
- 26.12.2022
- 25.08.2024
- обучение
- #mlsystemdesign
Пятнадцатая лекция открытого курса "Дизайн систем машинного обучения", "Интеграция в бизнес-процессы".
Слайды можно скачать тут mlsysd15ods.pdf
Текстовая расшифровка:

Добрый день. У нас сегодня 15 лекция курса "Дизайн систем машинного обучения". Она посвящена интеграции ML-систем в бизнес-процессы.

Эта лекция некоторым образом предваряет две следующие лекции, которые прочитает Ирина Голощапова. Она будет рассказывать о своей методике внедрения ML в бизнес-процессы, а я по верхам подготовлю почву.

Итак, что такое бизнес-процесс? Бизнес-процесс — это совокупность мероприятий или работ, направленных на создание продукта или оказание услуги. У нас есть ГОСТ на это дело, международный и российский, который описывает этот термин бизнес-процесс. Но если неформально, то бизнес-процессы — повторяющиеся последовательности действий, с помощью которых мы организуем нашу работу.

Например, пример бизнес-процесса — процесс найма. Кандидат пишет резюме, отправляет нам, мы его либо берем в работу, либо нет. Дальше мы назначаем интервью, сама по себе фирма проводит внутренние какие-то процессы, и в результате мы либо нанимаем, либо не нанимаем человека.
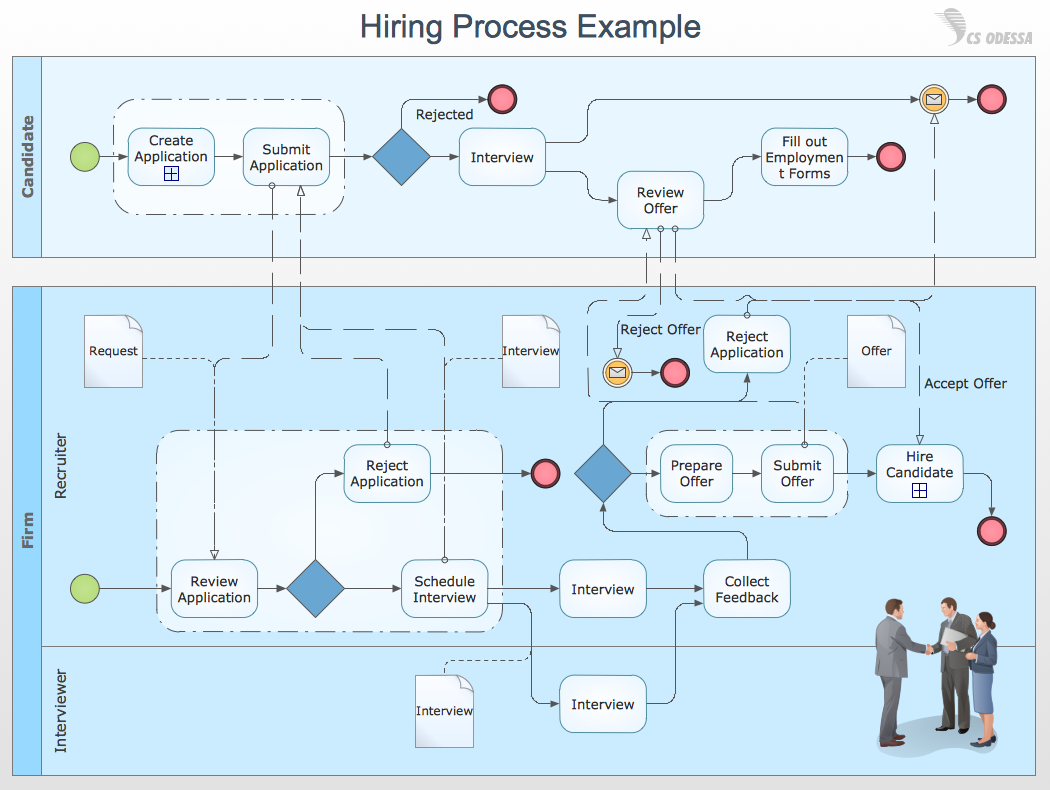{kind=link}
Дорожки, разделяют деятельности, выполняемые одним участником. В данном случае есть две дорожки — кандидат и фирма. На самом деле в фирме еще две дорожки есть — собственно рекрутер и интервьюер. Есть некоторые входы процесса, то есть что попадает на вход процесса. Есть результат процесса, есть некоторый владелец процесса, то есть тот, кто определяет, как процесс будет работать, и несет за это ответственность. Есть исполнители, то есть те, кто непосредственно в процессе работают.

Что собственно мы интегрируем — у нас есть некоторая ML-система. И куда мы ее интегрируем? В терминах стандарта на системы — это system of interest, то есть система, которую мы разрабатываем. Есть системы, которые окружают нас — system in operational environment, или смежные системы, то есть системы, которые передают нам входные данные, или системы, которые используют наши предсказания для своей работы.
Еще есть обеспечивающие системы, enabling systems. Это системы, которые нужны на разных этапах жизненного цикла системы, но не обязательно участвуют в ее операционной деятельности. Пример enabling system — это, например, система архивирования, где мы храним старые версии модели, или, например, системf регламентного обслуживания. То есть она не нужна постоянно, но без нее наша система не работает.

Есть дисциплина System Engineering, и в ней есть вики, в которых собран System Engineering Body of Knowledge. На слайде пример инженерной системы, ведь наша ML-система — это инженерная система, и частью системы является не только наш продукт, его интерфейс, технологии, но также — люди, которые ей пользуются; системы поддержки, некоторые обеспечивающие системы в зависимости от предметной области, они могут быть разные; у нас есть наше окружение, то есть есть регуляторные системы какие-то; есть наши клиенты; есть оргсистемы, которые, в принципе, с которыми мы опосредованно работаем, но они тоже влияют на нас.

Каково наше место на этой картине? Обычно это один из трех видов процессов.
Есть операционные бизнес-процессы — это процессы, которые непосредственно зарабатывают деньги для предприятия, они удобны тем, что можно измерить результат работы в деньгах, они приносят прибыль.
Есть управляющие бизнес-процессы, такие как, например, планирование и контроль качества. У них сложный KPI и не всегда, но часто важнее скорость и детализация горизонта прогноза, чем непосредственно деньги, потому что деньги там посчитать трудно — они считаются опосредованно. Например, мы оцениваем деятельность генерального директора по капитализации фирмы, но сама по себе капитализация довольно-таки сложно зависит от каждого нашего действия, и в наших процессах нам, как правило, важны скорость и детализация. Если мы можем предсказывать рынок на месяц дальше, если мы можем оценивать наши затраты на час быстрее, то мы зарабатываем больше денег.
Есть еще поддерживающие бизнес-процессы, такие как, например, бухгалтерия, найм сотрудников, техподдержка. Они обычно рассматриваются как центры затрат, то есть, попросту говоря, чем меньше мы на них потратили, тем лучше. Это упрощенный взгляд на вещи, но часто всю нашу IT-деятельность просто рассматривают как необходимую обузу, и чем ее было меньше, тем было бы фирме выгоднее.

Примеры метрик, как мы оцениваем процессы — это, например, эффективность, производительность, процент от брака, какая-то отдача на инвестиции, время цикла, то есть за какое время у нас проходит одна итерация процесса. Тут есть интересный момент, что время цикла может быть гораздо важнее, чем возврат на инвестиции. Например, мы зарабатываем на перепродаже товара какого-нибудь 10% — это много или мало? Все зависит от того, сколько раз мы успели этот товар купить, продать и снова купить. Если мы торгуем парфюмерией и умудряемся обернуть склад один раз за год, то 10% — это очень мало. А если мы торгуем продуктами и умудрились за день обернуть склад два раза по какой-то причине, то 10% — это отличная метрика, и мы с помощью сложных процессов превратим ее в очень хорошую прибыль в течение года.
Бизнес-метрики часто строятся на вот этих метриках процессов, но, в общем, они им недождественны.

Когда мы планируем построить ML-систему, мы как-то подсознательно думаем, что вот мы долго будем формулировать метрику, какое-то время будем собирать данные, строить инфраструктуру, потом долго-долго-долго мы будем обучать наш ML-алгоритм и потом принесем готовый, и он сразу пойдет в работу. На практике обычно получается, что мы действительно долго договариваемся о метриках, но гораздо дольше мы собираем данные, потом мы готовим инфраструктуру, потом, как успели, быстренько обучаем ML-модель, а потом долго и мучительно интегрируем ее в наши бизнес-процессы.

А что, собственно, сложного в интеграции? Во-первых, любая интеграция — это изменение бизнес-процессов со всеми прелестями Change Management. Во-вторых, при интеграции всегда всплывают неучтенные требования — что-то, о чем нам забыли сказать. Потом, если наш процесс не возникает в чистом поле, а заменяет какой-то другой бизнес-процесс, а обычно так оно и бывает — то у нас есть сложности перехода, есть просто инерция системы, большие системы менять трудно, а наша ML-система это обычно часть большой системы. Ну и наш предикт является шагом для какого-то другого большого процесса, и к этому шагу процесса предъявляют требования с интерпретируемостью, эскалируемостью и контролируемой деградацией, об этом мы тоже поговорим.
Эскалирование, кстати — это когда у нас процесс является частью другого процесса, и мы понимаем, что не справляемся, и вместо того, чтобы выкрутиться хоть как-нибудь, мы передаем процесс на более высокий уровень, говорим — ребята, случилось что-то, что вне моей компетенции, давайте вы разберетесь с этим сами. Люди умеют это делать, системы, построенные из людей, всегда закладывают в себя какую-то эскалируемость, а вот с ML-моделями ей труднее пойти и обратиться к начальнику со словами — Иван Васильевич, я не понимаю, как тут работать, объясните мне, пожалуйста.

Так вот, про управление изменениями. Если в смежных и обеспечивающих системах есть люди, а они обычно там есть, то вам придется учесть их интересы. Самое тривиальное — что им требуется дополнительное обучение. Менее тривиальное, но часто встречающееся — что в результате внедрения в вашей систему у них сменится KPI, то есть целевые показатели, которые им нужно достичь. Например, менеджерам по продажам повысят норму по продажам, и у них изменится оплата труда, не обязательно в большую сторону. Кто-то может быть будет уволен, у кого-то изменится граница ответственности. То есть раз теперь, например, планирование продаж занимает так мало времени — то зачем нам отдельный человек, который будет этим заниматься? Давайте мы передадим его обязанности руководителю отдела продаж, пусть он теперь сам с этим разгребается.
Может измениться схема коммуникации между сотрудниками. То есть, например, если у нас появился прекрасный алгоритм, который сам назначает тикет из поддержки на специалиста, то мы можем столкнуться с тем, что у нас разорвана цепочка коммуникации — то есть раньше пользователь звонил в поддержку, за ним записывали проблему, и, если, проблема сложная, задавали уточняющие вопросы. Теперь у нас тикеты принимаются и сортируются автоматически, и некому задать дополнительный вопрос пользователю, когда человек на основании опыта видел бы, что вот тут бы хорошо бы еще уточнить задачу. То есть могут рваться цепочки коммуникации.

Еще, как только мы начинаем сопрягать нашу систему с другими системами, мы сталкиваемся с тем, что смежные системы, то есть те, которые передают нам данные или которые от нас забирают данные, могут быть плохо документированы. Мог никто не подумать о том, как быть, если одна из систем недокументированно ведет себя в нестандартных ситуациях, то есть какая-нибудь проблема в системе пришла, она вам вернула что-нибудь странное. Или вы вернули что-нибудь странное — что делать им?
Для процессов, состоящих из людей, нормально иметь инструкции на 95% случаев, а в остальных процентах случаев просто сообщать руководителю и просить решить проблему за него, то есть — давайте как-нибудь разберемся. Во многих системах многие требования самоочевидны и нигде не зафиксированы, то есть все знают, что это так, только вам не сказали. И для выявления неучтенных требований, проверки предположений, как раз запускают пилотный проект на каком-то меньшем маленьком подмножестве. Это что-то вроде канареечного деплоя, когда мы жертвуем одним магазином, маленькой группой пользователей, и у нас появляется возможность отладить наши процессы, выявить неучтенные требования.

Плюс есть еще сложности перехода, когда нам нужно обеспечить совместимость с другими системами. Например, мои знакомые разработчики делают дополнительное оборудование, которое позволяет из глупого лесопильного станка сделать умный лесопильный станок. То есть вы ставите коробочку на станок, и он начинает работать экономичнее, лучше, замечательнее. Они продают это производителям станков. Есть одна проблема, что им нужно обеспечить совместимость с другими системами в той системе, в которой они интегрируются. В данном случае — а что будет, если станок сломается? Нужно ли им самим ездить по всей стране и ремонтировать эти станки? Или они смогут обеспечить какую-то документацию и инструкции для уже существующих служб, которые эти станки ремонтируют? Сможет ли мастер, который до этого ездил смазывать станок, настраивать натяжение ремней и заменять сгоревшие электромоторы, также установить обновление на программное обеспечение или там, скажем, поменять сгоревшую Raspberry Pi, или переподключить веб-камеру?
Получается, что вы должны обеспечить не только работу системы, но и обеспечить стыковку с обеспечивающими системами, которые нужны системе для работы, но, возможно, не всегда, а только на каких-то этапах ее жизненного цикла.
Вы должны, скорее всего, обеспечить параллельную работу старой и новой системы во время миграции, то есть вам никто не даст сломать систему, поставить новую, отладить и запустить.
В этом случае часто делают интерфейс-фасады, которые позволяют использовать новую систему в старой. Например, у нас есть колл-центр, который мы хотели бы автоматизировать, и вместо того, чтобы заменить операторов, мы в их систему коммуникации с клиентами добавляем специальные кнопочки — то есть как бы ответила программа. И они могут не набирать ответ, а просто нажать кнопочку, и программа скопирует готовый подготовленный ответ. Тем самым мы ускоряем их работу и проверяем работу нашей системы — то есть, если операторы не пользуются предложенными подсказками, то, наверное, что-то не так с нашей новой красивой модной системой.
Иногда делают наоборот. То есть предположим, что у нас пока решения делают люди, но мы оборачиваем их решение в API, мы вызываем это API, у людей появляется наш запрос, люди пишут ответ, ответ уходит в наше API, мы приходим и получаем наше решение. Конечно не сразу, медленно, то есть это асинхронная API, но мы можем использовать старую систему и притвориться, что это уже новая система, и постепенно часть запросов переключать на новую систему — а потом, когда все заработает, мы переключим на новую систему и от старой можем отказаться.

Еще у систем обычно большая инерция — чем система больше, тем больше ее инерция. ML-системы ошибаются не там, где люди, и люди привыкли и приспособились к ошибкам людей, и людей очень раздражают ошибки, которых они не делали бы сами. Предположим, что у вас есть система ассистент врача, которая очень хорошо может выявить ошибки, хорошо выявить, допустим, раковые опухоли или какие-то заболевания на коже, но она не в состоянии отличить мужчину от женщины при заполнении карточки. Или, допустим, она путается при заполнении карточки, мужчина это или женщина. Человек бы не сделал такой ошибки, но человек мог бы пропустить опухоль на рентгене. И нам надо учитывать, что мы будем делать, когда ML-системы начнут ошибаться там, где никто сейчас не ошибается, и к этому не готов. То есть там, где люди часто ошибаются, уже подстелена соломка, все обложено правилами, проверками, чек-листами. ML-система может работать с таким же в среднем качеством, но просто ошибаться не там, и это может быть неприятно.
Потом часто трудно оценить влияние новой системы на всю организацию. Всегда есть какие-то процессы, которые объективно усложнились в внедрении системы. Основной процесс, который мы автоматизировали, стал быстрее, лучше, качественнее, но какие-нибудь вспомогательные процессы из-за этого затруднились. И, таким образом, внедряя новую систему, мы будем мешать людям. Люди будут сопротивляться. Поэтому при внедрении новой системы нам нужен кредит доверия. Обычно это воля директора, старшего руководителя, как говорят — первых трех людей в иерархии. Или какой-нибудь большой прирост производительности и экономии, за который вам простят неудобства. То есть о кредите доверия, то есть о том, что позволит вам перейти через начальное сопротивление, надо думать еще до начала внедрения.

Важный момент — это интерпретируемость. Когда человек делает что-то странное, то мы его можем спросить — почему так поступил? И он нам расскажет. В ML-модели эту функцию надо обеспечивать отдельно.

Важный момент работы больших систем — это контролируемая деградация. В большой системе всегда что-нибудь ломается. И если откажет новая ML-система, можем ли мы временно переключиться на старую?
Из ситуаций, которые я наблюдал вживую — финансовый сервис в момент объявления карантина, когда руководитель страны выступил и сказал, что мы не дадим наших заемщиков в обиду, то есть людей, которые взяли кредиты. Люди это восприняли как сигнал, что можно брать кредиты и не отдавать. И в результате модель, которая раньше предсказывала, отдаст кредит человек или нет, стала давать странные предсказания. Мониторинг это дело выловил, и финансовый сервис, с которым мы тогда сотрудничали, просто переключился на ручной андеррайтинг. До момента, пока модель накрутится, они проверяли заявки вручную, чтобы хоть какие-то заявки обрабатывать. Они достаточно быстро скорректировали модель, но, тем не менее, период ручного андеррайтинга был, когда никто не понимал как жить и мы переключались от новой системы к старой.
Иногда нам нужен способ временно повысить производительность системы ценой снижения качества. То есть предположим, что у нас какие-то передновогодние продажи, и наша рекомендательная система работает чуть-чуть медленно, она тормозит работу сайта. Нам нужно ее либо отключать, либо переключать в режим, когда она работает быстро, пусть и тупо. То есть вместо того, чтобы делать персонализированные рекомендации, мы просто отдаем топ-5 самых продаваемых товаров. То есть мы получим прирост в продажах не 6%, как дала бы нам рекомендательная система, а 3%, но все-таки это будут продажи.
Контролируемая деградация это вещь, которую нужно закладывать в систему, если вы хотите обеспечить ее надежное функционирование. По ссылке статья с разбором того, как контролируемая деградация может быть устроена в разных системах.

Получается, что при внедрении системы приходится помнить об очень большом количестве вещей, и всегда, когда у нас возникает что-то, что может не уместиться в голове, нас спасают контрольные списки. Хороший пример такого контрольного списка при разработке ML-системы — это Data Project Checklist Джереми Ховарда, предпринимателя и преподавателя, который сделал курсы Fast.AI. Он предлагает пройти по контрольному списку по стратегии — где, собственно говоря, мы возьмем пользу, почему наша модель принесет пользу; как мы можем повлиять, усилить или что может ослабить эффект нашей модели; что у нас данными, доступность и насколько они подходят для решения нашей задачи; собственно аналитика, как мы будем делать предсказания и извлекать какие-то инсайты из данных; как мы будем реализовывать, какие нам нужны IT ресурсы и люди; и как модель будет работать в продуктовом окружении поддержки.

У Google есть прекрасный инструмент, прекрасный набор методик, чек-листов, инструкций — The People + AI Guidebook. Это набор шаблонных решений, типичных проблем при взаимодействии людей и AI-систем. То есть, например — как я могу ответственно построить мой датасет, чтобы не дай бог кого-нибудь не дискриминировать? Или как я буду показывать, продавать пользователям новые AI-фичи так, чтобы они согласились ими использовать? Хорошее руководство, рекомендую посмотреть.

Есть известный так называемый Startup Canvas, где расписывается то, как создается стоимость стартапов, и есть такая же модель для ML-проектов. То есть, для того, чтобы понять, будет ли ваш проект успешен, на одном листе А4 просто расписываете окружение — то есть, что собственно хотят ваши пользователи, какие у них есть боли; как вы их будете решать, что вы предлагаете, какую ценность вы приносите пользователям; какие ключевые показатели нам нужно обеспечить, чтобы проект взлетел; как-то описать в двух-трех словах решение, почему оно вообще возможно; какие у нас есть данные, какие метрики, как мы будем оценивать; как мы будем моделировать, что у нас будет с экспериментами; как мы будем собирать фидбэк и как мы организуем управление проектом. Как ни странно, такая простая схема на листе А4 часто позволяет выявить большие проблемы нашего проекта еще до того, как мы начали что-то программировать и собирать данные.

Для собеседований есть прекрасный ресурс ML Design Template, который позволяет подготовиться к ML Design интервью, но он полезный не только для собеседования, то есть те шаги, которые вам приходится пройти на собеседование, они же вообще-то и в работе полезны, то есть они не с неба упали.
Шагов 8 — то есть мы уточняем требования, мы делаем какие-то предположения об архитектуре данных, как мы будем работать с данными, то есть наша ML Ops стратегия для данных, потом как мы будем моделировать, ML Ops стратегия для моделирования, как мы будем непосредственно вытаскивать модель на прод, и наша ML Ops стратегия для сервинга.

Ну и последнее, о чем хотелось сегодня рассказать, это ML System Design Doc. Ирина Голощапова в канале #Reliable ML опубликовала свою методику, и у нее будет лекция по этому поводу, по так называемым Design Doc. Design Doc — это такой живой чек-лист, который вы в процессе работы над проектом дописываете, и по мере того, как у вас появляется дополнительная информация, вы выявляете какие-то ограничения, новые требования приходят, и вы его дополняете. Это живой журнал, живой срез вашего представления о том, как устроен будет дизайн вашей системы.
Участники разработки — это product owner, то есть постановщик задачи, владелец бизнес-задачи; data scientist, в данном случае их может быть много, он тут указан как один; A/B Testing Group, то есть в большой организации у вас всегда есть какая-то группа людей, которая отвечает за контроль показателей вашего проекта, то есть вы выкатили систему, ее будут тестировать, вам будут оценивать пилот, есть специальные люди, которые будут этим заниматься, вам нужно привлечь их к дизайну вашей системы. Там разбираются цели и предпосылки, методология, подготовка пилота и внедрение, про это Ирина рассказывает в своих лекциях:

Дополнительные материалы: