
- 19.09.2025
- 19.10.2025
- обучение
- #causal_inference
Слайды можно скачать тут ciw2.pdf
Материалы
Ссылки
*

У нас второй воркшоп из серии. У нас было вступление в ортогонализацию, скажем так, мы только затронули его - напоминаю еще раз, что все темы, которые упомянуты, мы будем постепенно, как снежный ком, проходить, повторять, разбирать на каждом воркшопе в серии.

Сейчас у нас на повестке дня difference in difference и синтетический контроль. Обычно эти темы разбирают вместе, но если хорошо задуматься, то они очень похожи и связаны. Поэтому мы начнем их обсуждать здесь, а продолжим потом в других воркшопах.

Ну и обещанный экскурс в терминологию. В прошлый раз мы оценивали эффект, но как-то ни одной формулы не показали. То есть что мы оцениваем, почему мы оцениваем, как мы оцениваем. Можно оценивать много разных средних эффектов, обычно их там выделяют с десяток. Но для нашего случая, наверное, имеют значение Average Treatment Effect, то есть ожидаемый средний эффект - как целевая переменная изменилась бы, если бы ко всем применили наше воздействие или ко всем не применили наше воздействие, то есть матожидание, обусловленное нашим воздействием на всей нашей группе. И есть ATT, Average Treatment On Treated Group, то есть средний эффект на тех, на кого мы воздействовали. И, соответственно, есть ATU, ожидаемый эффект на тех, на кого мы не воздействовали.
Зачастую в реальной жизни у нас между воздействием и непосредственно тем, что человек на него согласился, есть большой промежуток. То есть, например, мы прописали больному таблетки, а пить он их не стал. Мы дали, допустим, клиенту скидку, а скидкой он не воспользовался. Мы ввели какую-то policy, и часть людей стала следовать ей, часть людей стала следовать ей через раз, а часть вообще не следует. И если мы хотим оценить с поправкой на вовлеченность, если у нас есть какой-то способ эту самую вовлеченность измерить, то мы оцениваем LATE.
И есть еще CATE, в смысле Conditional Average Treatment Effect. Это как наше воздействие отозвалось бы на конкретном человеке.
Так, а что такое Y0, Y1? То есть у нас Y - наша целевая переменная, это do-нотация. И вот формула для АТЕ. Первая часть формулы - при условии, что мы сделали наше действие, action, и матожидание нашей целевой переменной (то есть, например, это выживание в примере про ИВЛ или, скажем, покупки клиента при условии того, что мы ему дали скидку или снизили цену). Вторая часть формулы - это интересующий наш эффект, какой бы он был при условии, что мы бы сделали вот так. И, соответственно, нас интересует АТЕ - это разница между тем, какой эффект был бы при условии, что мы бы сделали, и при условии, что мы бы не сделали. То есть это фактические и контрфактические воздействия на всей популяции.
Понятно, что на всю популяцию мы не воздействуем, поэтому есть АТТ, то есть когда эффект есть только на той группе, которую мы подвергали тестам. То есть как подействовало лечение на тех, кого мы лечили. ATU - это как бы оно подействовало на тех, кого мы не лечили. LATE - это с учетом того, что некоторые лечатся не полностью, не до конца.
В случае с ИВЛ я не придумал хорошего примера, но с таблетками, например - многие бабушки едят половину таблетки, а не полную. Я недавно об этом узнал, что это вообще общее явление. Врач прописывает одну таблетку, бабушка ест половину. Почему, непонятно.
Суть в том, что мы считаем так. Дело в том, что мы воздействовали на объекты, но у нас есть две реальности - в одной мы воздействовали на объекты, в другой бы мы не воздействовали на объекты. То есть do-оператор как раз определяет параллельную реальность. К сожалению, мы ее измерить так не можем. То есть формулу написать мы можем, а измерить мы ее не можем. То есть была бы возможность ее измерить, можно было бы всем этим Causal Inference-ом не париться.

Какие у нас предположения есть в Causal Inference, напомню. То есть, во-первых, важное предположение, что нет пропущенных конфаундеров, то есть нет какого-нибудь признака, который влияет и на наше воздействие, и на нашу целевую переменную, и мы про него вообще никак не знаем и не учли.
То есть, например, если бы, допустим, под вентилятор клали только людей, которые работают, например, в условной большой организации, а всех остальных бы не клали (и у нас этого в данных не было бы), и выживали бы они лучше, потому что у них был бы особенный уход по ДМС-страховке - это был бы такой хороший кофаундер, а мы его тут не учли.
А затем важное требование, это предположение о «Causal Inference» – это позитивность. А позитивность это, если так грубо сказать - у каждого был шанс как подвергнуться воздействию, так и не подвергнуться воздействию. То есть был ненулевой шанс как попасть под вентилятор, так и не попасть под вентилятор.
Есть еще консистентность. Это про то, что наше воздействие всегда одинаковое.
И что нет сетевого эффекта, то есть, например, если соседа положили под вентилятор, то меня уже не положат.
И в разных учебниках по Causal Inference это формулируют по-разному, то есть, например, SUTVA, которую часто используют в учебниках по causal inference, это, по сути, консистентность и отсутствие сетевого эффекта. А SPICE, про который пишут в других учебниках, это SUTVA, позитивити, консистентность и взаимозаменяемость.
Так или иначе, можно собрать разные наборы предположений, assumptions - так же как для ней для линейной регрессии можно собрать немножко разные наборы. Для начала будем самые простые четыре предположения рассматривать.
Про identifiability, или идентифицируемость, мы поговорим на третьем занятии workshop. Как раз будем говорить про propensity score.

Как с ИВЛ все устроено. Пропущенных переменных у нас нет. Из тех переменных, которые у нас были, мы выбросили переменную fate, то есть судьба конкретного больного. Но она не является конфаундером, она не влияет на попадание под ИВЛ. Соответственно, пропущенных переменных у нас нет.
У нас в том примере серьезно нарушена positivity. То есть легким больным ИВЛ не доставался никогда.
У нас немножко нарушена консистентность, то есть эффект там зависел от тяжести заболевания.
А сетевого эффекта мы не закладывали.
Надо понимать, что в реальных данных всегда что-нибудь нарушено. И самое больное нарушение – это нарушение позитивности. Несмотря на то, что про позитивность обычно вспоминают в контексте Propensity Score Matching, любой метод так или иначе требует позитивности. Просто некоторые страдают от отсутствия позитивности больше, некоторые меньше.
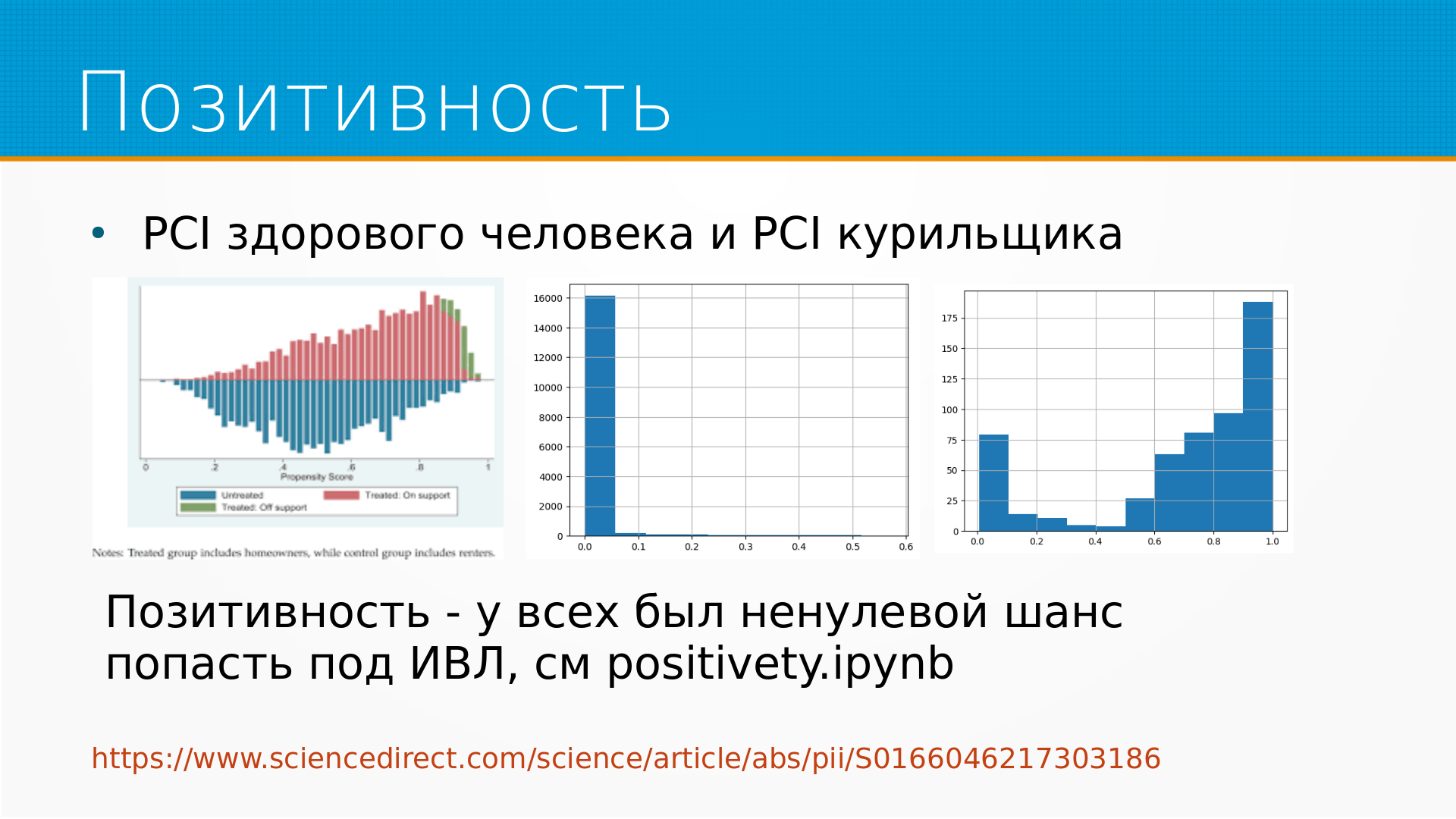
И позитивность принято рисовать на вот такой красивой диаграмме слева. То есть мы рисуем, допустим, тех, кому досталось лечение - красненьким, тех, кому не досталось лечение - синеньким, и считаем какой-нибудь propensity score, это опять же следующий воркшоп, который задает вероятность попасть под лечение.
И хорошо, когда вероятность попасть под лечение хорошо перекрывается для тех, кому досталось воздействие и не досталось. Полностью они никогда обычно не перекрываются, но вот хорошо, когда они перекрываются.