
- 26.09.2022
- 05.10.2025
- обучение
- #mlsystemdesign
Первая лекция открытого курса "Дизайн систем машинного обучения", "Машинное обучение на практике".
Слайды можно скачать тут mlsysd1ods.pdf
Текстовая расшифровка лекции:
 Привет! Меня зовут Дмитрий Колодезев, и это первая лекция нашего курса про дизайн систем машинного обучения.
Привет! Меня зовут Дмитрий Колодезев, и это первая лекция нашего курса про дизайн систем машинного обучения.
 О чем мы будем рассказывать в этом курсе? Обычно в курсах про машинное обучение учат строить модели, но мы
не будем этого делать, и вот почему. Во-первых, есть очень много хороших курсов, в которых этому учат. Во-вторых,
делать модели машинного обучения легко - ну, или легко после некоторой практики. Трудно сделать так, чтобы они работали хорошо.
Еще труднее сделать, чтобы ими пользовались. Мы будем изучать ML-системы в реальной жизни - в бизнесе, в производстве,
с точки зрения кода, оборудования и той пользы, которую машинное обучение может причинить.
О чем мы будем рассказывать в этом курсе? Обычно в курсах про машинное обучение учат строить модели, но мы
не будем этого делать, и вот почему. Во-первых, есть очень много хороших курсов, в которых этому учат. Во-вторых,
делать модели машинного обучения легко - ну, или легко после некоторой практики. Трудно сделать так, чтобы они работали хорошо.
Еще труднее сделать, чтобы ими пользовались. Мы будем изучать ML-системы в реальной жизни - в бизнесе, в производстве,
с точки зрения кода, оборудования и той пользы, которую машинное обучение может причинить.
 Чего в этом курсе нет: в этом курсе нет рассказов про алгоритмы машинного обучения. На самом деле немножко про алгоритмы
все-таки есть, но я не строю на этом акцент. Нет также ничего про дизайн пользовательского интерфейса, API, не упомянута статистика,
и про нейронные сети и правила написания хорошего кода толком ничего не сказано.
Чего в этом курсе нет: в этом курсе нет рассказов про алгоритмы машинного обучения. На самом деле немножко про алгоритмы
все-таки есть, но я не строю на этом акцент. Нет также ничего про дизайн пользовательского интерфейса, API, не упомянута статистика,
и про нейронные сети и правила написания хорошего кода толком ничего не сказано.
Про System Design есть очень много материалов - в основном про то, как проходить собеседования. В этом курсе этой полезной информации тоже нет, но, если вас это интересует, у Карпова будет хороший курс с Бабушкиным по ML System Design, и вас там научат проходить собеседования так, что от зубов будет отскакивать.
 Мы попробуем в пятнадцать лекций уместить основы разработки моделей машинного обучения от возникновения идеи, выявления ограничений,
через сбор данных, деплой, мониторинг, валидацию бизнес-идей, проверку гипотез к собственно интеграции ML-системы в живые бизнес-процессы.
15 лекций примерно соответствуют 15-ти лекциям стэнфордского курса CS329, но тут есть некоторые вольности. Список тем на экране. В двух первых лекциях мы разберем проблемы, возникающие при дизайне ML-систем, а в остальных 13-ти лекциях обсудим решения.
Мы попробуем в пятнадцать лекций уместить основы разработки моделей машинного обучения от возникновения идеи, выявления ограничений,
через сбор данных, деплой, мониторинг, валидацию бизнес-идей, проверку гипотез к собственно интеграции ML-системы в живые бизнес-процессы.
15 лекций примерно соответствуют 15-ти лекциям стэнфордского курса CS329, но тут есть некоторые вольности. Список тем на экране. В двух первых лекциях мы разберем проблемы, возникающие при дизайне ML-систем, а в остальных 13-ти лекциях обсудим решения.
 Зачем вам может пригодиться этот курс? Самый очевидный способ его полезно как-то использовать - это запилить свой пет-проект
для портфолио. Можно попробовать запустить свой стартап - хотя время сейчас для стартапов откровенно неудачное.
Оно всегда неудачное, конечно. Можно попытаться устроиться на работу ML-инженером или MLOps инженером. Я думаю,
что этого курса недостаточно для того, чтобы устроиться на работу MLOps инженером, но хотя бы направление, куда копать, он даст.
Я думаю, что этот курс будет полезен будущим менеджерам ML-проекта или ML-продукта для того, чтобы понять, как устроен мир - чтобы они понимали основные подходы и ограничения при дотаскивании ML-систем до прода.
Зачем вам может пригодиться этот курс? Самый очевидный способ его полезно как-то использовать - это запилить свой пет-проект
для портфолио. Можно попробовать запустить свой стартап - хотя время сейчас для стартапов откровенно неудачное.
Оно всегда неудачное, конечно. Можно попытаться устроиться на работу ML-инженером или MLOps инженером. Я думаю,
что этого курса недостаточно для того, чтобы устроиться на работу MLOps инженером, но хотя бы направление, куда копать, он даст.
Я думаю, что этот курс будет полезен будущим менеджерам ML-проекта или ML-продукта для того, чтобы понять, как устроен мир - чтобы они понимали основные подходы и ограничения при дотаскивании ML-систем до прода.
 Этот курс чуть менее, чем полностью содран с курса CS329, который
Chip Huyen читала в Стэнфорде. По материалам курса она издала книгу, и в книге написано все, о чем я хочу рассказать.
Все хорошее, что есть в этом курсе, скопировано оттуда, все грубые ошибки добавлены мной лично. Ссылка на ее курс выше.
Видео недоступно, но достаточно подробные конспекты лекций есть.
Этот курс чуть менее, чем полностью содран с курса CS329, который
Chip Huyen читала в Стэнфорде. По материалам курса она издала книгу, и в книге написано все, о чем я хочу рассказать.
Все хорошее, что есть в этом курсе, скопировано оттуда, все грубые ошибки добавлены мной лично. Ссылка на ее курс выше.
Видео недоступно, но достаточно подробные конспекты лекций есть.
 Что нужно знать, чтобы успешно пройти этот курс? Этот курс не про знания, он скорее про типовые подходы к решению проблем.
Но кое-что знать все-таки нужно. В первую очередь, хорошо бы знать основы статистики. Хотя бы самые азы. Идеально вузовский курс статистики, но если нет - курса на Степике будет достаточно.
Что нужно знать, чтобы успешно пройти этот курс? Этот курс не про знания, он скорее про типовые подходы к решению проблем.
Но кое-что знать все-таки нужно. В первую очередь, хорошо бы знать основы статистики. Хотя бы самые азы. Идеально вузовский курс статистики, но если нет - курса на Степике будет достаточно.
 Предполагается, что вы умеете программировать на питоне. Подойдет любой вузовский курс программирования. Если
вы совсем не умеете программировать, скорее всего, этот курс не для вас. Но если хотите быстро вспомнить питон, вот курс на Степике.
Предполагается, что вы умеете программировать на питоне. Подойдет любой вузовский курс программирования. Если
вы совсем не умеете программировать, скорее всего, этот курс не для вас. Но если хотите быстро вспомнить питон, вот курс на Степике.
 В рамках курса придется делать модели машинного обучения, и хорошо бы, чтобы этому вас научил кто-то другой.
Хорошо бы, если у вас в ВУЗе был про это курс. Идеально, если бы его вел Александр Дьяконов. Но не всем так везет,
и на Хабре есть серия статей - первый одс-овский курс по машинному обучению, он старый, но все еще прекрасный.
В рамках курса придется делать модели машинного обучения, и хорошо бы, чтобы этому вас научил кто-то другой.
Хорошо бы, если у вас в ВУЗе был про это курс. Идеально, если бы его вел Александр Дьяконов. Но не всем так везет,
и на Хабре есть серия статей - первый одс-овский курс по машинному обучению, он старый, но все еще прекрасный.
 Думаю, что всем, кто серьезно собирается заниматься машинным обучением, нужен хотя бы небольшой опыт программирования под Linux
и работы с его командной строкой. Курс The Missing Semester of Your CS Education дает хорошее введение в работу с инструментами командной строки.
Думаю, что всем, кто серьезно собирается заниматься машинным обучением, нужен хотя бы небольшой опыт программирования под Linux
и работы с его командной строкой. Курс The Missing Semester of Your CS Education дает хорошее введение в работу с инструментами командной строки.
 Для того, чтобы сделать что-то интересное с текстом или картинками, вам наверняка понадобятся нейронные сети. Здорово, если
вы сталкивались с ними раньше и умеете работать с Pytorch или Tensorflow. Самый лучший курс по Pytorch - его документация. У Tensorflow она тоже хорошая, пробуйте. Мне больше нравится Pytorch, но это вопрос вкуса.
Для того, чтобы сделать что-то интересное с текстом или картинками, вам наверняка понадобятся нейронные сети. Здорово, если
вы сталкивались с ними раньше и умеете работать с Pytorch или Tensorflow. Самый лучший курс по Pytorch - его документация. У Tensorflow она тоже хорошая, пробуйте. Мне больше нравится Pytorch, но это вопрос вкуса.
 Итак, что такое дизайн систем машинного обучения?
Это процесс принятия решений про программный и пользовательский интерфейс, используемые алгоритмы, доступные и собираемые данные,
программную инфраструктуру и оборудование системы. Разрабатываемая система должна приносить пользу, удовлетворяя ограничениям по
производительности, надежности, масштабируемости и так далее.
Итак, что такое дизайн систем машинного обучения?
Это процесс принятия решений про программный и пользовательский интерфейс, используемые алгоритмы, доступные и собираемые данные,
программную инфраструктуру и оборудование системы. Разрабатываемая система должна приносить пользу, удовлетворяя ограничениям по
производительности, надежности, масштабируемости и так далее.
 Любой дизайн начинается с ограничений. Если у нас нет ограничений, не о чем и беспокоиться: как бы мы ни сделали, все равно будет хорошо.
Но в реальной жизни ограничения есть всегда. Если у вас нет ограничений - значит, вы чего-то не учли.
Часто ограничения приходят к нам от бизнес-заказчика. Например, в виде ТЗ. Но во всех нетривиальных случаях
предоставленные требования неполны, противоречивы и являются в лучшем случае хорошо информированным предположением.
Любой дизайн начинается с ограничений. Если у нас нет ограничений, не о чем и беспокоиться: как бы мы ни сделали, все равно будет хорошо.
Но в реальной жизни ограничения есть всегда. Если у вас нет ограничений - значит, вы чего-то не учли.
Часто ограничения приходят к нам от бизнес-заказчика. Например, в виде ТЗ. Но во всех нетривиальных случаях
предоставленные требования неполны, противоречивы и являются в лучшем случае хорошо информированным предположением.
Требования в любом случае предстоит выяснять самим. И про большинство ограничений мы узнаем уже тогда, когда система будет частично готова.
Как выявлять ограничения? Методом последовательных приближений. Сделайте какие-то предположения об ограничениях. Придумайте, как проверить ваши предположения. Разрабатывайте систему, основываясь на ваших гипотезах, уточняйте предположения каждый раз, как узнали что-то новое о мире и задаче. Это итеративный процесс.
 Машинное обучение - это автоматизированный подход к выявлению сложных шаблонов в имеющихся данных и использование
этих шаблонов для предсказаний на новых данных.
Машинное обучение - это автоматизированный подход к выявлению сложных шаблонов в имеющихся данных и использование
этих шаблонов для предсказаний на новых данных.
Разберем это утверждение по частям. Мы делаем предположение, что мы можем выявить шаблоны в данных (а это не всегда возможно).
Кроме того, мы делаем предположение, что шаблоны - сложные. Нам не нужно машинное обучение, чтобы предсказать восход солнца - там довольно простой шаблон: оно восходит утром, заходит вечером. Есть некоторые аномалии в полярных районах, но в целом шаблон простой.
Но, чтобы предсказать погоду, машинное обучение нам нужно - потому что шаблоны там очень сложные.
Опять же, мы предполагаем, что данные, в которых мы будем искать шаблоны, у нас имеются. Часто заказчики ML-систем думают, что данные есть - а на самом деле их нет, или их очень мало. Получение данные и их обработка - основная статья денежных и временных затрат в ML-проектах.
Мы предполагаем, что мы сможем делать полезные для нас предсказания - но это тоже не всегда возможно. Чем больше в данных шума, тем меньше от данных пользы, и тем сложнее что-то на них предсказать.
Ну и мы предполагаем, что в тот момент, когда нам нужно будет сделать предсказание - нужные данные будут доступны. Часто нужные нам данные приходят с опозданием - и ими уже не получается воспользоваться. Например, мы могли бы предсказать, отчислят студента с первого курса или нет, по посещаемости им лекций. Но если данные о посещаемости вбивают в учебную систему задним числом в конце года, то воспользоваться ими для предсказаний отчисления по итогам первого семестра не получится.
 Для каких задач подходит машинное обучение?
Для каких задач подходит машинное обучение?
Машинное обучение наиболее полезно для автоматизированного быстрого принятия не очень важных решений в больших масштабах.
Например, часто повторяющаяся задача - рекомендации товаров в интернет-магазине - идеально решается машинным обучением. Если рекомендации будут неудачными, пользователь их просто проигнорирует и найдет нужные ему товары поиском.
В магазине много посетителей, рекомендации нужно подстраивать под каждого - масштаб большой. Шаблон поведения покупателей постоянно меняется - вчера была мода на одно, сегодня на другое, завтра в моду войдет третье.
Хорошие условия для использования машинного обучения - часто повторяющаяся задача, малая цена ошибки, большой масштаб, постоянно меняющиеся шаблоны.
 Когда машинное обучение лучше не использовать?
Когда машинное обучение лучше не использовать?
Например, когда это неэтично. Что такое этично или неэтично, каждый решает для себя сам, но некоторые вещи точно делать не стоит.
Например, мы могли бы сделать модель, которая анализирует социальные сети и подсказывает мошенникам, каких людей проще обмануть и как. Технически это несложно - но, пожалуйста, не делайте этого. Кроме морали есть еще и Уголовный кодекс.
Еще не следует делать ML-систему только ради ML, когда простое правило решает задачу. Таких примеров масса.
Не получится сделать ML-систему, если у вас нет данных для ее обучения и нет готовых моделей.
Следует с осторожностью использовать машинное обучение в ситуациях, когда цена ошибки высока - когда на кону человеческие жизни или сложные технологические агрегаты. Обычно в таких случаях ML выдает рекомендации, но решение принимает специально подготовленный человек или группа людей (например, врачебный консилиум).
Иногда вы вынуждены объяснять каждое принятое решение - и сложные ML модели с их необъяснимой простыми словами логикой тут неудобны. И иногда дешевле нанять человека делать ту работу, которую вы хотите поручить ML-системе.
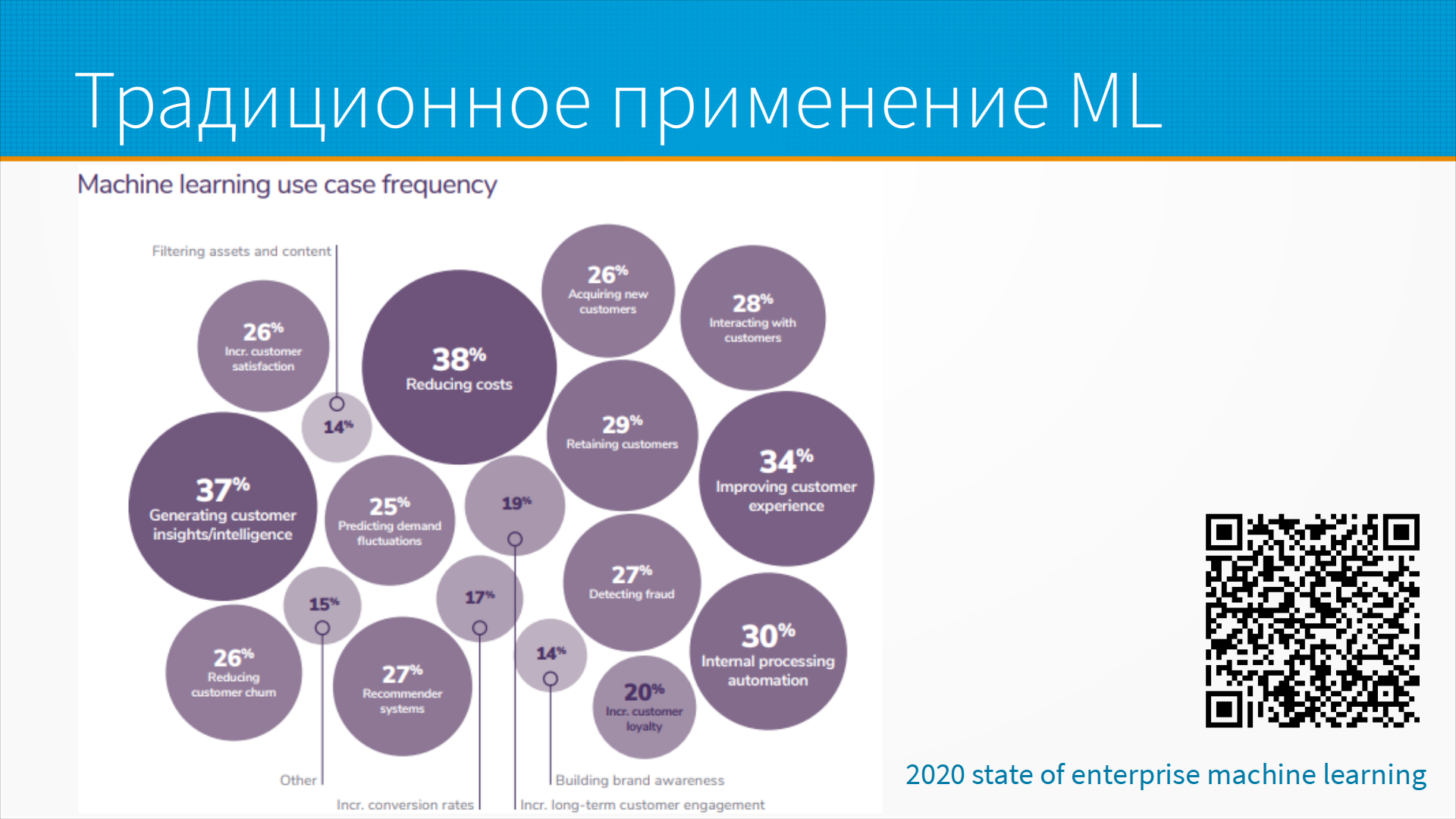 Для чего обычно применяют машинное обучение?
Для чего обычно применяют машинное обучение?
На этом слайде схема из доклада Алгоритмики "The State of Enterprise Machine Learning". Отчет описывает проблемы большого американского бизнеса. Понятно, что у стартапов и бизнеса в других странах проблемы могут быть другие, но как средняя температура по больнице эта схема хороша.
Что мы тут видим: большая часть ML-моделей - про привлечение и удержание клиентов и про снижение затрат на их обслуживание.
 Возможно, вы слышали что-то про пирамиду Маслоу, из которой следует, что, прежде чем говорить с человеком о смысле жизни,
его нужно накормить, дать выспаться и перестать бить по утрам. Вот аналог этой пирамиды - пирамида потребностей в Data Science.
Возможно, вы слышали что-то про пирамиду Маслоу, из которой следует, что, прежде чем говорить с человеком о смысле жизни,
его нужно накормить, дать выспаться и перестать бить по утрам. Вот аналог этой пирамиды - пирамида потребностей в Data Science.
Сначала нам нужно научиться фиксировать данные из наших бизнес-процессов. Поставить датчики. Научиться писать логи. Попросить пользователей написать отзыв о товаре и прочее.
Затем, когда появятся данные - нам нужно научиться их сохранять. Данные будут грязными - учимся чистить, выявлять аномалии, обогащать данными из других источников.
На этом этапе у нас есть возможность считать метрики процессов, делать аналитику, сегментировать пользователей, готовить данные для обучения ML-моделей.
С данными мы можем обучить простые ML-алогоритмы и наладить процесс A/B тестирования.
Имея на руках чистые данные, работающие A/B-тесты и отлаженный процесс постановки и анализа экспериментов, мы наконец-то можем взять с полки нейронную сеть и применить ее.
Стартапы обычно пробуют построить пирамиду с вершины вниз. Большие бизнесы вынуждены делать все по порядку. Ваша ситуация может отличаться - но как схема для обсуждения с бизнес-заказчиком пирамида AI-потребностей очень даже хороша.
Кстати, сейчас считается, что Маслоу был неправ, и потребность в самореализации возникает задолго до того, как все базовые потребности будут закрыты. Многие голодные и угнетенные люди размышляют о вселенной и своем месте в ней, а многие другие, у которых есть и поесть и поспать, только едят и спят. Как говорили еще в моем детстве, все модели неверны, но некоторые из них полезны.
 Еще одна интересная модель - деление всех, кто занимается машинным обучением, на ученых и инженеров.
Еще одна интересная модель - деление всех, кто занимается машинным обучением, на ученых и инженеров.
Ученые не умеют писать код, их код ужасен, невоспроизводим и малоприменим в реальных условиях.
С другой стороны, инженеры не проверяют базовые предположения и часто делают очень вольные допущения, не обосновывают применимость алгоритмов и вообще им лишь бы сделать, чтобы как-то работало.
Автор курса на стороне инженеров.
 Описанные выше различия в подходах исследователей и индустрии объясняется разными требованиями и ограничениями.
Описанные выше различия в подходах исследователей и индустрии объясняется разными требованиями и ограничениями.
В исследованиях вам важнее всего публикабельность.
Вас время от времени пускают посчитать ваши модельки на кластер, поэтому вам нужно, чтобы модель побыстрее училась и могла быстро обработать все ваши данные.
Масштабируемость обычно не важна - редко кому повезет, придя на работу, узнать, что данных стало в 100 раз больше.
Поддерживать код после публикации обычно не нужно, интерпретируемость не очень важна (если вы только не работаете в берлинской лаборатории, специализирующейся на интерпретируемости ML-моделей).
 С индустрией сложнее - у вас может быть пять начальников, у каждого свои требования и представления о том, что такое идеальный результат.
С индустрией сложнее - у вас может быть пять начальников, у каждого свои требования и представления о том, что такое идеальный результат.
Обычно вам нужно выдавать предсказания с как можно меньшей задержкой. Входные данные постоянно меняют свои распределения, меняется форма зависимости целевой переменной от входных признаков, какие-то данные перестают быть доступными, новые данные поступают постоянно.
Вам приходится поддерживать систему годами, и часто вы сознательно выбираете модель попроще и поменьше, чтобы снизить потребление ресурсов и задержку при предсказании. А еще некоторые модели масштабируются хорошо, а некоторые - нет, и это тоже бывает определяющим фактором при выборе модели.
 Этот слайд я украл в стэнфордском курсе, больно уж он хорош.
Этот слайд я украл в стэнфордском курсе, больно уж он хорош.
Пусть у вас есть сайт частных объявлений - какой-нибудь клон Авито, например.
ML-команда хотела бы выжать как можно больше качества из своих моделей. Например, рекомендовать пользователю нужный товар, чтобы он нашел его сразу, просмотрев меньше страниц.
Продажники хотели бы, чтобы пользователь увидел больше рекламы - зарабатываете-то вы на рекламе. И, чем больше страниц просмотрел пользователь, тем им лучше.
Продакт менеджер хотел бы, чтобы страницы сайта грузились побыстрее - а ваша ML-модель тормозит загрузку страниц. Пусть качество будет похуже, зато страницы грузятся быстрее.
Самый главный босс пытается понять, что ему выгоднее - дождаться, пока ML-модель окупится, или сразу уволить ML-команду и сэкономить на разработке. Кстати, так же, как у человека при повреждении мозга первыми отмирают самые сложные функции, при проблемах в конторе первыми увольняют датасаентистов.
 Когда мы говорим о скорости работы моделей, мы обычно имеем в виду скорость предсказаний. Нам нужно, чтобы наша модель
отвечала быстро - иначе ей не будут пользоваться. Например, если интернет-магазин начинает отдавать страницы медленнее,
покупатели уходят на более быстрый сайт, а поисковые системы понижают такой интернет-магазин в выдаче.
Когда мы говорим о скорости работы моделей, мы обычно имеем в виду скорость предсказаний. Нам нужно, чтобы наша модель
отвечала быстро - иначе ей не будут пользоваться. Например, если интернет-магазин начинает отдавать страницы медленнее,
покупатели уходят на более быстрый сайт, а поисковые системы понижают такой интернет-магазин в выдаче.
Дополнительная задержка в 0,1 секунды будет стоить вам потери какого-то процента продаж.
Для приложений реального времени - на конвейере или в автономном транспортном средстве - требования к скорости предсказаний еще жестче. Нам нужны пусть и не самые хорошие предсказания - но вовремя.
В противоположность этому банк, например, может позволить себе дополнительную секунду задержки в обработке платежей. Но этих платежей у него много, и система выявления мошеннических транзакций должна обрабатывать большой поток запросов.
А еще модели часто доучивают на новых данных. Кто-то раз в сутки, а кто-то раз в пятнадцать минут. И хотелось бы, чтобы это тоже было быстро.
Для каждой области применения моделей машинного обучения "быстро" означает что-то свое. Как мы измеряем скорость работы модели?
 Пропускная способность RPS - сколько запросов система способна обработать в секунду.
Пропускная способность RPS - сколько запросов система способна обработать в секунду.
Часто высокой пропускной способности мы можем достичь, обрабатывая данные "пачками", или, как их принято называть, батчами. Скорость инференса нейронных сетей иногда можно увеличить, увеличив размер батча. Но самый очевидный способ увеличить пропускную способность - поставить считать несколько моделей параллельно. Докупив оборудования, мы почти всегда можем увеличить пропускную способность.
 Самый простой способ ускорить ответ ML-модели - предрассчитать предсказания и сохранить их в базу, а потом отдавать готовые.
Так часто делают, например, в рекомендательных системах - для пользователя время от времени насчитываются и сохраняются рекомендации.
Если не получается предсказывать заранее и не получается обрабатывать пачками - приходится ускорять работу модели, уменьшая задержку.
Самый простой способ ускорить ответ ML-модели - предрассчитать предсказания и сохранить их в базу, а потом отдавать готовые.
Так часто делают, например, в рекомендательных системах - для пользователя время от времени насчитываются и сохраняются рекомендации.
Если не получается предсказывать заранее и не получается обрабатывать пачками - приходится ускорять работу модели, уменьшая задержку.
Задержка, или Lаtency - сколько времени занимает обработка одного запроса. Иногда это можно ускорить, купив более быстрое оборудование, но обычно уменьшение задержки требует серьезной переработки модели. Например, квантизации, перехода на вычисления с половинной точностью и так далее. Существуют библиотеки для ускорения работы нейронных сетей - enot, openvine, onnx могут помочь снизить задержку предсказаний.
Разницу между пропускной способностью и задержкой можно проиллюстрировать на таком простом примере. Пусть у нас есть модель, способная обработать 300 запросов в секунду, задержка 0,3 секунды. Предположим, что мы смогли собрать все запросы пользователя в пачки по 100 запросов и обработали их в три приема - это заняло секунду. Или мы не смогли собрать эти запросы в пачку - например, потому что пользователь отправляет запрос только после того, как получит ответ на предыдущий запрос. И тогда обработка 300 запросов займет 90 секунд.
 Что еще нужно учитывать при разработке ML-систем: данные меняются. Меняется распределение входных данных (сдвиг признаков). Меняется
поведение выходных данных (сдвиг целевой переменной). Меняется также зависимость целевой переменной от признаков, на которых мы ее
предсказываем - и качество нашей модели может ухудшиться или улучшиться неожиданно для нас. Для отслеживания сдвига данных есть
хорошие инструменты - например, Evidently AI, мы обсудим его в девятой лекции.
Что еще нужно учитывать при разработке ML-систем: данные меняются. Меняется распределение входных данных (сдвиг признаков). Меняется
поведение выходных данных (сдвиг целевой переменной). Меняется также зависимость целевой переменной от признаков, на которых мы ее
предсказываем - и качество нашей модели может ухудшиться или улучшиться неожиданно для нас. Для отслеживания сдвига данных есть
хорошие инструменты - например, Evidently AI, мы обсудим его в девятой лекции.
 Данные меняются потому, что меняется наш мир. Например, до ковида маски носили в основном медработники, и, видя человека в маске, вы
могли предположить, что он врач. Сейчас он может оказаться почтальоном или безработным - маска ничего не говорит нам о его профессии.
Данные меняются потому, что меняется наш мир. Например, до ковида маски носили в основном медработники, и, видя человека в маске, вы
могли предположить, что он врач. Сейчас он может оказаться почтальоном или безработным - маска ничего не говорит нам о его профессии.
Индустрия все время живет со сдвигом данных. Исследователям не хватало наборов данных с документированным сдвигом, но сейчас они начали появляться: (Shift, WILDS, MMSCI). И я думаю, что в работе со сдвигом данных в ближайшее время произойдет прорыв. А пока надо аккуратно мониторить распределения признаков.
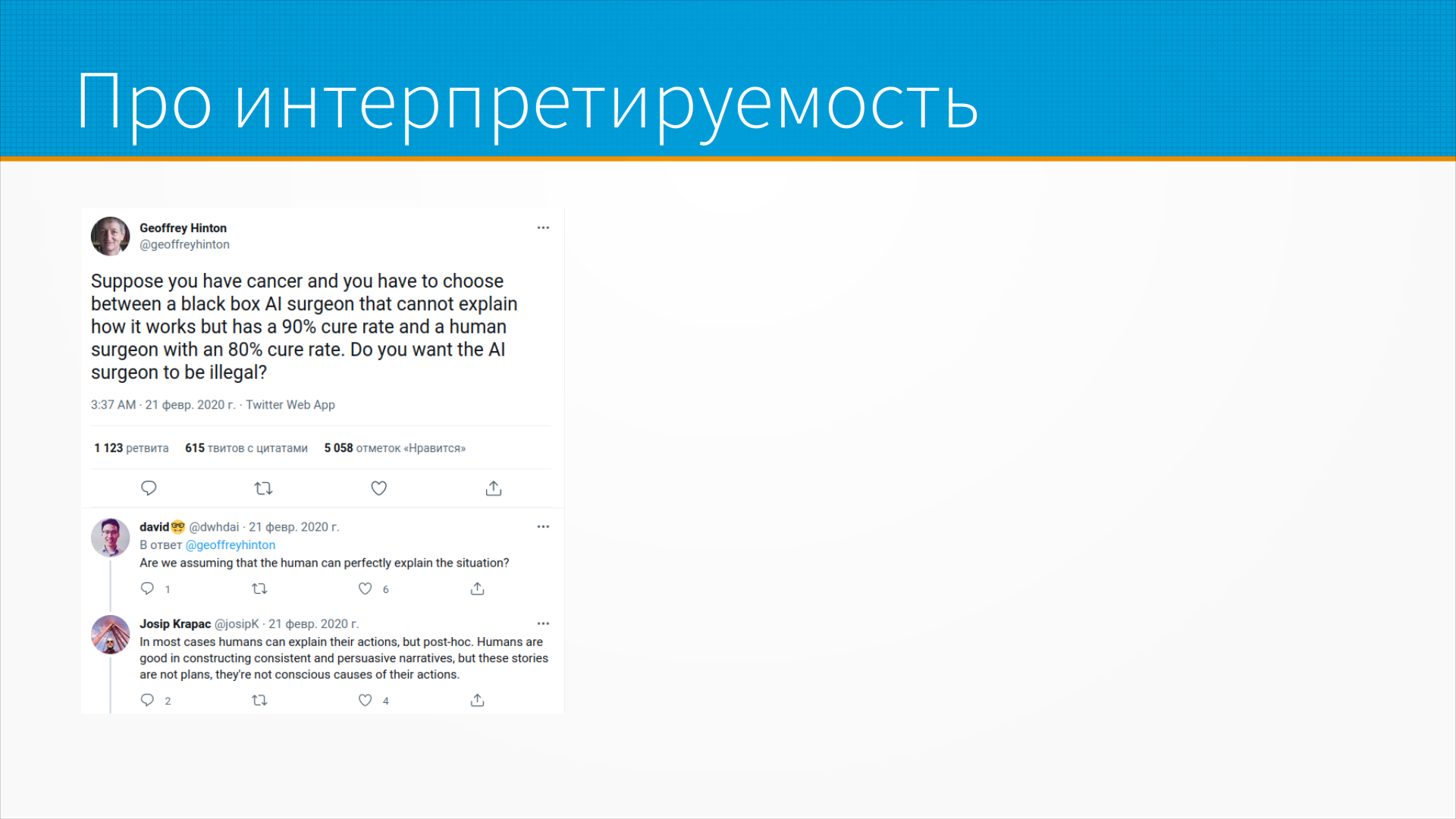 Отдельная интересная проблема - интерпретируемость моделей машинного обучения.
Отдельная интересная проблема - интерпретируемость моделей машинного обучения.
Последние несколько лет регуляторы разных стран пытаются добиться интерпретируемости ML-алгоритмов. Чаще всего это требуют от контентных рекомендательных систем, систем контентной фильтрации и систем кадрового скоринга.
Контентные рекомендательные системы подбирают для вас залипательные видео и интересные новости. Системы фильтрации решают, кто из нас должен быть забанен. Кадровый скоринг помогает принять решение - кого принять на работу, а кого уволить.
Часто интерпретируемость противопоставляют качеству - то есть, что вы выберете: интерпретируемую некачественную модель или качественную неинтерпретируемую? На мой взгляд, противоречие это искусственное. Можно добиться интерпретируемости, не теряя качества. Мы об этом целую секцию на датафесте организовывали.
На слайде - скриншот твита Джеффри Хинтона, где он задает провокационный вопрос - что вы выберете: неинтерпретируемого робота-хирурга с вероятностью ошибки 10% или интерпретируемого человека-хирурга с вероятностью ошибки 20%? В комментариях ему подсказывают, что люди обычно придумывают объяснения своим действиям задним числом, и сами в них верят - так что противопоставление это искусственное.
 О чем еще хочется сказать: как добавление машинного обучения в проект меняет разработку программного обеспечения.
О чем еще хочется сказать: как добавление машинного обучения в проект меняет разработку программного обеспечения.
ML-проект - это просто проект по разработке программного обеспечения, но есть нюанс. Или даже три: нюанс с данными, нюанс с управлением проектом и нюанс с мониторингом.
 Что касается данных.
Что касается данных.
ML-модель напоминает кентавра - это наполовину программный код, наполовину данные. Изменятся данные - ML модель начнет работать плохо или совсем перестанет.
Мы храним наш код в системе контроля версий, но данные мы обычно версионировать не можем. Есть, конечно, системы, версионирующие слепки данных и привязывающие версии данных к версии использующего их кода, например DVC. Но в случае любых практически значимых объемов свежих данных версионировать их будет технически очень трудно. Обычно версионируют схемы данных, например в форме дата-контрактов. Эта область сейчас бурно развивается, но пока там все плохо.
Данные обычно необозримы. Если у нас после изменения кода возникла ошибка, мы можем посмотреть в истории коммитов, что изменилось, и искать ошибку в этом месте. С данными все сложнее. Существуют инструменты для сравнения слепков данных, мониторинга распределений и прочее, но искать изменения в данных гораздо сложнее, чем в коде. К тому же, данных обычно больше, чем кода, намного больше.
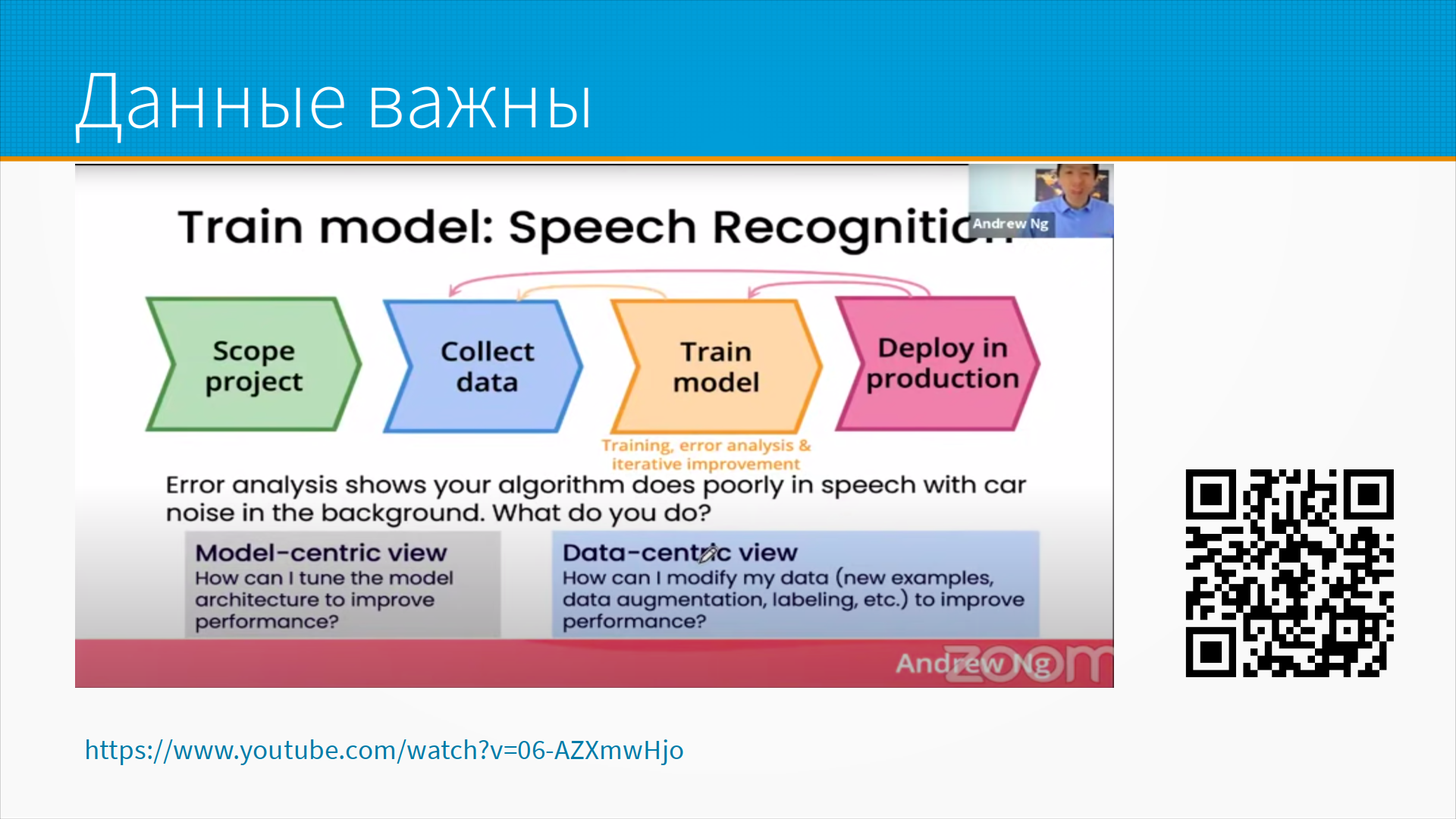 Andrew Ng, исследователь, предприниматель и преподаватель в своей лекции-манифесте предложил термины Model-Centric подход - когда мы стараемся улучшить качество модели, подбирая оптимальную архитектуру модели; и Data-Centric подход - когда мы пытаемся что-то сделать с данными, чтобы наша существующая модель заработала лучше. Собираем новые данные - например, проверяя разметку, обогащая (аугментируя) данные (например, добавляя обрезанные и повернутые копии изображений в датасет при обучении).
Andrew Ng, исследователь, предприниматель и преподаватель в своей лекции-манифесте предложил термины Model-Centric подход - когда мы стараемся улучшить качество модели, подбирая оптимальную архитектуру модели; и Data-Centric подход - когда мы пытаемся что-то сделать с данными, чтобы наша существующая модель заработала лучше. Собираем новые данные - например, проверяя разметку, обогащая (аугментируя) данные (например, добавляя обрезанные и повернутые копии изображений в датасет при обучении).
 По его опыту, который совпадает с моим, Data-Centric подход обычно продуктивнее.
По его опыту, который совпадает с моим, Data-Centric подход обычно продуктивнее.
На слайде - данные по двум проектам: выявление дефектов в стальном прокате и, кажется, в солнечных панелях. За несколько месяцев работы подход, ориентированный на модели, дал околонулевой прирост, тогда как подход, ориентированный на данные, помог улучшить результаты.
Это, конечно, достоверность на уровне анекдота, т.е. цифры чисто для иллюстрации. Если модель сделана как попало, ее не спасут хорошие данные. Но если вы уткнулись в плато по качеству модели, идите разбираться с данными - скорее всего, проблема там.
 Что касается управления проектами: в ML-проектах трудно управлять качеством.
Что касается управления проектами: в ML-проектах трудно управлять качеством.
Вы не знаете заранее, какого качества можно достичь. И, даже если у вас есть разумные оценки качества, заказчик наверняка будет проверять модель на новых данных, где распределения изменятся.
По этой же причине трудно управлять сроками - зачастую на старте проекта мы не знаем, какого качества можем достичь и узнаем об ограничениях моделей и данных только где-то в середине проекта. Все это напоминает погоню за постоянно перемещающейся целью.
Для небольших ML-проектов хорошо подходит двухфазная модель. Первая фаза - discovery - ограничена по времени. Например, выделим месяц на эксперименты. Как только месяц кончился - по результатам этих экспериментов запускаем обычный проект по разработке программного обеспечения.
У больших проектов своя логика, но упрощенно можно сказать, что в большом проекте эти фазы нужно повторять итеративно. Есть сообщество LeanDS, в котором собирают хорошие практики управления проектами в области анализа данных и машинного обучения, за подробностями лучше к ним.
 Отдельная проблема ML-систем - мониторинг.
Отдельная проблема ML-систем - мониторинг.
Система в целом может выглядеть совершенно работоспособной - на вход поступают данные, на выход прилетает решение модели, все задержки в норме, все хорошо с пропускной способностью, только вот модель выдает чушь.
Как мы будем ловить эти ситуации? Если модель переобучается автоматически раз в сутки или раз в пятнадцать минут, как мы отследим, что конкретно вот эта версия модели обучилась корректно?
Модель может несколько дней или недель выдавать чушь - и без мониторинга этого никто не заметит. Особенно опасны ситуации, когда мы не можем мгновенно оценить качество работы модели.
Например, эффект от инвестиций можно заметить через несколько лет, а о невозвращенном кредите мы узнаем через три месяца. Хорошо бы как-то узнавать о сломанной модели, пока мы не навыдавали кучу плохих кредитов.
 Вот как бы правила. У них куча исключений, конечно, но для грубой оценки они вполне подходят.
Вот как бы правила. У них куча исключений, конечно, но для грубой оценки они вполне подходят.
При внедрении модели мы обычно рассчитываем на какой-то эффект. Ускорение работы, снижение затрат и прочее. Примерно половины этого эффекта можно добиться без машинного обучения - простыми правилами. Фильтрацией по списку слов, например, регулярными выражениями, фильтрацией по порогу какого-то значения и т.д.
Часто встречающаяся идея: люди не видят тут закономерности - а давайте заставим компьютер эту закономерность найти. Обычно, если подготовленный эксперт предметной области не может различить по фото бракованную и нормальную детали, машинное обучение тоже не сможет. И, если вы раcсчитываете получить качество модели, превосходящее человеческое, вам надо откуда-то взять разметку. Наверное, размеченную сверхчеловеком.
На самом деле варианты есть - можно собрать группу экспертов, и тогда качество разметки, сделанное группой экспертов, будет лучше, чем у одного эксперта, и так далее - но все это сильно усложняет работу.
Большинство проблем ML-систем - не с алгоритмами, а на границах системы. Либо вам дали на вход что-то не то. Либо от вас ждут чего-то не того. Либо нужные данные недоступны в момент, когда нужно сделать предсказание. Либо предсказание, сделанное вашей системой, невозможно использовать в тот момент и там, где вы его выдали.
Хороший пример - предсказание оттока. Не очень трудно предсказать, кто из пользователей перестанет пользоваться вашим сервисом. Трудно что-то разумное с этим сделать.
Основные затраты при разработке ML-систем - получение, разметка, обработка, хранение данных. На этапе разработки лидирует стоимость разметки, часто она - главное ограничение на пути к качественной модели.
Ну и всегда надо помнить, что если ваша метрика непонятна бизнесу - это вызовет проблемы. Универсальная понятная для бизнеса метрика - сэкономленные/заработанные деньги, но ее очень трудно считать.
 Есть еще проблемы - мир меняется, модели нужно переобучать на новых данных, это часто нужно делать быстро,
нужно хранить и переключаться между разными версиями модели.
Есть еще проблемы - мир меняется, модели нужно переобучать на новых данных, это часто нужно делать быстро,
нужно хранить и переключаться между разными версиями модели.
Кроме того, модели размножаются как кролики - вы добавили в продукт одну ML-модель, и, если она хорошо работает - добавите еще. Так у вас будет целый зоопарк из моделей и версий, и придется управлять тем, как они живут вместе.
Кроме того, в данных могут быть закладки, в данных будут ошибки, и это бесконечная история.
 Все, о чем мы говорили выше, беспокоит разработчиков в индустрии и не очень беспокоит исследователей.
Все, о чем мы говорили выше, беспокоит разработчиков в индустрии и не очень беспокоит исследователей.
При этом хороший программист может быстро освоить ML-библиотеки, а вот научить ученого писать нормальный промышленный код может быть очень трудно. Но это все неважно, потому что без девопса ни те, ни другие ничего полезного не сделают.
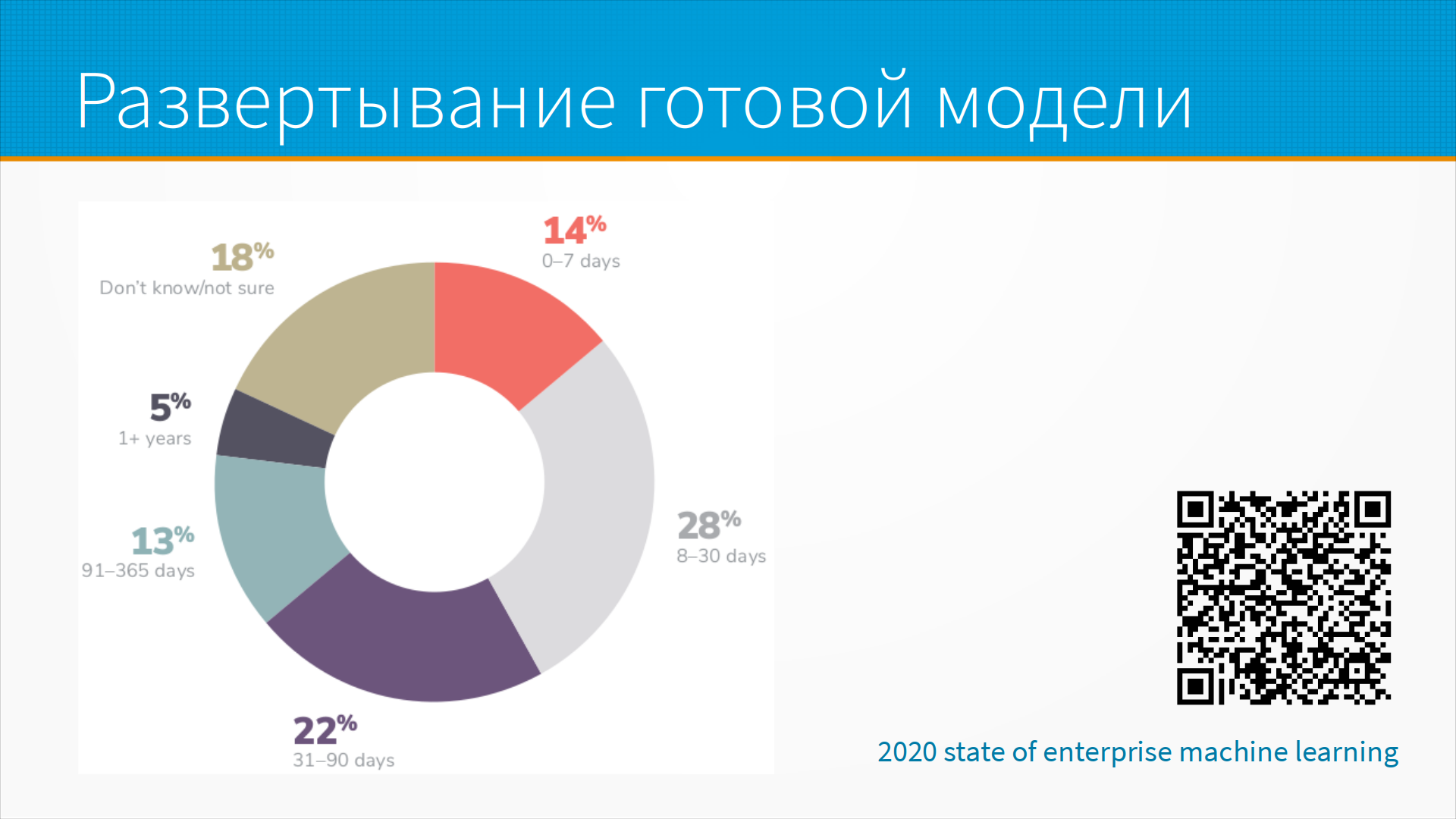 В упоминавшемся выше исследовании Алоритмики есть статистика - сколько времени проходит от момента, когда модель готова, до момента, когда
она развернута в продуктовой среде.
В упоминавшемся выше исследовании Алоритмики есть статистика - сколько времени проходит от момента, когда модель готова, до момента, когда
она развернута в продуктовой среде.
Большая часть моделей в 2022 году больше месяца ждала своего выхода на сцену, и примерно каждой третьей модели на развертывание понадобилось больше трех месяцев. И это уже готовые модели.
Поэтому либо имейте в команде девопсов, либо сами изучайте MLOPs, иначе будете по году тащить модель до прода.
 Дополнительные материалы к лекции:
Дополнительные материалы к лекции: