
- 05.06.2022
- 05.10.2025
- выступления
- #interpretable_ML
Лекция в треке ReliableML Data Fest Online.
Слайды можно скачать тут interpretable2022.pdf
Текстовая расшифровка, пока не очень вычитана:

Дмитрий Колодезев: Я тот самый Дмитрий Колодезев, который всем рассказывает про интерпретируемость. Работаю в ООО «Промсофт». Мы с Ириной Голощаповой вместе все время устраиваем про это секцию. Я хотел рассказать, что нового в интерпретируемости машинного обучения в 2022 году и столкнулся с проблемами. Во-первых, не так много с 2022 года прошло, и большая часть была занята совсем не интерпретируемостью.

А как раз в канале спросил кто-то: «А будет какой-нибудь рассказ для новичков?» В ответ Ирина сурово сказала, что нет, у нас все подготовленные. Я решил рассказать немножко для тех, кто случайно сюда попал, что такое интерпретируемость.

Еще дисклеймер: говоря про интерпретируемость, часто путают термины interpretability и explainability. Я тоже путаю. Interpretability скорее характеризует нашу способность понять, как модель работает в принципе. Например, самый крайний случай – когда мы берем и начинаем лезть в карты активации нейронов, распечатывать деревья градиентного бустинга и так далее. Мы получаем массу информации, которая детально описывает то, как работает модель, но она совершенно бесполезна, потому что мы не можем ее усвоить.
Другой вариант – это explainability. Свойство explainability характеризует нашу способность объяснить, как был получен конкретный результат. Крайний случай - самообъяснение модели, когда мы спрашиваем модель на русском языке: «Расскажи мне, как ты приняла это решение». Она говорит: «Потому что возраст у этого заемщика больше, чем…» При этом нас не так интересует, действительно ли решение было принято таким образом, как то, насколько это объяснение было красиво и хорошо.
Эти термины обычно используют вперемешку, и я тоже буду так делать. Еще важно: термины interpretability – это свойство не модели, а наше. То есть для кого-то линейная модель вполне интерпретируема, для кого-то нет. Для кого-то нейронная сеть вполне интерпретируема, для кого-то нет. Интерпретируемость всегда возникает в каком-то контексте. Для одних людей DAG-и интерпретируемы, для других нет.

Для тех, кто досмотрит до этого слайда, шпаргалка: как же на самом деле делать интерпретируемость. В этом году было много нового и интересного, но если вы делаете модель на табличных данных, то вам дорога в SHAP. С помощью SHAP вы можете определить значимость признаков для вашего предсказания, то есть какой из признаков повлиял на то, что модель сказала «даем кредит» или «не даем кредит».
Еще с помощью SHAP вы можете построить модель значимости признаков для функции потерь. Так редко делают, но это хороший подход. Можете построить модель, которая предсказывает, какой из признаков отвечает за ошибку модели, за loss. Вы смотрите: что-то модель у вас учится плохо, что-то у вас loss великоват, не падает. Строим модель, которая считает вам Shapley Values - как влияют признаки на функцию потерь. И говорим: «Ага, нам возраст заемщиков не дает функцию потерь уронить, наверное, что-то у нас с этой переменной не так».
Есть библиотека InterpretML. В ней собраны все важные и нужные методы. По большому счету для табличек больше ничего не нужно.
Совет, который я всегда даю: прежде, чем строить модели, даже не то, что их интерпретировать, а вообще строить, нарисуйте сначала график среднего отклика целевой переменный от ваших признаков – Mean Target Plot. Нашел у себя в выступлении 2019 года на датафесте: показывал там, как он рисуется. Для него нет толком библиотеки никакой просто потому, что это тривиально.
Прежде, чем строить модель, хорошо бы посмотреть и нарисовать Mean Target Plot. Вы увидите, чему эта модель научится. Все равно модель научится тому, что у нее есть в данных.
И про интерпретируемость, конечно, надо читать Мольнара, там все написано.
Если вы работаете с картинками, ваш друг – GradCAM. GradCAM – алгоритм, который позволяет подсветить на картинке рецептивные поля, то есть какие области картинки повлияли на решение модели. Там есть тонкое различие между тем, на что обратила модель, и что повлияло на ее решение. Например, если придет человек в огромной шляпе-сомбреро и предложит вам инвестиционный продукт, то я надеюсь, что ваше инвестиционное решение будет зависеть не от размеров его шляпы, на которую вы, конечно, обратите внимание, а от условий самих инвестиций.
И этот пример тривиальный, когда мы видим, что обращаем внимание на одно, а решение принимаем исходя из другого. В нейронных сетях очень часто любят построить карты насыщенности, то есть пробрасывают градиент на исходные пикселы и говорят: «Смотрите, отсюда был большой градиент, следовательно, модель на этот угол картинки смотрела». Нет же просто этот угол картинки был достаточно необычный для того датасета, на котором модель. GradCAM эту проблему обходит.
И для картинок, только для PyTorch есть прекрасная библиотека Captum, в которой все собрано вместе под рукой. Примерно как InterperetML только для картинок.
С трансформерами NLP у меня опыт меньше визуализации, потому что я не очень понимаю, зачем их визуализировать. Но из того, что я смотрел – BertViz, который визуализирует attention, дает, наверное, самое лучшее. Это шпаргалка.

Основные сценарии интерпретируемости, то есть зачем вообще модель интерпретировать, все распадаются на примерно три группы. Первая – это откладка или разбор инцидентов, то есть когда модель у нас не работает так, как нам нужно. Тогда имеет смысл смотреть Shapley Values, есть смысл смотреть на влиятельные семплы, то есть какие именно точки нашего обучающего набора данных повлияли на-э то или иное решение. Для отладки – это самое то.
После того как мы модель сделали, нам нужно самим провести дымовой тест. Дымовой тест – это когда мы включаем прибор, он не задымился, значит, хорошо. А потом тот, кому мы сдаем модель, должен ее как-то верифицировать, то есть убедиться, что то, что мы сделали, работоспособно.
Тут хорошие подходы – это Shapley Values, это контрпримеры. Например, если у этого заемщика был бы чуть-чуть доход побольше, тогда бы мы ему кредит дали. И набор самых лучших: лучшие заемщики, идеальные заемщики, самые худшие заемщики. То есть те, которым мы точно дадим кредит, те, которым мы точно никогда не дадим кредит. Обычный бизнес смотрит в них и сразу наши ошибки находит.
Третья группа сценариев – это социализация/кооперативность. Дело в том, что мы как люди для того, чтобы нам продуктивно работать с чем-то, будь то другой человек или модель, нам надо примерно понимать, как он себя ведет. Нам нужно понимать границы применимости модели, нам нужно понимать, когда на нее полагаться, когда не полагаться и когда она будет выдавать чушь, а когда она будет хороша. И что в нем можно совать, что нельзя.
Тут отлично подходят глобальные суррогатные модели и якорные примеры. Якорный пример – это когда мы отбираем минимальный набор признаков, который повлиял на принятое решение. Например, нам все равно, какой пол у человека, образование. Главное, что у него высокий доход и куча имущества. Даем ему кредит, надо будет – отдаст.

Это введение. И основные тренды индустрии укладываются в следующие группы. Во-первых, на каждом датафесте кто-нибудь рассказывает, что ученые изобрели интерпретируемые модели. То есть модели, которые наконец-то работают так, что их можно понять обычному человеку. И теперь мы только их и используем, и будет у нас счастье.
Прошлый раз это были обобщенные аддитивные модели. Ничего они не решили. Они интерпретируемые, конечно, но только авторами.
Следующий тренд: ученые выяснили, что интерпретируемость бесполезна. Есть куча статей, хороших и полезных статей, которые говорят: «Ребята, от вашей интерпретируемости только вред». На самом деле не только вред, но и польза тоже.
Потом периодически все больше и больше регуляторов начинают требовать объяснений. Как работает ваш алгоритм? Как работают ваши рекомендации? Как работает то, как работает се. Надо понимать, что каких бы от нас объяснений не требовали, мы всегда сможем их нарисовать. Они могут не иметь никакого отношения к реальности, но всю нужную отчетность любой инженер нарисовать сможет.
Еще один тренд: библиотека X все объясняет, и думать не надо. Это особенно в облачных сервисах. Есть куча облачных сервисов, которые по праву гордятся своими объяснениями интерпретируемости. И все это тяготеет к тому, что человеку говорят: «Не надо думать. Просто ты запустил модель, обучил, тебе показали графики, и так это все работает». На самом деле думать все равно приходится, потому что эти графики рисуются теми же самыми библиотеками Shapley Values и GradCAM, которыми мы все пользуемся. Там те же самые грабли.
И тренд последних лет – модель научилась объяснять сама себя. Тут нейрофизиологи подсказывают нам, что люди сами объясняют свои действия следующим образом. Они сначала принимают решение, а потом сочиняют правдоподобное объяснение, почему они приняли то или иное решение. И модели точно так же. Они могут, конечно, вам объяснить, но это не будет иметь никакого отношения к тому, как они приняли решение. Хотя, конечно, правдоподобно.

Из того, что действительно нового было в этом году, во-первых, это Responsible AI Toolbox. Это старый инструмент, но вечно новый, потому что они очень бодро развивают его и постоянно добавляют туда новые модельки, новые инструменты. Они – это Microsoft. Microsoft развивает свой облачный сервис Azure. И значительная часть того, что они делают там с ML, идет в опенсорс. Этот Responsible AI Toolbox он и есть, насколько я понимаю.
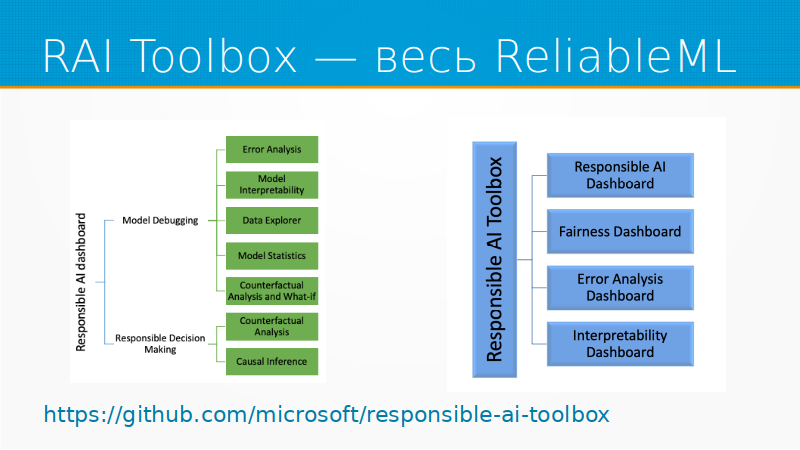
Для табличных задач это просто лучшее из того, что есть. Освоить его и использовать, больше никуда не смотреть. RAI Toolbox позволяет нам искать проблемы в модели, диагностировать их и каким-то образом обходить. В него входят четыре блока: про интерпретируемость, про анализ ошибок, про fairness – не обижали ли мы какие-нибудь группы населения. И Responsible AI Dashboard, который собирает все это вместе и позволяет в числе прочего выполнять анализ причинности, causal inference.

Для картинок стоит отметить бурно развивающийся инструмент Captum, для PyTorch. Они выпустили в этом году новую версию – 0.5, то есть он до сих пор в бете. В нем есть все что нужно для картинок: и Guided Grad CAM, и SHAP, и DeepLift, и все, что только придет вам в голову.

И они добавили туда прекрасную возможность Influential Examples. То есть у вас есть картинка, модель на ней выдает результат, а еще вам показывают примеры из датасета, которые повлияли за и против этого результата. То есть вы можете сразу увидеть, что эта ошибка обусловлена этим примером в датасете. Датасет почистить, и как нас учит Andrew Ng: если у вас есть лишние два месяца, лучше их потратить на чистку датасета, чем на дообучение модели. Captum в этом помогает самым простым и прямым образом.

Есть прекрасная статья про VL-InterpreT. Про что она? Сейчас куча моделей трансформеров, которые сочетают обработку картинки и текста. Их много, они хорошо работают, но для них нет нормального инструмента, которые бы их интерпретировали. И сделали VL-InterpreT, у него единственный недостаток – что он пока доступен только в виде ролика на YouTube. У них на GitHub написано: «Вот-вот сейчас-сейчас мы код выложим». Но учитывая, что буквально несколько недель назад они статью опубликовали, наверное, действительно выложат. Но ролик прекрасный. Я жду.
Вопрос из зала про слайды. Слайды свои я выложу, у меня уже лежат в интернете, я ссылку дам. Кроме того, у нас они на странице трека есть. И я думаю, что (мы с Ириной это обсудим), что они будут еще в телеграмм группе про Reliable ML.
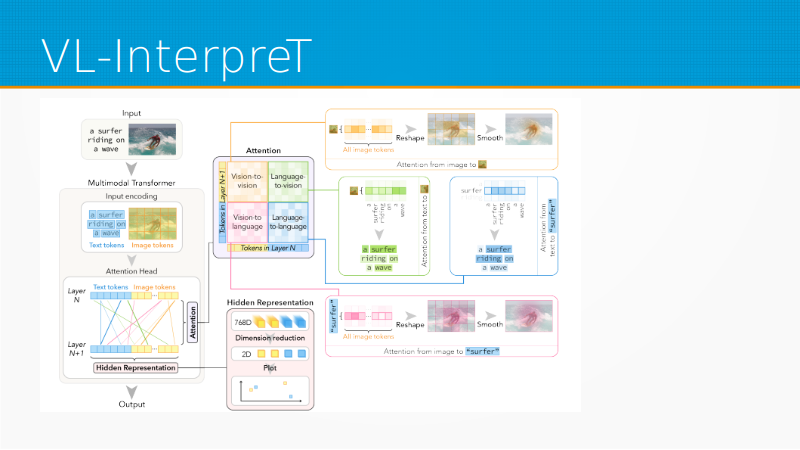
VL-InterpreT не делает ничего сверхъестественного. Он берет attention с картинки, берет attention с текста и просто вместе их аккуратно и хорошо показывает. Получается прилично.

Например, человек, который смотрит на конверт. Почему мы думаем, что он смотрит на конверт? Поэтому мы думаем, что он смотрит на конверт, нам подсветили глаза.
Инструмент всем хорош, кроме того, что попробовать его пока нельзя. Как я говорил, что он просто недавно зарелизен.
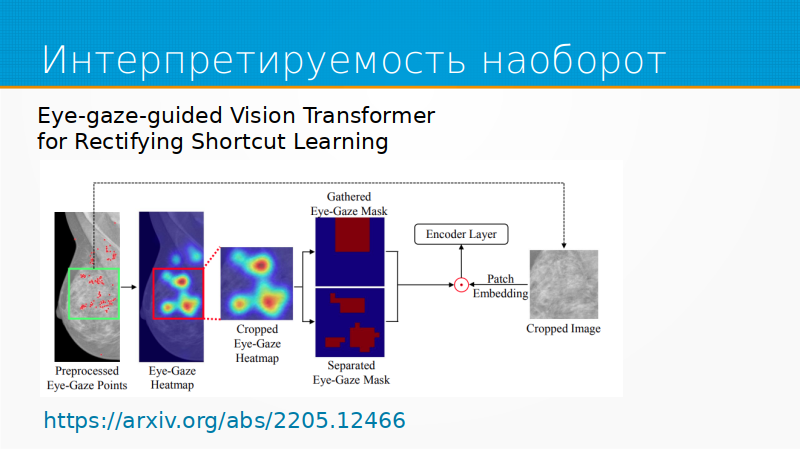
Из вещей, которые мне по-настоящему понравились, – это статья про интерпретируемость наоборот. В рекламе давно есть такая штука как отслеживание того места, куда мы смотрим – eye Tracking. И эта технология используется при анализе рекламы или сайтов, юзабилити-тестировании уже лет 20, наверное. И вот наконец-то ее кто-то додумался, чтобы учить attention. У нас есть рентгеновские снимки. Мы сажаем перед рентгеновским снимком специалиста-радиолога, он смотрит на этот снимок. Мы смотрим, куда он посмотрел, делаем карту attention, кропаем изображение по этой части и принимаем решение.
Но это еще один шаг в сторону матрицы, во-первых, а во-вторых – это сильное упрощение разметки. В значительной степени проблема разметки сейчас в том, что она собирается тяжелым, мучительным, противоестественным способом. А если мы могли бы раздавать разметку, просто глядя на картинку, то сбор разметки бы, наверное, упростился.
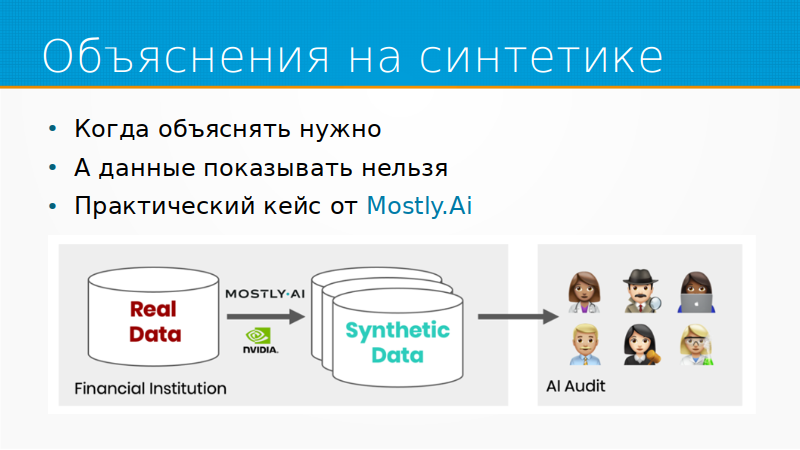
И из практических кейсов, не связанных с rocket science, когда все просто, но думаешь, почему я сам до этого не додумался, – объяснение на синтетике. Если тут Иван Комаров нас слушает. Я эту идею вам продаю уже второй год. Объяснение на синтетике – представьте себе, что вы банк, и вы построили модель. И к вам приходят и говорят: «Пожалуйста, объясните, как у вас работает модель». Вы: «К примеру, возьмем данные этого пользователя». А данные этого пользователя вы взять не можете, это персональные данные. Как же вы можете объяснить модель, если вы не можете показать данные?
Очень просто. Мы генерируем синтетические данные, которые неотличимы, что-то вроде adversarial validation, от наших реальных данных. И затем мы берем нашу модель и показываем, как наша модель работает, подсовывая ей синтетические данные.
Mostly.ai – очень интересный стартап, построенный вокруг синтетических данных. Если бы не санкции и все такое, я, наверное, у нас такой же запустил бы. Но боюсь, что у нас просто рынка не хватит.

И про объяснение не на тех данных, на которых училась модель. Я об этом часто говорю: мы не обязаны строить интерпретацию модели на том же наборе признаков, на котором мы ее учили. И иногда это даже неполезно. Почему? Потому что признаки модели, как мы сегодня уже обсуждали на одном из выступлений часто сами неинтерпретируемы.Например, национальность или день недели понятны человеку.
Но к тому моменту, когда признак попал в модель, он прошел через какой-нибудь генератор признаков, и после этого потерял интерпретируемость. Мы посчитали на нем гистограмму, мы сделали по нему One-Hot Encoding, мы выкинули часть из этих one-hot-encoding-значений, потому что они слишком редкие или слишком частые. В результате мы получили неинтерпретируемые признаки.
Если мы объясним пользователю модель на основании этих трансформированных признаков, он их не поймет. Но мы можем обучить, например, LIME на другом наборе признаков, не на том, на котором учились, но на том же таргете. И все будет хорошо работать, оно будет понятно. И, может быть, даже будет правдой. То есть это будет плохая интерпретация, но хорошее объяснение.
У Мольнара, между прочим, у которого я эту идею встретил, это написано было много лет назад, он рекомендовал учить так LIME. Но можно учить все что угодно. Можно и SHAP так учить, если немножко постараться.

Из интересных исследований и библиотек этой весны – это HIVE. Это набор инструментов для изучения того, что люди поняли из интерпретированности, как люди проинтерпретировали интерпретированность. Вот у вас есть объяснения моделей, а как мы поймем, какую информацию из них извлекли? Как и все исследования, открытия одни и те же: если пользователю показать красивую картинку, то он поверит в модель, неважно что модель будет выдавать, главное, чтобы картинка была красивая.
Если у нас есть хорошая, отлично работающая модель с плохой картинкой и плохая модель с хорошей картинкой, то наш бизнес-пользователь всегда выберет модель с хорошей картинкой. Поэтому будьте осторожны, рисуя красивые картинки.

Из разного интересного: Например, обзор про интерпретируемость в реинфорсмент лернинг. Если кратко, это возможно. Потому что мне всегда было интересно, как такие вещи можно интерпретировать.
Однажды мне довелось говорить с человеком, который разрабатывает искусственный интеллект для волейбольного симулятора. Я говорю: «А как ты его интерпретируешь?» Он говорит: «Никак. Мы ролики записываем и показываем экспертам. Они говорят, что что-то тут не то». Оказывается, что наука ушла дальше, чем просто записать ролик и показать экспертам. Есть хороший обзор.
Дальше вторая статья. Интерпретируемость саму по себе же тоже можно измерить. У нее есть некоторое количество метрик, и товарищи добавили еще метрики, говорят, давайте мерить чувствительность и стабильность интерпретации моделей NLP.
И они померили кучу метрик, и выяснилось, что все плохо. Одна модель хороша по одной метрике, совершенно плоха по другой. В общем, нет в жизни счастья. Однако, чем больше люди пробуют измерить интерпретируемость, тем мы ближе к тому, чтобы интерпретируемость стала чем-то нормальным.
И третье: люди покусились на святое. Мы все считаем, что неглубокие деревья – это идеальная интерпретируемая модель. На самом-то деле деревья, как правило, перегружены информацией, много лишнего, а список правил более понятен человеку. Если у человека маленький доход – не даем кредит, а если большой, то идем дальше, то есть такие правила. Список правил люди понимают хорошо, а деревья люди понимают плохо. Деревья тоже не вполне интерпретируемы.

Тут лежат слайды, ссылочка будет. Мне можно задавать вопросы.
Ирина Голощапова: Наш народ заслушался, и не хотелось отвлекаться на вопросы.
Дмитрий Колодезев: Потерял аудиторию.
Ирина Голощапова: Наоборот. Давайте чуть активнее пишите вопросы. Дима, может быть, ты еще прокомментируешь про Causal Shapley Values. Это тема, которая не весны 2022 года, конечно, но тема, с которой ты сильно связан, и много классного уже делаете.
Дмитрий Колодезев: Causal Shapley Values – это один из глубочайших провалов в моей жизни. Комментировать ее. Сначала мы разработали эту библиотеку сами и не очень удачно. Затем я взялся помогать Григорию и Кириллу разрабатывать ее, и тоже меня завалило проектами, фактически бросил ее.
Поэтому что я хочу сказать – то, что Shapley Values очень неустойчивы. Объяснение Shapley Values очень неустойчиво. Вы взяли чуть-чуть модель и пошатали или какое-то количество данных выбрали, или другой сид вы у модели выбрали, получили другие Shapley Values.
Это неплохо, потому что все эти объяснили неправдоподобные, но бизнес-заказчику это немножко странно. Сегодня ты говоришь одно, завтра ты говоришь другое. И тут есть два решения этой проблемы.
Вопрос из зала: Насколько инструменты готовы для использования с промышленным объемом данных?
Дмитрий Колодезев: Те инструменты, которые я показывал, в большинстве своем готовы. И Captum готов, и Interpret готов. Interpret работает в облаке Azure, вполне промышленные объемы данных на них гоняют.
Ирина Голощапова: Облако Azure теперь не у всех работает.
Дмитрий Колодезев: Что ж поделать. Кстати, облако Amazon в России вполне можно купить, кто не знал. Организация вполне может купить. Идете в Softline, заключаете договор, платите за него рублями. Softline мне за рекламу не платит. Но это работает. Я думаю, что у них можно и Azure купить, но я не пробовал, не нужно было.
Проблемы Shapley Values.
Вопрос из зала: Трансформеры NLP, трансформеры неинтересны для визуализации?
Дмитрий Колодезев: Они интересны для визуализации, просто я не понимаю, какую я пользу могу из визуализации извлечь. У меня есть большая модель. Я смотрю в них и вижу, что как-то она не так визуализирует мои слова, мне не нравится. Что я с этим сделаю?
Если у меня есть маленькая табличная модель, я пошел ее доучил, посмотрел, сравнил.
А языковые модели столь сложны, что по большому счету их уже не столько учат, а в лучшем случае чуть-чуть доучивают. Или вообще подбирают подводки. То есть с языковыми моделями проблема, если вы не живете языковыми моделями, то, наверное, смотреть их лишний раз не надо, чтобы не расстраиваться.
Я не понимаю, какие выводы можно сделать посмотрев Bert, поэтому и не пользуюсь визуализацией, а так-то трансформеры интересны.
Про attention есть история, что attention – это та же самая saliency map в нейронках, то есть он подсвечивает не то, почему модель принимает решение, а то, на что она обращает внимание. Это могут быть просто необычные для набора данных вещи. То есть внезапно что-то странное появилось в наборе данных, модель обратит на это внимание. Необязательно, что она будет учитывать это для принятия решения.
Да, Вадим пишет, что очень много статей, которые говорят, что attention – это не объяснение. Я про это и говорю, что attention означает, что модель обратила внимание, но вовсе не обязательно, что она поэтому приняла решение.
Возвращаясь к Shapley Values. В Shapley Values две проблемы. Первое – что его честно не считают, иначе бы это заняло бесконечное время.
А Shapley Values вычислительно сложен. И если его считать по-честному, то с большим количеством признаков его не посчитать, поэтому его алгоритмы аппроксимируют. И когда они аппроксимируют его, получается, что семплируют из какого-то подмножества признакового пространства. И можно повысить стабильность Shapley Values, семплируя из того исходного многообразия, где лежат точки. Не все комбинации точек возможны, давайте семлировать только из возможных наборов комбинации, и это расширения Shapley Values on manifold (на многообразиях).
А второе решение проблемы: зачастую ошибки Shapley Values будут размазаны по скоррелированным фичам. Почему Shapley Values плохо использовать для отбора признаков. Предположим, что у вас есть 100 хороших признаков, но они все скоррелированы. И еще один, но не такой хороший, но с ними не скоррелирован. Shapley Values будет равномерно размазан по всем 100 признакам. И у каждого из этих признаков он будет маленький, а у средненького признака он будет большой.
Поэтому вы: давайте мы выкинем все признаки с низким Shapley Values, оставим только с большим. Выкидывайте все признаки с низким Shapley Values, модель хоп – перестала работать. Это потому что Shapley Values размазывается по скоррелированным признакам, и ничего тут не поделаешь. Но мы зачастую можем скормить Shapley Values наш граф причинности и сказать: «Ребята, признаки, конечно, скоррелированы, но это у нас причина, а это у нас следствие». И если Shapley Values эту информацию дать, то он очень разумно сможет себя повести. Но для этого нужна библиотека, которая поддерживает эти асимметричные Shapley Values.
Про это статьи, есть библиотека, которую Григорий и Кирилл написали. Кириллу досталось больше всех, он писал код, а мы им руководили иерархически. Это про асимметричный Shapley Values. Есть библиотека для R, которую написали ребята из Google. Вот про Shapley Values. В комментариях Ирина написала: у Татьяны Шавриной про интерпретацию трансформенных моделей есть совершенно шедевральный доклад, который позволяет понять, где на каком слое какие концепты трансформер выучил и понял.
И причем там интересно, насколько я помню, у разных языков на разных уровнях разные концепты выучиваются. Поэтому если вас трансформеры хоть чуть-чуть интересуют, то стоит идти смотреть.
Еще вопрос был: «Если мы LIME учим на понятных людям признаках, мы же объясняют только понятные признаки, а не те, которые, возможно, важные для решения модели?» Здесь какая хитрость: мир обычно скоррелирован. У нас в жизни… Вот такой пример, я не помню, кто мне недавно его рассказывал, что можно определить по фотографии характеристики человека. Или это скоринг, или что-то еще. Уже не вспомню, но грубо говоря, если человек в рубашке, то у него хороший кредитный скор, если он в майке сфотографировался, то может быть плохой.
Но это, наверное, чисто российская тоже вещь, потому что если вы в какой-нибудь Калифорнии людей фотографируете, то в рубашках у них будут продавцы пылесосов, а в майках гуглеры. Но общая идея такая. Преступность по лицу – тоже был такой пример. Зачастую вещи между собой скоррелированы в животной природе всегда.
И зачастую в бедных странах есть люди не очень умные, потому что они в первые два года получали мало белка в пище. У них все хорошо, может быть, с наследственностью было, просто в детстве реально не повезло. И у них низкий рост. И есть простая корреляция низкого роста и умственных способностей. Вы можете пользователю объяснить: «Знаешь, мы просто не берем людей роста ниже метр 176 и все». И это будет неправда, но это будет для бизнеса вполне нормально, потому что действительно люди с высокими IQ будут обычно ростом высокие, потому что в детстве y них было нормальное питание. Это очень жесткий, но реальный пример.
В жизни обычно признаки идут толпой скоррелированы. И все равно по какому из коррелированных признаков объяснять до тех пор, пока бизнес может на них посмотреть и увидеть. То есть если у вас есть набор признаков, и мы можем объяснить по любому из них, надо выбирать тот, который более понятен человеку.
У нас есть спорт. Каждые полгода мы с Ириной обещаем сделать курс. Сначала про интерпретируемость, потом про causality, потом про reliable ML. В этом году мы его все равно сделаем. Я в очередной раз обещаю. Более того, когда датафест кончится, я начну записывать его первые лекции. Ирина, насколько я знаю, уже какие-то вещи подсобирает. И в нем будет чуть-чуть ML System Design. Но не про тот System Design, который на собеседованиях, а тот ML System Design, который позволяет вам запустить вашу модель в работу.
За пределами разработки моделей есть куча важных шагов, которые нужно сделать для того, чтобы ваше решение потом взлетело. То есть у вас может быть прекрасная модель, но не взлетит, потому что она использует признаки, которые на проде вам не доступны.
Ирина Голощапова: Я могу чуть-чуть, может быть, тоже дополнить, набросить. ты говорил про то, что модели научились сами писать объяснения. Кажется, с точки зрения применения довольно интересная вещь может быть. У нас как один из кейсов, что геомодель у нас есть, которая прогнозирует выручку открывающихся магазинов. Мы ее для бизнеса интерпретируем классическим SHAP, всем нравится. Но людям бизнесовым, как правило, лень смотреть график, что где было, какой фактор куда.
Поэтому мы постепенно сначала руками стали для них писать объяснение в нескольких словах, что показывает график. И в итоге сейчас автоматизировали эти комментарии, по сути, зашили этот в сервис. По сути, еще один слой упрощения, уже текстом ты объясняешь, что тебе показывает график. И это прямо топ в плане применения в нашем кейсе. Что ты здесь думаешь?
Дмитрий Колодезев: Это важная вещь, потому что я все время об этом говорю, что интерпретируемость – это генерация данных для обучения модели в голове пользователя. То есть все наши графики - это обучающие данные для этой модели. У нас есть модель в голове пользователя, которую он сам создал, и мы ее обучаем на обучающих примерах. Все, что мы можем сделать, – это дать такие обучающие примеры, чтобы обучить ее или доучить ее в нужном направлении.
И наши все графики про интерпретируемость – это обучение модели в голове пользователя. И если они правильны, хороши, но не обучают модель в голове пользователя или обучают ее неправильно, то это плохие графики.
Ирина Голощапова: И, наверное, они могут быть хорошими, но неориентированными на тот вопрос, который задает голова пользователя. То, что мы говорим про интерпретируемость, зависит от вопроса.
Дмитрий Колодезев: Вся интерпретируемость ценна ровно… За пределами отладки, конечно, то есть отладка – это отдельная история. Но интерпретируемость для конечных пользователей ценна настолько, насколько она позволила построить полезную модель в голове пользователя. А что такое полезная модель? Та, которая позволила им работать продуктивнее. Она, может быть, неверной технически, но она позволила лучше взаимодействовать с моделью. И любая интерпретация, которая не помогает строить эту модель, бесполезна.
Я назвал у себя в сценариях это социализацией модели. В конечном итоге у людей в фольклоре есть специальный раздел всегда для всяких зомби, кого-то еще. То есть это кто-то, кто выглядит как человек, но ведет себя непредсказуемым, непонятным, нелогичным способом. Он опасен. Люди боятся незнакомого, люди боятся опасного, люди должны как-то прогнозировать, как будет работать то, что вокруг них.
Например, на складе Amazon людей одевали в life vest. То есть жилет, на котором навешаны датчики, что роботы знали, где ты находишься, и могли прогнозировать тебя и в тебя не воткнулись. Иначе они тебя убьют. И тут та же самая история. Представьте себе, что вы приняли на работу человека, поручили ему важную работу, от которой зависит судьба предприятия, удовлетворенность клиентов, ваша премия на следующий год, и вы не понимаете, как он работает. И не понимаете, когда за ним надо смотреть, не надо смотреть.
Без интерпретируемости психически здоровый человек модель не оставит. Нам нужно понимать, как оно работает. Нам нужно строить модель модели, чтобы с ней нормально взаимодействовать. И если вы не дадите людям интерпретируемость, они возьмут ее сами, они построят модель модели на каких-нибудь случайных признаках. Если кто-то интересовался поведенческой психологией, там было понятие «суеверный голубь». То есть голубь, которого кормили в непредсказуемые для него моменты. И голубь такой: «А! Надо просто крыло поднять, повернуться на 90 градусов, подпрыгнуть и меня покормят». Люди изобретут такие же правила и суеверия и будут работать с вашей моделью.
Ирина Голощапова: А тут вернемся к причинности тогда.
Дмитрий Колодезев: Да.
Ирина Голощапова: Так что это все взаимосвязано.