
- 03.02.2022
- 08.10.2025
- выступления
- #management
Лекция в рамках Зимней школы Comptech @ 2022.
Слайды можно скачать тут slides_nsu_ml_bussiness.pdf
Текстовая расшифровка, пока не очень вычитана:

Дмитрий Колодезев: Наверное, все, пока никого нет, собственно, можно рассказать, кто я такой. Меня зовут Дмитрий Колодезев, я работаю, действительно, в «Промсофте», анализирую данные, я консультирую и учу. Еще я собираю дата-завтраки по вторникам, и еще я участвую в работе OpenDataScienceLab, это место, где студенты и научные сотрудники, аспиранты могут работать над какими-нибудь проектами за пределами их образовательной и учебной деятельности.

Про что я хочу сегодня рассказать? Во-первых, про то, что такое, собственно, машинное обучение, как его понимаю, полезный способ думать про машинное обучение. Второе, чем промышленное машинное обучение отличается от Kaggle. Там есть важное отличие, и о нем надо немножко по-другому думать. Чем ML-разработка отличается от обычной разработки, потому что все чаще приходят к выводу, что ML – это не какой-нибудь особый вид животных, а просто та же самая разработка программного обеспечения, только со своим библиотеками. Но вот нет. Есть свои важные отличия, я про них расскажу.

Поговорим о том, что нужно делать перед тем, как начать разработку ML-проекта. Я расскажу, почему важно всегда делать базовую модель, которая берет ваши данные и делает итоговый predict. Поговорим про данные, про бухгалтерию, этику и здравый смысл. Собственно, можно, наверное, начать.

У нас есть национальный проект национального стандарта в России на искусственный интеллект, и там написано буквально следующее, что искусственный интеллект – это нечто, обладающее способностью приобретать, обрабатывать, создавать применять знания в определенной форме модели для выполнения одной или нескольких поставленных задач. Что интересно, под эту формулировку попадает, например, любой студент или код, или калькулятор. Эта формулировка не говорит просто ничего, она бесполезна для практики, но, в общем, красиво выглядит.

Разные люди в разное время пытались определить, что же такое машинное обучение, например. Andrew Ng, который очень много сделал для популяризации машинного обучения, говорил, что машинное обучение – это наука о том, как заставить компьютеры действовать без того, чтобы явно задавать им программу действий.
Андрей Карпатый, если кто не знает, он глава AI в Tesla, называл машинное обучение программным обеспечением 2.0, это когда код вместо человека пишет оптимизационный алгоритм, основываясь на некоторых критериях.
Для меня машинное обучение – это все-таки автоматизированное построение удобной проекции признакового пространства. Но это все какие-то такие оторванные от жизни слова. Мне нравится определение машинного обучения в Стэнфордском курсе Computer Science 329: машинное обучение – это автоматизированный подход к выявлению сложных шаблонов в имеющихся данных и использование этих шаблонов для предсказания о новых данных. Тут важны выделенные цветом слова. Во-первых, мы можем выявить шаблоны. Не всегда шаблоны мы можем выявить. Например, очень многие люди пытались предсказывать генераторы случайных чисел. Иногда это даже работает, тогда, когда эти генераторы чисел не случайны, то есть если в них есть шаблон. У нас изначально есть предположение, что в том наборе данных, который мы исследуем, моделируем, там есть шаблоны, и мы примерно предполагаем, какие.

Дальше, шаблоны эти сложные. Мы предполагаем, что простым каким-нибудь решающим правилом, например, выдаем кредит всем, у кого есть, допустим, обеспечение больше, скажем, миллиона рублей, не выдаем кредит тем, у кого меньше. Если это простое решающее правило не позволяет нам принять хорошее решение, наверное, время для машинного обучения.
Потом, данные имеются. Очень много раз я видел в жизни ситуацию, когда люди приходят и говорит: «Нам нужно обучить ML-модель». Я говорю: «Данные есть?» «Да, данные есть. Вы сделаете ML-модель, а данные мы соберем».
Так не работает, сначала нам нужны данные, а потом уже нам нужна ML-модель.
Еще очень сильное предположение, что мы можем предсказывать из имеющихся данных новое поведение. Пример, например, погода. Есть теоретический результат, который говорит, что сколько бы у тебя данных ни было, дальше определенного горизонта хорошо погоду ты не предскажешь.
Мы будем использовать предсказание этих шаблонов, и использовать эти шаблоны для предсказания на новых данных. Важно, что новые данные у нас будут в тот момент, когда нам понадобится предсказание. Это неочевидный момент. Очень часто, когда строят ML-модели, используют какие-нибудь агрегаты. Например, среднее значение какой-нибудь метрики за месяц или что-нибудь еще. Проблема всех этих вещей в том, что когда вы будете делать предсказание, этих данных у вас не будет. Или некоторые данные, например, о пользователях поступают в систему с задержкой в несколько часов, а вам нужно принять решение о пользователе прямо сейчас.
У нас, например, есть такая ситуация, что мы в одной из систем Sales Prioritization получаем данные буквально на несколько секунд позже, чем пользователь их ввел, но пользователь ожидает, что рекомендация поступит сразу же. Это проблема, потому что к тому моменту, когда приходит запрос в нашу ML-модель, данных там еще нет. С этим отдельно приходится справляться, об этом нужно думать.
Тут вопрос мне прислали в Telegram, не полагаясь на ведущего: «А разве нельзя сказать, что машинное обучение – это способность алгоритм извлекать общие правила из конкретных примеров, обобщения?» Сказать, наверное, можно. Сказать можно, но обязательно ли это машинное обучение? Хитрость тут какая? В первоначальных формулировках машинного обучения, которые давали до последнего его взрыва, там обсуждался вопрос, что машинное обучение – это когда чем больше данных, тем больше оно учится. В вашей формулировке вопрос собственно самого обучения немножко размазан. У вас машинное обучение – это способность. Я потом с вами лично подискутирую, но мне кажется, что это неполная формулировка.

Ну так вот, про машинное обучение. На этом слайде все про него рассказано, если кратко. Машинное обучение ищет шаблоны в данных, и в соответствии с этими шаблонами делает предсказания. Соответственно, если в данных все прыгали с крыши, то и машинное обучение с крыши прыгнет, вы никуда от этого не денетесь. Опять же, я повторюсь, что я говорю о машинном обучении в бизнесе. В науке, в соревнованиях все может быть по-другому. В бизнесе машинное обучение – это вот так.

Затем, машинное обучение – это почти всегда про экономию, то есть не про совершенство, не про скорость, не про выявление каких-то сложных вещей, которые не видны глазу, а просто про то, чтобы тратить меньше денег на принятие решений. Мы быстро принимаем не очень важное решение среднего качества дорого и неконтролируемо. Из этого, собственно, проистекает область применения. Например, когда люди используют машинное обучение, чтобы остановить конвейер, который печатает этикетки, это хорошее применение, потому что тут не очень важное решение среднего качества, его надо быстро принять. А если же вы, допустим, используете машинное обучение для, например, принятия судебных решений, это спорная вещь, потому что это важное решение, хотелось бы чтобы оно было качественное, последствия его велики. В общем, машинное обучение – это про экономию. Это не про качество, не про магию, это про экономию денег и времени.

Машинное обучение – это про «просто, быстро и много». Люди медленные, ML-алгоритмы быстрые. Тупые, но быстрые. С людьми дешево начать проект. Вы можете взять человека, на пальцах ему объяснить, что от него требуется, он начнет как-то работать. С ML-алгоритмами начать обычно дорого. Люди, однако же, не масштабируются. Если вам внезапно понадобилось в 10 раз больше делать предсказаний человеком, вам этого человека придется учить.
ML-алгоритм можно раскатать на еще 10 серверов, он будет работать. Люди, однако же, адаптируются, причем, адаптируются сами, даже если вы их специально этому не учите. ML-алгоритмы не адаптируются, если вы об этом не позаботились.
У людей достаточно разные, неровные качества. Они обычно работают очень хорошо, то есть принимают решения лучше, чем ML-алгоритмы, в большинстве сфер, но иногда человек бывает не выспавшийся, расстроенный, невнимательный, временно заменили кем-то, и качество проседает. У ML-алгоритмов качество среднее, то есть обычно ML-алгоритмы дают более ровное качество, чем люди.
Одна из вещей, которая определяет то, почему, собственно говоря, машинное обучение так бурно растет, это то, что оно проходит по другой статье в бухгалтерии. Затраты на людей идут по статье «издержки», затраты на ML-алгоритмы идут как капитальные вложения. Поэтому если вы, допустим, закопали миллион рублей в ML-алгоритмы, вы вырастили капитал предприятия. Если вы закопали миллион рублей в людей, вы просто закопали миллион рублей. В тех местах, где предприятие торгуется на бирже, это имеет очень большое значение.
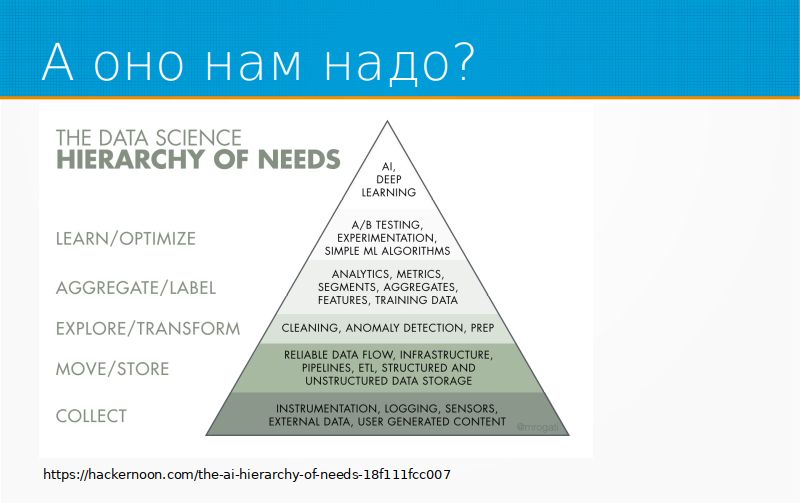
Про то, как машинное обучение внедряется в предприятия. Хорошая диаграмма, иерархия потребностей в искусственном интеллекте. Она как раз описывает главные этапы, через которые проходит бизнес, прежде чем у него появляются интересные модельки Machine Learning. Сначала, прежде чем данные анализировать, их надо собирать, потом их надо научиться складывать, обрабатывать, и только после того, как мы их научились собирать, складывать и обрабатывать, мы можем делать в них что-нибудь очень простое, например, детекцию аномалий. Мы внедрили детекцию аномалий, можно внедрять какие-нибудь метрик, аналитику, можно А/В-тестирование, можно внедрять простые ML-алгоритмы. И только после того, как все это счастье у нас уже есть, имеет смысл доставать модели машинного обучения и делать что-то сложное. Иначе вы будете пытаться решить проблему, которой еще нет.

Широко распространено мнение, что машинное обучение в промышленности как бы отличается, но чем именно... Вот чем именно. Главная цель, на кадре ваша цель – это получить наибольшее качество на отложенной выборке, которую вы, причем, не видите. В бизнесе ваша цель – это не качество на отложенной выборке. Качество может никого не интересовать, оно попадает в отчеты, им хвастаются, его используют как аргумент в спорах. На самом деле, в бизнесе ваша задача – решить проблему заинтересованных лиц имеющимися силами в срок в рамках имеющегося бюджета и в условиях конфликта интересов.

Какие вопросы нужно себе задать? А можем ли мы в принципе улучшить текущий результат? Есть человек на сортировке, например, заявок. Будет ли ML сортировать их лучше? Скорее всего, оно будет сортировать их хуже. Оправдано ли это экономически? Может быть оправдано, а может быть, и нет. Например, если у нас сидят три оператора на сортировке заявок, и мы ускорим их обработку с помощью ML, допустим, на 25%, все равно у нас останется три оператора. Мы не сможем уволить ни одного оператора. ML мы внедрим, а количество операторов у нас останется тем же самым, то есть денег никаких не будет.
Другое дело, что если у нас есть, допустим, дневная смена, восемь человек, и ML позволит нам обрабатывать заявки круглосуточно, и это избавит нас от того, чтобы нанимать людей в ночную смену, вот тут ML экономически оправдан. Так обычно работают чат-боты. Чат-боты снимают нагрузку с операторов в такие часы ночью, допустим, вечером, в час пик, тут они прям сразу дают отчет.
Является ли это узким местом? В принципе, в бизнесе то, что вы хотите ему оптимизировать, проэмэлить, может вообще не являться узким местом. Мы можем делать удивительные модели, удивительные предсказания, но конкретно у этого бизнеса, например, ему это неинтересно.
Хорошо запомнил ситуацию, когда мы продавали мониторинг посевов по космоснимкам в сельском хозяйстве. Ребята говорят: «Это здорово, это хорошо, а зачем нам это?» Я говорю: «Как же, вы же за два месяца до того, как у вас будет неурожай, сможете об этом узнать, может быть, что-то предпринять». Они говорят: «У нас нет никаких возможностей что-то предпринять, если мы узнаем, что через два месяца у нас будет неурожай, мы просто на два месяца раньше расстроимся». И они, на самом деле, были правы.
Является ли узким местом то, что вы собираетесь оптимизировать, будет ли доступны данные вовремя? Очень часто данные, которые вам дают обучающие данные, в реальности поступают в систему с большой задержкой. Еще часто мы не можем использовать предсказание. ML-модель сделала предсказание, типа, например, мы построили модель оттока, и такая ML-модель говорит: «Здорово, смотрите, вот я считаю, что этот пользователь, скорее всего, уйдет от нас». Что вы с этим сделаете, то есть как вы в принципе поступите? Очень многие бизнесы ничего не могут сделать, то есть они просто могут вовремя расстроиться, и все.
Еще важный момент, что внедрение машинного обучения всегда – это проект по изменению бизнес-процессов. Какие-то вещи делали люди, или какие-то вещи делали простые механизмы, а вы внедряете сюда машинное обучение, вы меняете процессы. Любое управление изменениями не работает без поддержки со стороны высшего руководства. Образно говоря, без пиджаков никакое управление изменениями не работает. Если вас не поддерживает генеральный директор, если вас не поддерживает финансовый директор, если вас не поддерживает директор по производству, никакой процесс вы изменить не сможете, скорее всего, и машинное обучение вы тоже не сможете внедрить. Эти факторы вообще лежат за пределами математики, данных, машинного обучения.

Когда я говорил про конфликт интересов, вот хороший слайд. В принципе, может быть, для какого-то из менеджеров, который владеет этим процессом, самый простой способ максимизировать прибыль – это просто уволить ML-команду и получить премию. Такое тоже может. Допустим, сисопы, то есть люди, занимающиеся непосредственно поддержкой системы на проде, они не любят эмэльщиков просто потому, что те в их быструю систему, которая может обрабатывать десятки тысяч, сотни тысяч запросов в секунду, приносят что-то тормозное, которое отвечает через полсекунды, например. Ваша ML-модель с высокой производительностью может противоречить интересам тех людей, для которых вы работаете.

Иногда бывают другие примеры. У некоторых организаций просто стоит галочка, им нужно поставить галочку, что они внедрили машинное обучение. Особенно это зарубежные заказчики таким знамениты, и у нас отечественные, по-моему, тоже могут. «Пусть оно работает так же, как человек, но зато все наши инвесторы знают, что у нас прошла AI-трансформация».

В принципе, разработка ML-проектов очень похожа на просто разработку программного обеспечения. Человек приходит делать Data Science и обнаруживает в себе Python-разработчика. В принципе, это действительно просто разработка со специальными библиотеками, кроме трех небольших особенностей.
Во-первых, это разработка, жестко завязанная на данные, поскольку мы ищем шаблоны в данных. Во- вторых для этой разработки нужно немножко модифицировать управление проектами. В-третьих, в этой разработке еще важнее, чем в обычной разработке, мониторить то, что у вас происходит.

Про данные. Вся инженерия программного обеспечения строилась вокруг того факта, что некоторые вещи должны быть вместе, некоторые вещи должен быть раздельно, это про сцепление вещей, что вот это мы инкапсулируем, прячем зависимости, и так далее, и тому подобное, объектно-ориентированное программирование вокруг этого построено и так далее. А тут у нас есть ML, и модель жестко сцеплена с данными. Модель – это у вас не просто код, а она бесполезна без тех данных, которые в нее поступают.
И тут возникает проблема. Данные обычно не версионируются. Часто версионируют схемы данных. Например, это у нас схема данных номер 1, это схема данных номер 2, но сами данные, которые льются по этой схеме, обычно не версионируются. Есть, конечно, системы версионирования данных, например, DVC, но в жизни обычно данных много, и их негде хранить, или нельзя хранить, или еще что-нибудь. Каждый день, допустим, генерируется достаточное количество данных, и вы все время работаете с данными из потока.
Данные обычно необозримы. Например, у нас в проекте может быть миллион строк кода. У нас есть проекты, в которых 2 миллиона строк кода. Но все равно, ты можешь сесть, и хорошая поддержка инструментов, каждую строчку кода посмотреть, сказать: «Да, вот это написано плохо, вот это бы хорошо переписать, вот это мы отрефакторим, вот здесь ты прямо красиво сделал, это запутанно, прокомментируй, пожалуйста». Принята практика code review. Но данных обычно больше строк, чем кода, и никаких инструментов для того, чтобы просматривать каждую строчку данных, нет. Обычно нет самой культуры, что пришли новые данные, все их просмотрели, часто это просто невозможно. Даже просто DIF, то есть что изменилось у нас в данных, это уже нетривиальная задача.
Всякая модель, которую мы построили, она строится на каких-то предположениях о данных. Например, в этой колонке нет пропусков, или в этой колонке данные взяты из вот этого списка, из этого перечисления. Или, например, данные в этой колонке всегда больше, чем сумма вот этих данных. Для того, чтобы наша модель работала нормально, нам нужно предположение о данных проверять. Но это трудно, потому что, на самом-то деле, зачастую, когда построили модель, нам трудно отследить, на какие именно предположения мы заложились.
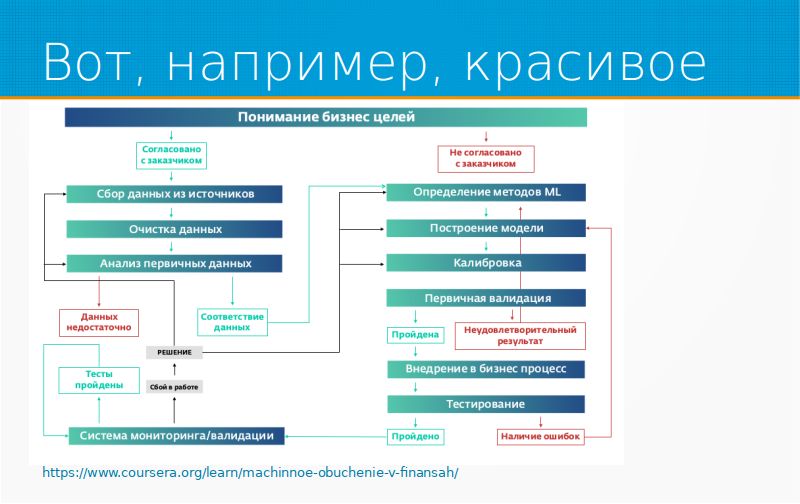
У «Сбербанка» есть хороший курс «Машинное обучение в финансах», и там они разбирают подход, который принят у них. Все начинается с понимания бизнес-целей, то есть что, собственно, мы хотим достичь. После того, как мы договорились, мы заботимся о данных, есть ли у нас данные. Потом мы пытаемся понять, как мы будем учить, валидируемся, внедряем, мониторим, и если что-нибудь не то с мониторингом, мы снова собираем данные и так далее. Это как раз вот эти главные блоки, особенности управления, особенности сбора данных и мониторинг.

Данные очень важны. Например, есть такое программное видео Andrew Ng, он давал вебинар на тему Data-centric AI, и там он разбирал ситуацию. например, у вас есть проблема с вашим алгоритмом распознавания команд внутри машины, он не слышит, что сказал пользователь, и что вы будете делать? Либо вы будете улучшать модель, либо вы будете больше собирать данных. Как-то очистить данные, улучшить данные, найти и выкинуть выбросы, аугментировать их как-то лучше. Он утверждал, что на основании его опыта, который гораздо больше моего, Data-centric-подходы всегда побеждают Model-centric. Грубо говоря, если у вас осталось два месяца, а проект все еще не взлетел, потратьте их на данные, а не на модель. Я немножко утрирую, но, в общем, ссылка на слайдах есть, можно посмотреть.

Он приводит примеры из двух своих проектов. В одном они детектировали дефекты в стали, это похоже на конкурс, который у нас проходил в «Северстали» по дефектам на стальных листах. Во втором они искали, по-моему, брак в солнечных батареях. Когда они пытались улучшать baseline, допиливая модель, они не получили практически никаких результатов. Потом они бросили, пошли чистить данные, и тут у них все и заработало.
Это совпадает с моим опытом, который, в общем, гораздо скромнее. Так что можно, утрируя, сказать, что данные важнее модели. С хорошими данными почти любая модель заведется и будет работать хорошо, с плохими данными никакая модель работать не будет.

Что касается управления проектом, чем отличается управление проектом по разработке программного обеспечения от проекта по созданию ML-продукта какого-то, ML-сервиса? Прежде всего, тем, что там есть очень большая неопределенность, что же мы такое строим, возможно ли оно. Поэтому один из работающих подходов – это делить проект на две фазы: фаза Discovery и фаза Delivery. Discovery – это ограниченная по времени активность типа «давайте мы поиграем в песочнице, вот у вас есть месяц, и целый месяц мы пробуем эксперименты, строим модельки, рисуем ноутбучики, пытаемся понять, что возможно, какие есть проблемы, какие есть решения и так далее». У вас в плане проекта вот так и написано, типа «месяц, играем». Через месяц мы выявляем, если нам повезло, проблемы убеждаемся, что все доступно, что данные как таковые есть, что, в принципе, подходы, возможно, работают, и тогда можно идти тем же самым способом, как устроена обычная разработка программного обеспечения, то есть со спринтами, короткие спринты по неделе-две, выбрали список задач, сделали, посмотрели, что получилось. С маленькой особенностью. Если кто-то разрабатывал программное обеспечение, представьте себе, что у вас каждую неделю меняется схема баз данных, и раз в полгода вы меняете движок анных, мигрируете с MySQL, допустим, на SQL-сервер, потом с SQL-сервера мигрируете на Postgres, и так по кругу. У вас все время проблемы с данными. Но в остальном примерно такое же управление проектами, как и в любом другом программном обеспечении.

Про мониторинг. Модели машинного обучения – это как бы роботы, которые принимают решения. Они могут принимать решения неправильно, а мы никак об этом не узнаем. Они могут внезапно перестать принимать хорошие решения. Например, вчера оно работало, а сегодня плохо. Они могут вообще принимать средние решения, и не факт, что мы можем это проверить. Например, мы выдаем кредиты, а вернут их или нет, мы узнаем только через год или через полгода, смотря, на сколько вы даете. Я слышал от разных людей истории про то, как у них ломалась модель, и она выдавала случайные результаты, и кто-то заметил это через день, а кто-то через несколько месяцев.
Мониторинг очень важен, и тут, наверное, вместо того, чтобы рассказывать про это, я ссылку на Evidently AI добавлю, там хороший опенсорсный продукт для мониторинга моделей и очень-очень много статей с рассказами, почему это важно, и какие обычно ошибки случаются на этом пути.

Как я думаю, что надо подходить к разработке ML-проектов? Понятно, что все начинается с продуктовых гипотез, и мы предполагаем, что если мы, например, построим систему, которая предсказывает следующий переход на странице пользователя, то мы сможем как-то улучшить продажи в нашем Интернет-магазине. Тут хорошо бы эту модель провалидировать, потому что самый хороший вопрос – это «и что?». Вы приходите и говорите: «Я могу предсказать, какой будет следующий переход пользователя на сайте». Вам говорят: «И что?» «Ну, как? Вы же можете знать, какой товар его заинтересует». Вам говорят: «Так он все равно же туда перейдет, зачем нам это предсказание?» Много вещей, которые можно предсказать, совершенно бесполезны для бизнеса.
Поэтому продуктовую гипотезу надо тщательно обсудить, и желательно выразить в деньгах. «Смотрите, мы предсказываем, куда перейдет человек», и сразу в браузере начинает предзагрузку этой страницы, и, таким образом, он переходит, страница у него грузится на полсекунды раньше, а известно, что ускорение загрузки страницы на полсекунды увеличивает конверсию на 10%. Это примерно, была такая информация, цифры чуть-чуть не такие, но, в общем... Вам говорят: «О, здорово, если конверсия увеличится на 10%, мы зарабатываем дополнительно 2 миллиона в день. Отлично, поехали».
Дальше, какие данные нам доступны? Вы в своей модели, например, в данном случае базировались на истории переходов пользователя, но как вы получите эту историю переходов пользователя? Вы ее брали из Google Analytics, но в Google Analytics она попадает с задержкой, может быть. Тут вам надо понимать, где вы ее будете брать. Вопрос решаемый, но дальше, а можете ли вы действительно предсказать? Тут анализ осуществимости, бэк-тесты, то есть тесты на существующих данных, хорошо ли ваша модель предсказывает. Тут встает вопрос оценки. Очень часто у нас есть несколько критериев, по которым мы могли бы оценивать модель, и по какому критерию мы будем модель оптимизировать? Допустим, мы оптимизируем ее по тому, как хорошо она предсказывает следующий переход. А нам бизнес говорит: «Хорошо, это все здорово. Но лучше бы вы точно предсказывали переход на странице, которая медленно грузится, а если вы ошибетесь, и человек перейдет на страницу, которая грузится быстро, и Бог бы с ним, она все равно быстро загрузится». Внезапно наша метрика становится совсем другой, когда мы поговорили с бизнесом, критерий оценки другой.
Дальше важно сделать какую-нибудь базовую модель, неважно, какой тупости. Даже в вашем случае, например, в этом случае, про который я рассказываю, можно предсказывать, что он просто перейдет по первой ссылке на этой странице.
Попытаться измерить качество этой модели. Тут обычно самые трудности и всплывают, что, например, данные недоступны, или результат вашей модели невозможно применить, потому что к тому моменту, когда вы даете кредит, пользователь уже сам куда-то перешел. Или бывает, что результат работы базовой модели вполне устраивает пользователей ваших, и ничего больше делать не надо.
Дальше начинается доработка модели, и тут мы сравниваем: «Ага, вот мы у нас была базовая модель, которая всегда предсказывала первую ссылку. Мы сделали модель на нейронных сетях, она предсказывает сложнее». И, скажем, качество выросло на 0,3%. Стоило ли это возни? В общем, то есть прежде, чем мы делаем сложную модель, надо сделать простую, чтобы было, с чем сравнивать.
Затем мы пробуем все это дело развертывать, внедряем мониторинг, и думаем, как мы будем дообучать нашу модель, когда она начнет работать плохо.

Часто машинное обучение делать просто не надо. Во-первых, если это неэтично. Что такое «неэтично», у каждого человека свои критерии. Мы, например, не работаем с проектами для взрослых, мы не работаем с проектами, связанными с наркоторговлей, даже косвенно, например, продажа оборудования для выращивания, мы сталкивались с таким. Мы не работаем с многими другими проектами. Каждый для себя решает, что такое этично и что такое неэтично. Есть, например, Slack-сообщество Open Data Science, там недавно было большое обсуждение, что человек пришел устраиваться на работу, и ему говорят: «О, ты работал в системе, которая делала видеонаблюдение для Москвы, ты неэтичный человек, мы тебя не будем принимать на работу». Такое тоже бывает.

Потом, очень часто простое правило решает проблему. Есть мнение, что если вы считаете, что вам ML-модель, допустим, даст прирост производительности на 100%, то простое правило 50% из этого прироста тоже сможет дать. Часто данные недоступны, и тогда просто надо отправить людей собирать данные, и не мучиться. Если цена ошибки высока, возможно, это дело не для ML-модели, как, например, судебные ошибки. Если каждое решение должно быть объяснимо, возможно, что ML-модель тут не нужна. Возможно, что она может просто помогать человеку, но принимать решение все равно должен он. Очень часто дешевле иметь человека, чем сажать ML-модель. Очень жаль, что это так, но на самом деле так.
Если бы здесь было одно правило, я бы сказал, что это правило большого пальца, но тут пять правил, поэтому это просто правила. 50% эффекта ML-модели можно достичь без ML – правилами, регулярками и так далее, часто это так.
Если эксперт не видит в данных закономерности, ML тоже не увидит. Если вы сами не видите на картинке, допустим, какого-то сигнала, то вы не научите нейронку видеть этот сигнал. Большинство проблем на границах системы, то есть не в том, что ML работает плохо, а в том, что в нее не поступают нужные данные, либо predict ML-модели идет не туда, или не вовремя.
Основные затраты при создании ML-проектов – это данные: приобретение данных, разметка данных, обработка данных, хранение данных и так далее, и тому подобное. Если ваши метрика выражена не в рублях, она, на самом деле, неважна, то есть ей могут пользоваться, когда нужно что-то использовать в отчете или как аргумент, но всех, на самом деле, интересуют деньги.

Есть несколько хороших ссылок на «почитать». Первая – это старая книга «Правила ML» гугловская. Ей много лет, но там все правда. Второе – это Machine Learning Yearning. Andrew Ng издавал одно время главами свою книгу, где рассказывал, какие проблемы в машинном обучении он встречал на практике, и какие бы советы он дал человеку, который взялся за это. Evidently AI Blog, про мониторинг, и прекрасный стэнфордский курс. Сам курс, конечно, закрытый, видео у него нет, но есть их презентации и записи лекций, в смысле, конспекты. В принципе, про построение практически полезных систем машинного обучения там очень хорошо и много рассказано.
Можно спрашивать меня, я тоже немножко про это знаю.

Ведущий: Да, спасибо большое за такую интересную лекцию. Вопросов в YouTube я сейчас не вижу, но у меня у самого есть вопрос. Дмитрий Колодезев: У меня сейчас, секунду, есть из Telegram пара вопросов. А, нет, из Telegram вопросы не сюда. Давайте ваш. Ведущий: Вы затрагивали тему соревнованний по Kaggle. Для человека, который уже в индустрии, насколько полезно заниматься соревнованиями, по вашему мнению?
Дмитрий Колодезев: Смотрите, во-первых соревнования – это хороший способ прокачать резюме. Если вы хотите перекатываться в DS из экономики, например, из экономистов, как, допустим, Павел Плесков, то это хороший подход. Потом, в них еще интересно играть. На самом деле, Kaggle интересный. Не всегда на него хватает времени, но есть некоторое количество медалек кэгловских, не то, чтобы много, даже до мастера не хватило, времени не хватает, редко этим занимаюсь.
Я думаю, что Kaggle – это хорошая техническая школа. Как мне говорили люди, которые в нем участвовали, со мной участвовали, что «мы тут за месяц узнаем больше, чем за полгода в реальной работе». Kaggle – это очень хорошо, просто надо не путать соревнования и... Грубо говоря, не надо путать секцию каратэ драку на улице, в жизни все сложнее.
Еще, на самом-то деле, у Kaggle есть такая прекрасная вещь, что если вы хотите посмотреть, какие подходы люди пробовали в той или иной тематике, то есть, например, вы не занимались анализом гистологии или рентгеновских снимков, или томографии, вы можете зайти в соревнования, на которых такие данные обрабатывались, и посмотреть там. Любой разумный подход, который может возникнуть у вас, он там уже был. Например, в любой абсолютно теме: на рекомендательные системы, на предсказания временных рядов, на работу с акциями, с кредитами.
Везде там удобные открытые датасеты, и можно оценивать работу вашей модели в сравнении с тем, что у других людей получилось. Я знаю, что многие разработчики библиотек используют Kaggle просто как baseline для отладки. Например, сделали какой-нибудь авто-ML и порешали им текущий Kaggle, заняли шестое место – ну, и здорово, молодцы.
Ведущий: Да, спасибо большое. У меня примерно такое же, на самом деле, мнение, в плане того, что имеет смысл, чтобы прокачаться именно технически, то есть в реальной жизни очень много задач, но не всегда, например, хватает R&D, и как раз Kaggle может это дать, какие-то новые подходы. На основной работе этого может не быть, ты занимаешься данными 80% времени, всеми видами, соответственно, задачки пообучать модельки не всегда доступны, скажем так.
Дмитрий Колодезев: Еще иногда просто у вас нет данных, с которыми хотелось бы поиграть. Возникла какая-нибудь интересная идея про графы, например, а у вас реально в работе графов-то и нет. Полезли туда, ее проверили.
Ведущий: Да, да, и посмотреть в другую сторону, немножко расширить свой кругозор.
Дмитрий Колодезев: Ну да. А еще иногда, смотрите, какая штука здесь. Мы занимаемся... У нас не своя продуктовка, мы делаем модели для других, и иногда не очень понятно, что же там у них творится. Приходит человек и говорит: «Мне нужно сделать то-то», а данные нам дадут только после, того как мы продадим свои услуги, и там, на самом деле, очень долгий процесс доступ к данным. На Kaggle могут быть данные этой же отрасли выложены в открытый доступ с описанием примерно проблем, за решение которых они готовы платить деньги. Это как способ искать готовые прототипы. У меня два любимых, это сайт Paper with Code, где разбираются, так сказать, лучшие подходы к тем или иным задачам и примеры кода, и Kaggle, где тоже люди выкладывают свои реальные задачи, за деньги соревнуются. Кому-то не лень за это деньги платить, значит, проблемы актуальны.
Ведущий: Да. На аутсорсе есть такая проблема, что нужно показать себя, сказать, что «я решал примерно такую задачу, и я примерно готов на такие метрики». Есть, конечно, исследовательские задачи, но они очень редки в аутсорсе.