
- 05.12.2022
- 25.08.2024
- обучение
- #mlsystemdesign
Одиннадцатая лекция открытого курса "Дизайн систем машинного обучения", "Эксперименты и версионирование".
Слайды можно скачать тут mlsysd11ods.pdf
Текстовая расшифровка, пока не вычитана:

Добрый день. Меня зовут Дмитрий Колодезев и это 11 лекция курса дизайна систем машинного обучения — про эксперименты и версионирование.

Мы ранее обсуждали, как можно построить модель машинного обучения, как объединить эту модель с другими компонентами в систему, как мониторить эту систему. В процессе мы все время будем дообучать наши модели, то есть наш жизненный цикл предполагает, что наша модель будет все время меняться. Мы будем ставить много экспериментов, и моделей у нас тоже будет много. Как мы будем отслеживать наши эксперименты и версионировать наши модели — не только во время начальной разработки, но и в процессе всего жизненного цикла системы?

Во-первых, что можно отслеживать? Отслеживать можно данные — и не очень понятно, как это делать, как их версионировать.
Можно версионировать код предобработки данных — и тут все достаточно прозрачно, мы просто складываем его в git.
Можно версионировать код обучения моделей, ему то же самое место в git. Как версионировать веса модели — это отдельный вопрос. Наверное, самый простой способ — это копировать и складывать их куда-нибудь в S3.
Как отслеживать метрики модели? Мы обсуждали ранее системы для отслеживания экспериментов.
Как отслеживать предсказания модели? Это непростой вопрос, потому что обычно предсказания модели на начальных этапах разработки системы не сохраняют. Между тем предсказания, которые сделала модель, то есть вероятности, которые она выдала по тем или иным входным данным, это такие же ценные данные, как и разметка. Вы, пользуясь ей, сможете улучшить качество модели, построить более качественные модели. То есть, ее тоже хорошо бы сохранять для анализа, для дообучения модели, для разбора полетов.
Когда модель учится, она производит некоторое количество журналов обучения. И во время работы системы тоже есть куча логов, как-то их надо хранить, и отслеживать, что именно вот этот эксперимент породил вот эти логи, эти журналы.

Самое сложное тут, на самом деле — это версионирование данных. Сами по себе модели машинного обучения имеют смысл только в контексте данных, то есть в отрыве от данных модели машинного обучения бесполезны. При этом данных обычно сильно больше, чем кода, то есть, например, проект с миллионом строк кода — это достаточно большой проект. А база данных с миллионом записей — в общем, такая небольшая база. И мы не можем версионировать данные так же, как мы это делаем с кодом. Как мы версионируем код? Для кода, например, в git, мы сохраняем изменения между версиями, то есть, например, мы создали пустой файл, у нас сохранился образ "пустой файл". Затем мы написали в нем hello world — и у нас сохранилась не копия файла hello world, а разница, то есть какие символы изменились между этими версиями. И так по одной мы складываем наши изменения, дельты, и храним их — так, например, делает git.
С данными мы вроде бы как не можем так делать. То есть, предположим, что у нас система генерирует каждый день хотя бы 10 гигабайт данных. Это вообще-то немного. И получается, что каждый раз, когда мы меняем данные, то есть мы меняем, допустим, может быть, миллион раз в день, мы должны сохранять этот diff, или мы должны сохранять его раз в несколько дней, или мы должны сохранять его раз в несколько часов. То есть как бы не очень понятна сама по себе идея диффов в данном контексте. Трудно делать дифф и трудно читать эти диффы между данными. То есть, например, у нас есть две базы данных, которые разошлись когда-то по данным. Как мы их сравним?
Во многих базах данных есть какие-нибудь инструменты, которые считают чексуммы по строкам, по столбцам, и говорят — ну, вот эта строка изменилась, или вот этот столбец изменился. Но это обычно очень тяжелая процедура, которую запускают только когда что-нибудь сломалось, произошла репликация. В общем, диффы эти можно выявлять, но просто смотреть их глазом тоже трудно. Нет инструментов.
И все изменения датасета хранить тоже трудно. Если он большой, если он, не дай бог, петабайтный, то вы физически не сможете его хранить. Ну и датасет может не помещаться на локальной машине. Соответственно, если вам нужно подкачать данные для эксперимента и сохранить копию, как это, допустим, предполагает делать DVC, вы можете столкнуться с тем, что вы просто на самом первом этапе сломались, то есть вы только решили подкачать себе данные, а у вас уже кончилось место на диске.
Как пишет в своей книге Chip Nguyen, сейчас версионирование данных — это что-то вроде флоссинга зубов: все согласны, что это хорошо, но никто этим не занимается.
Версионирование — это отслеживание того, как какой-то объект менялся во времени для того, чтобы можно было вытащить более раннюю версию или более позднюю. То есть отслеживание изменения.

Что такое изменение в данных? Ну, во-первых, изменение в данных — это изменение схемы, то есть метаинформации модели. Например, мы добавили столбец, или удалили столбец, или сменили тип столбца, то есть где-то у нас была строка, а теперь это число или наоборот. Соответственно, изменение схемы данных обычно ломает модель, и хорошо, если оно ломает ее с грохотом, то есть мы заметим. Оно может сломать модель незаметно — то есть она просто перестанет работать. Отслеживать и проверять схему данных очень важно и для этого есть инструменты, мы их тоже обсуждали. Хорошие инструменты, например, Great Expectations, Pydantic и так далее и тому подобное.
И обычно хранят версии схемы данных, то есть, например, есть какой-нибудь инструмент, который каждый раз, когда схема данных меняется, сохраняет скрипт, который, например, генерирует структуру базы данных, и этот скрипт лежит в системе контроля версий. Это удобно, потому что вы можете посмотреть, как во времени менялась схема, то есть это надо делать обязательно. Но, во-первых, это полагается на внешние инструменты, которые вы должны запустить, сгенерировать эту схему и сложить в гит, то есть она сама туда не попадет. А во-вторых, несмотря на то, что мы как бы отслеживаем схему данных, еще меняются сами данные. И нужна ли нам версионность на самих данных? Как мы ее можем обеспечить?
Например, самый простой способ обеспечить версионность на самих данных — это делать копию данных при каждом обучении модели, типа вот мы учили модель на вот этих конкретно данных. Если у нас данных много, это невозможно. Затем мы можем версионировать код извлечения данных. Например, мы брали данные вот этим скриптом и каждый раз, когда у нас код извлечения данных меняется, мы складываем в гит его новую версию. Если наши данные статичные, то это решает проблему, но если наши данные лежат в живой продуктовой базе данных, куда они все время поступают, то с помощью той же самой версии кода извлечения данных мы можем получать каждый раз разные данные. Ну и мы можем попробовать обеспечить версионирование данных на уровне самой модели данных.

С изменениями данных тут есть еще несколько проблем — как мы будем проверять, что данные изменились? Например, если мы данные храним на диске, мы можем считать контрольную сумму для каждого файла или для каждой папки. Помимо того, что файл может измениться без изменения контрольной суммы, это коллизии, они редко, но случаются, у нас еще есть данные, которые лежат в базах данных — и как там считать контрольную сумму? Иногда у нас файлы лежат на удаленных серверах, каких-нибудь объектных хранилищах. Как там считать контрольную сумму? То есть это просто физически очень тяжело будет. Возможно ли сливать изменения в данных? То есть, например, один источник изменил данные одним образом, другой другим. Можем ли мы их слить так, как мы сливаем изменения в репозитории git?
Ну и очень часто, когда говорят о версионировании данных, забывают, что вообще-то хранить данные в репозиториях не всегда можно. То есть, например, общепринято, что токены с паролями хранить в системе контроля версий плохо, но ведь наши данные, с которыми мы работаем, это зачастую те же самые токены и пароли, это личные персональные данные пользователей, которые мы должны хранить осторожно просто по закону. Мы не имеем права складывать их куда попало, мы должны следить, где они есть, мы должны утилизовать их определенным образом. То есть иногда версионирование данных просто незаконно. И данных много, то есть версий кода намного-намного меньше, чем версий данных.

В принципе, мы можем организовать хранение данных так, чтобы сохранялась история изменения данных. Наиболее очевидный подход – это моделирование данных с помощью так называемого подхода Event Sourcing. Event Sourcing – это когда мы храним не наши данные, а храним все операции, которые их изменили. То есть предположим, что у нас завелся новый покупатель в интернет-магазине. В классической схеме мы бы записали в таблицу покупателей покупателя, а потом, когда покупатель изменил бы данные, мы бы изменили данные в таблице покупателей, например, его адрес доставки или номер телефона и так далее. Таким образом, у нас в данных всегда лежит последняя актуальная версия, а предыдущие версии потеряны.
Мы можем вместо этого сохранять историю изменений, то есть, например — поле "имя покупателя" изменено на вот такое, дальше, допустим, timestamp и, например, номер версии. То есть мы храним, какое поле изменили, на какое значение и какой-нибудь либо порядковый номер изменения, либо, что еще проще, timestamp. Тогда, если нам нужно получить свежую версию данных, мы просто применяем с нуля все изменения и смотрим, что у нас получилось. А если нам нужно восстановить старую версию данных, то мы применяем все изменения до определенного timestamp. Например, мы берем все изменения до 1 января, которые были, и смотрим, какой у нас был пользователь на 1 января.
Это очень хороший подход, но у него есть несколько проблем. Самое очевидное – это медленная выборка данных. То есть для того, чтобы получить последнюю версию данных, нам нужно совершить много операций, накатить всю историю изменений пользователя. Эту проблему обычно обходят, сохраняя отдельно последнюю версию данных, которую всегда можно перегенерировать из истории ивентов. Или иногда, как это делают, например, бухгалтерия или банки, мы закрываем операционный период, то есть налоговый период. То есть мы подсчитываем все, что у нас произошло, и говорим — ага, ну вот у нас есть такой ключевой кадр, как в видео, groundtruth. То есть можно отсчитывать версии не с самого начала, а с вот этого ключевого кадра данных.
В принципе, бухгалтерия вся на этом построена. То есть если кто-то немножко сталкивался, в бухгалтерии хранится не конкретное состояние денег на счетах и так далее и тому подобное, а так называемые проводки, то есть каждое изменение данных. И мы берем начальное состояние, допустим, на 1 января, и накатываем все эти проводки, проводим проводки, чтобы получить текущую историю. И поэтому, когда бухгалтер что-нибудь меняет задним числом, он все это дело проводит и ждет, пока система пересчитается. Вот в принципе это пример Event Sourcing моделирования.
Эта система отлично работает, когда данные меняются не очень часто, то есть не каждую секунду, например, и когда у нас данные могут меняться в разных местах, то есть для Event Sourcing проблемы репликации как таковой нет.
Обычно, если у нас данные, допустим, пишутся в несколько баз данных, нам надо как-то их сливать. У нас могут быть проблемы, если одновременно одну и ту же самую запись исправили в нескольких местах. Допустим, я взял запись о клиенте и исправил его адрес, вы одновременно со мной взяли запись о клиенте и исправили его телефон. И произошла ошибка, то есть либо я переписал старую версию телефона вместе со своим адресом, либо вы переписали старую версию адреса вместе с новым телефоном. В случае Event Sourcing нам не нужно координировать действия — я изменил адрес, вы изменили телефон, и тот, кому понадобятся свежие данные о пользователе, просто по timestamp накатит изменения до нужного момента. Из отрицательных примеров — это довольно медленный способ работы с данными.
Следующее — это Anchor Modeling. Это достаточно сложно описать в двух словах, там по статье есть разбор. Такой тривиальный пример — предположим, что у нас есть большая-большая таблица с данными. Например, скажем, 10 терабайт она занимает. И в ней есть поля о пользователе — имя, фамилия, отчество, адрес, телефон. И мы хотим сохранить в эту таблицу данных еще и ИНН. То есть, если у нас все это, не дай бог, лежит в обычной реляционной базе данных, мы такие говорим — ALTER TABLE, добавляем столбец в базу данных и ждем, например, день, пока таблица применит эти изменения. То есть, это совершенно реальные сроки и истории. То есть, база данных должна остановить запись в таблицу, добавить столбец, залив его значение по умолчанию, потом восстановить и так далее. Таблицы типа базы данных, колоночной базы данных, с этим работают лучше, быстрее. Но, допустим, в clickhouse вы фактически создаете таблицу заново, когда вы ее меняете. Ну и, кстати, в каких-нибудь MySQL вы тоже его создаете заново, это медленная операция.
Предположим, что нам нужно построить систему хранения данных, в которых у нас будет меняться схема сложносочиненным образом, и мы не знаем, каким. И мы говорим — хорошо, вот у нас есть некоторая сущность, у сущности есть ID, у каждого пользователя есть ID. И у пользователя есть атрибуты, например, есть адрес, есть телефон, есть адрес доставки. И мы каждый из этих атрибутов храним в отдельной таблице. И у нас получается много-много-много таблиц. Это кажется достаточно странным, ну и не все базы данных позволят нам сделать много таблиц в базе данных. И дальше мы связками один к одному и один ко многим все эти наши данные собираем. Что это нам даст? Если нам нужно будет добавить еще один столбец, мы просто добавим еще одну таблицу и начнем писать туда данные, вот для этого конкретного столбца. А остальные таблицы вполне могут в это время работать, то есть это даст нам гибкость при изменении данных.
И есть подход Slowly Changing Dimensions, как раз по ссылке разбирается ситуация, как жить с данными, которые меняются во времени. От простейшего варианта, когда вы сохраняете только последнюю копию данных, до варианта, когда вы сохраняете всю историю. Где-то посередине между этими вариантами, между шестью, допустим, типами Slowly Changing Dimensions, есть тот вариант, который подойдет вам.
Если кратко, нужно версионировать код извлечения данных, и о том, как хранить историю изменения данных, нужно думать заранее на этапе проектирования базы данных. По ссылке хорошая статья на Хабре в блоге Авито, как они моделировали хранение данных в вертике.
Если данные у вас лежат в объектном хранилище, скажем, в S3, и потом вы ходите по нему, например, с помощью Spark, то непонятно, как их версионировать. То есть, вот у нас лежит объект — грубо говоря, кусок файла размером, например, 64 мегабайта, и вот вы его меняете. Объектное хранилище создаст, например, копию этого объекта, и у вас будет новая версия файла. Хотелось бы, например, иметь возможность переключаться между версиями. Некоторые объектные хранилища это позволяют, например, тот же самый Amazon S3 позволяет для bucket S3 задать версионирование. Google в своем объектном хранилище позволяет задать версионирование, но глубина, то есть количество версий, которые там будут храниться, у вас ограничены. Ну, и естественным образом, такие операции, как слить изменения из разных версий и так далее, вам недоступны.
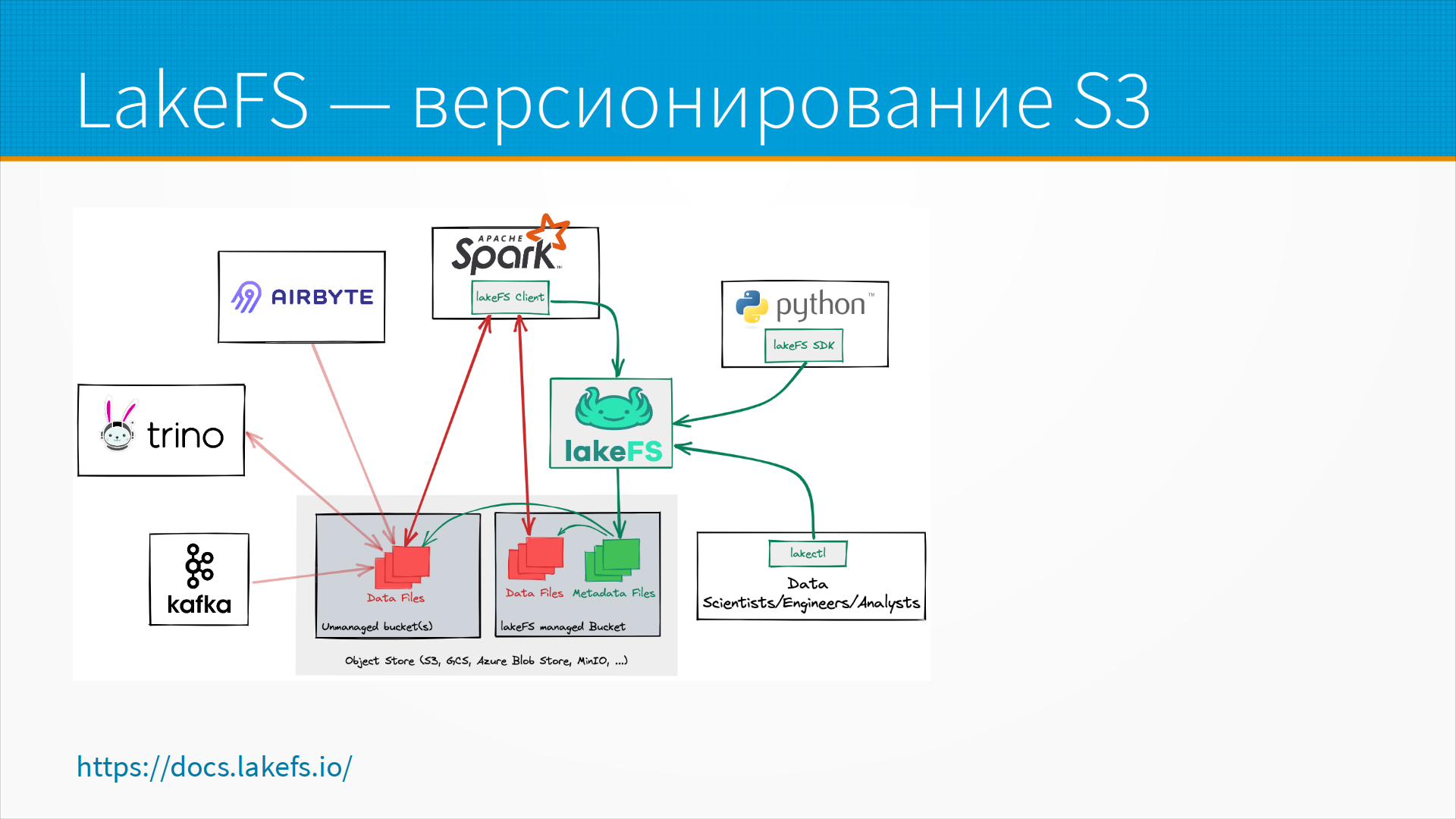
Есть инструмент LakeFS, который специально предназначен для версионирования объектных хранилищ, то есть S3 и так далее и тому подобное. Вы можете делать в нем операции, очень похожие на те, которые вы делаете в git.
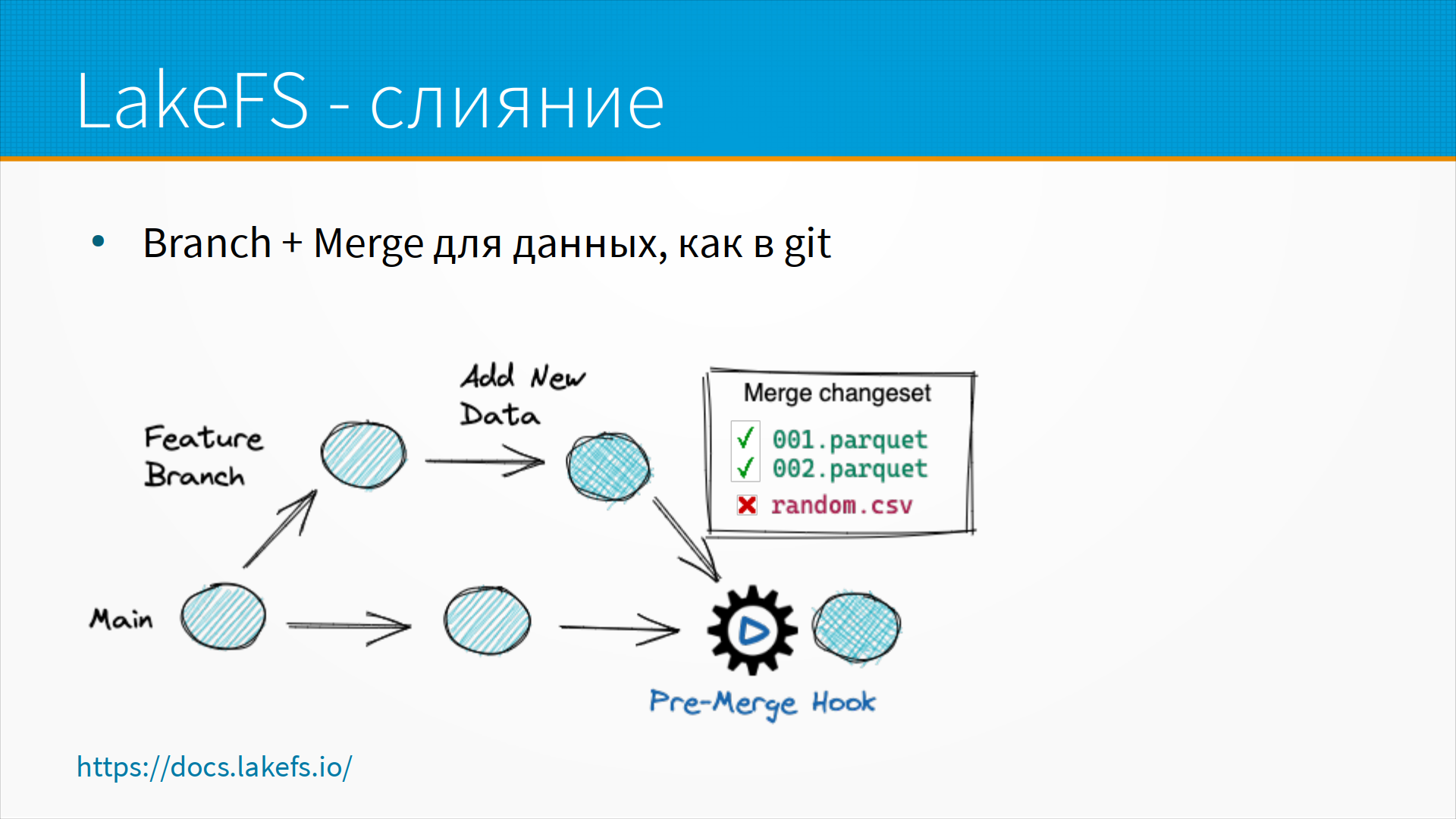
Например, вы можете сделать ветвление данных, то есть branch создать, вы можете поменять какие-то данные, вы можете сделать merge, добавив какие-то новые данные, и у вас он может получиться или не получиться. То есть, для промышленных объемов данных, хранящихся в S3, наверное, LakeFS — это единственное, что более-менее похоже на версионирование. Я, во всяком случае, не знаю про другие.

Про отслеживание данных поговорили, теперь про отслеживание экспериментов. Про отслеживание экспериментов мы говорили раньше в предыдущих лекциях, но, в любом случае, что следует хранить? Следует хранить кривую потерь, то есть график того, как падал ваш loss. Хранить метрики качества модели, какие-то ссылки на данные, на которых модель обучалась, скорость работы модели, то есть сколько, допустим, точек данных в секунду вам удалось обработать, какие-нибудь метрики системы, то есть потребляемая память, утилизация ЦПУ, ГПУ и так далее. И, конечно, значения параметров и гиперпараметров модели.
В этом придуманы много интересных инструментов под разные инфраструктурные системы. Мы в свое время много использовали Netflix-овский Metaflow. Он, например, каждый раз, когда запускает обучение, в бакете в S3 создает папочки, в которых складывает копии данных, складывает модели, складывает отчеты о работе, складывает значение гиперпараметров в JSON, и потом вы можете по этому строить отчеты или откатываться к какой-нибудь версии модели. То есть по-своему удобно, но жестко завязано на стек AWS, Amazon, поэтому мы от него отказались. Но это очень хорошая система.

С версионированием моделей. Когда вы пишете код и, допустим, что-нибудь сделали, какое-нибудь изменение, которое его сломало, вы с помощью системы контроля версии можете посмотреть, что конкретно вы поменяли, вернуть его в прошлое работоспособное состояние, при этом еще и выбрав, в какое состояние вы его вернули. А можете ли вы сделать то же самое с моделью машинного обучения? То есть, например, вы доучили нейронную сеть и сказали — нет, как-то она училась плохо, давайте мы откатимся, отменим часть изменений.
В некотором смысле мы можем это сделать, потому что наша нейронная сеть может при обучении сохранять чекпоинты, то есть свои промежуточные значения, и мы можем вернуться к какому-то из чекпоинтов и продолжить работу из этого места. Но для этого нам надо будет хранить не только итоговые веса модели, но и все чекпоинты. Обычно, когда моделей учится много, мы отслеживаем только сам код обучения модели, стараясь сделать его воспроизводимым, то есть устанавливаем везде, где можно random seed и так далее и тому подобное. То есть само по себе версионирование моделей гораздо более упрощенное сравнительно с версионированием кода.
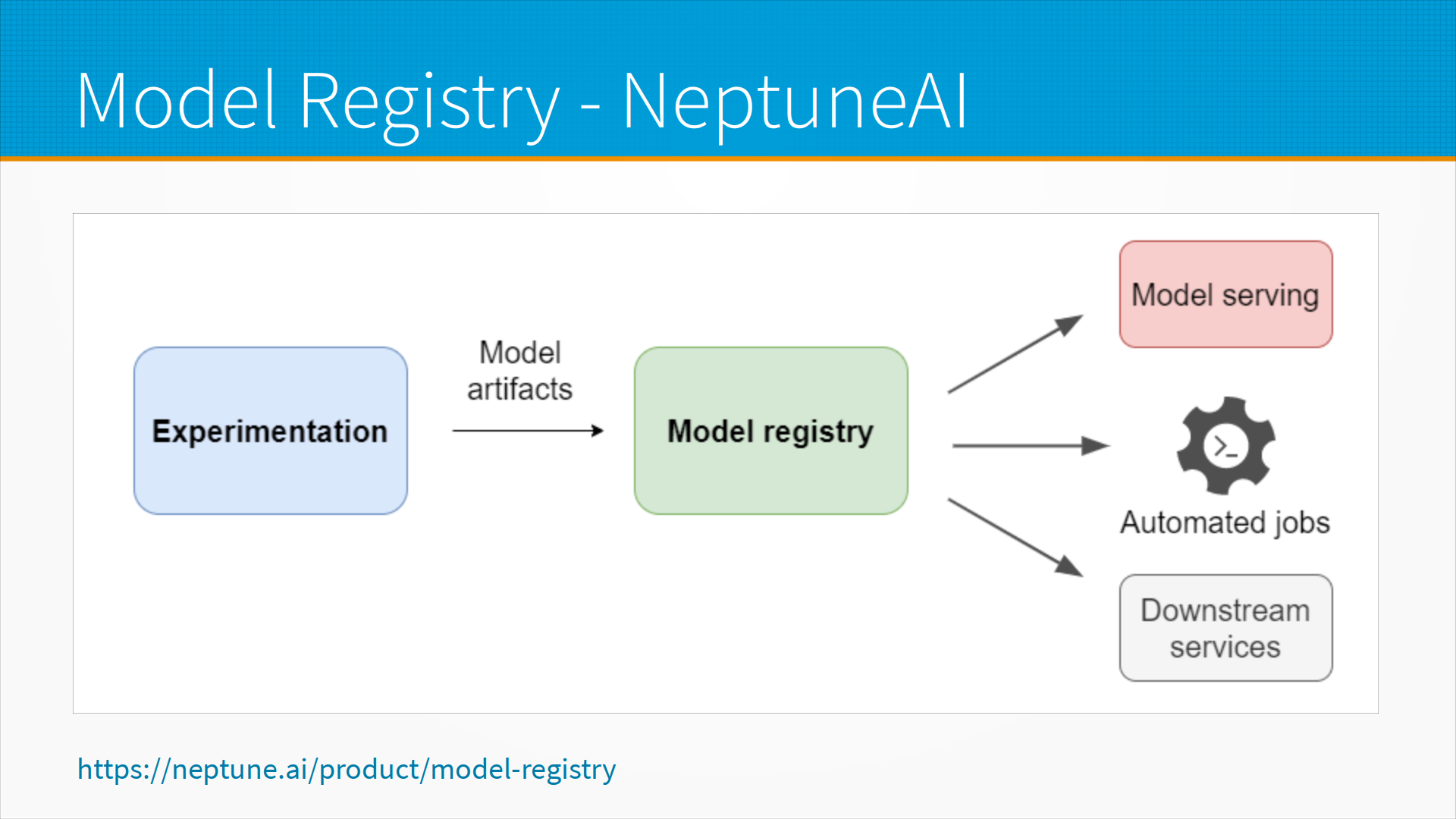
Для хранения моделей обычно используют Model Registry в системах отслеживания экспериментов и моделей. Например, в NeptuneAI у нас любые эксперименты порождают некоторые артефакты моделей, которые сохраняются в Model Registry, откуда модель берется, допустим, для того, чтобы сервить, то есть развёртывать ее и отвечать на запросы. Для каких-нибудь автоматических запусков — например, у вас автоматически раз в сутки должен запускаться какой-нибудь процесс, который насчитывает признаки для всех ваших клиентов, automated jobs — вы можете использовать вашу модель как часть других систем, downstream services, и все они могут опираться на одно и то же хранилище моделей Model Registry.
Когда модель публикуется в Model Registry, вместе с ней вы сохраняете какие-то атрибуты модели, а также сохраняется, кто учил, когда учил, и вы можете в каком-то виде смотреть историю изменения модели и то, как менялись её параметры. Самый лучший общепризнанный инструмент для отслеживания экспериментов, Weights & Biases, в данный момент не содержит Model Registry в себе, но они обещают, говорят — мы вот-вот сделаем, запишитесь в waitlist.
В DVC, это система для отслеживания экспериментов, похожая идеологически на git, мы можем использовать внешние Model Registry, и в качестве Model Registry мы можем использовать, например, git.
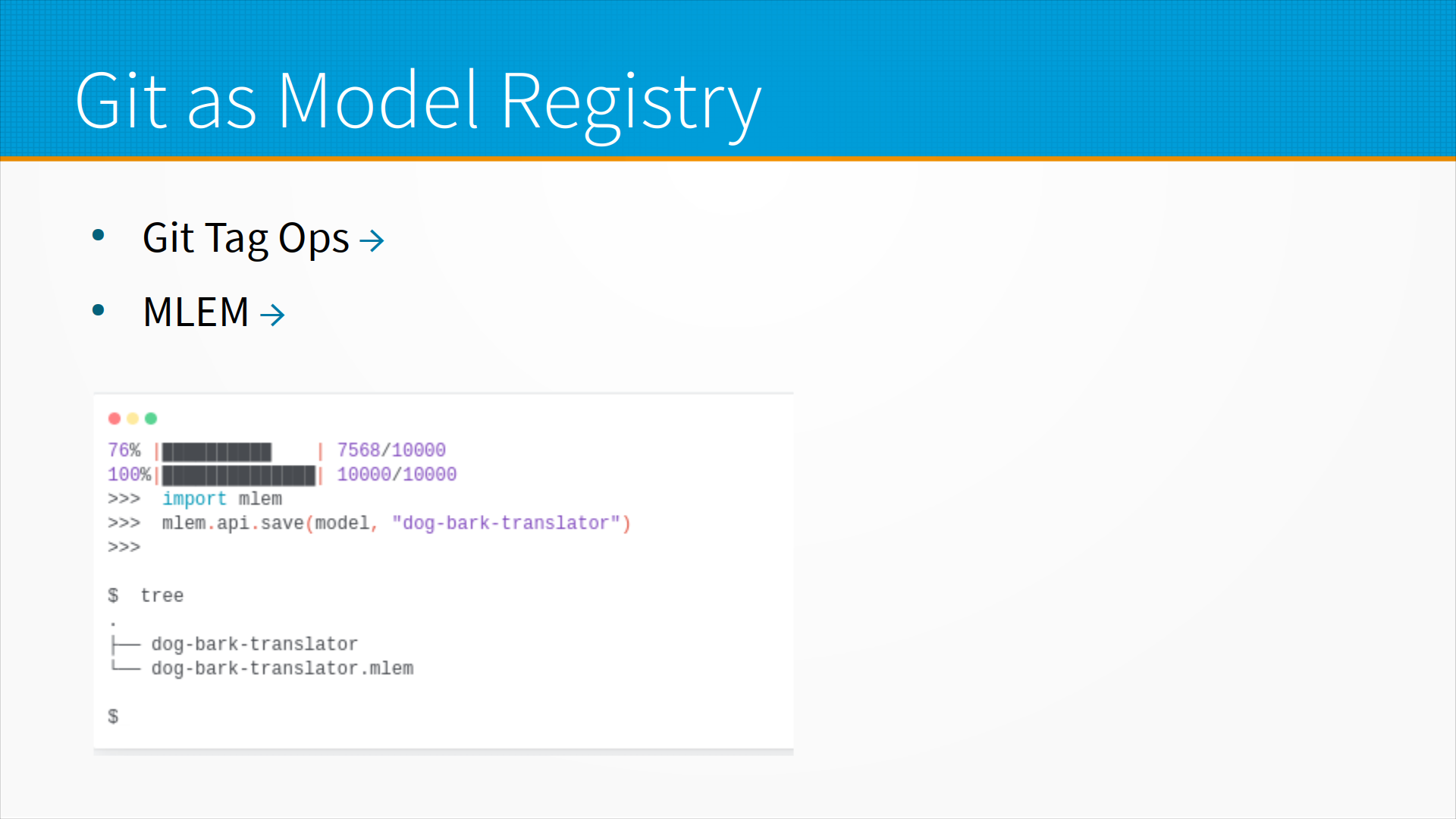
То есть, есть некоторые плагины DVC, которые позволяют использовать Git Tag Ops или MLEM. При этом мы сохраняем нашу модель в git примерно тем же способом, как вот Metaflow, о котором я рассказывал, от Netflix, сохраняет в S3, то есть там у вас в репозитории создается специальная структура, и плагин туда эту модель сохраняет. По-своему удобно, но при условии, что у вас все помещается в ваш git.
Наиболее популярный среди открытых инструментов — это MLflow. В MLflow вы поднимаете свой сервер, либо вы можете запускать прямо у себя на компьютере какую-нибудь панель MLflow для просмотра. И, допустим, у Microsoft есть хорошее руководство по тому, как разворачивать Model Registry MLflow в облаке для того, чтобы брать оттуда модели и разворачивать прямо оттуда. У самого MLflow есть документация на то, как использовать его Model Registry.
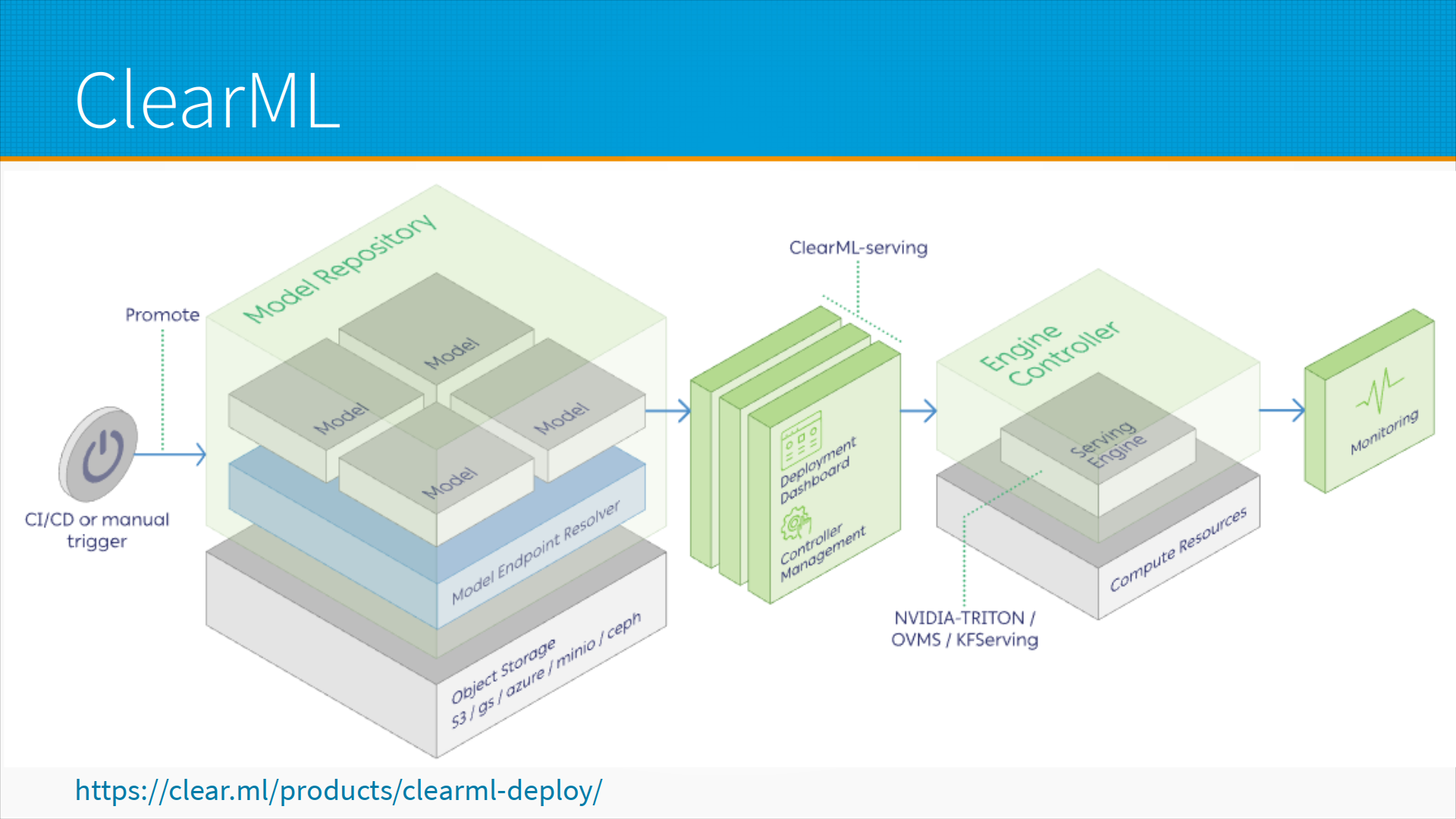
В ClearML, который, как я узнал от своих студентов, очень популярен в Китае, а значит, будет популярен и у нас, есть отдельный Model Repository, который хранит в объектном хранилище, то есть также как Metaflow в S3, в Google Object Storage и так далее и тому подобное, хранит сами модели, хранит мета-информацию о них, веса, и система развертывания моделей позволяет вам указать, какую конкретно версию моделей взять из репозитория. Поскольку они хранятся вместе с мета-информацией, там есть все, что нужно для того, чтобы развернуть, запустить и обслуживать запросы.

Что мы имеем в итоге? В принципе, агрессивное отслеживание экспериментов и версионирование очень помогают с воспроизводимостью обучения и позволяют возвращаться к прошлым версиям данных, моделей, обдумывать решения, которые вы тогда принимали, может быть, идти каким-то другим путем, то есть вернуться, исправить и пойти по-другому. Но на самом-то деле, как бы вы агрессивно не отслеживали ваши эксперименты, версионирование вам воспроизводимость не гарантирует. То есть вы используете много библиотек, у вас может быть совершенно воспроизводимый ваш собственный код, но у используемых вами библиотек могут быть проблемы с детерминизмом. То есть, например, несколько запусков одной и той же библиотеки даст разные результаты.
Кроме того, оборудование может вносить недетерминизм в модели. Если вы используете ГПУ, например, то у вас технологически не всегда возможен детерминизм.
Потом данные, на которые вы опираетесь, могут невоспроизводимо меняться. Если вы храните только код извлечения данных, вы можете обнаружить, что тот же самый код извлечения данных возвращает вам разные данные при каждом запуске и, соответственно, у вас получаются разные модели.
И разные модели графических ускорителей в одном и том же Pytorch могут учиться по-разному. То есть, если вы, например, учитесь в Collab, вам выдают тот или иной тип графических ускорителей в зависимости от того, повезло вам или нет. И, соответственно, ваша модель может выдавать разные результаты.
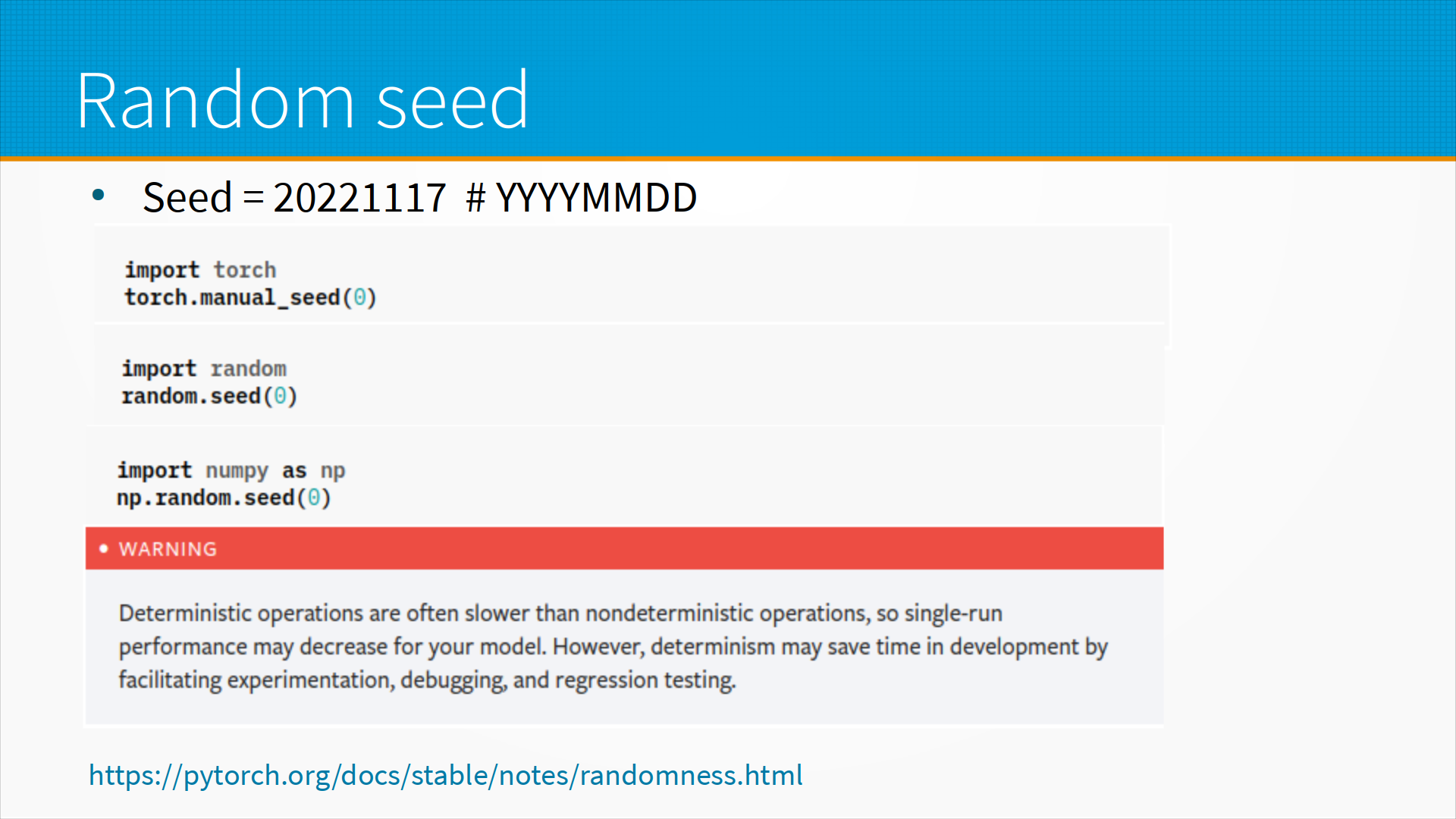
Везде, где можно, следует задавать так называемый random seed. Это стартовое значение генератора случайных чисел — некоторые параметры, которые генератор псевдослучайных чисел использует для генерации последовательности.
Очень часто в качестве seed задают 0 или 42. Это, конечно, интересно, но я придерживаюсь следующего подхода. В качестве сида я всегда задаю восьмизначное целое число, состоящее из четырех цифр года, двух цифр месяца и двух цифр дня. Это защищает меня от так называемого подбора сида, когда мы перебираем разные сиды и надеемся, что вот может быть этот сид окажется более удачным, этот неудачным. Я точно знаю, какой seed я сегодня выберу, это решено за меня, поэтому у меня нет пространства для маневра, это улучшает воспроизводимость.
В Pytorch мы можем указывать seed, в python мы можем указывать seed, в numpy мы можем указывать seed, и, кстати, это разные сиды, то есть их надо указывать все. В Pytorch Lightning, которым мы последнее время пользуемся, есть такой метод — установить все сиды. Он хороший, удобный, но все равно вам придется устанавливать сиды, когда вы будете разбивать на обучающую и тестовую выборки, и так далее. Хорошо взять один seed, где-нибудь в начале вашего Jupyter ноутбука зафиксировать, и затем во все места, где требуется random state, где требуется seed, вставлять его и надеяться, что библиотеки будут воспроизводимо работать.

В некоторых библиотеках, например, в Pytorch, детерминированные операции, то есть операции, которые дают воспроизводимый результат, медленнее, чем недетерминированные. И получается, что вы будете учить модель гораздо медленнее с детерминированными операциями. Детерминизм сохраняет нам в целом время в проекте, когда мы анализируем наши ошибки, но в моменте модели могут учиться медленнее. Кроме того, как я уже говорил, воспроизводимость не всегда возможна. Часто это просто ошибки в библиотеках. Иногда это особенности их. Если вы просто погуглите по какому-нибудь типа "Pytorch no determinism", сюда можно подставить ваш любимый фреймворк — TensorFlow или все что угодно, MXNet, то вы найдете кучу проблем с детерминизмом в вашей библиотеке. У Pytorch есть issues на GitHub, где можно посмотреть, какие проблемы и какие требования к вашему коду предъявляются для детерминированных расчетов, то есть расчетов, которые каждый раз возвращают один и тот же самый результат.

Попробуйте системы отслеживания экспериментов. Пройдите Quick Start для каждой платформы: