
- 27.11.2022
- 25.08.2024
- обучение
- #mlsystemdesign
Десятая лекция открытого курса "Дизайн систем машинного обучения", "Жизненный цикл модели".
Слайды можно скачать тут mlsysd10ods.pdf
Текстовая расшифровка:

Добрый день. Меня зовут Дмитрий Колодезев, и это десятая лекция нашего курса про дизайн систем машинного обучения.
В этой лекции мы будем разбирать жизненный цикл моделей.

В нашей стране существует ГОСТ, принятый в 2016 году, который определяет, что такое жизненный цикл. Жизненный цикл — это развитие системы, продукции, услуги проекта от замысла до списания. Грубо говоря, для дома, например, жизненный цикл — это от решения его построить через чертежи, выделение площадки и до момента сноса и рекультивации под новое использование.
А модель жизненного цикла — это как раз структура, которая описывает эти процессы, которые происходят в течение жизненного цикла объекта. И у системы машинного обучения тоже есть свой жизненный цикл и есть какая-то структура.
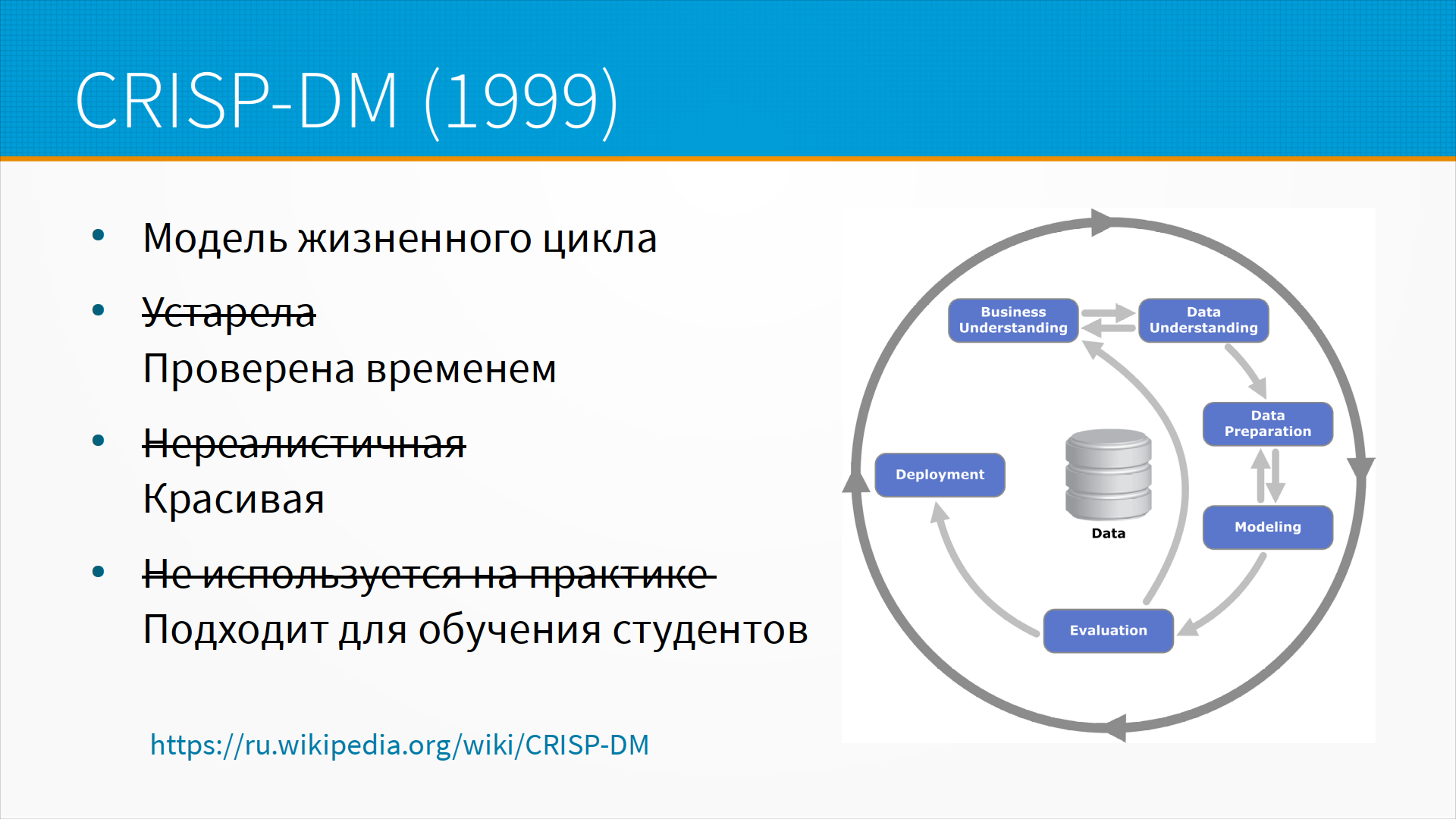
Традиционно, когда говорят про модель жизненного цикла машинного обучения, вспоминают CRISP-DM. Это модель, которая описывает процессы анализа данных — от понимания бизнеса, для чего мы этот проект делаем, через понимание данных, подготовку, моделирование, оценку, и возвращаемся снова к пониманию новых проблем бизнеса. В ней все хорошо — единственное, что она на самом деле не используется сейчас. Она 23 года назад опубликована и попала во многие стандарты. Отлично подходит для обучения студентов, но на самом-то деле пользуются совсем-совсем другими моделями.
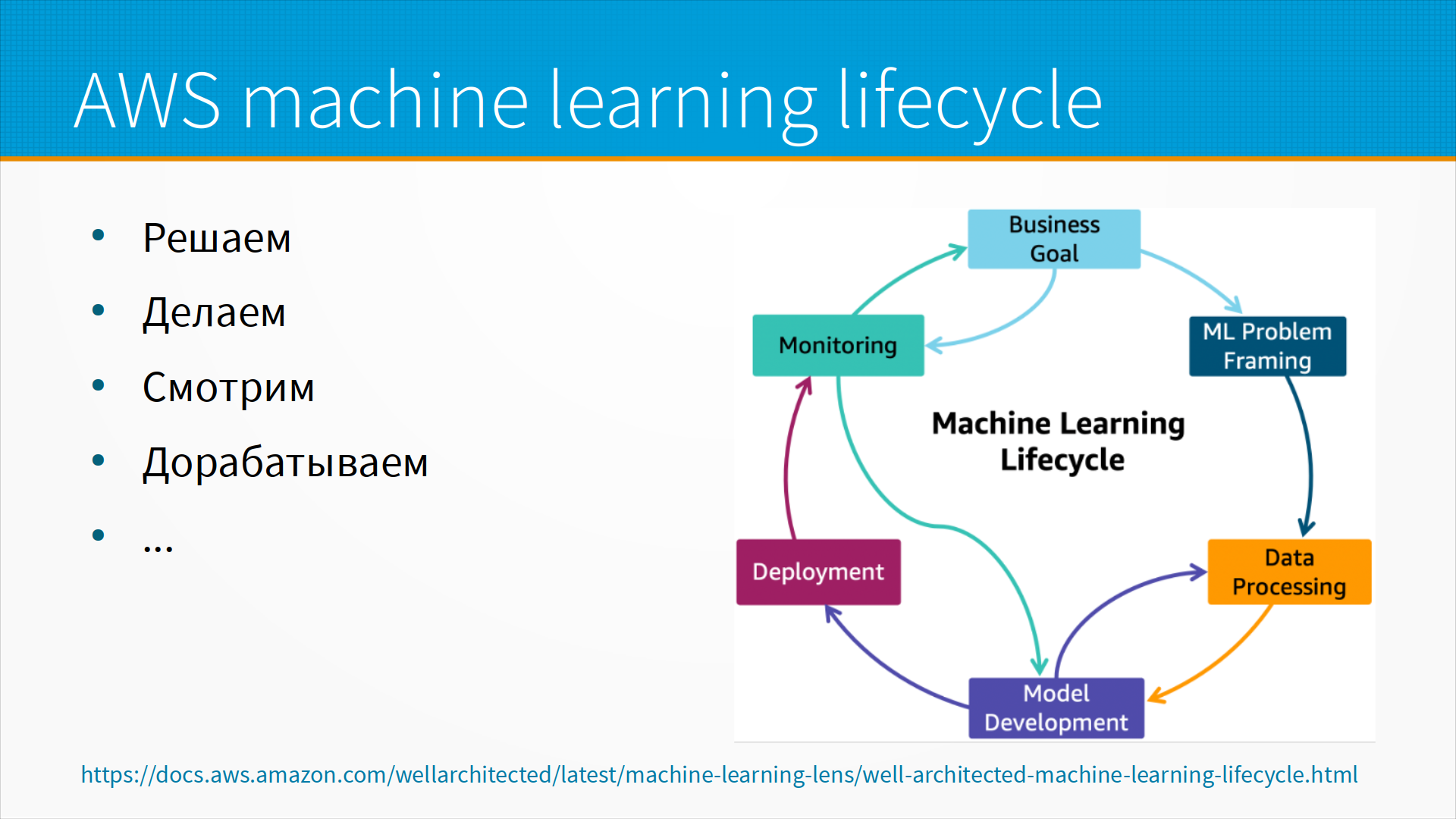
Например, рекомендованный AWS, то есть Amazon, Machine Learning Cycle. Если мы внимательно посмотрим, то на самом-то деле мы увидим ту же самую модель CRISP-DM. То есть понимание бизнеса, постановка задачи, понимание данных и так далее и тому подобное. Если переформулировать простыми словами, то мы решаем, что же нужно сделать, сделаем это, потом смотрим, что получилось и дорабатываем. То есть мы ходим по кругу — решили, сделали, оценили, доработали.
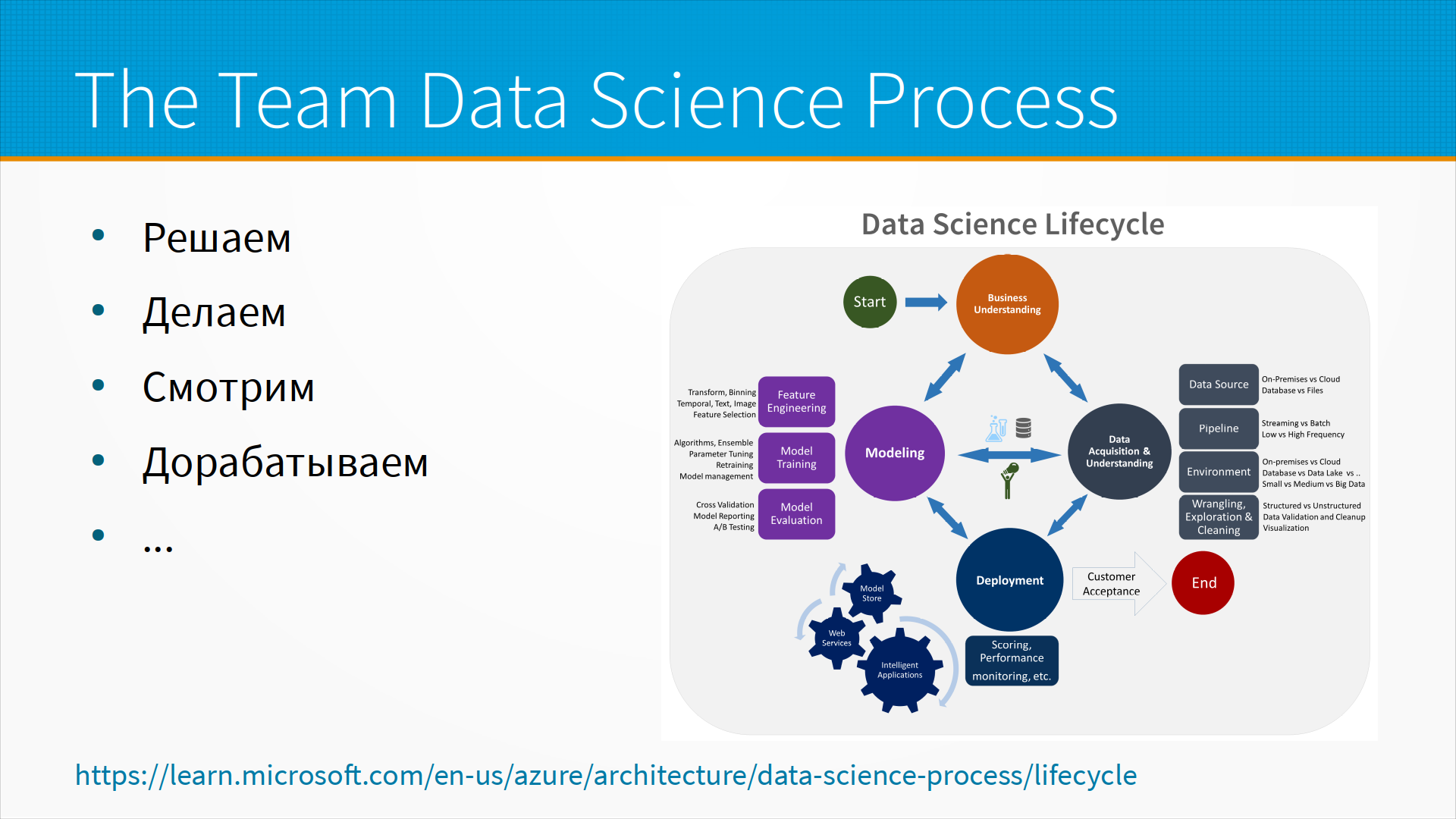
У Microsoft рекомендованный подход — это Data Science Lifecycle. И там примерно то же самое. Единственное, что он нарисован по-другому. Он нарисован не как некоторый круг, а как некоторая игра, в которой мы переставляем фишку с места на место. Но мы тут же видим те же самые этапы — то есть Business Understanding, Data Acquisition, Modeling, Deployment и снова оценка и повтор. То есть все так же решаем, делаем, смотрим и потом дорабатываем. Ходим по кругу.
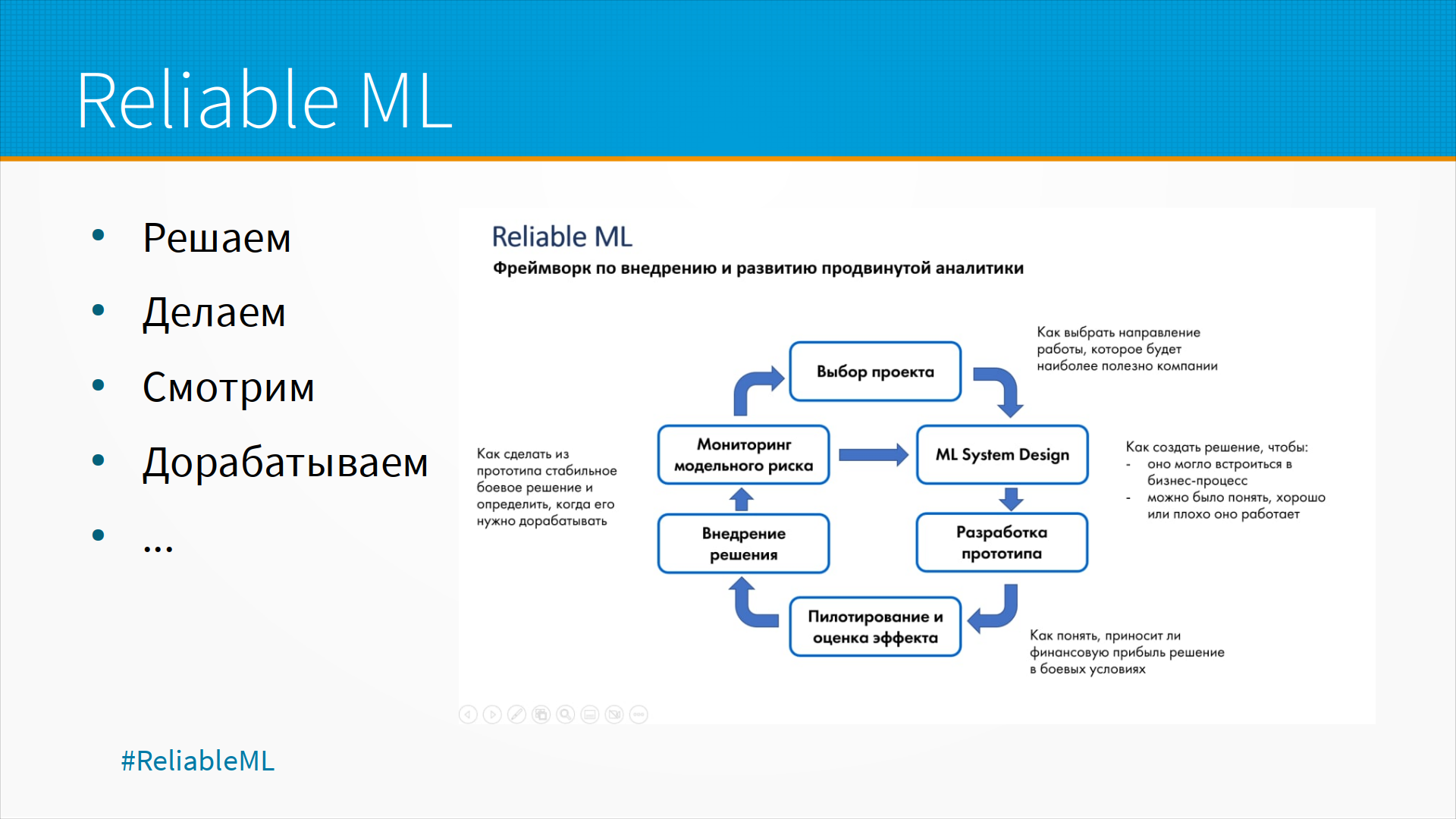
В модели Reliable ML, которую Ирина Голощапова публикует в нашем с ней канале Reliable ML, рассматривается внедрение продвинутой аналитики в больших организациях. И там процесс устроен тоже так: выбор проекта — считай, business understanding, ML System Design — то есть понимание данных и уточнение задачи? разработка прототипа, пилотирование, оценка эффекта — evaluation, внедрение решений — deployment. И затем мы снова идем по кругу. То есть по-прежнему мы решаем, делаем, смотрим и дорабатываем. То есть во всех этих моделях, очень в разных условиях построенных, есть одно общее — модель придется дорабатывать много раз. То есть мы ходим этим кругом, и на каждом круге нам придется переделывать модель.

Почему нам ее приходится переделывать? Ну, во-первых, это тот самый пресловутый сдвиг данных, data shift. Во-вторых, меняющиеся бизнес-требования. За те полтора года, что мы внедряли нашу аналитику или нашу систему, бизнес радикально изменился. Условия ведения бизнеса, его цели, задачи, планы.
Нам нужно понять, как часто мы будем переобучать модель. Некоторые бизнесы требуют переобучать модель раз в год, некоторые раз в 15 минут. Достаточно ли нам будет переобучить модель на новых данных, чтобы учесть сдвиг данных, или нам нужно будет переделывать модель?
Не совсем понятно, как сравнивать производительность новой и старой модели. В конечном итоге то, что старая модель плоха, мы понимаем на наших новых данных. А как мы поймем, что наша новая модель плоха — ведь данные, позволяющие сделать этот вывод, придут только потом? Ну и как бы автоматизировать дообучение модели, чтобы это происходило все более-менее автоматически? По ссылке внизу слайда есть хороший разбор того, как эти проблемы можно решать.

Всегда, когда мы приходим и начинаем улучшать нашу модель, встает вопрос, что мы делаем — учим ли мы модель на новых данных, пытаемся ли мы добыть новые данные, как-то почистить их, обработать, или нам нужно разработать, улучшить нашу архитектуру модели?
Правило большого пальца, которым я придерживаюсь сам и придерживаются многие коллеги, с которыми я это обсуждал, это — сначала сделайте акцент на данных. То есть, если есть возможность переобучать модель чаще, то есть, если вы переобучили модель на новых данных и качество выросло, делайте так: если есть возможность дочистить данные, то есть выкинуть какой-то мусор, и вы заметили, что, дочистив данные, вы получаете увеличение качества, то чистите их, пока это не перестанет давать отдачу. А если есть возможность собрать еще данных, купить, собрать, залить, подождать, пока они еще зальются, и это увеличивает качество модели, оставайтесь на той же архитектуре и просто докидывайте данные. И только если вы выжали из данных уже все, что можно выжать, переходите к поиску новых архитектур и моделей.
Но это все исходит из предположения, что существующая модель более-менее хорошо, как-то плюс-минус уже работает. То есть если она не работает совсем никак, то, конечно, надо искать новую архитектуру. Но если у вас уже есть рабочая модель, и вы сталкиваетесь со сдвигом данных или с тем, что качество чуть-чуть проседает по времени непонятно почему, то попробуйте просто поработать с данными.

Хорошо бы, конечно, постоянно дообучать модель каждый раз, как приходят новые данные. Например, у нас пришел новый клиент, мы получили его данные и сразу дообучили модель, чтобы она учитывала и эти новые данные.
Тут есть несколько проблем. Одна из них – это явление катастрофического забывания. Это когда мы берем нашу модель, доучиваем ее на новых примерах, и она, когда учится новым примерам, забывает старые. По ссылкам тут на слайде есть разбор этой проблемы для нейронных сетей и некоторые подходы, как с этим можно жить.
Другая проблема – это большая вычислительная нагрузка. То есть, если мы будем переобучать нашу модель каждый раз, когда к нам пришел новый пользователь, нам понадобится гораздо больше серверов, чем просто для инференса. Обычно обучение – это более тяжелая задача, чем инференс. И еще — наша вычислительная архитектура, на которой мы выдаем результаты модели, она обычно оптимизирована для инференса, не для обучения. То есть, например, инференс нейронных сетей часто делается на ЦПУ, а обучают их на ГПУ.
Решение тут простое – это дообучать не каждый раз, когда приходит новая точка данных, а дообучать батчами. То есть, мы дообучаем раз в день или каждую тысячу новых посетителей, или как-нибудь еще. То есть, мы собираем данные в пачку и отправляем модель дообучаться.

Как часто дообучать модель? Это сложный вопрос, и зависит он от того, много ли данных нам поступает каждый день, часто ли меняется распределение, и замечаем ли мы улучшение после переобучения. То есть, например, мы можем провести такой эксперимент — взять наши данные за последний год и обучить на данных за первые три месяца года, за первые шесть месяцев года, за первые десять месяцев года и смотреть, как качество работы модели на исторических данных меняется. То есть, скорее всего, после того, как мы обучили модели на первых трех месяцах, на четвертом месяце в апреле-мае она вела себя хорошо, а затем качество ее начало падать. И вот если мы проведем этот эксперимент и увидим, как быстро наша модель начинает деградировать, мы можем оценить, как часто нам ее надо переобучать. То есть, если, например, мы видим, что наша модель до неприемлемого уровня деградирует за месяц, то, наверное, раз в две недели ее надо переобучать.
В производстве часто делают так, что у нас есть какие-то основные датчики, которые снимают показания, и они изнашиваются, они ломаются, у них уплывает точность, и их рано или поздно меняют, то есть проверяют и меняют. И, скажем, нам надо переобучать модель в два раза чаще, хотя бы в два раза чаще, чем меняют основные датчики. Почему так? Ну, потому что датчик меняют, когда его точность вышла за допустимые пределы, и где-то вот в середине она уже значительно уплыла. То есть, смотрим, что у нас полный комплект датчиков меняется, допустим, раз в полгода, но хотя бы раз в три месяца надо переобучаться. А если мы помним, что на производстве датчики меняются по одному, а не все сразу, то, в общем, понятно, что нам, скорее всего, надо будет переобучаться раз в месяц или даже чаще.
На слайде цитата из фейсбуковской статьи 2016 года, тогда они перешли из тренировки моделей еженедельно к тренировке моделей ежедневно и просто получили один процент качества дополнительного. А сейчас, я думаю, что они учат чаще, чем раз в день, но я не нашел статью, которая бы это описывала.
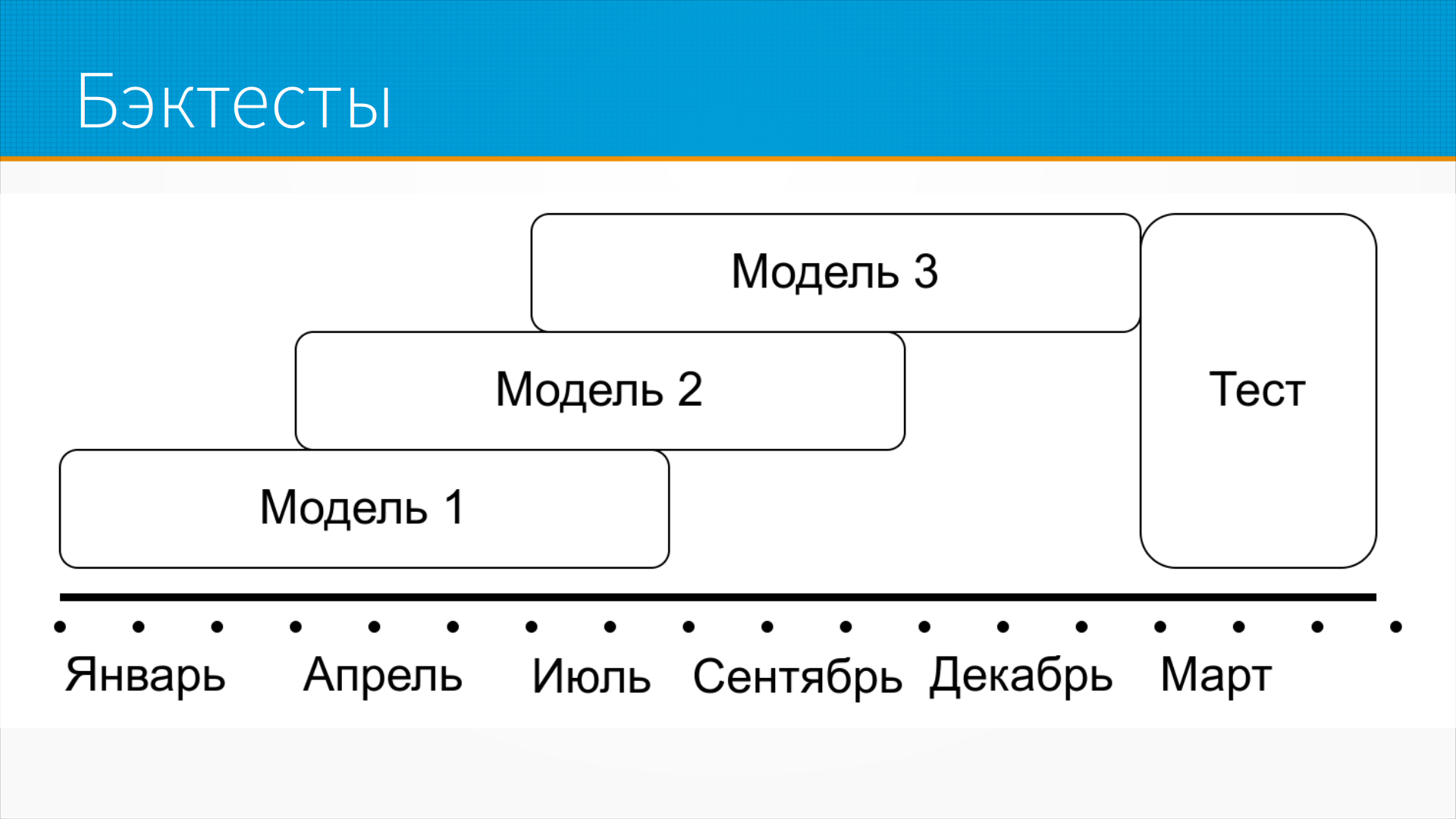
Для анализа качества моделей хорошо использовать так называемые бэктесты, или ретротесты. Мы берем наши данные за последние несколько месяцев, и на некоторых подмножествах наших данных, допустим, на первых трех месяцах года, на вторых трех месяцах и так далее, мы учим нашу модель и смотрим, как качество этой модели 1, модели 2, модели 3 меняется на наших тестовых данных в конце года. И так мы можем оценить, насколько наши данные подвержены сдвигу, насколько наша модель к нему устойчива.

Есть еще один выбор, который нам предстоит сделать — это дообучать нашу модель кусочками итеративно или переобучать ее с нуля.
Не все модели можно дообучать, то есть, например, модели градиентного бустинга дообучаются добавлением новых деревьев в конец модели. Таким образом, при каждом цикле дообучения модели модель становится все больше и больше. В тех случаях в индустрии, когда используют дообучение модели градиентного бустинга, обычно делают так. Ей позволяют расти до какого-то размера, а потом ее снова переобучивают маленькую, скажем, до 300 деревьев, и потом при каждом переобучении по 150-200 деревьев снова добавляют. Ну, цифры случайные, то есть, это из практического примера, у вас может быть по-другому.
Это statefull обучение модели, обучение от текущего, скажем, чекпоинта, то есть, у нас есть какой-то чекпоинт модели, какая-то версия модели, и мы ее потихонечку дообучаем. Это лучше всего работает с нейронными сетями, они естественным образом дообучаются. Другой вариант — это stateless, когда мы дообучаем модель на данных с нуля. Это несколько более тяжелая операция, то есть, нам нужно дольше ее учить, но зато у модели меньше проблем с этим катастрофическим забыванием того, чему она училась вначале. То есть, stateless или statefull. То есть, надо понять, позволяет ли нам сама архитектура модели обучаться statefull, и, если позволяет, то насколько это оправдано, какой выигрыш это нам дает. Это надо просто смотреть по ситуации.

Что может ограничивать частоту обучения? Ну, прежде всего, частоту обучения ограничивают проблемы с доступом к данным. Во-первых, новые данные могут поступать не так быстро. Во-вторых, например, есть практические примеры, когда просто для того, чтобы выгрузить данные из базы для обучения, нужен почти день работы пайплайна. И, соответственно, чаще, чем раз в день, вы их дообучать просто физически не сможете.
Есть большая проблема в многих бизнесах с доступом к разметке. То есть, когда у нас есть естественные метки, и разметка поступает почти сразу же — то есть, мы показали пользователю какую-нибудь рекламу, он перешел по ней или не перешел, или мы порекомендовали ему какой-нибудь кинофильм, он, допустим, пошел его смотреть или не пошел. Это естественные метки с быстрой обратной связью. Мы можем быстро на них учиться. Но иногда у нас разметка поступает с большой задержкой, как, например, в кредитах, когда даже после того, как человек перестал платить по кредиту, нам все равно нужно выждать три месяца, прежде чем решить, что это дефолт. И таким образом мы могли бы, допустим, переобучаться на новых клиентах, но мы должны дождаться, пока нам приедет их разметка.
Мне приходилось сталкиваться с моделями, которые переобучались ежедневно, но при этом само переобучение занимало значительную часть дня. Таким образом, чаще, чем раз в день, учить особо не имело смысла, потому что мы как раз за день успевали дообучиться.
И большая проблема с оценкой и сравнением моделей. То есть вот мы обучили модель — а как мы сравним ее с предыдущей моделью, которая у нас стоит на проде? Если бы у нас переобучение шло редко и вручную, то есть человек подошел, запустил, сравнил модель, прогнал на тестовые выборки, запустил бэктесты, он мог бы хорошо и обоснованно сравнить модели, хотя и тут есть проблема с оценкой на сдвигающихся данных.
Если мы обучаем модель автоматически раз в сутки, например, то как мы можем обоснованно сказать, что эта модель лучше или хуже, чем та, которую мы обучили вчера? Как мы можем гарантировать то, что на прод у нас не улетит плохо обученная или вообще сломанная модель? Как мы измеряем качество моделей, как мы сравниваем их между собой? То есть как мы понимаем, что наше переобучение моделей вообще улучшает работу системы, а не ухудшает ее?
Это сложный вопрос, потому что если мы, например, просто будем оценивать качество работы нашей модели, то может так получиться, что, например, вчера мы обучили модель на воскресных данных и в понедельник она работала плохо, во вторник мы обучили модель на данных в понедельник, и она работала хорошо, но мы не заметили этой разницы, потому что разница в поведении людей между воскресением и понедельником сама такая, что качество модели на фоне этой разницы незаметно, то есть само поведение людей меняется гораздо сильнее, чем качество модели, которое должно предсказать это поведение. То есть не наша рекомендательная система работает хуже или лучше, а люди больше или меньше покупают, например.
Ну и, как я уже говорил, большая проблема с ограничениями ML-алгоритмов — у них точно так же частоту обучения может ограничивать чисто архитектура, то есть, например, градиентный бустинг вы не можете дообучать бесконечно.
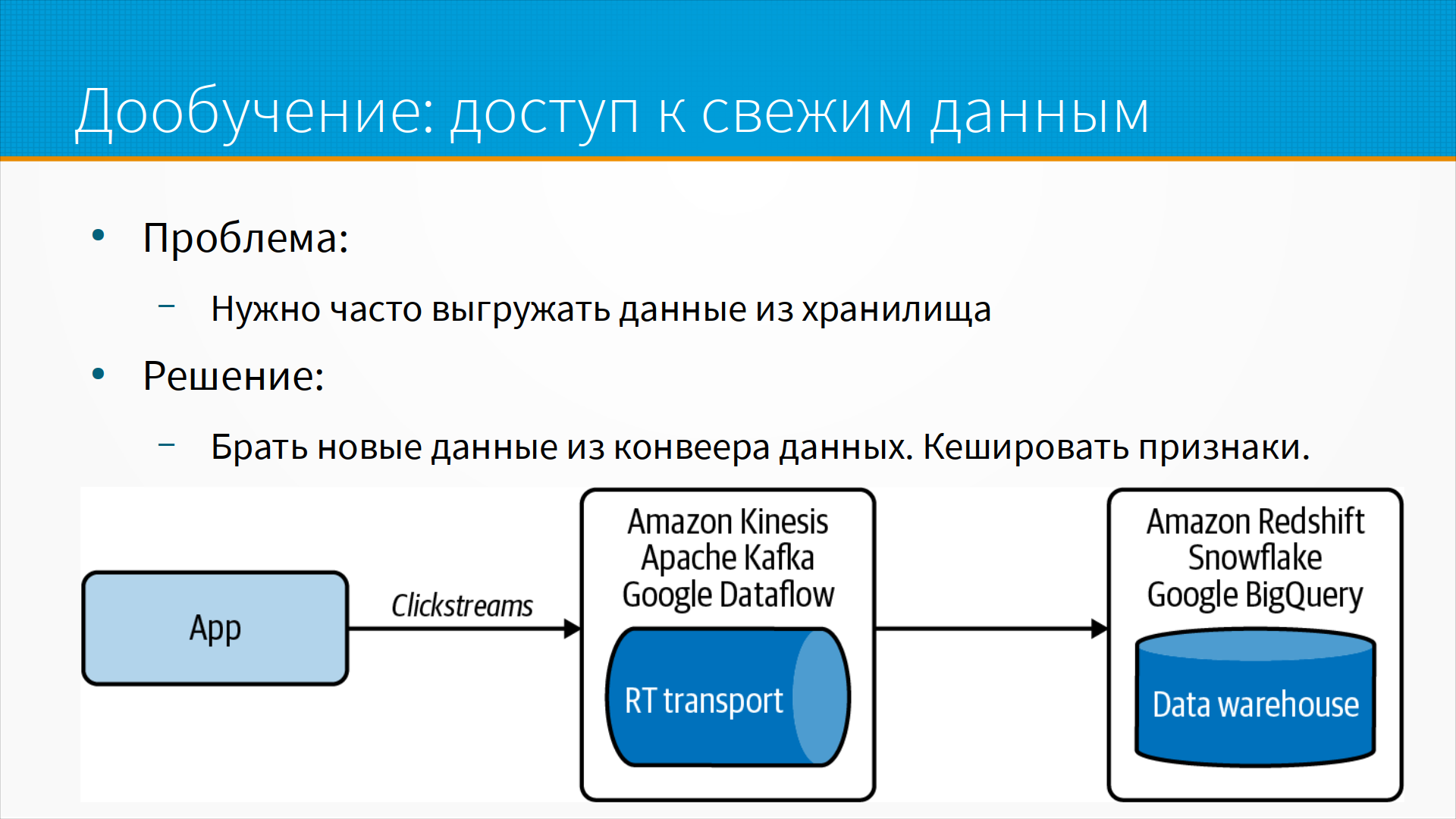
С дообучением есть интересный архитектурный паттерн, когда нам нужно выгружать много данных из хранилища, и это медленная процедура, то мы можем брать новые данные не из хранилища, а из конвейера данных и кэшировать. То есть предположим, что сначала мы выгрузили наши данные для моделей из хранилища, насчитали на них признаки и закэшировали признаки. Признаки гораздо меньше, чем сырые данные, и мы можем позволить их себе закэшировать. А когда нам пришли новые данные, мы взяли их прямо из Apache Kafka, насчитали на них признаки прямо на лету и тоже сложили. Таким образом, для дообучения моделей у нас всегда готов кэш насчитанных признаков. То есть мы досчитываем признаки прямо из пайплайна обработки, из Google DataFlow, или из Apache Kafka, или из Amazon Kinesis.

Проблему доступа к свежей разметке мы можем решить, добавив какую-нибудь обратную связь от пользователей, которая бы притворялась естественными метками. То есть, например, мы показали людям какой-нибудь перевод в нашей системе перевода, и вместо того, чтобы пытаться как-то оценить самим, хорошо мы их перевели текст или плохо, мы спрашиваем пользователей — пожалуйста, оцените, это был хороший перевод или нет. И, даже если у нас нет естественных меток и обратной связи, мы тем не менее можем построить программную слабую разметку, то есть построить свою модель, которая будет предсказывать на основании поведения пользователей его естественную метку.
То есть, например, несмотря на то, что формально по закону мы должны подождать 90 дней до того, как засчитать человеку дефолт, на практике мы можем уже по его поведению — что он перестал выходить на связь с нами, что он не отвечает на наши звонки, что он не обслуживает платежи, не заходит в приложение, - ну, в принципе, мы дефолт можем предсказать раньше, чем закон нам разрешает это сделать. И мы можем добавить программную слабую разметку. Тут вопрос, можем ли мы юридически опираться на эту разметку, но, в общем, тем не менее, добавить мы ее можем.
Точно так же в рекомендательных системах по тому, какое количество страниц просмотрел человек после того, как мы вам показали рекомендацию, мы можем построить модель, которая предсказывает, какой будет сильная метка. То есть, скажем, мы узнаем о качестве рекомендации через, допустим, месяц, если это какая-нибудь инвестиционная или кредитная рекомендация, но уже сразу по поведению пользователя, по тому, как он ходит по сайту, мы можем предположить, понравилось ему это или нет.
То есть, с помощью программной разметки мы можем сделать слабую разметку. То есть, лучше всего иметь natural label, естественную разметку, обратную связь от пользователя, но мы можем сделать слабую разметку, которая притворяется естественными метками. Таким образом мы можем учиться быстрее, чем нам приходит ground truth с твердой разметкой.
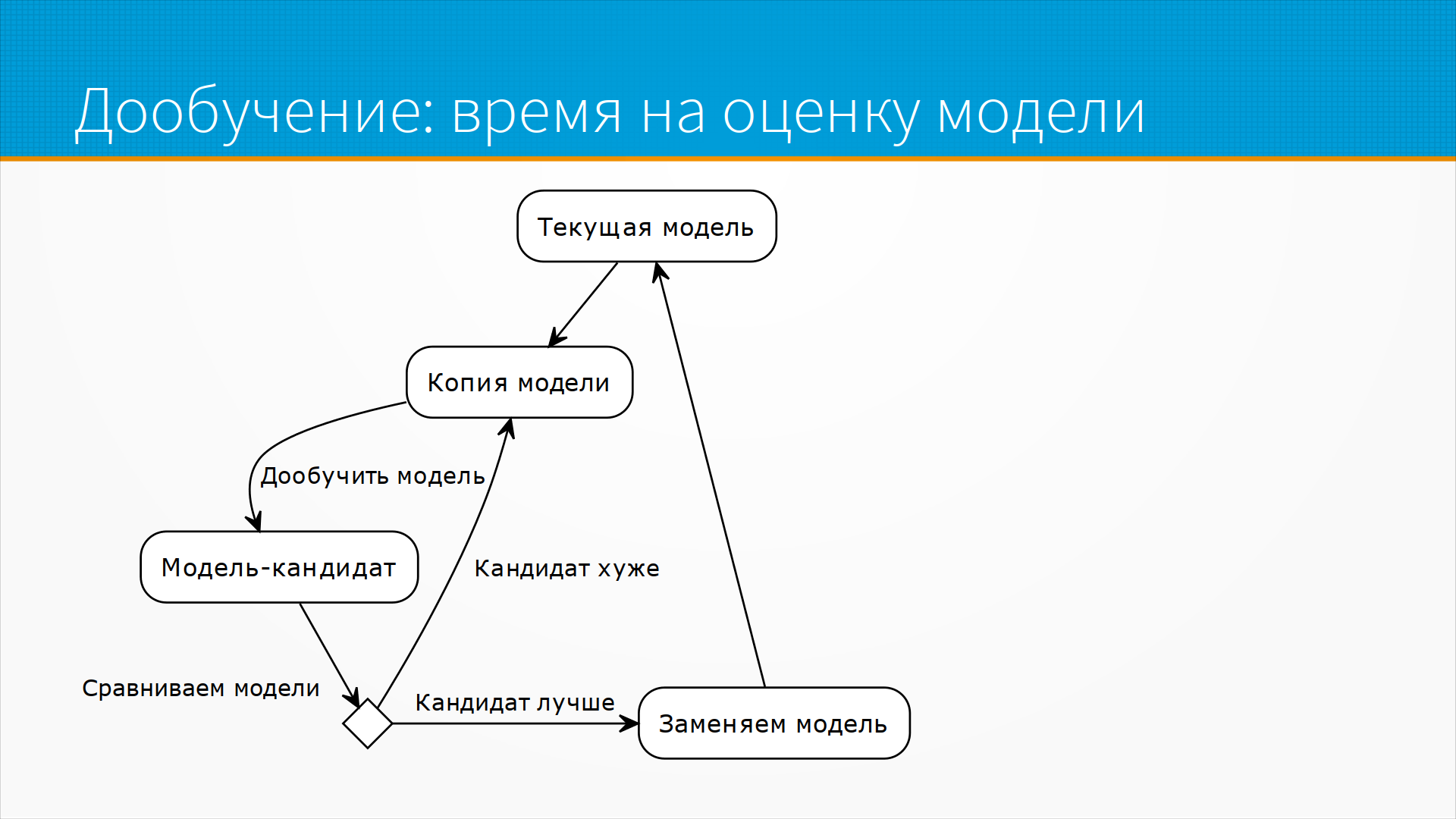
Очень ограничивает время на оценку модели. То есть, обычно это самое сильное ограничение. Как мы могли бы, допустим, дообучать наши модели? Вот есть у нас текущая модель, которая висит у нас на проде, и мы копируем ее и дообучаем ее на свежих данных. Получаем некоторую модель-кандидат, после чего мы должны каким-то образом сравнить модели. В самом тривиальном случае мы запускаем, допустим, так называемую фоновую модель, фоновый deployment, когда наши данные с прода льются на нашу новую модель, но ее решения мы не принимаем в расчет, мы их просто фиксируем, но на основе их никаких рекомендаций не даем. По-прежнему все рекомендации, все решения идут от нашей текущей старой модели. И так мы даем ей поработать, чтобы накопилась какая-то статистика, и смотрим, насколько решение нашей новой модели лучше, чем решение старой.
Тут, кстати, есть проблема с selection bias, то есть с самоотбором, поскольку у нас есть подтвержденные решения только текущей модели, и нет подтвержденных решений модели-кандидата. Но тем не менее предположим, что мы эту проблему как-то решили.
??? Нам получается для того, чтобы принять решение, что кандидат лучше, чем текущая модель, Selection Bias, то есть текущая статистика. ???
И это количество трафика может быть достаточно большое, чтобы мы получили нужную статистическую значимость при заданной мощности. И только потом мы можем заменить модель. И понятно, что переобучать модели чаще, чем мы их можем оценить, нет никакого смысла. Поэтому время на оценку модели — самое большое ограничение после доступа к данным.

Ну и про ограничение алгоритмов мы уже говорили. Тут обычно есть какие-то архитектурные решения, которые позволяют дообучать нейронки. То есть, например, большие нейронные сети дообучать долго, но у нас есть технологии few shot learning, которые могут не переобучать большую нейронную сеть, а дообучать некоторую проекцию на ее выходе, тем самым поднимая качество ее работы, дотягивая ее до новых данных, избегая переобучения большой нейронной сети, что может занимать месяц или, скажем, несколько месяцев на даже достаточно крупных вычислительных мощностях. Небольшие нейронные сети мы можем дообучать быстро и легко, но, соответственно, полезность их тоже ограничена. Про дообучение градиентного бустинга — это достраивание деревьев — это всегда проблема. И есть большая проблема с дообучением алгоритмов матричной факторизации в рекомендательных системах. В некоторых моделях, например, в implicit, есть варианты рекалькулировать, когда мы пересчитываем нашу матрицу для каждой входящей точки. Там есть свои ограничения, но все-таки как-то мы можем чуть-чуть улучшать нашу модель прямо онлайн во время инференса.

По мере того, как наша система становится более зрелой, как более зрелыми становятся наши процессы обучения и дообучения, мы проходим условно через четыре этапа. Первое — это manual stateless retraining, то есть ручное переобучение с нуля по запросу. То есть нам аналитики сказали — ребята, у вас модель работает плохо. Мы прогнали бэктесты, дообучили новую модель, прогнали на них бэктесты и сказали — вот, теперь стала лучше, и выкатили ее на прод. Это то, как в большинстве организаций работают с моделями машинного обучения.
По мере того, как моделей становится больше и переобучаются они чаще, команды переходят к automated stateless retraining, то есть когда мы переобучаем и дообучаем наши модели по расписанию. Тут нам приходится решать немного интересных вопросов по автоматической оценке качества модели, по мониторингу моделей, по откату к предыдущим версиям моделей.
И после того, как мы с этим разобрались, отстроили процессы, мы обнаруживаем, что у нас очень много моделей, и, как правило, наша система зависит от нескольких моделей. И не все комбинации моделей у нас работают вместе хорошо, то есть у нас получается проблема качества работы не конкретной модели, а качества работы всей системы. То есть, в принципе, каждая модель работает хорошо, но, поскольку система зависит от взаимодействия всех своих частей, она больше, чем каждая часть по отдельности, может так получиться, что, в принципе, все модели хорошие, но именно вот эта комбинация версий моделей разных работает плохо. И нам приходится управлять многими версиями моделей, многими версиями схем данных, и в этот момент у нас, скорее всего, образуются какие-нибудь фич-сторы, витрины данных у нас появились раньше, и какое-нибудь версионирование моделей в нашем инструменте MLOps мы вынуждены использовать.
И после того, как мы все эти процессы обучения отстроили, мы переходим к continual learning. Это когда наша система сама решает, когда нам нужно дообучать модели. Либо она делает это на лету при получении каждой точки данных, если вдруг мы архитектурно это смогли. Либо она сама раз в какое-то время, либо при падении качества определяет и запускает переобучение модели, либо она сама выявляет сдвиг и опять же запускает переобучение модели. То есть по мере того, как мы движемся по этой лестнице зрелости процессов MLOps, мы переходим от полностью ручного принятия решений, что модель пора переобучить, что модель хороша, что качество новой модели на A/B-тестах подтверждено, к continual learning системе, которая более-менее автоматически принимает сами эти решения, а человек включается в эту систему только когда у нас появляются новые идеи по поводу данных или архитектуры, или когда нам прилетают алерты из этой системы, что что-то пошло не так.

Так или иначе мы придем к тому, что нам придется тестировать нашу модель на живых людях. Это как бы то, от чего, допустим, разработчиков программного обеспечения отучивают, то есть тестировать вживую плохо, тестировать на проде плохо. Но на самом-то деле, в большинстве случаев, в условиях сдвига данных, тестировать вживую все равно придется, потому что по-другому мы не оценим качество новой модели. То есть сдвиг данных искажает качество. Какую-то оценку качества модели нам могут дать ретро-тесты, но у них известная проблема, ну, это бэктесты, о которых мы говорили раньше — переобучение на тестовой выборке. То есть так или иначе нам придется сравнивать наши модели на живых данных, и надо понять, как это делать.

Базовых подходов в основных пять. Это, во-первых, теневое развертывание. То есть мы разворачиваем нашу модель на дополнительном сервере, но не принимаем ее решение в расчет. Canary release, пробный релиз – это когда мы разворачиваем нашу модель на маленьком количестве пользователей, которых не жалко, если все пойдет плохо. A/B-тестирование – это когда мы сравниваем производительности старой и новой модели, ищем статистическую разницу в пользу новой модели. Чередование, interleaving – это когда мы пускаем рекомендации через одну, если получается. Ну и многорукие бандиты – когда мы запускаем модели одновременно, и, по мере того, как какая-то из моделей работает лучше или хуже, мы перераспределяем трафик на них.

Про теневое развертывание. Схема тут такая – мы разворачиваем новую модель, дублируем на нее весь трафик, записываем предсказания, но не отдаем пользователям, и пытаемся проанализировать, ошиблась она или нет. Очевидная проблема — что мы удваиваем затраты на инференс совершенно бесполезно, то есть у нас полностью вся инфраструктура дублирована для инференса, но реально никакого практического использования там нет, то есть пользователи не видят эти предсказания. Затем мы выкатили нашу модель, она работает, может быть, она уже работает лучше нашей старой модели, но все равно мы ее пока пользователям не показываем, то есть наша полезная хорошая модель доходит до пользователей с большой задержкой, до тех пор, пока мы не накопим достаточно данных, которые бы подтверждали, что да, эта модель лучше. Ну и смещение выборки, selection bias, тут имеет значение, по ссылке на слайде немножко разбирается эта проблема.

Канареечный деплой, canary release – это когда мы развертываем нашу новую модель и направляем на нее небольшую часть трафика. Мы так можем поймать самые грубые ошибки. То есть, например, во многих моделях машинного обучения у нас есть варианты, когда мы совершенно точно знаем, что ответ должен быть отрицательный или положительный, и мы на канареечном релизе можем проверить, что наша модель не делает грубых ошибок. Проблема канареечного релиза в том, что он не заменяет A/B-тест, потому что обычно, раз трафика мало, то и статистическая значимость найденных различий невелика. Но канареечный релиз хорошо запускать перед A/B-тестом, чтобы убедиться, что у модели нет грубых ошибок, прежде чем выпустим на нее половину продуктового трафика. Ну, или вместо него, если мы не ожидаем значительных изменений, а просто вот такое дежурное небольшое изменение. По ссылке на слайде есть статья, где Netflix рассказывает, как они делают канареечный деплой при каждом релизе, чтобы проверить, что они не сломали рекомендательную систему этим маленьким улучшением.

Золотой стандарт оценки качества модели — это A/B-тестирование. То есть мы разворачиваем новую модель, направляем на нее часть трафика и сравниваем качество, отзывы пользователей. Обычно делают не просто A/B-тест, а так называемый A/A/B-тест, или еще сложнее, когда мы делим трафик, например, на три части. Одну часть трафика направляем на старую модель, вторую часть трафика тоже направляем на старую модель, но считаем метрики отдельно, и третью уже часть мы направляем на новую модель. Для чего это делается? Для того, чтобы сравнить разницу между старой и новой моделью и между старой и старой моделью. Если у нас статистически значимая разница в качестве между предсказаниями старой модели в первой и во второй группе, то, наверное, что-то у нас с нашим тестом, сама по себе организация эксперимента где-то просела. То есть нам нужно более качественно делать эксперименты.
Проблема тут — это качественная рандомизация трафика. То есть, например, что такое в интернет-магазине поделить трафик на три группы? Например, мы берем и случайно образом раскидываем пользователей на старый и новый интерфейсы оформления заказов. Но ведь старые пользователи уже видели интерфейс оформления заказа, и они увидели новый — это повлияло на их поведение, соответственно, мы исказили A/B-тест. Либо мы старых, например, направляем на старый интерфейс, а всех новых направляем на новый интерфейс. Но у нас старые пользователи уже были в нашем магазине, у них поведение другое, не такое, как у новых. То есть они уже знают, где расположены элементы управления, им удобнее делать заказ. То есть, в общем, корректно сделать рандомизацию трафика трудно.
Всегда проблема со статистической мощностью — с объемом выборки. Даже если у вас огромные потоки в каком-нибудь Яндексе — как Яндекс говорит, даже им не хватает статистической мощности для того, чтобы делать столько тестов, сколько они хотят. То есть, грубо говоря, объема выборки всегда не хватает. Поэтому всегда приходится предпринимать какие-то специальные меры для повышения качества ваших A/B-тестов, для того, чтобы вытащить статистическую мощность из того, что у вас есть. Это CUPED и похожие на него алгоритмы. По ссылке несколько разборов того, как мы можем вытаскивать статистическую мощность в наших экспериментах.
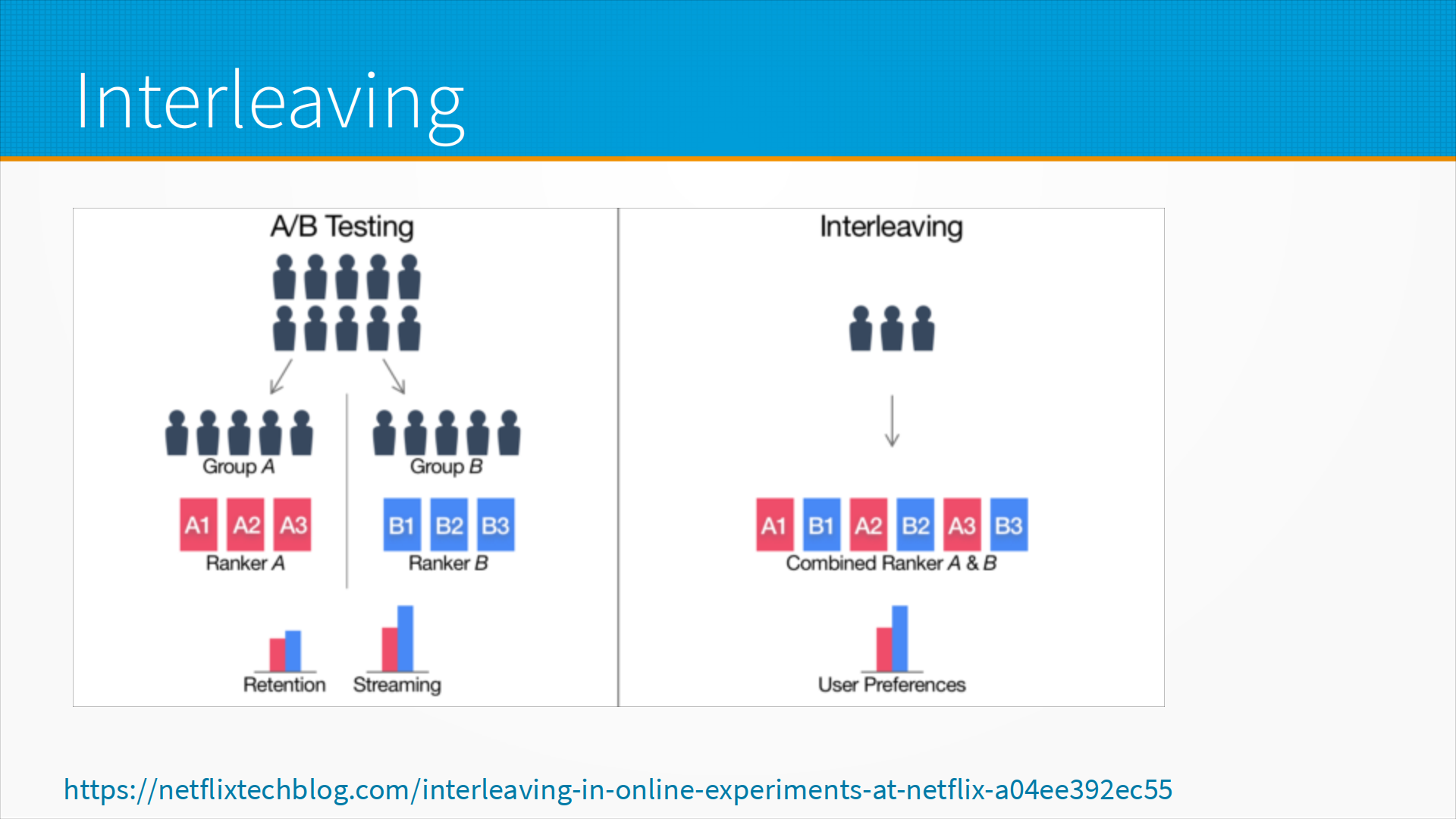
Хороший подход, если вы можете таким образом построить эксперимент, это interleaving. Это когда вместо того, чтобы делить трафик на группы и одной группе показывать, допустим, одну рекомендательную систему, а другой — другую, вы показываете всем рекомендации старой и новой системы перемешанные. То есть, через одного — отсюда это название и идет. Это позволяет вам избавиться от головной боли по рандомизации. Ну, на самом деле, тоже надо корректно это делать. По ссылке на слайде — то, как это делает Netflix.
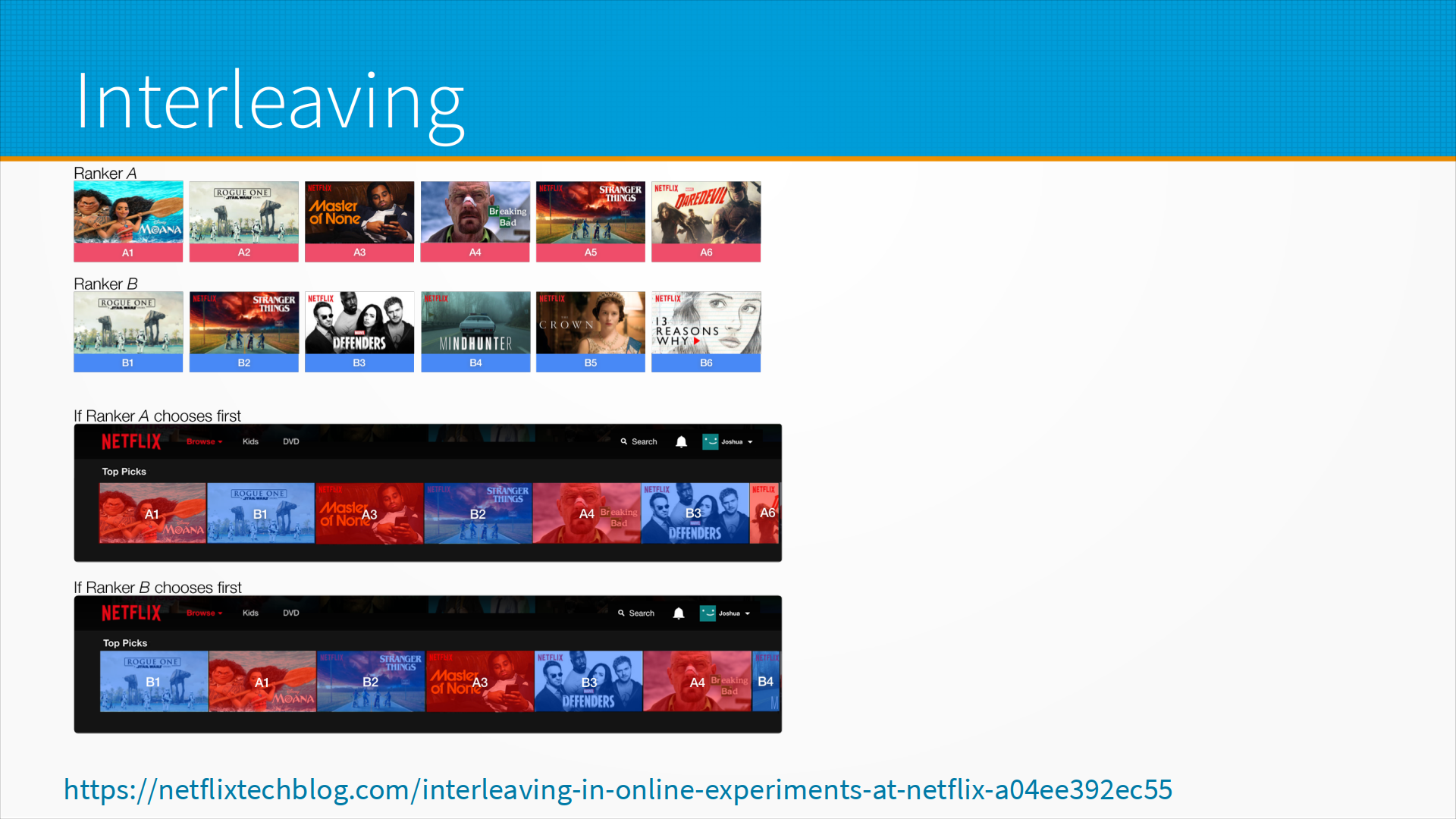
И вот на следующем слайде у нас пример того, как интерливинг работает у них вживую. То есть, несмотря на то, что они ставят их через одного, может повлиять то, какой будет, допустим, какая рекомендация самая левая. Потому что если у человека маленький экран, он может видеть три самых левых рекомендации. Если большой — пять самых левых рекомендаций. Поэтому они не только ставят рекомендации через одну, но и меняют, какая из них будет четная и нечетная. И таким образом они могут сравнивать, по каким конкретно рекомендациям человек кликнул. И таким образом сравнить, какая модель работает лучше.

Естественное развитие идеи интерливинга – это так называемые многорукие бандиты. Идея какая — мы разворачиваем несколько моделей одновременно и направляем трафик на всех них, более-менее случайно делим. И чем лучше модель работает, тем больше она получает трафика. Таким образом, если наши алгоритмы многоруких бандитов сходятся, то у нас в конечном итоге получается, что одна модель получает почти весь трафик, а остальные модели получают мало трафика. И таким образом мы время от времени худшие модели убираем, и новые дообученные модели добавляем в этот пул. Плюс мы быстро переключаемся на лучшую модель — то есть, если мы выкатили совсем хорошую модель, которая сильно лучше, чем старая модель, многорукие бандиты быстро переключат на нее трафик. А если мы выкатим плохую модель, то бандиты очень быстро уберут с нее трафик.
Минусы — это, во-первых, сложнее, чем A/B-тест. Ну и, на самом деле, с самой сходимостью алгоритмов многоруких бандитов тоже есть много проблем. То есть, вовсе не обязательно мы так уж быстро сойдемся к самой хорошей модели. Это надо проверять, это надо тестировать.
В алгоритмах многоруких бандитов мы всегда балансируем между изучением новых возможностей и эксплуатацией текущих возможностей. То есть, баланс между exploration и exploitation. То есть, что нам лучше — обеспечить высокое качество предсказаний для всех пользователей либо попробовать новые какие-то интересные варианты. Обычно это настраивается в самом алгоритме многоруких бандитов.

Дополнительные материалы: