
- 15.10.2022
- 25.08.2024
- выступления
- #interpretable_ML, #NLP
Вместе с OML-омской группой специалистов по машинному обучению - провели митап. Было три доклада - Иван Глухов про process-mining, Иван Бодаренко про робастные NER-модели, и мой - про интерпретируемость NLP-моделей. Все было вживую, и после митапа было еще интереснее, чем на митапе. Обязательно приедем к ребятам еще раз.
Слайды тут omsk_nlp_2022.pdf
Текстовая расшифровка, пока не вычитана:
Привет, меня зовут Дмитрий Колодезев и я попробую рассказать про интерпретируемость NLP-моделей. Я из Новосибирска, работаю в Промсофте и, наверное, это все, что мне про себя надо рассказать.

Дело было так, на больших дата-фестах, вот этих вот, которые московские, мы с Ириной Голощаповой почти всегда ведем секцию по интерпретируемости, либо про reliable ML, то есть про то, как сделать машинное обучение надежным, полезным, практичным для бизнеса. И вот последний раз, когда я делал доклад, что нового в интерпретируемости моделей машинного обучения, я так мимоходом сказал, что ну вот, есть такие инструменты, такие инструменты, еще есть вот этот инструмент для визуализации трансформеров, я правда не понимаю нафиг их визуализировать, и мне из зала говорят, ну как же, как же, как же, что вы думаете, неинтересно? Я говорю, ну интересно, конечно, только провизуализируешь трансформеры, что делать-то с этой визуализацией? Ну и как-то так я поставил себе галочку, что надо кого-нибудь взять и рассказать, что я думаю про визуализацию NLP моделей, ну вот и вы мне попались.

Ага, прежде всего это конечно про Natural Language Processing, и это типичная задача, например, классификация текста, допустим, токсичный, нетоксичный текст, это генерация текста, это продолжить текст, это разбор текста на кусочки, о том, о чем сейчас рассказывал Иван named entity recognition, заполнение пропусков, преобразование текста в текст, типа переводы, суммаризация, ну короче, вся вот это вот счастье.

За последние 10 лет очень много было сделано для появления и развития так называемого Explainable AI, XAI. Первоначально это была вражеская инициатива, американская исследовательская ассоциация, которая, DARPA по-моему, она дала денег и сказала, ну, ребята, давайте-ка вы, пожалуйста, за два года разберитесь, как эти самые ML модели делать объяснимыми и воспроизводимыми. Бюджет был благополучно освоен, по-моему, к 2020 году, модели стали воспроизводимые, понятные, в общем, все здорово. Обычно про интерпретируемость во всяких контекстах за рубежом говорят про имеем право знать, как с нами обращаются роботы. Ну и этот подход имеет право на жизнь, потому что сейчас так или иначе ML алгоритмы, они буквально в каждом чайнике, то есть они скорее всего управляют, допустим, нагревом лампы в этом проекторе, они управляют охлаждением ноутбука, они управляют светофорами, чем-то еще, то есть реально мы окружены ML алгоритмами, они принимают какие-то решения, они влияют на нашу жизнь, мы хотели бы знать, что происходит-то. Но нас как инженеров обычно, я инженер, обычно интересует отладка моделей и данных. Отлаживаем мы не только модель, но и данные. Если бы мы были просто программисты, мы бы отлаживали только наши программы-модели. Но наши ML-модели, они симбиоз программы-данных, они от данных зависят часто больше, чем собственно от кода. То есть у нас может быть очень тупая модель, хорошие данные, мы всех побьем. Explainable AI важен при приемочном тестировании, то есть такие вам приносят модели, вы такие думаете, уж не фигню ли они сделали, как вы поймете. И потом выясняется когда-нибудь, что все-таки сделана была фигня и начинается анализ ошибок и разбор полетов, а почему это сделана была фигня, как бы сделать, чтобы она больше с нами не случалась. Сравнительно новая тема это выявление уязвимостей. Когда вы берете чужую модель, вы на самом деле не можете быть уверены, что там нет каких-нибудь прикольных закладок. Например, разработчик системы распознавания лиц специально обучил, например, модель так, что любой, кто наденет красивые красные очки, не распознается как человек. И это есть пример, это не пример уязвимости, это пример работы, которая доказывает существование такой уязвимости Proof-of-Concept. То есть ребята просто сделали, что любой человек, который одевает эти очки, он не распознается как человек, может идти мимо security камеры, все отлично. Стало быть, бизнес он состоит примерно из двух шагов. Первый продать систему распознавания, а потом сидеть и продавать очки. И кроме всего прочего, есть такие смешные вещи, например, как ImageNet, в котором, допустим, 10 миллионов изображений, и никто их глазом не посмотрит. То есть там могут быть закладки в данных, и никто их никогда не найдет. И хотелось бы, конечно, ловить систему на странном поведении. Если вы помните, во многих фантастиках там бывает такое, что человек живет нормально, потом к нему приходят и говорят строгим голосом «Абракадыбр», и он идёт и всех убивает. То есть мы такие передали ему команду. Вот с ML-моделями это тоже возможно. Нам хотелось бы отловить момент, когда он начнёт вести себя странным. Ну и при тестировании моделей очень важная вещь – это такая проверка очевидных зависимостей. Что такое проверка очевидных зависимостей? Ну, например, мы делаем модель кредитного скоринга, и мы хотели бы так по-быстрому до того, как банк начнет терять деньги на нашей фиговой модели, проверить, не сделали ли мы какую-нибудь глупость. Ну и какие мы точно знаем очевидные зависимости, которые обязательно должны работать. Ну, если человек зарабатывает меньше, вероятность получения кредита у него должна уменьшиться. Если у него больше долгов, вероятность кредита должна уменьшиться. Если, допустим, в нашем тексте, который мы анализируем на предмет токсичности или нет, мы добавим туда матерное слово, балл токсичности должен увеличиться. И если в нашем модели этот простой тест не проходит, значит мы сделали какую-то фигню. И социализация модели – это важный момент. Дело в том, что мы, люди, имеем тенденцию объяснять все, что действует вокруг нас. А ML модели действуют. И в человеческой культуре есть специальный такой образ чего-то, что действует как человек, но мотив его непонятный – это зомби, мы его боимся. То есть все, что выглядит как человек, но мотивы непонятные, оно нас пугает. И с ML моделями то же самое. То есть когда пользователь начинает сотрудничать с вашей ML моделью, а он с ней именно сотрудничает, то есть мы передаем ей часть действий, которые так бы делали люди, когда пользователь начинает с ней сотрудничать, он вынужденным образом построит у себя в голове ее модель. И если вы не дадите ему эту модель, он построит у себя в голове чудовищную модель какую-то. То есть модель необходимо социализировать при внедрении, ее надо объяснять пользователям. Даже, обратите внимание, если это неправильное объяснение, то есть оно простое, ну ты знаешь, она смотрит всех, если доход маленький, она кредит не дает. Это хорошее объяснение, которым может пользоваться человек, и он примерно полагает, что ну да, от модели мы можем этого ждать. То есть социализация модели тоже очень важна. Ну и какое это отношение собственно имеет к NLP.

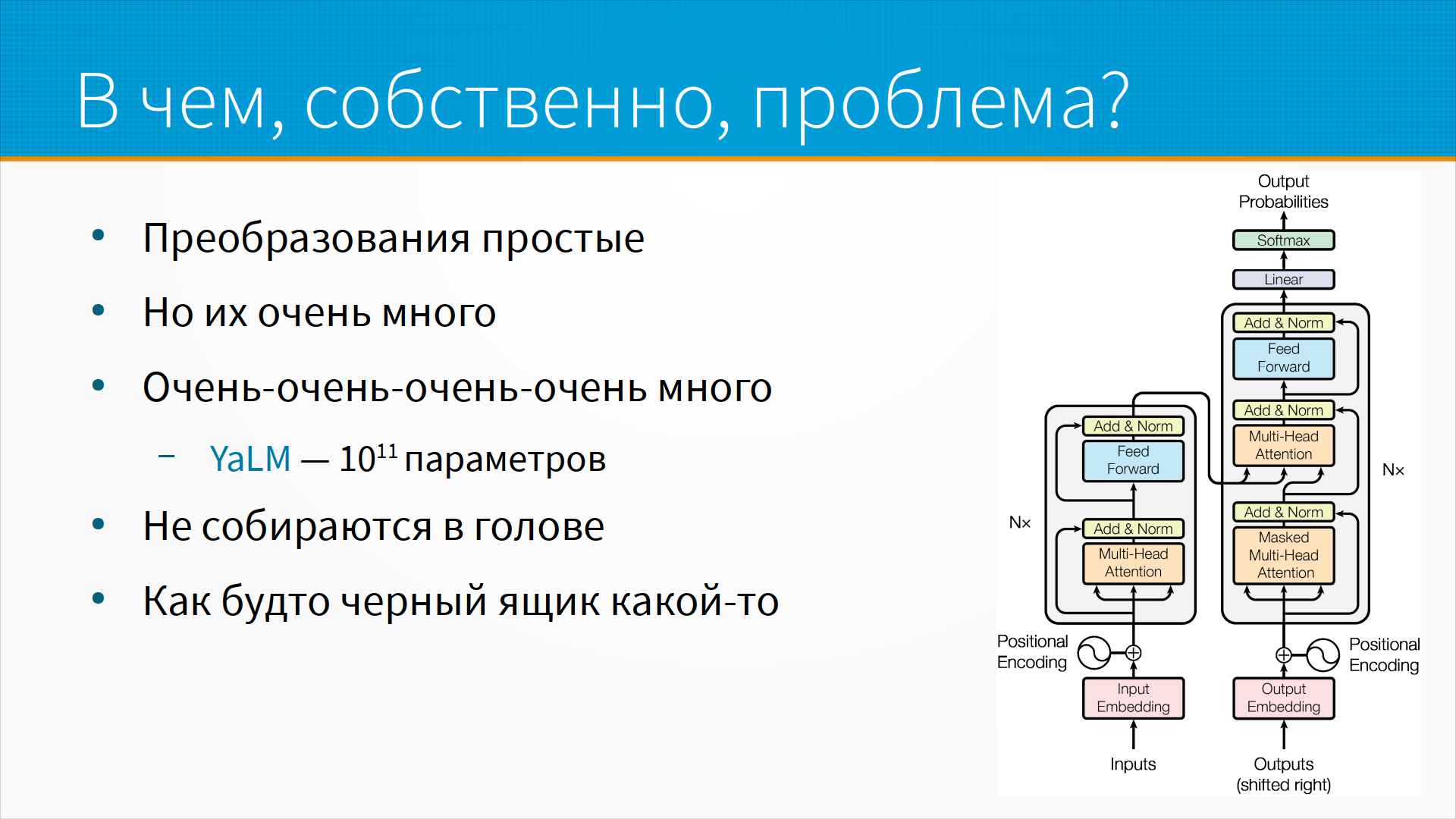
Есть такое мнение, что на самом-то деле нам не нужно как-то специально объяснять модели, потому что все, что внутри происходит, это просто матричное умножение, сложение, какие-то еще такие операции. Конконтиненция векторов, и в принципе это так, то есть все операции, которые происходят в нейронной сети, они все простые, мы можем просто посмотреть, как у нас вот эта чиселка путешествует по нашей нейронной сети. Но есть тут проблема, что этих параметров, этих операций в нейронной сети много. Большая Яндекс языковая модель Яун, которая недавно выкатили, в ней 10 в 11 степени параметров, то есть примерно столько же, сколько нейронов в мозге. Если бы мы решили понять, как она работает, нас бы как раз на один параметр, мы потратили бы один нейрон, и все было бы наверное хорошо. То есть попросту говоря, это простые операции, но настолько сложные, что в голове их собрать на самом деле нереально. И тут надо заметить, что есть городская легенда про объяснимые и необъяснимые модели машинного обучения, типа ну зачем вы делаете просто неинтерпретируемые модели машинного обучения. Нормально делай, нормально будет, давай везде используем логистическую регрессию, но человек не способен понять логистическую регрессию больше, чем с пятью параметрами. То есть люди, которые проходят специальную подготовку, то есть они учатся на математиков, они учатся на инженеров, они видят, у них есть какая-то социализация логистической регрессии, они думают, что они ее понимают. На самом-то деле, представьте себе, ну вот скажем, пятимерное пространство, представились, да? Вот, трудно. Вот, теперь представьте себе, что в этом пятимерном пространстве есть вот такая вот изогнутая вещь, и наша логистическая регрессия в ней ошибается. Я вот, например, представить этого не могу. Вот, и собственно на основании этого я предполагаю, что люди не очень понимают даже логистическую регрессию с пятью параметрами, а в нейронках их чуть-чуть побольше.
Вот, ну или, говоря другими словами, модели наши работают очень хорошо, но ученые, которые их сделают, в общем, сами в некоторой задумчивости, как им это удаётся. Эта фраза немного немало с сайта AlinNLP, ребята, которые много делают как раз для разработки NLP моделей.

Вот, а как люди объясняют свой текстовый опыт, свои NLP модели, задачи? Вот по этому слову я сразу узнал вас интеллигента. То есть, вот пример объяснения классификатора на основе текста. Или, он научился этой фразе у одноклассников, это то, что называется object importance. Мы в нашем дата-сете выделяем какие-то строчки, которые научили нашу модель плохому, из-за которых у нас появляется ошибка. Тут надо понимать, что почти все практические дата-сеты, наверное, все практические дата-сеты, они друг другу немножко противоречат. То есть, какая-то строчка говорит про этот набор признаков да, какая-то строчка про этот набор признаков говорит нет. И поэтому абсолютного качества нельзя достичь, есть так называемый байсовский порог качества. И вот мы могли бы найти эти противоречия, выкинуть их, и тогда бы у нас наступило счастье. Или там, например, только не говорите ему про деньги, это его бесит. То есть, это вот то, как люди описывают свой текстовый опыт. Логичным продолжением сказанного будет, но это вот почти что GPT-3. То есть, ну да, GPT-3 может продолжить. Это все равно что сказать, я не буду вам помогать. Саморизация. То есть, мы люди в нашем опыте работы с текстом как-то умудряемся объяснять, но тоже на самом деле не очень.

Вот, ну и вот это тот самый инструмент, по поводу которого я тогда говорил на DataFest, он хороший. Я ничего против него не имею, и для исследования обученного вами трансформера он неоценим. Но что он делает? Он визуализирует attention в трансформере. То есть, что такое в принципе в трансформере attention? Это на какие части предложения модель обращает внимание, когда смотрит на важность этого конкретного слова, допустим. Да, можно так сказать. И в принципе в модели есть несколько голов, она смотрит на одну и ту же самую тему под разными углами. И мы можем увидеть на вот этой визуализации attention, что вот смотрите, у нас есть, например, один способ attention в весах, второй способ attention, скажем, третий, четвертый, ну что, четыре разных концепта она здесь поймала. Это полезное знание. А если мы увидим, что у нас как-то неравномерно окрашено или очень равномерно окрашено это внимание, ну, наверное, с этой моделью что-то не так. Но это в принципе вот для инженера, то есть Ваня Бондаренко, наверное, может больше узнать отсюда, но для меня, как для инженера, больше отсюда информации не пойму. То есть, если что-то совсем плохо, я здесь это увижу. Главный образом, потому что здесь будут черные прямоугольнички с какими-нибудь редкими полосами. А если вот так покрашено, ну, покрашено и покрашено. То есть визуализация это полезная, но она объясняет непонятные непонятными словами.

А вообще про attention есть, ну, собственно, с трансформера начались статьи attention is all you need, где предлагалась сама концепция self-attention, внимание, что мы при анализе какого-то, при построении embedding какого-то слова, мы смотрим на то, какие слова на него тоже влияют. И вот такие вот картинки, когда смотришь на них, ну да, понятно, что вот это слово, оно семантически связано с вот этими. Вот. Все здорово, но вот таких вот картинок по трансформеру можно построить миллион. По одному, ну, то есть для каждой головы, для каждого слоя, и они все разные. То есть, если бы у нас была такая одна картинка, как в LSTM, она была бы очень понятно интерпретируема. В трансформере их много. Вот. И таким образом, несмотря на то, что attention is all you need, attention is all you want, соответственно, кроме attention вы тут ничего не видите. И еще надо заметить, что само по себе attention – это не объяснение. То есть, предположим, что мы вот сейчас сидим, я вам рассказываю про интерпретацию моделей машинного обучения, и тут заходит такая девица вот с таком sombrero. Вы обратили на нее внимание, но никакого влияния на ваше решение она не влияет. Есть куча примеров, где разбирается влияние похожей концепции карт насыщенности в computer vision, где, например, модель классифицирует фотографию старинного замка, она говорит точно замок, ей говорят подсвети, почему ты так решила. И там такой фонарь электрический. Вот поэтому, я считаю. И я приводил это как раз к человеку, который рассказывал про исследование в интерпретируемости. Я говорю, смотри, ну вот это же явная чушь. Он, да, все так думают, но вот мы долго обсуждали и решили, что все-таки не чушь. Ну, то есть вот такие вещи. На самом деле, карты насыщенности и карты внимания говорят о том, какие вещи могут иметь значение. То есть, если вы на что-то не обратили внимание, то оно не будет иметь значение. Но обратно и неверно. И опять же, тут можно вспомнить такую типичную ошибку при интерпретации весов линейной регрессии. То есть, предположим, что у нас есть линейная регрессия, и мы такие думаем, а какой из параметров линейной регрессии оказал наибольшие влияния, наиболее важный для нашей модели. Ну, и мы смотрим на веса. И говорим, ну вот у кого веса больше, тот и важнее. Ну, у нас тут вопрос в масштабе самих этих величин. То есть, я мерил вес больного в килограммах, потом стал мерить в граммах, у меня раз в тысячу раз масштаб изменился, так? А затем тут масштаб в вариабельности переменной. То есть, например, если ко мне пришли все больные исключительно весом 65 килограмм плюс-минус 100 грамм, то на самом-то деле вариабельность этой переменной низкая, какой бы там ни был вес, большого значения она не имеет. Эти все вещи, все эти представления собрали в так называемую концепцию attention flow, и в общем объяснения с помощью attention изрядно доработали.
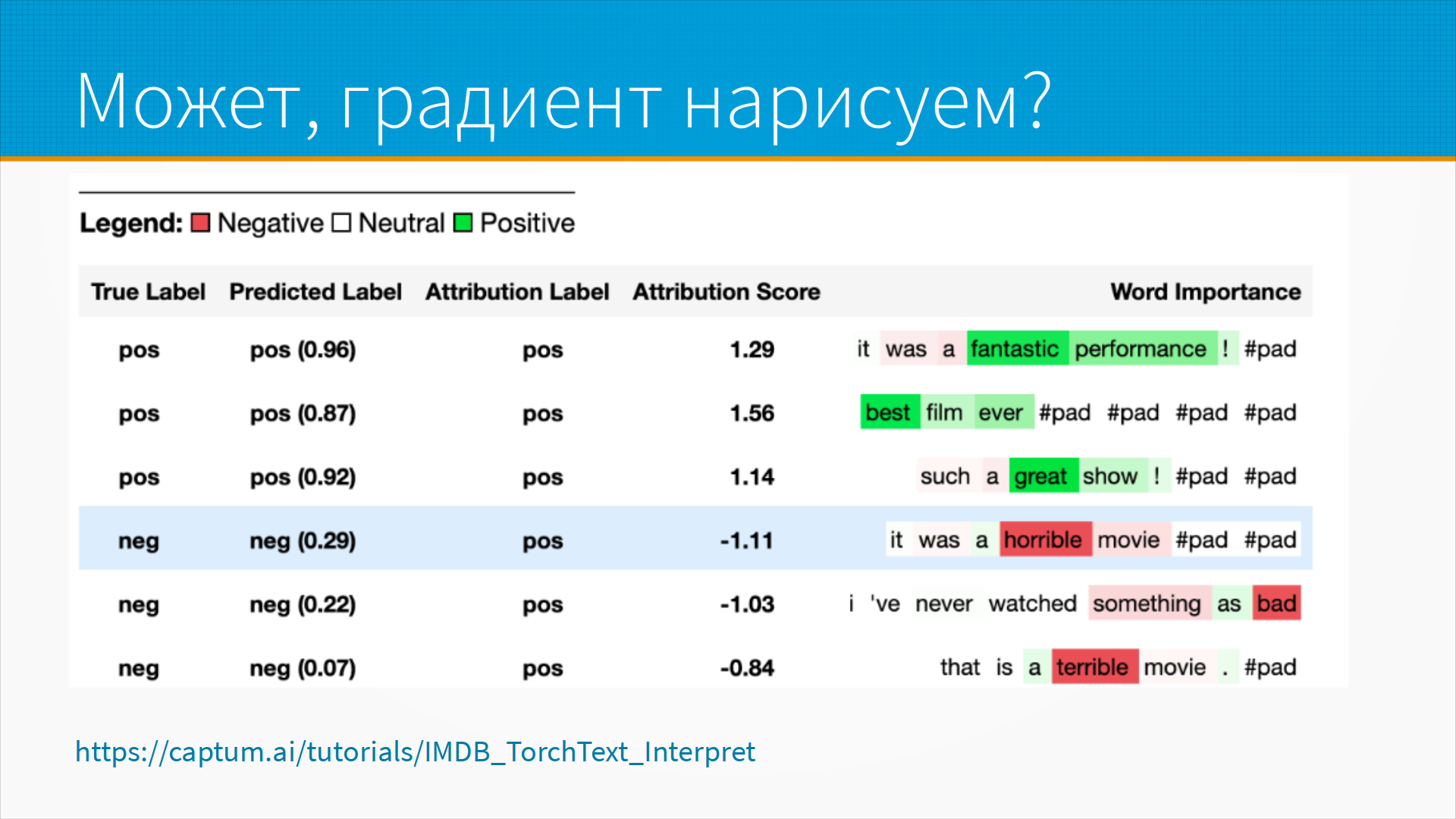
Ну, в общем, можно точно так же и посмотреть, допустим, особенно в каких-нибудь задачах классификации, скажем, sentiment analysis, мы можем пробросить градиент назад до конкретного входного признака и посмотреть, насколько он повлиял на то или иное решение. То есть, вот, например, в данном случае это классификатор тональности текста, и у нас подсвечены зеленым те, которые у нас оцениваются в положительную тональность, в положительный сантиметр, и красным в отрицательную тональность. На самом деле это не так. На самом-то деле, поскольку мы анализируем трансформер, там все сложнее, там существуют сложные взаимосвязи, семантические взаимосвязи между словами, но можно... В последнем предложении, я так понимаю, terrible это наоборот в положительный должен быть, да? Ну, там на самом деле... Положительная оценка. Я бы сказал, ну, как многие пост-хок объяснения, я бы сказал, что это красивая ложь для кожаных мешков. То есть, на самом-то деле, внутри трансформер происходит гораздо более сложные вещи. А как проверить, так ли это? Возьмем-ка мы и уберем это слово. Изменится эта наность, хоп, а она не изменится, он просто в зеленом перекрасит другое. Вот, я про это чуть позже скажу. Ну, это очень полезная вещь, но относиться к ней надо с некоторой капелькой соли.
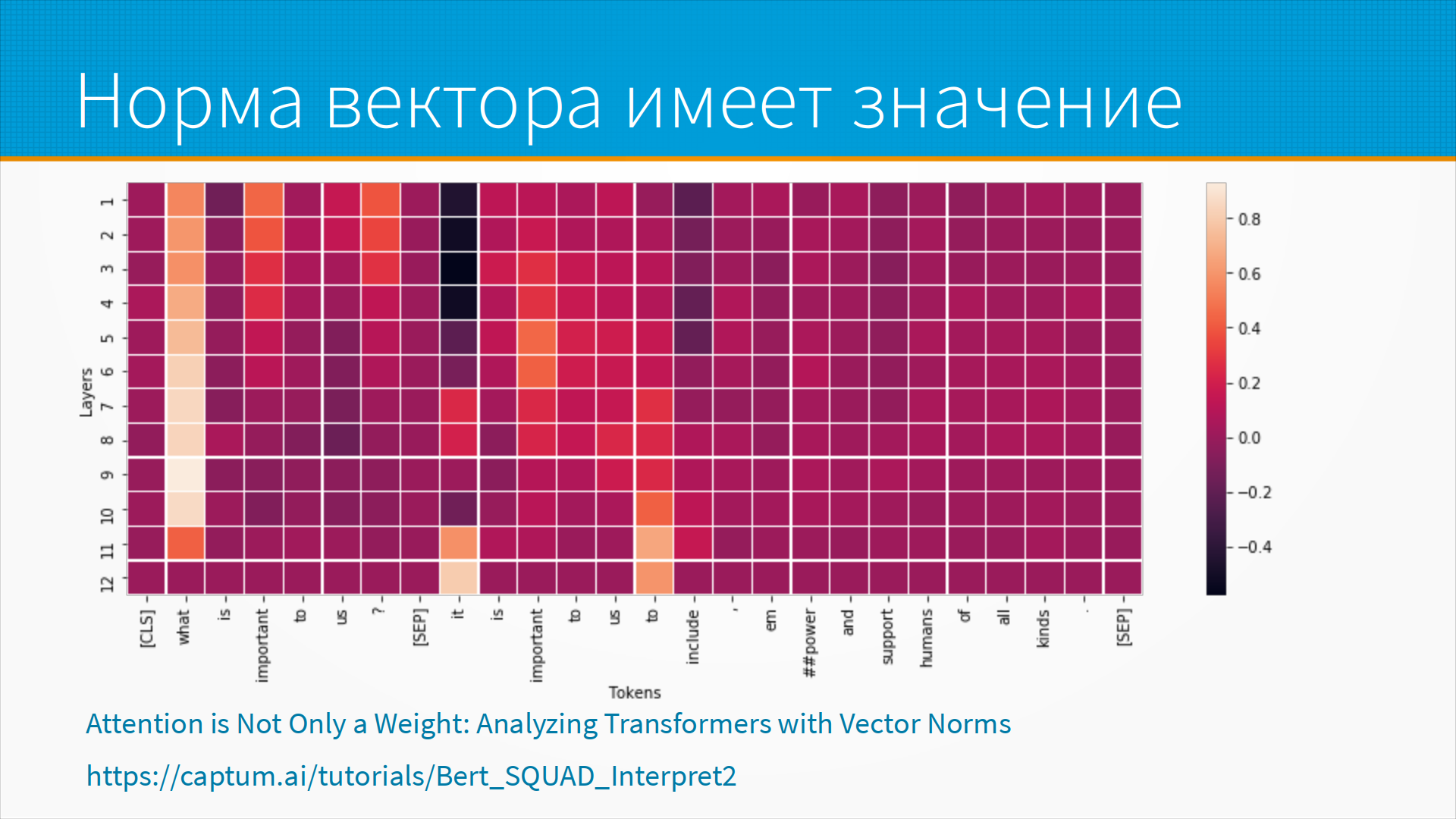
Вот это история про attention flow, векторную норму и так далее и тому подобное. То есть, вот эти вот статьи я на самом-то деле привожу как примеры удачных инструментов, которыми следует пользоваться, просто на формате этой рукописи недостаточно широкие поля, чтобы я про нее рассказал. Вот, здесь, в частности, видно, например, что какой-то вот вопрос what is important to us и, значит, what – это главное, что повлияло, потому что на всех слоях оно быстро, его attention flow улетел, ну, стал большим и потом не менялся. То есть, как бы она вот уперлась, что вот это важно, и это было важно на всех слоях. Это, кстати, вообще общее место у нейронок, если она в чем-то уверена прямо на всех слоях, это хороший признак, что, наверное, это на самом деле важно. Но не суть. Если возвращаться к тому моему примеру, что будет, если мы, допустим, выкинем то слово или выкинем это, естественным образом вспоминается shape-evaluus.
Про shape-evaluus надо ли рассказать? Вот, был такой Шепли, он занимался теорией игр, и потом он стал лорд Шепли, так успешно занимался этой теорией. Предположим, что мы пошли, допустим, втроем и сели в карты, выиграли у дилера 19 долларов. При этом известно, что если бы мы не пошли, ничего бы не выиграли. Я бы пошел один, я бы выиграл 7, вы выиграли бы 4, а, допустим, Ваня Бондаренко выиграл бы 6. Как нам поделить выигрыш? Он, очевидно, неаддитивный. Непонятно пока. Вот другой вариант. Предположим, смотрите, что, допустим, мы объединились, я, Ваня Бондаренко и, допустим, вы. Мы пошли на Kegel и выиграли там, допустим, 25 тысяч долларов. Как делить? Почему не поровну? Почему не поровну? Ну, смотрите, Ваня известный и опытный ученый. Ему, по идее, надо больше отдать. А вы опытный разработчик и, в общем, про разработку знаете больше, чем мы забыли. Поэтому, в принципе, больше вам надо отдать. А я всю свою жизнь занимаюсь тем, что помогаю команде разработчиков выкрутиться из той засады, в которую они попали, и я изворотливый. Я изворотливый менеджер разработчиков, поэтому, на самом деле, все надо мне. Понимаете? И вот как поделить? То есть, можно поделить, конечно, поровну, но разумнее было бы, например, понять, какой вклад каждый внес.

И вот мы, допустим, проводим эксперимент и все возможные сочетания мы отправляем. А, то есть, способ оценки, я так понимаю. То есть, предположим, вы один решаете Kegel, потом одного меня запустили. Потом одного Ивана. Потом вы с Ваней без меня. Все, понял, понял. Вот. И обратите внимание, что тут такое правило треугольника не работает в этой штуке, да? Вот. И затем, настроя, мы можем добавлять человека в команду шестью разными способами. Сначала добавить его, потом добавить к нему его, потом добавить к нему его, и смотрим. Он бы один выиграл семь. Если добавить этого, они бы выиграли еще восемь. Если потом добавить этого, они бы выиграли еще четыре. Так? И так у нас в шесть возможных последовательностей, да, как мы можем организовать трифакториал. И для каждой из них мы можем понять, сколько человек добавит, если его докинуть в команду. Вот.

Ну, и затем мы просто считаем его маржинальную прибыльность для команды и получаем оценку той пользы, которую он наносит в сферической команде в вакуум, если его добавить. И вот это те самые Shapew values. Какое это отношение имеет к НЛП и объяснению моделей? Предположим, что вот это у нас не люди, а слова в предложении. И мы смотрим, какой из них повлиял на то, что решение было принято такое или это. Тут есть разные варианты, как с ними пропускать их. Можно заменять на что-нибудь левое, либо заменять на пропуске. Это, кстати, лучше всего работает не с текстами, а с табличками. И вот, собственно, статья Ландберга, Unified Approach to Interpreting Model Predictions, он автор библиотеки Shap. И обычно, когда... Что? Это именно они, да. Это вот именно они, да. И когда говорят Shapew values, обычно думают про Shap. А внутри они устроены вот так вот. На самом деле, внутри они так не устроены. Почему? Потому что, как мы видим, тут надо факториал раз пересчитать и все попробовать. То есть, все перестановочные методы вычислительно intractable, не вытаскиваемы. Поэтому конкретно Shapew values интересным образом аппроксимируются, что приводит к интересным искажениям и глюкам, о чем есть тоже пара интересных научных статей, но не суть.

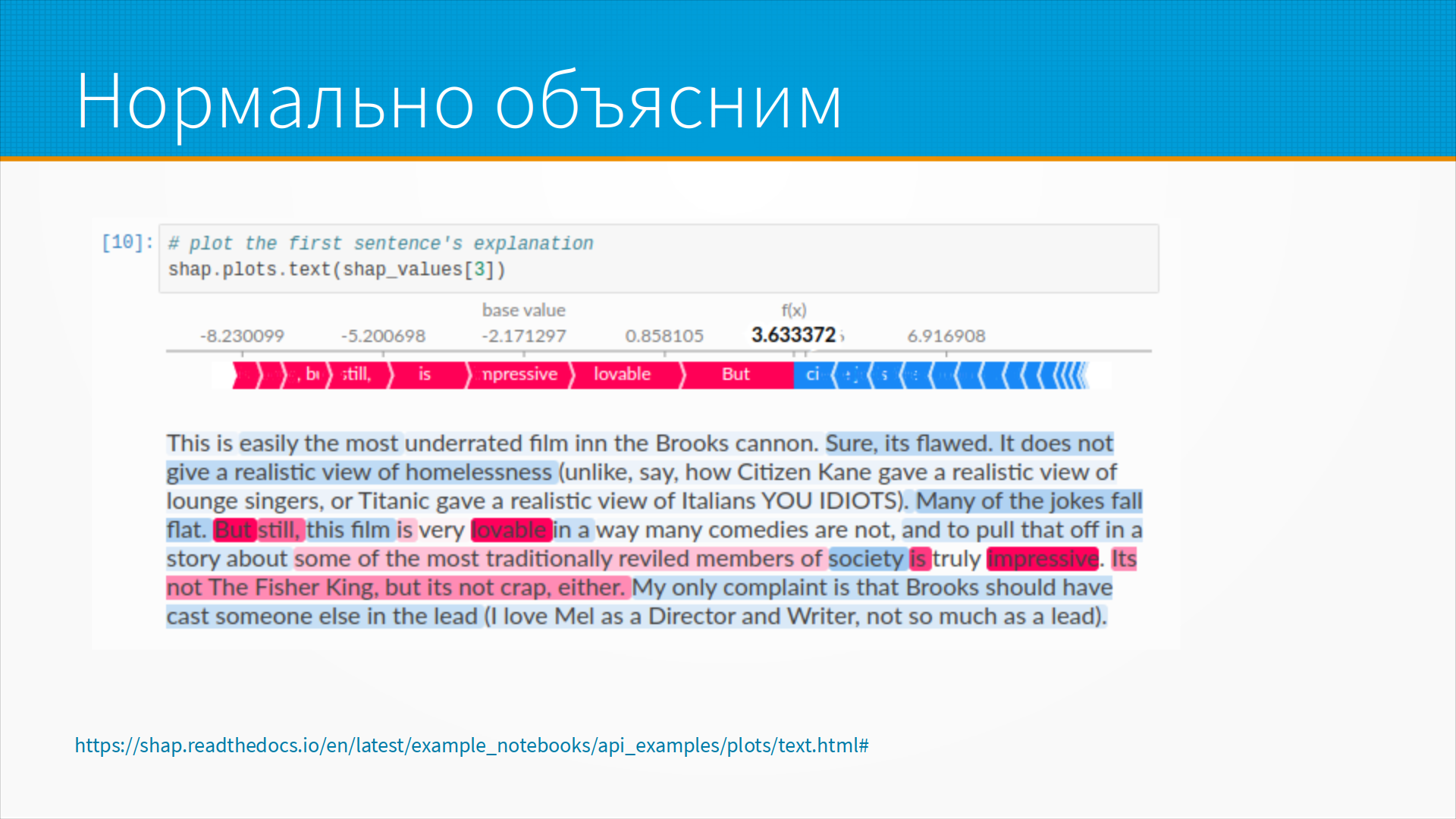
Ну, а как они объясняют тексты? Тексты они объясняют примерно так. То есть, вот это у нас конкретно sentiment analysis. И она говорит, что, ну, вот это вот, это отзывы на кинофильмы. Вот, допустим, большинство шуток плоские, это в минус. Вот. А вот это вот, допустим, в плюс. Но если мы внимательно посмотрим, очень хорошее объяснение, оно как бы понятное. Если мы внимательно посмотрим на объяснения, то почему-то вот society, общество снижает балл. Где разум, где логика? This film снижает балл. Ну, то есть, такие объяснения, они красивые, правдоподобные, им очень легко верить, ну и в общем с ними есть проблема.
А это вот, кстати, про перевод. То есть, с английского на испанский мы переводим. И какая часть английского текста больше всего повлияла на то, что испанский текст получился именно таким. Ну, все тоже выглядит довольно логично. Хотя вот тут есть один странный момент. Например, me madre, my hermana y hermana. Вот этот блок, он одинаково зависит от my brother and my sister and my mother. А по-моему, my father, он в другое место. То есть, какая-то нелогичность тут тоже есть. И если бы я интерпретировал модель, я бы зацепился за это и пошел бы, посмотрел бы, почему так. То есть, общий подход, на самом-то деле, к интерпретируемости моделей сидеть и молча слушать, пока не покажется что-нибудь странное, а потом вцепиться в него и начать копать.

Но есть проблема пост-хок объяснений. Люди верят красивым картинкам. Есть прекрасная работа Interpreting Interpretability 20-го года, где тестировали людей на интерпретируемость. То есть, им давали практикующих дата сатанистов, анонимных. В смысле, не раскрывали их фамилию, чтобы людей не позовить. Им давали модели, но не сами модели, а результаты их интерпретации с помощью шапа чего-то еще. И они должны были ответить на ряд вопросов. Например, готова ли эта модель к ПРОДу? Нет ли тут какой-нибудь проблемы и так далее и тому подобное. И, в общем, кожаные мешки с треском провалили это упражнение. На самом-то деле, выяснилось, и, кстати, во многих других работах этот результат подтверждался, чем красивее картинка, тем больше люди верят модели. То есть, грубо говоря, готовность моделей к ПРОДу зависит от красивости картинки и тут на самом деле... А если там еще и графики? Да, да, да. Вторая важная проблема пост-хок-объяснений — это то, что Лео Бреймон, автор алгоритма Random Forest, называл эффект Росимон. Росимон — это профильм Куросавы «Ворота Росимон», где убили самурая и несколько действующих лиц рассказывают свою историю. И главное, что у каждого из действующих лиц ключевые моменты истории все совпадают. И смысл истории вообще разный. То есть, вроде все сходится, но мальчик не наш. И Лео Бреймон говорит, что на самом-то деле, поскольку все данные, они обычно... Ну, задача у нас переопределенная, то мы можем построить модель на этих данных, на этих данных, на этих данных вот таким способом. То есть для одних и тех же данных, для одной и той же целевой разметки мы можем построить много хороших моделей с разными весами, по разным характеристикам. Множественность хороших моделей. То есть они будут рассказывать разные истории с одним и тем же результатом. Ехал самура и его убили. Вот. Причины везде разные. И получается, что нам модель может объяснить одним способом, а на самом деле она сделала другим. Ну и главное, вот как бы кому верить-то. Вот. И еще есть интересные патологии в работе моделей. Вот тут, например, по патологиям там статья как раз интересная. Предположим, что у нас есть система вопросно-ответная. Нам дан текст, мы задаем ей вопрос, она должна выделить кусок. Вот. На что потратил Тесла деньги автора? На Colorado Spring Experience. Отлично. Берем и выкидываем из этой фразы вопросы, которые мы задали модели, разные слова. И вот, если мы выкинем все, кроме did, она все равно будет отвечать. Более того, ее confidence только вырастет. То есть мы ее спрашиваем did, она говорит Colorado Spring Experiment. Вот. Звучит как анекдот, типа приборы 8. То есть буквально так. Однако модель очень уверенно говорит did Colorado Spring Experiment. Да. Перейдем к другому примеру. Хорошо одетый мужчина и женщина танцуют на улице. Вот. Это одно предложение. Второе. Два мужчины танцуют на улице. Вот. И нам нужно сказать, противоречит эти утверждения или они согласованы? Мы редуцируем the dancing и она говорит противоречие. Приборы 8. Вот. То есть человек не сможет сделать этого вывода. И допустим, what color in the flower? Мы редуцируем the flower, он отвечает yellow. И вот это вот приборы 8 просто в чистом виде. Вот. И языковые модели на самом деле ведут себя так. Ага. Особенно в последнем примере кажется нормально. Мы просто контекст извлекаем из кучи всего. Цветок желтый. То есть это я могу представить такой диалог реальных людей. Только в условиях контекста. Я также могу представить цветок под солнышком. Цветок в вазе. Цветок живой. А это контекст определяет, о чем они говорили. Тут смотри. Ну да, да, да. Шкаф коричневый. Смысл тот, что нейронная сеть научилась притворяться вести себя как человек. Но внутри она совершенно нечеловеческие какие-то критерии использует. Вот. И на самом-то деле это общая проблема пост-хок объяснений. То есть задним числом можем объяснить и реализировать все что угодно. Вот. Посмотрите вот эту статью про патологию. Она прям, я считаю, мастерит для любого, кто думает, что объясняет текстовые модели. Вот.

Тем не менее, есть варианты сесть и во всем разобраться. То есть, например, language interpretability tool. Открытый инструмент. Он позволяет сесть, нарисовать имбеддинги. Здесь не видно, но там такие красивые имбеддинги. Посмотреть вот эти вот все градиентики, attention и покрутить. Найти какие-то странности в тексте, посмотреть, как у нас какие-то сущности были рассыпаны, в какой части имбеддингов, как их дисперсия в имбеддингах распределилась после обучения. То есть, ну, по-хорошему, если нужно сесть и залезть с топором и скалепелем внутрь модели, то, наверное, вот ли тут взяли и залезли.

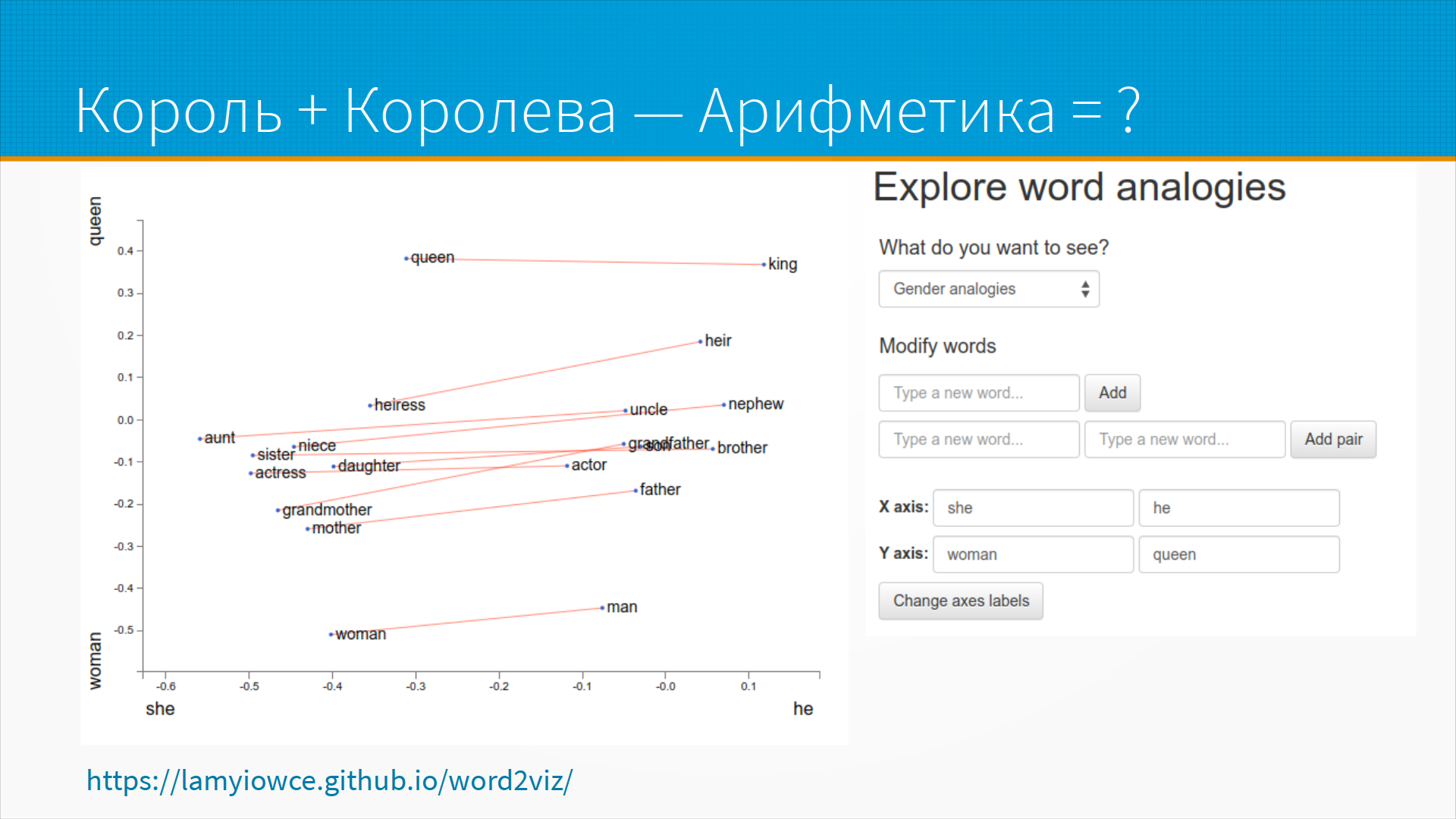
Тут, опять же, как у всех остальных, не видно красивых линий. Но есть известный мем про то, что, дескать, вот король плюс королева, король минус королева, плюс там мужчина будет, женщина. Ну, в общем, вся вот эта вот арифметика. На самом-то деле, есть сайт, который позволяет исследовать эти самые аналогии. Вот мы взяли, действительно, от королевы до короля, у нас примерно то же самое, да. Что, да, вот, ну, как бы, вот, вот, вот, вот, как бы, что-то около этого, да. Вот, они используют, исследуют одну модель, но, в общем, не очень сложно взять и руками сделать то же самое для любой другой. Вот. А тут единственное возражение ко всему этому, что пространство имбеддингов, оно, вообще-то говоря, обладает, если так прилично сказать, сомнительной метрикой обычно. То есть, оно обычно не круглое какое-нибудь облако, а какой-нибудь изогнутый конус. То есть, ну, там странно в нем выполнять арифметические операции. Но, тем не менее, что есть, то есть. Вот.
Из вещей, которые вышли не так давно и, на мой взгляд, за ними будущее, это чеклист. Предположим, мы сделали модель и хотим убедиться, что она делает хорошо. Что она делает хорошо? Ну, естественно, что, ну, это те самые проверка прямых зависимостей. У нас есть какие-то вопросы, на которые она должна обязательно давать такие ответы. Вот. То есть, например, I didn't love the flight. Да. Оно это действительно должна быть негативная оценка, да? Вот. Если она вдруг позитивная, то, ну, что-то не так с нашей модели. Я не могу порекомендовать эту еду, но это негативная, да, она прошла эту тест. То есть, мы собрали какой-то набор утверждений, каких-то набор подстановок, какой-то набор оценок, продолжений, которые модель должна пройти. Это, на самом деле, не так просто подобрать такой, построить хороший тест. И тут ребята предложили методологию, опенсорсные инструменты. Насколько я понимаю, это направление сейчас развивается бурно.

То есть, вот примеры тестов, например, да. То есть, мы брали вот этот текст, допустим. Вот American Air Service wasn't great. Если мы добавляем туда you are lame, вот, то тональность должна ухудшиться. То есть, более негативная. Она стала нейтральная, ну, значит, у модели тут ошибка. Она не понимает, как устроен язык, да? Ну, и вот такие вещи, они на самом-то деле позволяют интегрировать практики software quality assurance в разработку моделей, привыкать к их на прод. Я думаю, что мы к этому придем.

И вот тут у меня есть кое-что секретное. Дело в том, что я планировал выступать через неделю позже и не успел сделать два слайда. Вот. И не стал тут что-то пытаться, я лучше их словами расскажу. Есть удивительные вещи, которых не должно быть, а они есть. Как тот суслик. Предположим, что мы взяли какой-нибудь BERT и доучили его на нашем наборе документов. Что произошло с весами этого BERT? Это, кстати, интересный вопрос. Ну, чуть-чуть изменились. Чуть-чуть изменились. А на каких слоях они изменились? Как изменилась кластеризация этих весов при активации тем или иным текстом? Вот тут есть безумная совершенно идея, она не моя. Предположим, что у нас есть исходный BERT и доученный BERT. Мы возьмем вот этот дифф в весах. И предположим, что это линейная вещь. И возьмем, и чуть-чуть его сдвинем сюда. Это изменение весов. И по идее мы ее чуть-чуть разучим. Звучит безумно учитывая сложность функции потерь нейронок. Но это работает. У меня нет доказательств. Я их, надеюсь, к хэллоуину притащу. Для хэллоуина как раз самый то. Но статья есть не моя на эту тему. Где люди тоже копают это дело. Более того, предположим, что мы учили, допустим, нашу сеть копаться в нашей интересной предметной области. У нас не так много данных. Возьмем и экстраполируем дальше. Сейчас, секунду. Задвинем ее чуть-чуть больше. Как будто мы ее чуть-чуть дальше доучили. Вот. И это тоже работает. Мы можем оценить качество работы модели. Мы видим, как она забывает и вспоминает концепции. По мере того, как мы этот движок, так сказать, в весах двигаем. Как мы их смешиваем между собой. Вот. То есть, этого не должно быть. Но это есть. Это просто, наверное, недостаточно хорошо документированная фича этого мира.

А вторая вещь, это, ну, со всеми этими королевами, мы можем найти концепции, которые, допустим, близки друг к другу в векторном пространстве. А некоторые далеки. И построить, например, скажем, основное дерево на них. Вот. Есть такая, продолжающаяся лет 40, работа по построению языкового портрета. Или как-то слепка языкового сознания. Я в терминологии не очень. Ваня может быть в курсе. Вот. Где пытаются понять, что вот, значит, для американцев любовь означает совсем не то, что для нас и так далее. Ну, кстати, это вот прям факт медицинский. Потому что love это состояние ничьи в теннисе. Вот. Как бы по-русски вообще непонятно, откуда эта коннотация взялась. И вот мы этот граф построили, а затем мы сетку доучили и посмотрели, как этот граф изменился. И, грубо говоря, до обучения у нас было понятно, что Маша умница. А потом мы добавили данные, и эта связь потерялась. Мы такие, хо. Вот. Что-то мы про Машу такое ему сказали. Вот. То есть мы подбираем набор опорных фраз и видим разницу в графе. У меня этот результат у меня есть, но очень спорная сами по себе опорная фраза, поэтому я его сюда не притащил. Вот. Такие вот дела.
Ну, и слайд лежит тут. Я живу тут.

Здравствуйте. Я хотел сказать про магию на вот этих весах и диффах. Это просто вообще бомбическая штука. Я вспомнил следующий эффект, который мы наблюдали в Stylegun 2, когда много с ним экспериментировали. И где-то прочитал тоже. Мы берем Stylegun, просим сгенерируем просто рандомно кучу картинок. Потом берем классификатор, который классифицирует картинки, она нормальная или плохая. Вот. Этим классификатором размечаем выборку. Потом находим с помощью свэма классификатор, короче говоря, лучшим. Получаем вектор, который показывает направление, где картинки получше. Теперь берем, вычисляем эмбеддинг, как нужно его менять, чтобы картинка получилась лучше. Берешь, рандомно генерируешь эмбеддинг, прибавляешь смещение, картинки получаются лучше. И ты такой, в смысле? Это как сейчас, спросить Дали и прочего. Можешь, пожалуйста, получше хорошего качества картинку сгенерирую, и она будет лучше. Да, а между прочим, у Дали это работает. То есть, есть такой прикол, что вам сгенерировали картинку, типа, скажем, nice girl. Она вам нарисует nice girl. Very nice girl. Она нарисует girl более nice. А если вы напишите много раз very, very, very, very, very nice girl, это работает. Она нарисует яркую ее, такую всю звезду, такую прекрасную. Вот это правда работает. Вот. Ну, это одна из вещей, на которые рано наткнулись. Она широко подтверждена, и не я ее выдумал. Вот, ну вот, в общем, very, very, very. Да, мир удивителен. Но у меня нет нормальных устойчивых доказательств, которые выдержали бы спор с Ваней Бондаренко. Поэтому я пока тут секретный слайд. Вот. Так, что меня смущает вот в этой всей теме об интерпретации? Интерпретация – это некое конечное количество правил, которые описывают сложную систему. Вот модель, ну, это, наверное, сложная система. Вот. И из теории систем известно, что никакую сложную систему нельзя описать конечным набором правил. Вот. То есть всегда будут какие-то такие поведения, которые, ну, не будут укладываться вот в этот конечный список правил. И у нас получается, что никакая интерпретация не является достаточной. Не является верной. Все модели не верны, но некоторые из них полезны. Если мы возьмем распределительный щит и напишем на нем «не влезай, убьет», мы на самом-то деле здорово погрешим против истины. Я много раз влезал в распределительные щиты, меня ни разу не убило. Но в целом это очень полезное обобщение сложившейся практики. Вот. То есть все-таки… То, что вот вы говорите, это называется суррогатная модель. Смотрите, мы можем обучить нейронку принимать очень сложные решения. А затем мы можем обучить логрек, который будет имитировать решение этой нейронки с 80-процентной точностью за примерно одну стомиллиардную ее ресурсов. Вот. И говорить, ну знаешь, чаще всего эта нейронка принимает решение так. Понятно, есть нюансы, но общая идея такова. То есть суррогатные модели, которыми часто объясняют черные ящики, они именно таковы. Вот. Что мы строим простую модель, которая помещается в голове человека, для объяснения сложной модели, чтобы он как-то с ней крутился. Если человеку нужно точное, именно точное описание системы, то не может быть точного описания системы, которая проще, чем сама система, как вы верно заметили. Чуда не бывает, и вечные двигатели не бывают, и бесконечное сжатие файлов тоже не бывает. Вот. Но, как правило, нам не нужно знать все. Нам зачастую, мы же других людей не знаем, мы как-то интерпретируем, что типа, ну вот Петя не любит кошек, например, да, а с Васей здорово сходить на футбол, например. Это вообще сильное упрощение, и Петя, и Вася, но оно полезно. Понял, да. Наверное, меня этот устроит. Я тут просто подумал, что когда человек принимает какое-то решение, мы его можем спросить и диалог с ним выстроить, почему он принял именно такое решение. Ему понадобятся еще усилия для того, чтобы это передать эту информацию нам. У меня ощущение, как будто бы с языковыми моделями тоже можно как будто бы общаться. Вот, вы в самую суть ухватили. Во-первых, есть интересный научный результат, что люди, принимая этические решения, принимают их, сначала их принимают, а потом сами для себя их рационализируют, объясняют. То есть это процессы, которые в обратном порядке идут в мозги. То есть это говорят на томографе видно, что сначала он принял решение, а потом как-нибудь более-менее прилично его объяснил. А большинство решений сложных профессионал объяснить не может, он зависнет. Это тот самый анекдот про сороконошку, который спросили, какой ногой она сейчас пойдет, она зависла. Но есть, вот тут было года-два назад, мода такая на объяснение моделей. Мы учим модель синтезировать текст. И мы такие, модель-модель, почему ты не дала кредит? Ну, вы знаете, в сложившихся условиях людям с таким низким доходом кредит давать нельзя. Кайф. Вот, другое дело, что никакого отношения к процессу реальной принятия моделей, этого нет. То есть если вы читали такую книгу Пелевина «Зенитные суры альф-эс-би», там главный герой с помощью запроса таких объяснений завешивал боевую компьютерную систему. Вот, и тут именно вот это, то есть пошло много статей, смотрите. Нейронные сети научились объяснить сами себя, потом как-то притихли. Я думаю, что мы к этому придем, но не сейчас пока еще. Прочитайте очень-очень, не то чтобы жизнеутверждающе, она, конечно, грустная. С интерпретацией картиночных моделей тоже проблемы. Это, конечно, можно там свёртки порисовать и сказать, смотрите, мы что-то понимаем. На самом деле ничего не понятно. С интерпретацией картиночных моделей на самом-то деле есть прекрасный инструмент, например, ГрадКам. Из всего, что есть про картинки, ГрадКам на самом-то деле самый простой, объясняемый и надежный. Про картинки много чего есть, но я тут на пальцах могу объяснить прямо вот на этой вот картинке. Предположим, у нас есть сверточная сеть, да, и в конце сверточной сети у нас есть просто классификатор. И как бы мы могли объяснять нашу нейронку? Мы могли бы пробросить градиент и посмотреть, какой конкретный пиксел повлиял на классификацию. Но мы придем вот к этим фонарям средневековым замкам обязательно, в смысле, так и мы пришли. А есть другой способ, смотрите, мы можем посмотреть, построить, так сказать, рецептивные пятна поля. То есть, грубо говоря, где-то от серединки мы можем посмотреть, с какой интенсивностью вот это вот пятно действовало на вот этот вот конкретный. То есть мы пробрасываем градиент по полносвязной сети, а затем этим градиентом закрашиваем рецептивное поле через сверточные слои. И они у нас перекрываются и получаются такие яркие пятна, неяркие пятна. И они действительно показывают, куда нейронка смотрит, когда принимает решение. То есть из всего, что есть в готовых библиотеках и на пальцах, делается к городкам, на мой взгляд, это лучше для сверточных сетей. Вот, то есть прям отлично работает. Так можно оверфитинг какой-нибудь случайно найти, когда ты подаешь картинку, она делает предположение, там нарисована машина. Тут такая как бы интересная мысль, что как бы при интерпретации здесь на данный момент мы как бы задаем вопрос, почему? То есть почему так делает модель? Но это как бы неправильная схема, то есть смысл в том, что модель, ну как бы это не какой-то живой организм, ничего. То есть это просто, ну блин, набор цифр. То есть она не понимает, почему. А скорее там нужно было бы задавать вопрос, что она делает. То есть, условно говоря, мы когда делаем интерпретацию модели, мы не спрашиваем, почему. Мы спрашиваем, что она делает, чтобы потом можно было посмотреть, как эта модель будет работать на исходных данных. А почему она это делает? Просто потому, что данные были такие вот, ну как бы условно говоря, на каких данных она была обучена. Условно говоря, именно такое, ну как бы такие там attention и в итоге будут складываться. Вы говорили примерно, например, с замком, да? Соответственно, если бы, скажем, на тассете было большое количество замков именно с таким фонарем, то, соответственно, attention будет именно на этот фонарь. Вот, то есть как бы поэтому я думаю, что интерпретация нужна не для того, чтобы понимать, почему эта модель как бы так делает, а чтобы понимать, что она делает конкретно в данном ситуации и чтобы понимать, как она будет себя вести на последующих данных. То есть как бы вот такая мысль. Но тут, наверное, я своими словами попробую перефразировать, что модель не действующий агент. У нее нет своей собственной воли. И что мы ей в данных дали, то она и примет. Но какое влияние оказывает то или иное изменение вектора входных признаков на результат работы модели? Вот. И тут тоже есть интересный момент, очень скользкий. Дело в том, что каждый студент слышал, что корреляция не есть причинность и все такое прочее. И тем не менее мы при интерпретации модели прямо вот через раз путаем корреляцию и причинность. Есть более строгие подходы, когда мы подходим с всей мощью causal inference и econометрики к нашим ML-моделям. Вообще, кстати, тут следует сказать о разнице между ML-щиками и эконометристами. ML-щики и эконометристы друг на друга смотрят с некоторым презрением. Потому что эконометристам, например, все равно, что будет в результате. Главное, что влияло на результат. То есть типа вот это вот важный признак. А что там получилось? Такая разница. Тогда как ML-щику важно, что получилось. А как оно получилось? Ну, по большому счету работает, но не трошанно работает. Так вот, именно эконометристы, они испокон веков интересовались такими интересными вопросами. А почему, собственно говоря, люди перестали нести деньги в банк? А почему у нас больные здесь, в этом районе города, чаще болеют, допустим, или эпидемиологи? То есть они интересовались именно причинностью. И вот тут как раз есть следующее направление развития ШАПа, когда shape-evaluus скрещивает с нормальным causal inference. То есть там проверяют и внедряют туда явные утверждения о причинности. Надо понимать, что без интервенции нет причинности. То есть если вы, допустим, топнули ногой, там, скажем, упал шкаф. Не топнули ногой, шкаф не упал. Мы пытаемся понять, влияет ли топ ногой на падение шкафа, например. Как в эту модель, где тут интервенция? Ну, то есть вот эти вот вопросы немножко непонятные. И есть, например, расширение shape-evaluus, asymmetric shape-evaluus, которое явно говорит, вы знаете, я точно уверен, что ругательные слова влияют отрицательно на тональность. Там немножко по-другому. То есть как работает в принципе shape-evaluus? Предположим, что у нас есть 10 признаков, и все они об одном и том же, они скоррелированы. Shape-evaluus на самом-то деле размажет это значение по всем поровну. И в результате у вас получится как бы не очень важное. А вы точно знаете из каких-то априорий предположений, что один из них на самом деле важный, а вторые просто его слепо копируют. И вы можете библиотеке asymmetric shape-evaluus сказать, знаешь, вот это важный признак, а вот это просто его жалкие копии. Учти это, пожалуйста, при распределении. Она учтет. У меня с некоторой моей помощью ребята написали реализацию гугловской статьи про asymmetric shape-evaluus. Сам гугл сделал ее для R, ребята написали для Python. И в общем, ну, к сожалению, тут случился коронавирус и все прочее. Вот так внедрение библиотеки затянулось. Вот, что я еще хочу сказать, раз уж я здесь оказался. 29-го будет ODS-овский Хэллоуин. И у меня может быть там будет с двумя секретными слайдами этот доклад. А может быть и нет, посмотрим на загрузку. Но там будет точно много других интересных докладов. Еще у нас есть у ODS-а слаг. У кого, ну, туда новых не очень принимают, зато есть у ODS-а матриксы. Туда принимают новых, если кому-то надо в матрикс стучитесь, я вас туда проведу за ручку. Что? Ну, в матриксе какое-то количество народу уже есть. Приходите, и вы там тоже будете. Вот. Там жизни особенно пока нет, но с каждым днем ее все больше и больше. Что, да. Хэллоуин будет в матрикс. В смысле, Хэллоуин будет онлайновский или оффлайн? Да, Хэллоуин будет онлайн весь. И туда же войдут доклады, которые не попали на дата-сет. О, на дата-фест в Новосибирске, который мы проводили. То есть кто-то не смог приехать по техническим причинам, еще по каким-то. И они будут выступать онлайн на ДТ Хэллоуине. Ну, вот, наверное, все. Спасибо. Конечно же, это зайдет в запись. Спасибо большое, что приехали, рассказали такие классные доклады. Запись у нас есть, люди нас смотрели в онлайне, даже задавали вопросы. Все было очень классно. Ура. Спасибо большое. Спасибо. Спасибо.