
- 28.09.2025
- 25.12.2025
- обучение
- #causal_inference
Слайды можно скачать тут ciw01.pdf
Ноутбук rmlci_w1.ipynb

Много лет мы с Ирой Голощаповой собирались сделать курс по Causal Inference, на курс нас не хватило, но зато сделали серию воркшопов про анализ причинно-следственных связей, это первый.
Воркшопы будут построены "от обратного" - сначала будем рассказывать "на пальцах", а потом будем понемного обосновывать и усложнять. Кому хочется большей академичности - можно начать смотреть воркшопы в обратном порядке.
К одному и тому же примеру мы будем возвращаться неоднократно, с разными подходами и библиотеками.
Чем воркшоп отличается от курса:
- никто никого не оценивает
- нет домашних работ
- вместо теории - ссылки на почитать
- никаких сертификатов об окончании.

Предыдущие наши мероприятия про Causal Inference:
- Митап ODS Reliable ML по АБ-тестированию и Causal Inference
- Датафест, Causal Inference in ML
- Датафест, Interpretable & Causal ML
- Датафест, Reliable ML
Плейлист с выступлениями с этих мероприятий.

По анализу причинно-следственных связей есть много хороших книг:
- Causal Inference for The Brave and True переведена на русский как Причинно-следственный анализ для смелых и честных.
- Дружелюбная эконометрика
- Causal Artificial Intelligence
- Introduction to Causal Inference
- Applied Causal Inference Powered by ML and AI
Я поддерживаю список ссылок про causal inference.

План серии воркшопов:
- Ортогонализация: Мы поговорим про ортогонализацию, мы на самом деле не обсудим всю ортогонализацию, здесь мы её только зацепим краем ← вы находитесь здесь
- Difference in Difference и синтетический контроль: для меня это одна и та же тема, хотя их обычно рассказывают отдельно.
- Матчинг
- Мета-лернеры
- Хороший и плохой контроль: какие переменные включать в анализ, а какие нет.
- CATE
- Инструментальные переменные: способ оценивать одни переменные по другим.
- Пропущенные переменные
- Causal Discovery: выявление причинно-следственного графа из данных.
- Обзор библиотек
Дополнительные воркшопы:
- Витовт Копыток расскажет про regression discontinuity design и regression kink.
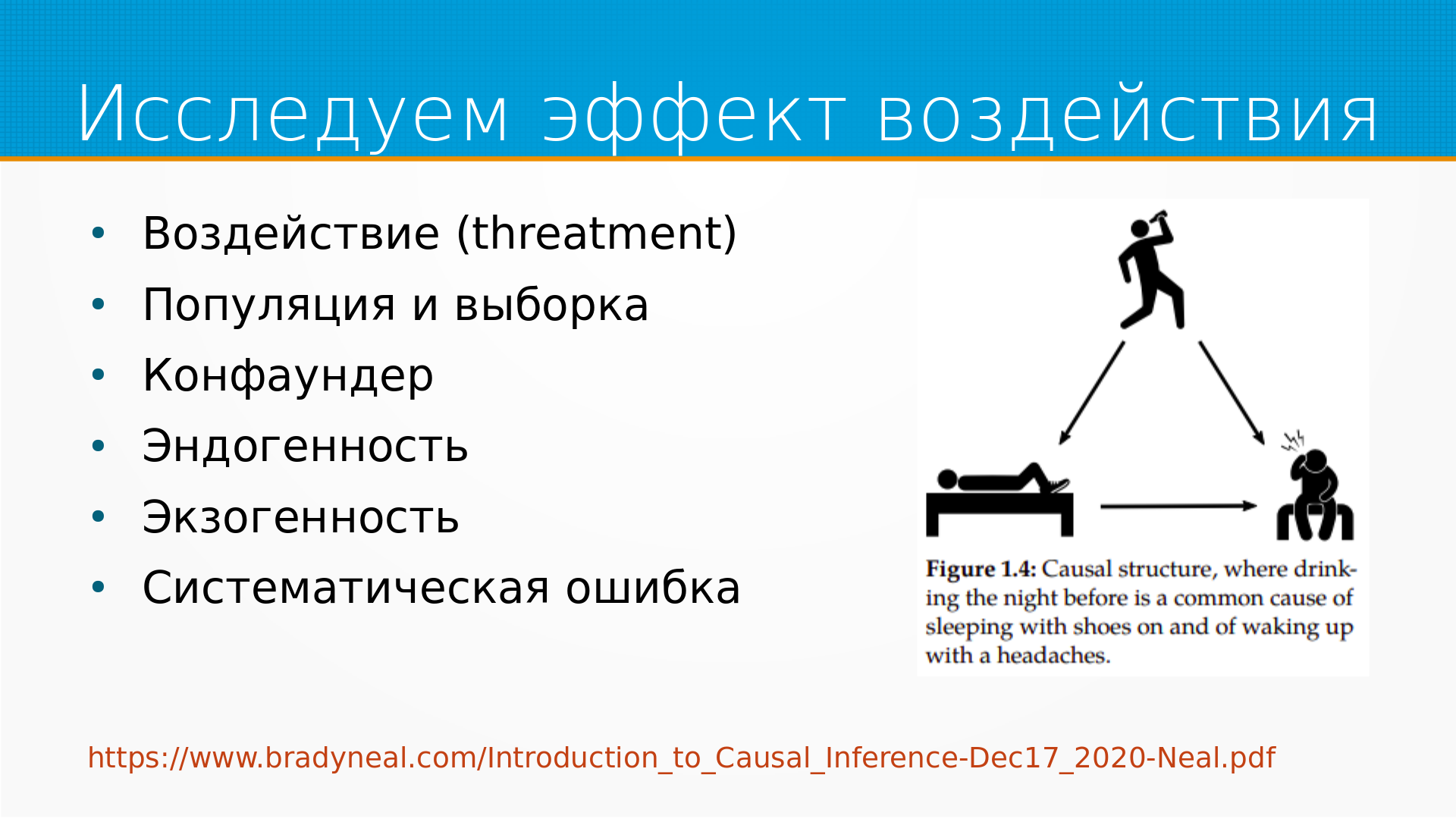
Что именно мы понимаем под Causal Inference?
Мы пытаемся исследовать эффект воздействия.
Это иллюстрация из Брэда Нейла - замечено, что если человек просыпается в обуви, то у него часто болит голова. Но это не потому, что обувь ему на голову надавила, а потому что в обуви на трезвую голову редко засыпают.
Так вот, у нас есть какое-то воздействие. То есть, например, мы спим в обуви или не спим в обуви. Есть какой-то результат - голова болит. Есть какая-то популяция и выборка из нее, которую мы исследуем. А есть какой-то конфаундер, это некоторый внешний фактор, который воздействует и на наш результат, и на наше воздействие. Скажем так, если мы пили с вечера, то шансы уснуть в обуви увеличиваются, ну и с головной болью тоже.
Есть эндогенность, экзогенность, систематическая ошибка, все это мы будем обсуждать.
Causal Inference вырос в эпидемиологии, поэтому под воздействием они имели в виду поставить прививку или сделать какую-нибудь операцию.
Так вот, предположим, мы исследуем влияние чего-нибудь, прививок или, допустим, надетых перед сном ботинок. Самый очевидный подход – это провести Randomized Control Trial, то есть, например, АБ-тесты. Мы берем и то надеваем ботинки, то не надеваем ботинки, потом отслеживаем, что у нас с головой.
Общая схема АБ-тестов – мы вмешались в жизнь одной части популяции (тестовая группа), другую часть (контрольную группу) мы оставили в покое и посмотрели, что получится. АБ-тесты это прекрасно, если они у вас работают. Мы чуть позже обсудим, почему АБ-тесты вообще работают и как именно они не работают.
Сейчас хотелось бы отметить три момента.
Первое, это то, что АБ-тесты направлены в будущее. То есть мы можем притвориться, что мы делаем АБ-тесты на исторических данных, когда к нам приходят и говорят - слушай, вот мы тут поменяли дизайн, как он повлиял? То есть - мы тогда не делали АБ-тесты, а сейчас уже поздно их делать. Но нам интересно, как это влияло на будущее, например. Или мы, например, планируем АБ-тесты и хотим понять, что влияет, что не влияет на будущее. Мы можем сделать АБ-тесты на исторических данных, притворившись, что мы находимся в прошлом, что мы разделяем людей на контрольную группу и тестовую группу, но в конечном итоге мы заново изобретем матчинг из causal inference, который мы будем разбирать на третьем семинаре, и можно просто не притворяться, что это АБ тест, а сразу назвать это матчингом. Суть матчинга в том, что мы находим в популяции похожие объекты, различающиеся только тем, что на одни объекты воздействия было, а на другие нет, и смотрим на разницу результатов.
Второе - не все, что нас интересует, мы можем поменять. То есть некоторое воздействие мы не можем случайно применять к части популяции по организационным, юридическим причинам или каким-нибудь еще.
На эту тему есть дискуссия. Можно ли установить причинно-следственную связь, если мы в принципе не можем повлиять на причину?
То есть, например, если нас интересует, как различается отклик мужчин и женщин на рекламный звонок по телефону, то навряд ли мы будем отбирать тысячу мужчин, половине менять пол и смотреть, как изменился их отклик на звонки. Но что-то делать надо, и мы, используя ровно те же самые техники causal inference, можем попробовать оценить это влияние, хотя это не будет в классическом смысле воздействием. То есть мы не поменяли им пол, пол у них был и без нас, но мы хотели бы выяснить, как он влияет.
Или, например, мы поменяли цену для всех клиентов. Как установить причинно-следственную связь, если у нас нет контрольной группы? Например, если мы делаем какую-то акцию по телевидении на всю аудиторию, или у нас сильный сетевой эффект, или если мы по закону обязаны продавать по одной и той же самой цене, то у нас могут быть сложности с контрольной группой - хотя люди выкручиваются.
Здесь и далее мы не будем различать то, что мы могли бы поменять, и то, что поменять не могли. И то, и другое для нас будет воздействием.
Еще иногда при анализе АБ-тестов часто выясняется, что учли таки не всё. И назначение получилось не совсем случайным. Можно, расстроившись, выкинуть АБ-тест, а можно попробовать выявить внесенное смещение и исправить его.
АБ-тесты прекрасны - так же, как все остальные инструменты, они имеют ограничения, часто их делают неправильно, не всегда они нужны, но мы не про них. Не воспринимайте все это как критику АБ-тестов, они клевые. Если ситуация позволяет, используйте.
Следующий важный момент – это неразличимость процессов по их следам. Есть, например, такой рассказ у Акутагавы «Ворота Расемон», там четыре свидетеля преступления сходились абсолютно в ключевых факторах повествования, но сама история у каждого была совершенно разной. И это именно то, что мы видим в анализе данных - разные процессы генерации данных могут порождать похожие данные, и глядя только в данные, мы не всегда их можем различить.
Например, простая история, мы позвонили клиенту, и он рассердился на нас и стал покупать меньше. Это, кстати, мой случай, то есть мне звонят с рекламой, а я перестаю там покупать. Или мы позвонили клиенту, потому что он, как нам кажется, перестанет вот-вот покупать, ну и часть клиентов все-таки начала покупать, хотя и не так много, как раньше. И там и там мы увидим падение продаж после звонков клиентов, но это совершенно разные истории.
В большинстве случаев нам нужно заранее решить, что на что влияет, прежде чем мы начали это влияние оценивать.
Есть методы, позволяющие при определенных обстоятельствах восстановить причинно-следственный граф из данных, и мы будем обсуждать это в семинаре про causal discovery.
Еще есть пропущенные переменные. Например, у нас есть данные об объеме продаж, о цене единицы товара, температуры на улице, и мы видим, что цена поднялась, а продажи выросли. Какие модели генерации данных тут могли сработать? На рынке дефицит, спрос растет, и даже спад спроса, возникший в результате повышения цены, его не пересилил, не смазал. Либо просто растет курс доллара, все цены в рублях, наша цена растет чуть медленнее курса доллара, то есть с точки зрения клиента товар-то дешевеет, вот и покупают больше. Ну или мы подняли цену настолько, что на нас обратил внимание другой потребительский сегмент и покупает нас, решив, что мы качественнее.
И вот глядя только в данные, мы не различим эти ситуации, у нас есть пропущенные, влияющие переменные. Некоторые из них мы можем собрать, но мы никогда не будем уверены, что собрали их все. И про это мы поговорим в разделе про пропущенные переменные.
Ну и про то, что ML-инженеры любят использовать всю доступную информацию, ну, может быть, отобрать из них те, которые лучше предсказывают. Задача машинного обучения ставится как задача предсказания, а задача causal inference ставится как задача выявления влияния. И получается зачастую, что модели, которые хуже предсказывают результат, лучше выявляют влияние - и вот это мы будем разбирать в хорошем-плохом контроле.
Зачастую у нас есть похожие группы и случайно так вышло, что к одной из них воздействие применялось, а к другой нет. Например, в одной области разрешили торговать алкоголем только два часа в обед, а в другой точно такой же похожей торгуют с утра и до вечера. И в разделе про DND и синтетический контроль мы обсудим, как работать с такими естественными экспериментами, какие там есть подводные камни.
В Causal Inference есть набор отработанных рецептов, они довольно просты, хорошо проработаны - делай раз, делай два, делай три. Такие готовые рецепты они называют металернерами, а мы их обсудим в отдельном воркшопе.
Иногда мы оцениваем воздействие косвенно - это инструментальные переменные.
Еще иногда мы оцениваем среднее воздействие, как сейчас - то есть насколько у нас в среднем влияют надетые ботинки на головную боль. А иногда нам нужно не среднее влияние, а влияние на конкретный объект. То есть, например, мы хотим понять, кто из наших клиентов лучше отреагирует на маркетинговую акцию. Нас не интересует среднее влияние на клиентов. Нас интересует, как отобрать из наших клиентов те 5%, до которых мы этой акцией хотим дотянуться. И тут нам помогает оценка условного среднего воздействия. Про нее тоже есть раздел.
Большинство того, что мы тут делаем, можно сделать с помощью готовых библиотек. И так и надо поступать. В иллюстративных целях мы будем делать некоторые вещи руками, чтобы понять, как это устроено. Но когда вы делаете какую-нибудь оценку руками, вы фактически изобретаете causal inference заново. Вам нужно очень аккуратно все делать, строить доверительные интервалы трудно, и так далее и тому подобное. Ну, в общем, везде, где можно использовать готовые библиотеки, надо использовать готовые библиотеки. Так и шансов ошибиться меньше и быстрее. И последняя тема у нас будет как раз разбор библиотек.
Я буду рассказывать про библиотеки для Python, но если кто-то хочет рассказать про библиотеки для R или, например, для Rust, то пишите мне, я с удовольствием уступлю кафедру.
Ну и сегодня мы поговорим про ортогонализацию, даже не столько поговорим, сколько начнем про нее говорить. Это подход, который позволяет вычистить систематическую ошибку из наших наблюдений. Технически это, наверное, самая сложная тема, не считая causal discovery. А мы с нее начнем, потому что это часть Causal Inference, более всего понятная ML-инженерам. Во-первых, она довольно универсальна, во-вторых, довольно свежая и часто является хорошим бейзлайном - то есть мы быстро делаем черновое решение и потом смотрим, может быть, мы можем сделать лучше.

Фундаментальная проблема причинно-следственного анализа состоит в том, что у нас нет параллельной вселенной, чтобы сравнить другой вариант, контрафактический. То есть если бы у нас была параллельная вселенная, мы бы в одной поставили человеку прививку, а в другой нет, и смотрели бы, что изменилось. Или в одной мы бы легли спать в ботинках, в другой нет и сравнили бы головную боль.
У любой проблемы есть очевидное, простое и неправильное решение. В данном случае это, например, мы возьмем привитых и непривитых и сравним. На этом пути нас ожидает куча удивительных открытий.
Во-первых, те, кого лечат, умирают чаще, чем те, кого не лечат. Это факт. Само попадание в больницу опасно. Тут внутри больничные инфекции и врачебные ошибки и у процедуры есть осложнения. Но здравый смысл подсказывает, что здоровые люди умирают редко и еще реже ложатся в больницу. А больные люди чаще умирают и в больницу попадают тоже часто. То есть чаще всего виновато не лечение, а болезнь.
Еще в этом мегасписке удивительных открытий: повышение цен ведет к росту продаж обычно через какие-то общие признаки рынка.
Чем больше пожарных, тем больше ущерб - это понятно, потому что 100 пожарных на мелкий пожар не приедет.
Алкоголь в малых дозах полезен, но это потому, что на самом деле люди, у которых тяжелые проблемы со здоровьем, обычно воздерживаются.
Ну и еще смешная история, что курильщики гораздо чаще доживают до 100 лет, но только на бумаге. То есть в тех местах, где пенсия дедушки - это значительная сумма, его не всегда показывают властям и продолжают получать пенсию, пока у него не случится юбилей и не приедет телевидение. По ссылке очень хорошо разобрана эта удивительная история.
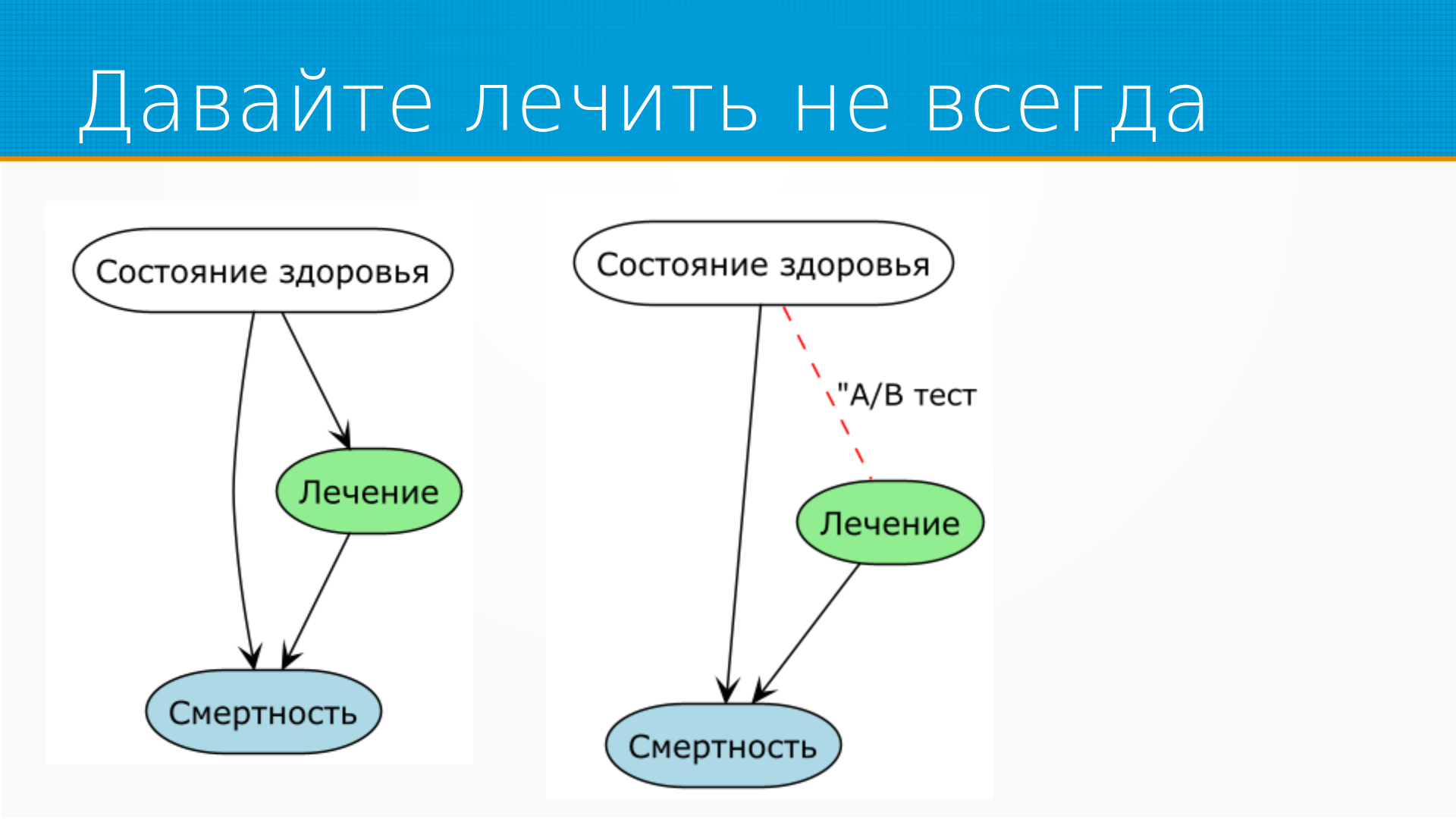
Возвращаясь к тому, что те, кого лечат, умирают раньше.
Строго говоря, и смертность, и назначенное лечение зависит от состояния здоровья пациента, и состояние здоровья являются кофаундером, то есть чем-то, что влияет одновременно и на наше лечение и на итоговый результат.
Мы могли бы убрать влияние кофаундера, назначая лечение случайно. Ну или в нашем случае случайно отказывая в лечении. Это помогло бы, но у нас были бы некоторые проблемы юридического и этического характера.
То есть мы вне зависимости от состояния здоровья хватаем человека на улице, подвергаем лечению, а потом смотрим, чаще они после лечения умирают или нет. Вот настоящая наука!

Замечательный пример есть в книжке «Дружелюбная эконометрика», что на самом деле число преступлений и количество патрулей связаны. Патрули появляются на улице потому, что там случаются преступления, и там дается такая клевая рекомендация – случайно отправляйте полицейских в ряд районов, получится АБ-тест, тогда мы хорошо можем получить несмещенную оценку.
Это примерно как менять пол в эксперименте. Я, кстати, против книги ничего не имею, книга прекрасная, там просто игрушечный пример, вот я его игрушечно и комментирую.
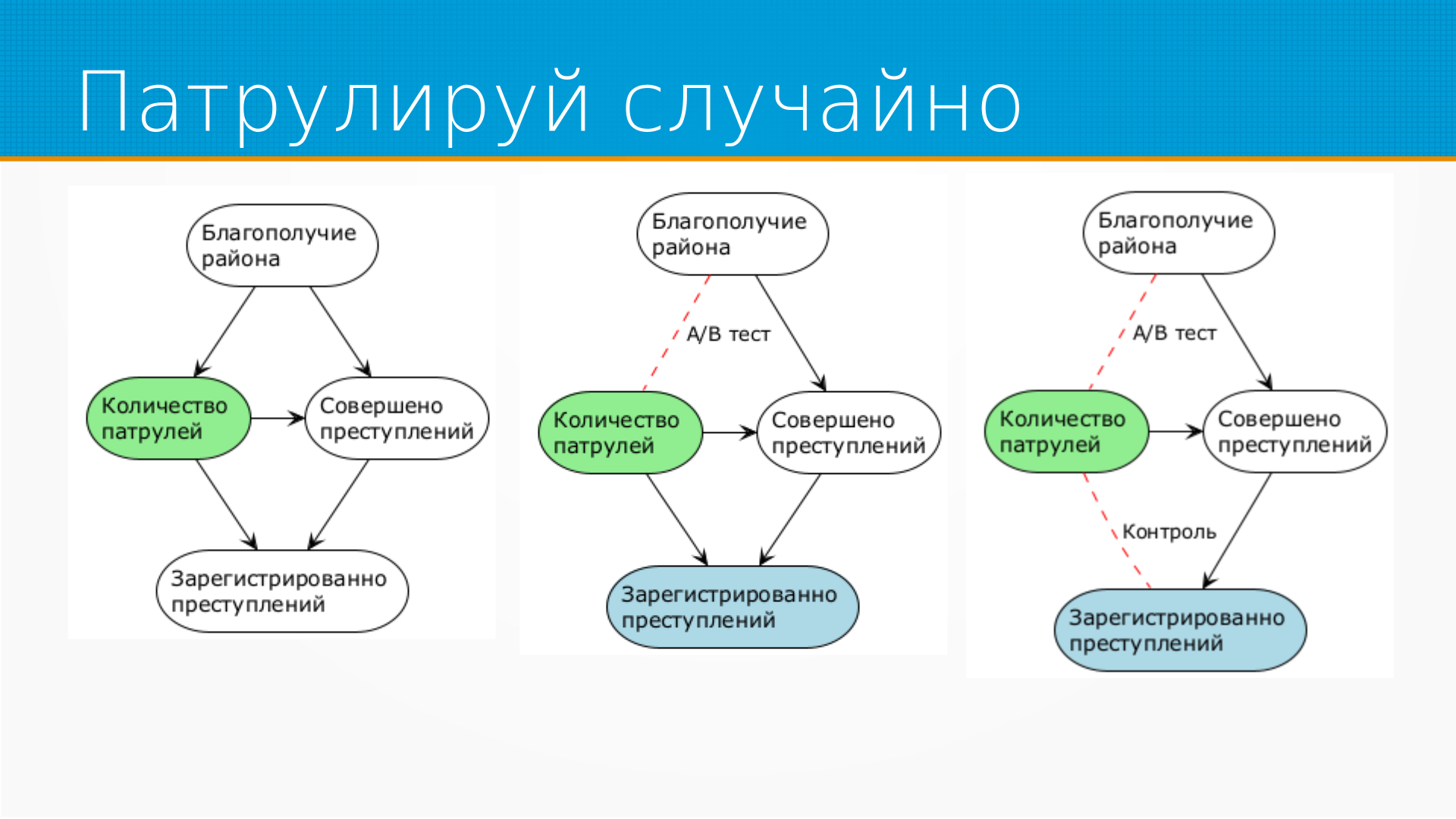
Разберем ситуацию, что преступлений тем больше, чем больше патрульных на улице.
От чего зависит количество патрульных? Нарисуем граф причинности.
Я вот тут нарисовал такой, вы можете нарисовать другой, но есть некоторое благополучие района, и в зависимости от него на улицы отправляют больше или меньше патрулей. В зависимости от благополучия района у нас случается больше или меньше преступлений, и полиция на улице тоже влияет на это.
Однако мы не видим все совершенные преступления, мы видим только те, которые зарегистрированы. Если человека ограбили, а он не пошел в полицию, или его ударили по лицу, а он не пошел в полицию, то он не попадет в статистику и в наш анализ. И патрули влияют не только на количество совершенных преступлений, но и на полноту их учета.
Соответственно, у нас есть кофаундеры - благополучие района и количество зарегистрированных преступлений. Если мы начнем проводить АБ-тесты, просто случайно раскидывая патрули по городу, то мы разрежем эту зависимость между благополучием района и количеством патрулей. То есть АБ-тест, благодаря тому, что мы будем случайно назначать количество патрулей, разрежет эту зависимость, здесь она у меня красным помечена.
Но у нас останется другая зависимость. То есть у нас есть зависимость между количеством совершенных преступлений и зарегистрированных. И она все равно будет нам мешать.
В данном случае у нас получается, что, поскольку мы предполагаем, что полиция снижает количество преступлений, - что бы там ни говорили, - и мы полагаем, что полиция увеличивает полноту регистрации преступлений, то это приведет к тому, что эффект от полиции будет занижен. То есть полиция будет снижать количество преступлений, а полнота учета будет расти. То есть мы выявим эффект от полиции не полностью.
Но мы могли бы что-то с этим поделать. Например, мы могли бы учитывать, пришел человек в полицию сам или вместе с патрулем, то есть проконтролировать, повлиял ли патруль на учет правонарушения. Тогда анализ был бы точнее, но, кстати, встает вопрос - почему количество совершенных преступлений влияет на количество патрулей?

Ведь у нас же стрелка в другую сторону. То есть мы показываем, что на что влияет у нас, а получается, что хвост машет собакой. Получается, что мы как будто путаем причину и следствие. Тут нас ждет неприятное открытие.
Как мы узнаем вообще о причинах?
У нас бывает априорное знание механизма - например, я сам построил механизм, и я точно знаю, что если я нажму эту кнопку, отсюда вылетит пулька.
Либо мы можем наблюдать через действие. Например, мы можем сегодня нажать на кнопку, пулька вылетела, завтра не нажать на кнопку, и пулька не вылетела. И таким образом строить свои выводы о причинности.
Либо мы можем смотреть на кнопку и пульку, как другие на нее нажимают, и, глядя в корреляцию этих вещей, которая как бы не подразумевает у нас причинно-следственные связи, тем не менее эту связь выявлять.
Ну и главное, что мы используем в быту - это последовательность. То есть если А случилось перед Б, то А может быть причиной. Если А случилось после Б, то А не может быть причиной.
Тут есть интересная история с ретроспективными молитвами - для проверки разных инструментов анализа данных хорошо брать какие-нибудь датасеты, где проблема доведена до абсурда. Я знаю два таких исследования. Первое – это когда брали мертвых лососей, клали их в томограф, показывали им картинки и выявляли статистически значимую активацию тех или иных областей мозга. А второе – это про ретроспективные молитвы. То есть специальная группа читала молитвы о здоровье пациентов, - правда, эти пациенты болели 10 лет назад, но те, кто читал молитву, не знали исхода. Поэтому это был совершенно чистый эксперимент. И на самом-то деле молитва помогает - во всяком случае, статзначимость авторы статьи показали. Если кому интересно, погуглите ретроспективная молитва.
Но мы отвергаем этот научный результат и будем считать, что последовательность изолирует причинность. То есть если что-то случилось перед чем-то, то оно не могло быть следствием этого.
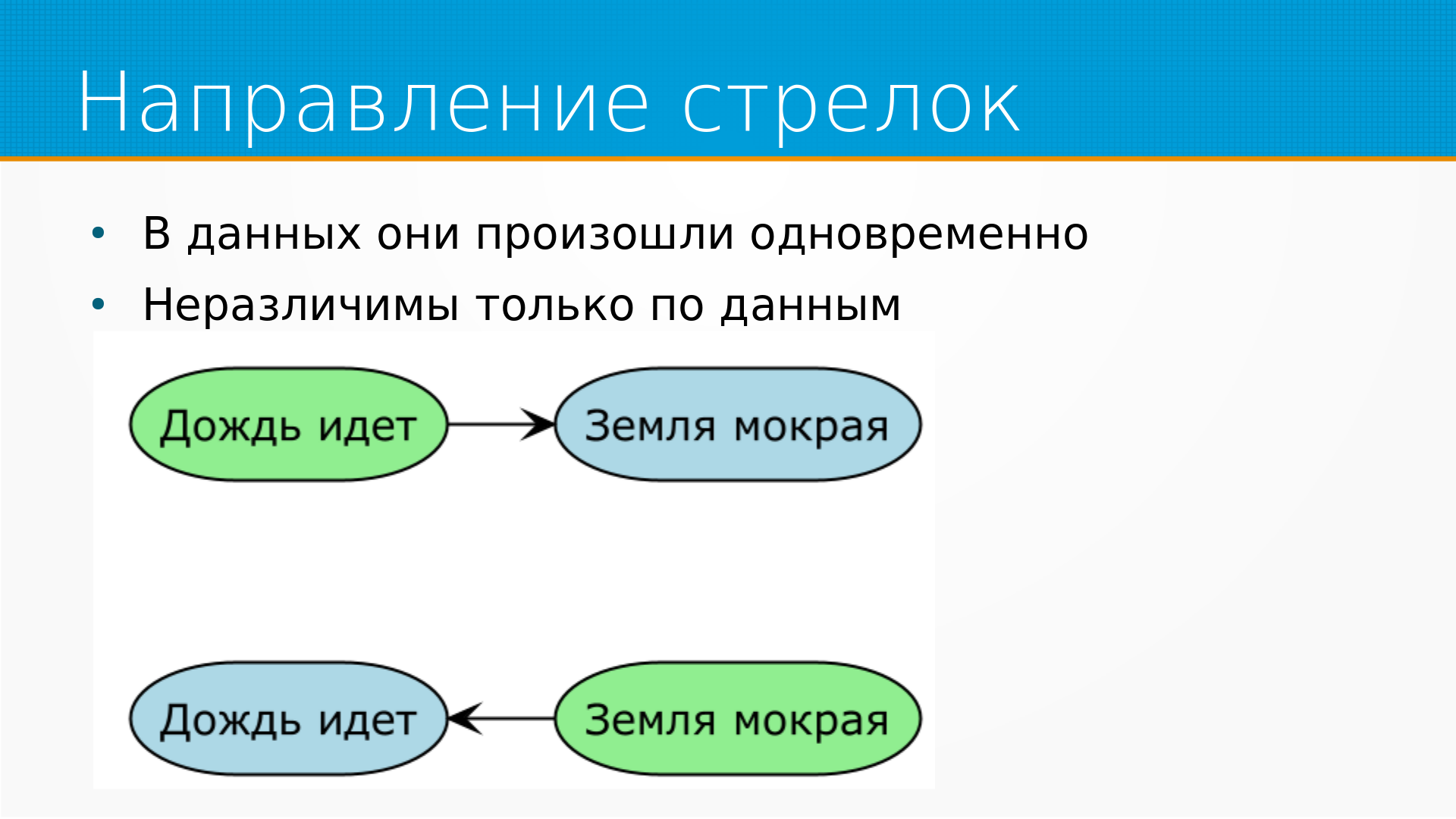
Проблема в том, что в тех данных, которые мы анализируем, они часто неразличимы. Несмотря на то, что причины и следствия расположены во времени в определенном порядке, в данных мы, например, фиксируем их раз в день. И они там неразличимы.
То есть, например, если у нас дождь идет и земля мокрая, что чему причина? Земля промокла и дождь пошел - или, например, дождь пошел, потому что земля промокла. Мы не можем различить это, если у нас нет фиксации с точностью до секунд.
Кстати, в этом конкретном случае мокрая земля действительно вызывает дождь - грозовые тучи так и образуются: солнце нагревает влажные участки земли, поднимается водяной пар, образуется дождь. Но самостоятельно вызывать дождь у вас так не получится.
В чате слушатели пишут, что случившееся позже может быть причиной случившегося раньше. Пример - выплата дивидендов и повышение цены акций. Кажется, что да, но на самом деле я считаю, что тут есть пропущеные влияющие факторы.
То есть если мы берем граф причинности и отрезаем от него какие-то куски, то нам может казаться, что следствие было перед причиной. Я думаю, что у них была общая причина - есть какие-то причины, по которым было понятно, что выплатят дивиденды, и эти причины вызвали повышение цены акций. Дивиденды наверняка не в рамках АБ тестов выплачивались, что-то им предшествовало.
Решение о выплате скорее всего принималось на основе экономических показателей и политических тёрок, экономические показатели могли быть доступны, политические тёрки тоже как-то выясняются. В общем, я остаюсь при своем мнении, что это неполный граф и следствие идет после причины.
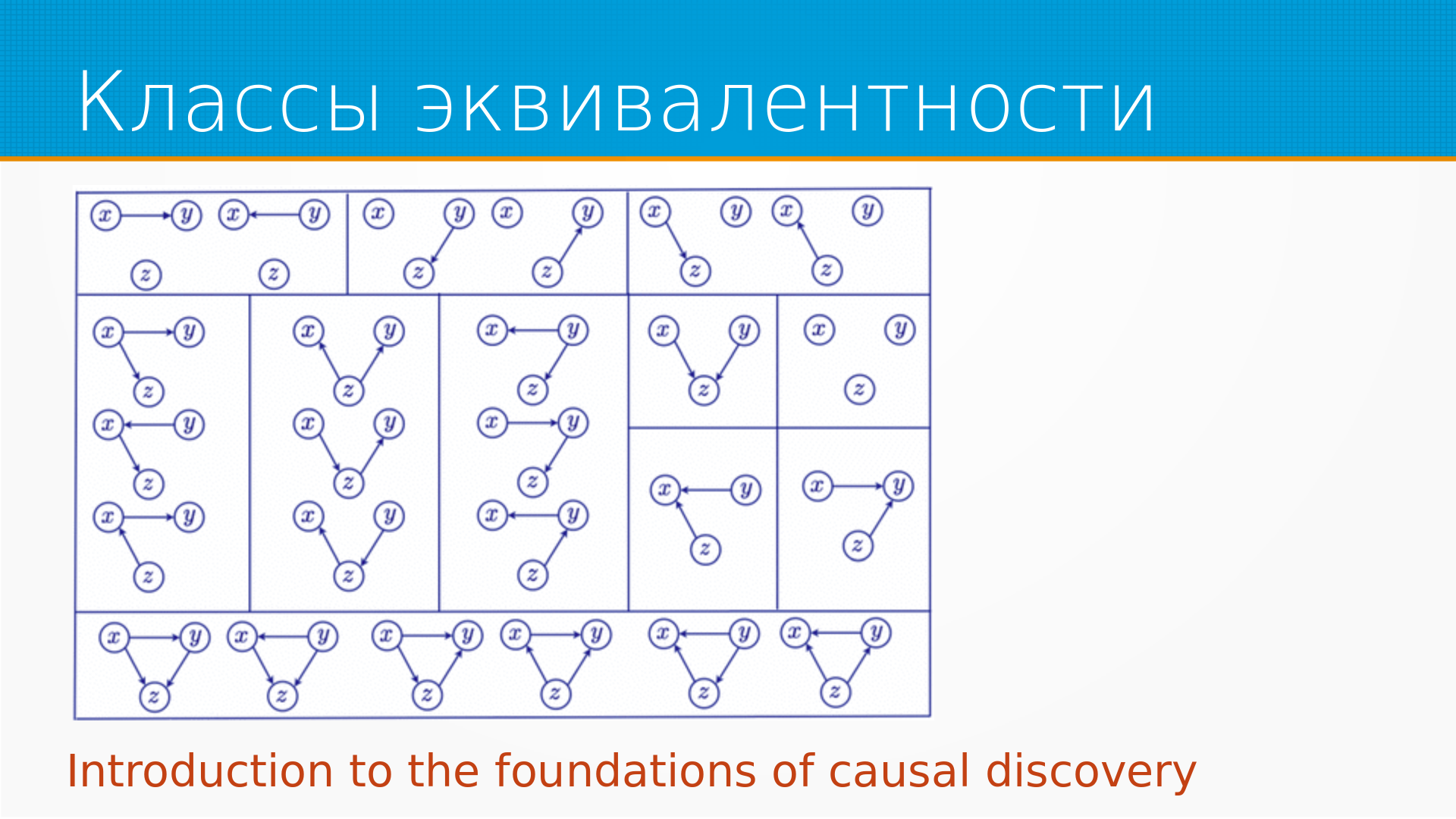
Кстати, про графы - есть классы марковской эквивалентности. С точки зрения причинности все эти комбинации внутри одного блока одинаковы, то есть мы не можем их различить без дополнительной информации.
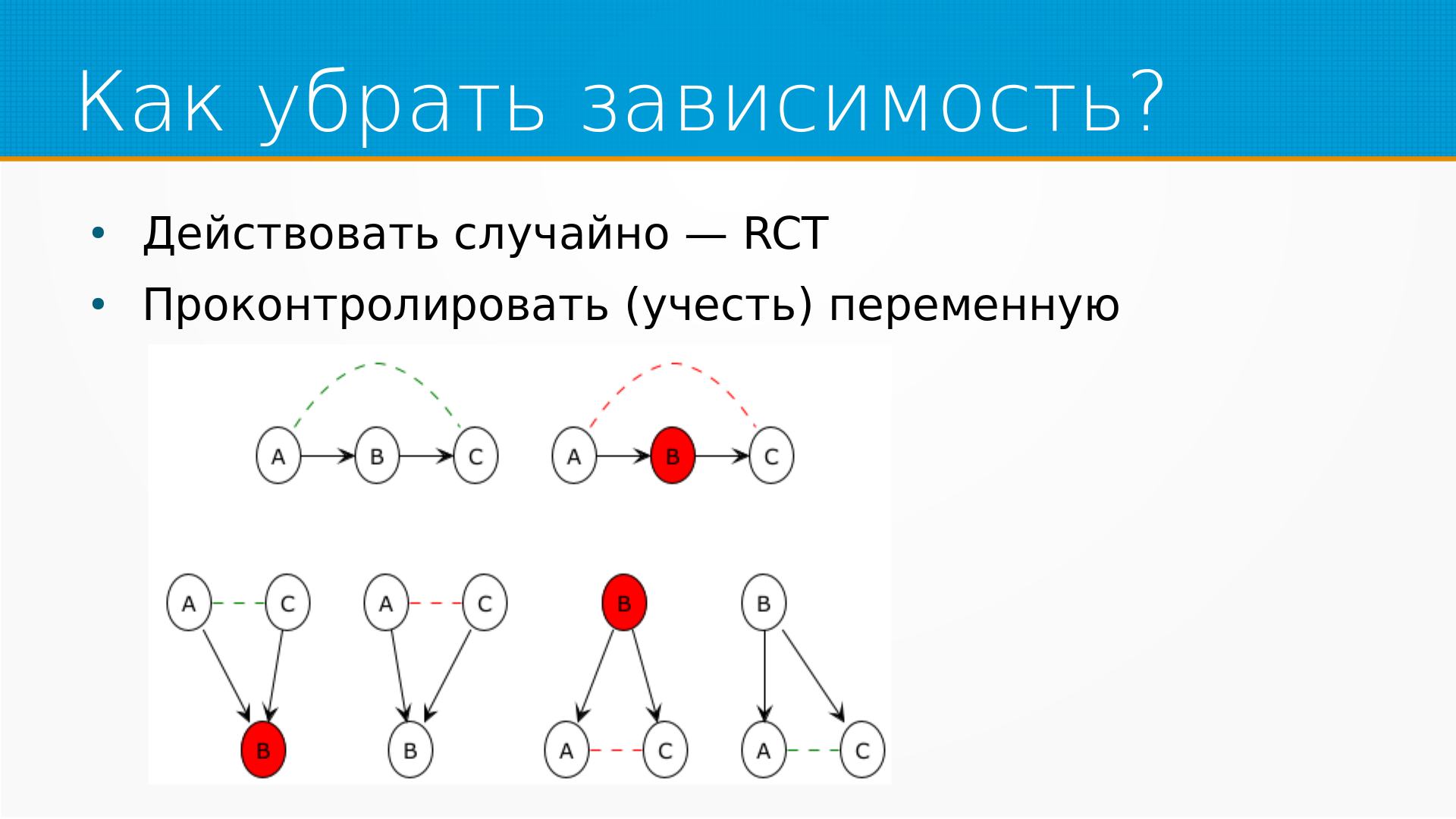
Можем ли мы как-нибудь убрать зависимости? Что же мы можем сделать, чтобы анализировать факты правильно? Там везде есть какая-нибудь зависимость от одного и того же признака и в нашем воздействии и в нашем результате.
Ну, подходов, в общем, два.
Первое - мы можем какую-нибудь зависимость разорвать, назначая воздействие, тритмент, случайно - но, как мы видели в примере с полицейскими, мы можем так не все зависимости разорвать.
Ну и, во-вторых, мы можем проконтролировать, то есть учесть некоторую переменную. Мы можем сказать - ага, на эту конкретную переменную мы сделаем поправку при расчете, мы рассчитаем propensity score, или как-нибудь еще ее учтем.
И получается, что, например, если у нас А влияет на Б, Б влияет на С, а мы пытаемся выявить, влияет ли А на С - А, скорее всего, влияет на С, А связано с С, А ассоциировано с С. Если Б мы при этом знаем, то есть проконтролировали, то А перестает быть ассоциировано с С.
Например. Предположим, что у нас есть наследственное заболевание и дети с этим наследственным заболеванием хуже успевают в школе. И мы знаем, что у родителя ребенка это наследственное заболевание есть. Тогда мы можем уверенно сказать, что да, скорее всего, этот ребенок будет плохо успевать. При условии, что мы не знаем, есть ли заболевание у ребенка. Но, это вот первая диаграмма, которая А-Б-С. Но если мы внезапно знаем, что у ребенка нет этого заболевания, то связь между заболеванием родителей и успеваемостью ребенка исчезает. Ну, с поправкой на то, что это могла быть не единственная связь.
Если у нас и А и С влияют на некоторое Б, и мы это Б не знаем, то мы не можем сказать, что они как-то связаны. Но если мы знаем Б, то между А и С внезапно появляется связь.
Предположим, что у нас есть А и С, между которыми мы пытаемся выяснить причинно-следственную связь. И оба зависят от Б. Например, опять же - продажи мороженого и количество утопленников - и то и другое зависит от температуры. То есть, когда людям жарко, они ведут себя менее воздержанно, ну и мороженого тоже покупают больше. Таким образом, если мы не знаем, какая температура на улице, то мы можем выявить зависимость между потреблением мороженого и уровнем утопленников. Но если мы точно знаем, какая температура, то такой зависимости нет.
Точно так же, допустим, рост ребенка здорово скоррелирован с ростом родителей. И если мы не знаем рост ребенка, то, зная рост одного родителя, мы ничего не можем сказать про рост другого. Но если мы знаем рост ребенка, то во многих случаях у нас есть возможность делать предположение. Например, у нас очень высокий ребенок и один родитель низкого роста, мы можем предположить, что второй родитель у него высокий. То есть эта связь появилась именно когда мы проконтролировали эту переменную.

И из корреляции на самом-то деле следует причинно-следственная связь. Нас все время учат говорить, что корреляция не предполагает причинность, но на самом деле кое-что она предполагает.
Есть принцип Райенбаха, который говорит, что из корреляции между А и Б следует что-нибудь из трех. Либо А это причина Б, либо Б это причина А, либо у них есть какая-то общая причина С.
На эту тему есть хороший как раз доклад от Григория, ссылка на него есть.
Егор напоминает про лестницу причинности - история такая, что контрафактическую реальность мы можем наблюдать только в синтетических данных. Поэтому, конечно, схема клевая, на практике не встречается.
Ну и помаленьку переходим к практике. То есть мы вот так вот и будем идти на воркшопах, то есть сначала пламенная речь и потом какая-нибудь скучное тыканье в ноутбук.
И - ассоциация - это обобщение корреляции на нелинейные и прочие типы связи.

Есть такой парадокс Симпсона, его в своей статье упомянул в 51 году Эдвард Симпсон.
Там было два вида лечения и два вида камней в почках - маленькие камни в почках и большие камни в почках. И получалось, что если сравнить эффект лечения, то в среднем лечение А было хуже, чем лечение Б. Но если разбить на группы - маленькие и большие камни, - то оказывается, что внутри каждой группы лечение А лучше. И встает вопрос, а вот мы приходим и какое же лечение мы хотим.
А тут все не так однозначно.
Во-первых, конечно, если мы учтем влияние размера камней, то все встанет на свои места. То есть у нас очень смещенная выборка - грубо говоря, лечение Б получали люди в основном с легкими случаями, а лечение А в основном с тяжелыми случаями. И если мы сделаем поправку на размер камней, то получится, что лечение А, конечно, выгоднее.
Но получается, что мы учли дополнительный признак, размер камней, и решение изменилось.
А если бы мы еще учли пол, вес, возраст, больницу, в которой проводилась операция, время года, то что получилось бы - мы не знаем.
То есть любое утверждение о причинности строится на наших галлюцинациях о том, как устроен мир. Несмотря на то, что casual discovery позволяет при некоторых обстоятельствах получить вызывающий доверие граф причинности, на самом-то деле мы всегда должны принимать на себя ответственность за этот граф причинности.
Один из примеров того, как можно вывернуть все наизнанку - что возможно на самом-то деле лучшее решение лечения это не А, а Б, но просто оно дороже и ресурсов у большинства госпиталей на него мало, и поэтому они везут таких больных в другой госпиталь, и после перевозки смертности количество осложнений растет, поэтому менее эффективное, но более доступное на местах лечение А выигрывает.

И основная проблема причинности в том, что у нас нет параллельной Вселенной, и мы не можем посмотреть, что было бы, если бы мы не применили воздействие. Но мы можем представить себе, что было бы, это контрафактические варианты, и для того, чтобы они у нас были, мы можем вместо того, чтобы брать реальные данные, брать синтетические. Потому что если на синтетических данных мы научимся вытаскивать эти самые причинно-следственные связи, то, наверное, у нас это будет и в реальности.
Пример, допустим, с болезнью. То есть то, что люди умирают чаще, когда их лечат. Что тут можно сделать?
Ну, действительно, те, кого лечат, умирают чаще, но мы знаем, что назначенное лечение зависит от здоровья. То есть это граф причинно-следственной связи, который у нас есть в голове.
Но мы хотим, чтобы назначенное лечение не зависело от здоровья - как будто случайно. Но мы не можем отказывать людям в лечении.
Также смертность зависит от здоровья. Ну, мы хотели бы, чтобы смертность зависела от лечения, а не от здоровья - но смерть придет и заберет вне зависимости от нашего желания по этому поводу.
А почему вообще мы хотим, чтобы не зависело? То есть чем нам эта зависимость мешает? Почему она мешает?

Это из книги «Дружелюбная эконометрика», там это немножко строже показывается, но что тут хотелось бы сказать - что если у нас есть некоторый кофаундер и его ковариация с нашими регрессионными остатками не нулевая, то он вносит смещение.
И если ковариация положительная, то он вносит положительное смещение, а если отрицательная, то отрицательное смещение. То есть тот оцененный параметр, который мы получили в результате моделирования (тут они используют линейную регрессию, но в общем можно использовать что-нибудь другое) будет смещен в ту сторону, куда его сместит этот самый кофаундер. Что мешает нам нормально оценить. А нельзя ли его как-нибудь сместить обратно?

И вот тут мы можем скорректировать нашу картину мира. То есть мы можем посмотреть не на то, каков был объем лечения, а каков был объем лечения сверх обычного в таких обстоятельствах. Тем самым мы выявим ситуации, когда лечили, когда не принято лечить и не лечили, когда принято лечить.
То есть мы уберем выборочное смещение, то есть мы по остальным признакам, которые у нас есть, спрогнозируем - а стали бы лечить этого больного или нет. И найдем разницу между предсказанным уровнем воздействия и реальным воздействием, найдем регрессионные остатки. То есть таким образом мы уберем выборочное смещение - как бы все получат у нас одинаковое лечение.
И затем у людей, вообще говоря, разная смертность, разное здоровье. Мы могли бы объяснить часть этой смертности, собственно, состоянием самих пациентов. То есть у нас есть общая дисперсия нашего результата. Часть дисперсии зависит от нашего воздействия, а часть просто от состояния пациентов. То есть люди болеют или люди здоровы. И мы можем построить предсказание на остальных признаках - выздоровели бы люди или нет без учета нашего воздействия. И таким образом часть дисперсии объяснить. То есть мы строим предсказанный исход болезни без учета воздействия и берем регрессионные остатки. То есть у нас есть отклонение лечения от ожидаемого, отклонение смертности от ожидаемого. То есть мы получили то самое, что лечение у нас не зависит от здоровья, потому что там уже все факторы учтены, в том числе и здоровье. И смертность тоже у нас внезапно не зависит от здоровья, потому что мы уже учли здоровье в смертности, мы всю эту ковариацию съели.
И теперь мы можем с чистой совестью построить модель регрессионных остатков смертности от регрессионных остатков нашего лечения. Собственно, это и есть ортогонализация. Она многолика, она базируется на ортогональности по Ньюману, она может использоваться в нелинейных случаях, но общий подход, общая идея ортогонализации именно такая. То есть мы выполняем debiasing, то есть убираем выборочное смещение и делаем denoising, то есть объясняем часть дисперсии исходного результата. Если, кстати, вспомнить АБ-тесты - все эти методы повышения разрешающей способности АБ-тестов это как раз вот denoising, то есть объяснение дисперсии.
Вообще, как я уже говорил, я против АБ-тестов ничего не имею, они один из инструментов Causal Inference.
Ортогональность по Ньюману не имеет отношения к идентификации, она просто является условием, что так можно делать. И Черножуков в 2016 году как раз обосновывал, что так можно и можно не только с помощью линейной регрессии, но и с помощью чего-нибудь более сложного.
Что важно - вот тут у меня нарисована регрессия Y от X, кстати, у меня тут опечатка, да, вот, тритмента от X, но на самом-то деле мы можем использовать сложные какие-нибудь методы машинного обучения для предсказания того, назначим ли мы этому больному лечение. И также мы можем использовать сложные методы машинного обучения для предсказания того, выживет больной без лечения или нет. И тут есть проблема. Методы машинного обучения обычно дают такое себе предсказание. То есть оно не калиброванное, не имеет никакого отношения к вероятности. И оно смещенное, то есть обычно это переобученная штука. То есть сами по себе методы машинного обучения, они спорные бывают. И в работе Черножукова как раз там разбирается такая история, он говорит - ну а давайте мы будем предсказывать деля на фолды. Но я много лет занимаюсь машинным обучением и хочу сказать, что поделить на фолды это та еще история. То есть в нетривиальных случаях вы не можете поделить хорошо на фолды. Поэтому все эти методы, все они тоже немножко галлюцинации. Но при определенных условиях, при аккуратном обращении все это работает.
Cross-val predict это тоже та самая еще история. То есть, например, если вы делаете кроссвал предикт без дедупликации, то у вас попадают одни и те же примеры в одни и те же фолды, а если вы делаете с дедупликацией, то почему вы его не взвешиваете? Ну вот эта вот вся история, она сложнее, чем просто сказать давайте сделаем кросс вал предикт.
Вопрос - почему ортогонализация не часть матчинга? Вообще-то, с моей точки зрения, весь causal inference – это ортогонализация. То есть, как таковая ортогонализация – это общая идея, к которой можно свести весь causal inference. И то, что какую-то часть называют ортогонализацией, а часть ортогонализацией не называют...
Ортогонализация в записи на слайде - как теорема Фриша-Во-Ловелла, но теорема Фриша-Во-Ловелла - про декомпозицию линейной регрессии. А если у нас, допустим, используются более сложные подходы, например, такие как случайный лес, то теорема Фриша-Во-Ловелла не применяется.
Иногда путаются два термина ортогонализация в смысле зависимости тритмента и ортогонализация по Ньюманну - да, они называются одинаково, поэтому они и путаются. Что я имею в виду под ортогонализацией - мы убираем зависимость нашего результата от кофаундеров, мы убираем зависимость нашего тритмента от кофаундеров, и получается у нас как раз моделька. То же самое можно сказать про большинство методов.
Adversarial validation тоже та самая еще история. Тут кардинальная проблема между эконометристами и ML-щиками, как между воинами света и тьмы. То есть у ML-щиков как - если оно предсказывает, то почему оно предсказывает? Да и хрен с ним, хорошо. Но adversarial validation, ну просто другое смещение можете добавить. Не факт, что оно станет меньше. Конкретно у Черножукова есть доказательство того, что при определенных обстоятельствах в нужную фазу Луны случайный лес это то, что нужно.
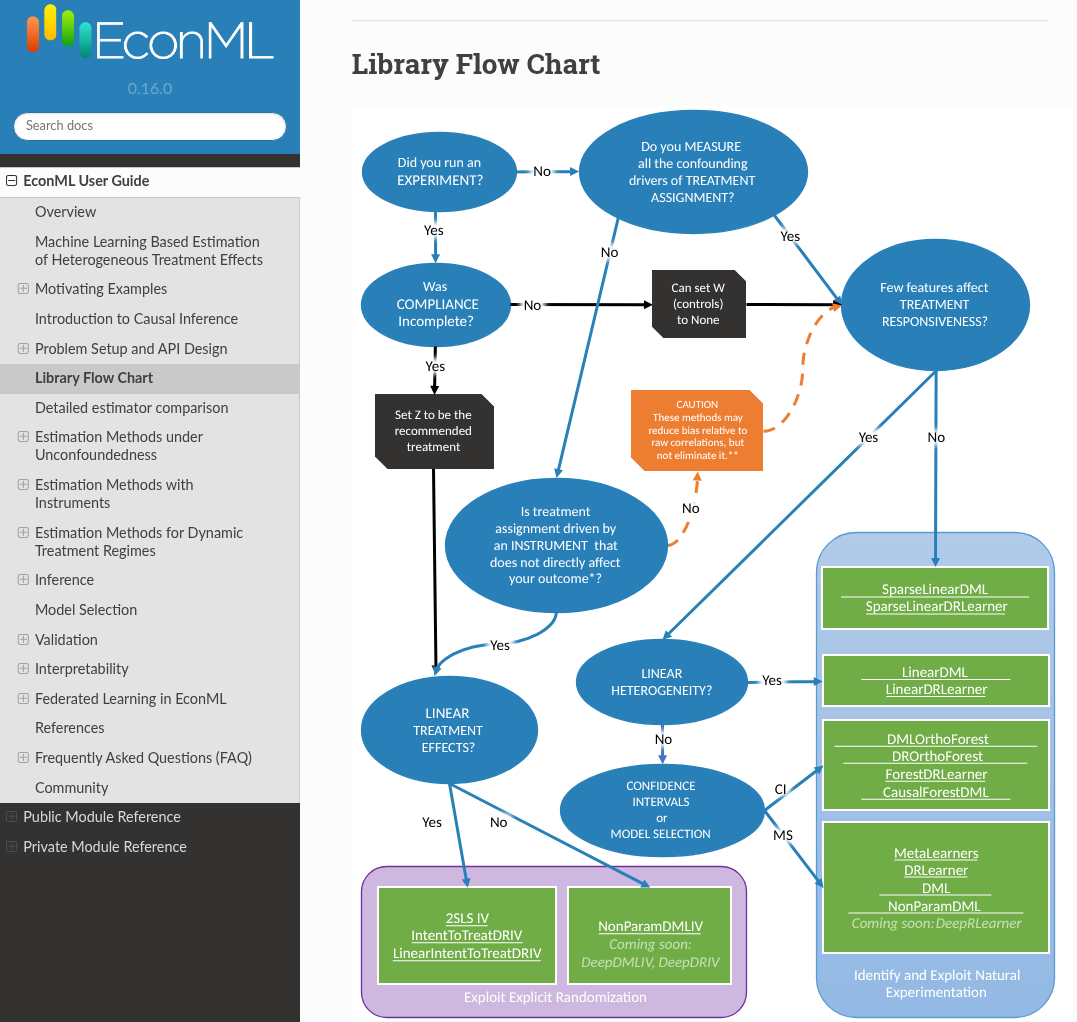
Мы будем говорить про библиотеку EconML в примерах, а еще мы будем делать игрушечные примеры с данными. Библиотека EconML, вот она, и у нее есть как раз примеры для исправления АБ-тестов, введение в Causal Inference и описание разных методов оценки в разных условиях. То есть вот конкретно здесь ссылка на статью Черножукова, который этот подход и описывает.
И сам по себе EconML делает это достаточно просто. То есть вы выбираете некоторые модели, которые будут оценивать отдельно влияние кофаундеров на ваш результат и на тритмент. А потом выбираете некоторую модель, которая будет сводить это все воедино. То есть в примерах, о которых я говорил раньше, у нас будут трилинейные модели. Ну, на самом деле, скорее всего, нет.
https://www.pywhy.org/EconML/spec/estimation/dml.html (???)
Остаток лекции (работа с ноутбуком):
- rmlci_w1.ipynb - версия с записи
- rmlci_w1_expanded.ipynb - версия с расширенными комментариями
Что итоге хочется сказать - мы даже не начали еще изучать causal inference. То есть хотелось на этих примерах просто задать общий язык, на котором можно будет говорить, потому что есть подход, которым пользуются в классической эконометрике - то есть сначала вам дают много математики, а потом вы ее собираете в кучу. Этот подход хорош, но у него есть проблема, что если математика вам в голову не попала, то дальше вам уже не интересно. Хочется сделать наоборот. Хочется показать примеры, а потом немножко, пока вы зазевались, подсунуть математику.