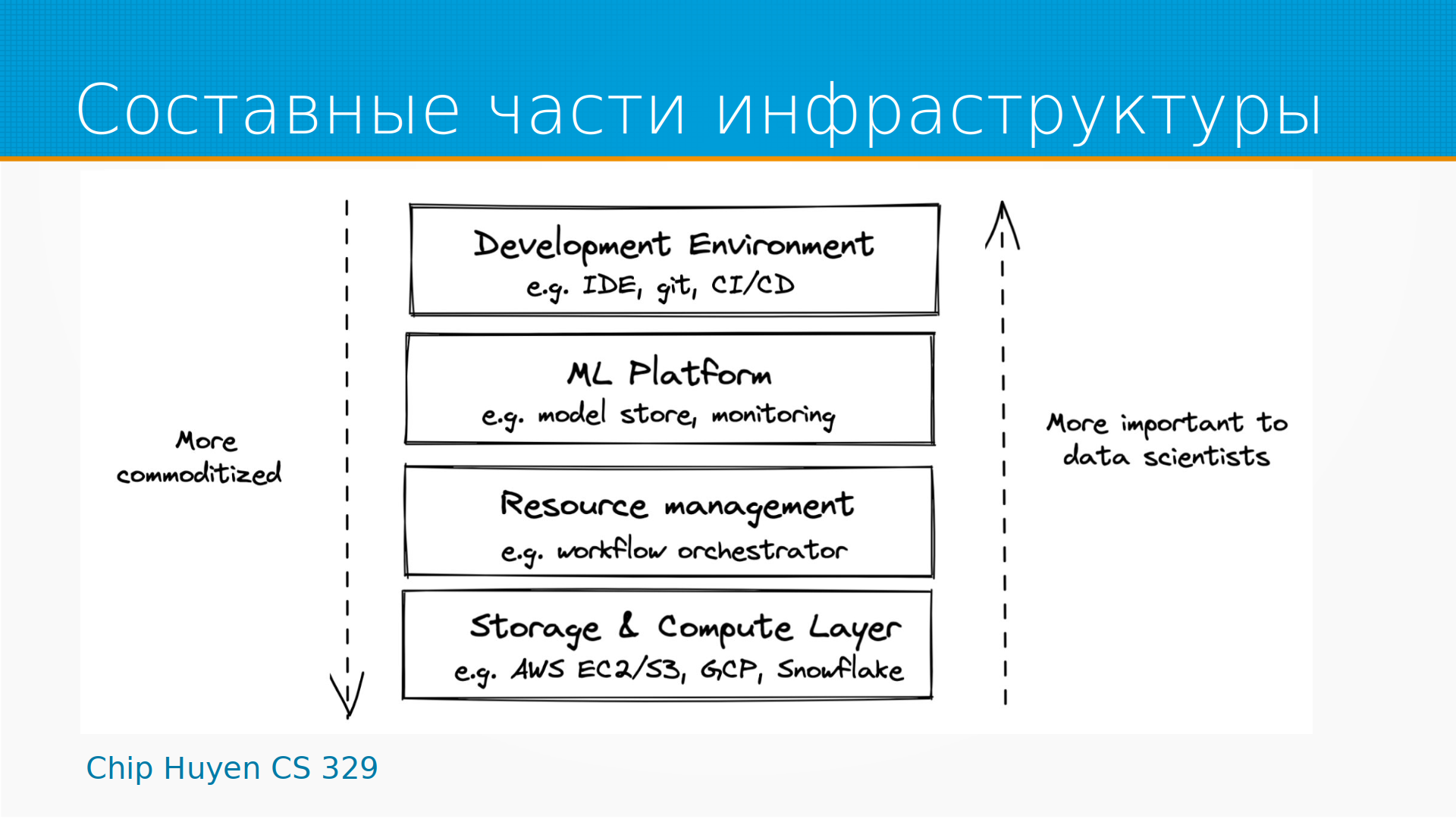
Мы можем думать об инфраструктуре как о некотором многослойном окружении, в котором наша модель существует и развивается. В этом окружении можно выделить слой вычислительный, слой хранения, это Amazon Storage, Google Storage, Яндекс.Диск и так далее. Есть слой управления вычислительными ресурсами и хранением данных. Есть ML-платформы, в которых мы храним наши модели, и испольуем их для развертывания и мониторинга. Есть некоторая среда разработки, jupyter ноутбуки, git, pycharm, IDE, CI/CD и так далее. Чем выше в этой пирамиде, тем мы ближе к дата-саентисту и тем более уникальные части инфраструктуры у нас есть. Каждый настраивает инструмент под себя. Ближе к вычислительным платформам у нас все становится более и более одинаково. Облачное хранилище примерно одно и то же у всех провайдеров.

Какие проблемы решает инфраструктура? Почему мы вообще о ней говорим и думаем? Во-первых, инфраструктура позволяет ускорить и обеспечить воспроизводимость процессов. То есть, если у нас есть готовый, пайплайн выкатки моделей, новому разработчику не нужно выучивать все это, у нас снижается порог входа. Мы просто ему даем кнопку, он на нее нажимает и предположительно безошибочно и воспроизводимо, то есть, каждый раз одинаково, происходит выкатка. Тем самым мы снижаем затраты на разработку, на развертывание и поддержку. У нас большая экономия времени, а значит, и денег. Мы повторно используем инженерные решения — наша команда меньше изобретает велосипедов. И у нас есть некоторый единый набор подходов и инструментов, которые мы можем совершенствовать, и он сам по себе начинает являться полезным имуществом нашей организации.
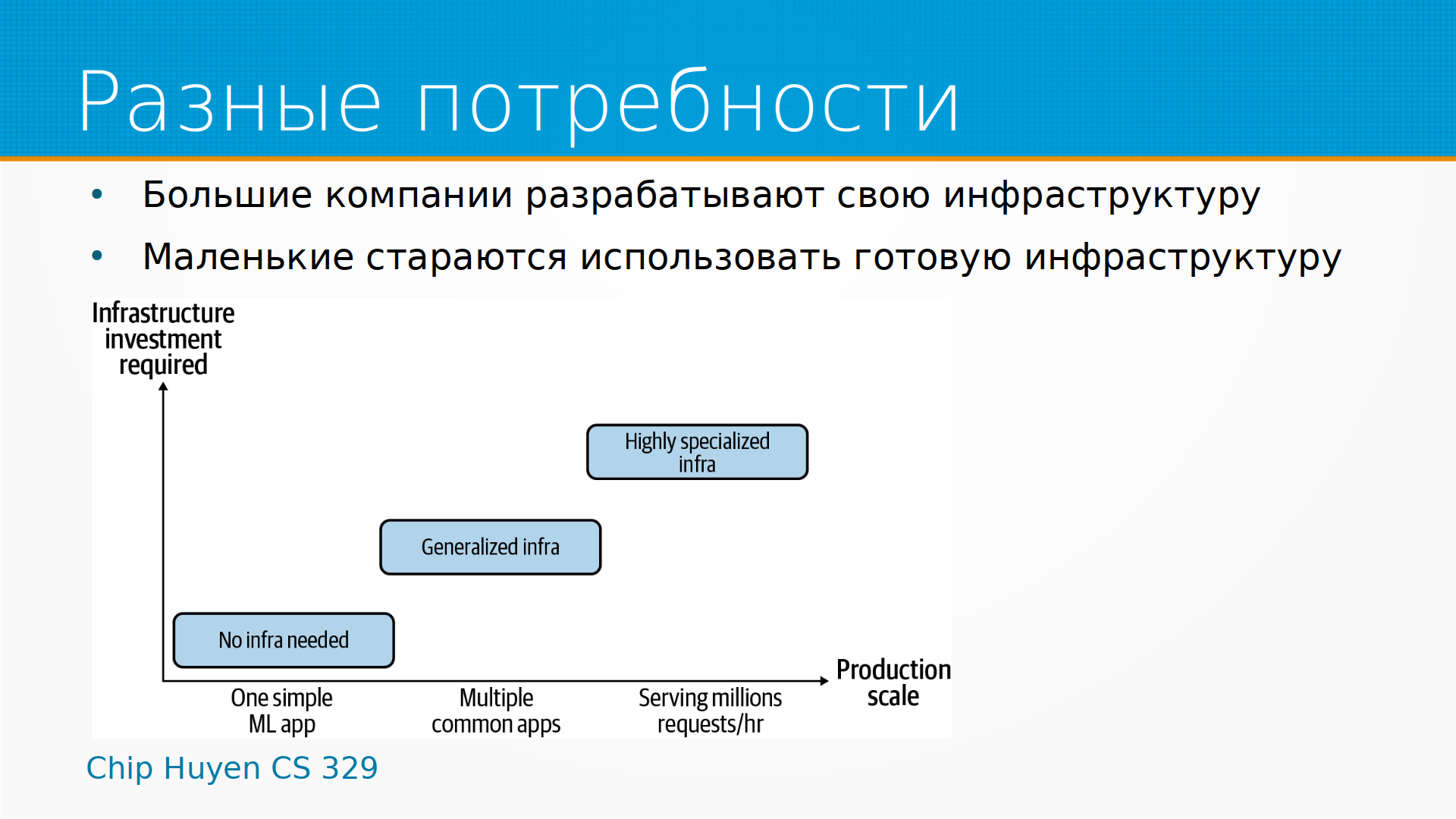
У разных организаций разные потребности в инфраструктуре. Большие компании часто разрабатывают свою инфраструктуру. У Амазона своя инфраструктура, он ее, собственно, продает. У Гугла своя инфраструктура, он тоже ее продает. У Майкрософт своя инфраструктура, он тоже ее продает. Так же и Яндекс.
Маленькие компании стараются использовать готовую инфраструктуру. И в зависимости от размера организации, от количества моделей, есть выбор между полностью готовой инфраструктурой и высокоспециализированной инфраструктурой. Большинство организаций, с которыми нам предстоит столкнуться, где-то посередине.

Все начинается с уровня хранения — где, собственно, хранятся данные? В конечном итоге, данные обычно хранятся на жестких дисках или SSD-дисках. Вообще-то, они могут храниться на стримерах. И это интересный пример, потому что мы думаем о данных, доступных в цифровой форме, как о данных, к которым мы обратились, и они сразу у нас появились. Но может случиться так, что данные у нас в каком-нибудь холодном хранилище, и, когда мы через API запросили эти данные, где-то там поехал робот на тележке, достал кассету из хранилища, физически кассету вставил в стример. И время от момента, когда мы захотели данные получить, до момента, когда данные мы получаем, может составить секунды или даже часы. Какие-то данные нам могут быть доступны через 6-8 часов после того, как мы захотели ими воспользоваться. И, например, у Амазона это разные классы хранилищ. У Яндекса, кстати, тоже есть.
Есть объектные хранилища, в которых у нас нет как таковых файлов. Есть блоки по 64, например, мегабайта, раскиданные между серверами. Для пользователя каждый из этих наборов блоков можно представить как файл. То есть сервер сохраняет файл из системы, раскидывает его на блоки, хранит у себя отказоустойчиво и надежно с нужным классом хранения, то есть с нужной скоростью доступа и стоимостью доступа к ней, и при необходимости собирает из кусочков обратно и отдает.
Более высокий уровень хранения, более сложный уровень хранения — это какие-нибудь Data Warehouse. Например, сервис BigQuery позволяет хранить структурированные данные как бы в базе данных. То есть нам кажется, что мы делаем записи в базу данных, у нас там строчки в базе данных, мы можем писать SQL-запросы в базе данных. А на самом деле это файлы, лежащие в файловой системе, и каждый раз, когда мы делаем запрос, по этим файлам запускается map reduce job, то есть какой-то сервис идет, вытаскивает из каждого файла данные, складывает их, группирует, обрабатывает в соответствии с планом, который был сгенерирован на основе нашего SQL-запроса, и потом возвращает нам результат. Для нас это выглядит как бесконечного размера SQL-хранилища, правда, немножко медленное.
И еще выше уровень хранения — это что-нибудь типа Snowflake, когда все это представляется для нас бесконечного объема и масштабируемости базой PostgreSQL. В PostgreSQL есть удобные драйвера, и за ними можно спрятать все что угодно, и получается — мы думаем, что мы храним данные в базе данных, а там совершенно отдельный сервис приложений, который позволяет на этих данных выполнять какие-то агрегации, ML-модели запускать и так далее и тому подобное. Но, опять же, оно все доступно нам как вроде бы база данных. То есть это разные абстракции поверх уровня хранения.
Ну и общая тенденция, что в слое хранения сравнительно дешевое место и дорогой трафик и обработка данных. Что, собственно говоря, я имею ввиду под дорогим трафиком — у большинства облаков дешевая загрузка данных в облако и дорогая выгрузка оттуда. Может быть даже бесплатная загрузка туда. А еще, например, в BigQuery тарифицируется тот объем данных, который вы обойдете вашим map reduce job задачей. То есть вы написали SQL-запрос "SELECT COUNT * FROM наша таблица". Вы обязали BigQuery пройти по всем этим файлам в хранилище, каждый из них посмотреть, а вам просто нужно было посчитать количество записей. И BigQuery, по-моему, оптимизирует именно этот вид тупых запросов. Но в целом надо понимать, что такой запрос, который вернет вам одно число, может перелопатить терабайт данных и влететь вам, например, в 5 тысяч долларов. То есть есть такой интересный дата-сет GDELT, доступный бесплатно в BigQuery. Вы оплачиваете только запросы к нему. Ну и вот наивный запрос к нему в 5 тысяч долларов вам обойдется — просто потому, что данных много.

Выше над уровнем хранения у нас есть уровень вычислений. И разнообразие тут очень велико. Можно выделить слои непосредственно Baremetal servers, то есть когда у нас есть что-то, что можно потрогать рукой. У нас есть центральный процессор CPU, у нас есть видеоускорители GPU, и мы физически к этому серверу имеем доступ. Это сервер. Он стоит либо у нас, либо он стоит в colocation, в стойке провайдера. Но так или иначе — когда в нем сгорает жесткий диск, это наша проблема, мы едем и меняем его.
В принципе тут где-то есть промежуточный этап, когда мы арендуем сервер со всем обслуживанием, и, когда в нем сгорает жесткий диск, туда едет специалист из дата-центра и тоже его меняет. Но все равно это физический сервер.
Мы беспокоимся о резервном копировании, мы беспокоимся о настройке операционной системы и разных параметрах ядра. И, собственно, если сгорает железо, то это наша проблема.
Следующий уровень абстракции — это виртуальные сервера. И у нас есть виртуальные CPU и виртуальные GPU. И мы покупаем сервер с 5, или 10, или 40, или 100 виртуальными CPU. Это удобно, потому что на самом-то деле эти виртуальные CPU размазаны, они находятся на каком-нибудь из больших серверов в дата-центре, и вы можете его спокойно масштабировать. Они обычно обходятся дороже в расчете на CPU, чем аренда сервера, но зато их можно резать мельче. А еще арендовать, допустим, 0.5 виртуального CPU, или даже 0.25. А еще обычно провайдер всех этих сервисов предоставляет вам услуги защиты резервным копированием, и защиту, например, от DDoS, сам решает проблемы со сгоревшими сетевыми картами и так далее.
Выше по уровням абстракции — это запуск контейнеров. То есть, у нас есть App Runner в Амазоне или Cloud Run в Гугле, или serverless-контейнеры в Яндексе, когда мы собираем свой докер-контейнер, отдаем его сервису и говорим — знаешь, мне все равно, на чем ты его будешь высполнять, вот тебе, пожалуйста, докер-контейнер, где-нибудь у себя в кубах его запусти, и не беспокой меня этими глупостями. Это удобно и хорошо.
Следующее логичное развитие этой же концепции, то есть подъем выше по уровню абстракции — это облачные функции. Первыми из них были AWS Lambda амазоновские, гугловские Cloud Functions. И вот в Яндексе есть Yandex Cloud Functions, это когда буквально вы пишете какой-то код на Питоне, отдаете его сервису, говорите — смотрите, вот этот код на Питоне, вот ему требуются такие зависимости, пожалуйста, сделай мне из этого сервер, который будет выполнять эту функцию, смасштабируй ее как надо, управляй ей, заботься о ней, а я хочу только дергать это по API.
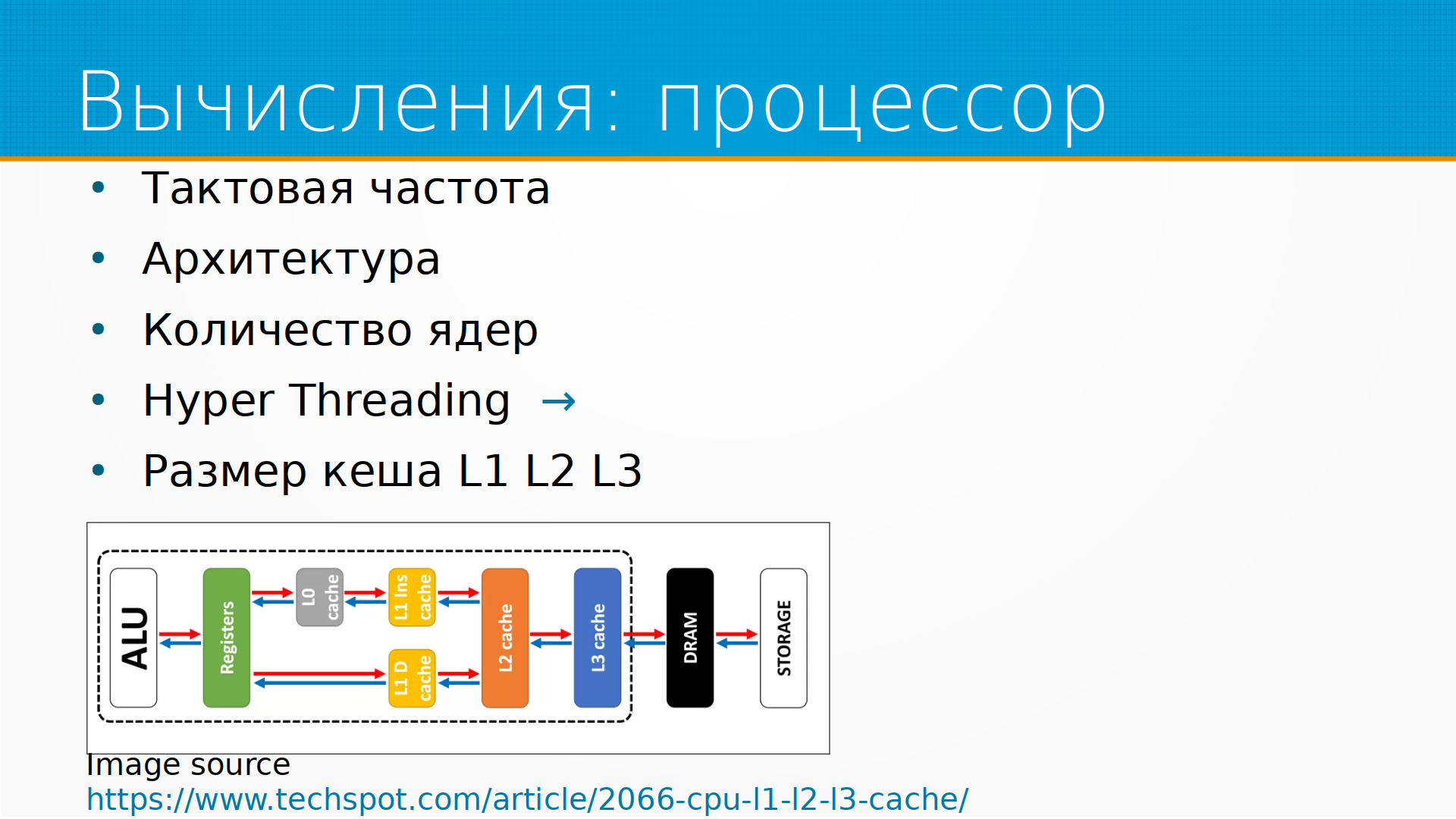
Под капотом всех этих вычислительных мощностей лежит процессор. У процессора есть свои характеристики, такие как, например, тактовая частота, о которой мы думаем — чем быстрее тактовая частота, тем в принципе быстрее работает процессор. Хотя тут есть свои хитрости — например, очень многие процессоры снижают тактовую частоту, чтобы экономить электроэнергию, и у вас на процессоре написано, допустим, 2.6 ГГц, он реально работает на 500 МГц, просто чтобы ему было прохладно.
Архитектура. Более современные архитектуры зачастую работают быстрее или потребляют меньше электроэнергии.
Количество ядер имеет значение.
У современных процессоров есть еще такая штука, как гипертрейдинг — это когда одно ядро притворяется двумя. Проблема тут в том, что зачастую в работе процессора возникают заминки — нужно данные какие-то откуда-то подкачать, еще что-нибудь, и сам по себе вычислительный блок в это время простаивает. И мы могли бы одну задачу держать в уме, то есть сейчас нам подгружаются нужные данные, а другую в это время делать, считать. Такое "солдат спит, служба идет". И вот эта технология называется гипертрейдинг, по ссылке со слайда там есть подробное описание, как она работает. Есть одна проблема. В принципе мы, получается, можем использовать одновременно два потока исполнения, и в статистике nproc, например, он тоже показывается как два процессора, и продают его нам часто как два vCPU, но реально ускорение в два раза обычно не происходит, то есть среднее ускорение там 15-20-30%. В некоторых случаях гипертрейдинг, наоборот, замедляет работу, потому что предсказание конвейера путается. То есть с гипертрейдингом надо осторожно.
Еще имеет значение у процессора размер кэша. О чем это? Процессор, что он делает — он берет одни числа, складывает их, умножает, перекладывает с места на место. Все это он способен делать в регистрах, так называемых. Доступ к регистрам у процессора очень быстрый. Одна проблема, что регистров очень мало — по-моему, 11 у интеловских процессоров, если не считать регистры FPU, то есть с плавающей запятой. Соответственно, есть разные уровни кэша, и чем медленнее они работают, тем они больше. Чем дальше от вычислительного ядра наш кэш, тем больше его размер, тем медленнее к нему доступ. Можно упрощенно сказать, что на этом рисунке каждая следующая ступенька работает в 10 раз медленнее. И еще медленнее работает память, а еще медленнее работает диск, с которого читается.
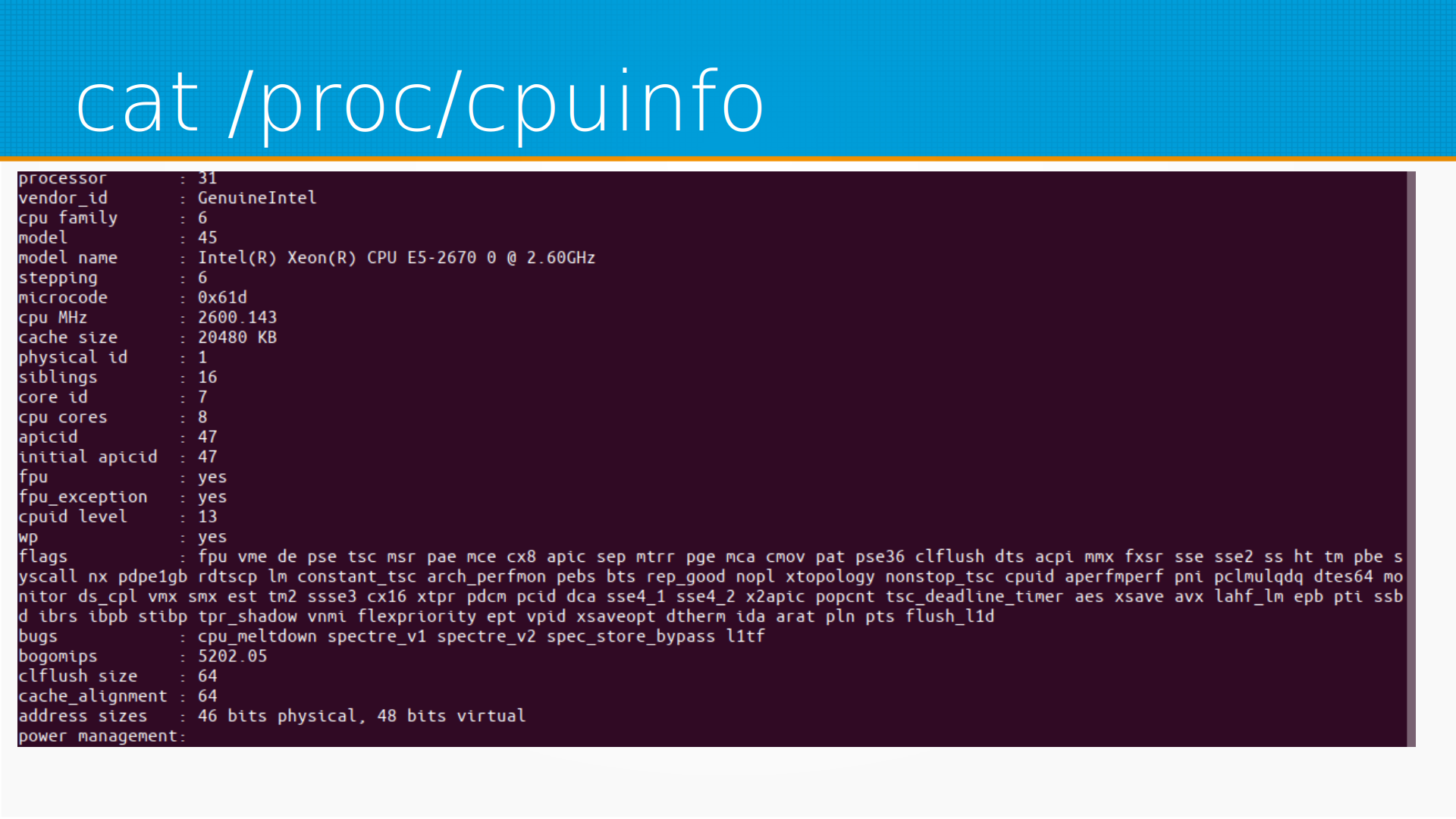
Где мы можем посмотреть информацию о процессоре? В линуксе в cpuinfo мы можем посмотреть количество ядер, данные о процессоре, текущую скорость и просто скорость.
Еще мы можем посмотреть флаги процессора. То есть у каждого процессора есть какие-то наборы команд, которые он поддерживает, и на самом деле у каждого поколения процессоров они разные. Тут еще, например, есть bogomips — это условная производительность процессора в, общем, попугаях. Чем она больше, тем он быстрее. Трудно это во что-нибудь серьезное отобразить. В данном случае — вот это серверный Xeon, 16-ядерные процессоры, и тут мы видим его флаги.

И вот что интересно — до сих пор можно столкнуться с тем, что, допустим, MongoDB требует флаг AVX. Казалось бы, уже 10 лет у всех процессоров этот набор инструкций поддерживается, но нет. Мы лично у заказчика этой весной на эту граблю наступили. Живой, вполне рабочий сервер, MongoDB обновляли с 4.6 на 5.0 — и оно перестало работать, потому что на этих серверах не было AVX Instruction Set.
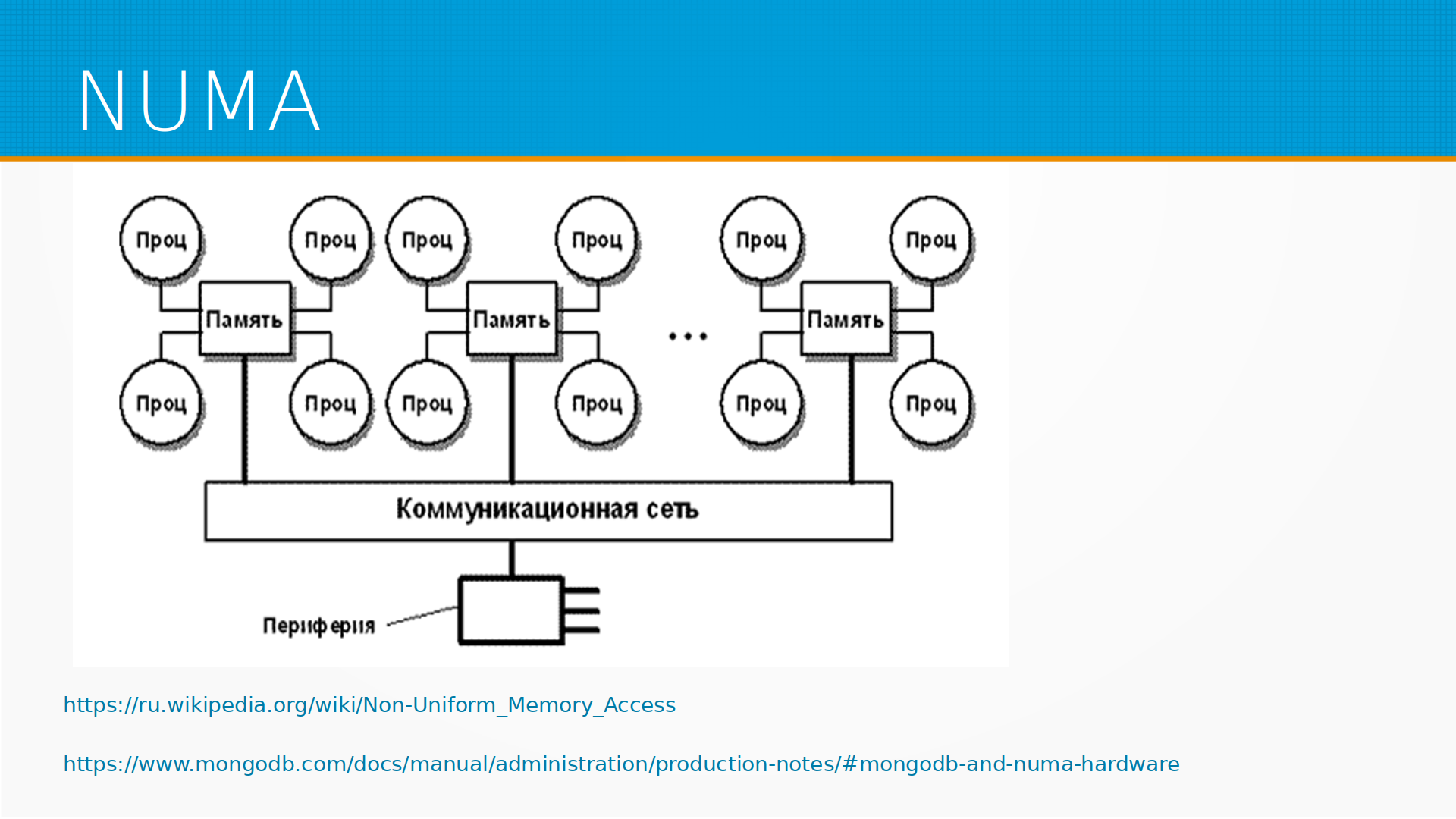
И еще из особенностей, с которыми можно столкнуться на многопроцессорных системах — это то, что процессору далеко до памяти, просто физически по дорожкам на материнской плате далеко. Совершенно неудобно работать всем процессором со всей памятью одновременно. И получается так, что у каждого набора ядер, у каждой группы ядер, есть своя какая-то память, к которой они могут обращаться напрямую, а к остальной они идут через специальную шину. Есть вот такая городская легенда, что через специальную шину обращаться сильно медленнее. На практике разница в процентах. То есть может быть на 10-15% медленнее может быть доступ к памяти.
Есть другая проблема. Иногда программное обеспечение, которое не рассчитано на работу в NUMA-платформах, где процессоры собраны в группы со своими кусками памяти, может сталкиваться с race condition, когда процессоры блокируют доступ к памяти друг другу. И, допустим, та же самая MongoDB рекомендует отрубать возможности NUMA. Обычно в выводе информации о процессоре можно как раз увидеть, есть там NUMA или нет. Во всех многоядерных системах она есть. Например у MySQL есть свои особенности с NUMA и еще тут про swap и NUMA.
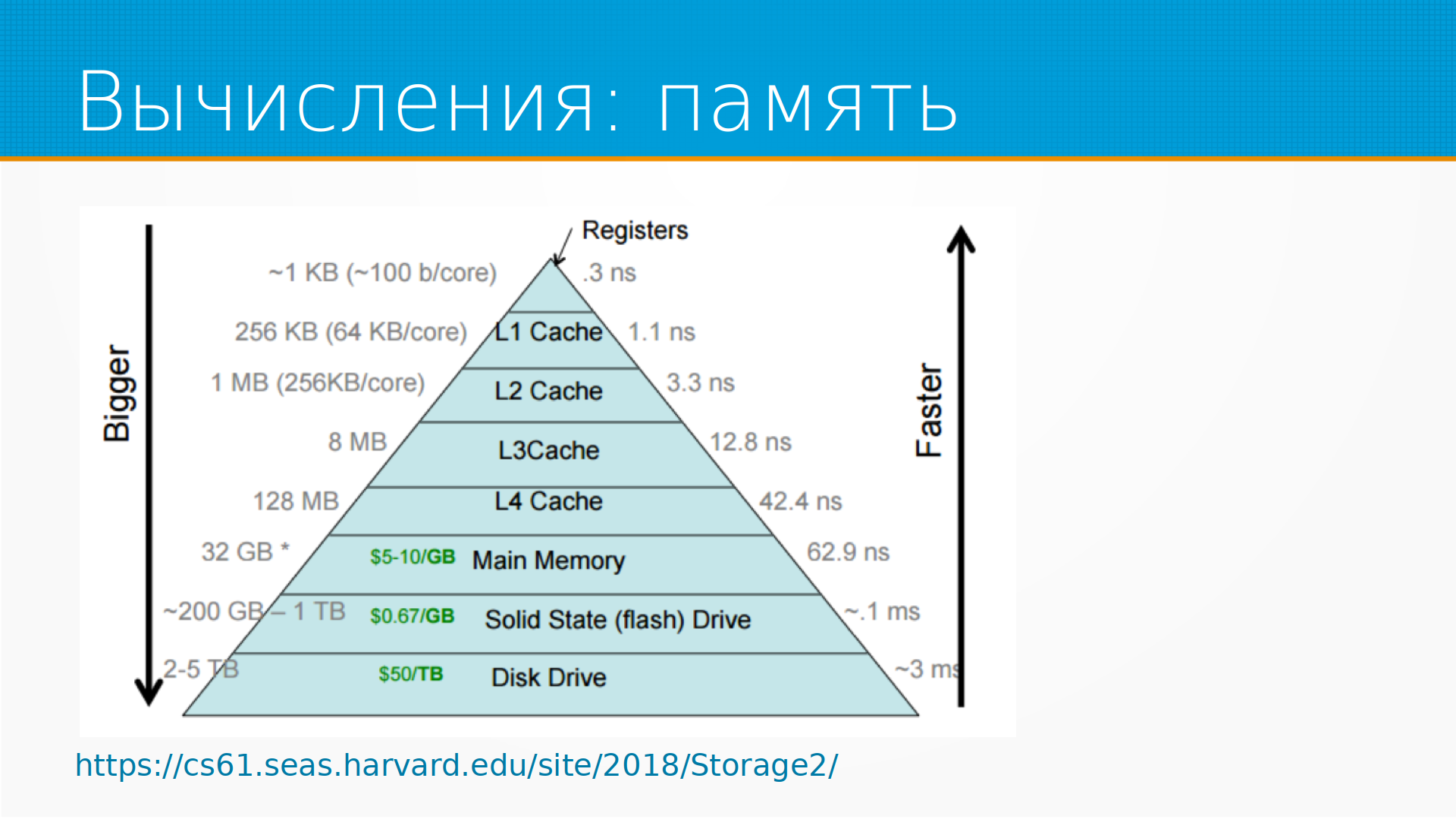
По скорости, как я уже говорил — чем дальше от вычислительного ядра, тем скорость меньше. И вот на этой диаграмме есть примерное, по состоянию на 2018 год, сейчас все немножечко легче стало, но, тем не менее, примерное соотношение скоростей. То есть в регистры вы получаете доступ условно за 3 наносекунды, а для того, чтобы прочитать что-то с диска, вам нужна 1 миллисекунда. И разница огромная, но разница и в скорости, и в вместимости.

Дальше у нас есть память. Про память мы обычно думаем как про что-то, обладающее размером, то есть вот у нас 100 гигабайт памяти, 50, 60 гигабайт памяти. Еще у памяти бывает и не бывает четность, то есть память с проверкой ошибок. Ошибки, кстати, в памяти встречаются гораздо чаще, чем принято думать. И очень часто, кстати, ошибки диска, дисковых подсистем, — это ошибки памяти или, тоже часто бывает, ошибки кабелей, которые ведут в диск.
Так вот, у памяти кроме размера важна еще пропускная способность. То есть память организована в некоторые блоки, банки, и у банков есть ширина шины, то есть сколько данных передается за один прием. Грубо говоря, если вам нужно передать 1 байт, то вы передать 1 байт не можете — вы можете передать столько, сколько пролетает за 1 передачу по шине. Поэтому, когда вам говорят, что пропускная способность шины, скажем, условно x гигабит в секунду, то x гигабит в секунду — это пропускная способность, если вы будете передавать пакетами, ровно равными размеру шины. Это может быть, например, 386 байт. То есть полная пропускная способность памяти на коротких, маленьких, случайных чтениях может быть недостижима.
С памятью видеокарт, GPU, все еще хуже. GPU память хранит и модель, и данные. В GPU есть своя еще иерархия памяти внутри, то есть есть регистры GPU, есть блоки, у них своя маленькая память, есть память групп блоков, и везде мы по этой иерархии идем, то есть чем дальше от непосредственно вычислительных ядер, тем медленнее. И в принципе главный плюс от CUDA — это то, что нам не приходится руками управлять этим перераспределением задач между ядрами и данных между памятью. Это довольно мучительно, я помню еще, как программируется все это руками. Вам приходится приспосабливать программу под архитектуру каждой конкретной карты, помнить про ее ширину шины и так далее.
Но сейчас, поскольку мы используем CUDA, CUDA прячет от нас этот кошмар, нам достаточно просто помнить, что у GPU очень медленный обмен с основной памятью. И часто встречаются ситуации, когда мощные быстрые видеокарты, то есть V100, A100, простаивают большую часть времени, то есть у нее загрузка 15-30%, просто потому, что не успевает подгружать данные. То есть считаются данные быстро, а подгружаются данные медленно.

Вот в частности цитата. Ребята использовали, правда, не CUDA-ядра, а так называемые Tensor Cores. Они очень быстрые, и у них не получалось загрузить их больше, чем на 30%. То есть все упиралось в производительность памяти.

Что выбрать, свои сервера или облака? Ну, условно можно сказать, это такие очень в попугаях измерения, что если сервер на своей стойке на своей территории, скажем, обойдется вам, например, в 100 тысяч рублей, то арендованный в стойке обойдется вам, допустим, в 300, а арендованный в облаке съест у вас полтора миллиона за это же время. И зачем же тогда брать в облаке? Свои сервера обычно сильно не нагружены. Облако позволяет вам взять столько вычислительной мощности, сколько нужно вам прямо сейчас. Сервера мы вынуждены покупать про запас, потому что, не дай бог, придет пик, мы должны иметь возможность его обработать.
У маленьких организаций, по-хорошему, нет выбора. Им надо размещать свои сервисы в облаке, потому что поддерживать свою серверную инфраструктуру долго, хлопотно. Это только кажется дешевым — поставил сервер под стол и работает. Но, как только вы начинаете заботиться о доступности, о связности, об электропитании, то сразу сервер, стоящий под столом, становится золотым.
У быстрорастущих стартапов тоже нет выбора. Им облака объективно дешевле, потому что цикл покупки серверов может не успевать за скоростью их роста.
Но вот уже большие организации частично мигрируют из облаков. Есть интересный рассказ дропбокса, как они начали мигрировать назад из облаков. Они сначала стартанули в облаках, а потом часть серверов утащили к себе в дата-центры, часть вычислительных мощностей. И получилось, что в первый же год после миграции они сэкономили на этом 75 миллионов долларов. Ну, как бы немало.
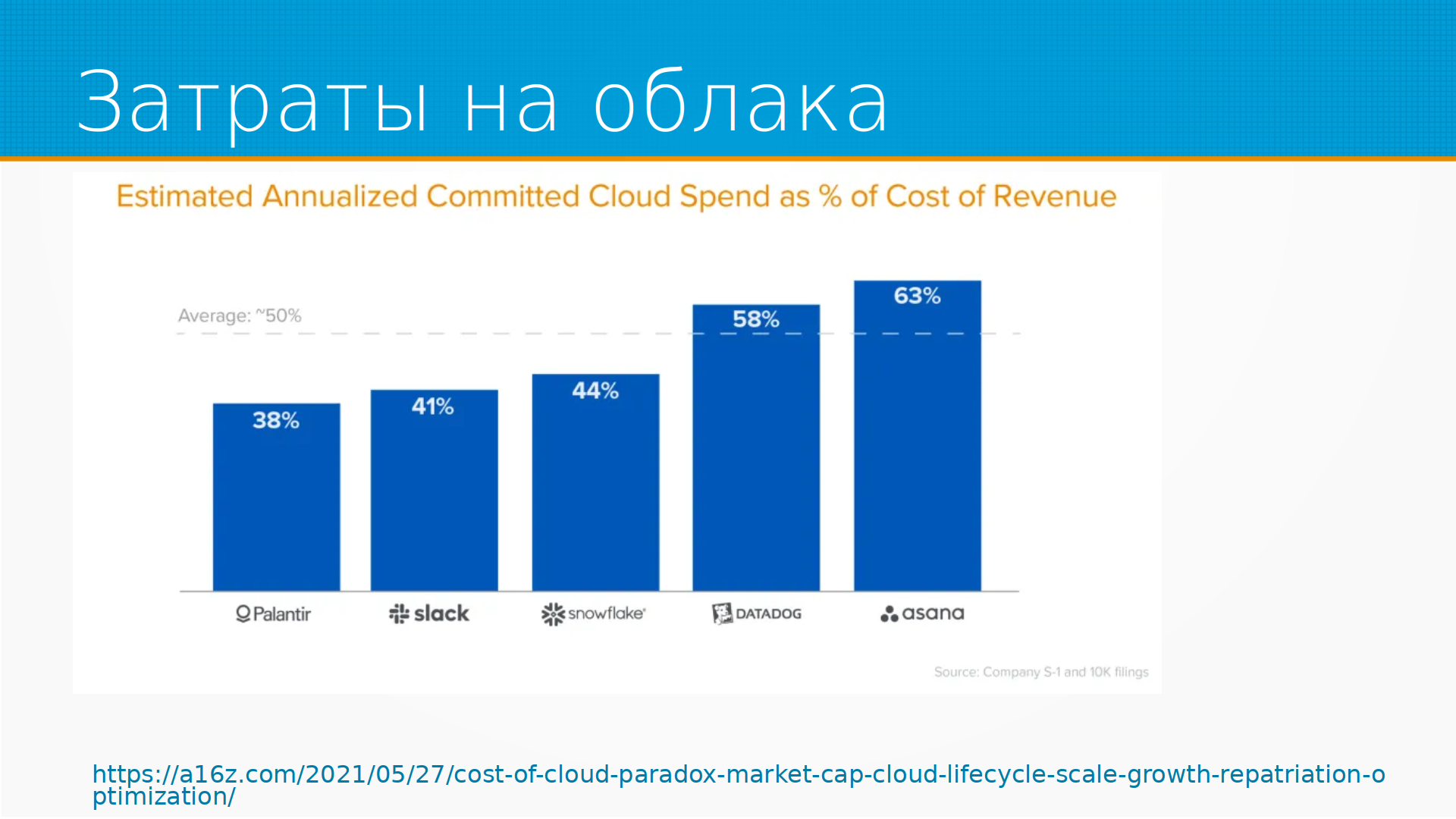
Затраты на облака составляют самый большый, непрерывный кусок затрат современных стартапов, о которых мы помним. То есть вот Asana — здесь оценки, то есть на самом деле это не рассказ, сколько Asana тратит, это по косвенным признакам аналитики оценили, сколько у них денег уходит от общих затрат на облака. И видим, что немало — в среднем половину.

После того, как мы обеспечили наши вычмощности и где-то мы храним наши данные, нам эти задачи надо как-то запускать. В Linux тривиальный выход — запускать задачи по расписанию, cron. Но, во-первых, cron работает в том случае, если у вас есть физический сервер, а у вас, допустим, физического сервера как такового может и не быть, то есть вы работаете в каком-нибудь серверлесс-окружении. Во-вторых, cron не отслеживает взаимосвязи задачи, то есть если у вас пайплайн, состоящий из пяти шагов, и второй из них упал, то третий спокойно запустится, отработает на старых данных, и никто ничего не заметит. Или если у вас задача может запуститься раньше, чем отработала предыдущая же ее версия, и у вас получится какой-нибудь нехороший race condition.
Дальнейший уровень развития — это планировщики, например, SLURM. Планировщик решает, когда запускать задачу. И оркестраторы — оркестраторы решают, где запускать задачу. Самый популярный оркестратор – это Kubernetes. В принципе, все планировщики так или иначе умеют в оркестрацию, и все оркестраторы так или иначе умеют в планирование. В общем, это условные разделения. Это способ думать. Планировщик решает, когда запускать задачу, оркестратор — где.

Плюс у задач есть последовательность, как я говорил, допустим, pipeline из пяти задач, и мы должны отслеживать эту последовательность. Для этого есть системы workflow-менеджмента, то есть управление потоком задач. Этап расчета в их терминах – это обычно task; граф последовательного выполнения задач – это directed acyclic graph, направленный ациклический граф, то есть в нем нет петель; и одно выполнение графа – это, например, flow. И поток, flow, запускается вручную, по расписанию или по какому-то внешнему событию, в Airflow и Dagster это называется сенсоры, то есть что-то стряслось в окружающем мире, и мы запустили flow. Примеры систем workflow-менеджмента – это, например, Airflow, Prefect и Dagster, сейчас мы по ним бегом пробежимся, по верхам.

Вот пример того, как workflow может быть устроен в Airflow. То есть мы импортируем некоторый класс DAG, и нашу задачку, которая печатает Airflow, мы оформляем как task, и из набора этих task-ов собран наш граф выполнений.
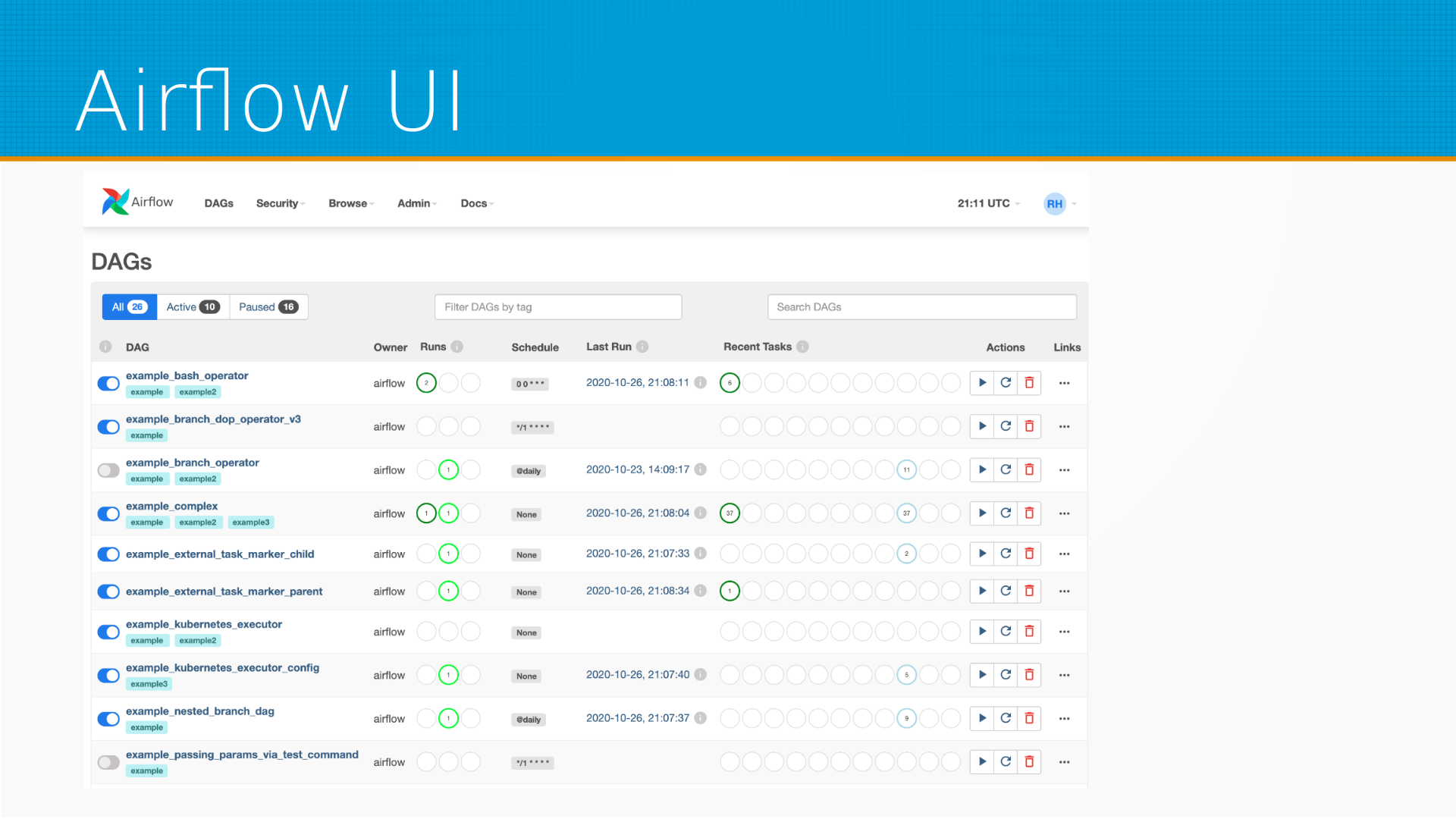
Мы запускаем его на выполнение, и у нас есть пользовательский интерфейс, с которым мы можем ставить эти задачи в расписание, мы можем смотреть, как они запускались, смотреть их логи, запускать вручную и удалять-добавлять новые, смотреть, кто их разместил. То есть такое управление нашим пулом задач. Принято считать, что Airflow — для сравнительно медленных задач, то есть задач, которые вы запускаете какое-то количество раз в час, не чаще, чем раз в минуту.
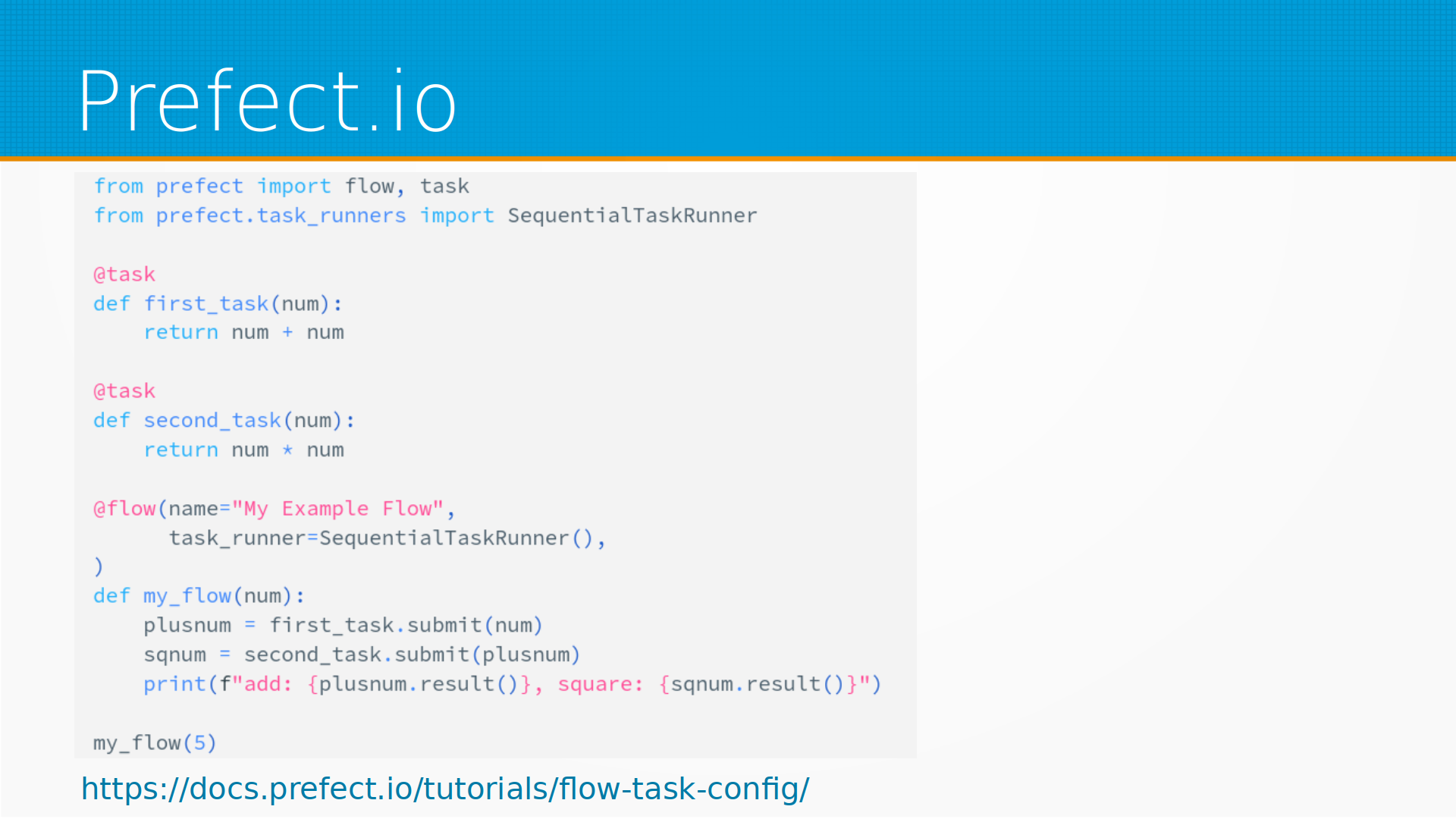
Следующее развитие, как говорят сами разработчики Prefect.io: мы взяли идею Airflow и сделали ее наконец-то нормально. Это тоже система управления потоком задач, где мы с помощью декораторов определяем наши задачи. В данном примере у нас есть первая задача first_task, вторая задача second_task, и собираем из них некоторый поток, в котором мы передаем одни таски в другие, и префект сам собирает из них граф и его выполняет. Граф может быть выполнен как на вашем компьютере, так и на каких-нибудь удаленных агентах, причем не обязательно, чтобы каждый таск был выполнен на одном и том же компьютере. То есть они выполняются, результаты собираются где-то и передаются на выполнение дальше.
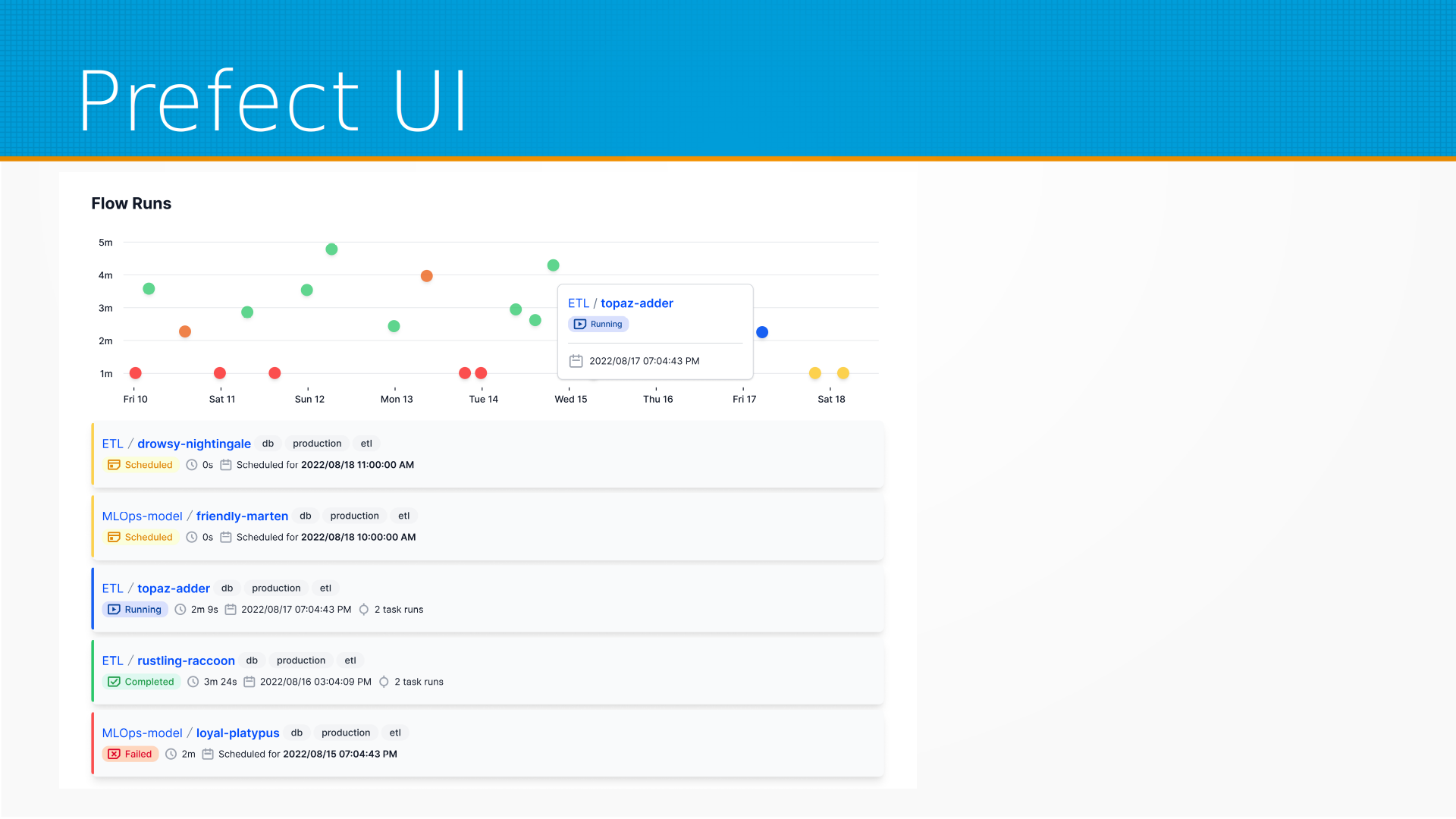
И вот это пример запуска flow в Prefect. Префект отслеживает версии flow, хранит историю и показывает, как те или иные потоки выполнялись, какие из них были выполнены успешно, какие запланированы, какие будут выполняться дальше.
Создатели Prefect утверждают, что он позволяет более гранулярно запускать задачи, чем Airflow. И мы сами работаем на Prefect, это наша базовая система flow-менеджмента, нам она нравится. У нее есть некоторое количество недостатков — в основном то, что ее командный центр, он SaaS, то есть он крутится не на вашем компьютере, а где-то там вдалеке, и вы должны за него платить, это неудобно. Из удобств — то, что до трех пользователей они предоставляют доступ бесплатно, и у Prefect более логично сделана передача данных, чем у Airflow. Ну, собственно, у Airflow она сделана никак, а у Префекта она сделана как-то.
Airflow сервер вы можете, кстати, развернуть у себя, и Префект сервер вы тоже можете развернуть у себя, но там вам надо будет самому заниматься безопасностью этих серверов, и тут все у Префекта неоднозначно — вы можете развернуть сервер, но никакой защиты на нем не будет. То есть вы должны положиться на то, что он работает внутри закрытого контура, например, на вашем кластере kubernetes, куда никто чужой не попадет.
У Airflow в опенсоурс есть админка, но с защитой API-агентов там тоже свои есть проблемы, о которых часто забывают. В общем, с безопасностью надо осторожно.
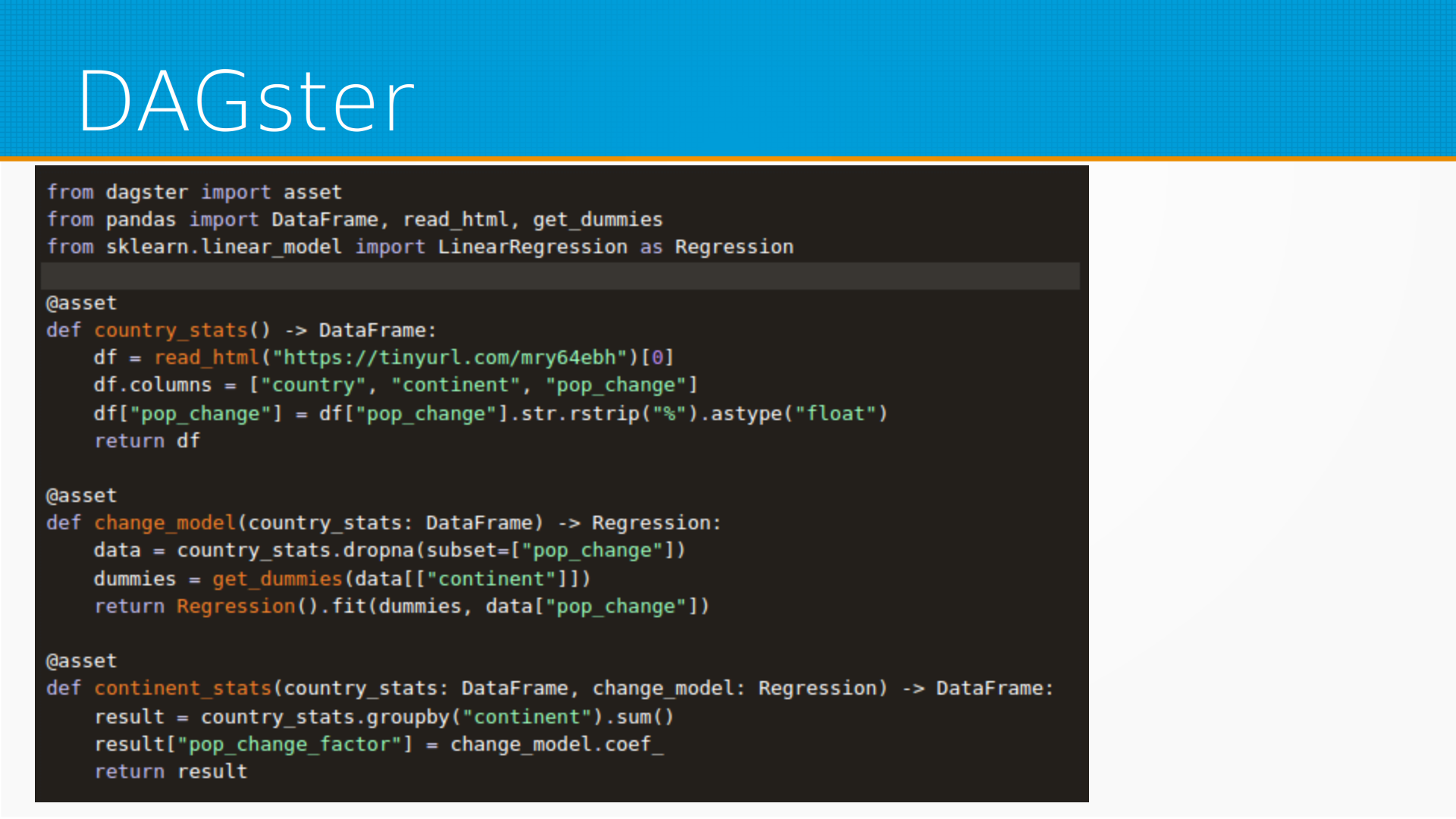
И третья система — это Dagster, у нее тоже есть SaaS-версия, вы можете запустить ее у себя, она похожа на Prefect. И вот тут вы определяете некоторые ассеты — это то, что таски у Prefect.
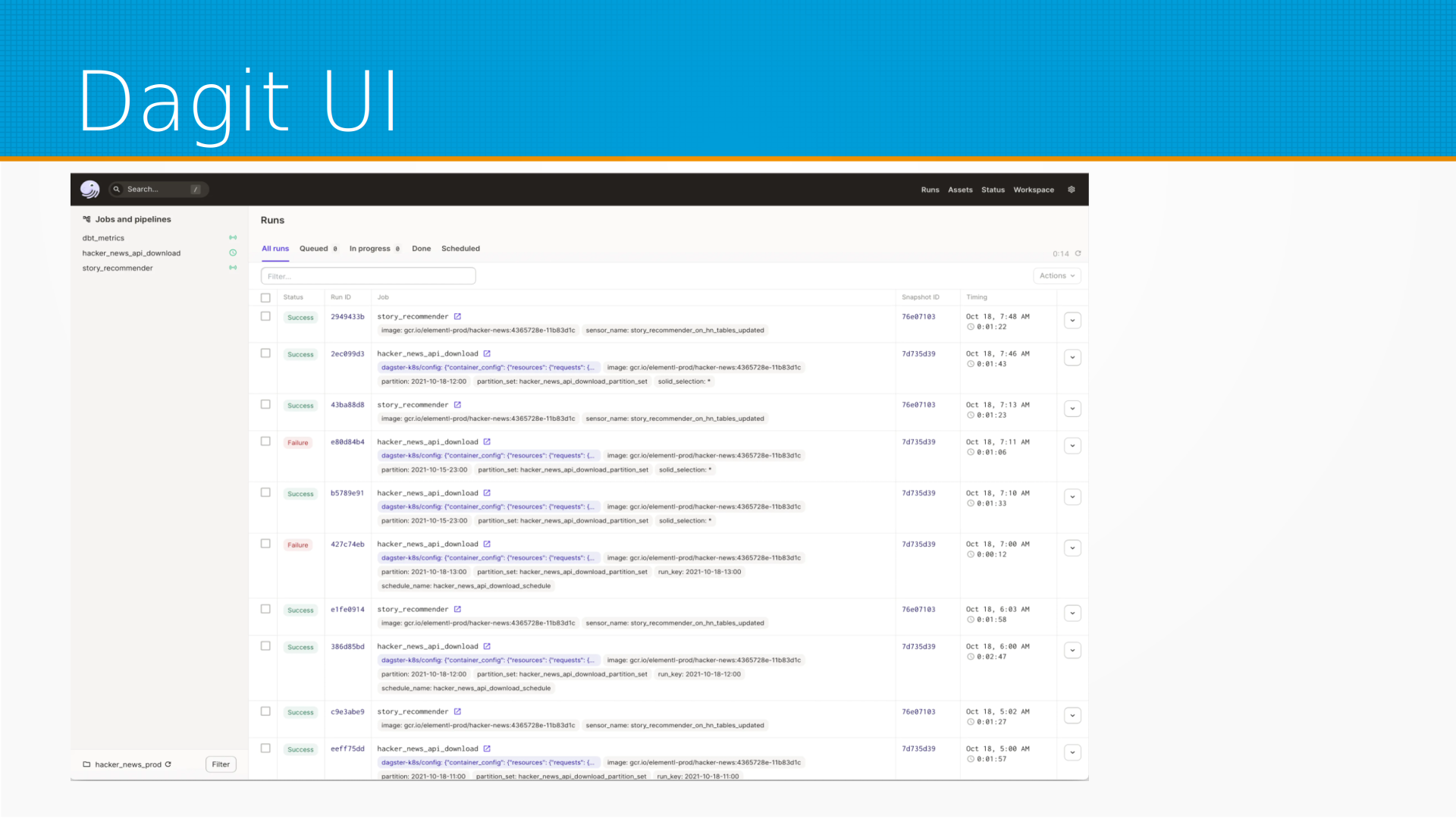
Dagster использует pydantic для того, чтобы определить структуру параметров, то есть что можно передавать между задачами, и у него свой пользовательский интерфейс есть, Dagit UI, который позволяет тоже смотреть, когда кто запускал, когда что будет запущено, что где сломалось и так далее.

Следующий этап усложнения инфраструктуры — это ML-платформы. Ключевые задачи, которые решают ML-платформы — это развертывание, хранилище моделей, мониторинг, отслеживание экспериментов, сбор метрик, дашборды и feature store, то есть витрины данных. Строго говоря, feature store — это не совсем витрины данных. И обо всем этом мы уже говорили в предыдущих лекциях, а сейчас затронем немножечко фич-сторы.

Какие есть вообще проблемы с признаками? Если у нас много моделей, то может получиться так, что разные модели используют одни и те же признаки, а мы их считаем независимо. То есть мы тратим лишние вычислительные мощности. Хорошо было бы посчитать признак один раз и использовать его во всех наших моделях.
Еще, если кто-то уже считает признаки, то хорошо бы снабдить данные документацией, чтобы другая команда или мы при разработке другой модели мы понимали, какой признак считается, какие признаки доступны.
Еще, даже если у нас разработчики считают их одинаково, мы не можем быть в этом уверены. Например, кто-то считает среднесуточные продажи, и при этом он считает сутки по гринвичу, а какая-то другая команда считает среднесуточные продажи, но она считает их в среднем по Москве, то есть от нуля Москвы до нуля Москвы. Кто-то считает, допустим, от нуля Новосибирска до нуля Новосибирска. Это просто живой наш пример, мы с этим сталкиваемся постоянно, что разные смежные организации считают одни и те же признаки по-разному. И здорово было бы иметь такой фич-стор, где у нас хранятся насчитанные признаки, они считаются всегда одинаково, все знают, как они считаются.
А еще, допустим, вы считали при обучении признаки вашей программы на Питоне и непосредственно инференс вашей программы делали на Питоне, потом вы выгрузили модель в какой-нибудь PMML, и инференс дальше делается оптимизированным Scala-бэкэндом, например, который считает по-другому. И может так получиться, что у вас признаки по-разному считаются на трейне и на вашем проде, и чтобы этого избежать, хорошо было бы иметь централизованное хранилище преднасчитанных признаков.
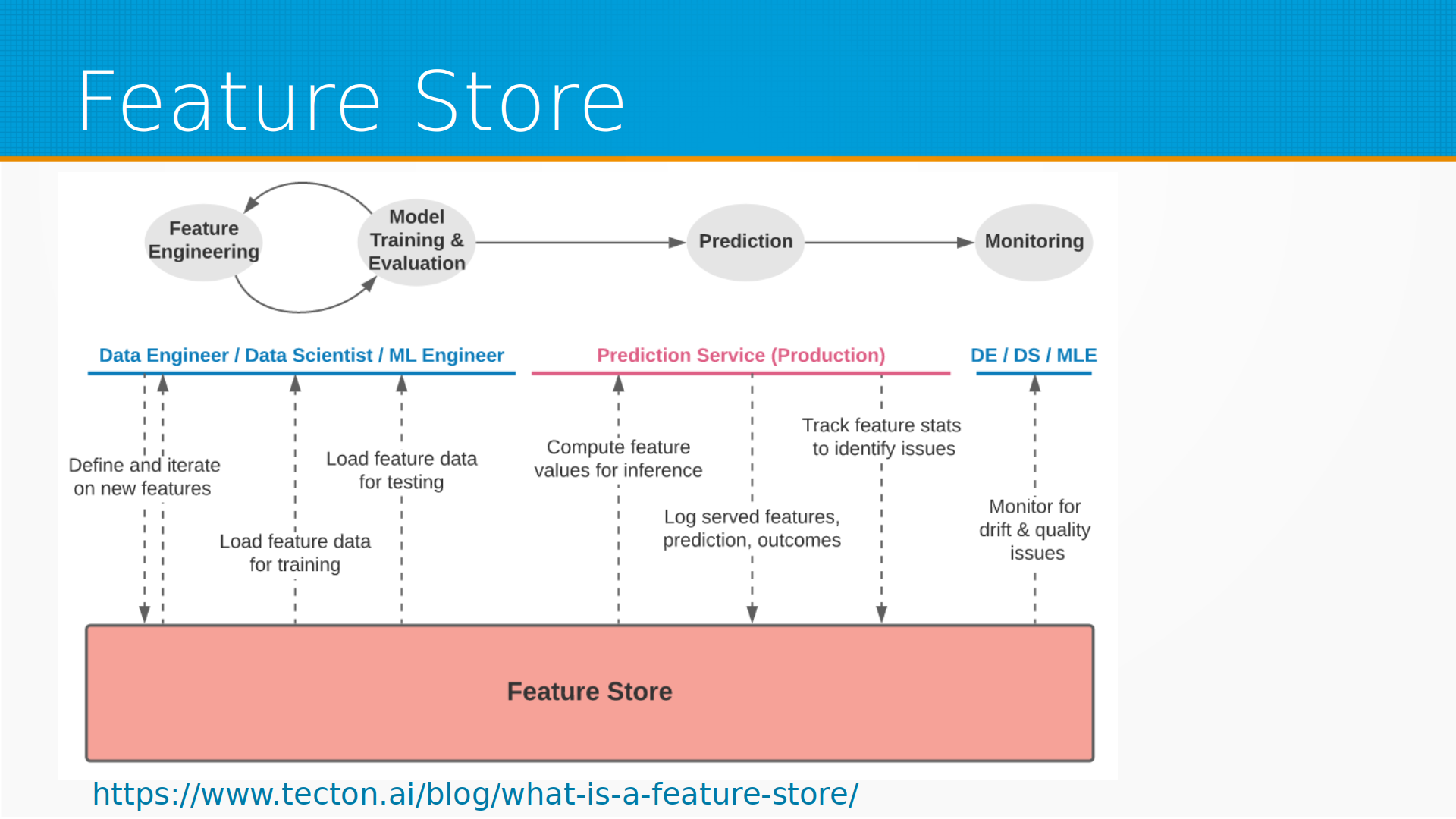
И фич-стор решает эту проблему на всем этапе жизненного цикла. Все задействованные в работе модели люди и сервисы работают с фич-стором. То есть в самом начале, на этапе-фич инжиниринг, дата-инженер вместе с дата-саентистом определяет, какие возможны признаки, потом дата-саентист смотрит, какие признаки доступны, работает с ними, потом ML-инженер выгружает эти признаки для тестирования, работы, готовит их. После этого prediction сервер берет сервисы оттуда, готовит готовые признаки на инференсе при поступлении новых данных, считает какие-то статистики по признакам, чтобы можно было мониторить качество данных. И дата-инженер смотрит в этом фич-сторе, анализирует, нет ли у нас каких-нибудь проблем со сдвигом данных или выбросами и так далее.
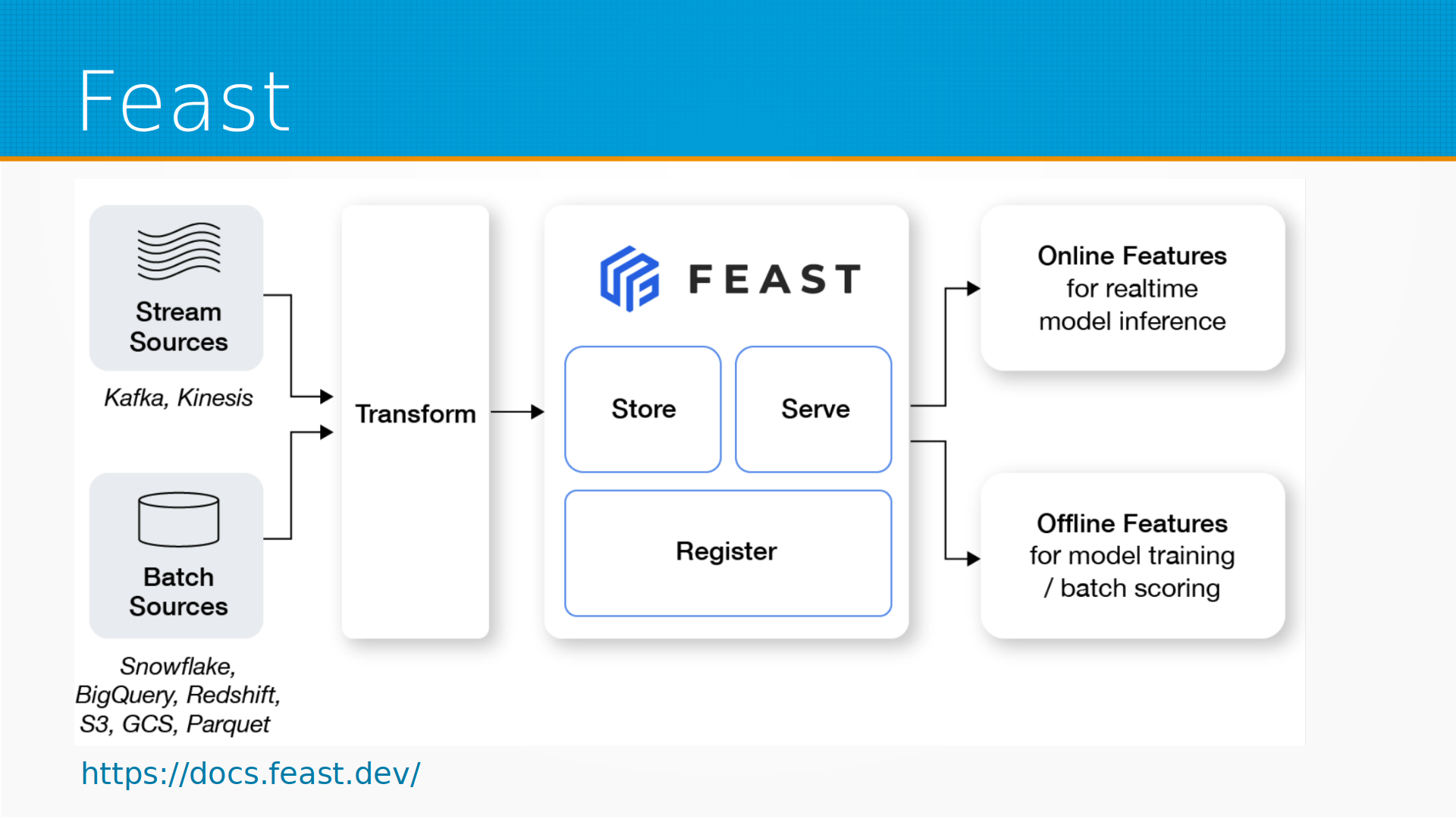
Самый, наверное, известный фич-стор – это Feast. Собственно, они, наверное, родоначальники этого термина. Они позволяют хранить описание признаков, хранить сами насчитанные признаки, а непосредственно расчетом данных, расчетом признаков Feast не занимается. Предполагается, что у вас есть какие-то источники данных, потоковые или по расписанию насчитанные, есть какая-то инфраструктура, которая выполняет подготовку данных, а Feast уже хранит насчитанные данные в каком-нибудь хранилище, с которым он умеет работать, и отдает их в систему инференса, и позволяет обеспечить доступ к данным для обучения моделей, для бэк-тестов и так далее и тому подобное, то есть онлайн и оффлайн фич-стор.
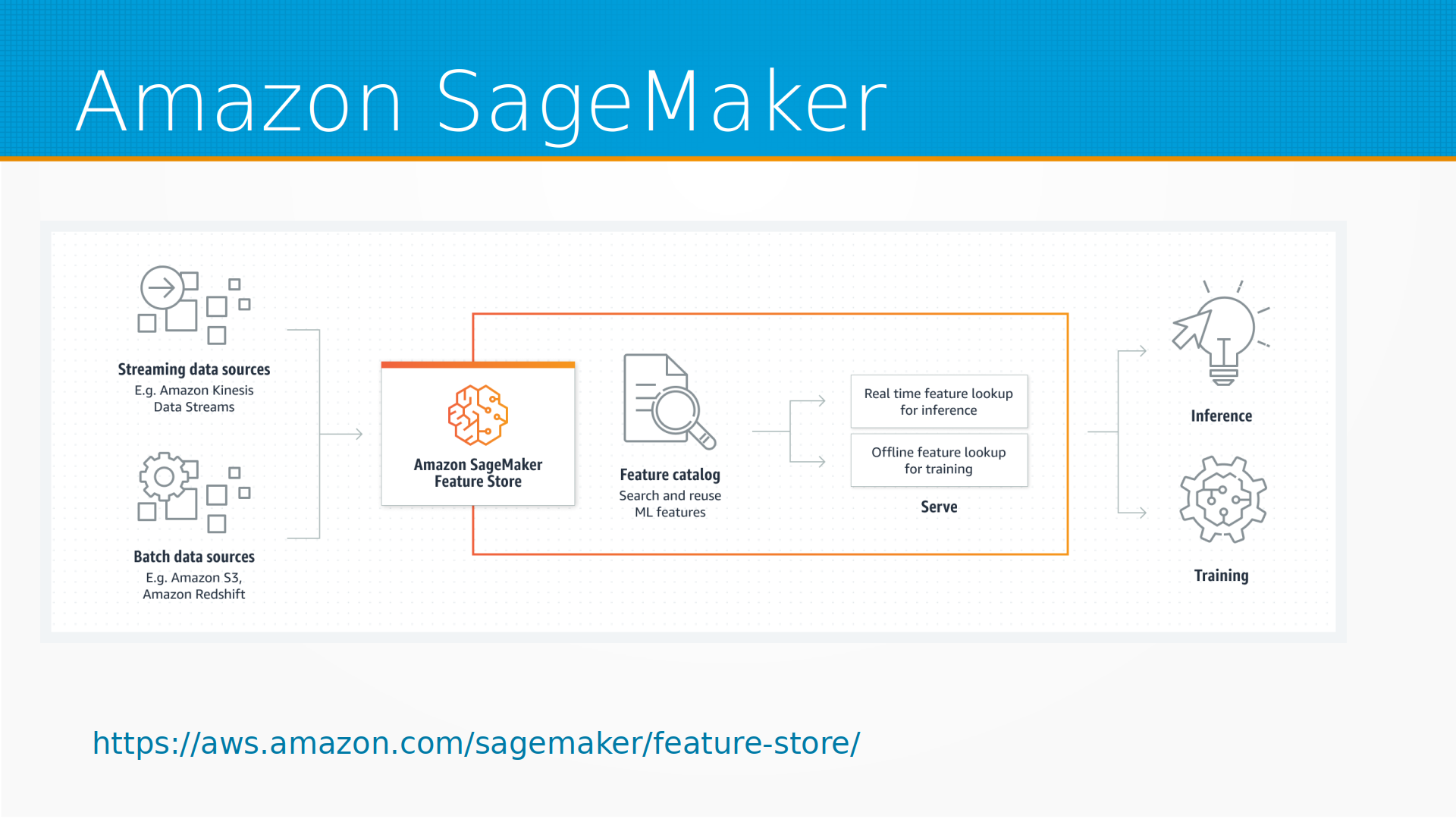
У Амазона есть, например, система SageMaker для построения моделей и их инференса, и в Амазоне есть свой фич-стор.

Такие же фич-сторы есть у Google в их Vertex AI и вообще у любого крупного поставщика вычислений. То есть есть в Databricks, есть в Tecton, есть в Hopsworks поверх Hadoop. И тут хорошо посмотреть на сайте featurestore.org, сравнить их по этой ссылке, какие у них есть особенности, и подобрать тот, который лучше укладывается в ваш набор инструментов.
Ну и последнее, о чем хотелось поговорить. Большинство организаций — это не Google, который разрабатывает свою инфраструктуру, и не какой-нибудь магазин овощей, потому что магазины овощей, на самом деле, еще пока мало ML-моделей внедряют. Большинство случаев — это такой вот сферический средний бизнес в вакууме, который можно обслуживать примерно шаблонно следующим образом.
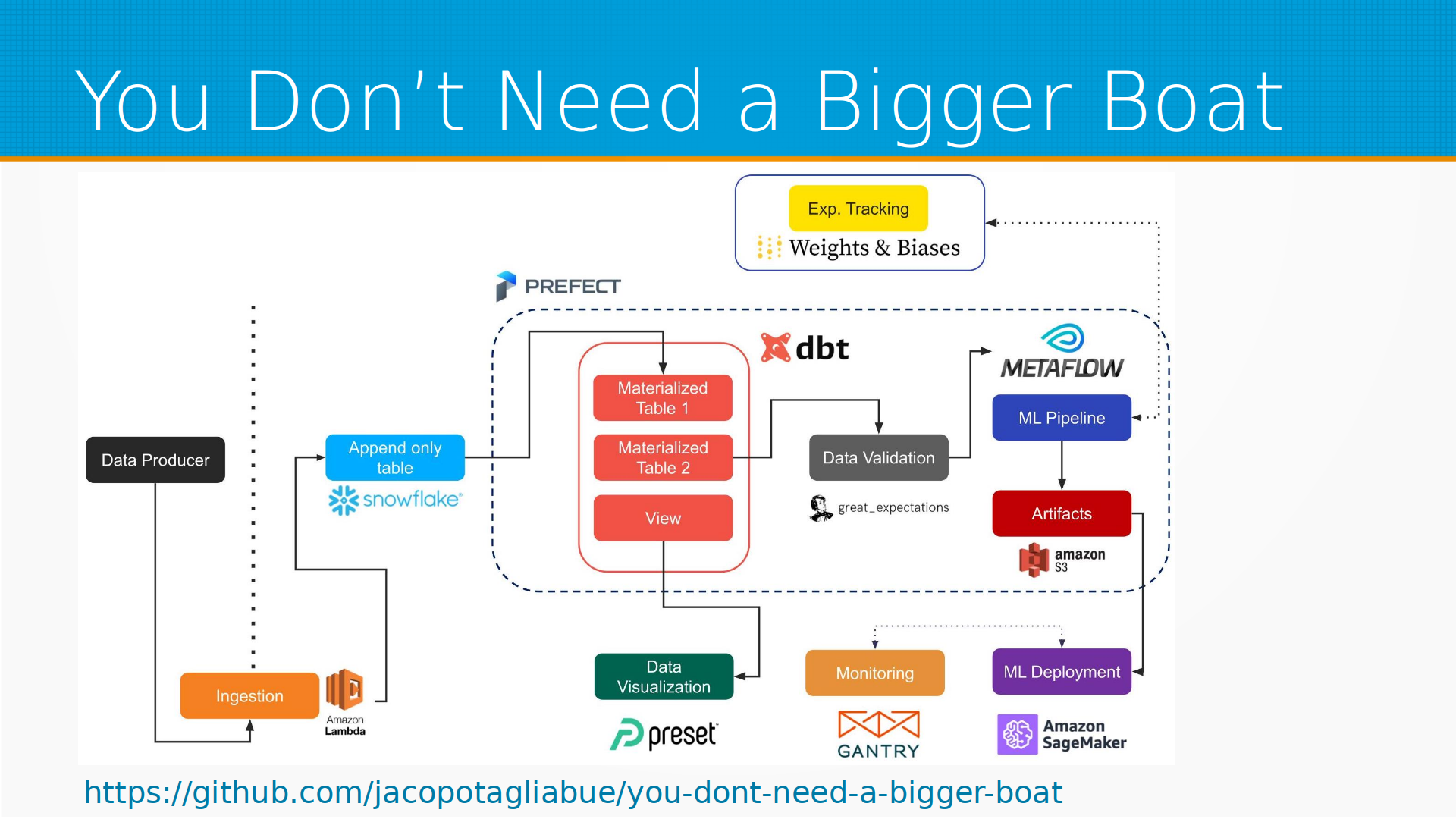
Есть хорошая статья и референсная архитектура, где мы обходимся без своих серверов и все serverless считаем. То есть есть некоторые источники данных, которые выдают нам данные в наш брокер данных, откуда мы в Amazon Lambda их обрабатываем, и складываем в Snowflake, это таблицы, в которых мы не обновляем данные, а только добавляем их, только дописываем в конец. Из этого с помощью, например, Prefect мы готовим некоторое материализованное представление, то есть таблицу с последними самыми свежими данными по каждому объекту. Они проходят какую-нибудь валидацию с помощью, например, GreatExpectations, преобразуются с помощью DBT, мы их визуализируем с помощью Preset. Дальше с помощью Metaflow, например, мы serverless обучаем модели, сохраняем артефакты в S3, деплоим в Amazon SageMaker, мониторим с помощью Gentry — я бы посоветовал Evidently AI, но в общем в этой статье используют Gentry. И все это не требует вам покупки серверов, все это вы можете сделать serverless.

Дополнительные материалы: